Downloaded accillaries of Murphy's Introduction to AI robotica (Aug 2020).
Requested accilaries for Bhandari's Computational Imaging (Mar 2023).
Downloaded the slides of Torralba's Foundations of Computer Vision (Sep 2024). Converted the key-presentation with the German cloudconvert. Introduction lecture on image formation was already quite interestin
Waveshare also has an outdoor base with a payload of 12kg: the Cobra Flex. Strong enough to carry a robot-arm:
The UGV02 has a payload of 4kg, and the robot arm is mounted off-center:
With the rf2o_odometry working so well, it would be interesting to look at Peter Corke's exercise 6.9.2.12, which asks for a test on the path saved in killian.g2o (see section 6.8.1).
In the camera matrix the skew is typically zero, see blog. The skew is defined as s = f_x tan α, according to Matlab documentation.
When the resolution doubles, the focal length only changes with the sqrt(2).
December 5, 2025
The Basic Knowledge on Visual SLAM: From Theory to Practice has several nice practical sections, like section 10.4 (loop closure with Bag-of-Words), which illustrates slide 48-49 from Lecture 5-2: VisionForRoboticsVisualSLAM2025. Yet, the ch12/loop_closure.cpp is C++ code, so should be ported to python first. Could look what cpp2py could do here.
I like the discussion in section 10.5.5 (Relationship with ML): Loop detection itself is very much like a classification problem.
The difference with traditional pattern recognition is that the number of categories in
the loop is enormous. The samples of each category are very small. When the robot
moves, the image changes, and new categories are created. Categories are treated as
continuous variables rather than discrete variables; loop detection, equivalent to two
images falling into the same category, is rarely seen. From another perspective, loop
detection is also equivalent to learning the concept of similarity or metric learning.
Since humans can determine whether images are similar, it is possible for machines
to learn such concepts.
There is also a 2D/3D lidar version of the book: SLAM in autonomous driving and robotics.
I like Barfoot's Fig 4.17, which illustrates the sliding window filter. Could be added between slide 26 and 27 in lecture 5-2: VisionForRoboticsVisualSLAM2025.pdf.
Chapter 6 covers the 3D geometry of image formation (including stereo-camera's and IMUs).
Chapter 7 (Lie Algebra), which is nicely summarized with the formula's on page 252-253 (correspondence of Lie Algebra with Jacobians).
Section 9.2 finally covers SLAM and in section 10.2 STEAM (which also give trajectory estimates between the observations).
Tried ros2 launch ugv_vision camera.launch.py use_rviz:=false, which gave complaints that the topics /image_raw and /camera_info are out of sync.
For every 30 CameraInfo messages, only 7-9 image messages are published.
The script publishes both the rectified and raw images, both with a compressed and compressedDepth variant. The framerate is in ugv_vision/config
/params.yaml, so could be adjusted to less than 30 Hz.
The supported formats can be expected with ros2 run usb_cam usb_cam_node_exe:
Motion-JPEG 1920 x 1080 (30 Hz)
Motion-JPEG 160 x 120 (30 Hz)
Motion-JPEG 320 x 240 (30 Hz)
Motion-JPEG 352 x 288 (30 Hz)
Motion-JPEG 640 x 480 (30 Hz)
Motion-JPEG 800 x 600 (30 Hz)
Motion-JPEG 1024 x 768 (30 Hz)
Motion-JPEG 1280 x 720 (30 Hz)
Motion-JPEG 1280 x 960 (30 Hz)
Motion-JPEG 2592 x 1944 (30 Hz)
Motion-JPEG 2048 x 1536 (30 Hz)
YUYV 4:2:2 640 x 480 (30 Hz)
YUYV 4:2:2 1280 x 720 (10 Hz)
YUYV 4:2:2 2048 x 1536 (1 Hz)
YUYV 4:2:2 1920 x 1080 (5 Hz)
YUYV 4:2:2 1280 x 960 (5 Hz)
YUYV 4:2:2 960 x 540 (10 Hz)
YUYV 4:2:2 800 x 600 (10 Hz)
YUYV 4:2:2 2592 x 1944 (1 Hz)
In the params.yaml of ugv_vision av_device_format UYV422P is chosen, but pixel_format mjpeg2rgb. The bare node indicates that no accelarated colorspace coversion is available from yuv422p to rgb24.
Note that they suggest to submit compressed, and uncompress the images to vizualise them.
With the camera they recommend mjpg-streamer as resource.
The executable is 32bits ARM. Building from scratch fails on opencv-plugin, no clear way to select only part of the plugins.
Switched of the opencv-plugin in CMakelists.txt
Now the MJPG Streamer is build. Started jpg_streamer -i 'input_uvc.so' -o 'output_http.so -w /www', which gave a slow stream at http://127.0.0.1:8080/?action=stream
To get the program running, I needed to clone recursive.
Also run python3 install_requirements.py, which uninstalled my depthai version 3.1.0, and installed version 2.30.0 instead.
As by-product also opencv_contrib_python was downgraded to version 4.5.5.62.
Still, Axes3D was not working because multiple version of matplotlib were isntalled. Removed the apt-version with sudo apt remove python3-matplotlib.
Had to do python -m pip cycler fonttools kiwisolver before all dependencies were solved.
Pointed the OAK-D-Lite to Charuco board 10x7, but still received unable to find chessboard. Tried with python3 calibrate.py -s 4 -nx 10 -ny 7, still a problem. Printing the smallest charuco_board of 13x7 failed on Linux.
Looked into the code of calibrate.py. The status of the capture left and right are both True, still show_failed_capture_frame is called. The capture of color is the one that fails.
The color camera is the IMX214, which indeed has a different field of view (and seems very blurry). Yet, the script gives for the color focus True, while the focus is false for left/right. Used the dsb option for the color-camera.
Recorded 39 images left/right. The reprojection error of the right is 0.0, the intrinsic calibration of the left failed (device closed in exception).
Played around with color camera, with the focus set correctly. Modified the code to make sure that the right focus was set, and started the calibration with python3 calibrate.py -s 4 -nx 10 0ny -dsb left right -rlp=80. Optimum is somewhere between 50-135. Yet, with focus=80 the tags were well recognized.
Collected 39 images, but the code now fails on line 969 of the code on NoneType in objects.
Back to depthai-core DynamiCalibration. Had to upgrade again with python -m pip install depthai--3.10. Showing the charuco_board to the camera.
The line wiht Data Acquired went up to 100%. At that moment the Dynamic calibration status went from Not enough data to No error. Received Succesfully calibrated!
The succesfull calibration report directly following indicated a rotation difference of 0.01 deg, a achievable Sampson error of 0.123px, a current Sampson error of 0.122px, a theoretical depth error rangeing from 0.19% @1m to 1.83% @10m.
Looking further back I also see the Dynamic calibration status New calibration doesn´t have a significant impact
The pan-tilt camera is described here, which points to the camera as Rasberry-Pi camera with 160 deg field-of-view. Yet, with lsusb -v shows itself as a Xitech USB Camera. It is actually IMX335 camera.
Started with the gmapping example. Modified view_slam_2d.rviz, changeing the Reliability of the map from Reliable to Best Effort. That helps, although got still warnings on dropping base_lidar_link:
Trying to also change the RobotModel and LaserScan to Best Effort. Could not test this setting, because the Wifi was overloaded.
Seems that starting ros2 launch ugv_vision oak_d_lite.launch.py overloads the system, I see with top a process at 100%.
Tried instead ros2 launch depthai_ros_driver camera.launch.py, which only uses 22% of the CPU. Yet, ros2 run image_view image_view --ros-args --remap image:=/oak/stereo/image_raw showed nothing.
I looked at the TF-tree, but see no TFs, can also not change the Fixed frame.
Rebooted, received one image (after switching to the oak-frame). Tried the compressed one, but got [component_container-1] [ERROR] [1764168531.438835946] [CompressedPublisher]: [16UC1] is not a color format. but [mono8] is. The conversion does not make sense. On the rviz2 side I got !buf.empty() in function 'imdecode_'.
Looking again to the dynamic calibration examples. On UGV Rover #12, I cloned https://github.com/luxonis/depthai-core.git.
The python3 in ~/ugv_jetson points to /usr/bin/python, which doesn´t exist. /usr/bin/python3 exits, which is used.
Installed python3 -m pip install depthai, which installs depthai-3.1.0. It has a dependency on numpy<3.0.0, which is satisfied.
Yet, it fails on opencv (no Text). The current opencv-contrib-python is 4.10.0.84.
Tried python3 -m pip install opencv-contrib-python==4.9.0.80. Same error.
Tried python3 -m pip install opencv-contrib-python==4.7.0.72. That gives partially initialized module 'cv2' has no attribute 'gapi_wip_gst_GStreamerPipeline'
Tried higher version, which gave problems with numpy>2.0. Installed numpy==1.26.4 again.
Trying lower versions, like 4.6.0.66 (both opencv-python and opencv-contrib-python). Still problem with GSStreamerPipeline.
Finally succes with version 4.5.5.64. First received an X_LINK_DEVICE_ALREADY_IN_USE error, but next was no Qt platform (no display).
Went to trouble-shooting, and indeed there were no 80-movidius.rules. There was 50-qualcomm-oak.rules, with another vendor (and an explicit Product).
Once the udev-rules were set, the script python3 calibration_quality_dynamic.py started working. Only, it seems that it has not enough data:
Pointed it to the charico_42inch screen, still it gives not enough data. Indicates that the current error is 0.331 pix, while 0.255 is possible.
First installed xelatex with sudo apt-get install texlive-xetex. When algorithm2e.sty was not installed, also did sudo apt-get install texlive-science. Failed on /include commands, but including the chapters with /input worked.
Now it fails on missing font Monaco, which is the system-font of Macs.
Tried sudo apt-get install texlive-fonts-extra.
The build command xelatex -synctex=1 -file-line-error -output-directory=./release -jobname=31104 slambook-en.tex still fails on the missing Monaco font.
I love the Hotel and Ball streams Tomasi and Kanade use.
The sparse measurement matrix on slide 50 resembles the figure from Tomasi and Kanade.
Also like slide 61, converting the unit-vectors to a graph of camera positions.
Also like slide 66, with explains selecting the right Bundle-Adjustment pairs from the Neptune fontain in Rome.
As origin for her slides, she points to Cornell: Introduction to Computer Vision (2022) by Noah Snavely and Berkeley Introduction to Computer Vision (2023) by Angjoo Kanazawa.
The robotic applications in chapter 15 were in the 2001 draft still missing, the textbook is published by Springer in 2004.
In the 2nd lecture the new content starts at slide 41, with Shape from Shade and Depth from Normals (slide 79).
Shaodi skipped slide 60 of the StereoVision lecture, which gives the details of the Luxonis camera of the RAE (which should be updated with the Luxonis camera of the UGV Rover). Anyway, the first part is important for the obstacle avoidance, the 2nd part for the localization.
Students asked for the Depth camera documentation. There was a link in Lab0, should also add it the 2nd assignment (and test the camera-feed). Done.
Should also highlight next week that inside the 3D-SLAM, you can incorporate multiple odometry-sources.
Next week again SfM pops up (with motion constraints). Ends with GraphSLAM, while Gmapping/Cartographer are not mentioned (2D mapping on UGV Rover), nor COLMAP or RTAB-MAP.
Checked again the ROS2 SLAM comparison, which compares cartographer versus rtabmap for a simulated Turtlebot.
Tried to do ros2 run rqt_graph rqt_graph directly on UGV Rover 12.
The jetson partition has no ros, so tried to display from docker.
At the end I found the solution via stackoverflow. Before starting the docker, I did xhost +. Started the docker and connected with ssh -X -p. Defined export DISPLAY=:1. Now I could do xclock (installed with x11-apps) and ros2 run rqt_graph rqt_graph. Yet, only the LD19 node showed up (2nd time even none).
Luckely the 3rd time also the /ugv_bringup and /ugv/joint_state_publisher showed up:
Interesting is for instance Continual SLAM, based on visual+IMU input.
Trying to install the whole project with git clone https://github.com/opendr-eu/opendr.git, but is at last 2.47 GiB.
This are the release nodes of v3 of the OpenDR toolkit.
The activate script doesn't work, because no venv is present. Yet, some environment variable are added, including OPENDR_HOME.
Only one package gives warnings (Policy CMP0148 not set - see below).
Looked at the OpenDR Perception prerequisites, and started the usb_cam_node. The pose estimation ros2 run opendr_perception pose_estimation failed, because torch wasn´t in my Python-path.
Looked into ~/git/opendr/dependencies/dependencies.ini and did pip install torch==1.13.1, which also installed nvidia_cuda cu11 packages.
Still, opendr could not be loaded. export PYTHONPATH=$OPENDR_HOME/src:$PYTHONPATH from ~/git/opendr/bin/activate.sh solved that.
Still, opencv is missing. In ~/git/opendr/bin/install_nvidia.sh the required version is given: pip3 install opencv-python==4.5.4.60 opencv-contrib-python==4.5.4.60. Also did pip3 install numpy==1.19.4. That wheel couldn´t be found.
Did pip3 index versions numpy and tried version 1.19.5 (2.2.6 was installed). Also failed. Could install the latest numpy-1 version (1.26.4), although that gives a conflict with rerun-sdk 0.25.1.
Now ros2 run opendr_perception pose_estimation fails on cannot import name 'Classification2D' from 'vision_msgs.msg'.
According to this post, 'Classification2D' was renamed 'Classification' (or vice-versa). Indeed, modifying the bridge.py solved that.
Next missing dependency is onnxruntime. bin/install_nvidia.sh indicates v1.3.0, installed the lowest available version (v1.12.1).
Next missing dependency is tqdm. bin/install_nvidia.sh indicates v4.54.0, installed v4.54.1
Also installed torchvision==0.14.1 and pycocotools==2.0.10.
Still, Could not import 'rosidl_typesupport_c' for package 'opendr_interface'. Check the policy-warning (tomorrow).
November 12, 2025
Checked ugv_bringup documentation, and try to make a rosgraph. Checking at WSL, I only got part of the nodes that are visible with ros2 node list. ros2 run rqt_graph rqt_graph gave:
Moving to native Ubuntu. No node at all. Installed greenwave_monitor on UGV Rover 12, both /scan and /odom_rf2o are published with 10 Hz.
Also installed greenwave monitor on my Ubuntu, yet get Could not import 'rosidl_typesupport_c' for package.
Strange, because sudo apt install ros-humble-rosidl-typesupport-c was already installed.
Modified the greenwave_monitor_interface CMakeList.txt, with two additional statements to build the package without warnings:
cmake_minimum_required(VERSION 3.10)
cmake_policy(SET CMP0148 OLD)
Still ros2 run greenwave_monitor ncurses_dashboard fails on No module named 'greenwave_monitor_interfaces.greenwave_monitor_interfaces_s__rosidl_typesupport_c'.
I used as rebuild command colcon build --allow-overriding greenwave_monitor_interfaces --packages-select greenwave_monitor_interface.
When this didn´t work, I did colcon clean workspace and colcon build. Still same error.
Problems with starting up (python3 still running on jetson). Tried serial_simple_ctrl.py from UGV02 wiki. Tried python3 serial_simple_ctrl.py /dev/ttyAMA0 which gave no error, but also no response. python3 serial_simple_ctrl.py /dev/ttyTHS1 gave the error UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc1 in position 13: invalid start byte.
Launching ros2 launch ugv_bringup bringup_imu_ekf.launch.py use_rviz:=false gives me the JSON decode error: Expecting value: line 1 column 1 (char 0) with line: z":1404,"odl":0,"odr":0,"v":1204}. Tried 3x, same error, while the other launch files work fine.
Yet, the /odom is visible from rviz, but when adding a panel it gives: Message Filter dropping message: frame 'odom' at time 1762338021.593 for reason 'discarding message because the queue is full'.
Inspecting with ros2 topic info /odom -v shows that the reliability is RELIABLE and the durability VOLATILE.
What is more concerning is ros2 topic info /odom/odom_raw -v, which shows that there is only a subscriber, no publisher. Should check what the happens when I add a imu_complementary_filter node.
Had to do sudo apt-get install ros-humble-imu-tools first.
Also had to do sudo dpkg -i /tmp/ros2-apt-source.deb before I could do sudo apt update && sudo apt upgrade -y could be done. That is an update of 764 packages!
Note that essential tools like vi and ifconfig are not installed. ifconfig is depreciated, so did sudo apt-get install iproute2
Started ros2 run imu_complementary_filter complementary_filter_node --ros-args -r do_bias_estimation:=true -r do_adaptive_gain:=true -r use_mag:=false (setting gain_acc or gain_mag didn´t work). Note that the node names itself differently. ros2 node info /ComplementaryFilterROS shows that it also reads /imu/data_raw, and publish /imu/data
Note that essential tools like vi and ifconfig are not installed. ifconfig is depreciated, so did sudo apt-get install iproute2
Started ros2 run imu_complementary_filter complementary_filter_node --ros-args -r do_bias_estimation:=true -r do_adaptive_gain:=true -r use_mag:=false (setting gain_acc or gain_mag didn´t work). Note that the node names itself differently. ros2 node info /ComplementaryFilterROS shows that it also reads /imu/data_raw, and publish /imu/data. Also /imu/data_raw has one subscriber, no publisher.
Check after lunch if bringup_imu_origin.launch.py works.
Started ros2 launch ugv_bringup bringup_imu_origin.launch.py, which failed on JSON decode error. Could I add some way to clean the JSON-buffers, or add some protection. For now, try again.
There were two nodes /ugv_bringup running. Tried ros2 lifecycle set ugv_bringup shutdown, but no Node found.
Running ros2 launch ugv_bringup bringup_imu_origin.launch.py started 6 nodes. Tried os2 run rqt_graph rqt_graph but no node or topic shoed up (although visible with os2 node list
Inspecting the nodes, indicates that the node ugv_bringup is the one that publishes the /imu/data_raw and /odom/odom_raw. Also node that voltage is both published by ugv_driver and ugv_bringup
Created a rviz which displays the Odom and IMU-values. The covariance of the orientation is huge, switched it off.
Checked the parameters of the node with ros2 param list.
Checked the performance when run as two independent nodes. Got again the buffer messages. This post suggested to do sudo timedatectl set-ntp true, but the system has not been booted with systemd.
Instead, did sudo apt-get install ntp, followed by sudo ntpd -qg && sudo hwclock -w.
Didn´t help. Timezone was still China. Also sudo timedatectl set-timezone Europe/Amsterdam doesn´t work in Container, because no systemd is started.
Changed it manually, by sudo ln -sf /usr/share/zoneinfo/Europe/Amsterdam /etc/localtime and editing /etc/timezone. Still the discarding occurs.
With ros2 launch ugv_bringup bringup_imu_origin.launch.py the problem doesn´t occur. Inspected with ros2 topic info /odom -v, do not see any difference.
Made a launch-file that starts the two nodes together, that works.
Also tried to create bringup_base_node_ekf.launch.py which fails in the container on missing robot_localization, which can be solved by sudo apt-get install ros-humble-robot-localization -y.
The play_robot_started.py only plays a sound, so the services to print something to the display are also not started. Seems that the /dev/video0 is claimed by the vizanti_server in the app.py script, instead of the Jupyter notebook. The notebook seems to be started differently, as a service which starts at boot.
Still, runnig rosmaster_x3_gazebo.sh fials on the mecanum_drive_controller:
[ign gazebo-3] Exception thrown during controller's init with message: Invalid value set during initialization for parameter 'front_left_wheel_command_joint_name': Parameter 'front_left_wheel_command_joint_name' cannot be empty
Changed the test_mecanum_drive_controller.yaml, but it seems not be loaded (even after a new build). Not sure where the yaml is specified. At least not explicit in load_ros2_controllers.launch.py.
The URDF of the robot can now be extended with a ros2_control-tag.
The simple commmand ros2 control list_controllers doesn't work (yet), because waiting for service /controller_manager/list_controllers to become available.... Same for ros2 control list_hardware_interfaces and ros2 control view_controller_chains.
Checking 2023 presentation ricycle Controller with ros2_control, but only learned that there is an initiative to let mobile base controllers inherit from SteeringControllers, but it is not clear if this functionality is now finished. documentation implies that it can be used for a bicycle, tricycle and Ackerman mobile robots.
Looked again at rosmaster_description, in robots/rosmaster_x3.urdf.xacro first a number of sensors and actuators urdf are loaded, while at the end three control-urdfs are loaded: control/velocity_control_plugin.urdf.xacro, control/gazebo_sim_ros2_control.urdf.xacro and control/rosmaster_x3_ros2_control.urdf.xacro.
If the parameter use_gazebo is true, the gz-sim-velocity-control-system plugin is loaded.
Looked into ~/ros2_ws/install/yahboom_rosmaster_description/share/yahboom_rosmaster_description/urdf/, there are actual separate directories for robot, sensors, mech and control. This ros2_control-tag is sed in control/rosmaster_x3_ros2_control.urdf.xacro, with parameters name="RobotSystem" type="system". The 4 joints are defined, and for hardware the gz_ros2_control/GazeboSimSystem
Started with the first part of the workshop. After colcon build the command ros2 launch controlko_description view_rrbot.launch.py works. The launch-file starts three nodes: joint_state_publisher_node, robot_state_publisher_node and delay_rviz_after_joint_state_publisher_node. ros2 node list shows also an additional transform_listener. The rrbot-description is implemented with macro and xarco's. The real ros2_control-tag can be found in rrbot/rrbot_macro.ros2_control.xacro. The control has two sensors, one force-sensor at the tip and flange_gpios, although I don't see them in ros2 topics.
Still no response from ros2 control list_controllers.
Continued with the 2nd example. With ros2 launch controlko_bringup rrbot.launch.py robot_controller:=joint_trajectory_controller the robot started to move in RVIZ, when I did ros2 launch controlko_bringup test_joint_trajectory_controller.launch.py in another terminal.
Now ros2 control list_controllers gives two controllers:
joint_state_broadcaster joint_state_broadcaster/JointStateBroadcaster active
joint_trajectory_controller joint_trajectory_controller/JointTrajectoryController active
Even more informative is ros2 control list_hardware_interfaces:
command interfaces
flange_gpios/digital_out_1 [available] [unclaimed]
flange_gpios/digital_out_2 [available] [unclaimed]
joint1/position [available] [claimed]
joint1/velocity [available] [unclaimed]
joint2/position [available] [claimed]
joint2/velocity [available] [unclaimed]
state interfaces
flange_gpios/digital_in_1
flange_gpios/digital_in_2
flange_gpios/digital_out_1
flange_gpios/digital_out_2
joint1/effort
joint1/position
joint1/velocity
joint2/effort
joint2/position
joint2/velocity
tcp_fts_sensor/fx
tcp_fts_sensor/fy
tcp_fts_sensor/fz
tcp_fts_sensor/tx
tcp_fts_sensor/ty
tcp_fts_sensor/tz
The command ros2 node list shows now two additional nodes:
/controller_manager
/joint_trajectory_controller
Note that /joint_state_publisher has become /joint_state_broadcaster.
The joint-trajectory_controller loads four positions from config/test_goal_publishers_config.yaml
Fourth step shows how to inspect which interfaces a controller requires: ros2 control list_controllers -v
Running ros2 launch controlko_bringup test_forward_position_controller.launch.py directly didn't work (controller is clearly active, but not visible from control manager). Only when it is spawned with ros2 run controller_manager spawner forward_position_controller --inactive the forward_position_control becomes visible with ros2 control list_controllers this controller also only needs the two joint-positions.
Now I could do ros2 control switch_controllers --deactivate joint_trajectory_controller --activate forward_position_controller and I see them the joints claimed. The RVIZ robot-model doesn't move, it starts to move when ros2 launch controlko_bringup test_forward_position_controller.launch.py is starting to publish its 4 goal-positions (robot really jumps instead of slow moves).
As expected, ros2 launch controlko_bringup rrbot_sim_gazebo_classic.launch.py didn't work, although the script came further than expected. Only one error message:
[ERROR] [gzclient-2]: process has died [pid 1152942, exit code -6, cmd 'gzclient --gui-client-plugin=libgazebo_ros_eol_gui.so'].
During the start I see also one interesting warning:
[gzserver-1] [WARN] [1762193723.781208310] [gazebo_ros2_control]: Skipping sensor in the URDF named 'tcp_fts_sensor' which is not in the gazebo model.
As expected, ros2 launch controlko_bringup rrbot_sim_gazebo.launch.py starts without errors. Interesting warnings:
[ign gazebo-1] [WARN] [1762194008.273748801] [joint_trajectory_controller]: [Deprecated]: "allow_nonzero_velocity_at_trajectory_end" is set to true. The default behavior will change to false.
[ign gazebo-1] [INFO] [1762194008.291317839] [joint_trajectory_controller]: No specific joint names are used for command interfaces. Using 'joints' parameter.
Could switch controllers and command the Gazebo rrbot with ros2 launch controlko_bringup test_forward_position_controller.launch.py.
Not clear why in yahboom the mecanum-drive-controller is build from source, because sudo apt install ros-humble-mecanum-drive-controller should also work.
Looked in the modifications made by Addison with git log. Several modifications were made in June/May, including Fixed calling set_value() on an std::optional without first checking if it contained a valid handle.
Quite some modifications on mecanum-drive-controller, most seem Ok.
Tried colcon build --packages-select mecanum_drive_controller. That gives a warning that 'mecanum_drive_controller' is already in: /opt/ros/humble
Too much changed in the mean time between Humble and Jazzy.
Added COLCON_IGNORE in mecanum-drive-controller. starts, but the mecanum_drive_controller crashes:
[ign gazebo-3] [INFO] [1761746204.335864431] [controller_manager]: Loading controller 'mecanum_drive_controller'
[ign gazebo-3] Exception thrown during controller's init with message: Invalid value set during initialization for parameter 'front_left_wheel_command_joint_name': Parameter 'front_left_wheel_command_joint_name' cannot be empty
[ign gazebo-3] [ERROR] [1761746204.352118932] [controller_manager]: Could not initialize the controller named 'mecanum_drive_controller'
[ros2-9] Error loading controller, check controller_manager logs
[ERROR] [ros2-9]: process has died [pid 947577, exit code 1, cmd 'ros2 control load_controller --set-state active mecanum_drive_controller'].
The line 124 of drive_controller.cpp is not changed. Yet, according to the update notes, its a Jazzy update (#1683)
Looked in yahboom_rosmaster.gazebo.launch.py, which loads load_ros2_controllers.launch.py from yahboom_rosmaster_bringup. Calling ros2 control load_controller --set-state active mecanum_drive_controller directly didn't fail, because no /controller_manager/load_controller is active
Just running ros2 control load_controller --set-state active mecanum_drive_controller indicates: waiting for service /controller_manager/load_controller to become available..
There are different versions, the difference between the Superior and the Ultimate is the RPLIDAR (A1 vs S2L)
Tomorrow I should try rosmaster_x3_gazebo.sh, which just launches the robot.
The JSON errors were due to the running app.py. Did in ~/ugv_jetson/ a download with wget https://staff.fnwi.uva.nl/a.visser/education/VAR/2025/play_robot_started.py. Used crontab -e to do ~/ugv_jetson/ugv-env/bin/python ~/ugv_jetson/play_robot_started.py instead of app.py.
Many errors of non-build packages in ~/ugv_ws. Tried ./build_first.sh on UGV Rover #4. Seems the old build-script, the laser package is not build.
On UGV Rover #5 I only modified the crontab-script.
Also tested UGV Rover #8. Also download and executed the script source repair_nvpmodel.sh. Because #8 has no ROS, nor ugv_ws, I removed that from the ~/.bashrc. No ~/ugv_ws is a problem, because that is the directory shared with the docker.
Checking my git-configuration with git config --global --list.
After the build, I was able to do ros2 launch ros_gz_example_bringup diff_drive.launch.py. Rviz start with a missing Fixed Frame, but that is solved when you start Gazebo to Run. At that moment also the robot-description gets textures. Still, two strange things. A number of black boxes instead of icons in Gazebo, and a number of warnings (which can partly be ignored):
[robot_state_publisher-3] [WARN] [1761549811.905565875] [sdformat_urdf]: SDFormat link [lidar_link] has a , but URDF does not support this
[robot_state_publisher-3] [WARN] [1761549811.911327303] [kdl_parser]: The root link chassis has an inertia specified in the URDF, but KDL does not support a root link with an inertia. As a workaround, you can add an extra dummy link to your URDF.
[robot_state_publisher-3] [WARN] [1761549811.911608525] [kdl_parser]: Converting unknown joint type of joint 'caster_wheel' into a fixed joint
...
[robot_state_publisher-3] [INFO] [1761549811.911781632] [robot_state_publisher]: Floating joint. Not adding segment from chassis to caster.
rviz2-4] [WARN] [1761549812.748224347] [sdformat_urdf]: SDFormat link [lidar_link] has a , but URDF does not support this
...
[parameter_bridge-2] [WARN] [1761549812.864420218] [ros_gz_bridge]: Failed to create a bridge for topic [/clock] with ROS2 type [rosgraph_msgs/msg/clock] to topic [/clock] with Gazebo Transport type [gz.msgs.Clock]
[ign gazebo-1] (ign gazebo gui:35239): IBUS-WARNING **: 08:23:33.190: Failed to mkdir ~/.config/ibus/bus: Not a directory
At least ros2 run teleop_twist_keyboard teleop_twist_keyboard --ros-args --remap cmd_vel:=/diff_drive/cmd_vel, ros2 topic pub /diff_drive/cmd_vel geometry_msgs/msg/Twist "{linear: {x: 1.0}}" -1 and ros2 topic pub /diff_drive/cmd_vel geometry_msgs/msg/Twist "{linear: {x: 0.0}}" -1 worked.
Checked ~/.config/ibus/bus. Was a symbolic link to itself, created Nov 27, 2024. Removed it. Warning is gone, missing icons are still there.
Created again ugv_rover.launch.py in ros_gz_example_bringup/launch, changing only the robot-description for RVIZ (URDF based).
Created ugv_rover_in_empty_world.sdf in roject_template/ros_gz_example_gazebo/worlds. The launch worked, but failed to teleop the robot. The ugv_rover is also expelled after a short while.
Seeing at launch the following warnings:
[ign gazebo-1] Library [/opt/ros/humble/lib/libgazebo_ros_diff_drive.so] does not export any plugins. The symbol [IgnitionPluginHook] is missing, or it is not externally visible.
[ign gazebo-1] Library [/opt/ros/humble/lib/libgazebo_ros_joint_state_publisher.so] does not export any plugins. The symbol [IgnitionPluginHook] is missing, or it is not externally visible.
[ign gazebo-1] Library [/opt/ros/humble/lib/libgazebo_ros_imu_sensor.so] does not export any plugins. The symbol [IgnitionPluginHook] is missing, or it is not externally visible.
[ign gazebo-1] Library [/opt/ros/humble/lib/libgazebo_ros_camera.so] does not export any plugins. The symbol [IgnitionPluginHook] is missing, or it is not externally visible.
[ign gazebo-1] Library [/opt/ros/humble/lib/libgazebo_ros_ray_sensor.so] does not export any plugins. The symbol [IgnitionPluginHook] is missing, or it is not externally visible.
In the diff_drive.sdf model, there is one plugins, ignition-gazebo-diff-drive-system
In the world.sdf, the model is loaded with additional plugins: ignition-gazebo-joint-state-publisher-system, ignition-gazebo-pose-publisher-system, ignition-gazebo-odometry-publisher-system
In the ugv_rover.sdf model, there is a plugin for libgazebo_ros_imu_sensor.so, libgazebo_ros_camera.so, libgazebo_ros_ray_sensor.so, libgazebo_ros_diff_drive.so, libgazebo_ros_joint_state_publisher.so.
Looked into this discussion. Seems a GZ_version issue. Touched models/urg_rover/model.sdf and rebuild ugv_was with export GZ_VERSION=fortress.
Build failed on teb_local_planner, missing g2o. Did source install_additional_ros_humble_packages.sh again. Still missing, add sudo apt-get install ros-humble-libg2o -y to script, teb_local_planner can now be build.
Launched ros2 launch ros_gz_example_bringup ugv_rover.launch.py, which gave:
ign gazebo-1] [Err] [SystemLoader.cc:94] Failed to load system plugin [libgazebo_ros_diff_drive.so] : couldn't find shared library.
[ign gazebo-1] [Err] [SystemLoader.cc:94] Failed to load system plugin [libgazebo_ros_joint_state_publisher.so] : couldn't find shared library.
[ign gazebo-1] [Err] [SystemLoader.cc:94] Failed to load system plugin [libgazebo_ros_imu_sensor.so] : couldn't find shared library.
[ign gazebo-1] [Err] [SystemLoader.cc:94] Failed to load system plugin [libgazebo_ros_camera.so] : couldn't find shared library.
[ign gazebo-1] [Err] [SystemLoader.cc:94] Failed to load system plugin [libgazebo_ros_ray_sensor.so] : couldn't find shared library.
[ign gazebo-1] [Err] [SystemLoader.cc:94] Failed to load system plugin [libgazebo_ros_camera.so] : couldn't find shared library.
I didn´t do ~/ugv_ws/install/setup.bash, but still same errors.
My current IGN_GAZEBO_SYSTEM_PLUGIN_PATH is ~/project_ws/install/ros_gz_example_gazebo/lib/ros_gz_example_gazebo/, which contains libBasicSystem.so and libFullSystem.so.
Changed in ugv_rover/model.sdf the plugin filename from libgazebo_ros_diff_drive.so to ignition-gazebo-diff-drive-system. That helps: the diff_drive warning is no longer there. Yet, the diff_drive is now loaded from two places at the same time. At the moment that a /cmd/vel is given, the robot starts to fly.
Replaced the joint-state-publisher plugin. Looked up IMU sensor in Fortress documentation.
The camera doesn't need a dedicated plugin, the general gz-sim-sensors-system is enough. Node that this can only loaded once (more world than sensor-based). Note that also the IMU-system has some Preliminaries. Actually, the general ignition-gazebo-physics-system, ignition-gazebo-scene-broadcaster-system and ignition-gazebo-sensors-system are already loaded in ugv_rover_in_empty_world.sdf. In addition (not seen mentioned before, ignition-gazebo-user-commands-system and the BasicSystem and FullSystem which were examples I saw in the lib.
Also the LiDAR is now part of the general libignition-gazebo-sensors-system.so, see Fortress documentation. Commented camera and lidar-plugins out, note that this also removes the ros-remapping. All warnings on loading plugins are gone. Looked with ros2 topic list:
/clicked_point
/clock
/diff_drive/cmd_vel
/diff_drive/odometry
/diff_drive/scan
/goal_pose
/initialpose
/joint_states
/parameter_events
/robot_description
/rosout
/tf
/tf_static
No Camera topics, although I see /diff_drive/scan. ugv_rover is gone after a short while (no cmd_vel given). RVIZ indicates that the URDF is OK, only the transforms to diff_drive/odom are missing. Seems a naming issue between odom and odometry, because log indicates:
[parameter_bridge-2] [INFO] [1761558591.570123849] [ros_gz_bridge]: Creating GZ->ROS Bridge: [/model/diff_drive/odometry (gz.msgs.Odometry) -> /diff_drive/odometry (nav_msgs/msg/Odometry)] (Lazy 0)
Note that cmd_vel is still using the diff_drive namespace. Note that the camera (and ugv_imu) are part of the world/demo namespace (because sensor-systems is loaded as part of the world?)
Created new ugv_ros_gz_bridge.yaml, which also included PointCloud message (inspired by rgbd_camera_bridge.yaml
UGV_rover still disappears after a few seconds. Now I see with ros2 topic list:
/ugv_rover/cmd_vel
/ugv_rover/depth_camera/camera_info
/ugv_rover/depth_camera/image
/ugv_rover/depth_camera/points
/ugv_rover/joint_states
/ugv_rover/odometry
/ugv_rover/pt_camera/camera_info
/ugv_rover/pt_camera/image
/ugv_rover/scan
/ugv_rover/tf
/ugv_rover/tf_static
Yet, the robot-description in RVI| seems to be still based on diff_drive.
Changed TF prefix to ugv_rover, now no transform from [ugv_rover/base_footprint] to [diff_drive/odom]. Changed the Fixed Frame to [ugv_rover/odometry], still no transform.
Note that there is odometry is used for the observation, and odom for the coordinate frame. Modified both ugv_rover/model.sdf (diff-drive-system with takes cmd_vel and publishes odometry) and world/ugv_rover_in_empty_world.sdf (ignition-gazebo-odometry-publisher-system). Odometry is also in gv_ros_gz_bridge.yaml.
Checked the two Gazebo applications (Basic and Full). They only print some debug info (not seen in log). Anyway, commented them out.
Will change the tf message from ugv_rover name space to just /tf.Logout to get rid of old-messages, and try again.
After a reboot, there is still /diff_drive/odometry. Did ros2 topic info /diff_drive/odometry, ther is no publisher, only a subscriber (RVIZ). Try again, with modified RVIZ. At least, there is no /diff_drive/odometry. Looks like the odometry should be defined between ugv_rover/odom and ugv_rover/base_link (maybe also the ugv_rover namespace should be added too, to have a warm start before Gazebo-play).
OK, now RVIZ starts OK, only thing missing is a transform between base_footprint and base_link. Actually, base_footprint is parent of base_link (and imu_joint), etc, etc. Is this the difference between URDF and SDF?
Changed loading the SDF, instead of the URDF (both in Gazebo and RVIZ).
RVIZ gives an error loading the SDF (link with sensor). Worse, also the changing in both rviz, world and model, still fails (only a transform to ugv_rover/base_footprint, transform to base_link fails). Also loading resource 'model://ugv_description/meshes/ugv_rover/*.stl' fails. Tried to set GAZEBO_RESOURCE_PATH, IGN_GAZEBO_RESOURCE_PATH, GAZEBO_MODEL_PATH and IGN_GAZEBO_MODEL_PATH, the STL are actually there. No avail.
I didn´t install Yahboom yet, so back to Build the workspace. I still had a ros2_ws with some dreamvu packages, so moved that one to old_ros2_ws. Did a git clone https://github.com/automaticaddison/yahboom_rosmaster.git in ~/ros2_ws/src.
The rosdep install -i --from-path src --rosdistro $ROS_DISTRO -y failed on:
yahboom_rosmaster_gazebo: Cannot locate rosdep definition for [gz_ros2_control]
mecanum_drive_controller: Cannot locate rosdep definition for [hardware_interface_testing]
According to the ROS Index, gz_ros2_control exists. Doing it manually also installs ros-humble-hardware-interface. rosdep still fails. Build partly finishes. Also needed sudo apt install ros-humble-urdf-tutorial, sudo apt install ros-humble-generate-parameter-library, sudo apt install ros-humble-pal-statistics-msgs, sudo apt install ros-humble-ros2-control, sudo apt install ros-humble-ros2-controllers.
At the end only mecanum_drive_controller fails, but a COLCON_IGNORE in /ros2_ws/src/yahboom_rosmaster/mecanum_drive_controller. More or less at the stage where I was on October 21, 2025.
Tried ros2 launch gz_ros2_control_demos diff_drive_example.launch.py, just sudo apt install ros-humble-gz-ros2-control-demos. (enough for tomorrow?). Also here the missing icons. Looked at , was able to ros2 run gz_ros2_control_demos example_diff_drive. The ros2 run teleop_twist_keyboard teleop_twist_keyboard --ros-args -p stamped:=true didn´t work. Seems I am not the only one with :this problem.
At least ros2 run teleop_twist_keyboard teleop_twist_keyboard --ros-args --remap cmd_vel:=/diff_drive_controller/cmd_vel -p stamped:=true starts, but no response. Also tried ros2 run teleop_twist_keyboard teleop_twist_keyboard --ros-args --remap cmd_vel:=/diff_drive_controller/cmd_vel_unstamped -p stamped:=false.
Finally, the correct command ros2 run teleop_twist_keyboard teleop_twist_keyboard --ros-args --remap cmd_vel:=/diff_drive_base_controller/cmd_vel_unstamped
Next to try is source install/yahboom_rosmaster_bringup/share/yahboom_rosmaster_bringup/scripts/rosmaster_x3_gazebo.sh.
RVIZ starts in error, but switching the Fixed Frame to base_footprint solves that. Don´t see the topic odometry, so that corresponds. Problem is the missing mecanum_drive_controller:
[ign gazebo-3] [INFO] [1761583832.336041810] [controller_manager]: Loading controller 'mecanum_drive_controller'
[ign gazebo-3] Exception thrown during controller's init with message: Invalid value set during initialization for parameter 'front_left_wheel_command_joint_name': Parameter 'front_left_wheel_command_joint_name' cannot be empty.
Still, the LaserScan works, no idea why the images are grey, it should see the wooden floor:
Also like the Top view of source install/yahboom_rosmaster_bringup/share/yahboom_rosmaster_bringup/scripts/rosmaster_x3_navigation.sh: .
For the camera, I see errors like:
[image_transport] Topics '/cam_1/color/image_raw' and '/cam_1/camera_info' do not appear to be synchronized.
Created a pick_and_place script. The rosmaster starts a bit high, but is looking upwards. Finally an image:
Next example is on how to drive the mecanum-robot in a square.
ros2 launch nav2_bringup tb3_simulation_launch.py headless:=False required sudo apt install ros-humble-gazebo-ros. After that, I got a RVIZ window, with the Fixed Frame map doesn´t exist. COuld be that Gazebo is loadin a world. See in the huge launch-log only one concerning Warning:
[component_container_isolated-6] [INFO] [1761586523.805132380] [local_costmap.local_costmap]: Timed out waiting for transform from base_link to odom to become available, tf error: Invalid frame ID "odom" passed to canTransform argument target_frame - frame does not exist
At the end of the seminar I looked at basic_image_subscriber.py form opencv-in-ros, which fails on numpy:
<
IIf you are a user of the module, the easiest solution will be to
downgrade to 'numpy<2' or try to upgrade the affected module.
We expect that some modules will need time to support NumPy 2
Essential concept, what became clear to me last week was that both Gazebo and ROS2 have topics, with their own transports. As Michael Carroll said, the Gazebo topic-transport is much older, and much better than the ROS1 topic-transport:
There are two ways to integrate ROS and Gazebo. Direct embedding is more efficient, but less flexible. Using a bridge makes it version-independent (even still works with ROS1):
Configuring a ros_gz_bridge can be done from the commandline or with a YAML. The last option is new (and better), but I haven't seen any example of that (yet):
What is positive from the Hooks file (which make ROS2 package:// available to Gazebo as model:// is that models and worlds are made available by a single environment variable: GZ_SIM_RESOURCE_PATH:
At the end she is showing the DiffDrive.sdf with two extra boxes. Are added from the commandline or is the other rr* world in the template:
Working on WS9 again, fresh login.
Did source ~/project_ws/install/setup.bash, ros2 launch ros_gz_example_bringup rrbot_setup.launch.py. Gazebo is started in the background, the robot is a 2-joint robot-arm, controlled by the joint-state-publisher:
Don't see the bridge-commands in launch.py file. Actually, no Gazebo is called, this is just the robot_description in Rviz example
This configuration-file is actually called for the bridge-node from diff_drive.launch.py.
Saw this post, it seems that images should not be send with the ros_gz_bridge, but with ros_gz_image. Should work like ros2 run ros_gz_image image_bridge /topic1 /topic2 --ros-args qos:=sensor_data.
Looked at ROS + Gazebo Sim demos, there is an example both with the regular bridge and with the image bridge.
The ros_gz_sim_demos also works with a hook, although to ./share and not to ./share/@PROJECT_NAME@/models!
The launch-file starts a world from gz_sim: camera_sensor.sdf. At line 154 the camera-model is loaded.
Made a diff_drive_with_camera model. (In install, instead of src, for the moment). Note that the model is loaded both in the launch and world. Note that the world uses not only the bridge, but also the embedded ignition::gazebo::systems::OdometryPublisher (see Class Reference. There are more System Classes, but only CameraVideoRecorder plugin.
Trying my ros2 launch ros_gz_example_bringup diff_drive_with_camera.launch.py
At least the cone is right world is loades, with a diff_drive_with_camera model and the additional cone. Yet, in Rviz the robot_model is lacking some textures, and the ros-topics are still /diff_drive related (and not /diff_drive_with_camera.
So, with ign list -l, I see:
/camera
/camera_info
/scan
/model/diff_drive/cmd_vel
/model/diff_drive_with_camera/odometry
/model/diff_drive_with_camera/odometry_with_covariance
/model/diff_drive_with_camera/pose
/model/diff_drive_with_camera/pose_static
/model/diff_drive_with_camera/tf
Forgot to add camera bridge configuration to my extended_ros_gz_example_bridge.yaml. Note that here topic_name is used, which could mean that the topic has the same name in gz_ and ros_. In the model indeed /camera was specified as topic.
Try ros2 launch ros_gz_example_bringup diff_drive_with_camera.launch.py again. When I press Play in Gazebo, I get an image in RVIZ. Yet, the camera is placed behind the right wheel. Strange, from the Gazebo visual, the Lidar and Camera are at the same spot (at top of the robot).
When I look at the TFs, the camera_link and lidar_link appear twice, but all overlapping with the chassis (which also appears twice).
Positive thing is that I now have both a camera-image and can drive around with ros2 run teleop_twist_keyboard teleop_twist_keyboard --ros-args --remap cmd_vel:=/diff_drive_with_camera/cmd_vel.
I also see the Cone, yet the LaserScan is not visible (although the topic is). Yet, get many message that message filter /diff_drive/lidar_link complains the the queue is full. Thatis TF frame, and not with new model name.
Started the ros2 run r2s_gw r2s_gw_dashboard again.
Note that in ros_gz_example_gazebo/worlds/diff_drive_with_camera.sdf for the OdometryPublisher two parameters are specified. The odom_frame should be {name_of_model}/odom, and is diff_drive_with_camera/odom. Yet, the robot_base_frame should be {name_of_model}/base_footprint, and is set to just diff_drive_with_camera, while I expect it to be diff_drive_with_camera/chassis (corrected that). Note that the rviz still starts with /diff_drive/odom (corrected that).
Tried again ros2 launch ros_gz_example_bringup diff_drive_with_camera.launch.py. Again dropping TF-messages, this time diff_drive_with_camera/lidar_link
Also the ros2 run r2s_gw r2s_gw_dashboard indicates that the /tf messags are send with high frequency (1000 Hz). Yet, coupling is not good according to RVIZ:
Trying again, now with ugv_rover model.
Copied in ~/project/src/ros_gz_project_template/ ugv_rover.launch.py from diff_drive.launch.py. Changed only the pkg_project_description. Result is that RVIZ displays the UGV Rover (without meshes), while Gazebo still loaded the diff_drive from its world.
Tried export IGN_GAZEBO_RESOURCE_PATH=$IGN_GAZEBO_RESOURCE_PATH:/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/, still no meshes.
Yet, I am also missing a number of TFs:
The original ugv_bringup/launch/bringup_lidar.launch.py had a ugv_base_node with the option to pub_odom_tf
Now included in launch ugv_rover_in_empty_world.sdf. ugv_rover_in_empty_world.sdf calls uri[package://ugv_gazebo/models/ugv_rover], which only works when the hook is executed. With export IGN_GAZEBO_RESOURCE_PATH=$IGN_GAZEBO_RESOURCE_PATH:/home/arnoud/ugv_ws/install/ugv_gazebo/share/ the model can be loaded. Yet, only visible as entity, cannot move to it. There are also several warnings like:
Unable to find file with URI [model://ugv_description/meshes/ugv_rover/base_link.stl]
Also added export IGN_GAZEBO_RESOURCE_PATH=$IGN_GAZEBO_RESOURCE_PATH:/home/arnoud/ugv_ws/install/ugv_description/share/
Now I have a UGV Rover in Gazebo, just above the ground:
No description is visible in RVIZ (gives Errors loading geometries). Loadin the description as URDF instead of SDF worked better. See also several error-messages like:
[ign gazebo-1] Warning [parser.cc:1192] Can not find the XML attribute 'version' in sdf XML tag for model: ugv_rover. Please specify the SDF protocol supported in the model configuration file. The first sdf tag in the config file will be used
[ign gazebo-1] Library [/opt/ros/humble/lib/libgazebo_ros_diff_drive.so] does not export any plugins. The symbol [IgnitionPluginHook] is missing, or it is not externally visible.
[rviz2-4] [WARN] [1761318241.347038722] [sdformat_urdf]: SDFormat link [base_imu_link] has a , but URDF does not support this
[rviz2-4] [ERROR] [1761318241.356004859] [rviz2]: Error retrieving file [model://ugv_description/meshes/ugv_rover/3d_camera_link.stl]: Protocol "model" not supported or disabled in libcurl
[parameter_bridge-2] [WARN] [1761318241.435733871] [ros_gz_bridge]: Failed to create a bridge for topic [/clock] with ROS2 type [rosgraph_msgs/msg/clock] to topic [/clock] with Gazebo Transport type [gz.msgs.Clock]
Changed the launch-file, so RVIZ gets the URDF and Gazebo the SDF. Still, some missing TF (Odometry!), the SDF has a base_footprint! Also, the robot is laucnched when the Cone hits the floor. Maybe I should spawn not so high, or increase the weight.
Changed the SDF-version from 1.5 to 1.8, still complains on Can not find the XML attribute 'version' in sdf XML tag for model: ugv_rover. Version is clearly there!
Continue Monday with Odometry, followed by the ros-bridge.yaml
October 23, 2025
Lets get an overview of what worked and what not in simulation:
On October 22, 2025 Working on WS9, I worked with dolly. Got /cmd_vel as ign-topic, should also check ros-topic and otherwise create a bridge, although ros2 launch dolly_ignition dolly.launch.py starts three bridges in its launch-file.
On October 21, 2025 Working on WS9, I tried several of Addison's tutorials. I was able to have a complete UGV Rover simulated in Gazebo, including meshes and TFs. Only thing missing was /cmd_vel. Was based on gz_ros2_control_demos, which uses the controller_manager service. Also tried ign gazebo -v 4 -r visualize_lidar.sdf, together with ros2 run ros_gz_bridge parameter_bridge, which allowed me to drive the vehicle with ros2 topic pub
On October 14, 2025 I tried ReRun again. Simulation part worked a bit, also here missing TFs and Meshes, even for the Turtle robot.
On September 9, 2025 I commented that the polulate.py script uses spawn_entity (which no longer works, should be service based).
On September 5, 2025 Working on WS9, I was further experimenting with ros2 launch ros_gz_sim_demos robot_description_publisher.launch.py, providing it with the robot_description topic. Partly worked, although the meshes were missing. Solved it for the base, but four wheel-joints were still missing.
On September 4, 2025 Working on WS9, I was experimenting with bridge and non-bridge versions of the GPU_lidar demo. The LiDAR is still not mounted on a robot. Ends with ros2 launch ros_gz_sim_demos robot_description_publisher.launch.py, which seems to wait on the robot_description topic.
On September 3, 2025 Working on WS9, I tried several basic Gazebo tutorials, which gave strange enough a lot of errors. The one that worked was ros_gz_sim_demos battery.launch.py, which I could control with ros2 topic pub. Not clear if I also was able to drive ros2 launch ros_gz_sim_demos diff_drive.launch.py, but I received odometry updates. ros2 launch ros_gz_sim_demos camera.launch.py gave me images, yet not clear if the camera was mounted on a vehicle.
On September 2, 2025 Working on WS9, I tried to use Francisco's simulated Tiago robot. The Chapter3 code uses a controller_manager, which I didn't get working. Chapter2 depends on MoveIt. Gave up, because after a lot of how work still no Gazebo showed up. Instead started with a empty world, and was able to load the ugv_rover model.sdf with ros2 run ros_gz_sim create -world empty -file command. Yet, without mesh.
On August 30, 2025 I suggested to use Francisco's simulated Tiago robot.
On July 22, 2025 I was experimenting with RESOURCE_PATHs. At the end I did ros2 launch ros_gz_sim gz_sim.launch.py gz_args:=empty.sdf which worked (but couldn't Load client configurations).
On July 21, 2025 I started experimenting with ReRun, which also uses a simulator. ros2 launch ugv_gazebo bringup.launch.py failed on /spawn_entity.
Working on WS9, I could do ros2 launch ugv_description display.launch.py use_rviz:=true and move the pan-tilt both in RVIZ and the real UGV.
On June 16, 2025 Working on WS9, I could do ros2 launch ugv_description display.launch.py use_rviz:=true and move the pan-tilt both in RVIZ and the real UGV.
On June 2, 2025 Continued to work with UGV Rover, after focusing on the AML course.
On February 6, 2025 The first UGV Rover arrives.
On November 9, 2024 Working on nb-dual Ubuntu 20.04. I had a dependency on gazebo for the realsense camera.
On October 30, 2024 Working on WS9. I compared cmpr_apb with Addison's ArUco Marker Pose.
On October 30, 2024 I Addison's Load Robot model in Gazebo. Didn't respond to /cmd_vel.
On October 29, 2024 Working on WS9. I installed ros-humble-ros-gz.
On October 29, 2024ros2 launch cpmr_apb gazebo.launch.py gave GazeboRosFactory error.
On October 29, 2024 Started with ros-humble-gz-demos. ros2 launch ros_gz_sim gz_sim.launch.py gz_args:=~/var_ws/install/cpmr_apb/share/cpmr_apb/world_demo.sdf gave an empty world.
On October 29, 2024 Succes: ign service -s /world/empty/create --reqtype ignition.msgs.EntityFactory --reptype ignition.msgs.Boolean --timeout 1000 --req 'sdf_filename: "~/var_ws/install/cpmr_apb/share/cpmr_apb/blockrobot.urdf", name: "blockrobot"' worked! Yet, no movement.
On October 29, 2024 Continued with the bridges. Was able to drive the diff_drive around, both with ros2 topic pub and ros2 run teleop_twist_keyboard.
On October 29, 2024 The day ended that I tried to load cpmr_apb's blockrobot, which succeeded only partly (no wheels, no cmd_vel.
On October 25, 2024 Working on WS9 I could start ros2 launch rae_gazebo gazebo.launch.py, and drive with ros2 topic pub. Started to do the same for cpmr_apb, but no spawn_entity, because of missing libgazebo_ros_factory.so.
On October 24, 2024 I moved from WSL to WS9. First had to build rae-ros. Got no further than rosdep.
On October 11, 2024 Seems I was working on WSL. I could start ros2 launch rae_gazebo gazebo.launch.py after install mamba install ros-humble-robot-localization. I mention a missing diff_controller. Robostack problems.
On October 10, 2024 I could start ros2 launch cpmr_apb gazebo.launch.py, but NOT drive with ros2 topic pub. Missing several topics (no /scan or /odom).
On October 9, 2024 I could start ros2 launch cpmr_apb gazebo.launch.py, but did no further tests.
Fresh terminal on WS9. ros2 launch ros_gz_example_bringup diff_drive.launch.py failed on missing package 'ros_gz_example_bringup'.
This package is part of ros_gz_project_template. On October 29, 2024 I installed it with git clone https://github.com/gazebosim/ros_gz_project_template.git -b fortress. Looked in ROS Index, no binary install. Didn't see the ws on WS9. Instead, followed the Guide, and created ~/project_ws, followed by git clone https://github.com/gazebosim/ros_gz_project_template.git -b fortress, export GZ_VERSION=fortress. All rosdep where already installed. Continued with the instructions of the github: colcon build --cmake-args -DBUILD_TESTING=ON.
Started ros2 launch ros_gz_example_bringup diff_drive.launch.py. Both Gazebo and RViz popped up. A Global Status error on the Fixed Frame /diff_drive/odom, and an error on the RobotModel (missing the transform from /diff_drive/odom. The ros2 launch also gave some warnings which seems relevant:
[robot_state_publisher-3] [WARN] [1761223860.220062313] [sdformat_urdf]: SDFormat link [lidar_link] has a , but URDF does not support this
[robot_state_publisher-3] [WARN] [1761223860.223756378] [kdl_parser]: The root link chassis has an inertia specified in the URDF, but KDL does not support a root link with an inertia. As a workaround, you can add an extra dummy link to your URDF.
[robot_state_publisher-3] [WARN] [1761223860.223785311] [kdl_parser]: Converting unknown joint type of joint 'caster_wheel' into a fixed joint
[robot_state_publisher-3] [INFO] [1761223860.223867058] [robot_state_publisher]: Floating joint. Not adding segment from chassis to caster.
The clock is bridged twice, but that bridge seems to fail:
[parameter_bridge-2] [WARN] [1761223861.195600309] [ros_gz_bridge]: Failed to create a bridge for topic [/clock] with ROS2 type [rosgraph_msgs/msg/clock] to topic [/clock] with Gazebo Transport type [gz.msgs.Clock]
Checking with ros2 topic list gives:
/clicked_point
/clock
/diff_drive/cmd_vel
/diff_drive/odometry
/diff_drive/scan
/dolly/laser_scan
/goal_pose
/initialpose
/joint_states
/parameter_events
/robot_description
/rosout
/tf
/tf_static
Dolly is still there, so could better logoff and try from scratch.
But at least ros2 topic pub /diff_drive/cmd_vel geometry_msgs/msg/Twist "{linear: {x: 1.0}}" -1 and ros2 topic pub /diff_drive/cmd_vel geometry_msgs/msg/Twist "{linear: {x: 0.0}}" -1 worked (after hitting the gazebo play button).
Looked in ~/.ignition/fuel/fuel.ignitionrobotics.org/openrobotics/models/, I have a 'construction cone' model.
The world is called demo, so I tried ign service -s /world/demo/create --reqtype ignition.msgs.EntityFactory --reptype ignition.msgs.Boolean --timeout 1000 --req 'sdf_filename: "~/var_ws/install/cpmr_apb/share/cpmr_apb/blockrobot.urdf", name: "blockrobot"'. That gave data: true (but no addition to the Entity Tree.
The command ign service -s /world/demo/create -reqtype ignition.msgs.EntityFactory --reptype ignition.msgs.Boolean --timeout 1000 --req 'sdf_filename: "~/.ignition/fuel/fuel.ignitionrobotics.org/openrobotics/models/construction\ cone/3/model.sdf", name: "Cone"' gave --req: At Most 1 required but received 2.
Seems there is a space wrong. Filled the path again in the one that works. ign service -s /world/demo/create --reqtype ignition.msgs.EntityFactory --reptype ignition.msgs.Boolean --timeout 1000 --req 'sdf_filename: "~/.ignition/fuel/fuel.ignitionrobotics.org/openrobotics/models/construction cone/3/model.sdf", name: "cone"' now also gives data: true (but no cone).
Checked ign model --list, gives:
Available models:
- ground_plane
- diff_drive
Did ign sdf --check "~/.ignition/fuel/fuel.ignitionrobotics.org/openrobotics/models/construction cone/3/model.sdf", which gives Valid.
Checked the services with ign service -l, which gave a long list, including:
/world/demo/create
/world/demo/entity/system/add
/world/demo/remove
Note that ign sdf --check "/home/arnoud/project_ws/install/ros_gz_example_description/share/ros_gz_example_description/models/diff_drive/model.sdf" also gives a valid, so the check is not so critical as the robot_state_publisher.
Used ros2 run teleop_twist_keyboard teleop_twist_keyboard --ros-args --remap cmd_vel:=/diff_drive/cmd_vel to turn the robot around.
ros2 run greenwave_monitor ncurses_dashboard only gives the topics. According to the monitor, /diff_drive/cmd_vel is STALE, while /diff_drive/odometry is published with 50 Hz. The /diff_drive/scan is published with 10 Hz.
Also started ros2 run r2s_gw r2s_gw_dashboard. If I look at interfaces, I see several /ros_gz_bridge services, such as /ros_gz_bridge/list_parameters and /ros_gz_bridge/describe_parameters
Did a call ros2 service type /ros_gz_bridge/list_parameters, which gives rcl_interfaces/srv/ListParameters. The next call ros2 service call /ros_gz_bridge/list_parameters rcl_interfaces/srv/ListParameters gives a long lists, with many qos_overrides.*.
Calling ros2 service call /ros_gz_bridge/describe_parameters rcl_interfaces/srv/DescribeParameters expand_gz_topic_names gives expected to be a dictionary but is a str
Next that worked was ros_gz_sim_demos battery.launch.py from September 3, 2025.
After that I had a working visualize_lidar.sdf from October 21, 2025.
Storm is coming, logout. Continue tomorrow.
Reading the rest of ROS Gz Template Guide. Important note is There is a difference in how ROS and Gazebo resolves URIs, that the ROS side can handle package:// URIs, but by default SDFormat only supports model://. Now libsdformat can convert package:// to model:// URIs. So existing simulation assets can be loaded by “installing” the models directory and exporting the model paths to your environment.. In the project-template they give an example of a hook for COLCON, a DSV-file.
October 22, 2025
Connected to UGV Rover #6 (untouched), entered the container.
Looked at the environment. The GAZEBO_RESOURCE_PATH, IGN_GAZEBO_RESOURCE_PATH, GAZEBO_MODEL_PATH and IGN_GAZEBO_MODEL_PATH are set to /opt/ros/humble/share.
Trying to launch from the container, but ros2 launch ugv_gazebo bringup.launch.py gives package gazebo_ros not found.
Without the install, /opt/ros/humble/share/gazebo_ros/worlds/ doesn't exist (yet) in the container.
Tried sudo apt install ros-humble-gazebo-ros, which failed. Tried sudo apt update, which also fails on signature.
Executed the first part of the install_additional_ros_humble_packages.sh, but even after install ros2-apt.source.deb the Chinese miror keep having signature problems. Commented out the mirror in /etc/apt/sources.list.d/ros2.list.
Still sudo apt install ros-humble-gazebo-ros doesn't work, instead did sudo apt install ros-humble-ros-gz
The launch ros2 launch ugv_gazebo bringup.launch.py doesn't work without gazebo-ros.
On amd64 systems sudo apt install ros-humble-gazebo-ros still works, so if we need it on the UGV Rover we should build it from source.
Back to WS9.
On WS9, gazebo-ros seems to be installed. Note that this Package is Deprecated since January 2025.
Interesting enough, /opt/ros/humble/share/gazebo_ros/worlds/ exists and in /opt/ros/humble/lib/gazebo_ros/gazebo_ros_paths.py the path are set, while /opt/ros/humble/lib/gazebo_ros/spawn_entity.py gives an example how a model can be loaded from file. Can be launched with ros2 launch gazebo_ros spawn_entity_demo.launch.py
Checked the installed packages with apt list --installed | grep gazebo, ros-humble-gazebo-ros v3.9.0 is installed.
Looked at Foxy tutorial, which uses ros2 run gazebo_ros spawn_entity.py -topic robot_description -entity robot_name
Running ros2 launch gazebo_ros gazebo.launch.py fails on Assertion `px != 0' Instead did ign gazebo -v 4 -r empty.sdf. Got an empty world.
Started source ~/ugv_ws/install/setup.bash, followed by ros2 launch urdf_tutorial display.launch.py model:=/home/arnoud/ugv_ws/install/ugv_description/share/ugv_description/urdf/ugv_rover.urdf
Still, ros2 run gazebo_ros spawn_entity.py -topic robot_description -entity ugv_rover fails, because /spawn_entity service was not started. Was Gazebo started with GazeboRosFactory?.
Modified the environment with export IGN_GAZEBO_MODEL_PATH=$IGN_GAZEBO_MODEL_PATH:/opt/ros/humble/share/gazebo_ros/worlds/:/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/ and export IGN_GAZEBO_RESOURCE_PATH=$IGN_GAZEBO_RESOURCE_PATH:/opt/ros/humble/share/gazebo_ros/worlds/:/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/.
Trying ign gazebo -v 4 -r ugv_world.world gave unable to find download file.
Trying instead ign gazebo -v 4 -r ~/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world, which gave:
[Msg] Ignition Gazebo GUI v6.16.0
[Dbg] [gz.cc:161] Subscribing to [/gazebo/starting_world].
[Dbg] [gz.cc:163] Waiting for a world to be set from the GUI...
[Dbg] [Gui.cc:253] Waiting for subscribers to [/gazebo/starting_world]...
[Msg] Received world [/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world] from the GUI.
[Dbg] [gz.cc:167] Unsubscribing from [/gazebo/starting_world].
[Msg] Ignition Gazebo Server v6.16.0
[Msg] Loading SDF world file[/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world].
[Dbg] [Application.cc:92] Initializing application.
[GUI] [Dbg] [Application.cc:555] Create main window
[Err] [Server.cc:139] Error Code 13: [/sdf/world[@name="default"]/include[0]/uri:/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world:L6]: Msg: Unable to find uri[model://ground_plane]
[Err] [Server.cc:139] Error Code 13: [/sdf/world[@name="default"]/include[1]/uri:/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world:L10]: Msg: Unable to find uri[model://sun]
[Err] [Server.cc:139] Error Code 13: [/sdf/world[@name="default"]/model[@name="world"]/include[0]/uri:/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world:L49]: Msg: Unable to find uri[model://world]
[Err] [Server.cc:139] Error Code 3: Msg: The supplied model name [world] is reserved.
[Err] [Server.cc:139] Error Code 2: Msg: Model with non-unique name [world] detected in world with name [default].
[Err] [Server.cc:139] Error Code 2: Msg: Model with non-unique name [world] detected in world with name [default].
[Err] [Server.cc:139] Error Code 27: Msg: PoseRelativeToGraph error, too many incoming edges at a vertex with name [world].
[Err] [Server.cc:139] Error Code 9: Msg: Failed to load a world.
[Dbg] [gz.cc:410] Shutting down ign-gazebo-server
Escalating to SIGKILL on [Ignition Gazebo GUI]
Try again, with GAZEBO_MODEL_PATH and GAZEBO_RESOURCE_PATH. Still not works.
Could also look how to start the Factory with ign.
Found this post, which suggested to use file://robot.sdf, with the additional comment The model directory must be renamed to the model name specified on the model.sdf file, and must be in the same directory as the world file using it..
For instance, ign gui -l showed that I have no plugins in ~/.ignition/gui/plugins, but several in /usr/lib/x86_64-linux-gnu/ign-gui-6/plugins, including libTeleop.so. See no Factory plugins.
The command ign gui --versions gives one version: 6.8.0.
The command ign gui -s ImageDisplay gave an empty display.
Started ign gazebo segmentation_camera.sdf, which has both an /panoptic/ and /semantic camera.
The file /usr/share/ignition/ignition-gazebo6/worlds/segmentation_camera.sdf would be also a great world for the UGV Rover. The camera is the black box floating in the air at the back. Another nice one is ign gazebo -v 3 sensors_demo.sdf. ign gui -s ImageDisplay crashes, probably because there is a ign topic /camera_info, but the raw image seems to be in /camera topic.
Did ign model --list, which gave the models available in the current running world (sensors_demo.sdf calls its world lidar_sensor). The available models:
- ground_plane
- box
- cameras_alone
- camera_with_lidar
- rgbd_camera
- thermal_camera
- Construction Cone
The command ign model --versions gives 6.16.0. ign model -m cameras_alone shows the distortion of the stereographic camera. The pose and inertia of the cone can be requested with ign model -m 'Construction Cone'
The command ign gazebo --help displays interesting information, including several Environment Variables, including IGN_GAZEBO_SERVER_CONFIG_PATH. Gazebo Sim has version 6.16.0
Running ign gazebo -v 3 -r gives a Dashboard to load the worlds in /usr/share/ignition/ignition-gazebo6/worlds/. Loading ugv_world.sdf crahses on uri[model://ground_plane].
The repos. The latest version of Dolly, a sheeplike following robot, is galactic, but that works.
Several additional packages are installedi with the rosdep command.
rosdep gave the following warnings:
ros_gz_bridge: Cannot locate rosdep definition for [gz_transport_vendor]
ros_gz_sim_demos: Cannot locate rosdep definition for [gz_sim_vendor]
ros_gz_image: Cannot locate rosdep definition for [gz_transport_vendor]
ros_gz_sim: Cannot locate rosdep definition for [gz_transport_vendor]
dolly_tests: No definition of [ignition-gazebo5] for OS version [jammy]
New installed: ros-humble-gazebo-ros-pkgs, libcli11-dev, ros-humble-simulation-interfaces.
Changed in simslides/CMakeLists.txt the cmake_minimum_required(VERSION 3.5.1 FATAL_ERROR) to VERSION 3.10.2, yet the actual fail was on /usr/lib/x86_64-linux-gnu/cmake/jsoncpp/jsoncppConfig.cmake, which still used cmake_policy(VERSION 3.0)
Next failure was in ros_gz_bridge, which was not needed to be build. There was a dependence on ros-humble-gz-transport-vendor, which was not available yet. Started with cloning the code.
ros-humble-gz-transport-vendor was on ament-cmake-vendor-packages, so also cloned git clone -b humble https://github.com/ament/ament_cmake.git
Added COLCON_IGNORE to several ament_cmake packages which were already installed.
Many of the packages in ros_ign doesn't have to be build from source. Added COLCON_IGNORE in ros_gz
gz_transport_vendor still had depenendencies on gz_*_vendor. gz_math_vendor couldn't be build, because of a pybind error. With touch gz_transport_vendor/COLCON_IGNORE all 13 packages are now build.
Could start the /world/ign_ros2_ci/scene/, with the dolly robot and a human:
More important, I see the ign topic /dolly/cmd_vel (and /dolly/laser_scan). No camera.
According to Dolly github, I also could start dolly in an empty.world, city.world, and a station.
Yet, ros2 topic pub --once /dolly/cmd_vel geometry_msgs/msg/Twist "{linear: {x: 0.2, y: 0.0, z: 0.0}, angular: {x: 0.0, y: 0.0, z: 0.0}}" didn't start the robot, although gazebo indicates: [parameter_bridge-4] [INFO] [1761142172.170746193] [ros_gz_bridge]: Passing message from ROS geometry_msgs/msg/Twist to Gazebo gz.msgs.Twist (showing msg only once per type)
The laser-scan indicates that the buffer is full. Modified some of the QoS Policies, to no avail.
Tried ros2 launch dolly_gazebo dolly.launch.py world:=dolly_city.world, which gave the error: Error [parser.cc:749] Could not find model.config or manifest.xml in [/usr/share//gazebo]. The gzclient also gave the Assertion `px != 0' error again.
I have the ignition version, so tried ros2 launch dolly_ignition dolly.launch.py. Loading took a while, with updates like [ros_gz_sim]: Requesting list of world names.
Received a number of warnings, to use https://fuel.gazebosim.org/1.0/OpenRobotics/models/ instead of https://fuel.ignitionrobotics.org/1.0/OpenRobotics/models/.
Positive feedback: [ros_gz_sim]: Requested creation of entity. followed by [ros_gz_sim]: OK creation of entity.
After that I receved some errors on not resolving the female_casualsuit*.png.
Yet, the station looks nice, and the launch also started RVIZ. There is an error that the Fixed Frame dolly/chassis/sensor_ray doesn't exist. No TFs at all.
Tried ros2 launch dolly_tests follow_ignition_TEST.launch.py, but doesn't does not contain the required function 'generate_launch_description()'
Command ros2 run dolly_follow dolly_follow starts, but no output.
Added some output, but ros2 topic echo /dolly/laser_scan also gives no response.
Looked into station.sdf. Important are the plugins, including:
filename="libignition-gazebo-user-commands-system.so"
name="ignition::gazebo::systems::UserCommands">
The scene includes two models: 5 2 0.23 0 0 3.14 model://casual_female
0 0 -5 0 0 0 https://fuel.ignitionrobotics.org/1.0/OpenRobotics/models/Urban Station
The casual_female can be found at ~/.ignition/fuel/fuel.ignitionrobotics.org/openrobotics/models/. Looked into casual female/4/meshes/casual_female.dae, and indeed I recognize material like: ../materials/textures/ponytail01_diffuse.png. Those materials are there now.
Indeed, in the launch-file the dolly_ignition/model.sdf is added.
The dolly_follow node is called with remappings, from cmd_vel to /dolly/cmd_vel.
Three ign-msgs are bridged to ros with the bridge-node.
October 21, 2025
Also experimented with the rich TUI. There are actually three tabs (interfaces, nodes, topics). Quite informative, maybe good to introduce already at the first seminar:
Yet, in that case I could better stay with the lightweight dashboard, because pip install -I textual gave many version conflicts:
r2s-gw 0.1.0 requires lark-parser<0.13.0,>=0.12.0, which is not installed.
r2s-gw 0.1.0 requires distro<2.0.0,>=1.9.0, but you have distro 1.7.0 which is incompatible.
r2s-gw 0.1.0 requires numpy<3.0.0,>=2.0.1, but you have numpy 1.26.4 which is incompatible.
r2s-gw 0.1.0 requires psutil<7.0.0,>=6.0.0, but you have psutil 5.9.8 which is incompatible.
r2s-gw 0.1.0 requires rich<14.0.0,>=13.0.0, but you have rich 14.2.0 which is incompatible.
r2s-gw 0.1.0 requires textual<6.0.0,>=5.3.0, but you have textual 6.3.0 which is incompatible.
Also tried the manual launch ros2 launch greenwave_monitor hz.launch.py topics:='["/rosout"]', which gave in updates in the terminal:
[greenwave_monitor-1] [INFO] [1761037365.934614321] [greenwave_monitor]: ====================================================
[greenwave_monitor-1] [INFO] [1761037365.934851124] [greenwave_monitor]: Frame rate for topic /rosout: 4.50 hz
[greenwave_monitor-1] [INFO] [1761037365.934912245] [greenwave_monitor]: Latency for topic /rosout: nan ms
[greenwave_monitor-1] [INFO] [1761037365.934950358] [greenwave_monitor]: ====================================================
Continue with the first seminar, I got stuck at September 10, 2025, still doesn't work.
Did source ~/var_ws/install/setup.bash, followed by source ~/var_ws/install/setup.bash, which fails on:
[gzclient-2] gzclient: /usr/include/boost/smart_ptr/shared_ptr.hpp:728: typename boost::detail::sp_member_access::type boost::shared_ptr::operator->() const [with T = gazebo::rendering::Camera; typename boost::detail::sp_member_access::type = gazebo::rendering::Camera*]: Assertion `px != 0' failed.
[ERROR] [gzclient-2]: process has died [pid 480663, exit code -6, cmd 'gzclient --gui-client-plugin=libgazebo_ros_eol_gui.so'].
Looked at CPMR github. Followed the instructions of the ROS2 Tutorial. Looked at my GAZEBO_RESOURCE_PATH, which is /opt/ros/humble/share. I have no GAZEBO_PLUGIN_PATH defined, althoug I have IGN_GAZEBO_SYSTEM_PLUGIN_PATH=/home/arnoud/var_ws/install/ros_gz_example_gazebo/lib/ros_gz_example_gazebo/ defined. In this directory two libraries can be found: libBasicSystem.so and libFullSystem.so. Also defined GAZEBO_PLUGIN_PATH, same error.
Yet, a build fails on mecanum_drive_controller hardware_interface::LoanedCommandInterface::set_value(0.0)’ from ‘void’ to ‘bool’
The first test requires no build: ros2 launch gz_ros2_control_demos diff_drive_example.launch.py:
Yet, see nothing moving when I do ros2 topic pub /diff_drive_base_controller/cmd_vel geometry_msgs/msg/TwistStamped "{header: {stamp: now, frame_id: 'base_link'}, twist: {linear: {x: 0.2, y: 0.0, z: 0.0}, angular: {x: 0.0, y: 0.0, z: 0.5}}}" --rate 5.
Checked with ros topic list. The actual topic is /diff_drive_base_controller/cmd_vel_unstamped, but also there I see no response.
Looked at the prerequisite. After explaining all parts of the URDF, jumped to Visualize the URDF File.
The command ros2 launch urdf_tutorial display.launch.py model:=~/ros2_ws/src/yahboom_rosmaster/yahboom_rosmaster_description/urdf/robots/rosmaster_x3.urdf.xacro failed because the yahboom_rosmaster_description was not build yet.
Did colcon build --packages-select yahboom_rosmaster_description, followed by source install/setup.bash. Now I get the yahboom robot-description in RViz:
Note that a number of transforms are missing a transform to the base_link: caster, chassis, left_wheel, odom, right_wheel:
Also nice for Seminar 1, is the mass-distribution. Note that the wheels have now more mass than in Addison's tutorial:
Also nice for Seminar 1, is the collision-surface:
Did the same for the ugv-rover. First did source ~/ugv_ws/install/setup.sh, followed by ros2 launch urdf_tutorial display.launch.py model:=/home/arnoud/ugv_ws/install/ugv_description/share/ugv_description/urdf/ugv_rover.urdf
The description looks good, no warnings for the TFs, could control the pan-tilt link1 to turn the camera:
Not only visualized the mass, also the inertia:
The collision seems very detailed, nearly overlapping with the Visuals:
Used pdftoppm ugv_rover_frames.pdf ugv_rover_frames.png -png to convert pdf (created with ros2 run tf2_tools view_frames) to this image:
Trying to launch the ugv_rover urdf from gz_ros2_control_demos. Copied diff_drive_example.launch.py to ugv_rover_drive_example.launch.py.
Started ros2 launch gz_ros2_control_demos ugv_rover_drive_example.launch.py, which can find the urdf, but is unable to find [model://ugv_description/meshes/ugv_rover/base_link.stl].
Tried to solve this by setting IGN_GAZEBO_MODEL_PATH and/or GAZEBO_MODEL_PATH, to no avail.
Checked this gazebo issue, trick is to set IGN_GAZEBO_RESOURCE_PATH with xport IGN_GAZEBO_RESOURCE_PATH=$IGN_GAZEBO_RESOURCE_PATH:/home/arnoud/ugv_ws/install/ugv_description/share. Now I have the ugv_rover in Gazebo:
Note that I also had something running in September 5, 2025. At that time not all links where connected. Looked with ros2 node list. I have three nodes with the name /robot_state_publisher, maybe because I have rviz still running.
What I am missing is a node that is lissening to /cmd_vel.
I see a warning: [spawner-5] [WARN] [1761050330.488577964] [spawner_joint_state_broadcaster]: Could not contact service /controller_manager/list_controllers.
The script diff_drive_example.launch.py calls the diff_drive_controller.yaml, which defines the left and right_wheel_names.
The ackermann_drive_controller.yaml has front_wheels_names: ['right_wheel_steering_joint', 'left_wheel_steering_joint'].
Tried os2 topic pub --once cmd_vel geometry_msgs/msg/Twist "{linear: {x: 0.2, y: 0.0, z: 0.0}, angular: {x: 0.0, y: 0.0, z: 0.0}}", which works (October 13, 2025 for the real robot (with bringup running).
Looked at gazebo_example_world.launch.py, which not only set the environment GZ_SIM_RESOURCE_PATH, but also GZ_SIM_PLUGIN_PATH.
Looking at Waveshare's Gazebo tutorial. Seems that the ugv_rover is spawned in the ~/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world.
Changed the empty.sdf for ugv_world.world in ugv_rover_drive_example.launch.py, but ros2 launch gz_ros2_control_demos ugv_rover_drive_example.launch.py fails to find the ground plane, sun.
Defined export GZ_SIM_RESOURCE_PATH=/opt/ros/humble/share/:/home/arnoud/ugv_ws/install/share and export GZ_SIM_PLUGIN_PATH=/opt/ros/humble/share/:/home/arnoud/ugv_ws/install/share.
Together with export IGN_GAZEBO_RESOURCE_PATH=$IGN_GAZEBO_RESOURCE_PATH:/home/arnoud/ugv_ws/install/ugv_description/share I get the empty world again.
The empty world is loaded from /usr/share/ignition/ignitation-gazebo6/worlds.
Cannot find which ENVIRONMENT variables are needed for this version of GAZEBO. Looked at ROS Humble Gazebo.
At least ign topic -l seems to work:
/clock
/gazebo/resource_paths
/gui/camera/pose
/stats
/world/empty/clock
/world/empty/dynamic_pose/info
/world/empty/pose/info
/world/empty/scene/deletion
/world/empty/scene/info
/world/empty/state
/world/empty/stats
Yet, in ROS Humble Gazebo there is also /model. Am I missing some bridges?
Starting ign gazebo -v 4 -r visualize_lidar.sdf and starting ros2 run ros_gz_bridge parameter_bridge /model/vehicle_blue/cmd_vel@geometry_msgs/msg/Twist]ignition.msgs.Twist allowed to drive the vehicle. The lidar gave some errors, but I couldn't select the right frame (many ugv_rover frames, no blue_vehicle frames).
Looked into /usr/share/ignition/ignition-gazebo6/worlds/. Interesting is for instance skid_steer_mecanum.sdf and tracked_vehicle_simple.sdf
Tried one of the skid_steer_mecanum.sdf. The command ign topic -l seems to give a mix of current and previous simulation:
/clock
/gazebo/resource_paths
/gui/camera/pose
/model/vehicle_blue/cmd_vel
/model/vehicle_blue/odometry
/model/vehicle_blue/tf
/stats
/world/diff_drive/clock
/world/diff_drive/dynamic_pose/info
/world/diff_drive/pose/info
/world/diff_drive/scene/deletion
/world/diff_drive/scene/info
/world/diff_drive/state
/world/diff_drive/stats
The entity Tree gives a vehicle_blue with 4 wheel_joints. ros2 run ros_gz_bridge parameter_bridge /model/vehicle_blue/cmd_vel@geometry_msgs/msg/Twist]ignition.msgs.Twist is still running. The model also responds on ros2 topic pub /model/vehicle_blue/cmd_vel geometry_msgs/Twist "linear: { x: 0.1 }"
Did sudo cp ugv_world.world /usr/share/ignition/ignition-gazebo6/worlds/ugv_world.sdf.
Looked at the actual model which is should be loaded by ugv_world. It is actual in ~/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/models/world/model.sdf. It actually loads some walls and a table.
Not so informative, shows how to create from strings, not from files.
The cpmr_apb populate.py script does something comparible (creating a SDF-string, and send a request). It is only waiting for a /spawn_entity service.
Tried ros2 run gazebo_ros spawn_entity.py -topic /robot_description -entity ugv_rover. Yet, that crashes, with Gazebo started with GazeboRosFactory?
Made ~/scripts/insert_sphere_in_gazebo.sh which worked. Create insert_cone_in_gazebo.sh inspired by populate.sh's string. Script gave no error, but no coke_can appeared.
Inspired by /usr/share/ignition/ignition-gazebo6/worlds/segmentation_camera.sdf, I tried to add a Cone instead of Coke.
Found /usr/share/gazebo-11/models/, but the worlds in /usr/share/gazebo-11/worlds/ were not known (Fuel world download failed). Time to go home. Login out, fresh Login tomorrow.
October 20, 2025
Trying to install greenwave-monitor, but this fails on ament_cmake with colcon build --packages-up-to greenwave_monitor:
CMake Error at CMakeLists.txt:25 (find_package):
By not providing "Findament_cmake.cmake" in CMAKE_MODULE_PATH this project
has asked CMake to find a package configuration file provided by
"ament_cmake", but CMake did not find one.
Could not find a package configuration file provided by "ament_cmake" with
any of the following names:
ament_cmakeConfig.cmake
ament_cmake-config.cmake
Add the installation prefix of "ament_cmake" to CMAKE_PREFIX_PATH or set
"ament_cmake_DIR" to a directory containing one of the above files. If
"ament_cmake" provides a separate development package or SDK, be sure it
has been installed.
Trying to build in a fresh ~/ros_ws (on Rover #4). Initiated the workspace with sudo rosdep init, followed by rosdep update (to no avail)
Tried sudo apt install ros-humble-ament-cmake-auto, but all ament-cmake packages were already installed.
Did sudo apt upgrade, which updated some docker packages (and downgraded 4 nvidia-container-toolkit packages).
The suggestion of this forum-issue solved it: source /opt/ros/humble/setup.bash. Now it compiles
The demo ros2 run greenwave_monitor ncurses_dashboard --demo shows the how images and imu-measurents are monitored.
Started reading in the image as mono (bits 0-255). Working with dtype="float" (bits 0.0-1.0) worked less with following algorithsm:
Otsu method filters out most of the grass, so there are less edges:
Setting a manual threshold (0.95) works better:
The final Machine Vision Toolbox code was:
field = Image.Read("/mnt/c/tmp/frame0006.jpg", mono=True)
new_binary = field.threshold(250)
new_binary.disp()
new_binary.canny().disp()
The code could also have been abbreviated to field.threshold(250).canny().disp().
October 16, 2025
The ROS GreenWave monitor looks interesting to monitor the topics during runtime, including /nitros_topics.
Updating Assignment 1.
Trying to visualise the line_follower_edit.db3 from WSL, but once I subscribe to topic /image_raw I get many Message filter dropping on frame 'pt_camera_link'.
Strange enough, ros2 run image_view image_view image:=image_raw works fine:
Did git clone https://github.com/petercorke/RVC3-python.git. Had to install python3 -m pip install ipympl, which installed version 0.9.8.
Started the notebook of Chapter 11 with jupyter notebook (still in WSL with Xlaunch running)
No problem to run canny() on the images, but this number of edges still needs some filtering:
Yet, the image pipeline has a github, which point in the upper-right corner to some recent documentation.
After some through clicking I finally reach ROS2 image_view.
Yet, intermediate steps like image_view index also misdirect to the image_view website, which is actually the image view page in the ROS index, which points to a website (itself and back to the repository).
Inside ~/git, I did git clone https://github.com/rerun-io/rerun.git
Instead of in the virtual env, I installed the packages natively.
Still had to install many packages from gazebo: $ sudo apt install ros-humble-desktop gazebo ros-humble-navigation2 ros-humble-turtlebot3 ros-humble-turtlebot3-gazebo.
Started ros2 launch nav2_bringup tb3_simulation_launch.py headless:=False, which brings up a RVIZ display, which works. The display is the same as NAV2 getting started, with a Global Status error. Yet, what is different, is that Nav2 'startup/pauze, shutdown' buttons are all grey-out. Adding a 2D Pose estimate and/or Nav2 goal, with one exception: the map doesn't has transform from map to base_link.
See only warnings on waiting for transform from base_link to odom. Base_link is there, odom is nowhere.
Tried to run python3 main.py, which gave a numpy crash with pybind11.
So, tried instead the venv. Started with python3 -m venv venv. Did source venv/bin/activate (typo).
Tried again python3 examples/python/ros_node/main.py, which gave again a warning about pybind11>=2.12, although the real error is inside cv_bridge.
Looked at the python/ros_node/main.py example, which does rr.log(), rr.set_time(), rr.Image(), rr.Pinhole() for the different messages.
The main() in main.py calls TurtleSubscriber(), which calls TransformListener() and a number of callbacks, which are combined in a group.
At least the Rerun viewer visualises the /map/box and /map/robot/, although the urdf contains no mesh, only the /map/robot/urdf/base_footprint tf-tree:
Checked ros2 bag info line_follower_edit.db3. Only the following topics: /camera_info, /cmd_vel, /image_raw, /image_raw/compressed, /image_raw/compressedDepth, /parameter_events (35x), /rosout(18x)
Inspected the /parameter_events with ros2 topic echo /parameter_events while doing ros2 bag play line_follower_edit.db3 in another terminal.
For /rosout I got some warnings on incompatible policy: DURABILITY_QOS_POLICY. The policy can be set with --qos-durability. Seems to be added to ros2 bag play
Seminar Week 2 - Omnidirectional camera + quizes on camera-models
Seminar Week 3 - Hyperspectral camera + quizes on Kalman Filter and loc
Seminar Week 4 - Quiz on stereo + deep depth estimation
Seminar Week 5 - Quiz on SLAM + sensor fusion
Seminar Week 6 - Advanced on Autonomous Driving + Quiz on Planning
Seminar Week 7 - Presentations on assignments (included in grading assignment 3 - minutes for presentation + Q&A).
Lecture 6 - Planning for me.
October 13, 2025
To see if it was really due to WSL, the same test as last Friday, but now from the Ubuntu 22.04 partition of my nb-dual.
Connecting to UGV Rover failed, because it stills starts the hotspot (nothing changed in the standard configuration). Also the jupyter notebook is running, blocking the camera. Left the default configuration on Rover #6 for the moment.
Note that when the hotspot is no longer active, the IP is no longer on the small base-display.
Note that it would be great to overload the on-off button, so the robot would say its IP. Lets start with saying its IP during boot.
Should also look-up a general way to give a name to a terminal.
The dockers are now started up succesfully at both UGV Rover #4 and #6.
Checked that the voltage of the Rover #4 gives:
data: 10.899999618530273
---
root@ubuntu:~# JSON decode error: Expecting ',' delimiter: line 1 column 33 (char 32) with line: {"T":1001,"L":0,"R":0,"ax":24672,"ay":4320,"az":255,"gx":4064,"gy":25{"T":1001,"L":0,"R":0,"ax":24672,"ay":4320,"az":255,"gx":4064,"gy":255,"gz":6656,"mx":2816,"my":2304,"mz":-27647,"odl":0,"odr":0,"v":1090}
Tested ros2 topic echo /voltage --once also on nb-dual. Works:
data: 11.0
---
Turning on the lights and pan-tilt works fine, sending the Twist gives no repsonce. Strange, the /cmd_vel topic is visible.
Tried ros2 launch ugv_tools teleop_twist_joy.launch.py, which fails on missing module 'pygame'.
Installed pygame (and add it to requirements). Connected USB-dongle to USB-C adapter, no response.
Tried instead ros2 run ugv_tools keyboard_ctrl, which allows to drive the robot.
So, the problem was the angular-z of 1.8. ros2 topic pub --once cmd_vel geometry_msgs/msg/Twist "{linear: {x: 0.2, y: 0.0, z: 0.0}, angular: {x: 0.0, y: 0.0, z: 0.0}}" works fine. A linear-x of 2.0 is really fast ...
Started the last command in the UGV Rover manual, which seems to fail:
[usb_cam_node_exe-1] [INFO] [1760353706.684736710] [usb_cam]: Starting 'pt_camera' (/dev/video0) at 640x480 via mmap (mjpeg2rgb) at 30 FPS
[usb_cam_node_exe-1] [swscaler @ 0xaaab0320d2c0] No accelerated colorspace conversion found from yuv422p to rgb24.
[usb_cam_node_exe-1] [INFO] [1760353706.720664490] [usb_cam]: Setting 'white_balance_temperature_auto' to 1
[usb_cam_node_exe-1] [INFO] [1760353706.720766669] [usb_cam]: Setting 'exposure_auto' to 3
[usb_cam_node_exe-1] [INFO] [1760353706.728084427] [usb_cam]: Setting 'focus_auto' to 0
[usb_cam_node_exe-1] [INFO] [1760353706.864792710] [usb_cam]: Timer triggering every 33 ms
[usb_cam_node_exe-1] terminate called after throwing an instance of 'std::runtime_error'
[usb_cam_node_exe-1] what(): Invalid v4l2 format
Tried again, after having killed some python3 process running in the background.
Still fails, but now on selecting the right device:
[usb_cam_node_exe-1] [ERROR] [1760353861.152765749] [usb_cam]: Device specified is not available or is not a vaild V4L2 device: `/dev/video0`
[usb_cam_node_exe-1] [INFO] [1760353861.152876855] [usb_cam]: Available V4L2 devices are:
[usb_cam_node_exe-1] [INFO] [1760353861.152905464] [usb_cam]: /dev/video2
[usb_cam_node_exe-1] [INFO] [1760353861.152921625] [usb_cam]: USB Camera: USB Camera
[usb_cam_node_exe-1] [INFO] [1760353861.152938713] [usb_cam]: /dev/video3
[usb_cam_node_exe-1] [INFO] [1760353861.152950905] [usb_cam]: USB Camera: USB Camera
Going lower level: ros2 run usb_cam usb_cam_node_exe.
The documentation is not explicit on how to specificy the video_device; it loads this parameter together with many others in a config file.
Tried ros2 run usb_cam usb_cam_node_exe --ros-args --video_device /dev/video2, which gives unknown ROS argument.
Copied ~/ugv_ws/src/ugv_main/ugv_vision/config/params.yaml to /tmp/pan_tilt_video_device2.yaml, modified the device. Did ros2 run usb_cam usb_cam_node_exe --ros-args --params-file /tmp/pan_tilt_video_device2.yaml. Several warnings (no accelerated colorspace conversion, no auto_control of white_balance, exposure, focus):
INFO] [1760355022.835715932] [usb_cam]: camera_name value: pt_camera
[WARN] [1760355022.835927073] [usb_cam]: framerate: 30.000000
[INFO] [1760355022.837851251] [usb_cam]: camera calibration URL: package://ugv_vision/config/camera_info.yaml
[INFO] [1760355022.909005577] [usb_cam]: Starting 'pt_camera' (/dev/video2) at 640x480 via mmap (mjpeg2rgb) at 30 FPS
[swscaler @ 0xaaaaf3cab480] No accelerated colorspace conversion found from yuv422p to rgb24.
This device supports the following formats:
Motion-JPEG 1920 x 1080 (30 Hz)
Motion-JPEG 160 x 120 (30 Hz)
Motion-JPEG 320 x 240 (30 Hz)
Motion-JPEG 352 x 288 (30 Hz)
Motion-JPEG 640 x 480 (30 Hz)
Motion-JPEG 800 x 600 (30 Hz)
Motion-JPEG 1024 x 768 (30 Hz)
Motion-JPEG 1280 x 720 (30 Hz)
Motion-JPEG 1280 x 960 (30 Hz)
Motion-JPEG 2592 x 1944 (30 Hz)
Motion-JPEG 2048 x 1536 (30 Hz)
YUYV 4:2:2 640 x 480 (30 Hz)
YUYV 4:2:2 1280 x 720 (10 Hz)
YUYV 4:2:2 2048 x 1536 (1 Hz)
YUYV 4:2:2 1920 x 1080 (5 Hz)
YUYV 4:2:2 1280 x 960 (5 Hz)
YUYV 4:2:2 960 x 540 (10 Hz)
YUYV 4:2:2 800 x 600 (10 Hz)
YUYV 4:2:2 2592 x 1944 (1 Hz)
unknown control 'white_balance_temperature_auto'
[INFO] [1760355022.936042631] [usb_cam]: Setting 'white_balance_temperature_auto' to 1
[INFO] [1760355022.936154634] [usb_cam]: Setting 'exposure_auto' to 3
unknown control 'exposure_auto'
[INFO] [1760355022.942577744] [usb_cam]: Setting 'focus_auto' to 0
unknown control 'focus_auto'
[INFO] [1760355023.078257937] [usb_cam]: Timer triggering every 33 ms
This is actually the config used in ugv_vision camera.launch.py.
When using the usb_cam_node, only the /image_raw is published. For the rectified image I have to launch ros2 launch ugv_vision camera.launch.py
Note, check the remarks on Compression in documentation.
Made a camera.launch.py version which loads the correct camera parameters. ros2 launch ugv_vision pan_tilt_camera_device2.launch.py starts fine.
Yet, when requesting rectified images with ros2 run image_view image_view --ros-args --remap image:=/image_rect, driver start to complain with:
[component_container-2] Image messages received: 10
[component_container-2] CameraInfo messages received: 5
[component_container-2] Synchronized pairs: 3
[component_container-2] [WARN] [1760356402.172106811] [rectify_color_node]: [image_transport] Topics '/image_raw' and '/camera_info' do not appear to be synchronized. In the last 10s:
Looked with v4l2-ctl --list-devices, there are both /dev/video2 and /dev/video3 mounted. Checked with v4l2-ctl --device=/dev/video2 --all, both devices have the same SerialNumber. Same device?
Rebooted, now the USB Camera is on /dev/video0
Yet, rectify still has the same problem. Hypothesis: camera_info needs the TF, so also the robot_description should be active.
Tested that hypothesis by starting ros2 launch ugv_description display.launch.py use_rviz:=false, which (partly) worked; I received images from my webcam (combined with the rectification of the UGV Rover:
Yet, starting the ugv_vision camera.launch a second time had as effect that the video was again on /dev/video1. Reboot again.
Made a version that launches the robot_description without gui: ros2 launch ugv_description robot_description.launch.py The synchronization seems to fail for rectify_color_node.
Also node that on May 2024 Mike says that the image_proc node is broken.
Looking into the Rolling Rectify node documentation.
Tried several examples from image_proc tutorial, such as ros2 launch image_proc image_proc.launch.py, but the synchronization always fails. The image_proc.launch.py also seems to subscribe to topics /image_color and image_mono, instead of image_raw.
Experimenting with Isaac ROS Image pipeline exampes. According to the documentation, JetPack 6.1 or 6.2 is needed (while our docker uses Jetpack 6.0)
Looked at Quickstart. Just sudo apt-get install ros-humble-isaac-ros-image-proc doesn't work, seems that the repository is added with script run_dev.sh from isaac_ros_common
Found the ISAAC apt repository. Inside the docker of UGV Rover #4. Now I could do sudo apt-get install ros-humble-isaac-ros-image-proc. Checked inside the version of the Jetpack inside the docker sudo apt-cache show nvidia-jetpack give no package found. Still 21 new packages are installed:
ros-humble-gxf-isaac-atlas ros-humble-gxf-isaac-gems
ros-humble-gxf-isaac-gxf-helpers ros-humble-gxf-isaac-image-flip
ros-humble-gxf-isaac-message-compositor ros-humble-gxf-isaac-messages
ros-humble-gxf-isaac-optimizer ros-humble-gxf-isaac-sight
ros-humble-gxf-isaac-tensorops ros-humble-isaac-ros-common
ros-humble-isaac-ros-gxf ros-humble-isaac-ros-image-proc
ros-humble-isaac-ros-managed-nitros ros-humble-isaac-ros-nitros
ros-humble-isaac-ros-nitros-camera-info-type
ros-humble-isaac-ros-nitros-image-type
ros-humble-isaac-ros-nitros-tensor-list-type
ros-humble-isaac-ros-tensor-list-interfaces ros-humble-magic-enum
ros-humble-negotiated ros-humble-negotiated-interfaces
Next is sudo apt-get install -y ros-humble-isaac-ros-examples.
The examples give examples for rosbag, realsense, hawk and zed camera.
The call is ros2 launch isaac_ros_examples isaac_ros_examples.launch.py launch_fragments:=rectify_mono interface_specs_file:=${ISAAC_ROS_WS}/isaac_ros_assets/isaac_ros_image_proc/quickstart_interface_specs.json.
Just running without interface_specs_file give launch exception: camera_resolution'. Downloading the assets is different for each isaac package.
The script to download the one of isaac_ros_image_proc can be found here: Download Quickstart assets. Indicated that two version were available (3.1.0 and 3.0.0). Made a script to download version 3.0 (~/isaac_ros_ws/scripts/download_isaac_ros_image_proc_assets.sh. So, the quickstart_interface_specs.json is actually quite simple, just the camera_resolution (width/height 1920/1200). In the isaac_ros_assets/isaac_ros_image_proc/quickstart you can also find a rosbag. From the metadata.yaml I see that it is the topic /hawk_0_left_rgb_image together with /hawk_0_left_rgb_camera_info.
My camera_resolution is 640x480.
Tried launch isaac_ros_examples isaac_ros_examples.launch.py launch_fragments:=rectify_mono interface_specs_file:=${ISAAC_ROS_WS}/isaac_ros_assets/isaac_ros_image_proc/quickstart_interface_specs.json. Get a missing library: libnvvpi.so.3. Also libcudart.so.12 is missing according to ldd /opt/ros/humble/lib/librectify_node.so | grep found
On August 26, 2025 I solved this with installing sudo apt install cuda-toolkit-12-2. Google suggested sudo apt install nvidia-jetpack.
The libnvvpi.so.3 is part of vpi-package inside the jetpack. Yet, the docker itself hasn´t have the apt-source. Copied it the r36.3 version from the jetson. That wasn´t trusted, so modified the lines in etc/apt/sources.list.d/nvidia-l4t-apt-source.list to deb [allow-insecure=yes] https://repo.download.nvidia.com/jetson/common r36.3 main.
Now I could do sudo apt install nvidia-vpi-dev.
The command ros2 launch isaac_ros_examples isaac_ros_examples.launch.py launch_fragments:=rectify_mono interface_specs_file:=${ISAAC_ROS_WS}/isaac_ros_assets/isaac_ros_image_proc/quickstart_interface_specs.json is now running (with too large resolution).
Still, ros2 run image_view image_view --ros-args --remap image:=image_rect freezes. I see from rectify-log that the data-format is nitros_image_bgr8. Not sure if that format is known to image-view. Maybe add some plugin tomorrow.
October 10, 2025
Checking the docker-interface of the UGV Rover, and updating the UGV Manual.
Connecting to UGV Rover #4. ssh -p 23 failed, so connected to the barebone.
See no docker running. Checked docker container list. One container present with name ugv_jetson_ros_humble. Container has one image, as checked with docker image list.
As the Waveshare Preparation indicates, the ssh server of the container can be started with source ugv_ws/ros2_humble.sh.
ssh -p 23 now works, yet the /home/ws/ugv_ws/install/setup.bash fails on several non-build packages:
not found: "/home/ws/ugv_ws/install/apriltag_msgs/share/apriltag_msgs/local_setup.bash"
not found: "/home/ws/ugv_ws/install/apriltag_ros/share/apriltag_ros/local_setup.bash"
not found: "/home/ws/ugv_ws/install/cartographer/share/cartographer/local_setup.bash"
not found: "/home/ws/ugv_ws/install/costmap_converter_msgs/share/costmap_converter_msgs/local_setup.bash"
not found: "/home/ws/ugv_ws/install/explore_lite/share/explore_lite/local_setup.bash"
not found: "/home/ws/ugv_ws/install/ldlidar/share/ldlidar/local_setup.bash"
not found: "/home/ws/ugv_ws/install/openslam_gmapping/share/openslam_gmapping/local_setup.bash"
not found: "/home/ws/ugv_ws/install/rf2o_laser_odometry/share/rf2o_laser_odometry/local_setup.bash"
not found: "/home/ws/ugv_ws/install/robot_pose_publisher/share/robot_pose_publisher/local_setup.bash"
not found: "/home/ws/ugv_ws/install/slam_gmapping/share/slam_gmapping/local_setup.bash"
not found: "/home/ws/ugv_ws/install/teb_msgs/share/teb_msgs/local_setup.bash"
not found: "/home/ws/ugv_ws/install/ugv_base_node/share/ugv_base_node/local_setup.bash"
not found: "/home/ws/ugv_ws/install/ugv_description/share/ugv_description/local_setup.bash"
not found: "/home/ws/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/local_setup.bash"
not found: "/home/ws/ugv_ws/install/ugv_interface/share/ugv_interface/local_setup.bash"
not found: "/home/ws/ugv_ws/install/ugv_nav/share/ugv_nav/local_setup.bash"
not found: "/home/ws/ugv_ws/install/ugv_slam/share/ugv_slam/local_setup.bash"
not found: "/home/ws/ugv_ws/install/vizanti_cpp/share/vizanti_cpp/local_setup.bash"
not found: "/home/ws/ugv_ws/install/vizanti_msgs/share/vizanti_msgs/local_setup.bash"
not found: "/home/ws/ugv_ws/install/vizanti_demos/share/vizanti_demos/local_setup.bash"
not found: "/home/ws/ugv_ws/install/vizanti_server/share/vizanti_server/local_setup.bash"
not found: "/home/ws/ugv_ws/install/vizanti/share/vizanti/local_setup.bash"
Note also that vi is not installed.
Tried again, now for a fresh UGV Rover #6. Nothing modified (no repair of nvmodel, jupyter notebook still running).
No complains after port-23 login in Rover #6.
Back to UGV Rover #4.
Started with sudo apt install vim-tiny. Fails because the repositories are not up-to-date
Continued with sudo apt update. Fails on signature verification of http://packages.ros.org/ros2/ubuntu and http://mirrors.ustc.edu.cn/ros2/ubuntu.
Running the commands:
export ROS_APT_SOURCE_VERSION=$(curl -s https://api.github.com/repos/ros-infrastructure/ros-apt-source/releases/latest | grep -F "tag_name" | awk -F\" '{print $4}')
curl -L -o /tmp/ros2-apt-source.deb "https://github.com/ros-infrastructure/ros-apt-source/releases/download/${ROS_APT_SOURCE_VERSION}/ros2-apt-source_${ROS_APT_SOURCE_VERSION}.$(. /etc/os-release && echo $VERSION_CODENAME)_all.deb" # If using Ubuntu derivates use $UBUNTU_CODENAME
sudo dpkg -i /tmp/ros2-apt-source.deb
Solves the general case, but not the Chinese mirrors.
Continue with sudo apt install vim-tiny. Could better install just vim, because I get many warnings like:
update-alternatives: warning: skip creation of /usr/share/man/da/man1/vi.1.gz because associated file /usr/share/man/da/man1/vim.1.gz (of link group vi) doesn't exist
Commented out 4 Chinese mirrors in /etc/apt/sources.list and one in /etc/apt/sources.list.d/ros2.list. The ros2.list is now 'empty'
Funny, we now only have two apt-resources, ros2 and cuda-developer. Still 532 packages can be upgraded.
Uncommented 6 deb's without space after #. This are the default Ubuntu 22.04 jammy packages (main, security, updates, backports). Now there are 20 repositories, and 761 packages ready to be upgraded.
Finally found out what is different between UGV Rover #4 and #6. When you go in the container to ~/ugv_ws, the /home/ws/ugv_ws is actually the old /home/jetson/ugv_ws. The mounted the local user under a different name.
Seems that I never did a build on UGV Rover #4.
Running from inside the container the script install_additional_ros_humble_packages.sh Note that the script asks to update the settings of the sshd-server. Choose option 2 (keep current). In this script is also a sudo apt upgrade -y, so 758 packages are upgraded.
The command sudo add-apt-repository universe -y is not known. That means that sudo apt install software-properties-common is not done. Updated the script in ugv_ws fork.
Checked the other initial commands from Install ROS2 Humble. Checked locale inside the docker of UGV Rover #6. Still set to Chinese.
Tried git pull, but get:
fatal: detected dubious ownership in repository at '/home/ws/ugv_ws'
To add an exception for this directory, call:
Running the script is a bit overkill, because removing libopencv-dev also removes many of the ros-humble again. Yet, it seems to work. Having an US locale. There are 4 packages upgradable, but held back:
libcudnn8-dev/unknown 8.9.7.29-1+cuda12.2 arm64 [upgradable from: 8.9.6.50-1+cuda11.8]
libcudnn8/unknown 8.9.7.29-1+cuda12.2 arm64 [upgradable from: 8.9.6.50-1+cuda11.8]
libnccl-dev/unknown 2.28.3-1+cuda13.0 arm64 [upgradable from: 2.15.5-1+cuda11.8]
libnccl2/unknown 2.28.3-1+cuda13.0 arm64 [upgradable from: 2.15.5-1+cuda11.8]
Leave this for the moment, upgrading from cuda11.8 to cuda12.2 and/or cuda13.0 has to be done with care.
The first command cd ~/ugv_ws fails, because that is interpreted as /root/ugv_ws.
Looked in ENV. HOME is indeed /root. Would be good to overwrite that environment variable. Seems to work. Yet, there is no /home/ws/.bashrc, all ws-specific calls are made from /root/.bashrc.
Added the following three lines to /root/.bashrc:
export HOME=/home/ws
source $HOME/ugv_ws/install/setup.bash
source $HOME/.bashrc
Seems to work. Also the last build_apriltag.sh goes well, although I receive some warnings on the use of an explicit constructor
Tried to set CMAKE_CXX_STANDARD from 14 to 98 in src/ugv_else/apriltag_ros/apriltag_ros/CMakeLists.txt, but see no effect.
Also, the build gives three linking warnings:
/usr/bin/ld: warning: libopencv_calib3d.so.4.5d, needed by /opt/ros/humble/lib/libimage_geometry.so, may conflict with libopencv_calib3d.so.405
/usr/bin/ld: warning: libopencv_core.so.4.5d, needed by /opt/ros/humble/lib/libimage_geometry.so, may conflict with libopencv_core.so.405
/usr/bin/ld: warning: libopencv_imgcodecs.so.4.5d, needed by /opt/ros/humble/lib/libcv_bridge.so, may conflict with libopencv_imgcodecs.so.405
The next command from is ros2 launch ugv_description display.launch.py use_rviz:=false. When use_rviz is false, the launch script still tries to start the joint_state_publisher_gui-2 (which fails, without display)
So, this should be executed from the laptop, only the ros2 launch ugv_bringup bringup_lidar.launch.py use_rviz:=true should be run from the UGV Rover #4
Trying to run the install_additional_ros_humble_packages.sh script, but on WSL I get conflicting values when running ros2-apt-source.
Problem was that I had two ros-entries in /etc/apt/source.list.d. Commented out the ros2.list, which was keyring based. Now I could do sudo apt upgrade again. Running the remainder of install_additional_ros_humble_packages.sh.
When the Xlaunch running on the background, I could start ros2 launch ugv_description display.launch.py use_rviz:=true. That gives gui to control the different wheels, but strange enough no rviz. Sliding the bars in the gui let nothing move.
Tried also for UGV Rover #6. Also no response. ros2 topic echo /voltage --once gives nothing. Also ros2 topic pub --once /cmd_vel geometry_msgs/msg/Twist "{linear : {x: 2.0, y: 0.0, z: 0.0}, angular: {x: 0.0, y: 0.0, z: 1.8}}" no response (nor on rover, nor in WSL).
Seems to be a problems for WSL, Joey also experienced that some topics are lost when running ROS Humble under WSL.
Going to the native node. Strange enough the build is not visible in /home/jetson. Doing a git pull gives .git/FETCH_HEAD: Permission denied. Actually, three files are now owned by root (and no longer jetson).
Changed those files, and some others. Such as sudo chown -R jetson:jetson install. Also for log and build.
The file /home/jetson/ugv_ws/install/vizanti/share/vizanti/local_setup.bash cannot be found, because it is a symbolic link to /home/ws/ugv_ws/build/apriltag_msgs/ament_cmake_environment_hooks/local_setup.bash. Is this a side-effect of --symlink-install?
When building, the CMakeCache fails:
CMake Error: The current CMakeCache.txt directory /home/jetson/ugv_ws/build/apriltag/CMakeCache.txt is different than the directory /home/ws/ugv_ws/build/apriltag where CMakeCache.txt was created. This may result in binaries being created in the wrong place. If you are not sure, reedit the CMakeCache.txt
CMake Error: The source directory "/home/ws/ugv_ws/src/ugv_else/apriltag_ros/apriltag" does not exist.
Solved it by colcon clean packages --packages-select apriltag apriltag_msgs apriltag_ros -y first. Indeed, without the option --symlink-install it is no longer a symbolic link to build.
October 9, 2025
In the last Chapter of the SLAM Handbook (the Computational Structure of Spatial AI) Andrew J. Davision makes the following statement: SLAM is notable within the broader picture of artificial intelligence in that it has not yet been completely dominated by ML
As latest networks not only DUSt3R but also VGGT is mentioned.
Another important quote: a future optimally efficient camera should report places where the received data is different from what was predicted
The 5 steps on page 536 and 537 could also usefull in a lecture.
The idea that the 5 processing steps of page 537 are parallel, so fit for a GPU. The graph-based operations of page 536 are better suited for an IPU.
The trick I used VisualSfM - Ubuntu installation: deb [allow-insecure=yes] http://archive.ubuntu.com/ubuntu/ trusty main universe parlty worked.
I could do sudo apt install libpng12-0, but the install complained that it needed a /lib/x86_64-linux-gnu/libpng12.so.0 to overwrite. Added sudo add-apt-repository ppa:linuxuprising/libpng12 (from askubuntu, which works.
Also installing sudo apt-get install liblog4cxx-dev liblog4cxx10 worked.
The tool DSReadCameraInfo has no longer missing dependencies, yet only partly works:
Number of DS Cameras Detected 2
Serial number XXXXXXXXXX data:
log4cxx: No appender could be found for logger (DS).
log4cxx: Please initialize the log4cxx system properly.
DSAPI call failed at ReadCameraInfo.cpp:134!
status: DS_HARDWARE_MISSING
details: Open device failed.
Looking into this discussion. Problem seems that libDSAPI.so is in ../Lib Added the LIB directory to LD_LIBRARY_PATH. Still same error.
Tried ~/git/librealsense/build/Release/rs-hello-realsense, which gives 09/10 15:00:31,331 ERROR [129896929003008] (rs.cpp:256) [rs2_pipeline_start( pipe:0x5fc3a87cc0c0 ) UNKNOWN] No device connected
Looked into /lib/udev/rules.d/60-librealsense2-udev-rules.rules, there was arleady a rule for the R200, which points to RUN+="/usr/local/bin/usb-R200-in_udev". Did I overwrite this start script with the old R200_install. Removed all old and double udev scripts. Run ~/git/librealsense/scripts/install-r200-udev-fix.sh again. Still rs-hello-realsense fails.
Tried realsense-viewer, and usb-c to ubs-b converter. Still nothing.
Run in ~/git/pangolin/build make again. If I ignore the warnings, the errors are actually on the CODEC_FLAGS
Trying to switch the ffmpeg-driver off. Yet, cmake still says -- ffmpeg Found and Enabled, followed by CMake Error at src/CMakeLists.txt:563 (add_library):
Cannot find source file:
video/drivers/ffmpeg.cpp.
With this file I get errors like TEST_PIX_FMT_RETURN(RGBA);
| ^~~~
| GL_RGBA
Instead of building from source, tried pip install pangolin-tool
That works, but example code uses pangolin, not pangolin-tool.
Looking at the compile-discussion. cmake -DBUILD_PANGOLIN_FFMPEG=OFF brings me further (compilation breaks on Invalid use of incomplete type ‘PyFrameObject’ {aka ‘struct _frame’}).
The pangolin github indicates that the installation is tested under Ubuntu 16.04, Python 3.6+. Tried it both with installig python3.8 via deadsnakes, as creating a python 3.6 and 3.8 environment with micromamba create -n pangolin-python3.6-env python=3.6. Maybe try a different C++ version (tomorrow).
October 8, 2025
Chapter 17 of SLAM Handbook (Open-World Spatial AI) opens with a quite a good short overview of deep learning in Computer Vision, before it focuses what is needed for SLAM.
Impressive how modern transformer models can estimate depth and surface normals, as described in CVPR 2024 paper.
VLMaps accumulate semantic information in a 3D point clould and project it in a 2D grid map. Work of Burgard from ICRA 2022. Has Jupyter notebooks as code. Is based on RGBD input.
Get the feeling that it easier to write a plugin to read a rosbag into MASt3R-SLAM, than to write a index with timestamps and names.
Remember that for the IAS-paper I looked at the 'average' OAK-D calibration. On page 6 I mention the calibration with the fisheye .calibrate function, which gave a focal length of 284.64 pixels.
Looked at rae_camera/config/camera.yaml, which only specifies the resolution (800P) and width/height (640/400) of the right-camera. The right-camera has socket-id 2.
Yet, there is also rae_camera/config/cal.json. The boardName's are not the 4K camera (IMX214 board) or stereo-camera's (OV9782 boards), but boardName DM3370. The IMX214 camera has socket 0, the OV9782 boards socket 1-4 (according to the EEPROM).
Seemed that the IMX214 image was never accessed in RAE. The IMX214 has 4 resolutions (from 1920x1080 to 4208x3120). In November 14, 2024 I mention that the 1080 resolution can be accessed via the enable_rg option.
Asked UvA AI-chat to generate create_index_from_ros2bag.py. Library is incorrect, the current timestamp is written and not the one from the message. Manually corrected it
The timestamp is actually in msg.stamp, which has both seconds and nanoseconds: stamp=builtin_interfaces__msg__Time(sec=1732709327, nanosec=131527671, __msgtype__='builtin_interfaces/msg/Time'
The index file is now the same as the "rgb.txt" from the tum-dataset.
Actually, this was not needed, because the last line of mast3r_slam/dataloader.py shows that it can load just RGBFiles.
So, just running python main.py --dataset ~/tmp/big_maze/right_camera/ --config config/eval_no_calib.yaml works with 12 FPS:
There is an option "save-as", which has a default. Looks like that the map is saved as logs/right_camera.ply. Visualizing it with f3d logs/right_camera.ply (after sudo apt install f3d): gives a binary mesh:
Continue with git clone https://github.com/spmallick/learnopencv.git (3.62 GiB).
Build was succesful. Went to ~/git/OpenNI2/Bin/x64-Release SimpleViewer indicated no devices found. Connected a Structure Core. Is visible with lsusb. The SimpleViewer still sees no devices.
The Cross Platform SDK should work with the Structure Core.
Had the same problem March 11, 2021. At that time I downloaded SDK v0.8.1, now version 0.9.
Still No MAGIC from USB interface 0 (error=7).
OK, modified /etc/udev/rules.d/55-structure-core.rules as before. Essential is not only sudo udevadm control --reload-rules, but also to reconnect the USB-cable.
The CorePlayGround indicated After Structure Core is connected FW version 1.0.0-release. Most of it works, although I don't see anything in the InfraRed window, green stripes in the Visual window, but nice Depth images:
Updated the Firmware to version 1.2.0 (compatible with SDK 0.9.0). The dates of the log-message are now more recent (mixed 1970 and 2025). The CorePlayGround indicates that the last calibration is from 2019_01_04. Still same green stripes.
Looks like OpenNI2 needs a RealSense. Connected a RealSense D435. Cloned librealsense. Install instructions suggest to install via apt-get.
Found instructions on what librealsense tools are actually installed on D435i page.
Simply realsense-viewer worked. There were two rules for the realsense (no difference). Most other devices where installed in /lib/udev/rules.d, so removed the one in /etc/udev/rules.d/ (although installed today. The previous one was installed July 28, 2025.
The realsense-viewer (v2.56.5) indicated that the D435 had firmware 5.16.0.1, while 5.17.0.10 was available. Did a Firmware update:
The realsense-viewer build from source in ~/git/librealsense/build/Release is als v2.56.5 (and also works).
Connected a Realsense R200. Not recognized by the realsense-viewer.
Run the install script, but without the patch. The DSReadCameraInfo tool doesn't work, because the ancient libpng12.so.0 and liblog4cxx.so.10 are not there.
Should be availabe in Ubuntu 14.04 (trusty), so could look to tricks I used VisualSfM - Ubuntu installation: deb [allow-insecure=yes] http://archive.ubuntu.com/ubuntu/ trusty main universe (tomorrow)
October 7, 2025
Chapter 16 of sLAM Handbook (Semantic SLAM) points to Semantic keypoints (ICRA 2017) and semantic edges (CVPR 2017) as mid-level parts of objects.
An example of object SLAM is OrcVIO (IROS 2020), with code (ROS1 Melodic)
On page 466 they refer to the Eikonal equation, which is a loss-term to regularize the surface gradients. ICML 2020 paper with code:
I like the discussion on hybrid solvers (section 16.2.2), which splits the problem in discrete, continues and discrete-continues factors. The continues part is differentiable (i.e. can be estimated with a DNN), while the discrete part has to be solved sequentially.
An example is DC-SLAM (RAL 2022), which compare its results with VISO2 (2011)
Section 16.3 mentions several efficient LiDAR based Semantic SLAM algorithms, like SuMA++ (IROS 2019 - code catkin-based, but not ros-dependent), SA-LOAM (ICRA 2021 - code ROS1 Melodic), SELVO (IROS 2023 - no code)
A reference back to the occupancy maps (chapter 9 of Probabilistic Robotics), bt now 3D and with Semantic information (2023 paper with ROS2 code). Arash has more recent papers with code.
A paper from 2025 is ROAM, which also includes indoor Gazebo experiments. code, including ROS1 Noetic based example.
Nice that all algorithms in this chapter are all illustrated based on the same Unity simulation of a a Husky robot equiped with a RGBD-camera, looking at two vehicles on a courtyard.
Figure 16.17 is usefull for one of the lectures on sub-symbolic representations, for sure when combined with a real example as shown in Figure 16.18.
Would still be interesting to make a pose-graph (left/right) of the AprilTags.
The tutorial is using opencv's ORB detector with 5k keypoints.
After the feature pose estimation is explained based on image formation and epipolar geometry.
Depth in the image is estimated with triangulation.
In the back-end loop closure is done with the classic Bag-of-Words algorithm.
The back-end is finalized with pose-graph optimization.
The 3D point-cloud is visualized with the pangolin-library.
The main starts with setting up the intrinsic matrix of the camera.
The post ends with a promise that in a future post also a code walk-through of ORB-SLAM2 (RGBD) and ORB-SLAM3 (Visual-Inertial fusion) will be made (haven't seen that yet).
Tried to build MASt3R-SLAM again (after last crash).
Did micromamba activate mast3r-slam (made a shell-script to do it)
Did pip install -e thirdparty/mast3r
Did pip install -e thirdparty/in3d
Try pip install --no-build-isolation -e .. Building wheel for lietorch (pyproject.toml) ... takes its time. Done.
Running the Freiburg1_room example works fine with python main.py --dataset datasets/tum/rgbd_dataset_freiburg1_room/ --config config/calib.yaml:
The config/calib.yaml only indicates that calibration has to be used, the actual calibration-measures are in config/intrinsics.yaml: distortion model (fx, fy, cx, cy, k1, k2, p1, p2).
Looked in ~/tmp/big_maze with ros2 bag info rosbag2_2024_11_27-13_04_36_0.db3. Only the /rae/right/image_raw/compressed frames, no RGBD frames.
Seems that MASt3R-SLAM also works with only monocular images.
The provided tum-datasets are directories created by unpacking ros1-bags. Checked python main.py --help, no option to read rosbags. There are different *.txt files which contain the timestamp/frame info:
# color images
# file: 'rgbd_dataset_freiburg1_room.bag'
# timestamp filename
Other files:
::::::::::::::
datasets/tum/rgbd_dataset_freiburg1_room/accelerometer.txt
::::::::::::::
# accelerometer data
# file: 'rgbd_dataset_freiburg1_room.bag'
# timestamp ax ay az
1305031906.964072 0.778306 7.627394 -5.699591
Chapter 15 of SLAM Handbook (Dynamic SLAM), indicates that recently multi-objects SfM becomes possible (DynaSLAM II (RAL 2021).
On page 434, as part of Memory Management for long-term SLAM, the long-term and short-term memory of RTAB-Map is mentioned.
A map cleaning algorithm like Erasor (RAL 2021) could be handy for the maze-map generated in the 3rd assignment. Paper with code (ROS1 Melodic)
Continue at page 454.
Note that MASt3R and MASt3R-SfM are part of the 3D-Vision series of OpenCV lessons, while MASt3R-SLAM is part of the Robotics series of OpenCV.
The breakdown of the "mast3r"-code, followed by the "mast3-sfm"-code would be nice for one of the 'werkcolleges'. For sure if we end the session with an 'own' dataset.
Is there also a croco-walkthrough? At least as short explanation is given with DUSt3R.
Not related, but I like the Inner circle of the 5 papers that are most relevant for your research, in the 'How to get your PhD' book (page 79)
One of the papers which influenced John Leonard was Rodney Brook's Mobile Visual Map Making, before he went to behaviors. His key idea is to use a relational map between the landmarks, rubbery and stretchy, instead of registering them in a 2-d coordinate system. First mentioning of loop closure.
Chapter 14 of SLAM Handbook (Boosting SLAM with Deep Learning) highlights Gaussian Splatting, which they trace back to forward sensor model from Thrun (2003).
Checking where the RoPE2D warning comes from. Checked micromamba list, not installed via micromamba. Checked pip list, not installed via pip. Checked with apt list --installed, not installed via apt.
The last (optional) step is to install dust3r/croco/curope.
First command habitat-sim headless -c conda-forge -c aihabitat failed because habitat-sim requires python 3.6-3.9, while the must3r environment is based on python 3.11. Instead tried directly python setup.py build_ext --inplace Instead tried directly python setup.py build_ext --inplace . I see a warning about cuda_str_version, so it seems a CUDA based version.
When starting the demo, I see now Parsed pos_embed: RoPE100, base size = 512
Running with mode: local context, context size set to (instead of default 25). Now only one CPU node is used (yesterday all 32 cores were used).
The GPU is well used (80%-97%), memory usage stays around 59%.
With context, the first part of the maze is correctly rendered, but fails after the first turn. The process crashes at 53%, because the GPU run out of memory. Got this suggestion:
UDA out of memory. Tried to allocate 554.00 MiB. GPU 0 has a total capacity of 23.54 GiB of which 703.12 MiB is free. Including non-PyTorch memory, this process has 21.39 GiB memory in use. Of the allocated memory 20.37 GiB is allocated by PyTorch, and 547.02 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
Setting the environment variable didn't help, still:
UDA out of memory. Tried to allocate 470.00 MiB. GPU 0 has a total capacity of 23.54 GiB of which 574.81 MiB is free. Including non-PyTorch memory, this process has 21.80 GiB memory in use. Of the allocated memory 17.89 GiB is allocated by PyTorch, and 3.43 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
Moved 1138 frames to the skipped_frames directory. Did the run with context (set on default size=25) for 435 frames. The Visual Map looks good, but actually the robot turned already 180 deg into another corridor:
Added 200 extra images, but reduced the number of Max Points to 10K. Run in mode:linspace. Run to completion, but no reconstruction.
Tried again, but now with local context, but context size=50.
Still, runs out of memory, with the reduced Max Points. At frame 683/735:
Performed the install commands with micromamba, instead of conda. micromamba create -n mast3r-slam python=3.11 followed by micromamba activate mast3r-slam, and micromamba install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=12.4 -c pytorch -c nvidia.
The first two pip installs worked, at the third WS9 runned out of memory (but MUSt3R was still running).
October 1, 2025
Chapter 13 of SLAM Handbook (Boosting SLAM with Deep Learning) starts with high-lighting some recent works, like DUSt3R and MUSt3R.
In section 13.1.2 on Visual Odometry, they back up the claim that DL cannot predict the relative positions as accurate as SLAM, which they backup with a reference to DROID-SLAM (NeurIPS paper 2021 with code, torch-based, no ROS-wrapper, updated 5 months ago).
For the course the combination DSO, DVSO and D3VO could be interesting.
Section 13.2 (on Feature Matching and Optical Flow) mentions next to SuperPoint Universal Correspondence Network (NeurIPS 2016), as the method that proved that the features produced by a NN could improve the downstream feature matching. Matching is naturally done with SuperGlue. SuperGlue was later improved to LightGlue.
Optical flow can be estimated with RAFT, which is the basis of DROID-SLAM.
Figure 13.10 still contained hand-drawn illustrations of a network!
DROID-SLAM not only works on monocular settings, but has also been applied to stereo, RGBD and event cameras.
DPVO works like DROID-SLAM, but on patches instead of dense textures. Interesting for the soccer field? DPVO can run onboard.
MASTt3R in principle performs local 3D reconstruction, and is extended to MASt3R-SfM (3DV 2025) to do it globally. Would be interesting to see if we could feed last years rosbag into MASt3R-SfM. See OpenCV lesson, which is based on the MASt3R-SfM branch from Naver.
MUSt3R is no longer based on image-pairs, but on whole collections. The github code is also from Naver.
MASt3R-SLAM can perform monocular SLAM system at 15 FPS. Code can be found github (pytorch-based).
Everything in the installation instructions goes well, until pip3 install . inside build asmk. there seems to be a version clash with faiss (no attribute 'delete_GpuResourcesVector')
The asmk code is not explicit on its faiss version.
I did micromamba install -c pytorch faiss-gpu=1.11.0.
Tried different version (default is version 1.12), but the error remains: ERROR: faiss package not installed (install either faiss-cpu or faiss-gpu before installing this package.)..
There were two problems. First the numpy version (upgraded from 1.26.0 to 1.26.4) python3 -m pip install numpy==1.26.4, the other was the version of faiss-cpu (tried 1.12 and 1.11, it worked for 1.10): python3 -m pip install faiss-cpu==1.10
Now pip3 install . gave Successfully installed asmk-0.1.
Started the first demo of MUSt3R: python demo.py --weights pretrained-models/MUSt3R_512.pth --retrieval pretrained-models/MUSt3R_512_retrieval_trainingfree.pth --image_size 512 --viser --embed_viser
The result should become available at viser interface at http://127.0.0.1:8080/, the input should be specified at http://127.0.0.1:7860/. I tried to upload mazeweek1.mp4, but only the formats like h5 or mpg are allowed. Looked at the gradio documentation, not completly clear.
Converted the video to frames (1Hz) with ffmpeg -i mazeweek1.mp4 -vf fps=1 mazeweek1_frame%d.png. Resulted in 39 frames.
Result is not bad (default option keyframes), although if I interpret it right, only the green viewpoints are matched, and the black ones skipped:
Tried again, with mode sequence:linspace. Less outliers, less walls rendered:
Tried a third time, with mode sequence:local context. If you reduce the KeyFrame Interval to a minimum (#1), you get a nice result:
The retrieval mode failed because I had only downloaded the pth file, not the pkl file. With both files the system is much slower. Result is also much less:
Looking how to convert the ros-bag of the big-maze to frames, with this example code.
Looked up the type of topics in the rosbag with ros2 bag info rosbag2_2024_11_27-13_04_36_Correct/. The frames have topic /rae/right/image_raw/compressed.
Uploading no longer works, too many open files. Run the demo with --allow_local_files option.
Specif
The first 563 frames are Joey carrying the RAE towards, the maze. Moved those into ~/tmp/big_maze/skipped_frames. Run python demo.py --weights pretrained-models/MUSt3R_512.pth --retrieval pretrained-models/MUSt3R_512_retrieval_trainingfree.pth --image_size 512 --viser --embed_viser --allow_local_files. Started nicely with local-context and keyframe interval=1, until the error-message at 6%:
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 464.00 MiB. GPU 0 has a total capacity of 23.54 GiB of which 478.19 MiB is free. Including non-PyTorch memory, this process has 22.18 GiB memory in use. Of the allocated memory 21.13 GiB is allocated by PyTorch, and 584.59 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
Tried again, now with keyframes. I see no rendering, only a path. Had missed that also the Depth and Confidence are displayed in the display:
Firefox froze, but MUSt3R continued, until it also froze after 2500 frames.
Note that in the last frames Joey is carrying the RAE home, so removed also those frames.
There is a warning on Maximum batch size. Also note the warning:
Warning, cannot find cuda-compiled version of RoPE2D, using a slow pytorch version instead
Started again, first micromamba activate must3r in ~/git/must3r/, followed by python demo.py --weights pretrained-models/MUSt3R_512.pth --retrieval pretrained-models/MUSt3R_512_retrieval_trainingfree.pth --image_size 512 --viser --embed_viser --allow_local_files.
Tryingthe mode linspace. There are two options: number of memory images (default 50) and Render once (off).
Seems that first 49 keyframes are selected, before the 3723 extra images are rendered. Started with a straight trajectory, before the space was filled with additional frames. Got the following memory usage: Mem_r=12048 MB, Mem_a=11805 MB, Nmem=3360
Run the sequence again, now monitoring the process with nvtop (GPU usage) and btop. The process freezes when all cpu-memory (32Gb) is used.
Saw that halfway again there was a pickup of the robot, so selected 1574 frames. Now at 67% of the run 72% of the memory is used (mode: keyframes, local context size=0, subsample 2, max batch size=1)
When the point-cloud is prepared there is still 5% memory remaining.
Not much of point-cloud:
Should look tomorrow to RoPE2D and faiss-gpu, to use the cpu and its memory less.
September 30, 2025
Also did the Python3 library step from ugv_ws fork: python3 -m pip install -r requirements.txt on Rover #3.
Added export PATH=$PATH:$HOME/.local/bin to top of ~/.bashrc. Tested it with which f2py.
The software updater also wants to update several (ros-humble) packages. Agreed.
The script to run the sound only is on my Linux-partition of nb-dual. Switching.
Copied the play_robot_started.py directly from my Linux-partition to Rover #3. Followed the Waveshare Preparation instructions. Started crontab -e. Changed ~/ugv_jetson/ugv-env/bin/python ~/ugv_jetson/app.py to ~/ugv_jetson/ugv-env/bin/python ~/ugv_ws/play_robot_start.py
Tested the new crontab configuration with a restart.
No sound. The ugv.log shows an error: No PulseAudio daemon running
I see a lot of messages from the inference_feedback manager.
Yet, those are old messages. The actual error message is that audo_ctlr.py couldn't be found. Moved the play_robot_started.py to ugv_jetson/.
Now it works.
During both boots I saw: Failed to start dnsmasq: see 'systemctl status dnsmasq' for details. Checked. Fails because port 53 is already in use.
Tried the solution of stackexchange and configured /etc/systemd/resolved.conf and uncommented the line DNSStubListener=no. Now systemctl status dnsmasq indicates that dnsmasq is active. No local nameservers are found, so using nameservice 8.8.8.8#53.
Also checked systemctl status systemd-resolved. Also active, indicating that using system hostname 'ubuntu´.
Did the same for Rover #4, including checks.
Rover #2 had already the python libraries and .local/bin installed.
Rover #2 had the hotspot running. Copied the play_robot_started.py and tested with a reboot.
Time to go home.
September 29, 2025
Could check the obstacle avoidance code from the LiDAR from ROS example code from the
The ROS example code from the
Avular Origin-One robot has also a Aruco marker example. Like the way how the marker positions are stored in a dictonairy, including quarternions.
They made two fundamental low-level choices:
Use CycloneDDS to replace FastDDS, to provide more stable communication.
Use the Zenoh bridge to seperate the ROS2 network of the robot from the ROS2 network of your machine.
An attractive feature of Zenoh is the usage in a multirobot setting, because it allows to define a name-space per robot.
September 25, 2025
Labelled the Gamecontrollers #2 and #5, and mounted the dongles. Got AA-batteries for GameController #2.
On nb-dual native Ubuntu, did mv ~/ugv_ws ~/original_ugv_ws and followed the instructions from ugv_ws fork.
Installation went well, until . build_apriltag.sh. Got a number of warnings:
libwebp.so.6, needed by /usr/local/lib/libopencv_imgcodecs.so.3.4.4, not found
libIlmImf-2_3.so.24, needed by /usr/local/lib/libopencv_imgcodecs.so.3.4.4, not found
...
/usr/bin/ld: /usr/local/lib/libopencv_imgcodecs.so.3.4.4: undefined reference to `Imf_2_3::hasChromaticities(Imf_2_3::Header const&)'
A apt search imgcodecs shows that the package to be installed with sudo apt install libopencv-imgcodecs4.5d (no other candidates).
Yet, libopencv-imgcodecs4.5d is already the newest version.
There are several 3.4 libopencv libraries in /usr/local/lib, from Apr 16.
On November 1, 2021 I needed libopencv v3.4 for the DreamVU camera.
On July 30, 2021 I made manual symbolic links in /usr/local/lib.
Did in /usr/local/libsudo mv libopencv_* opencv3.4/.
Yet, the makefiles of apriltag still point to /usr/local/lib/libopencv_highgui.so.3.4.4.
Did colcon clean workspace -y. . build_apriltag.sh complains that install-diretories in in the environment variable AMENT_PREFIX_PATH no longer exist. Yet, /usr/local/share/OpenCV/OpenCVModules.cmake still try load /usr/local/lib/libopencv_core.so.3.4.4.
Did apt search opencv | grep 3.4, and found none installed 3.4 package: only libopencv-calib3d4.5d/jammy,now 4.5.4+dfsg-9ubuntu4 amd64 [installed,automatic]
The /usr/local/share/OpenCV/OpenCVModules.cmake only points to the core-module, without mentioning a version.
Apriltag remains a problem, but seems specific to my machine. Leave it for the moment.
Checked /usr/local/share/OpenCV In OpenCVConfig.cmake there is an explicit reference to version 3.4.4. Als in version and release an explict reference is made.
Moved the configuration to from /usr/local/share/OpenCV to /usr/local/share/OpenCV3.4.4/, /usr/local/share/OpenCV3.4.4/OpenCVModules.cmake was still found.
The UGV Rover #4 didn´t had a /usr/local/share/OpenCV, so moved the directory to /tmp/share/OpenCV3.4.4.. That solved the issue.
Rover #2 had another ip, so connected to Rover #4.
The commands from build_first were not included in the bashrc, so added them manually.
Followed Joystick control tutorial from the wiki, but serial wasn´t installed as python-package. Installing gave module 'serial' has no attribute 'Serial', so a version problem.
More people had this problem (stackoverflow). Should use pyserial, instead of serial.
That works, although I got an error in publish_imu_mag (KeyError on imu_raw_data["mz"]).
I had a comparible KeyError (on "ay") on September 17, 2025. Seems a temporary error, which should be protected.
Note that before there was a JSON decode errorL [ugv_bringup-3] JSON decode error: Extra data: line 1 column 114 (char 113) with line: {"T":1001,"L":0,"R":0,"ax":-526,"ay":-464,"az":8138,"gx":3,"gy":16,"gz":14,"mx":-307,"my":-103,"mz":1685,"odl":0}{"T":1001,"L":0,"R":0,"ax":-428,"ay":-518,"az":8082,"gx":-3,"gy":13,"gz":9,"mx":-311,"my":-45,"mz":1715,"odl":0,"odr":1,"v":1054} and [ugv_bringup-3] [base_ctrl.feedback_data] unexpected error: device reports readiness to read but returned no data (device disconnected or multiple access on port?) and
[ugv_bringup-3] JSON decode error: Expecting ',' delimiter: line 1 column 49 (char 48) with line: {"T":1001,"L":0,"R":0,"ax":-552,"ay":-490,"az":8:15,"gz":9,"mx":-331,"my":3,"mz":1745,"odl":0,"odr":1,"v":1054}
Feeling that the buffers are messed up, so try what happens after a reboot. Still the same error.
It goes wrong in the function feedback_data() in ugv_bringup.py. The decode is done with 'utf-8' characters, so should look if the first pack of ROS are executed. Checked Humble install and locale looks good.
Problem was that the Jupyter notebook was still running.
Also note that when logging in remotely, bashrc is not sourced.
With well recharged batteries, I got indeed a red led above the select button, and could drive the robot with the joystick.
The last message when executing ros2 launch ugv_bringup bringup_lidar.launch.py use_rviz:=false is:
[rf2o_laser_odometry_node-6] [INFO] [1758809468.615585976] [rf2o_laser_odometry]: Got first Laser Scan .... Configuring node
The last message when executing ros2 launch ugv_tools teleop_twist_joy.launch.py is:
[joy_node-1] [INFO] [1758809598.033177426] [joy_node]: Opened joystick: Xbox 360 Controller. deadzone: 0.050000
As suggested Preparation I commented the first part of the line.
Tried a reboot, yet although pulsaudio has started, there is no welcome message. Could be part of the ~/ugv_jetson/app.py
Checked the code in ~/ugv_jetson/app.py. Note that in the camera control-functions, there are three zoom commands (x1,x2,x3)
Those commands can be found at ~/ugv_jetson/cv_ctrl.py. There are also functions for following a (yellow) line.
September 24, 2025
Part III of SLAM Handbook promisses the thing that our Msc-students expect: spatial AI as the integration of recent advances in deep learning for spatial
understanding.
Surprisingly, the prelude is used to list the application areas where spatial AI could be used.
When working with Pollefeys, Martin Oswald also contributed to NICE-SLAM:
Neural Implicit Scalable Encoding for SLAM. Mentioned in the Deep Learning in Mapping section 5.4.7 (page 145, [1306]) as an example of the use of voxel grids. Also mentioned in section 14.2.4 (page 406) as an hybrid representation. One of the figures is reused on page 408.
First attempt of python3 examples/python/install_requirements.py fails on missing OPEN_BLAS_CORE_TYPE variable. Suggested is to use TYPE=ARMV8. That indeed works.
Yet, running python3 examples/python/DynamicCalibration/calibration_integration.py fails on Insufficient permisions to communicated with X_LINK_UNBOOTED device.
On August 27, 2025 I had the same error, but hello world worked.
On June 25, I installed depthai-2.30.0.0. The install_requirements notified that version 2.0.0 was required and already installed. Checked with python3 -m pip install depthai== which versions were available and installed with python3 -m pip install depthai==2.30.0.0
Note that I had to install blobconverter first (and add /home/jetson/.local/bin to PATH.
blocbconverter is downloading mobilenet-ssd for the demo.
As indicated in v2-vs-v3, there are no explicit XLink nodes anymore. Yet, they should be created automatically.
Did two things to get the hello_world demo working again. First killed the python process that was running the jupyter nodes. Next I executed the script suggested in this luxonis post
The suggested v2-vs-v3 videostream example didn't work. ColorCamera is depreciated, the socket-board (left / right) seems to be already called during the first call. Better try the show all camera's examples.
Yet the dynamic calibration examples, runs in sided the venv with v3.0.0.0:
The script claims that it has not enough coverage and not enough data (but no error).
Note that the README indicates that the calibrartion target should be well-lit, shaper and observed accross the entire FOV, without specifying the calibration target.
The depth calibration mentions an Charuco Board on a large screen.
Dynamic calibration just says to move the camera slowly around, with enough textured objects at multiple depths.
Instead tried python calibration_quality_dynamic.py which is more informative.
It starts with 0.0 / 100 [%] 2D Spatial Coverage and Data Acquired.
That increases to a 2D Spatial Coverage of 93.75 / 100 [%] and 100% Data without moving. No error, and starting Quality evaluation.
The rotation difference is reported in the first round as 0.18 deg, an achievable Mean Sampson error of 0.467px, a current Mean Sampson error of 1.076px. The theoretical Depth Error Difference is at 1m: 1.55%, 2m: 3.16%, 5m: 8.47%, 10m: 18.69%.
Directly after that the 2D SPatial coverage is back to 59% and the acquired data back to 11%.
In a 2nd measurement a Mean Samson error of 1.101px is reported (theoritical 10m: 28.7%)
In a 3rd measurement a Mean Samson error is increased to 1.129px is reported (theoritical 10m: 33.01%). So it getting worse.
In a 4th measurement a Mean Samson error is decreased to 1.118px, but the achievable Samson error increased to 0.503 ox, so (theoritical 10m: 51.37%). So it getting worse. What increases every turn is the rotation difference. It is now already 0.23 deg.
In the 5th measurements it increased to 0.39 deg, theoretical 10m: 180.10%
In the 6th measurements it decreased to 0.26 deg, theoretical 10m: 79.96%
In the 7th measurements it decreased to 0.17 deg, theoretical 10m: 13.35% (did I start moving?)
In the 8th measurements it increased again to 0.24 deg, theoretical 10m: 29.97%
In the 9th measurements it decreased again to 0.19 deg, theoretical 10m: 22.98% (did I start moving?)
In the 10th measurements it decreased further to 0.17 deg, theoretical 10m: 5.06% (no longer the sun in the camera, but pointing to the door?)
Also installed oakctl, but oakctl list gives no (OAK4) devices. There is oakctl adb option for communication over USB, but that also fails. No support for old devices.
The OPENBLAS_CORETYPE trick can also be found in deploy on Jetson page.
There is also a web-based visualiser, which requires chrome. Yet, I can try start the Visualizer, and connect via the chrome-browser from my laptop.
Nice task for tomorrow.
September 23, 2025
Another nice algorithm to try: RKO LIO. ROS based, platform indepent.
Chapter 10 of SLAM Handbook on Event-based SLAM indicates that the edge maps can be converted back to panoramic images with Poisson integration (ECCV 2024).
Because I read Chapter 11 already on Sept 8, I can continue tomorrow on page 333.
Read Chapter 7 of the Concise Introduction textbook from my Bookshelf. 2nd part zooms in on real-time strategies for ROS.
Also read Chapter 8 of the Concise Introduction textbook from my Bookshelf. Describes on the end how the process of creating a binary version of your package works.
Maybe I should make a pull request of all issues I fixed in the fork.
Trying again the build, but again failed on a segmentation error in rf2o_laser_odometry.
Also had the nvpmodel error again.
Run rf2o_laser_odometry direct together with the suggested--event-handlers console_direct+ --cmake-args -DCMAKE_VERBOSE_MAKEFILE=ON. The package is now build without problems. Also source install/setup.bash works.
Also run repair_nvpmodel.sh. No error anymore after reboot.
Ready to install UGV Rover #4. The mouse and keyboard didn'work with the USB-C, so used the pan-tilt USB-cable (together with my small USB-C hub (and USB-B/C addapter) to connect the input devices.
Switched off hotspot, connected to vislab_wifi.
Removed Mail from favorites, added terminal to favorites.
Started with sudo timedatectl set-timezone Europe/Amsterdam.
Moved the original ws to ~/original_ugv_ws. Did git clone https://github.com/IntelligentRoboticsLab/ugv_ws.git.
Next the command source repair_nvpmodel.sh.
Next source install_additional_ros_humble_packages.sh, which takes a few minutes to complete.
Next . build_first.sh. No problems.
Running . build_apriltag.sh without the cmake commands fails on missing opencv_core.
The command apt list --installed | grep opencv showed that version 4.5 was installed, while camek report that version 4.8 is claimed to be installed (but the library is missing).
Did a sudo apt upgrade, which updated 430 packages. Still same error.
The command apt list --installed | grep opencv shows several libopencv-*4.5d libraries, which doesn't match the installed libopencv-dev.
I am not the only one with this problem. Did sudo apt install libopencv-dev=4.5.4+dfsg-9ubuntu4 which installs 31 new packages. That seems to solve the issue.
Yet, running ros2 launch ugv_vision camera.launch.py use_rviz:=false shows that all other packages are gone, only the three apriltag packages can be found in ~/ugv_ws/install Strange, because I didn't do any clean. Doing a . build_common.sh again, to build the missing packages.
Trying the combination ros2 launch ugv_vision camera.launch.py use_rviz:=false with ros2 run ugv_vision apriltag_ctrl --ros-args --remap use_rviz:=false.
That failed, because of two reasons. First was the notebook code still running, claiming the camera.
Secondly I disconnected the pan-tilt camera, because I needed the USB-B. Luckely the USB-C now works again, so I could test. In the mean time I started ros2 run ugv_tools behavior_ctrl --ros-args --remap use_rviz:=false, but those three were enough to recognize the AprilTag. Note that the apriltag_ctrl opens a window to show the found tag, so you need a display (or commend that line out).
The vncmodel error appeared again, so did the repair again (was maybe overwritten by the apt install upgrade.
Note that all 6 desktop files are empty. Remove them?
This nvidia post indicates to mount the filesystem.img.
That image is already running, so don't need to be done.
Interesting, is the option to add the VNC server to autostart, as described in the README-vnc.txt.
Modified ugv_driver.py. Note that the low_battery.wav is not copied to the install directory.
Modified export_to_mat.py. The teb_local_planner has no install directory, so saved it in /tmp (instead of /home/albers).
In service_handler.py I already used to more elegant get_package_share_directory('ugv_nav'), which requires:
from ament_index_python.packages import get_package_share_directory # from ros-humble-ament-index-python package
Also modified map_modal.html template. Pointed to the share/ugv_nav/maps, although the original ~/.ros/maps seems more general.
Suddenly, the hotspot is on again. When login in directly, the bashrc is called.
Now, a simple git pull fails on server certificate verification failed. none CRLfile..
Looked at these stackoverflow suggestions. One suggestion was to check the time. date -R indicated that it was already evening, so installed ntp. Seems that the service is not restarted automatically.
Checked with timedatectl, but NTP service is n/a. Timezone is still set on Shanghai.
Setting sudo timedatectl set-timezone Europe/Amsterdam solved the git pull issue.
Ready to install UGV Rover #3.
Switched off hotspot, connected to vislab_wifi.
Removed Mail from favorites, added terminal to favorites.
Started with sudo timedatectl set-timezone Europe/Amsterdam.
Setting sudo timedatectl set-timezone Europe/Amsterdam solved the git pull issue.
Next I tried:
snap download snapd --revision=24724
sudo snap ack snapd_24724.assert
sudo snap install snapd_24724.snap
sudo snap refresh --hold snapd
Which gave snapd 2.68.5 installed and General refreshes of "snapd" held indefinitely.
Now I tried sudo apt install chromium-browser, which called the chromium snap.
Still, snap "chromium" gave a timeout on getting security profiles. Trying to do it a 2nd time.
Still goes wrong. With snap info chromium you can see different available versions.
Tried snap install --channel=latest/edge chromium. ... Still fails.
In the mean time, continued with the main install.
Tested the script. Seems to work fine. Only the package libopencv-dev is kept back.
Running the script a 2nd time fails. Many complaints that the AMENR_PREFIX_PATH doesn't exist. The real break is inside the rf20_laser_odometry, where cc1plus gets a kill signal.
colcon clean workspace also removes the build-directory. Systems seems to be frosen. Could be memory problem, also see the 10W throtle active.
Try shutdown and try again on Monday.
The Concise Introduction textbook can be found at Bookshelf.
Reading Chapter 7: Deep ROS.
For instance, a detail I didn't know: "Another important detail to keep in mind is that the order in which messages are processed depends on the order in which they were created within the node. If the subscriber to /topic_1 was created before the one for /topic_2, the polling point will first call the callback for /topic_2 and then for /topic_1. If we want the messages from one topic to be prioritized over others when both have messages, we should create the preferred topic last. In many applications, this does not make a significant difference, but in critical applications, this processing order can have an impact.".
Another new fact (for me): "The humanoid robot Nao, for instance, had a general-purpose computer in its head, but the functions that required real-time execution are handled by a microcontroller located in the robot's chest, which ran in real-time."
Checked the Table of Content of the first edition. Indeed these two last chapters are new.
Chapter 8 of SLAM Handbook on LiDAR starts with a Risley-prism-based LiDAR, which I didn't know. Benefit is that it produce denser point clouds over time.
The textbook point to this ICRA 2020 paper for background of Risley-based LiDAR.
The last mentioned 3D algorithm is LOAM (RSS 2014). From LOAM there are several githubs, like LeGO-LOAM (ROS1 Melodic), updated as LIO-SAM (Still ROS1 Noetic), although there is a ROS2 branch. The package SC-A-LOAM can work with several odometry algorithms (4y old, catkin based).
More recent implementations with code are DeLORA (ICRA 2021 - ROS1 based), PWCLO-Net (CVPR 2022) and RSLO.
Like how they represent LiDAR place recognition as separate subject. For instance the history of 3D local descriptors for RGB-D in the same way as SIFT or ORB, such as Viewpoint Feature Histogram (ICRA 2010) and CSHOT (ICIP 2011i - no code). See this Overview.
After that, ScanContext++ and RING++ used BEV transforms. Even more recent: OperlapNet and FRAME. FRAME (Field Robotics 2024), which is based on the fast GICP package, which is now replaced by small GICP (twice as fast)..
For long-term mapping, an anchor node is handy, which is used both in Visual SLAM as LiDAR SLAM. Visual SLAM already RAS 2013, for LiDAR SLAM as recent as ICRA 2022, paper with code (ROS1).
The chapter summarizes the main contribution of LiDAR Odometry as LOAM, with 4 improvements (Fast-LIO2, 2022 code, including LIvO2 version and LiDAR camera calibration ROS1-based, but with ROS2 fork, LIO-SAM 2020, KISS-ICP 2023, CT-ICP 2022)
Created 4 AprilTag 36h11 tags (#1 to #4) from arucogen.
The readme indicates that the tag should be the default tag size of 0.08. Configuration tags_36h11_filter.yaml has indeed that value. Not clear what is the unit, but apriltag.h should give more information. Looked into apriltag.h, but no units.
The tag with size of 80mm works, turn right command given. Only should set ROS_DOMAIN_ID, because I also get the images from UGRover #1.
When logging in via ssh, bashrc is not loaded. Strange, because I am using the bash shell.
Started in terminal #1 ros2 launch ugv_bringup bringup_lidar.launch.py use_rviz:=false.
Started in terminal #2 ros2 launch ugv_vision camera.launch.py use_rviz:=false
Started in terminal #3 ros2 run ugv_tools behavior_ctrl --ros-args --remap use_rviz:=false
Started in terminal #4 ros2 run ugv_vision apriltag_ctrl --ros-args --remap use_rviz:=false
The robot got one turn right command, but after that the apriltag_ctrl tried to open a display.
Made a version ros2 run ugv_vision apriltag_ctrl_no_show, which seems to work. Should only look carefully for the waits, because the behavior_ctrl keeps turning. Another minor change is to use the topic /image_rect
The script works, although it should include a driving forward to a certain distance, now it keeps tuning left/right between the two tags.
Note that the script is copied to install after a . build_common.sh (after modifying the entry_points in src/ugv_main/ugv_vision/setup.sh
The Handbook mentions two real-time capable methods as first VSLAM algorithms: CVPR 2000 and ICCV 2003. The latter (Andrew J. Davison's Real-time simultaneous localisation and
mapping with a single camera) I knew. The first was not cited by Andrew. Looks like a nice EKF implementation in Matlab. Short paper with method, no results.
The chapter starts with the camera model, as we do in the course. They refer to BabelCalib: A Universal Approach to Calibrating Central Cameras (ICCV 2021), a paper with MATLAB code. They not only cover Geometric Camera models, but also Photometric Models. Motion blur is mentioned, but no other suggestion is given than to use a global shutter camera.
I like Figure 7.2 (to be reused in the lectures), which gives the timeline of keypoint algorithms. The latast is MASt3R. The MASt3R method was published at ECCV 2024, and used in SLAM by Andrew J. Davidson in CVPR 2025 paper with code. Fully pytorch based. Also explained by Learn OpenCV.
As one of the first Deep Learning approaches, a predecessor of SuperPoint, LIFT was mentioned (ECCV 2016 paper with python code, mainly opencv and scipy dependent.
SuperPoint is used in DX-SLAM IROS 2020 paper with C++ code, OpenCV and Tensorflow based.
A catkin-based (5y old) ROS2 wrapper of DX-SLAM and Orb-SLAM2.
They don't end with MASt3R, but with D2-Net. This CVPR 2019 paper with pytorch code.
They summarize keypoint-based Visual SLAM with several methods, like Batch Optimization, Filtering-Based approaches, KeyFrame-Based approaches, and Factor Graphs approaches. The last one is the formal way, they like in Part I.
Most examples in this part fall back to ORB-SLAM.
They mention SfM and BA as golden standard, but many tricks like pose-only BA and local BA to get it working in real-time (running in seperate threads).
As alternative for the keypoint-based approach are the Direct Image Alignment, with as example LSD-SLAM and DSO. LSD-SLAM is from ECCV 2024 paper with ROS1 code. Cannot find a ROS2 implementation, although there is a No ROS implementation. DSO is published in PAMI 2017. Also ROS1 (fuerte) code.
Again no ROS2 implementation, next to RTMAP Nvidia's NVBLOX NAV2 plugin, which works only with depth-camera's.
Section 7.4.4 (Bundle Adjustment Revisited) is clear, BA has been studied over a century, but has two important shortcomings. Firstly it needs a suitable initialization. Secondly its computational and memory requirements can grow prohibitively large.
Power Bundle Adjustment promises to solve this. Published in ECCV 2024, paper with C++ code. No ROS implementation.
A monocamera version of ORB-SLAM is OKVIS2. arXiv 2022 paper with ROS2 code for a realsense camera. Note the calibration warning!
Another practical approach is a hybrid approach, mixing keypoints with direct VO / SLAM, as in ICRA 2021 paper without code.
For RGB-D SLAM the latest paper mentioned is from RSS 2015. Found an C++ implementation with explicitly no ROS bridge (relies on tight coupling between mapping and tracking).
More advanced methods will be discussed in Part III of the handbook. Continue tomorrow with page 224.
Would be a nice research/education project to implement those classic keypoint algorithms in ROS2.
Continue with ugv_ws github fork, but UGV Rover #2 complains that no buffer space is available.
Made a copy of the ugv_ws. Which package is so large? The new ugv_ws is 148 Kb. The ugv_tmp is 216 Kb.
Did a disk usage analysis. Only 43Gb of the available 248Gb is used. Inside /home/jetson the directory ~/ugv_jetson is the largest, with the jupyter-notebook code.
At root-level, /usr/localhost/*/snapshots/timeshift is the largest (9.6 Gb). From the installed software, /usr/lib/aarch64-linux-gnu is 2.9 Gb the largest, with 366 Kb in the nvidia section.
With the chrome browser killed, the system works again.
Started ros2 launch ugv_web_app bringup.launch.py host:=ip, and with the installed flask and executable scripts it seems to work. Note that /home/jetson/ugv_ws/src/ugv_else/vizanti/vizanti_server/public is used as public directory (shouldn't that be in install?)
Looking in Waveshare wiki for web-based control tutorial.
Also the default_layout.json is read from src instead of install. Maybe I shouldn't use the symbolic-link option in the build.
Yet, the webinterface seems to work, I get an empty web-interface.
Launching ros2 launch ugv_bringup bringup_lidar.launch.py use_rviz:=true fails, because package ldlinar is missing (and LDLIDAR is not set).
Added this package to the first_build script, together with the MODEL environment variables.
Now it works (after setting the frames to all with TF-button, and zooming in:
Could control the robot with the web-based Teleop (section 9.1 of tutorial.
Yet, in the terminal I see several JSON decode errors (Expecting property name in double quotes). Seems that it complains on additional return, because the line looks OK.
At the end the process dies on a keyerror when asking the linear acceleration.y with key "ay" from imu_raw_data.
Updated apriltab_build.sh, but fails because it hasn't the rights to install /usr/local/include/apriltag. Yet, colcon build --cmake-args -Wno-dev --packages-select apriltag apriltag_msgs apriltag_ros --executor sequential --symlink-install should also build apriltag.
No explicit information how to use apriltag in tutorials.
Instructions can be found in original readme: ros2 run ugv_vision apriltag_ctrl. Nothing happens! Waiting on camera?
Yet, ros2 launch ugv_vision camera.launch.py fails on No accelarated colorspace found from yuv422p to rgb24.
Same for ros2 run usb_cam usb_cam_node_exe, which claims that there is no default camera calibration in ~/.ros/camera_info/default_cam.yaml
On June 17 I coulld also do ros2 launch ugv_vision camera.launch.py on Rover #1.
There is a config/camera_info.yaml present in ugv_vision. Looked at usb_cam documentation.
Suggestions don't seem to work. Others have same issue with usb_cam package. Suggestion is to switch to camera_ros package. Documentation can be found here
That also gives an error: Camera in Acquired state. Failed to start camera.
The command v4l2-ctl --list-devices worked without an install of v4l-utils. Gave 4 input devices:
NVIDIA Tegra:
/dev/media0
USB Camera:
/dev/video0
/dev/video1
/dev/media1
Also sudo v4l2-ctl --device=/dev/video0 --all gave Device Caps: Video Capture.
Yet, ffplay /dev/video0 indicated that the device was busy. top showed that there was still a python-process running (the jupyter notebook?!).
Disabled it with according to section 1.2 of preparation.
The command ros2 run usb_cam usb_cam_node_exe works with ros2 run image_view image_view --ros-args --remap image:=/image_raw and ros2 run image_view image_view --ros-args --remap image:=/image_rect with ros2 launch ugv_vision camera.launch.py. The rectification looks good.
Running ros2 run ugv_vision apriltag_ctrl shows the non-rectified image, not clear what right,left,front,rear is expected. Anyway, apriltag seems to be set to tag36h11, while a tag41h12 is presented.
Same for ros2 run ugv_vision apriltag_track_0. Running ros2 launch ugv_vision apriltag_track.launch.py launches also an usb_cam_node_exe, so if a camera_node is still running it fails.
The rectivation complains that the the image_raw and camera_info are not synchronized, but that can be Rover #1 also being on.
Found a tag3611 (#8), so ros2 run ugv_vision apriltag_ctrl finds the Tag, including the location in the image. It also indicates that Action server not available:
That server can probably started up with ros2 run ugv_tools behavior_ctrl.
Nothing happens, probably waiting on ugv_driver. Tried ros2 doctor, which complains that Fail to call PackageCheck class functions.
Indeed, when starting the drivers with ros2 launch ugv_bringup bringup_lidar.launch.py use_rviz:=true and ros2 run ugv_vision apriltag_ctrl, the behavior_ctrl gives "Executing goal...", self.stop()
Looking into apriltag_ctrl.py. The tag36h11 #1 should give a "turn right" command, #2 gives "turn left", #3 gives "move forward", #4 gives "move back", any other tag36h11 (including #8) would give "stop".
September 16, 2025
Cyrill Stachniss published a LiDAR-only based odometry paper, with github code.
First applications from certifiable algorithms were SfM algorithms published in CV conferences. Seems to be paper without code.
A certifiable algorithm which can handle outliers is STRIDE.
Should also check KISS Matcher, which can handle registrations from object to Map level, based on ROS2 Humble.
Note on page 180 of the SLAM Handbook that Visual SLAM is not-yet attacked with certifiable algorithms, nor the inclusion of IMU measurements!
Also read the prelude of Part II, so I can start with Visual SLAM at page 193.
Continue with my progress of September 12 on the UGV #2.
The command colcon build --cmake-args -Wno-dev --packages-select cartographer costmap_converter_msgs explore_lite fails because the log-file is owned by root, instead of jetson.
Checked for other problems. Another directory owned by root is /home/jetson/.docker. Inside /home/jetson/ugv_ws three directories have this problem: install, build and log.
Just chown -R changes only the owner, not the group. sudo chown jetson:jetson -R build works. Did this for four directories.'
Now the build fails on the CMakeCache. The suggestion was to rerun cmake with a different source directory.
Checked the files in src/ugv_else/cartographer/*. No explicit reference to /home/ws was makde.
Followed ros2-workspace-clean suggestion and installed sudo apt install python3-colcon-clean
Install failed because the hotspot is still on. Should switch the automatic start of the hotspot off.
Finally found my first reference in the ~/ugv_ws/src/ugv_else of /home/ws: in ugv_ws/src/ugv_else/vizanti/vizanti_server/scripts/service_handler.py.
Created IRL fork. Updated the readme. Original contained many instructions, including those that could better be described in the corresponding ugv-package. Also saw the equivalent of all instructions for Gazebo, although some Gazebo models had to be downloaded and installed first.
The vizanti-server is dependent on the ugv_main packages, so should be installed after ugv_main.
The . first_build.sh script works, except that command register-python-argcomplete is not found.
Modified the vizanti_server service_handler.py, to use get_package_share_directory. sudo apt install ros-humble-ament-index-python was not needed, that was already implicitly installed.
The command register-python-argcomplete is not part of python3-colcon-argcomplete. Should follow the instruction from the python-package argcomplete itself. First pip install argcomplete, followed by activate-global-python-argcomplete.
If I read the argcomplete documentation carefully, this should not be neeeded because bash already supports global completion.
Next script with depends on /home/ws is build_apriltag.sh, although save_2d_cartographer_map.sh also depends.
First see if my code from the vizanti_server works. I think that this can be tested with ros2 launch ugv_web_app bringup.launch.py host:=ip.
That fails on No executable rosapi_launch.py found in libexec directory /home/jetson/ugv_ws/install/vizanti_server/lib/vizanti_server. That is correct, because that file can be found in ugv_ws/src/ugv_else/vizanti/vizanti_server/scripts, but is not copied to the install. The ugv_web_app/launch/bringup.launch.py just calls the launch/vizanti_server.launch.py. Indeed, there the rosapi_launch.py is called as executable. Yet, the CMakeLists.txt specifies that three scripts should be copied to lib/vizanti_server. Not clear why that is not done. Trying make list_install_components in build/vizanti_server, but this gives "Unspecified". Did make install, which indicates that all symbolic links are already in place. Indeed, I see the lib/rosapi_launch.py as symbolic link to script/rosapi_launch.py.
Problem was that the three scripts were not executable. Doing chmod +x solved that.
Script starts, but get warning that the address of the vizanti_rosbridge is already in use.
Should check tomorrow this Waveshare Web tool tutorial. Note that the script server.py fails on missing module flask, which was in requirements. The requested python3 -m pip install -r requirements installed several packages, including opencv and numpy. Note that the installation complains that /home/jetson/.local/bin is not in the path. Added that PATH to the Readme.md. To be tested tomorrow.
September 15, 2025
Continued with Chapter 6 of the SLAM Handbook, which is the capstone of the Foundations. It promisses a certified optimal solution, with a bound on the solution and an indication when no solution is found.
Chapter 5 of the SLAM Handbook is about Dense Map Representations. For 3D representations there are several methods to subsample and store the non-redundant points. Yet, to convert such point-cloud in other representations, such Poisson surface reconstruction or a Signed Distance Function (SDF), the viewpoint is needed, information which wasn't stored. Surfels and Gaussian Splats allow to store viewpoint information.
Would be nice to extend Assignment 3, and convert the 3D point-clouds to voxels and/or surfels, before reducing them to a 2D occupancy grid.
On page 138, TSDF is mentioned as popular method to do it on a live sensor stream. No reference is given, although I see references as old as Nießner et al. (2013). A recent implemention is described here (2020).
Yet, a package from ETHZ-ASL is VoxBlox, with a tight ROS integration, described in this ICRA paper (2017).
VoxBlox is mentioned on the next page, together with an estimated Euclidean Signed Distance Field (ESDF). FIESTA updates an ESDF map directy from a occupancy map.
FIESTA is ROS 1 based, not maintained for 6 years.
For our navigation in the maze the Hilbert Map of Figure 5.11 look promissing, but I have seen no ROS2 implementation (yet). A recent ICRA publication was here (2019).
On page 146 one looks foreward to deep learning based methods like Dust3r.
The other UGV Rovers have arrived. Unboxed Rover #2.
As part of the kit is SD-card to USB-converter, but it seems that Jetsin Orin has only a TF card slot, no SD card slot. The Orin Development kit comes also with a free 64Gb SD-card, but it seems that this version is with a eMMC.
Connected a display to the display-port and a keyboard / mouse to the USC-C connector, as done on (Feb 6). The robot nicely reports by voice that it is operational. Screen starts with a system program detected, and an update that are ready to be performed. The problem is the nvpmodel, which I solved earlier (July 17).
Switched off the hotspot, and connected to vislab_wifi.
Started with a sudo apt-get update THere are 455 packages to be upgraded.
Did snap install chromium. Snap starts with updating security profiles. Connection time out. 2nd time snap tries to connect all eligible plugins. After that core and chromium are installed.
Alternative is to fetch the debian installation package directly from Google, as described ask-ubuntu. Doesn't work, not available for arm64. Instead tried sudo apt install chromium-browser, which again trying to install chromium via snap.
chrome installation still fails. Going to do an upgrade.
The rover is running Ubuntu 22.04.4 LTS (jammy) (checked with lsb_release -a).
The rover is running nvidia-jetpack 6.0+b87 (checked with sudo apt-cache show nvidia-jetpack)
The upgrade will downgrade 4 nvidia packages related with the nvidia-container-toolkit.
One of the upgraded packages is linux-firmware (from ubuntu3.30 to ubuntu3.39)
I am not the only one with this issue, seems to be part of a recent snap version which enforces apparmor to be set.
Trying now the trick from rsazid99:
snap download snapd --revision=24724
sudo snap ack snapd_24724.assert
sudo snap install snapd_24724.snap
sudo snap refresh --hold snapd
Got chrome working, by going with Files to /snap/chromium/3247/usr/lib/chromium-browser and starting chrome.
Added a symbolic link to chrome in ~/bin. The home-directory has both an empty ~/.bashrc and ~/.profile.
Looking into how the rovers are prepared by waveshare. One of the commands is jetson-containers build --name=ugv_jetson_ros2_humble opencv:cuda ros:humble-desktop. The jetson-container comes from this github repository. Note that there is a jp6 branch.
The install script is run, which installs a python3-venv. Inside the activated venv the requirements, which is quite short (mainly pyyaml).
Continue with the missing dependencies as indicated in my draft UGV Rover manual.
The ros-apt-source command didn't work, because ' was replaced with `. Setting the option \lstset{upquote=true} worked.
Made a source ~/ugv_ws/dependencies.sh script which installs all the required ros-humble packages.
Last package is gazebo, which is maybe not needed.
The first build colcon build --cmake-args -Wno-dev --packages-select cartographer
costmap_converter_msgs explore_lite fails on permission denied for 'log/build_2025*'
September 11, 2025
Chapter 4 of the SLAM Handbook starts with the claim that deep-learning is very usefull in the SLAM front-end, while geometry-based techniques persist as essential in the SLAM back-end.
The combination could be quite powerfull, when the deep-learning is not used as just a "plugin", but that the SLAM backend is used to give feedback to train the front-end.
They point to several recent examples, including a SfM example from 2020 (paper with code).
To do this two loss-function should be learned at the same time.
For Visual SLAM with Learned Features the upper-level loss is the feature matching error and the lower-level loss the reprojection error of Bundle Adjustment.
For Pose Graph Optimalization of the odometry drift both the upper and lower-level loss can be the pose-graph error.
For differentation, they point to e.g. PyPose, a impressive library with several tutorials, such as the IMU Corrector tutorial.
Section 4.4 gives some examples tackled with PyPose, including the combination of LieTensors with quaternions.
Wang-Chen provided two Jupyter notebooks with PyPose code-snippets, for section 4.4.1 and 4.4.2.
Continue at page 120.
September 10, 2025
Chapter 3 of the SLAM Handbook focuses on the sensitivity on outliers both on the front-end and back-end. Although still mainly based on GTSAM, the different outlier rejection methods are demonstrated on three datasets. It is astonishing how 'easy' the modern SubT dataset is compared to the classic Victoria Park dataset. The artificial M3500 dataset is also interesting, because it shows completly other sensitivities than the two real ones.
It is also astonishing to see how two outliers in the odometry front-end can put the algorithms astray which depend on a reasonable good initial update.
Looking for an implementation of FSAD-Net, but only found from the same institute DS-TFN, which is based on CMAp-Net and IMAP-Net.
Davide Scaramuzza showed at 2/3 part of his lab, which is actually quite small (35 m^2)
Working on the seminar. Should look again at the cpmr_apb code on github. The first lab has two nodes (populate.py and depopulate.py).
The populate.py spawns three cans into the Gazebo world.
The gazebo.launch.py reads the blockrobot.urdf, used that to start a robot_state_publisher that publish it as a robot_description, and calls from gazebo_ros package the executable spawn_entity.py with as arguments the /robot_description topic and giving a name to the model with argument -entity block_robot
For Seminar 1, I looked up the release notes of JetPack 6.0.
The Nvidia Development roadmap indicates that Jetpack 6.2.1 should already be released, together wth Jetpack 7.0 for Ubuntu 24.04.
Chapter 2 directly goes into Manifolds and Lie algebra, but I like Fig 2.2 and the introduction of the wedge and vee operator.
In section 2.1.3 they give as example of Lie Group Optimization the lineralization of the measurement function h() of seeing a landmark in the camera frame, to finding the 3D transformation that corresponds with that observation, which is the perspective-n-point (PNP) problem.
Section 2.2 is about Continues-Time Trajectories, which are particular usefull wiht high-rate measurements like IMU (so relevant for Julian).
In section 2.2.2 they swap a limited number of basis functions (defining splines) for a kernel function. By using Gaussian estimates of the transition function they can keep the inverse kernel matrix sparse. The Markov condition of the state description keeps the inverse kernel matrix block-tridiagonal.
The tools described in this chapter will be used in the following chapters, so the chapter ends with a reassuring keep reading.
It is a paper with code, and links to 7 datasets. Three datasets are real, consisting of images recorded with both high-speed and low-speed shutter cameras. The ReLoBlur dataset looks most promising, because it contains mixing effects of moving objects and backgrounds.
For autonomous driving, the introduction points to Fsad-net for dehazing.
On the RealBlur-J dataset, Uformer is clearly the winner.
From the efficiency side, GhostDeblurGAN was mentioned for its short inference time (real-time according to Table 1). Also HINet and BANet had were positivly mentioned for their short inference (in Table 1).
Trying the code, but no dependencies, and input- and output directories have to be created manually.
Trying python3 evaluate_RealBlur_J.py. Created ./out/Our_realblur_J_results. Followed the link to RealBlur dataset. This has the also the requirements for DeblurGAN-v2 (Python3.6.3, cuda9.0).
The RealBlur dataset is 12 Gb.
Checked the requirements with pip3 show torch. Installed version is 2.7.0, requirement is 1.0.1. At the jetson the installed version is 2.5.0.
torchvision was not installed, so show give no information. Instead installed pip3 install pip-versions, and checked pip-versions list torchvision which gave version 0.1.6 to 0.23.0. At the jetson the installed version is 0.20.0. Version 0.2.2 was required for DeblurGANv2.
pretrainedmodels was not installed on the jetson. Version 0.1.0 until 0.7.4 are available, which is the required version for DeblurGANv2.
Also opencv-python-headless was not installed on the jetson. Available are 3.4.10.37 till 4.12.0.88. The required 4.2.0.32 version of DeblurGANv2 is not available, there is gap between version 3.4.18.65 and 4.3.0.38.
Next non-installed is joblib. On the jetson v0.3.2dev to v1.5.2 are available. The required v0.14.1 is there.
Next non-installed is albumentations. On the jetson 0.0.0 to 2.0.8 are available, including the required version 0.4.3.
Next non-installed is scikit-image. On the jetson 0.7.2 to 0.25.2 are available, including the required 0.17.2
Next non-installed package is tqdm. On the jetson 1.0 to 4.67.1 are available, including the required 4.19.9
Next non-installed package is glog. On the jetson the required 0.3.1 is the latest version.
Next non-installed package is tensorboardX. On the jetson 0.6.9 to 2.6.4 are available, including the required version 2.0
Next non-installed package is fire. On the jetson 0.1.0 to 0.7.1 are availeable, including the required version 0.2.1
Next non-installed package is torchsummary. On the jetson the required 1.5.1 is the latest version.
Tried on ws9 python3 predict.py. Failed on missing module fire. Also had to install tqdm and albumentations. albumentations-0.4.3 also installed imgaug-0.2.6
Continued on ws9 with python3 predict.py. Missing module pretrainedmodels-0.7.4 also installed munch-4.0.0 nvidia-cublas-cu12-12.8.4.1 nvidia-cuda-cupti-cu12-12.8.90 nvidia-cuda-nvrtc-cu12-12.8.93 nvidia-cuda-runtime-cu12-12.8.90 nvidia-cudnn-cu12-9.10.2.21 nvidia-cufft-cu12-11.3.3.83 nvidia-cufile-cu12-1.13.1.3 nvidia-curand-cu12-10.3.9.90 nvidia-cusolver-cu12-11.7.3.90 nvidia-cusparse-cu12-12.5.8.93 nvidia-cusparselt-cu12-0.7.1 nvidia-nccl-cu12-2.27.3 nvidia-nvjitlink-cu12-12.8.93 nvidia-nvtx-cu12-12.8.90 torch-2.8.0 torchvision-0.23.0 triton-3.4.0
Last missing package for the predict is torchsummary-1.5.1.
Executed python3 predict.py ~/tmp/preview_with_bounding_box.jpg, which fails on missing pretrained weights.
Predict loads per default config/config_RealBlurJ_bsd_gopro_pretrain_ragan-ls.yaml. The used weights_path is provided_model/fpn_inception.h5.
Would be interesting to see if the algorithm could deblur:
Yet, although both config as with weights exists, still python3 predict.py --weights_path provided_model/fpn_inception.h5 ~/tmp/apriltag_ctrl_result-1757084064-860794635.png fails:
File "/home/arnoud/git/DeblurGANv2/predict.py", line 86, in main
predictor = Predictor(weights_path=weights_path)
File "/home/arnoud/git/DeblurGANv2/predict.py", line 19, in __init__
config = yaml.load(cfg)
The trick was to do config = yaml.load(cfg, Loader=yaml.Loader). Now I get a result for provided_model/fpn_inception.h5. Optical inspection shows that the whiteboard at the left has less blur. The april_tag has not improved much:
In models/fpn_mobilenet.py a call is made for torch.load('mobilenetv2.pth.tar'), which fails. For the inception an automatic dowload from "http://data.lip6.fr/cadene/pretrainedmodels/inceptionresnetv2-520b38e4.pth" was made.
Difference seems to be from pretrainedmodels import inceptionresnetv2 vs from models.mobilenet_v2 import MobileNetV2.
Should look at how to load the state_dict from this post
Yet, a load fails. With weights_only=True it fails on Unpickler error: Unsupported operand 10, with weights_only=False it fails on UnpicklingError: invalid load key, '\x0a'.
Instead loading mobilenet_v2-b0353104.pth gives a layer mismatch.
Mobilenet by default starts pretrained, so by setting the explicit pretrained-load to false the code works:
Result is not better than the inception result, maybe even worse. Whiteboard is still better than the original.
Trying different settings for the inception model in the yaml, such as d_name resp. double_gan, multi_scale, patch_gan, no_gan. I don't see any difference:
Trying other backbones. There are several options, yet predict_resnet.py still tries to load provided_model/fpn_inception.h5, which is a mismatch.
Tried to build predict_inception_v4.py, which failed on 'InceptionV4' object has no attribute 'conv2d_1a'. Same is true for predict_inception_v3.py
Checked the results with
the default AprilTag implementation. No AprilTag was found, not in the original, nor in the deblurred image.
Looked at Uformer, but that has only a test, not an predict or inference instruction.
This recent implementation FourierDiff is better documented.
Not using the conda environment, the main.py fails on cannot import name '_accumulate' from 'torch._utils'. That is version issue (implemented until v2.2.0 of pytorch, while I use v2.8.0).
Switching resulted on installing several cuda-packages: vidia-cublas-cu12-12.1.3.1 nvidia-cuda-cupti-cu12-12.1.105 nvidia-cuda-nvrtc-cu12-12.1.105 nvidia-cuda-runtime-cu12-12.1.105 nvidia-cudnn-cu12-8.9.2.26 nvidia-cufft-cu12-11.0.2.54 nvidia-curand-cu12-10.3.2.106 nvidia-cusolver-cu12-11.4.5.107 nvidia-cusparse-cu12-12.1.0.106 nvidia-nccl-cu12-2.19.3 nvidia-nvtx-cu12-12.1.105 torch-2.2.0 triton-2.2.0.
Yet, the used implementation is even older: it now fails on module 'torch.library' has no attribute 'register_fake.
That seems to part of torch v2.4, so installed nvidia-cudnn-cu12-9.1.0.70 nvidia-nccl-cu12-2.20.5 torch-2.4.1 triton-3.0.0
That helps, it now fails on RuntimeError: operator torchvision::nms I am using version 0.23.0. They were using version 0.12.0
Went halfway an installed version 0.18.1, which also downgraded torch again to v2.3.1: nvidia-cudnn-cu12-8.9.2.26 torch-2.3.1 torchvision-0.18.1 triton-2.3.1
Back to cannot import name '_accumulate' from 'torch._utils'
Going all the way and installing torchvision-0.12.0 which also installed torch-1.11.0
The packages now load, got RuntimeError: CUDA error: no kernel image is available for execution on the device. This seems to originate from The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70. My RTX 4090 with CUDA capability has sm_89, which seems to much.
Simson rule, try to install torchvision-0.15.2, which also installs cmake-4.1.0 lit-18.1.8 nvidia-cublas-cu11-11.10.3.66 nvidia-cuda-cupti-cu11-11.7.101 nvidia-cuda-nvrtc-cu11-11.7.99 nvidia-cuda-runtime-cu11-11.7.99 nvidia-cudnn-cu11-8.5.0.96 nvidia-cufft-cu11-10.9.0.58 nvidia-curand-cu11-10.2.10.91 nvidia-cusolver-cu11-11.4.0.1 nvidia-cusparse-cu11-11.7.4.91 nvidia-nccl-cu11-2.14.3 nvidia-nvtx-cu11-11.7.91 torch-2.0.1 torchvision-0.15.2 triton-2.0.0.
Now I get: INFO - main.py - 2025-09-09 16:45:21,443 - Using device: cuda.
Downloading something big (2.21G).
After the download the inference is not too slow. Result for low-light samples is impressive, the motion-blur of our test-image is less impressive:
The AprilTag is still not recognized.
September 8, 2025
Because of Julian Gallas proposal, I read Chapter 11 (Inertial Odometry for SLAM) of the SLAM Handbook.
The preintegration selects integrated IMU factors inbetween Image keyframes:
Looking for the code. SVO Pro is from the same year, combining VIO with VI-SLAM, but not the manifold approach.
As state-of-the-art VIO algorithms ORB-SLAM, DSV-IO, VINS-Mono, OpenVINS, Kimera, BASALT and DM-VIO are mentioned.
Should check some of the Inertial-Only Odometry algorithms mentioned on page 331.
For Julian the Edge algorithms on page 332 are interesting.
Started with the historical notes from Chapter 1.
They point to optimizing the trajectory with PoseSLAM or Smoothing and Mapping (SAM) (2006). Frank Dellaert presents SAM as a Least Square Problem.
I like figure 1.4 from the SLAM Handbook.
Also nice on page 29 is the suggestion to combine equation (1.15) and (1.16) when both control input u_t and odometry measurement o_t is known.
On page 31, they indicate that by eliminating the covariance from the Jacobian and prediction error, the units of the measurements (length, angles) are removed, which allows to combine them in a single cost function.
For non-linear optimization, they introduce DogLeg as intermediate between Steepest Descent and Gauss-Newton algorithm, like the Levenberg-Marquardt algorithm but without rejected updates by explicitly tracking the trust region boundary.
Checked Bishop's Pattern Recognition, who only covers Gradient Descent, and points to other non-linear optimalization techniques to a book never published with Ian Nabney.
Looking into robot_description_publisher.launch.py script. The script both starts a robot_description-node and makes a ros_gz_sim create -topic /robot_description call.
Made a version ~/tmp/robot_description_publisher.launch.py which doesn't launch the robot_state_publisher, but uses the robot_description to launch a robot in the world.
In ~/ugv_ws/src/ugv_main/ugv_gazebo/launch/bringup/robot_state_publisher.launch.py only the robot-state node is started which publishes the robot_description of the ugv_rover. Combined the should work.
First started ros2 launch ugv_gazebo robot_state_publisher.launch.py. This start two nodes: /joint_state_publisher and /robot_state_publisher. The topic /robot_description is now visible.
Made a symbolic link from /opt/ros/humble/share/ros_gz_sim_demos/launch/spawn_from_robot_description.launch.py to ~/tmp/spawn_from_robot_description.launch.py. Still, a number of things go wrong. Not all TFs are defined:
Next, the meshes are not loaded, the URI are not found. For example:
[ign gazebo-1] [Err] [SystemPaths.cc:378] Unable to find file with URI [model://ugv_description/meshes/ugv_rover/base_link.stl]
Extended export IGN_GAZEBO_RESOURCE_PATH=/opt/ros/humble/share:/home/arnoud/ugv_ws/install/ugv_description/share/. That solves the Gazebo part: ros2 launch ros_gz_sim_demos spawn_from_robot_description.launch.py has now the ugv_rover displayed in Gazebo (and no warnings), instead the INFO:
[create-3] [INFO] [1757073678.522566814] [ros_gz_sim]: Requesting list of world names.
[create-3] [INFO] [1757073678.921602212] [ros_gz_sim]: Waiting messages on topic [/robot_description].
[create-3] [INFO] [1757073678.932812465] [ros_gz_sim]: Requested creation of entity.
[create-3] [INFO] [1757073678.932823080] [ros_gz_sim]: OK creation of entity.
There are now two additional nodes running: /rviz and /transform_listener
The current TF-tree has as root the base_footprint, which carries the base_link, which carries pt_base_link, 3d_camera_link, base_imu_link, base_lidar_link. That the four wheel_link's are missing I understand, that the pt_camera_link is not coupled to the pt_base_link is strange. Yet, this are all the dynamic links.
Note that there was already ros2 launch ugv_gazebo spawn_ugv.launch.py.
Tried ros2 launch gazebo_ros gzserver.launch.py world:=ugv_gazebo/worlds/ugv_world.world. No errors, but nothing to see yet.
Next is ros2 launch gazebo_ros gzclient.launch.py, which brings up a Window 'Gazebo not responding'
Extended export IGN_GAZEBO_RESOURCE_PATH=/opt/ros/humble/share:/home/arnoud/ugv_ws/install/ugv_description/share/:/home/arnoud/install/ugv_gazebo/share/. Still, the ugv_world could not be found.
Directly called ruby /usr/bin/ign gazebo -r /home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world --force-version 6. Now, the world could be found, but receive the error message Unable to find uri[model://ground_plane] again.
September 4, 2025
Used ros2 doctor, which indicates that several (rviz) packages have new versions.
Also robot_localization and apriltag_ros have new versions.
Also, it sees that several (ugv_rover) topics have subscribers without publishers and vice versa.
The outdated versions don't pop up with sudo apt upgrade. Tried instead pip list -o.
Did pip install xacro --upgrade. Upgrades succeeds, yet not visible from ros2 doctor.
The depth-image demo ros2 launch ros_gz_sim_demos image_bridge.launch.py image_topic:=/depth_camera works fine.
The equivalent ros2 launch ros_gz_sim_demos depth_camera.launch.py doesn't work. The choose a world windows shows up, so it looks that the world cannot be found. The bridge seems to be set up fine:
parameter_bridge-2] [INFO] [1756979694.078910720] [ros_gz_bridge]: Creating ROS->GZ Bridge: [/depth_camera (sensor_msgs/msg/Image) -> /depth_camera (gz.msgs.Image)] (Lazy 0)
.
The GPU-lidar demo ros2 launch ros_gz_sim_demos gpu_lidar_bridge.launch.py sort of works. Rviz gives an error, because it uses the wrong frame. Yet, when switching to map nothing is displayed anymore. Yet, I receive many warnings:
[rviz2-3] [INFO] [1756984073.412641424] [rviz]: Message Filter dropping message: frame 'model_with_lidar/link/gpu_lidar' at time 14.600 for reason 'discarding message because the queue is full'
.
Second way fails in the same way, without world to start with. The first script starts with ros_gz_sim/worlds/gpu_lidar_sensor.sdf, in the second this is commented out!
The actuall call to start the Gazebo simulation is ruby /usr/bin/ign gazebo -r gpu_lidar_sensor.sdf --force-version 6. Still, Rviz fails because no frame, and no additional panels. Also the rviz-configuration is commmented out. There is quite some difference between ../rviz/gpu_lidar_bridge.rviz and ../rviz/gpu_lidar.rviz
Now I get a RVIZ with a LaserScan and PointClound2 panel, yet still with an non-existent model_with_lidar/link/gpu_lidar (no other frames). I switched to ROS_DOMAIN_ID=42 to make sure that I don't be distracted by the real ugv_rover.
The ros2 doctor no longer complains on missing publish/subscribe combinations. But also no complaints on missing TF, while none are published.
Yet, the bridge version also has no TF, but shows the LaserScans. The non-bridge version shows a warning:
[parameter_bridge-2] [INFO] [1756986688.171719229] [ros_gz_bridge]: Creating GZ->ROS Bridge: [/lidar (gz.msgs.LaserScan/) -> /lidar (sensor_msgs/msg/LaserScan)] (Lazy 0)
[parameter_bridge-2] [WARN] [1756986688.171824490] [ros_gz_bridge]: Failed to create a bridge for topic [/lidar] with ROS2 type [sensor_msgs/msg/LaserScan] to topic [/lidar] with Gazebo Transport type [gz.msgs.LaserScan/]
According to ROS Gazebo demos only the point-cloud conversion is different, the LaserScan is parameterized via the ros_bridge. Yet, the parameters in the 2nd script contained a start- en end-'/'. Without this '/' the 2nd script works, althoug the point-cloud-dedicated conversion is not tested. The script indicates that a gpu_lidar.sdf inside ros_gz_point_cloud/ is needed to fix this:
Note that the environment the lidar-model is launched in is different from the one shown in ROS Gazebo demos, in the script the playground is used. The lidar is not mounted on a moving platform:
The package ros_gz_point_cloud exists, with gpu_lidar.sdf in examples. In examples there is also a depth_camera.sdf and rgbd_camera.sdf
In /opt/ros/humble/lib there is the plugins ros_gz_bridge/parameter_bridge and ros_gz_image/image_bridge, but no ros_gz_point_cloud/.
When I do ign gazebo -r ~/tmp/gpu_lidar.sdf I get:
[Err] [SystemLoader.cc:94] Failed to load system plugin [RosGzPointCloud] : couldn't find shared library.
Yet, this is a known issue. Note that this gpu_lidar.sdf world has the three objects from the demo page.
The script ros2 launch ros_gz_sim_demos imu.launch.py works, although it gives a rqt_topic plugin. If I start rviz2, and select the IMU or imu-plugin, I get the warnings:
[INFO] [1756991321.468821299] [rviz]: Message Filter dropping message: frame 'sensors_box/link/imu' at time 114.420 for reason 'discarding message because the queue is full'
Same for the MagneticField
Next trying ros2 launch ros_gz_sim_demos navsat.launch.py.
Starts well:
[ign gazebo-1] [Dbg] [gz.cc:161] Subscribing to [/gazebo/starting_world].
[ign gazebo-1] [Dbg] [gz.cc:163] Waiting for a world to be set from the GUI...
[ign gazebo-1] [Msg] Received world [spherical_coordinates.sdf] from the GUI.
[ign gazebo-1] [Dbg] [gz.cc:167] Unsubscribing from [/gazebo/starting_world].
[ign gazebo-1] [Msg] Ignition Gazebo Server v6.16.0
[ign gazebo-1] [Msg] Loading SDF world file[/usr/share/ignition/ignition-gazebo6/worlds/spherical_coordinates.sdf].
[ign gazebo-1] [Msg] Serving entity system service on [/entity/system/add]
[ign gazebo-1] [Dbg] [SystemManager.cc:70] Loaded system [ignition::gazebo::systems::NavSat] for entity [1]
Next step is defining some services:
[ign gazebo-1] [Msg] Create service on [/world/spherical_coordinates/create]
[ign gazebo-1] [Msg] Remove service on [/world/spherical_coordinates/remove]
[ign gazebo-1] [Msg] Pose service on [/world/spherical_coordinates/set_pose]
[ign gazebo-1] [Msg] Pose service on [/world/spherical_coordinates/set_pose_vector]
[ign gazebo-1] [Msg] Light configuration service on [/world/spherical_coordinates/light_config]
[ign gazebo-1] [Msg] Physics service on [/world/spherical_coordinates/set_physics]
[ign gazebo-1] [Msg] SphericalCoordinates service on [/world/spherical_coordinates/set_spherical_coordinates]
[ign gazebo-1] [Msg] Enable collision service on [/world/spherical_coordinates/enable_collision]
[ign gazebo-1] [Msg] Disable collision service on [/world/spherical_coordinates/disable_collision]
[ign gazebo-1] [Msg] Material service on [/world/spherical_coordinates/visual_config]
[ign gazebo-1] [Msg] Material service on [/world/spherical_coordinates/wheel_slip]
Several plugins are loaded, including at the end the NavSatMap:
[ign gazebo-1] [GUI] [Dbg] [Application.cc:426] Loading plugin [NavSatMap]
[ign gazebo-1] [GUI] [Msg] Added plugin [NavSat Map] to main window
[ign gazebo-1] [GUI] [Msg] Loaded plugin [NavSatMap] from path [/usr/lib/x86_64-linux-gnu/ign-gui-6/plugins/libNavSatMap.so]
Gazebo freezes / crashes while two warnings are given:
[ign gazebo-1] [Wrn] [Component.hh:144] Trying to serialize component with data type [N3sdf3v125WorldE], which doesn't have `operator<<`. Component will not be serialized.
[ign gazebo-1] [Wrn] [Model.hh:69] Skipping serialization / deserialization for models with //pose/@relative_to attribute.
Again a rqt_topic plugin shows up.
As expected ros2 launch ros_gz_sim_demos image_bridge.launch.py image_topic:=/rgbd_camera/depth_image works.
Also ros2 launch ros_gz_sim_demos rgbd_camera_bridge.launch.py works.
As expected, ros2 launch ros_gz_sim_demos rgbd_camera.launch.py, has no world to load. Could select the depth_cameras.sdf, but no native conversion of point-clouds.
The script ros2 launch ros_gz_sim_demos robot_description_publisher.launch.py shows only a ball (both Gazebo and rviz). Tomorrow I should add the ugv_rover description.
September 3, 2025
Looking into system variables for Ignition Gazebo 6 at the Finding resources page.
Models are searched in IGN_GAZEBO_RESOURCE_PATH and GZ_SIM_RESOURCE_PATH
Looked at /.ignition/fuel/fuel.ignitionrobotics.org/openrobotics/models/gazebo/3/model.config, which contains only a Gazebo model (from Nate Koenig)
Did grep Wrn ~/.ignition/gazebo/log/2025-09-02T17\:12\:29.706603374/server_console.log, which gave two warnings:
(2025-09-02T17:17:43.937214976) (2025-09-02T17:17:43.937220099) [Wrn] [Component.hh:144] Trying to serialize component with data type [N3sdf3v125WorldE], which doesn't have `operator<<`. Component will not be serialized.
(2025-09-02T17:18:17.60617480) (2025-09-02T17:18:17.60622432) [Wrn] [SdfEntityCreator.cc:910] Sensor type LIDAR not supported yet. Try usinga GPU LIDAR instead.
Looking into Server Configuration. I like the addition of a camera, which actually uses another system environment variable: IGN_GAZEBO_SERVER_CONFIG_PATH
Next looking at Model command, which allows to inspect the models loaded with ign model --list.
According to the Migration page, IGN-based environment variables are no longer used, and should one use GZ_SIM_RESOURCE_PATH. That variable is not defined (yet) in my environment.
This post gives an overview of other Environment variables used (quite a list).
Also note the ros_gz comment at the bottom of the migration page
Starting with the vehicle example from Visualize in RViz tutorial. The first command ros2 launch ros_gz_sim_demos sdf_parser.launch.py rviz:=True partly fails:
[robot_state_publisher-3] [INFO] [1756904410.927266716] [robot_state_publisher]: Floating joint. Not adding segment from chassis to caster.
[ign gazebo-1] [ignition::plugin::Loader::LookupPlugin] Failed to get info for [gz::sim::systems::OdometryPublisher]. Could not find a plugin with that name or alias.
[ign gazebo-1] [Err] [SystemLoader.cc:125] Failed to load system plugin [gz::sim::systems::OdometryPublisher] : could not instantiate from library [gz-sim-odometry-publisher-system] from path [/usr/lib/x86_64-linux-gnu/ign-gazebo-6/plugins/libignition-gazebo-odometry-publisher-system.so]
Following this segmentation example, I tried sudo apt-get install libignition-gazebo6-dev. Was already installed. /usr/lib/x86_64-linux-gnu/ign-gazebo-6/plugins/libignition-gazebo-odometry-publisher-system.so also exists.
Problem seems more the plugin-name, according to this post.
Looking into /opt/ros/humble/share/ros_gz_sim_demos/launch/sdf_parser.launch.py
This loads model/vehicle.sdf, but not explicit odometry-plugins.
Looked in /opt/ros/humble/share/ros_gz_sim/launch/gz_sim.launch.py. Here plugins are loaded, from GZ_SIM_SYSTEM_PLUGIN_PATH, but not explicit odometry.
Inside the lib, I see ignition::gazebo::systems::OdometryPublisher, instead of gz::sim::systems::OdometryPublisher. Seems a migration problem.
Instead of the latest, I should use the Fortress ROS 2 Integration tutorial, although it has not the Visualize in RViz part.
Finally, this worked, although I should use tree terminals, one for the bridge, one for gazebo and one for ros2 topic echo.
Also ros2 launch ros_gz_sim gz_sim.launch.py gz_args:="shapes.sdf" from ros_gz_sim_demos works.
The fluid pressure demo can be started with ros2 launch ros_gz_sim_demos air_pressure.launch.py (readme still said xml)
Trying to subscribe "reliable" indeed failed; ros2 topic echo /air_pressure --qos-reliability reliable gives:
[WARN] [1756911367.367823219] [_ros2cli_893745]: New publisher discovered on topic '/air_pressure', offering incompatible QoS. No messages will be received from it. Last incompatible policy: RELIABILIT
Also ros2 launch ros_gz_sim_demos battery.launch.py works, which gives two vehicles (and no odometry complains!)
Driving around with ros2 topic pub /model/vehicle_blue/cmd_vel geometry_msgs/msg/Twist "{linear: {x: 5.0}, angular: {z: 0.5}}" also works, although I don't see the battery level going down.
Also ros2 launch ros_gz_sim_demos image_bridge.launch.py
The command ros2 launch ros_gz_sim_demos camera.launch.py also launches rviz, which shows the image (although with a warning that no tf-data is received).
The command ros2 launch ros_gz_sim_demos diff_drive.launch.py launches a vehicle, including odometry.
With ros2 topic echo /model/vehicle_green/odometry I receive odometry updates.
Tomorrow the GPU lidar example, together with the BumpGo code.
Installing the software from the book is not completly trivial / documented.
Started with making a workspace:
cd
mkdir -p bookros2_ws/src
cd bookros2_ws/src/
Continued with cloning the humble-branch (quite some commits behind the main rolling-branch):
git clone --branch humble-devel https://github.com/fmrico/book_ros2.git
First had to install vcstool with sudo apt install python3-vcstool before I could import the dependencies with vcs import . < book_ros2/third_parties.repos. This installs the behavior-framework Groot, and packages of pal, pmb2 and tiago robots.
Continued with sudo rosdep init, rosdep update.
Installing all dependencies with cd ~/bookros_ws, rosdep install --from-paths src --ignore-src -r -y.
Finally the workspace itself is build with cd ~/bookros_ws, colcon build --symlink-install. 39 packages are build.
Activate the build packages with source ~/bookros_ws/install/setup.sh.
The simulation is start up with ros2 launch br2_tiago sim.launch.py. That fails because You are using the public simulation of PAL Robotics, make sure the launch argument is_public_sim is set to True
With help of this discussion, corrected the start command to ros2 launch br2_tiago sim.launch.py is_public_sim:=True
The simulation is waiting on the controller_manager. Starting up the controller with ros2 run br2_fsm_bumpgo_cpp bumpgo --ros-args -r output_vel:=/nav_vel -r input_scan:=/scan_raw -p use_sim_time:=true. See no output from bumpgo.
Tried instead ros2 launch br2_fsm_bumpgo_cpp bump_and_go.launch.py, which only indicated that the bumpgo process has started.
Tried instead starting the simulation including a world with ros2 launch br2_tiago sim.launch.py world:=factory is_public_sim:=True (Chapter 2). Now I see several Errors messages about missing MoveIt.
Run again, now with ros2 launch br2_tiago sim.launch.py world:=factory is_public_sim:=Truei moveit:=False navigation:=True. That starts up a rviz-window with a single TF. No Gazebo screen (yet), although gzserver prints a lot of models, material and links.
Still see some errors, such as moveit requesting the plugin of chomp-planning. The control_server is complaining that frame "odom" doesn't exist.
The documentation indicates ros2 launch tiago_gazebo tiago_gazebo.launch.py is_public_sim:=True [arm_type:=no-arm]. That stills give a lot of play_motion2 errors, mainly on the arm. Instead tried ros2 launch tiago_gazebo tiago_gazebo.launch.py is_public_sim:=True arm_type:=no-arm. Less errors, still tuck_arm and play_motion giving errors.
According to this discussion the play_motion errors could be ignored. The packages should work, I could try vcs pull (first doing sudo apt upgrade to get mostly 100 ros-humble packages up-to-date. According to vcs pull all packages are up-to-date.
Only remaining error-message I now see is:
[move_group-3] [ERROR] [1756806564.285553799] [moveit.ros_planning_interface.moveit_cpp]: Failed to initialize planning pipeline 'chomp'.
And the play_motion errors:
[play_motion2_node-9] [ERROR] [1756806590.164395740] [play_motion2]: Service /controller_manager/list_controllers not available.
[play_motion2_node-9] [ERROR] [1756806590.164568652] [play_motion2]: There are no active JointTrajectory controllers available
[play_motion2_node-9] [ERROR] [1756806590.164589783] [play_motion2]: Joint 'torso_lift_joint' is not claimed by any active controller
[tuck_arm.py-15] [ERROR] [1756806590.485311835] [arm_tucker]: play_motion2 is not ready
The Tutorial uses the colcon mixin build-interface. 55 packages are build, including moveit_planners_chomp. Terminal crashed while building! Trying again. Now all 55 packages are build.
Didn't do the Cyclone-DDS switch (yet).
Continue with MoveIt Quickstart. Receive many warnings that a link is not found in model 'panda'.
Rviz was hidden on my other monitor. When selecting “MotionPlanning” from moveit_ros_visualization, the robot appeared. Yet, the MotionPlanning gives a warning, Requesting initial scene failed.
Everything in the Quickstart worked, except showing a trail between start and goal. Both start-configuration were without collision, not sure why no path was found.
Checked terminal for error message. Saw:
rviz2-1] [INFO] [1756816210.851194549] [move_group_interface]: MoveGroup action client/server not ready
[rviz2-1] [ERROR] [1756816210.851330037] [moveit_background_processing.background_processing]: Exception caught while processing action 'update start state': can't compare times with different time sources
[rviz2-1] [ERROR] [1756816215.083438248] [moveit_ros_robot_interaction.robot_interaction]: Unknown marker name: 'EE:goal_panda_link8' (not published by RobotInteraction class) (should never have ended up in the feedback_map!)
[rviz2-1] [INFO] [1756816222.941671416] [move_group_interface]: MoveGroup action client/server not ready
[rviz2-1] [WARN] [1756816289.434020412] [rcl.logging_rosout]: Publisher already registered for provided node name. If this is due to multiple nodes with the same name then all logs for that logger name will go out over the existing publisher. As soon as any node with that name is destructed it will unregister the publisher, preventing any further logs for that name from being published on the rosout topic.
The Tiago simulation was still running in the background, maybe the problem.
With Tiago killed something is happening. I at least see:
[move_group-4] [INFO] [1756816658.654702357] [moveit_move_group_capabilities_base.move_group_capability]: Using planning pipeline 'ompl'
[move_group-4] [INFO] [1756816658.682241776] [moveit_move_group_default_capabilities.move_action_capability]: Motion plan was computed successfully.
[rviz2-1] [INFO] [1756816658.682573844] [move_group_interface]: Planning request complete!
[rviz2-1] [INFO] [1756816658.682721350] [move_group_interface]: time taken to generate plan: 0.015806 seconds
Still no trail, but good enough for the moment.
Back to ros2 launch tiago_gazebo tiago_gazebo.launch.py is_public_sim:=True arm_type:=no-arm. With both workspaces loaded, there is no MoveIt plugin problems anymore, but still no Rviz or Gazebo shows up.
Initiated the workspace ugv_ws and did ros2 launch ugv_gazebo bringup.launch.py. Receive a warning:
[robot_state_publisher-3] [WARN] [1756817272.617985721] [robot_state_publisher]: No robot_description parameter, but command-line argument available. Assuming argument is name of URDF file. This backwards compatibility fallback will be removed in the future.
Next is an info-message:
[spawn_entity.py-5] [INFO] [1756817272.876533049] [spawn_entity]: Loading entity XML from file ~/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/models/ugv_rover/model.sdf
Next is an error-message:
[spawn_entity.py-5] [ERROR] [1756817302.926052688] [spawn_entity]: Service /spawn_entity unavailable. Was Gazebo started with GazeboRosFactory?
Tried ros2 launch ros_gz_sim gz_sim.launch.py gz_args:=empty.sdf, which works.
Did ros2 launch ugv_gazebo display.launch.py, which gave a rviz screen with a RobotModel:
Tried ros2 launch ugv_gazebo gazebo_example_world.launch.py, with the launch example of Launch Gazebo from ROS 2. Gives package 'example_package' not found
Was marked with #Replace with your package, so changed it to ugv_gazebo.
Launch now failed on downloading the world:
[ign gazebo-1] Unable to find or download file
[ERROR] [ign gazebo-1]: process has died [pid 584622, exit code 255, cmd 'ruby /usr/bin/ign gazebo ~/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/example_world.sdf --force-version 6']
There is a world in ugv_gazebo package, but worlds/ugv_world.world is not a SDF.
Loading this as world gave the errors:
[ign gazebo-1] [Err] [Server.cc:139] Error Code 13: [/sdf/world[@name="default"]/include[0]/uri:~/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world:L6]: Msg: Unable to find uri[model://ground_plane]
[ign gazebo-1] [Err] [Server.cc:139] Error Code 13: [/sdf/world[@name="default"]/include[1]/uri:~/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world:L10]: Msg: Unable to find uri[model://sun]
[ign gazebo-1] [Err] [Server.cc:139] Error Code 3: Msg: The supplied model name [world] is reserved.
Changed in the launch-file the package to gazebo_ros, and the world to worlds/empty.world. Also here the model sun and ground_plane are not known.
There are three models directories in /opt/ros/humble/share/, in hte package ros_gz_sim_demos, rviz_rendering/ogre_media and depthai_descriptions/urdf.
The sun and ground_plane are actually in ~/.gazebo/models/.
Included both with GAZEBO_MODEL_PATH and IGN_GAZEBO_MODEL_PATH, still not found.
According to this Gazebo documentation, ros_gz_sim should have a file gz_spawn_model.launch.py. No longer there in /opt/ros/humble/share/ros_gz_sim/launch/, only gz_sim.launch.py. There is a ros_gz_spawn_model.launch.py code snippet, but this script also launches ros_gz_bridge (which has for humble no launch file).
When I start ros2 launch ros_gz_sim gz_sim.launch.py I got a quick start screen with several worlds to choose from.
Launching ros2 run ros_gz_sim create -world default -file 'https://fuel.ignitionrobotics.org/1.0/openrobotics/models/Gazebo' fails.
Started empty from the quick start screen worked. Note that the source file path is /usr/share/ignition/ignition-gazebo6/worlds/empty.sdf
Running ros2 run ros_gz_sim create -world empty -file 'https://fuel.ignitionrobotics.org/1.0/openrobotics/models/Gazebo' adds a house to the empty world.
See a error [ign gazebo-1] [Err] [SystemPaths.cc:473] Could not resolve file [gazebo_diffuse.jpg].
Started in the quick start shapes.sdf
Started in the quick start empty. When I do ros2 run ros_gz_sim create -world empty -file '/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/models/ugv_rover/model.sdf' the model is loaded, yet I see no mesh:
September 1, 2025
Updating the Overview lecture. Needed some time to find the Waveshare page of Unmanned Ground Vehicle basis, and Waveshare's Jetson Orin documentation.
Trying to start ros2 run rqt_console rqt_console from nb-dual (WSL with XLaunch running). Fails on from python_qt_binding import QT_BINDING, ImportError: libQt5Core.so.5.
Strange, added /usr/lib/x86_64-linux-gnu/libQt5Core.so.5 to LD_LIBRARY_PATH, still same error.
The trick from stackoverflow worked: sudo strip --remove-section=.note.ABI-tag /lib/x86_64-linux-gnu/libQt5Core.so.5.
Loading from python_qt_binding import QT_BINDING from python3 now works, yet ros2 run rqt_console rqt_console still fails, now on:
could not connect to display
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
Running xclock also gave the error Can't open display:. This could be solved with export DISPLAY=0:0. Now I got a rqt_console working under Windows from a WSL Ubuntu-22.04 terminal:
Chapter 3 has a nice simple application to control the robot with the Lidar, BumpGo (FSM-based). For a simulated Tiago robot. Is also available as python-version.
Nice project to try tomorrow on WS9 (Gazebo), before trying it on the Rover.
Chapter 5 has an example of tracking an object (camera based), with a HeadController, including a PID-controller.
Chapter 6 describes a patrolling behavior (implemented with Groot), with Nav and a costmap. Yet, example in slides is still ros1-foxy based. Nav2 (ros2-humble) with Turtlebot/Tiago is described in appendix.
August 29, 2025
Testing UvA AI-chat. Suggested this piece of code to draw the bounding box:
# Iterate through each detection and draw the bounding box
for detection in detections:
corners = detection['lb-rb-rt-lt']
# Convert corners to integer
corners = np.int32(corners)
The example-run python test_deeptag.py --config config_image.json seems to run, although on the end it crashed on Qt (tried to display the result?)
Indeed, at the end a call is made to visualize(). Made an equivalent function which saves the image.
That works, for the example image:
Yet, the config_image.json not only specifies the file-name, but also the cameraMatrix and distCoeffs. Running the same code on my preview.jpg , Stage already failed to detect a ROI, so also 2nd stage failed.
On June 2025 I did python3 examples/calibration/calibration_reader.py (for the RAE) and the UGV Rover.
The preview I stored was 300x300. I did a calibration run on the UGV already in June, so could try to reuse those values. The apriltag_cube was a 1280x960 image. The cameraMatrix of the apriltag_cube was [921.315, 0, 649.204, 0, 921.375, 459.739, 0, 0, 1], changing it to [453.941, 0.0, 318.555, 0.0, 454.052, 243.238, 0, 0, 1] (for height=480).
The distCoeffs were [ 0.978811, 3.71217, 0.000159566, 0.000281263, 0.638837, 1.36651, 3.99066, 1.93969], updated to [72.96343994140625,
-161.83697509765625,
0.0020885001868009567,
-0.0006911111413501203,
96.07749938964844,
73.06451416015625,
-162.3726806640625,
96.70803833007813,
0.0,
0.0,
0.0,
0.0,
-0.01333368755877018,
0.0015384935541078448]
Also update the marker_size from 3cm to 10cm.
Yet, now the code fails on cameraMatrix = np.float32(cameraMatrix).reshape(3,3), because I forgot the last row.
Now the code runs again, but still fails to find a ROI:
>>>>>>>Stage-1<<<<<<<
0 ROIs
>>>>>>>Stage-2<<<<<<<
>iter #0
>iter #1
Valid ROIs:
------timing (sec.)------
Stage-1 : [CNN 0.8183] 0.8188
Stage-2 (1 marker): [CNN 0.0000] 0.0000
Stage-2 (0 rois, 0 markers): [CNN 0.0000] 0.0000
The first part is on finetuning YOLO8. Started with the last part, which fails on pipeline = create_camera_pipeline(YOLOV8N_CONFIG, YOLOV8N_MODEL). That is correct, I didn´t specify YOLOV8N_CONFIG yet.
With YOLOV8N_CONFIG defined, it is missing the fine-tuned model: yolov8_320_fps_check/result/best.json.
So, I made in ~/test/ultralytics a download_pothole_dataset.py script. Script looks more like a shell-script. Downloaded the dataset directly with wget.
The commands seems to be intended for a Jupyter notebook. Just calling !yolo doesn't work. Looking at regular fine-tuning tutorial. That has a train.py file (instead of the yolo CLI).
According to this post, the command should be just ultralytics train. Tried ultralytics train model=yolov8n.pt imgsz=960 data=pothole_v8.yaml epochs=50 batch=32 name=yolov8n_v8_50e, which starts downloading yolov8n.pt but than fails on line 6 of the yaml file (missing quote).
Seems to start nicely:
Plotting labels to runs/detect/yolov8n_v8_50e2/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.002, momentum=0.9) with parameter groups 57 weight(decay=0.0), 64 weight(decay=0.0005), 63 bias(decay=0.0)
Image sizes 960 train, 960 val
Using 6 dataloader workers
Logging results to runs/detect/yolov8n_v8_50e2
Starting training for 50 epochs...
Directly after that the process is killed. Seems that specifying an additional "datasets" was not necessary. Without the dataset seems to be valid, some duplicate labels are removed. Still, the training is killed (without error-message). Running it with train_pothole.py also gives a kill.
Unfortunately, the openvino blob is no longer available.
Found an earlier (openvino_2021) version with artifactory.
Seems to work, yet looks like the preview crashes (no display). Removed the the preview-code. Now the script fails on in_cam = q_cam.get(). That was still the preview frame.
Script now works, get some warnings:
/home/jetson/test/ultralytics/detect_face_from_oak.py:22: DeprecationWarning: RGB is deprecated, use CAM_A or address camera by name instead.
cam.setBoardSocket(dai.CameraBoardSocket.RGB)
/home/jetson/test/ultralytics/detect_face_from_oak.py:26: DeprecationWarning: LEFT is deprecated, use CAM_B or address camera by name instead.
mono_left.setBoardSocket(dai.CameraBoardSocket.LEFT)
/home/jetson/test/ultralytics/detect_face_from_oak.py:29: DeprecationWarning: RIGHT is deprecated, use CAM_C or address camera by name instead.
mono_right.setBoardSocket(dai.CameraBoardSocket.RIGHT)
[14442C10019902D700] [1.2.3] [1.521] [SpatialDetectionNetwork(4)] [warning] Neural network inference was performed on socket 'RGB', depth frame is aligned to socket 'RIGHT'. Bounding box mapping will not be correct, and will lead to erroneus spatial values. Align depth map to socket 'RGB' using 'setDepthAlign'.
Looking at this post, which also uses a OAK combined with a Jetson. Points to Multi-Device Setup from Luxonis. Only one X_LINK_UNBOOTED device showed up.
Better is test-example is hello world from Luxonis. Should only safe the frame instead of showing it.
That works. Actually, it already recognized the AprilTag with mobilenet-ssd_openvino_2022.1_6shave.blob, although it didn´t print the label:
Executing YOLO on the CPU is really easy, just device="cpu". The result is also interesting. Inference is 2x as slow, but overall it faster, because the postprocess is 80x faster:
CPU-Speed: 8.8ms preprocess, 364.1ms inference, 8.1ms postprocess per image at shape (1, 3, 640, 480)
GPU-Speed: 8.6ms preprocess, 154.8ms inference, 638.9ms postprocess per image at shape (1, 3, 640, 480)
.
That works, it can detect a tagStandard41h12 with ID=1. The structure that is returned has the following form:
Detecting: {'hamming': 0, 'margin': 85.24191284179688, 'id': 1, 'center': array([197.00670206, 147.69477397]), 'lb-rb-rt-lt': array([[153.73930359, 193.42068481],
[244.68344116, 190.64276123],
[238.93740845, 103.38150787],
[151.60453796, 106.79576111]])}
August 26, 2025
The Rover is running JetPack 6. When checking with nvidia-smi, the CUDA version is 12.02 but no drivers are installed (nvidia-tools is version 540.3.0).
Starting with Yolo tutorial. It has start commands for three JetPacks (v4 to v6). Yet, all three docker based.
Ultralytics itself has a tutorial with a native installation on the Jetson.
Doing pip install ultralytics[export] starts to download for instance multiple versions of typing_extensions (4.2.0 to 4.15.0)
So, because at the end installing the rich-dependency (from keras, tensorflow, ultralytics) failed, I installed just pip install ultralytics.
I installed the other packages, and tried to run the example.
That failed on libcudart.so.12.
Looked at this post: I have only one libcuda.so version, in /usr/lib/aarch64-linux-gnu/libcuda.so.
Did sudo apt install cuda-toolkit-12-2, which contains cuda-cudart-12-2 cuda-cudart-dev-12-2. That solves it partly. Next improt error is on libcudnn.so.9. According to Installing cuDNN on Linux, this could be solved with sudo apt-get -y install cudnn9-cuda-12.
That solves all explicit dependencies. Yet, there are also implicit dependencies:
Creating new Ultralytics Settings v0.0.6 file ✅
View Ultralytics Settings with 'yolo settings' or at '/home/jetson/.config/Ultralytics/settings.json'
Update Settings with 'yolo settings key=value', i.e. 'yolo settings runs_dir=path/to/dir'. For help see https://docs.ultralytics.com/quickstart/#ultralytics-settings.
Downloading https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt to 'yolo11n.pt': 100%
YOLO11n summary (fused): 100 layers, 2,616,248 parameters, 0 gradients, 6.5 GFLOPs
Ultralytics requirements ['onnx>=1.12.0,<1.18.0', 'onnxslim>=0.1.59'] not found, attempting AutoUpdate...
torch 2.5.0 requires sympy==1.13.1, but you have sympy 1.14.0 which is incompatible
Major problem is the support-matrix. Checked tensorrt 10.7.x, which requires cuda 12.6.
I couldn´t find the installation instruction for tensorrt 9.x, and version 8.x is CUDA 12.2 based.
Followed this instructions to install 12.6 on JetPack.
Now I can download wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/10.7.0/local_repo/nv-tensorrt-local-repo-ubuntu2404-10.7.0-cuda-12.6_1.0-1_arm64.deb
Next available version is https://developer.download.nvidia.com/compute/tensorrt/10.13.2/local_installers/nv-tensorrt-local-repo-ubuntu2404-10.13.2-cuda-13.0_1.0-1_arm64.deb (maybe for JetPack 7).
Next step is according to sudo apt-get install tensorrt
Verifying the installation with dpkg-query -W tensorrt gives tensorrt 10.7.0.23-1+cuda12.6.
Running the example comes one step further:
PyTorch: starting from 'yolo11n.pt' with input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 84, 8400) (5.4 MB)
ONNX: starting export with onnx 1.17.0 opset 19...
ONNX: slimming with onnxslim 0.1.65...
ONNX: export success ✅ 3.2s, saved as 'yolo11n.onnx' (10.2 MB)
TensorRT: export failure 3.3s: libnvdla_compiler.so: cannot open shared object file: No such file or directory
Seems that it is part of the nvidia-toolkit. Found this notes and did sudo apt-get install nvidia-container-toolkit libnvidia-container-tools nvidia-container-runtime. That was not the trick.
The NVIDIA DLA (Deep Learning Accelerator) should be part of the Orin Jetson.
Did a sudo apt upgrade, which updates many ros-humble packages, and installs ros-humble-aruco-msgs ros-humble-aruco-opencv-msgs.
The first check cat /proc/driver/nvidia/version gives VRM version: NVIDIA UNIX Open Kernel Module for aarch64 540.3.0
Trying sudo apt install nvidia-jetpack, whcih gives the following dependencies clashes:
vidia-container : Depends: nvidia-container-toolkit-base (= 1.14.2-1) but 1.17.8-1 is to be installed
Depends: libnvidia-container-tools (= 1.14.2-1) but 1.17.8-1 is to be installed
Depends: nvidia-container-toolkit (= 1.14.2-1) but 1.17.8-1 is to be installed
Depends: libnvidia-container1 (= 1.14.2-1) but 1.17.8-1 is to be installed
nvidia-tensorrt : Depends: tensorrt-libs (= 8.6.2.3-1+cuda12.2) but 10.7.0.23-1+cuda12.6 is to be installed
Searched with apt list -a *dla* for relevant packages. Found nvidia-l4t-dla-compiler. Now /usr/lib/aarch64-linux-gnu/tegra/libnvdla_compiler.so, but python can still not find it. This path was not part of LD_LIBRARY (note, many libraries seems to be missing - I would also expect /usr/local/cuda-12/lib64
Start the definition now with export LD_LIBRARY_PATH="/usr/local/lib:/usr/lib/aarch64-linux-gnu/:/usr/lib/aarch64-linux-gnu/tegra/:/usr/local/cuda-12/lib64:${LD_LIBRARY_PATH:-}"
Now the example works:
TensorRT: starting export with TensorRT 10.7.0...
[08/27/2025-02:32:47] [TRT] [I] [MemUsageChange] Init CUDA: CPU +2, GPU +0, now: CPU 640, GPU 3219 (MiB)
[08/27/2025-02:32:50] [TRT] [I] [MemUsageChange] Init builder kernel library: CPU +965, GPU -392, now: CPU 1648, GPU 2860 (MiB)
[08/27/2025-02:32:50] [TRT] [I] ----------------------------------------------------------------
[08/27/2025-02:32:50] [TRT] [I] Input filename: yolo11n.onnx
[08/27/2025-02:32:50] [TRT] [I] ONNX IR version: 0.0.9
[08/27/2025-02:32:50] [TRT] [I] Opset version: 19
[08/27/2025-02:32:50] [TRT] [I] Producer name: pytorch
[08/27/2025-02:32:50] [TRT] [I] Producer version: 2.5.0
[08/27/2025-02:32:50] [TRT] [I] Domain:
[08/27/2025-02:32:50] [TRT] [I] Model version: 0
[08/27/2025-02:32:50] [TRT] [I] Doc string:
[08/27/2025-02:32:50] [TRT] [I] ----------------------------------------------------------------
TensorRT: input "images" with shape(1, 3, 640, 640) DataType.FLOAT
TensorRT: output "output0" with shape(1, 84, 8400) DataType.FLOAT
TensorRT: building FP32 engine as yolo11n.engine
[08/27/2025-02:32:50] [TRT] [I] Local timing cache in use. Profiling results in this builder pass will not be stored.
[08/27/2025-02:34:25] [TRT] [I] Compiler backend is used during engine build.
[08/27/2025-02:36:07] [TRT] [W] Tactic Device request: 260MB Available: 256MB. Device memory is insufficient to use tactic.
[08/27/2025-02:36:07] [TRT] [W] UNSUPPORTED_STATE: Skipping tactic 0 due to insufficient memory on requested size of 272793600 detected for tactic 0x00000000000003e8.
[08/27/2025-02:36:07] [TRT] [W] Tactic Device request: 260MB Available: 257MB. Device memory is insufficient to use tactic.
[08/27/2025-02:36:07] [TRT] [W] UNSUPPORTED_STATE: Skipping tactic 1 due to insufficient memory on requested size of 272793600 detected for tactic 0x00000000000003ea.
[08/27/2025-02:36:07] [TRT] [W] Tactic Device request: 260MB Available: 258MB. Device memory is insufficient to use tactic.
[08/27/2025-02:36:07] [TRT] [W] UNSUPPORTED_STATE: Skipping tactic 2 due to insufficient memory on requested size of 272793600 detected for tactic 0x0000000000000000.
[08/27/2025-02:36:14] [TRT] [I] Detected 1 inputs and 1 output network tensors.
[08/27/2025-02:36:16] [TRT] [I] Total Host Persistent Memory: 566592 bytes
[08/27/2025-02:36:16] [TRT] [I] Total Device Persistent Memory: 38912 bytes
[08/27/2025-02:36:16] [TRT] [I] Max Scratch Memory: 2764800 bytes
[08/27/2025-02:36:16] [TRT] [I] [BlockAssignment] Started assigning block shifts. This will take 226 steps to complete.
[08/27/2025-02:36:16] [TRT] [I] [BlockAssignment] Algorithm ShiftNTopDown took 25.7148ms to assign 11 blocks to 226 nodes requiring 19252224 bytes.
[08/27/2025-02:36:16] [TRT] [I] Total Activation Memory: 19251200 bytes
[08/27/2025-02:36:16] [TRT] [I] Total Weights Memory: 10588740 bytes
[08/27/2025-02:36:16] [TRT] [I] Compiler backend is used during engine execution.
[08/27/2025-02:36:16] [TRT] [I] Engine generation completed in 205.479 seconds.
[08/27/2025-02:36:16] [TRT] [I] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 1 MiB, GPU 213 MiB
TensorRT: export success ✅ 212.3s, saved as 'yolo11n.engine' (11.9 MB)
Export complete (214.0s)
Results saved to /home/jetson/test/ultralytics
Predict: yolo predict task=detect model=yolo11n.engine imgsz=640
Validate: yolo val task=detect model=yolo11n.engine imgsz=640 data=/usr/src/ultralytics/ultralytics/cfg/datasets/coco.yaml
Visualize: https://netron.app
WARNING ⚠️ Unable to automatically guess model task, assuming 'task=detect'. Explicitly define task for your model, i.e. 'task=detect', 'segment', 'classify','pose' or 'obb'.
Loading yolo11n.engine for TensorRT inference...
[08/27/2025-02:36:16] [TRT] [I] Loaded engine size: 11 MiB
[08/27/2025-02:36:16] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +18, now: CPU 0, GPU 28 (MiB)
Downloading https://ultralytics.com/images/bus.jpg to 'bus.jpg': 100% ━━━━━━━━━━━━ 134.2/13Downloading https://ultralytics.com/images/bus.jpg to 'bus.jpg': 100% ━━━━━━━━━━━━ 134.2/134.2KB 16.1MB/s 0.0s
image 1/1 /home/jetson/test/ultralytics/bus.jpg: 640x640 4 persons, 1 bus, 32.4ms
Speed: 20.0ms preprocess, 32.4ms inference, 622.3ms postprocess per image at shape (1, 3, 640, 640)
This is the bus.jpg:
Without the ONNX conversion to DLA with the engine, 152.4ms is needed for inference:
Speed: 9.5ms preprocess, 152.4ms inference, 544.9ms postprocess per image at shape (1, 3, 640, 480)
With the conversion, 31.6ms is needed (5x as fast):
Speed: 33.9ms preprocess, 31.6ms inference, 588.2ms postprocess per image at shape (1, 3, 640, 640)
In the mean-time I looked at some of my experiments of December 12, 2024. The UGV rover also has a DepthAI camera, so ros2 launch depthai_ros_driver camera.launch.py worked out of the box.
An oak_container is started up. Inside the container I get after a while:
[component_container-1] [INFO] [1756214142.940842084] [oak]: Starting camera.
[component_container-1] [INFO] [1756214143.845368276] [oak]: No ip/mxid specified, connecting to the next available device.
[component_container-1] [INFO] [1756214153.702111573] [oak]: Camera with MXID: 14442C10019902D700 and Name: 1.2.3 connected!
[component_container-1] [INFO] [1756214153.703465062] [oak]: USB SPEED: HIGH
[component_container-1] [INFO] [1756214153.752090092] [oak]: Device type: OAK-D-LITE
[component_container-1] [INFO] [1756214153.756476940] [oak]: Pipeline type: RGBD
[component_container-1] [INFO] [1756214154.265811788] [oak]: NN Family: mobilenet
[component_container-1] [INFO] [1756214154.371948858] [oak]: NN input size: 300 x 300. Resizing input image in case of different dimensions.
[component_container-1] [INFO] [1756214154.986553834] [oak]: Finished setting up pipeline.
After that I get three warnings, and the camera is ready:
[component_container-1] [14442C10019902D700] [1.2.3] [3.449] [SpatialDetectionNetwork(9)] [warning] Network compiled for 6 shaves, maximum available 10, compiling for 5 shaves likely will yield in better performance
[component_container-1] [WARN] [1756214156.322062749] [oak]: Parameter imu.i_rot_cov not found
[component_container-1] [WARN] [1756214156.322186081] [oak]: Parameter imu.i_mag_cov not found
[component_container-1] [INFO] [1756214157.512126477] [oak]: Camera ready!
Tried again, now with DEPTHAI_DEBUG=1.
Now I get some (too much) extra information, such as:
[component_container-1] CAM ID: 1, width: 640, height: 480, orientation: 0
[component_container-1] CAM ID: 2, width: 640, height: 480, orientation: 0
[component_container-1] CAM ID: 0, width: 1920, height: 1080, orientation: 0
Looking on nb-dual what I see when starting ros2 launch depthai_ros_driver camera.launch.py. With ros2 node list I see:
/launch_ros_147132
/oak
/oak_container
/oak_state_publisher
/rectify_color_node
With ros2 topic list I see the following oak-topics:
/oak/imu/data
/oak/nn/spatial_detections
/oak/rgb/camera_info
/oak/rgb/image_raw
/oak/rgb/image_raw/compressed
/oak/rgb/image_raw/compressedDepth
/oak/rgb/image_raw/theora
/oak/rgb/image_rect
/oak/rgb/image_rect/compressed
/oak/rgb/image_rect/compressedDepth
/oak/rgb/image_rect/theora
/oak/stereo/camera_info
/oak/stereo/image_raw
/oak/stereo/image_raw/compressed
/oak/stereo/image_raw/compressedDepth
/oak/stereo/image_raw/theora
Another interesting tutorial (directly on OAK-lite), is this Yolo on OAK tutorial
August 25, 2025
Interesting new 40K high-resolution depth-estimation dataset, fully panoramic with 3D LiDAR ground-truth. The dataset is available on github.
Removing sudo apt remove python3.10-distutils python3.10-lib2to3 python3.10-minimal python3.10 libpython3.10-minimal libpython3.10-stdlib was a bit too much. System crashed, no GUI, no internet.
Luckely a reboot gave a terminal (still no internet), but after sudo apt remove libpython3.10-minimal libpython3.10-stdlib and sudo apt install ubuntu-desktop I got my GUI back.
Now I could also do sudo apt install ros-humble-desktop.
Added build --cmake-args -Wno-dev to reduce the number of cmake Deprecation warnings
The package slam_mapping still gives output, but that is an explicit message() in the CMakefile (without Log level keyword.
Curious what the vizantie_demos are?
Looking at possible ros-humble official packages:
The dry-run sudo apt install --dry-run ros-humble-cartographer gives:
The following NEW packages will be installed:
libabsl-dev libcairo2-dev liblua5.2-0 liblua5.2-dev libpixman-1-dev
libreadline-dev libtool-bin ros-humble-cartographer
The version of ros-humble-cartographer is 2.0.9004-1jammy.20250701.011854.
In the 4th tutorial 2D Mapping Based on LiDAR, cartogrpaher is called, but with ros2 launch ugv_slam cartographer.launch.py use_rviz:=true. This script calls cartographer/launch/mapping.launch.py, together with ugv_bringup/launch/bringup_lidar.launch.py and robot_pose_publisher/launch//robot_pose_publisher_launch.py
The mapping.launch.py uses mapping_2d.lua as configuration_basename. It launches two nodes (cartographer_node and cartographer_occupancy_grid_node) from package cartographer_ros.
This package seems not be installed, sudo apt install --dry-run ros-humble-cartographer-ros installs 10 packages, including ros-humble-cartographer
ros-humble-cartographer-ros ros-humble-cartographer-ros-msgs.
Indeed, when I do ros2 launch cartographer mapping.launch.py I get the error that package 'cartographer_ros' not found.
Installed ros-humble-cartographer-ros and included it in the manual. Now ros2 launch cartographer mapping.launch.py starts.
I see three nodes:
/cartographer_node
/cartographer_occupancy_grid_node
/transform_listener_impl_6430e08998d0
I see the following topics:
/constraint_list
/landmark_poses_list
/map
/odom
/scan
/scan_matched_points2
/submap_list
/tf
/tf_static
/trajectory_node_list
When I do ros2 node info /cartographer_node I get:
/cartographer_node
Subscribers:
/odom: nav_msgs/msg/Odometry
/parameter_events: rcl_interfaces/msg/ParameterEvent
/scan: sensor_msgs/msg/LaserScan
Publishers:
/constraint_list: visualization_msgs/msg/MarkerArray
/landmark_poses_list: visualization_msgs/msg/MarkerArray
/parameter_events: rcl_interfaces/msg/ParameterEvent
/rosout: rcl_interfaces/msg/Log
/scan_matched_points2: sensor_msgs/msg/PointCloud2
/submap_list: cartographer_ros_msgs/msg/SubmapList
/tf: tf2_msgs/msg/TFMessage
/trajectory_node_list: visualization_msgs/msg/MarkerArray
In addition, I also see the services of /cartographer_node:
Service Servers:
/cartographer_node/describe_parameters: rcl_interfaces/srv/DescribeParameters
/cartographer_node/get_parameter_types: rcl_interfaces/srv/GetParameterTypes
/cartographer_node/get_parameters: rcl_interfaces/srv/GetParameters
/cartographer_node/list_parameters: rcl_interfaces/srv/ListParameters
/cartographer_node/set_parameters: rcl_interfaces/srv/SetParameters
/cartographer_node/set_parameters_atomically: rcl_interfaces/srv/SetParametersAtomically
/finish_trajectory: cartographer_ros_msgs/srv/FinishTrajectory
/get_trajectory_states: cartographer_ros_msgs/srv/GetTrajectoryStates
/read_metrics: cartographer_ros_msgs/srv/ReadMetrics
/start_trajectory: cartographer_ros_msgs/srv/StartTrajectory
/submap_query: cartographer_ros_msgs/srv/SubmapQuery
/tf2_frames: tf2_msgs/srv/FrameGraph
/trajectory_query: cartographer_ros_msgs/srv/TrajectoryQuery
/write_state: cartographer_ros_msgs/srv/WriteState
When I do ros2 node info /cartographer_occupancy_grid_node
/cartographer_occupancy_grid_node
Subscribers:
/parameter_events: rcl_interfaces/msg/ParameterEvent
/submap_list: cartographer_ros_msgs/msg/SubmapList
Publishers:
/map: nav_msgs/msg/OccupancyGrid
/parameter_events: rcl_interfaces/msg/ParameterEvent
/rosout: rcl_interfaces/msg/Log
With in addition:
Service Servers:
/cartographer_occupancy_grid_node/describe_parameters: rcl_interfaces/srv/DescribeParameters
/cartographer_occupancy_grid_node/get_parameter_types: rcl_interfaces/srv/GetParameterTypes
/cartographer_occupancy_grid_node/get_parameters: rcl_interfaces/srv/GetParameters
/cartographer_occupancy_grid_node/list_parameters: rcl_interfaces/srv/ListParameters
/cartographer_occupancy_grid_node/set_parameters: rcl_interfaces/srv/SetParameters
/cartographer_occupancy_grid_node/set_parameters_atomically: rcl_interfaces/srv/SetParametersAtomically
Service Clients:
/submap_query: cartographer_ros_msgs/srv/SubmapQuery
Last I do ros2 node info /transform_listener_impl_6430e08998d0:
/transform_listener_impl_6430e08998d0
Subscribers:
/parameter_events: rcl_interfaces/msg/ParameterEvent
/tf: tf2_msgs/msg/TFMessage
/tf_static: tf2_msgs/msg/TFMessage
Publishers:
/rosout: rcl_interfaces/msg/Log
No Service Servers of Clients.
Looking at Algorithm walkthrough, the /cartographer_node is the frontend (local SLAM) that builds submaps. The /cartographer_occupancy_grid_node is the backend (global SLAM) which tries to find loop closure constraints.
Also looked at original paper. Points to the Ceres-based scan matcher for the local SLAM.
Continue at Algorithm walkthrough, the /cartographer_node frontend (local SLAM) does uses TRAJECTORY_BUILDER_nD.min_range and max_range that be chosen according to the specifications of your robot and sensors. Didn't see this parameter specified in the launch-files.
Checking ros2 param get /cartographer_node TRAJECTORY_BUILDER_2D.min_range, give parameter not set.
Checking /opt/ros/humble/share/cartographer/configuration_files/trajectory_builder_2d.lua, which indicates a min_range-max_range of 0-30m.
Note that Cartographer ROS provides an RViz plugin to visualize submaps. In 3D there are both low and high resolution submaps.
I see artographer_ros/launch/visualize_pbstream.launch.py, which calls the node rviz2 with cartographer_ros//configuration_files/demo_2d.rviz.
Also the constraints of the backend (global SLAM) can be visualized in RVIZ. Also saw the trajecotries, as published by the frondend.
The global constraints can be used for multi-robot mapping!
Continue with the step of the cartographer-ros documentation: Tuning the algorithm.
One of the nice sections are Pure Localization in a Given Map and Odometry in Global Optimization.
The next waveshare tutorial Auto Navigation uses rtabmap_localization. Yet, the ugv_nav/launch/nav.launch.py has the option to use cartographer localization. That calls cartographer/launch/localization.launch.py (without _ros, that launch file doesn't exist only cartographer_ros/launch/localization.launch.py) The Map to localize on is /home/ws/ugv_ws/src/ugv_main/ugv_nav/maps/map.pbstream(wrong, should be corrected). The cartographer_localization.launch.py looks much more logicall than bringup_launch_cartographer.launch.py, because it launches two ros-nodes (backend, frontend), instead of the bare cartographer-localization.
Skipped the web-interface and chat-bot tutorials.
Last waveshare Gazebo tutorial combines all previous Mapping and Navigation.
Seems that Vizanti is a web-visualizer. Indeed, the ugv_web_app/launch/bringup.launch.py calls vizanti_server/launch/vizanti_server.launch.py.
The repository of vizanti can be found on github. Last update 2 weeks ago.
The version of ugv_ws is a unoffical clone, not updated for 11 months.
In Zelfbediening I have the tab 'Bestellen tot betalen', but not page 'Ontvangst'. When you search for 'Goederen ontvangen' you get the intended page. Yet, I cannot see the orders that already arrived (did somebody else give an OK?). The order that still has to come (the UGV Rover) was visible.
Trying to update to Ubuntu 22.04 via the software updater. That fails between after setting channels and calculating the changes.
Did in a terminal sudo apt update. Two channels had GPG errors, so looked in /etc/apt/sources.list.d and commented out kitware and opensuse.
Still, it fials. Looking in /var/log/dist-upgrade/main.log. Several errors with cuda-drivers
There is still one error in /var/log/dist-upgrade/main.log, related with rti-connext-dds-5.3.1. Did sudo apt list --installed | grep dds, which showed ros-foxy-rmw-dds-common. Removing ros-foxy-rmw-dds-common also removes ros-foxy-rmw-fastrtps-cpp
ros-foxy-rmw-fastrtps-shared-cpp ros-foxy-ros-base ros-foxy-rosbag2
ros-foxy-rosbag2-converter-default-plugins, but installs ros-foxy-connext-cmake-module ros-foxy-rmw-connext-cpp
ros-foxy-rmw-connext-shared-cpp ros-foxy-rosidl-generator-dds-idl
ros-foxy-rosidl-typesupport-connext-c
ros-foxy-rosidl-typesupport-connext-cpp rti-connext-dds-5.3.1.
Removing rti-connext-dds-5.3.1 would bring ros-foxy-rmw-dds-common back again. Deleted all ros-foxy packages with sudo apt remove ros-foxy-*, followed by sudo apt remove rti-connext-dds-5.3.1.
Commented out all additional /etc/apt/sources.list.d/*. Still 8 repo active, including dk.archive xenial, cloud-r and librealsense.
Removed those from /etc/apt/sources.*. Now suddenly there are many updates available (more than 2000 jammy-updates)
Something still goes wrong with /var/lib/dkms/librealsense2-dkms/1.3.27/6.8.0-65-generic/x86_64/dkms
.conf for module librealsense2-dkms includes a BUILD_EXCLUSIVE directive which
does not match this kernel/arch
Update seems to be succeeded.
Tried the steps from ROS install. Yet, I receive the error: Error: could not find a distribution template for Ubuntu/jammy. Yet, from /etc/apt/sources.list it is clear that universe is activated (see commandline help, because the app 'Software and Update' could be found but doesn't start.
Next steps work fine, until sudo apt update.
That fails on fingerprinting http://packages.ros.org/ros2/ubuntu/ jammy
Because 'software and Update' is not found, it seems that the update is not complete (although lsb_release -a says so. Trying sudo apt-get dist-upgrade, which removes a lot of ros-noetic (any many other packages).
Fixed the broken install with sudo apt -o Dpkg::Options::="--force-overwrite" --fix-broken install.
Could do sudo apt-get dist-upgrade, so 'Software and Updates' works. All other problems could be fixed. Running sudo dpkg -i /tmp/ros2-apt-source.deb followed by sudo apt update gives three repositories:
Hit:5 http://packages.ros.org/ros2/ubuntu jammy InRelease
Get:6 http://packages.ros.org/ros2/ubuntu jammy/main Sources [1,736 kB]
Get:7 http://packages.ros.org/ros2/ubuntu jammy/main i386 Packages [44.4 kB]
Get:8 http://packages.ros.org/ros2/ubuntu jammy/main amd64 Packages [1,707 kB]
Yet, sudo apt install ros-humble-desktop gives:
The following packages have unmet dependencies:
libpython3.10 : Depends: libpython3.10-stdlib (= 3.10.12-1~22.04.10) but 3.10.18-1+focal1 is to be installed
libpython3.10-dev : Depends: libpython3.10-stdlib (= 3.10.12-1~22.04.10) but 3.10.18-1+focal1 is to be installed
python3.10-dev : Depends: python3.10 (= 3.10.12-1~22.04.10) but 3.10.18-1+focal1 is to be installed
E: Unable to correct problems, you have held broken packages
No idea where this comes from, nor where the focal versions come from.
The code comes with three ros-demo bags (LiDAR, RGBD, KITTI).
Table I gives as related work 13 other SLAM algorithms (mostly with Semantic Localization), from 2013-2024.
Tried ldd /usr/bin/ign | grep factory, but ign is script. ldd /usr/bin/gazebo | grep factory gave nothing. The only library I see is /lib/x86_64-linux-gnu/libgazebo_common.so.11
Removed the non-ros gazebo version with sudo apt remove ignition-fortress && sudo apt autoremove.
Next step is to launch gazebo, following this gazebo-ros tutorial. ros2 launch ros_gz_sim gz_sim.launch.py gz_args:=empty.sdf works.
Launching just the server fails. The command ros2 launch ros_gz_sim gz_server.launch.py world_sdf_file:=empty.sdf gives:
file 'gz_server.launch.py' was not found in the share directory of package 'ros_gz_sim' which is at '/opt/ros/humble/share/ros_gz_sim'
Still ros2 launch ugv_gazebo bringup.launch.py gives an error (did you include ros_factory). Removed ros-humble-gazebo-ros, which fails on missing package gazebo-ros. Installed again. Fails on [gzserver-1] Error Code 12 Msg: Unable to find uri[model://world].
My GAZEBO_MODEL_PATH is set to /opt/ros/humble/share, while the worls are in /opt/ros/humble/share/gazebo_ros/worlds/
Setting export GAZEBO_MODEL_PATH=$GAZEBO_MODEL_PATH:/opt/ros/humble/share/gazebo_ros/worlds/. Trying also export GAZEBO_MODEL_PATH=$GAZEBO_MODEL_PATH:/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/.
According to this post, I also have to set my GAZEBO_PLUGIN_PATH and GAZEBO_RESOURCE_PATH.
Still fails on with:
[spawn_entity.py-5] [INFO] [1753198394.461104938] [spawn_entity]: Calling service /spawn_entity
[gzclient-2] gzclient: /usr/include/boost/smart_ptr/shared_ptr.hpp:728: typename boost::detail::sp_member_access::type boost::shared_ptr::operator->() const [with T = gazebo::rendering::Camera; typename boost::detail::sp_member_access::type = gazebo::rendering::Camera*]: Assertion `px != 0' failed.
[ERROR] [gzclient-2]: process has died [pid 117754, exit code -6, cmd 'gzclient --gui-client-plugin=libgazebo_ros_eol_gui.so'].
[gzserver-1] gzserver: /usr/include/boost/smart_ptr/shared_ptr.hpp:728: typename boost::detail::sp_member_access::type boost::shared_ptr::operator->() const [with T = gazebo::rendering::Scene; typename boost::detail::sp_member_access::type = gazebo::rendering::Scene*]: Assertion `px != 0' failed.
[ERROR] [gzserver-1]: process has died [pid 117752, exit code -6, cmd 'gzserver /home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world -slibgazebo_ros_init.so -slibgazebo_ros_factory.so -slibgazebo_ros_force_system.so'].
Note that in ls /home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/models/ there is also a world directory with a model.sdf.
Tried ros2 launch ros_gz_sim gz_sim.launch.py gz_args:=/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/models/world/model.sdf which gave:
[ign gazebo-1] [Err] [Server.cc:139] Error Code 3: Msg: The supplied model name [world] is reserved.
Changed the model-name in model.sdf from world to ugv_world. That gave:
ign gazebo-1] [Err] [Server.cc:145] SDF file doesn't contain a world. If you wish to spawn a model, use the ResourceSpawner GUI plugin or the 'world//create' service.
.
Instead tried ros2 launch ros_gz_sim gz_sim.launch.py gz_args:=/home/arnoud/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/worlds/ugv_world.world, which gave:
Msg: Unable to find uri[model://ground_plane]
Msg: Unable to find uri[model://sun]
Msg: Unable to find uri[model://world]
...
Error Code 27: Msg: PoseRelativeToGraph error, too many incoming edges at a vertex with name [world].
[ign gazebo-1] [Err] [Server.cc:139] Error Code 9: Msg: Failed to load a world.
Instead started ros2 launch ros_gz_sim gz_sim.launch.py gz_args:=empty.sdf. Tried to "Load client configuration". This gives a message ' Insert plugins to start' .
July 21, 2025
Looking on using ReRun for the course. Started with the python sdk.
Installing gave some warnings: uninstalled numpy 2.2.6 and installed numpy 1.26.4, including a warning on sys-platform "darwin".
Yet, rerun directly launches the welcome-screen of the viewer. Selected the RGBD example.
Following the instructions of my manual. The first thing that installs 10 new packages is sudo apt-get install ros-humble-usb-cam ros-humble-depthai-*.
Second command that installs 4 packages is sudo apt-get install ros-humble-robot-localization. Also sudo apt-get install ros-humble-imu-tools installs three packages.
Compilation goes well. Checked. Could install sudo apt install ros-humble-apriltag ros-humble-apriltag-msgs ros-humble-apriltag-ros (v3.4.3, v2.0.1, v3.2.2 resp). The one in ugv_ws is resp (v3.4.2, v0.0.0, v2.1.0)
Launch now fails on:
[ERROR] [spawn_entity.py-5]: process has died [pid 96307, exit code 1, cmd '/opt/ros/humble/lib/gazebo_ros/spawn_entity.py -entity ugv_rover -file ~/ugv_ws/install/ugv_gazebo/share/ugv_gazebo/models/ugv_rover/model.sdf --ros-args'].
Followed by [gzserver-1] Error Code 12 Msg: Unable to find uri[model://world]
Correct installation according to Gazebo documentation is sudo apt install ros-humble-ros-gz
Now I could do ign gazebo shapes.sdf . Loading instead the ugv_gazebo/models/ugv_rover/model.sdf gave:
[Err] [Server.cc:145] SDF file doesn't contain a world. If you wish to spawn a model, use the ResourceSpawner GUI plugin or the 'world//create' service.
Instead tried ros2 launch ugv_gazebo bringup.launch.py. Now ir fails with:
[spawn_entity.py-5] [ERROR] [1753111538.794482728] [spawn_entity]: Service /spawn_entity unavailable. Was Gazebo started with GazeboRosFactory?
Could look at ROS answer. Tried ign gazebo -s libgazebo_ros_init.so -s libgazebo_ros_factory.so shapes.sdf. No response.
July 18, 2025
No idea on which of the two networks the UGV was, so checked with map -sP 146.*.*.0/24. Only two machines on this network. Switched to the other network. Still on the old network.
Looking at the other nodes from bringup_imu_ekf.launch.py. Yesterday I already looked at base_node.
The ekf_node points to the package robot_localization. That package was actually not installed on the UGV rover. Added it to the manual. Reads the /odom_raw and published a filtere version. The documentation is quite rudimentary, but ugv_bringup used its own param/ekf.yaml, which indicates that it only uses the pose (x,y,yaw), and the x_vel and yaw_vel.
Also the package imu_complementary_filter seems not installed. See paper (2015). No parameter-file, but 5-parameters are set in the launch-file. Those are the same as the settings in imu_complementary_filter/config/filter_config.yaml. Installed sudo apt install ros-humble-imu-tools on UGV Rover.
Last important one is ldlidar package, which has its own ldlidar.launch.py. This points to ld19.launch.py, which has as 2nd node static_transform_publisher between the base_footprint and base_lidar_link, but with a null-vector (and the 2nd node is not launched). Check the robot-description if that contains a better transform between laser and base.
Indeed, in the ugv_rover.urdf the vector between base_lidar_link_joint to base_lidar_link (xyz="0.04 0 0.04") to base_link (xyz="0.0 0.0 0.0165") are defined.
Looked at the lines echo "eval "$(register-python-argcomplete ros2)"" >> ~/.bashrc. According to argcomplete documentation, this is needed when no global completion is activated. pip install argcomplete was already installed on UGV Rover, but the commmand activate-global-python-argcomplete could be found. Added manually python-argcomplete.sh in the PATH (~/.local/bin/)
Anyway, started ros2 launch ugv_bringup bringup_imu_ekf.launch.py. Checking with ros2 node list. 6 nodes are running:
/LD19
/base_node
/complementary_filter_gain_node
/ekf_filter_node
/transform_listener_impl_aaaabb524e10
/ugv/robot_state_publisher
/ugv_bringup
Also checked the published topics with ros2 topic list:
cmd_vel
/diagnostics
/imu/data
/imu/data_raw
/imu/mag
/joy
/odom
/odom/odom_raw
/odom_raw
/parameter_events
/rosout
/scan
/set_pose
/tf
/tf_static
/ugv/joint_states
/ugv/led_ctrl
/ugv/robot_description
/voltage
Note that there two odom_raw topics are published. Note also the /scan and /ugv/robot_description
Succes full launch ends with these two lines:
[ldlidar_node-5] [INFO] [1752846995.480029725] [LD19]: ldlidar communication is normal.
[ldlidar_node-5] [INFO] [1752846995.483222001] [LD19]: Publish topic message:ldlidar scan data.
Started on nb-dual (native Ubuntu 20.04) the RoboStack environment with mamba activate ros_humble_env. Could start ros2 run rviz2 rviz2, which showed the laser-scan. Only fails on /ugv/robot_description, because package ugv_description couldn't be found.
Did the first step of section 5.2 of the manual: clone the ugv_ws in my home.
Did the first of the installs with install ros-humble-nav2-msgs ros-humble-map-msgs ros-humble-nav2-costmap-2d. That installs 8 packages:
+ ros-humble-bond 3.0.2
+ ros-humble-bondcpp 3.0.2
+ ros-humble-nav2-common 1.1.5
+ ros-humble-nav2-costmap-2d 1.1.5
+ ros-humble-nav2-msgs 1.1.5
+ ros-humble-nav2-util 1.1.5
+ ros-humble-nav2-voxel-grid 1.1.5
+ ros-humble-smclib 3.0.2
mamba install ros-humble-image-geometry was not needed, already installed.
mamba install ros-humble-depthai-* couldn't be found, so only tried mamba install ros-humble-usb-cam. This fails on dependency:
The following package could not be installed
└─ ros2-distro-mutex 0.6* humble_* is requested and can be installed.
Tried the --only-deps option, to no avail. Continued to the next package.
Next is mamba install ros-humble-robot-localization (already installed).
Last is mamba install ros-humble-imu-tools (doesn't exist).
Starting to build. emcl2 failed, which can be skipped. Yet, also ldlidar fails, which is more a problem. Yet, probably less needed on the laptop side.
At least the ugv_description now works under RoboStack:
July 17, 2025
Found a solution for nvpmodel crash (nvpmode-SegFixed at the end).
New problem, firefox will no longer start. Do a snap install firefox? No, firefox is already installed.
Seems to be a SELinux protection added by Waveshare (see this discussion).
Instead of installing SELinux protection, I tried instead to do snap remove firefox. firefox was actually connected with a lot of other snap-packages, such as camera and joystick. Trying snap install firefox again. Still same error.
Installing via apt install firefox fails, because it is already installed via snap.
Checking SELinux install. systctl status apparmor indicated inactive (dead) - start condition failed June 4, 2025.
After installing SELinux it start relabeling all filessystems. Note that there is an user sddm with no passord. Relabbbeling costs a few minutes before the boot continues.
Got a snapd-error, so followed this advice and disabled SELinux. Now firefox can bes installed, but a new error: cannot set capabilities: Operation not permited.
Installed brave-browser instead. Gives a warning about libva, but works. Installing va-driver-all didn't help.
Installed the nvpmode-SegFixed (via remote terminal). That works.
Looking at the launch files in ugv_bringup. The bringup_imu_ekf.launch.py launches 10 nodes, bringup_imu_origin.launch.py and bringup_lidar.launch.py launches 9 nodes.
The most basic seems to be the driver_node, which is an executable om the ugv_bringup package.
Running ros2 run ugv_bringup ugv_driver & gives the following topics:
/cmd_vel
/joy
/ugv/joint_states
/ugv/led_ctrl
/voltage
First looked at the ugv_driver.py code. The pan/tilt are controlled with joy-messages, drive-angle is axis 0, drive-speed is axis 1, pan is axis 3, tilt is axis 4 (inverted). axes 2 is not used. The pan-tilt can also be contorlled with the joint_state (pt_base_link_to_pt_link1 - pan) and (pt_link1_to_pt_link2 - tilt). The joint_state is given in radians.
The driver subscribes to the voltage (and plays a sound when low), so in principal the ugv_bringup.py should be the first to be launched. It also publishes imu_data_raw, imu_mag and odom_raw.
Was able to read out the voltage and drive the rover forward with /cmd_vel.
Which node launches the pan-tilt camera and the depth camera. I know from June 26 that the depth-camera can be started with ros2 launch depthai_ros_driver camera.launch.py pointcloud.enable:=True.
The base_node is node that reads in the imu_raw message and publishes odometry messages and when configured also the odom_frame transform.
The ugv_vision package calls the usb_cam package with its own config/params.yaml. It also launches from image_proc pakage a RectifyNode. The two nodes are combined into a single container.
The command ros2 launch ugv_vision camera.launch.py seems to work:
[component_container-2] [INFO] [1752759640.742645655] [image_proc_container]: Load Library: /opt/ros/humble/lib/librectify.so
[usb_cam_node_exe-1] [INFO] [1752759640.885099049] [usb_cam]: camera_name value: pt_camera
[usb_cam_node_exe-1] [WARN] [1752759640.885346962] [usb_cam]: framerate: 30.000000
[usb_cam_node_exe-1] [INFO] [1752759640.892700837] [usb_cam]: camera calibration URL: package://ugv_vision/config/camera_info.yaml
[component_container-2] [INFO] [1752759640.907117633] [image_proc_container]: Found class: rclcpp_components::NodeFactoryTemplate
[component_container-2] [INFO] [1752759640.907235493] [image_proc_container]: Instantiate class: rclcpp_components::NodeFactoryTemplate
[INFO] [launch_ros.actions.load_composable_nodes]: Loaded node '/rectify_color_node' in container '/image_proc_container'
[usb_cam_node_exe-1] [INFO] [1752759640.971137276] [usb_cam]: Starting 'pt_camera' (/dev/video0) at 640x480 via mmap (mjpeg2rgb) at 30 FPS
[usb_cam_node_exe-1] [swscaler @ 0xaaab14a93020] No accelerated colorspace conversion found from yuv422p to rgb24.
[usb_cam_node_exe-1] [INFO] [1752759641.007471467] [usb_cam]: Setting 'white_balance_temperature_auto' to 1
[usb_cam_node_exe-1] [INFO] [1752759641.007589456] [usb_cam]: Setting 'exposure_auto' to 3
[usb_cam_node_exe-1] [INFO] [1752759641.012967833] [usb_cam]: Setting 'focus_auto' to 0
[usb_cam_node_exe-1] [INFO] [1752759641.520032053] [usb_cam]: Timer triggering every 33 ms
Run both ros2 run image_view image_view --ros-args --remap image:=/image_raw and image:=/image_rect. The rectification looks good. Adding image_transport:=theora and image_transport:=compressed didn't work.
The distorion coefficients are [-0.208848, 0.028006, -0.000705, -0.000820, 0.000000]. The camera matrix is not exact in the center of the 640x480 image, (347.23, 235.67). The diagonal element is (289.11,289.75) The rectifcation matrix is the Identity-matrix, but the project+matrix has diagonal elements (196.86,234.53) and off-diagioanl (342.88, 231.54).
According to ROS1 documentation the theora codec only works with 8-bit color or grayscale images. Not sure if the commment using transport "raw" is a default INFO from image_view. Remember that there was a bug in image_transport
Looked at the UGV rover in ~/git/ugv_jetson. The start_jupyter.sh is there, the noteboks are in the directory tutorial_en.
Started with Tutorial #3 - pan-tilt control.
Tutorial #14 fails on cv2.error: OpenCV(4.9.0) /io/opencv/modules/imgcodecs/src/loadsave.cpp:1121: error: (-215:Assertion failed) !image.empty() in function 'imencode'.
Same for Tutorial #20, the one I liked to reproduce. Made color_tracking_node.py in ugv_custom_nodes, a copy of the line_following_node.py. Should only stear the pan-tilt instead of the wheels.
July 16, 2025
Starting to use the UGV Rover at home. The small OLED screen doesn't show the Ethernet address anymore (as described at Waveshare documentation.
Luckely the hotspot is still there, advertised as UGV. Yet, doesn't work with the password in the documentation.
Connecting via the Jetson's ethernet connector is blocked by a Rover connector. Tried to connect via two USB-C to ethernet connectors, but don't see the ethernet lights up. Connecting with the suggested default IP address didn't work.
Instead will connect the Display-port, and make the connection directly to my home access-point.
Connecting to my home access-point with the suggested sudo nmcli d wifi list and connect worked.
Could use the wifi-connection to ssh into the jetson with the IP checked with ifconfig
Started with the suggested software update (including several ros-humble packages - which fails).
Used the suggested temporary fix from this discussion (three weeks ago). Now 679 packages are updating.
Looking for instructions to login to the UGV with USB, I found the battery and board instructions on youTube
This video shows the UGV lower body. The thing blocking the internet port is indeed a wifi antenna. You can control the robot directly, without the Jetson, via JSON commands.
Could login to UGV lower body, use the web-interface and even control the wheels.
In the FAQ also an indication is made which 18650 batteries to use.
In principal you can control the lower body also from the Jetson, you only have to know the serial interface (/dev/*?) of the Jetson PIN-40 interface.
Yet, nor /dev/ttyACM0 nor /dev/ttyTHS1 changed the OLED (no warnings, so the JSON commands where succesfull send to these devices).
Starting with colcon build --packages-select costmap_converter. Fails on abstract class. The compiler is g++ version 11.4.0, in CMakeLists.txt is specified CXX_STANDARD 14. These are the supported values. Setting it to 26 was too much. Start getting memory problems.
Tried CXX_STANDARD 23 and 20, but still a crash (although no error). Removed option -Wpedantic, and tried CXX_STANDARD 11, removed -Wextra and tried CXX_STANDARD 98, removed -Wall and tried CXX_STANDARD 17
Removed thunderbird, but I have the feeling that the problem is memory, not storage-space.
Looked at colcon build and used a single job with MAKEFLAGS=-j1 colcon build --executor sequentail. Now I get the error message again, and no complains about memory.
Commented out the line in map_to_dynamic_obstacles/blob_detector.cpp
Strange, this should be version 0.1.2, as I can see the blob_detecor in the humble version at github.
This patch solves the iisue. Still some warnings, but the package is built.
Could do source ~/ugv_ws/install/setup.bash without warnings.
June 27, 2025
Checked the Jetpack version with sudo apt-cache show nvidia-jetpack, which showed version 6.0+b106.
June 26, 2025
OpenCV blog-post on edge-detection on a AI-generated image.
The Knowledge Representation was very logic based, only watched the first unit.
Also looked at the other MOOC course, Robots in Action. Looked at the first video of RoboEthics.
Tried again to get the point-cloud from the RAE.
Started docker again, went to /underlay_ws/install/depthai_examples/share/depthai_examples/launch/. Activated point_cloud_xyzi and metric_converter in rgb_stereo_node.launch.py script.
Launched ros2 launch depthai_examples rgb_stereo_node.launch.py camera_model:=RAE. Could see the different topics.
Started on WS9 rviz2, and added displays on different topics. Only received an image from /color/video/image, received nothing from /stereo/depth.
Opened another terminal on the RAE. Outside the docker I see two processes active: depthai-device (31.8%) and rgb_stereo_node (15.8%). Not clear how I can see them outside the docker!.
Inside the docker I only see rgb_stereo_node (15.8%).
With ros2 node list I see:
/container
/covert_metric_node
/launch_ros_76
/point_cloud_xyzi '
The only topic which gives me updates is /color/video/camera_info.
Back to the ugv_rover. The oak_d_lite.launch.py starts the camera.launch.py from depthai_ros_driver. Inside the camera the pointcloud.enable is default False.
The example_multicam.launch.py launches both camera and rgbd_pcl.launch.py.
pointcloud.launch.py uses the PointCloudXyziNode plugin, and should publish /points.
rgbd_pcl.launch.py starts camera.launch.py with pointcloud.enable True.
rtabmap.launch.py also starts rtabmap_odom.
Running ros2 launch depthai_ros_driver camera.launch.py pointcloud.enable:=True works, I could see the pointcloud2 (once I set the QoS to best_effort and the frame to oak_camera_frame):
The capture-package needed matplotlib, which conflicted with ros. Created a virtual environment, did the requirements install there and run ../capture_env/bin/python3.11 capture/oak_capture.py default /tmp/my_capture, which gives a X_LINK_ERROR (and a warning on no IR drivers and no RGB camera calibration). So, as long as I have not installed the RVC3_support in the venv, this doesn't work.
Back to the ugv_rover. Tried ros2 launch ugv_slam gmapping.launch.py use_rviz:=false, but package slam_gmapping unknown.
In ugv_ws/src/ugv_else/gmapping two directories can be found: openslam_gmapping and slam_gmapping. According to the README.md this can be started with ros2 launch slam_gmapping slam_gmapping.launch.py, but it seems that this directory is not included in the build.
Had to be done in order. Did colcon build --packages-select openslam_gmapping followed by colcon build --packages-select slam_gmapping.
To get rid of the source install/setup.sh I also did colcon build --packages-select explore_lite which worked. Unfortunately colcon build --packages-select costmap_converter failed on line 56 of blob_detector,cpp, which seems to be an C++-version problem (comment mentions compatibility).
Running ros2 launch ugv_slam gmapping.launch.py use_rviz2:=false now works, in the sense that the LaserScan are visible. Could also select the Map inside RVIZ, but with the warning no Map received. Changing the Reliability QoS to Best effort solves that:
Started ros2 launch ugv_bringup bringup_lidar.launch.py (does this means a double lidar_node?) to be able to do ros2 run ugv_tools keyboard_ctrl. The turning is a bit slow, could be increased by e. Going forward / backwards also helps.
gmapping was able to make a map, although not perfect (two over each other). Can you reset the map without killing gmapping?
Second try was much better, could not only map the small maze, but also going back to the door, followed by going left halfway the soccer field:
June 25, 2025
Skipping two weeks of topics of the Robotics in a Nutshell MOOC (Force Control and Knowledge Representation).
The 5th week is on Graph-SLAM. The description of Wolfram Burghard was a bit too high-level, the description of Giorgio Grisetti a bit too low-level. Minimizing all constraints is simple, but the least-square method is not explained in the best way, with a lot of math but without introducing all functions and operations. Maybe the chapter is better.
The description of the manifold in Unit 2.4 is nice: "A manifold is a mathematical space that is not necessarily Euclidean on a global scale but can be seen as Euclidean on a local scale."
I like the idea of replacing L1 or L2 with more robust kernels, to prevent sensitivity to outliers. Will this also work in scikit-learn:
Started the RAE #1. Before I could ssh into the system, the RAE started already driving on one wheel. Once I started ros2 launch rae_bringup robot.launch.py enable_slam_toolbox:=false enable_nav:=false use_slam:=false in the docker the driving stopped.
Connected to another shell into the docker. Looked with ros2 topic list. Several front and back images are published, yet no point-cloud.
Inside the docker python3.10.12 is running.
Inside python3 import depthai as dai doesn't work, so tried python3 -m pip install depthai. No module pip.
Did sudo apt install python3-pip. Now I could isntall depthai-2.30.0.0.
Also did sudo curl -sSL https://raw.githubusercontent.com/ros/rosdistro/master/ros.key -o /usr/share/keyrings/ros-archive-keyring.gpg, because I had the ros gpg error again. At least 464 packages behind.
Cloned depthai-python in /tmp/git and run python3 calibration_reader.py. Gave the following error:
RuntimeError: No available RVC2 devices found, but found 3 non RVC2 device[s]. To use RVC4 devices, please update DepthAI to version v3.x or newer.
.
On October 31, 2024 I did something, directly playing with the depthai_ros_driver with DEPTHAI_DEBUG=1.
Looked in /ws/src/rae-ros/rae_camera/src/camera.cpp. Code also depends on depthai (and depthai_bridge), but that seems to be cpp-library, not the python-module.
For instance, /ws/src/rae-ros/rae_camera/stereo_node is an executable which loads /underlay_ws/install/depthai_bridge/lib/libdepthai_bridge.so, /usr/local/lib/libdepthai-core.so and /usr/local/lib/cmake/depthai/dependencies/lib/libusb-1.0.so.
Tried ros2 launch rae_camera perception_ipc.launch.py, which conflicts with the already running nodes.
Killed the other node, now I get several nodes running:
/RectifyNode
/battery_node
/complementary_filter_gain_node
/controller_manager
/diff_controller
/ekf_filter_node
/joint_state_broadcaster
/laserscan_kinect_back
/laserscan_kinect_front
/laserscan_multi_merger
/launch_ros_1345
/lcd_node
/led_node
/mic_node
/rae
/rae_container
/robot_state_publisher
/rtabmap
/speakers_node
/transform_listener_impl_55ba0cad70
/transform_listener_impl_55ba4dfdb0
/transform_listener_impl_55bbafe9d0
Also now get the topic /scan
Looked at my WLS-terminal with ROS-humble. The command ros2 node list gave a subset:
/complementary_filter_gain_node
/controller_manager
/diff_controller
/ekf_filter_node
/joint_state_broadcaster
/mic_node
/robot_state_publisher
/speakers_node
/transform_listener_impl_55bbafe9d0
Also the ros2 topic list is a subset:
/battery_status
/lcd
/leds
During the start of the perception_ipc script, I get the following startup information:
[perception_ipc_rtabmap-1] [INFO] [1750858282.709590462] [rae]: Camera with MXID: xlinkserver and Name: 127.0.0.1 connected!
[perception_ipc_rtabmap-1] [INFO] [1750858282.709810547] [rae]: PoE camera detected. Consider enabling low bandwidth for specific image topics (see readme).
[perception_ipc_rtabmap-1] [58927016838860C5] [127.0.0.1] [1750858282.710] [system] [info] Reading from Factory EEPROM contents
[perception_ipc_rtabmap-1] [INFO] [1750858282.741301485] [rae]: Device type: RAE
[perception_ipc_rtabmap-1] [INFO] [1750858283.008338842] [rae]: Pipeline type: rae
[perception_ipc_rtabmap-1] [WARN] [1750858283.062986091] [rae]: Resolution 800 not supported by sensor OV9782. Using default resolution 720P
[perception_ipc_rtabmap-1] [WARN] [1750858283.082811496] [rae]: Resolution 800 not supported by sensor OV9782. Using default resolution 720P
[perception_ipc_rtabmap-1] [WARN] [1750858283.134807345] [rae]: Resolution 800 not supported by sensor OV9782. Using default resolution 720P
[perception_ipc_rtabmap-1] [WARN] [1750858283.154057327] [rae]: Resolution 800 not supported by sensor OV9782. Using default resolution 720P
[perception_ipc_rtabmap-1] [INFO] [1750858283.945303168] [rae]: Finished setting up pipeline.
Followed (after initialization of the IMU) with:
[perception_ipc_rtabmap-1] [INFO] [1750858284.488374295] [rae]: Camera ready!
[perception_ipc_rtabmap-1] [58927016838860C5] [127.0.0.1] [1750858284.597] [StereoDepth(11)] [info] Baseline: 0.074863344
[perception_ipc_rtabmap-1] [58927016838860C5] [127.0.0.1] [1750858284.597] [StereoDepth(11)] [info] Fov: 96.69345
[perception_ipc_rtabmap-1] [58927016838860C5] [127.0.0.1] [1750858284.597] [StereoDepth(11)] [info] Focal: 284.64175
[perception_ipc_rtabmap-1] [58927016838860C5] [127.0.0.1] [1750858284.597] [StereoDepth(11)] [info] FixedNumerator: 21309.232
[perception_ipc_rtabmap-1] [58927016838860C5] [127.0.0.1] [1750858284.597] [StereoDepth(11)] [debug] Using 0 camera model
[perception_ipc_rtabmap-1] [INFO] [1750858284.806388901] [laserscan_kinect_front]: Node laserscan_kinect initialized.
.
Note that in /ws/src/rae-ros/rae_camera/config/cal.json can be found, for camera-model RAE (version 7).
Not clear where all those nodes are started, the launch file starts one executable (perception_ipc_rtabmap) and the control.launch.py.
The file /ws/build/rae-camera/perception_ipc_rtabmapi is a real exec, loading for instance:
/opt/ros/humble/lib/librtabmap_slam_plugins.so
/opt/ros/humble/lib/librtabmap_util_plugins.so
Yet, looked into the code, looks like several nodes are started:
executor.add_node(camera->get_node_base_interface());
executor.add_node(laserscanFront->get_node_base_interface());
executor.add_node(laserscanBack->get_node_base_interface());
executor.add_node(merger->get_node_base_interface());
executor.add_node(rectify->get_node_base_interface());
executor.add_node(rtabmap->get_node_base_interface());
Inside that branch I did python3 examples/install_requirements.py, which installed v2.19.1.0 from depthai. That gave:
RuntimeError: No available devices (3 connected, but in use)
Did ps -all and kill the ros2 process.
Now python3 examples/calibration/calibration_reader.py in the rvc3_support branch gives the RAE calibration info (stored in examples/calibration/calib_xlinkserver.json).
Also tried python3 examples/devices/list_devices.py, which gives the X_LINK info:
[DeviceInfo(name=127.0.0.1, mxid=58927016838860C5, X_LINK_GATE, X_LINK_TCP_IP, X_LINK_RVC3, X_LINK_SUCCESS),
DeviceInfo(name=192.168.197.55, mxid=58927016838860C5, X_LINK_GATE, X_LINK_TCP_IP, X_LINK_RVC3, X_LINK_SUCCESS)]
So, started ros2 launch depthai_examples rgb_stereo_node.launch.py camera_model:=RAE.
I see the following topics:
/color/video/camera_info
/color/video/image
/color/video/image/compressed
/color/video/image/compressedDepth
/color/video/image/theora
/joint_states
/parameter_events
/robot_description
/rosout
/stereo/camera_info
/stereo/depth
/stereo/depth/compressed
/stereo/depth/compressedDepth
/stereo/depth/theora
/tf
/tf_static
Checking on WS9. I also see the topics there. The /color/video/image I can display. For video rviz2 complains that it cannot display stereo. That is a warning of rviz2, not on stereo-msgs.
In rviz2 I also so a PointCloud, but it seems that the streaming just stopped (also no updates in the color-video). Restarting at the RAE didn't help.
Looking in /underlay_ws/install/depthai_examples/share/depthai_examples/launch/.
The rgb_stereo_node.launch.py should indeed also publish a point-cloud as topic /stereo/points.
Note that rgb_stereo_node should also tries to launch rviz. Yet, this is commented out, together with the point_cloud_node
I could try stereo_inertial_node.launch.py with depth_aligned=True, rectify=True, enableRviz=False.
Yet, that fails:
[stereo_inertial_node-2] [58927016838860C5] [127.0.0.1] [1750866665.675] [host] [debug] Device about to be closed...
[stereo_inertial_node-2] [2025-06-25 15:51:05.681] [depthai] [debug] DataOutputQueue (depth) closed
[stereo_inertial_node-2] [2025-06-25 15:51:05.681] [depthai] [debug] DataOutputQueue (preview) closed
[stereo_inertial_node-2] [2025-06-25 15:51:05.682] [depthai] [debug] DataOutputQueue (rgb) closed
[stereo_inertial_node-2] [2025-06-25 15:51:05.682] [depthai] [debug] DataOutputQueue (imu) closed
[stereo_inertial_node-2] [58927016838860C5] [127.0.0.1] [1750866665.682] [host] [debug] Log thread exception caught: Couldn't read data from stream: '__log' (X_LINK_ERROR)
[stereo_inertial_node-2] [58927016838860C5] [127.0.0.1] [1750866665.682] [host] [debug] Timesync thread exception caught: Couldn't read data from stream: '__timesync' (X_LINK_ERROR)
[stereo_inertial_node-2] [2025-06-25 15:51:05.682] [depthai] [debug] DataOutputQueue (detections) closed
[stereo_inertial_node-2] [2025-06-25 15:51:05.682] [depthai] [debug] XLinkResetRemote of linkId: (0)
[stereo_inertial_node-2] [58927016838860C5] [127.0.0.1] [1750866671.207] [host] [debug] Device closed, 5531
[stereo_inertial_node-2] [2025-06-25 15:51:11.210] [depthai] [debug] DataInputQueue (control) closed
[stereo_inertial_node-2] terminate called after throwing an instance of 'nanorpc::core::exception::logic'
[stereo_inertial_node-2] what(): Cannot use both isp & video/preview/still outputs at once at the moment (startPipeline)
Instead commented out the point_cloud_xyzi and metric_converter
On nb-dual WSL the /stereo/points is visible, but see no echo.
Commented both out again. Try again tomorrow, after a reboot.
June 24, 2025
The 2nd week of the Robotics in a Nutshell MOOC is on Image Formation and Calibration.
I like the explanation of the Pinhole model, including the conservation fractions of the object heights and distances h'/h = l'/l:
This is directly associated with the Thin Lense model, where the same fraction corresponds with the focal lens distances h'/h = l'/l = x'/f = f'/x:
The 3rd unit of the 2nd week is a topic not often covered: Laser scanning with projection patterns. Scanning with two colored laser-planes, or providing a corner background I have not seen explained before. Nice that the unit starts with a single laser point.
In the 4th unit impressive demonstration of the ICP algorithm in 3D is shown.
Connected the OAK-D with the Thunderbolt cable to nb-dual, with native Ubuntu 20.04. No ROS2, so looked at ROS1 Noetic first.
See no /opt/ros/noetic/share/depthai_ros_driver, so should install that one first.
First had to reinstall the signature keys by using the third suggested option: sudo curl -sSL https://raw.githubusercontent.com/ros/rosdistro/master/ros.key -o /usr/share/keyrings/ros-archive-keyring.gpg. 16 ros-packages are installed.
If I look at this Medium tutorial, I should also install ros-noetic-depthai-examples (was already part of the pack).
Yet, the command roslaunch depthai_examples rgb_stereo_node.launch camera_model:=OAK-1 fails on missing Intrinsic matrix available for the the requested cameraID.
Started with python3 depthai_demo.py, which gives one frame and crashes on:
depthai_sdk/managers/preview_manager.py", line 148, in prepareFrames
packet = queue.tryGet()
RuntimeError: Communication exception - possible device error/misconfiguration. Original message 'Couldn't read data from stream: 'color' (X_LINK_ERROR)'
CONTROL-C restarted the connection, which gave:
[DEVICEID] [3.8] [1.501] [StereoDepth(7)] [error] RGB camera calibration missing, aligning to RGB won't work
Seems that I did the same with the RAE on December 12, 2024 and June 6, 2024.
The calibration files are written to the EPROM. Could first look at what is stored in the EEPROM with Calibration Reader.
Moved to ~/git/depthai-python/examples/calibration. Running python3 calibration_reader.py gave the same error:
RuntimeError: There is no Intrinsic matrix available for the the requested cameraID
Looked at the calibration_flash_v5.py script. It tries to write ../models/depthai_v5.calib to the EEPROM. That file actually exists.
Run python3 examples/python/install_requirements.py, which instaleld PyYAML-6.0.2-cp38, opencv_python-4.11.0.86-cp37 and depthai-3.0.0rc2-cp38.
Moved to ~/git/depthai-core/examples/python/Camera. Running python3 camera_all.py gave:
RuntimeError: Device already closed or disconnected: Input/output error
[2025-06-24 17:01:55.193] [depthai] [error] Device with id XXX has crashed.
Switching back to WS9, look if it can work with the OAK-D or find calibration info at the UGV Rover OAK-camera.
Running python3 calibration_reader.py for the WS9 and OAK-D gave the same error
Moved to the ugv_rover. Cloned depthai-python, but python3 calibration_reader.py couldn't find module depthai. Running git submodule update --init --recursive didn't help. Doing python3 -m pip install . takes a while. Couldn't build the wheel at the end.
Just did python3 -m pip install depthai.
Now python3 examples/calibration/calibration_reader.py works, and gives the RGB Camera Default intrinsics, RGB Camera resized intrinsics... 3840 x 2160, 4056 x 3040, LEFT Camera Default intrinsics..., LEFT/RIGHT Distortion Coefficients..., RGB FOV, Mono FOV, LEFT/RIGHT Camera stereo rectification matrix..., Transformation matrix of where left Camera is W.R.T right Camera's optical center, Transformation matrix of where left Camera is W.R.T RGB Camera's optical center.
Seems that the information is stored in calib_device_id.json file. The productName is "OAK-D-LITE".
Tried oakctl. Could installed both on WS9 and the ugv_rover, but no (OAK4) devices found.
Tried to install oak-viewer on WS9. Installation goes well, but launching oak-viewer gives:
Viewer stderr: [PYI-3537627:ERROR] Failed to load Python shared library '/usr/lib/oak-viewer/resources/backend/viewer_backend/_internal/libpython3.12.so.1.0': /lib/x86_64-linux-gnu/libm.so.6: version `GLIBC_2.38' not found (required by /usr/lib/oak-viewer/resources/backend/viewer_backend/_internal/libpython3.12.so.1.0)
Not the only one with this problem. There are many (old answers) on stackoverflow. The patchelf answer #14 looks promising.
Close to my problem is the Proof of Concept at the end.
Looking how to split the bringup_lidar.launch.py nicely in a rover and workstation part. For the rover there is the use_rviz=False, so could make a launch-script that launches the rviz (and description?) locally on the workstation.
Strange enough, there is also a bringup-executable launched. What is in that executable?
At the end, only selected three nodes for the workstation-side: use_rviz_arg rviz_config_arg, robot_state_launch.
The executable seems to be ugv_bringup/ugv_bringup.py, which creates a number of publishers of the topics "imu/data_raw", "imu/mag", "odom/odom_raw", "voltage"
There is also ugv_bringup/ugv_driver.py, which subscribes to topics "cmd_vel", 'joy', 'ugv/joint_states' (pan/tilt) and 'ugv/led_ctrl'. There is also a subscription to 'voltage' (can the voltage be controlled?). Looked in the code, if the voltage_value drops below 9 a low_battery sound is played.
Made a rviz_lidar.launch.py with only three nodes, and added it to the install with colcon build --packages-select ugv_bringup. After setting the UGV_MODEL and LDLIDAR_MODEL I launced it with ros2 launch ugv_bringup rviz_lidar.launch.py use_rviz:=true
Made two scripts start_lidar.sh (rover-side) and start_rviz_lidar.sh (workstation-side)
Works, but I still have two robot_state_publishers, which also gives double /rf2o_laser_odometry, /transform_listener_impl_62d462ce14d0, /ugv/joint_state_publisher.
Killed the workstation-side robot_state_publisher, still have a double rf2o_laser_odometry.
Tried again, now without the robot_state_launch (2 nodes left). Starting start_rviz_lidar.sh gave 4 nodes:
/rviz2
/transform_listener_impl_5c12fd746e70
/ugv/joint_state_publisher
/ugv/robot_state_publisher
Adding start_lidar.sh still gave many doubles
Started a clean rviz2 with ros2 run rviz2 rviz2 -d ~/git/ugv_ws/install/ugv_bringup/share/ugv_bringup/rviz/view_bringup.rviz. Still two transform_listener_* and two rf2o_laser_odometry.
Rebooted the jetson, still two rf2o_laser_odometries. The LD19 in ugv_else/ldlidar also launches a transform_listener_impl.
Tried ros2 lifecycle set transform_listener_impl_636aff058900 shutdown, but get Node not found.
Could try to reboot also ws9, but there are other users. Leave it here for the moment.
In the directory ~/git/ugv_ws/src/ugv_main/ugv_slam/launch there are three launches files, cartographer, rtabmap_rgbd and gmapping. Tutorial 4 is ussing gmapping.
Started with activating the OAK-D camera with ros2 launch ugv_vision oak_d_lite.launch.py. Seems to work:
[INFO] [launch_ros.actions.load_composable_nodes]: Loaded node '/rectify_color_node' in container 'oak_container'
[component_container-1] [INFO] [1750338883.796983921] [oak]: Starting camera.
[component_container-1] [INFO] [1750338883.807265975] [oak]: No ip/mxid specified, connecting to the next available device.
[component_container-1] [INFO] [1750338886.592273026] [oak]: Camera with MXID: 14442C10019902D700 and Name: 1.2.3 connected!
[component_container-1] [INFO] [1750338886.593134048] [oak]: USB SPEED: HIGH
[component_container-1] [INFO] [1750338886.639988351] [oak]: Device type: OAK-D-LITE
[component_container-1] [INFO] [1750338886.642406675] [oak]: Pipeline type: RGBD
[component_container-1] [INFO] [1750338887.683423674] [oak]: Finished setting up pipeline.
[component_container-1] [WARN] [1750338888.471441275] [oak]: Parameter imu.i_rot_cov not found
[component_container-1] [WARN] [1750338888.471589696] [oak]: Parameter imu.i_mag_cov not found
[component_container-1] [INFO] [1750338889.080588298] [oak]: Camera ready!
In RVIZ, I could display both the topic /oak/rgb/image_rect as /oak/stereo/image_raw as Image:
When I look at the topics, only /oak/imu, /oak/rgb and /oak/stereo are published.
Luxonis has launch files which also starts ROS depth processing nodes to generate a poincloud
The oak_d_lite.launch.py script starts camera.launch.py from depthai_ros_driver, which starts the RGBD together with a NN.
The installed driver files can be found at /opt/ros/humble/share/depthai_ros_driver/launch/. Didn't see the NN in spatial Mobilenet mode.
Tried on the rover ros2 launch depthai_ros_driver rgbd_pcl.launch.py. Now there is also a topic /oak/points, of type PointCloud2.
I could add PointCloud2 display in rviz2, but the node-log showed: New subscription discovered on topic '/oak/points', requesting incompatible QoS. No messages will be sent to it. Last incompatible policy: RELIABILITY_QOS_POLICY
Looked with ros2 topic info /oak/points --verbose. The QoS profile of rviz and the driver match:
Reliability: BEST_EFFORT
Durability: VOLATILE
On November 7, 2024 I had point-cloud displayed for realsense camera.
Tried an alternative approach. Attached my OAK-D directly to ws9. Had to install ros-humble-depthai-ros-driver, which also installed ros-humble-depthai-ros-msgs and ros-humble-ffmpeg-image-transport-msgs.
Launching ros2 launch depthai_ros_driver rgbd_pcl.launch.py on ws9 failed on udev rules: Insufficient permissions to communicate with X_LINK_UNBOOTED device with name "1.1". Make sure udev rules are set
Looked at Luxonis troubleshooting and did the udev update. Still going wrong, so should try another USB-cable (currently using a white USB-B to USB-C).
Connected my Thunderbolt USB-C to USB-C cable. At least the camera_preview example from the python sdk works.
I have feeling that it has something to do with the bootloader.
Also tried device information, but also Couldn't find any available devices.
Tried on ws9 ros2 run rviz2 rviz2 -d /opt/ros/humble/share/depthai_ros_driver/config/rviz/rgbd.rviz. Didn't work, nor for the OAK-D, nor the ugv_rover.
On July 11, 2022 I had a working visualisation of the PointCloud in rviz.
June 16, 2025
Looking at the github ugv_ws, but this workspace is at least 4 months old.
The first step of the tutorial is starting rviz, which is a bit strange inside the docker (running on a remote station). Tried if I could start rviz on WSL with a Xserver running, but that gives:
rviz2: error while loading shared libraries: libQt5Core.so.5: cannot open shared object file: No such file or directory
This build failed because nav2_msgs package was not installed.
Installation failed on:
Failed to fetch http://packages.ros.org/ros2/ubuntu/dists/jammy/InRelease The following signatures were invalid: Open Robotics
Solved it by adding the signature in a keyring, as suggested on askubuntu.
Next to fail is again explore_lite, now on a missing map_msgs package.'
This can be solved with sudo apt install ros-humble-nav2-msgs ros-humble-map-msgs ros-humble-nav2-costmap-2d.
Next package (15/22) to fail is apriltag_ros, on package image_geometry.
The package vizanti_server fails on rosbridge_suite. Now the first colcon_build is succesfully finished. To be sure did an intermediate source install/setup.bash.
The second build is colcon build --packages-select ugv_bringup ugv_chat_ai ugv_description ugv_gazebo ugv_nav ugv_slam ugv_tools ugv_vision ugv_web_app --symlink-install .
The ugv_nav fails on missing nav2_bringup. This is the only package that has to be installed. Did again a source install/setup.bash.
In the README.md some additional humble-packages are mentioned, such as ros-humble-usb-cam and ros-humble-depthai-*.
Started the first step of the tutorial, but ros2 launch ugv_description display.launch.py use_rviz:=true failed on missing UGV_MODEL.
Looked in the launch-file and defined export UGV_MODEL=ugv_rover (name of urdf-file.
Next exception is missing joint_state_publisher_gui package.
That package was in the README.md, so did sudo apt install ros-humble-joint-state-publisher-*. The Joint-State Publisher window now pops up, only rviz2 is missing.
That is part of apt install ros-humble-desktop-*, also in the README.md. That installs 385 packages.
Now I could control the pan-tilt (both up/down and left/right), both in rviz and on the rover itself (after starting the driver):
The robot doesn't respond on the wheel commands. Maybe I should also have defined the UGV_MODEL at the rover side. Tried again with UGV_MODEL defined, same behavior. Checked the topics, no camera images or depth-images are published (yet).
Launching ros2 launch ugv_bringup bringup_lidar.launch.py use_rviz:=true on ws9 fails on LDLIDAR_MODEL. That is not in ugv_bringup/launch/bringup_lidar.launch.py, but in ldlidar.launch.py called from there. So, LDLIDAR_MODEL should be ld06, ld19 or stl27l. So set export LDLIDAR_MODEL=ld19.
Activated in RVIZ a LaserScan, selected the /scan topic, but nothing visible.
Also launched ros2 launch ugv_bringup bringup_lidar.launch.py use_rviz:=false, which gave an error:
[ugv_bringup-3] JSON decode error: Expecting value: line 1 column 1 (char 0) with line: z":1684,"odl":0,"odr":0,"v":1214}
Try again with ld06? Actually, its a D500 Lidar. Yet, the D500 Lidar-kit is based on a STL-19P.
Trying a 2nd time, now it works:
[rf2o_laser_odometry_node-6] [INFO] [1750080862.481144040] [rf2o_laser_odometry]: Initializing RF2O node...
[rf2o_laser_odometry_node-6] [WARN] [1750080862.495336634] [rf2o_laser_odometry]: Waiting for laser_scans....
[rf2o_laser_odometry_node-6] [INFO] [1750080862.695500846] [rf2o_laser_odometry]: Got first Laser Scan .... Configuring node
Could also drive around with ros2 run ugv_tools keyboard_ctrl (from ws9):
I see the updates in RVIZ, but I don't see the scan topic in the topic list. A bit strange, because I see in with ros2 node list many nodes (several double, not ideal to use the same bringup for both). One of the nodes is /LD19:
/LD19
/base_node
/base_node
/keyboard_ctrl
/rf2o_laser_odometry
/rf2o_laser_odometry
/rf2o_laser_odometry
/rf2o_laser_odometry
/rviz2
/rviz2
/transform_listener_impl_5b38e1b97df0
/transform_listener_impl_5e016b673f00
/transform_listener_impl_6337961ff800
/transform_listener_impl_aaaaf1f50810
/ugv/joint_state_publisher
/ugv/joint_state_publisher
/ugv/joint_state_publisher
/ugv/joint_state_publisher
/ugv/joint_state_publisher
/ugv/joint_state_publisher_gui
/ugv/robot_state_publisher
/ugv/robot_state_publisher
/ugv/robot_state_publisher
/ugv/robot_state_publisher
/ugv_bringup
/ugv_driver
When looking with ros2 topic echo /scan I see many .nan values:
- 228.0
- 232.0
- .nan
- 220.0
- 209.0
- 205.0
- 201.0
- 204.0
- 212.0
- 204.0
- .nan
- .nan
- .nan
- .nan
June 2, 2025
Looking at the UGV-rover again. Tried to connected to the rover via the vislab-wifi. I also see the UGV network still active.
Received Joey's labbook. The robot was connected via LAB42, not the vislab_wifi. Able to login via ssh.
The home-directory on the rover has several directories, including ugv_ws and ugv_jetson.
Started with source /opt/ros/humble/setup.bash, followed by source ~/ugv_ws/install/setup.bash. That gives two warnings:
not found: "/home/jetson/ugv_ws/install/costmap_converter/share/costmap_converter/local_setup.bash"
not found: "/home/jetson/ugv_ws/install/explore_lite/share/explore_lite/local_setup.bash"
Started ros2 launch ugv_custom_nodes line_follower.launch.py. Seems to work, only a few warnings:
[v4l2_camera_node-1] [INFO] [1749735101.182860329] [v4l2_camera]: Driver: uvcvideo
[v4l2_camera_node-1] [INFO] [1749735101.183075567] [v4l2_camera]: Version: 331656
[v4l2_camera_node-1] [INFO] [1749735101.183090895] [v4l2_camera]: Device: USB Camera: USB Camera
[v4l2_camera_node-1] [INFO] [1749735101.183096527] [v4l2_camera]: Location: usb-3610000.usb-2.2
[v4l2_camera_node-1] [INFO] [1749735101.183101583] [v4l2_camera]: Capabilities:
[v4l2_camera_node-1] [INFO] [1749735101.183105903] [v4l2_camera]: Read/write: NO
[v4l2_camera_node-1] [INFO] [1749735101.183111183] [v4l2_camera]: Streaming: YES
[v4l2_camera_node-1] [INFO] [1749735101.183125936] [v4l2_camera]: Current pixel format: MJPG @ 1920x1080
[v4l2_camera_node-1] [INFO] [1749735101.183234419] [v4l2_camera]: Available pixel formats:
[v4l2_camera_node-1] [INFO] [1749735101.183242515] [v4l2_camera]: MJPG - Motion-JPEG
[v4l2_camera_node-1] [INFO] [1749735101.183246995] [v4l2_camera]: YUYV - YUYV 4:2:2
[v4l2_camera_node-1] [INFO] [1749735101.183251315] [v4l2_camera]: Available controls:
[v4l2_camera_node-1] [INFO] [1749735101.184699257] [v4l2_camera]: Brightness (1) = 0
[v4l2_camera_node-1] [INFO] [1749735101.186169984] [v4l2_camera]: Contrast (1) = 50
[v4l2_camera_node-1] [INFO] [1749735101.187917198] [v4l2_camera]: Saturation (1) = 65
[v4l2_camera_node-1] [INFO] [1749735101.189416117] [v4l2_camera]: Hue (1) = 0
[v4l2_camera_node-1] [INFO] [1749735101.189443318] [v4l2_camera]: White Balance, Automatic (2) = 1
[v4l2_camera_node-1] [INFO] [1749735101.190926908] [v4l2_camera]: Gamma (1) = 300
[v4l2_camera_node-1] [INFO] [1749735101.192166269] [v4l2_camera]: Power Line Frequency (3) = 1
[v4l2_camera_node-1] [INFO] [1749735101.193665476] [v4l2_camera]: White Balance Temperature (1) = 4600 [inactive]
[v4l2_camera_node-1] [INFO] [1749735101.194914213] [v4l2_camera]: Sharpness (1) = 50
[v4l2_camera_node-1] [INFO] [1749735101.196162694] [v4l2_camera]: Backlight Compensation (1) = 0
[v4l2_camera_node-1] [ERROR] [1749735101.196197767] [v4l2_camera]: Failed getting value for control 10092545: Permission denied (13); returning 0!
[v4l2_camera_node-1] [INFO] [1749735101.196208903] [v4l2_camera]: Camera Controls (6) = 0
[v4l2_camera_node-1] [INFO] [1749735101.196217671] [v4l2_camera]: Auto Exposure (3) = 3
[v4l2_camera_node-1] [INFO] [1749735101.197664077] [v4l2_camera]: Exposure Time, Absolute (1) = 166 [inactive]
[v4l2_camera_node-1] [INFO] [1749735101.199412059] [v4l2_camera]: Exposure, Dynamic Framerate (2) = 0
[v4l2_camera_node-1] [INFO] [1749735101.200914146] [v4l2_camera]: Pan, Absolute (1) = 0
[v4l2_camera_node-1] [INFO] [1749735101.202424394] [v4l2_camera]: Tilt, Absolute (1) = 0
[v4l2_camera_node-1] [INFO] [1749735101.203911537] [v4l2_camera]: Focus, Absolute (1) = 68 [inactive]
[v4l2_camera_node-1] [INFO] [1749735101.203945650] [v4l2_camera]: Focus, Automatic Continuous (2) = 1
[v4l2_camera_node-1] [INFO] [1749735101.205413752] [v4l2_camera]: Zoom, Absolute (1) = 0
[v4l2_camera_node-1] [WARN] [1749735101.206874879] [camera]: Control type not currently supported: 6, for control: Camera Controls
[v4l2_camera_node-1] [INFO] [1749735101.207363787] [v4l2_camera]: Requesting format: 1920x1080 YUYV
[v4l2_camera_node-1] [INFO] [1749735101.218292138] [v4l2_camera]: Success
[v4l2_camera_node-1] [INFO] [1749735101.218322795] [v4l2_camera]: Requesting format: 160x120 YUYV
[v4l2_camera_node-1] [INFO] [1749735101.229039172] [v4l2_camera]: Success
[v4l2_camera_node-1] [INFO] [1749735101.236211424] [v4l2_camera]: Starting camera
[v4l2_camera_node-1] [WARN] [1749735101.804031818] [camera]: Image encoding not the same as requested output, performing possibly slow conversion: yuv422_yuy2 => rgb8
[v4l2_camera_node-1] [INFO] [1749735101.814271510] [camera]: using default calibration URL
[v4l2_camera_node-1] [INFO] [1749735101.814428698] [camera]: camera calibration URL: file:///home/jetson/.ros/camera_info/usb_camera:_usb_camera.yaml
[v4l2_camera_node-1] [ERROR] [1749735101.814617119] [camera_calibration_parsers]: Unable to open camera calibration file [/home/jetson/.ros/camera_info/usb_camera:_usb_camera.yaml]
[v4l2_camera_node-1] [WARN] [1749735101.814656576] [camera]: Camera calibration file /home/jetson/.ros/camera_info/usb_camera:_usb_camera.yaml not found
Checked on nb-dual (WSL) and saw the following topics:
/camera_info
/cmd_vel
/image_raw
/image_raw/compressed
/image_raw/compressedDepth
/image_raw/theora
/joy
/parameter_events
/processed_image
/rosout
/ugv/joint_states
/ugv/led_ctrl
/voltage
No topics like /scan and /odom yet, although Joey got that working at May 23 (ros2 launch ugv_custom_nodes mapping_node.launch.py.
Looked what I tried as last command on February 6.
Tried ros2 run image_view image_view --ros-args --remap image:=/image_raw inside WSL with VxSrv-Xlaunch running on the backgroud, but this gives:
[INFO] [1749735895.930762600] [image_view_node]: Using transport "raw"
terminate called after throwing an instance of 'cv::Exception'
what(): OpenCV(4.5.4) ./modules/highgui/src/window_gtk.cpp:635: error: (-2:Unspecified error) Can't initialize GTK backend in function 'cvInitSystem'
Tried again on ws9. Had to do unset ROS_DOMAIN_ID first. Still, ros2 topic list gives me only the two default topics, while I could ping and ssh to the rover, and see all topics there.
ws9 was busy with a partial upgrade (asking for a reboot). Hope that this is not an update from Ubuntu 22.04 to 24.04.
Switched off all TurtleBot related settings in my ~/.bashrc
Another user is running jobs on ws9, so could't reboot.
This seems to happen at the LAB42 network, not on the vislab_wifi. Looking into Multiple Network sections from linuxbabe. That didn't work.
Instead used the trick from stackexchange and looked up the UUIDs with nmcli c and switched to other network with nmcli c up uuid . The ssh-connection then freezes, because you have to build it up again via the other network.
The two ethernet-connections also are in the 192.* domain, so had to unpluck them to connect to the robot.
Now I see all topics. The image was black, but that was because the cover was still on the lens. Without cover the robot directly starts to drive (as expected from line-following).
The images displayed with ros2 run image_view image_view --ros-args --remap image:=/image_raw have a delay of 10s:
You can also request the processed_image with ros2 run image_view image_view --ros-args --remap image:=/processed_image:
There are now 4 nodes running:
/camera
/driver
/image_view_node
/line_following_node
The next step in the WaveShare tutorials is to control the leds (Tutorial 2).
On ws9 Mozilla could open this web-page, chrome could.
After starting the driver with ros2 run ugv_bringup ugv_driver, I could control the three led-lights with ros2 topic pub /ugv/led_ctrl std_msgs/msg/Float32MultiArray "{data: [255, 255]}" -1. With {data: [9,0]} only the two lower leds light up, with less brightness. Note that the ugv_driver is not the driver from the line-following. Yet, this seems only a difference in name (same executable) in ugv_custom_nodes/launch/line_follower.launch.py
Looking for nice images for the paper. Fig. 4 of Group 1 could be usefull to illustrate the first assignment.
Also Fig. 6 would be a nice illustration.
Yet, Group 1 chose the most centered line.
Group 9 shows in Fig. 9 the benefit of using RANSAC compared to Canny edge.
February 18, 2025
The RAE has a Robotics Vision Core 3, which is based on the Intel Movidius accelerator with code name (a href=https://www.intel.com/content/www/us/en/developer/articles/technical/movidius-accelerator-on-edge-software-hub.html>Keem Bay.
February 12, 2025
An interesting arXiv paper on a Wheeled lab on the University of Washington.
The rover comes without batteries. The instructions to load the batteries are not there yet.
The battery compartment is actually below the rover. The screw-driver provided nicely fits. Placed three of the 18650 lithium batteries from the DART robot into the compartment and start charging (connector next to the on-off button).
Connected the Display-port to my display and the USB-C to a mouse and keyboard. The ethernet-ip is displayed on the small black screen below the on-off button.
Could login via the screen/keyboard. The Jetson is running Ubuntu 22.04.04.
Switched off the hotspot (right top corner) and connected to LAB42.
Tried to switch of the python programming started during setup. The kills seem to fail, but after a while no 10% python script popped up anymore. Looked at /home/jetson/uvg.log. Last line is Terminated.
The docker scripts are actually in /home/jetson/uvg_ws. Didn't make two scripts mentioned in ROS2 Preparation executable. The ros2_humble script starts fine, and indicated a shell-server is started. Yet, I couldn't connect to the shell server, nor externally, nor via the docker-ip. Yet, doing a docker ps followed by docker exec -it CONTAINER_ID bash worked (no zsh in SPATH). Could find /opt/ros/humble/bin/ros2.
Next tried RVIZ, but that failed because no connection to display localhost:12.0 could be made.
The docker is a restart of container of a existing docker-image, not a fresh run.
Tried to make a script that run from the image, with reuse of the host. Yet, out of battery before finished(charging is before USB-B connector). Switched to USB-C connector after the reboot.
Starting the docker failed. Could be the background process. Tried docker run nvidia/cuda:11.8.0-cudnn8-devel-ubuntu22.04. That works, but returns directly. docker run nvidia/cuda:11.8.0-cudnn8-devel-ubuntu22.04. That works, but returns directly and gives a warning that no NVIDIA drivers are detected.
Tried sudo docker run -it --runtime=nvidia --gpus all /usr/bin/bash. That works, entered the image. Only, no /opt/ros to be found, only /opt/nvidia. Strange, because I don't see any other image with docker image ls
Looked if I could natively install the required ros-humble packages. sudo apt ugrade wants to downgrade 4 packages (nvidia-container-toolkit), so didn't continue.
Installed apt install python3-pip. Next are the ros-packages, but I have to install the ros-repository first. Trying to install firefox, but that is snap-based. Used firefox for the ROS Humble Install instructions.
Installed ros-humble-base first (258 packages), followed by ros-humble-cartographer-* (360 new, 7 upgraded).
Next ros-humble-joint-state-publisher-* (17 packages), followed by ros-humble-nav2-* (119 packages, 5 upgraded)
Next ros-humble-rosbridge-* (22 packages), followed by ros-humble-rqt-* (61 packages)
Next ros-humble-rtabmap-* (51 new, 1 upgraded), followed by ros-humble-usb-cam-* (11 packages).
Last one is ros-humble-depthai-* (28 packages). Left the gazebo part for the moment.
The code needed is available on github. Unfortunatelly, colcon build --packages-select doesn't work, so have do these three commands in each sub-dir of src/ugv_else:
cmake -B build -DCMAKE_BUILD_TYPE=Release
cmake --build build --target install
sudo cmake --build build --target install
There is not only /home/jetson/git/ugv_ws/install/setup.bash, but also the preinstalled /home/jetson/ugv_ws/install/setup.bash. Yet, running this script gave missing local_setup.bash for ugv_description, ugv_gazebo, ugv_nav and ugv_slam. Those local_setup.bash were logical links to /home/ws. Changing the link to /home/jetson (with sudo!) solved this. Now ~/.bashrc works.
Yet, nor ros2 launch ugv_description display.launch.py use_rviz:=true nor ros2 run ugv_bringup ugv_driver works (package not found). Maybe a ros-dep init first, even better in a humble_ws/src/, with the different packages in that src-directory.
At least ros2 run usb_cam usb_cam_node_exe worked. Could view the image with ros2 run image_view image_view --ros-args --remap image:=/image_raw. Only no permission to save image:
January 28, 2025
This paper describes iMarkers, which allow to make unvisible ArucoTags. Yet, one need a polarizer sheet in front of one of the stereo-cameras.
Chapter 10 covers the Navigation stack, Chapter 13 covers Computer Vision (no code!).
January 20, 2025
Looking for an anouncement of the next version of RAE, but according to this post, most of the developers are gone. We can ask for a refund.
Last August there were still plans to make a RCV4 version. The release was planned for Q3-Q4 2025.
According to this post the project was already deprecated in 2023. We could already ask for refunds in October 2024.
Alternative could be UGV Rover, Nvidia Jetson Orin based. Twice the price. But including Lidar and depth cameras. ROS2 Humble based. I also see that it is Docker based?! The depth sensor is OAK-D-Lite, the Lidar is D500 DTOF.







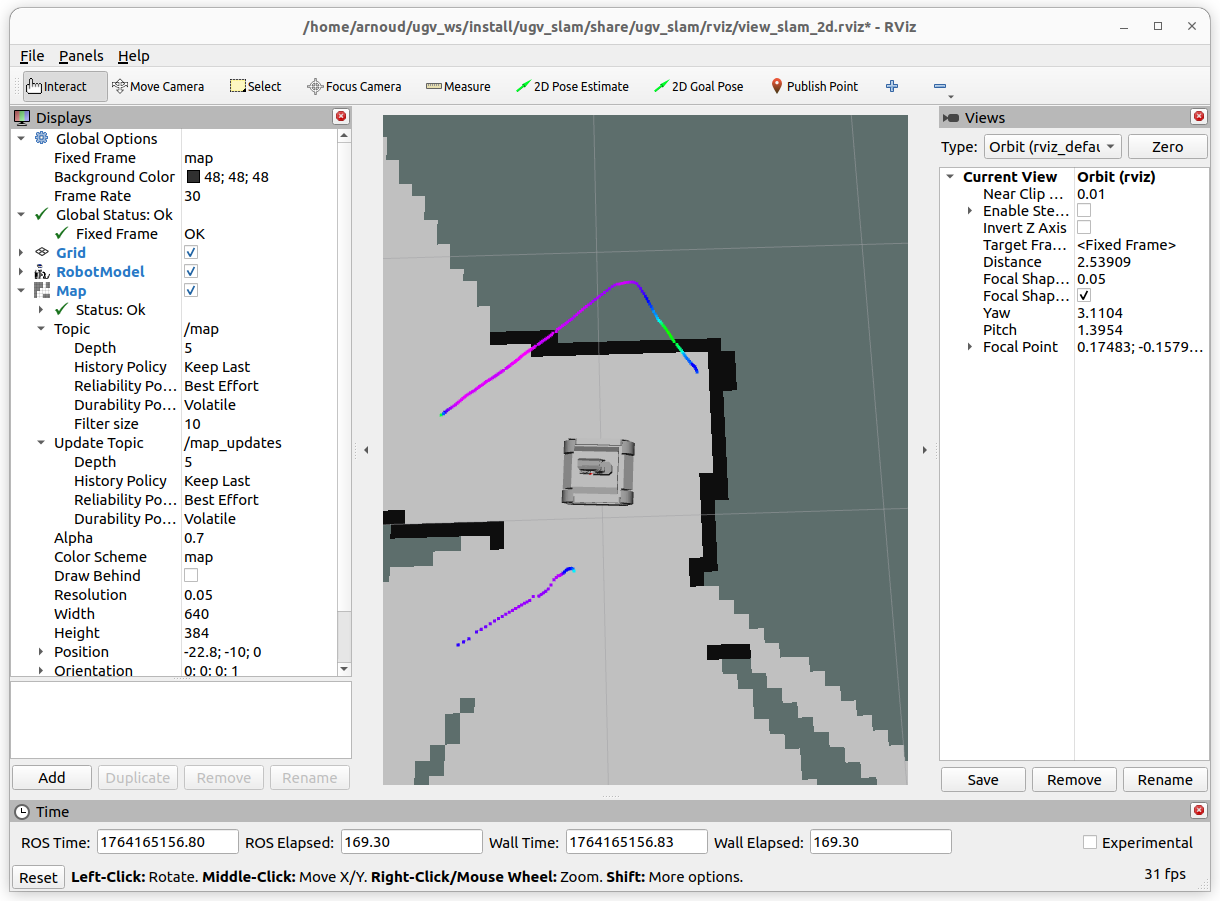
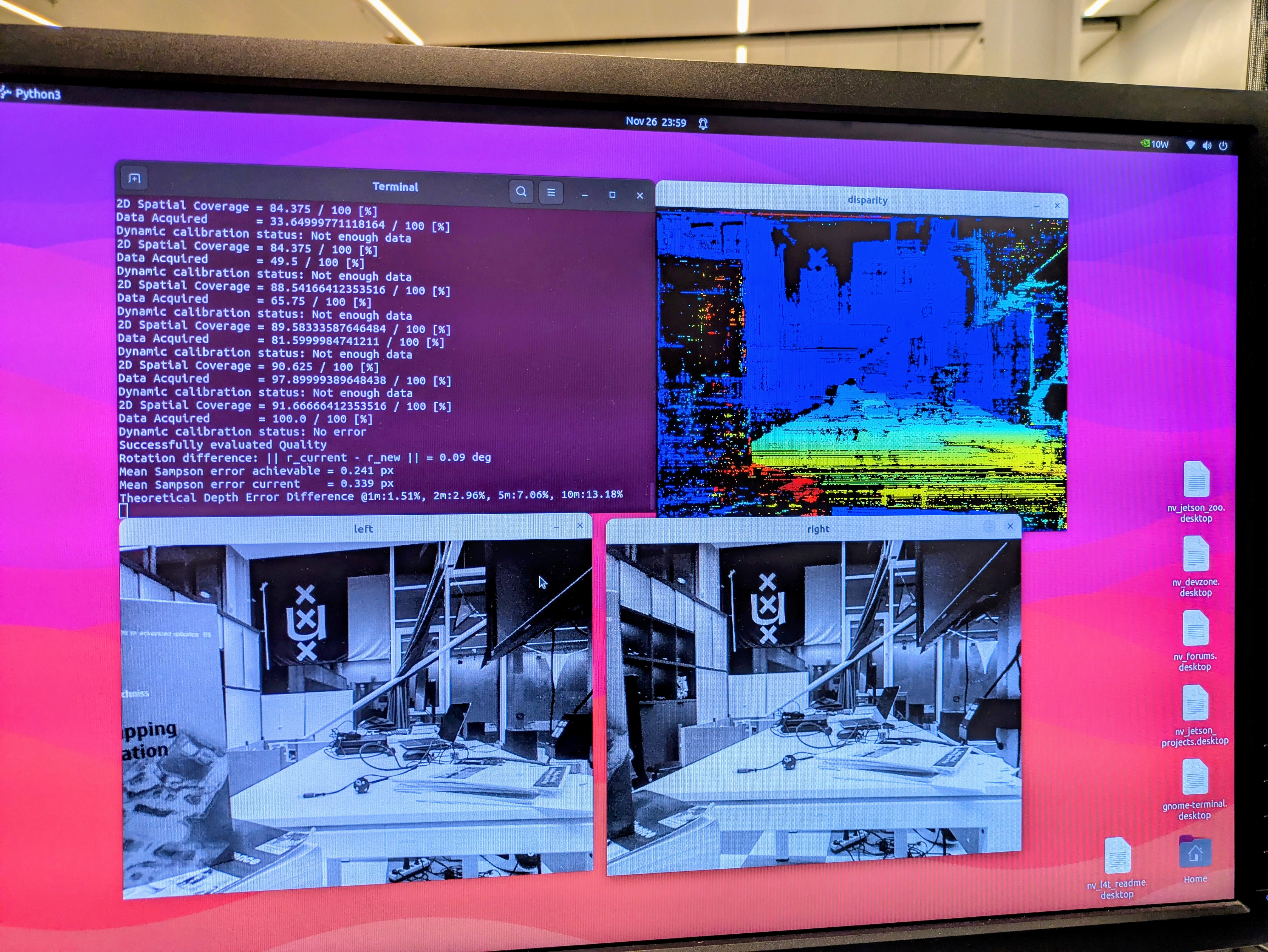
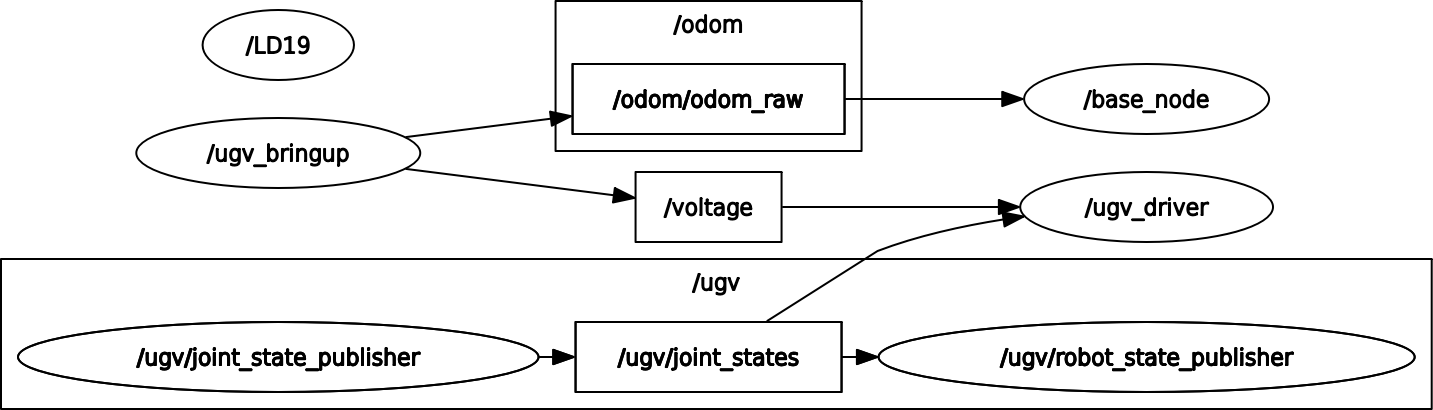
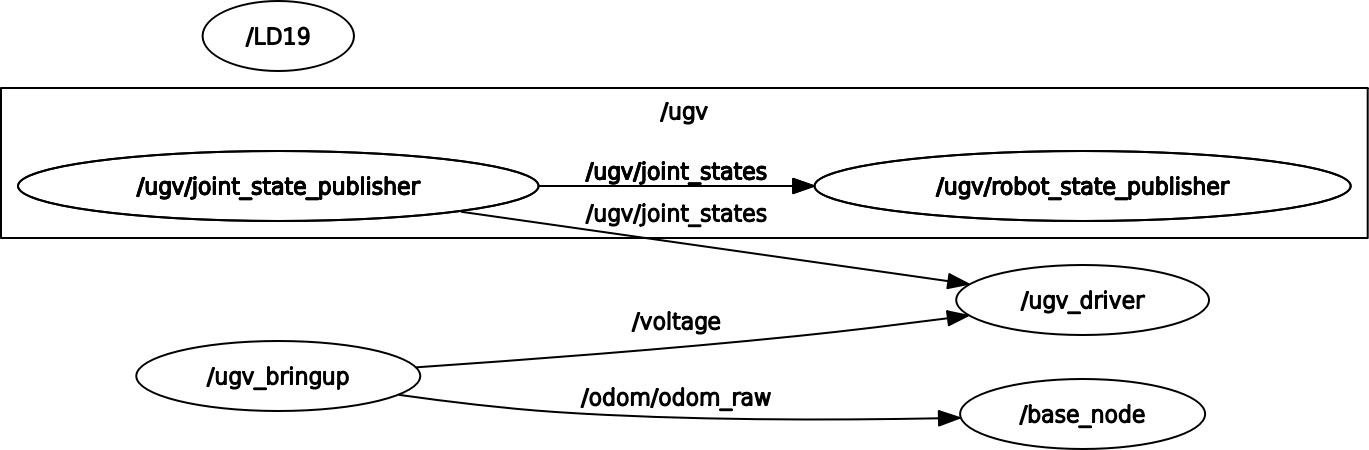
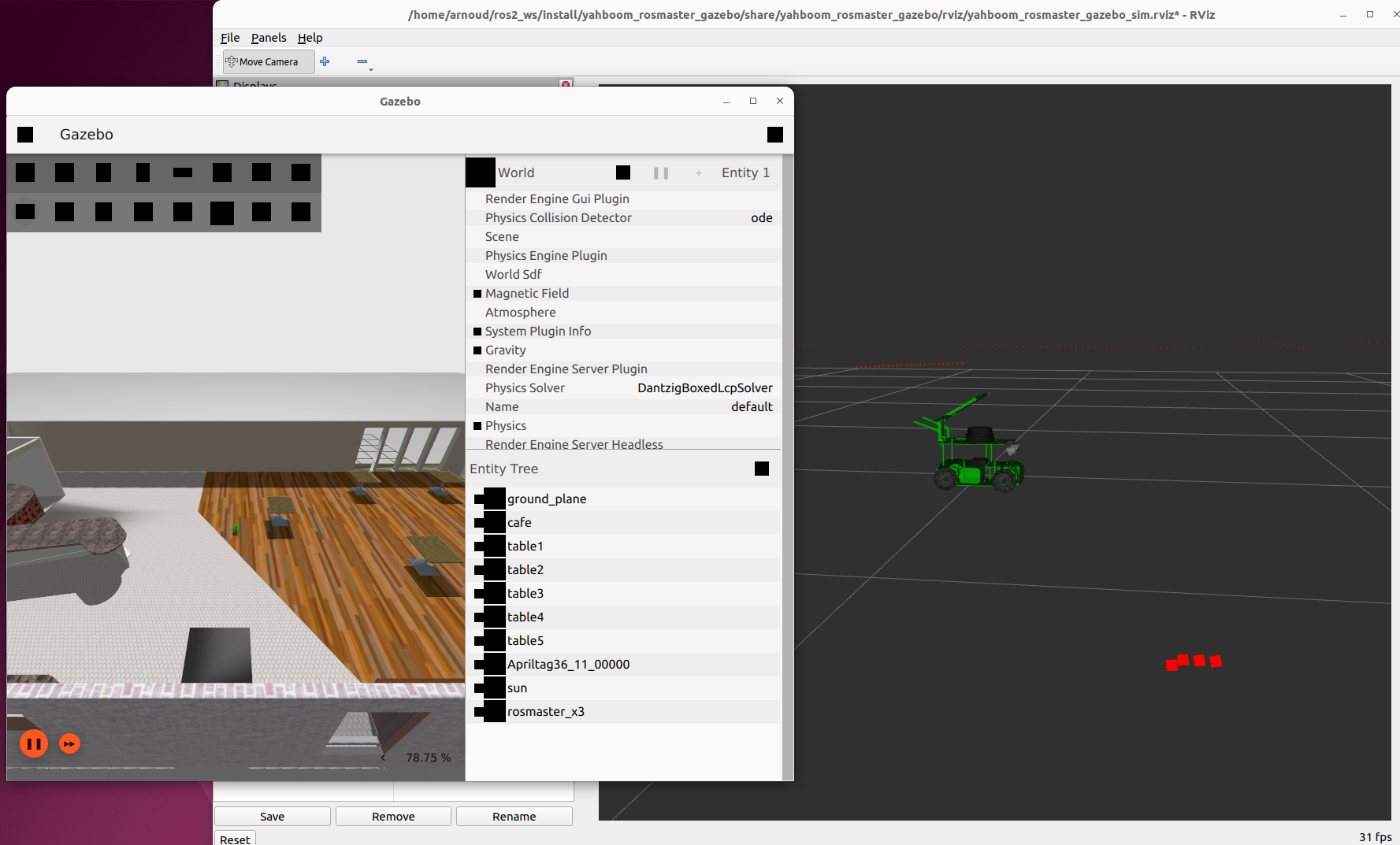
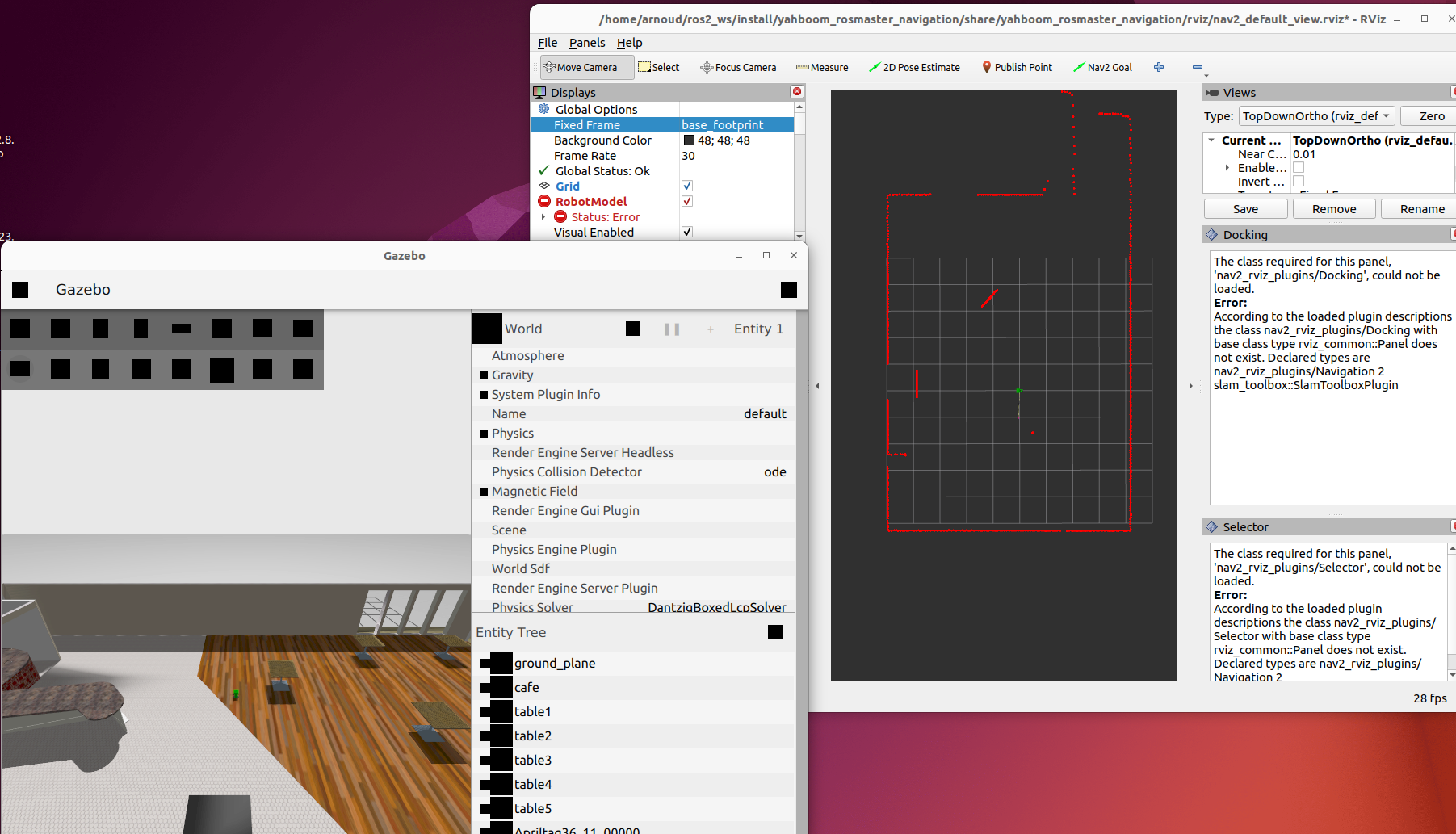 .
.
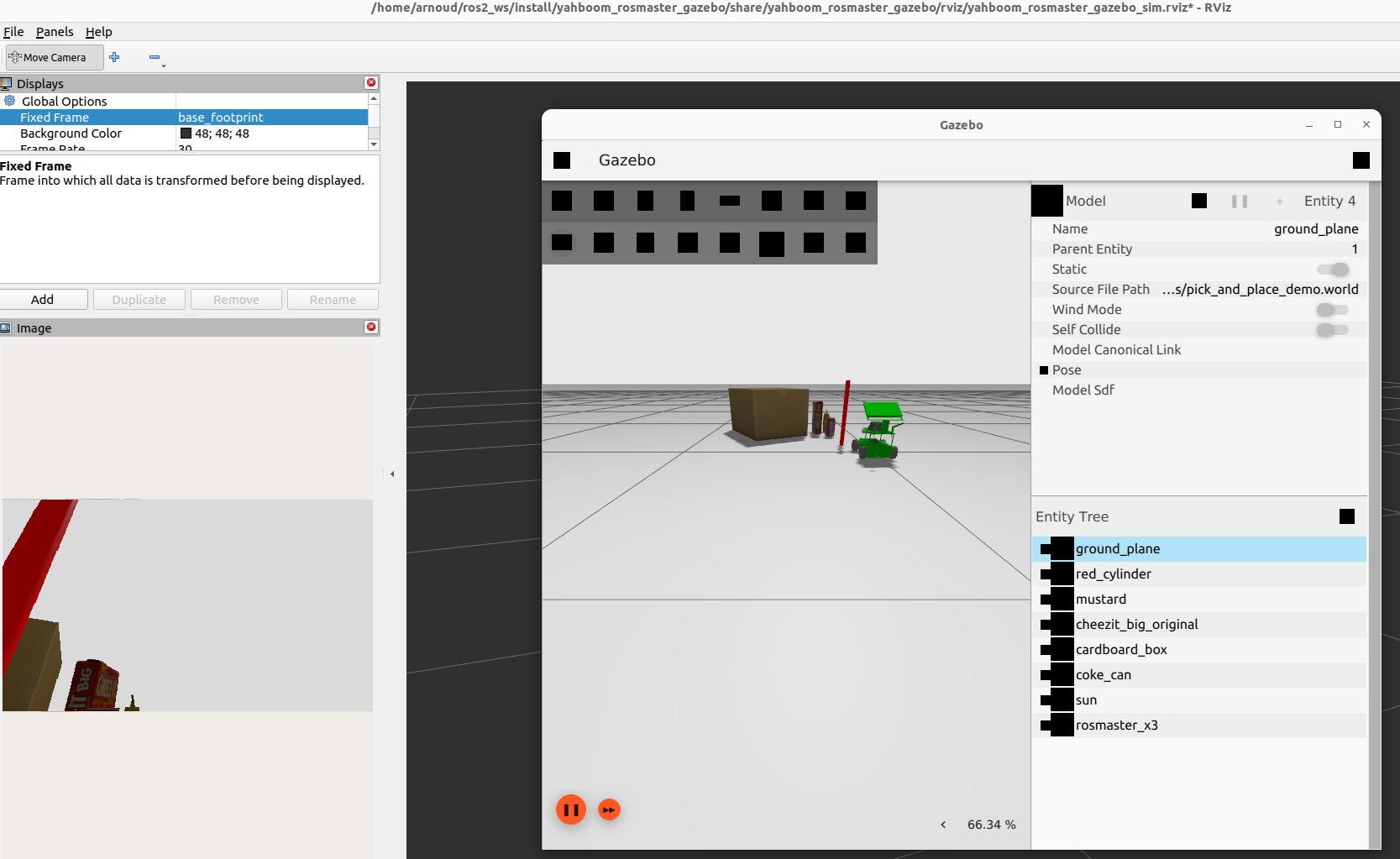
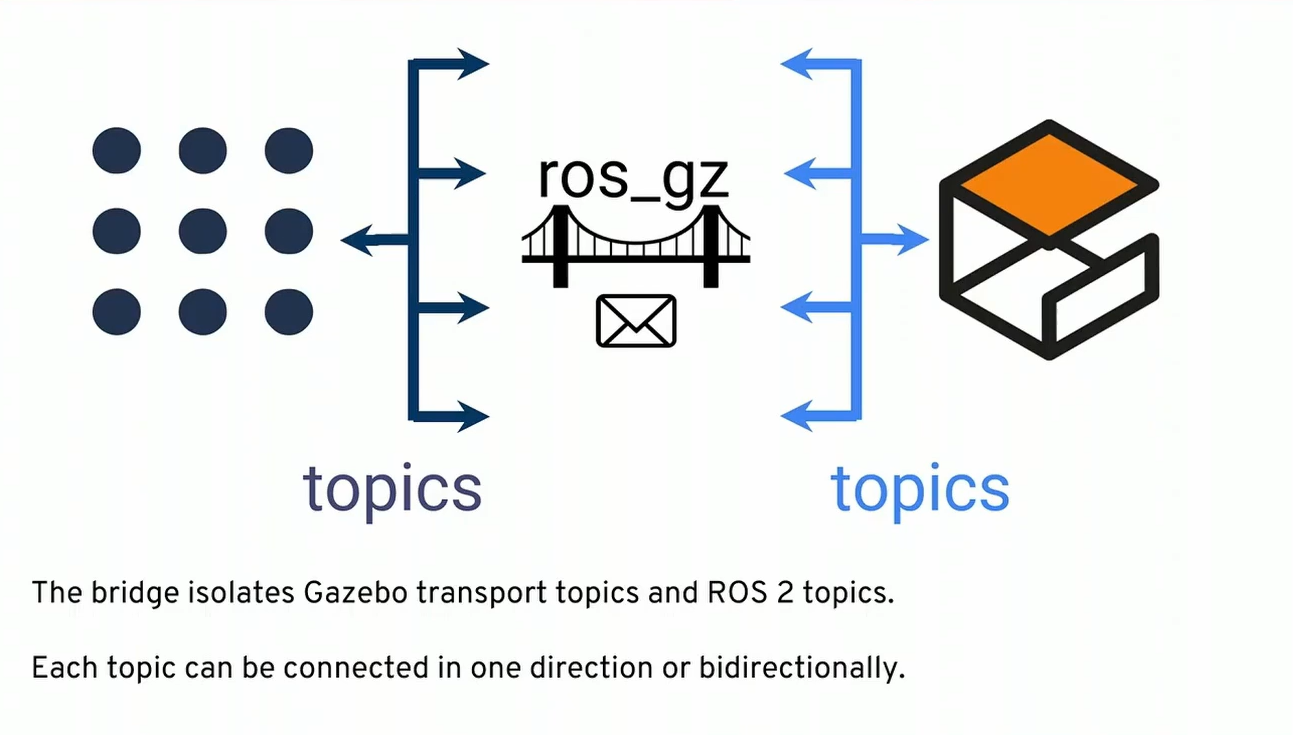
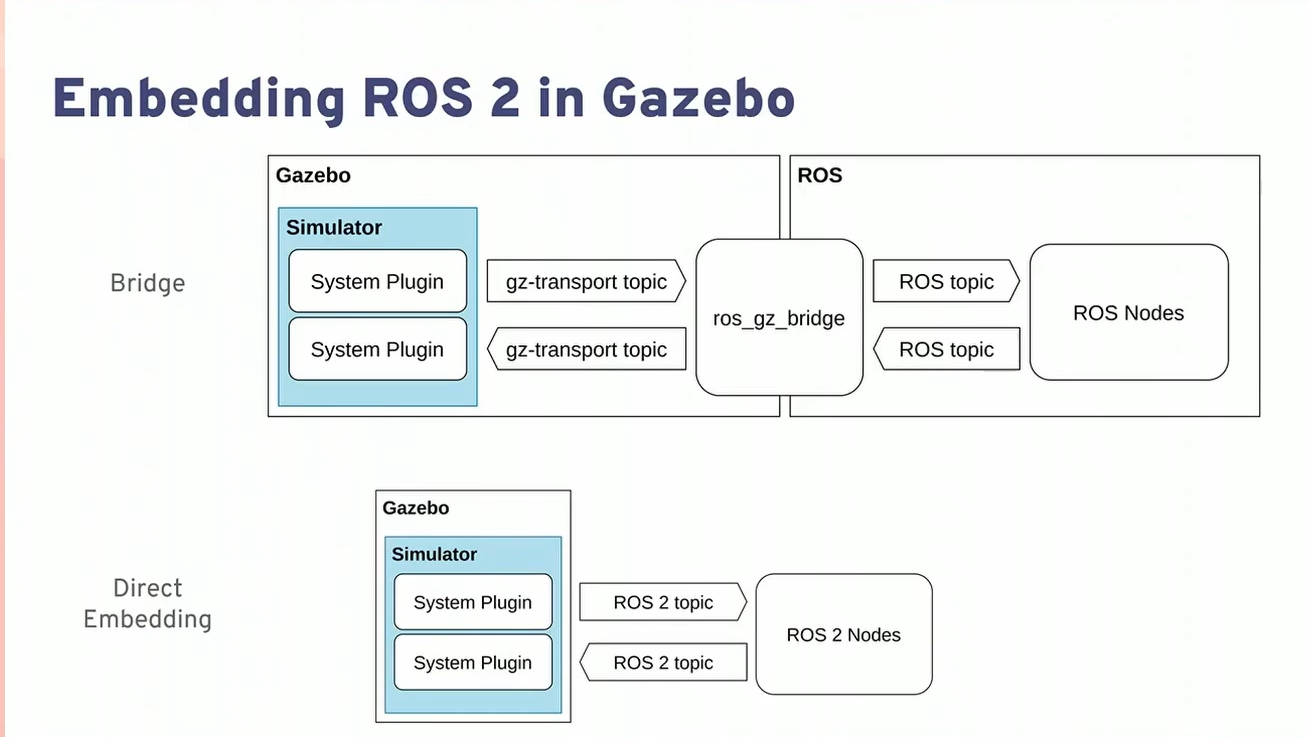


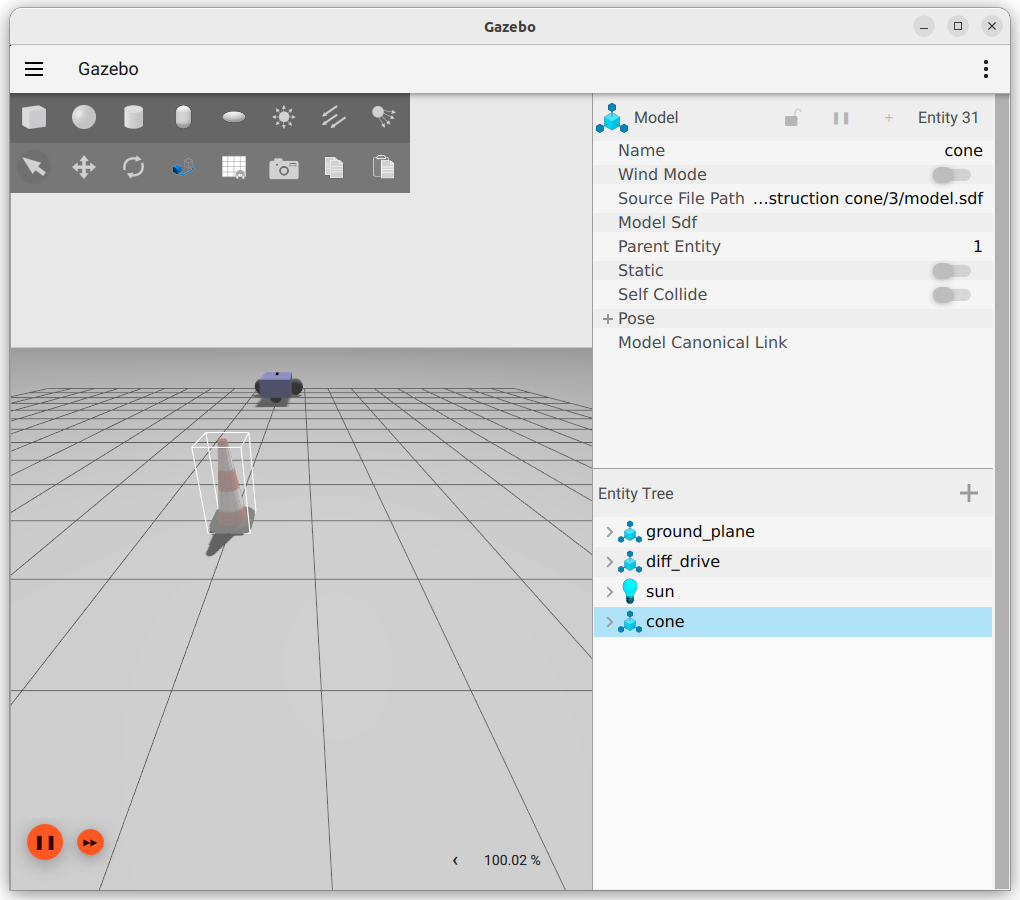
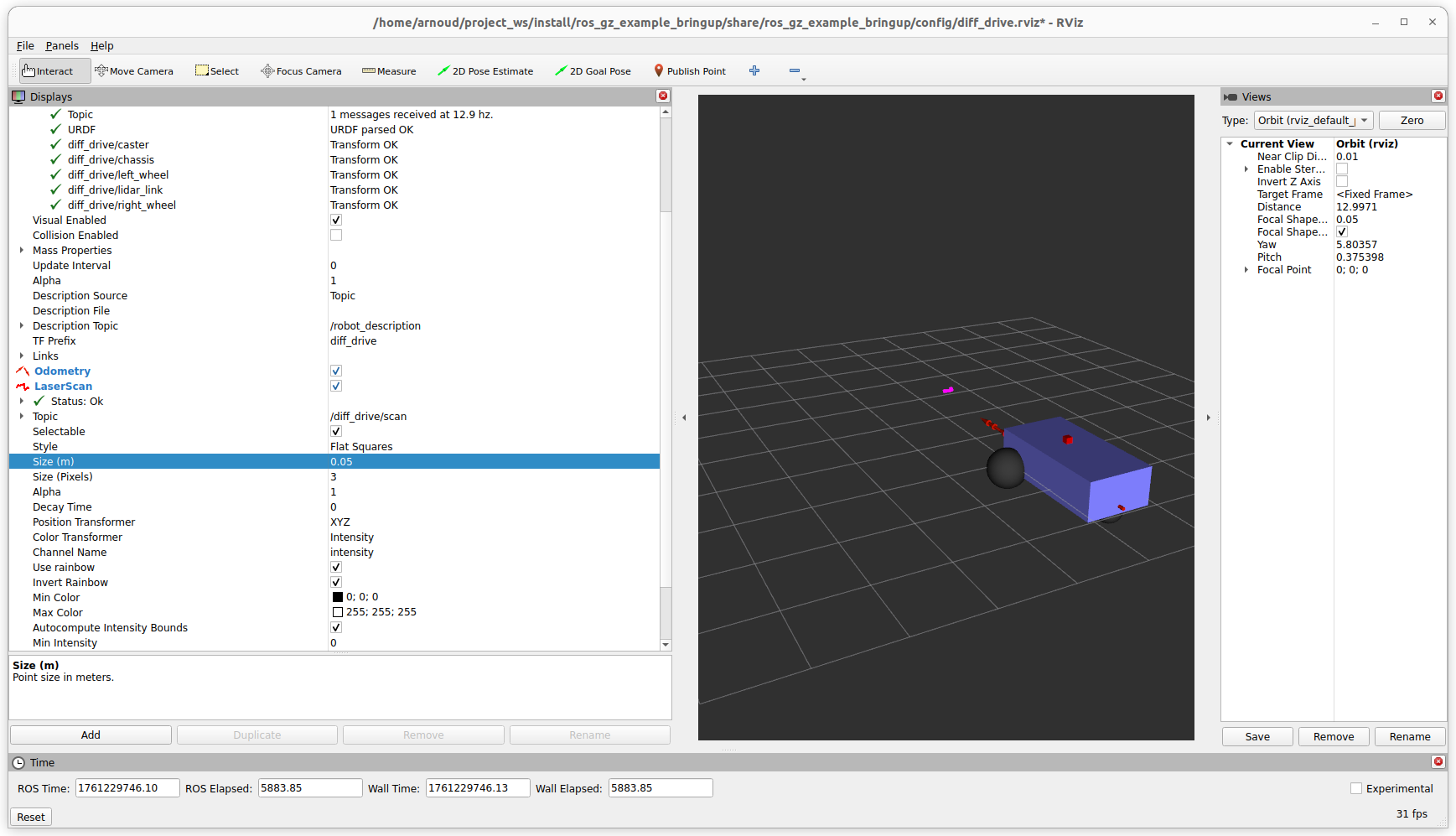
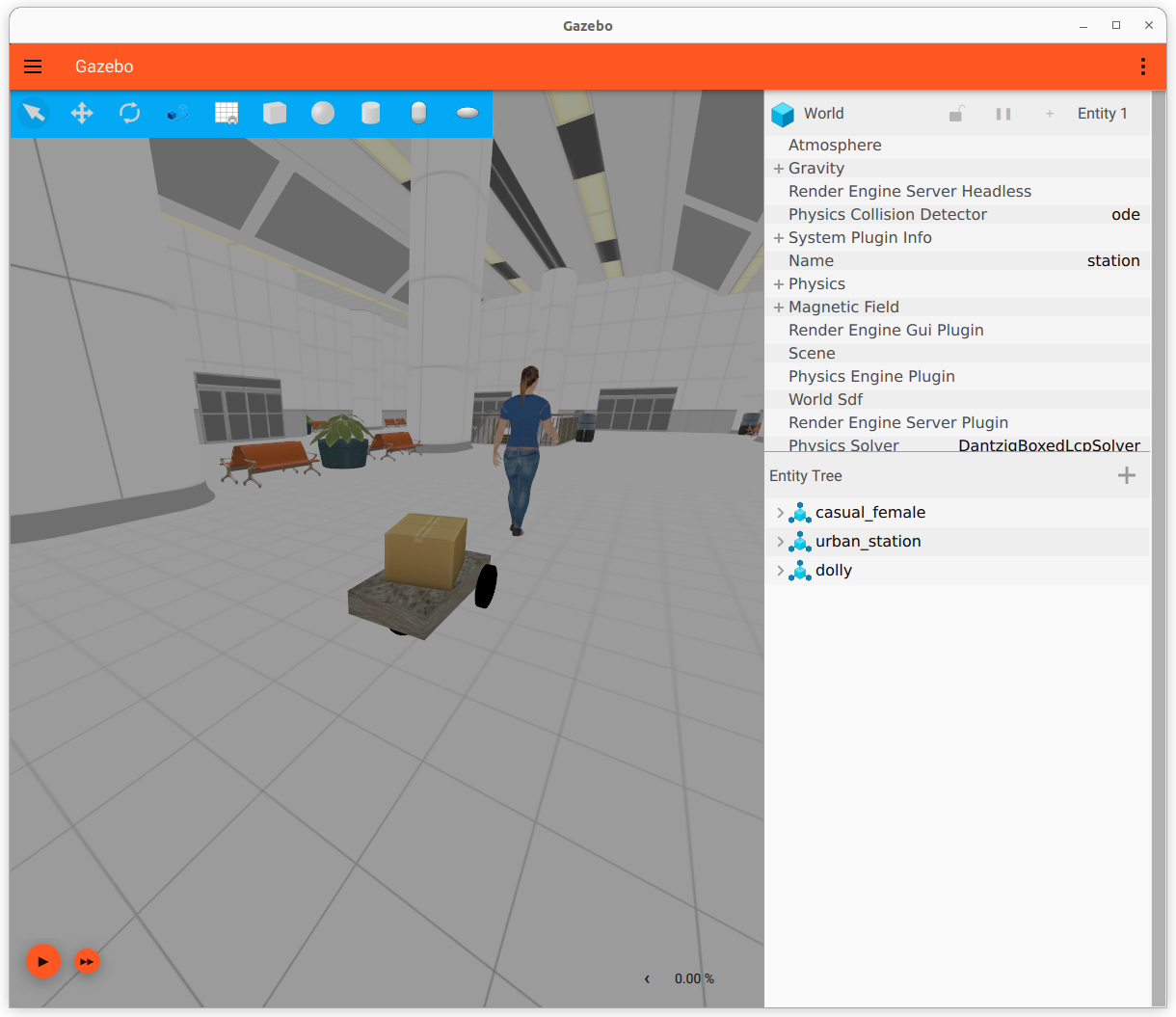
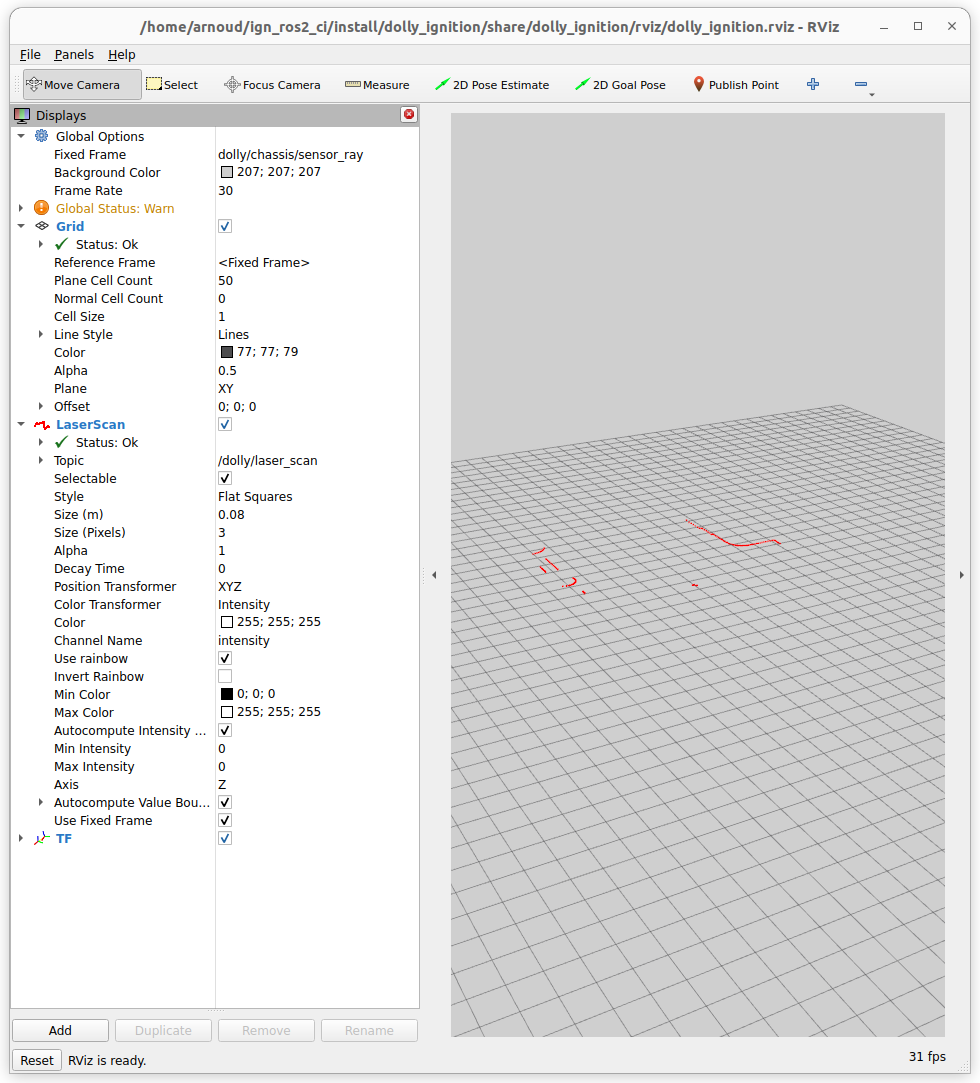
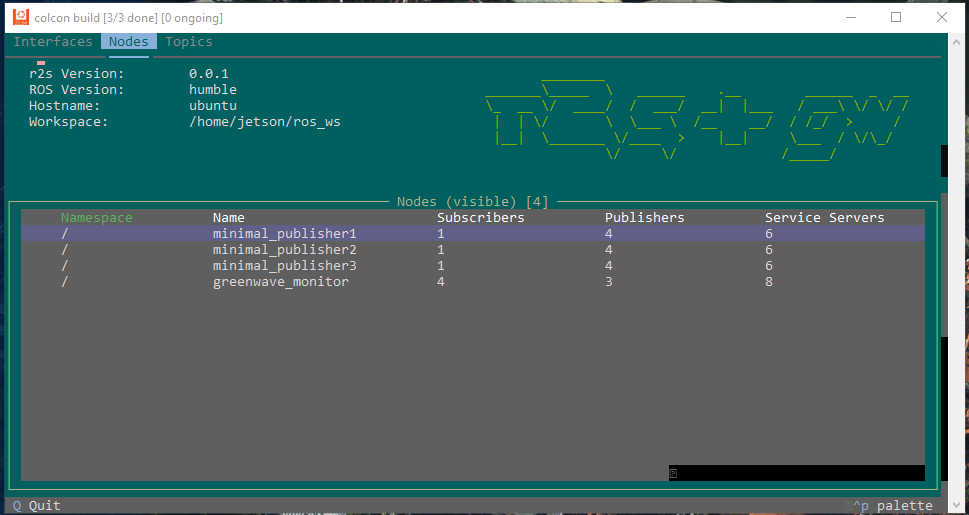
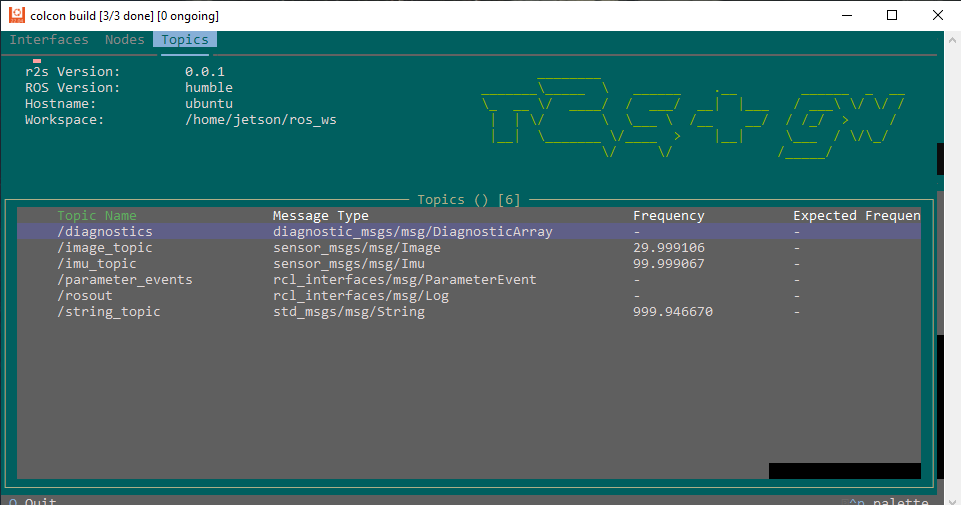
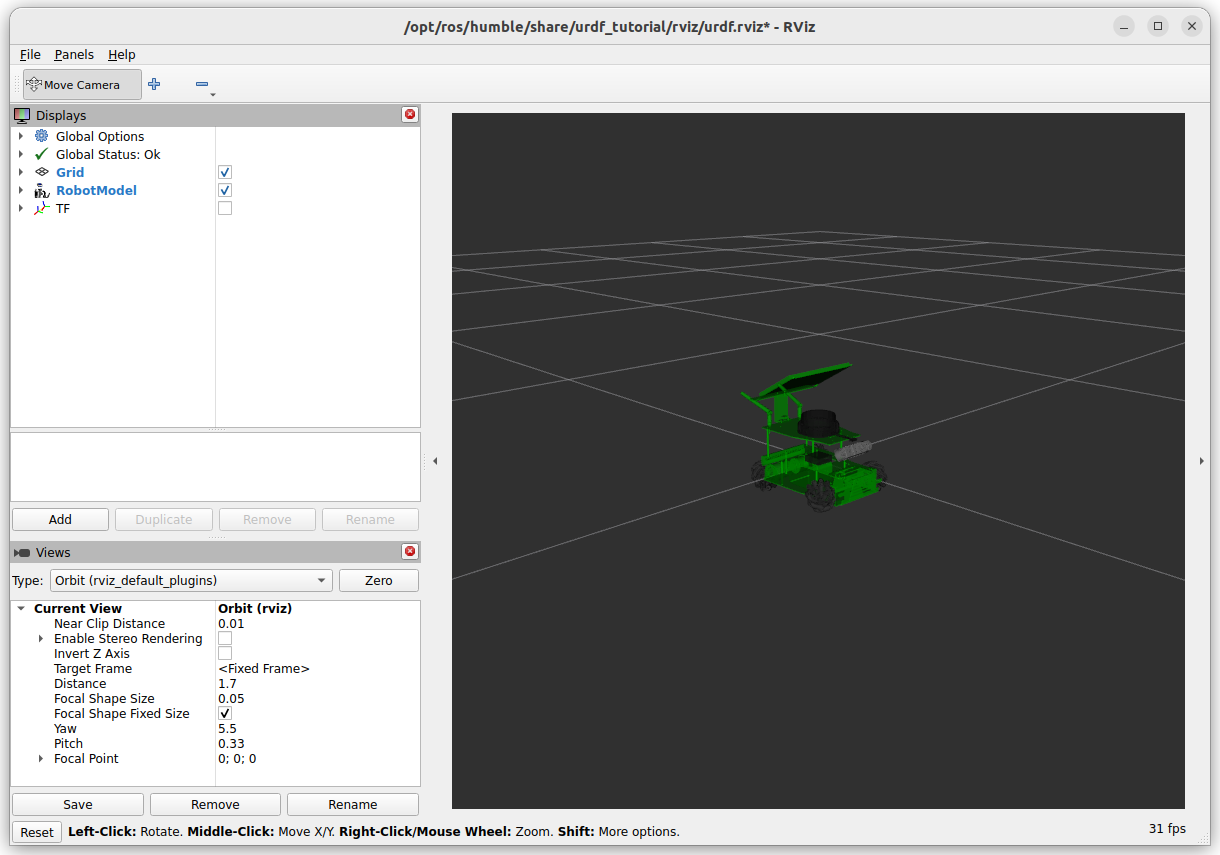
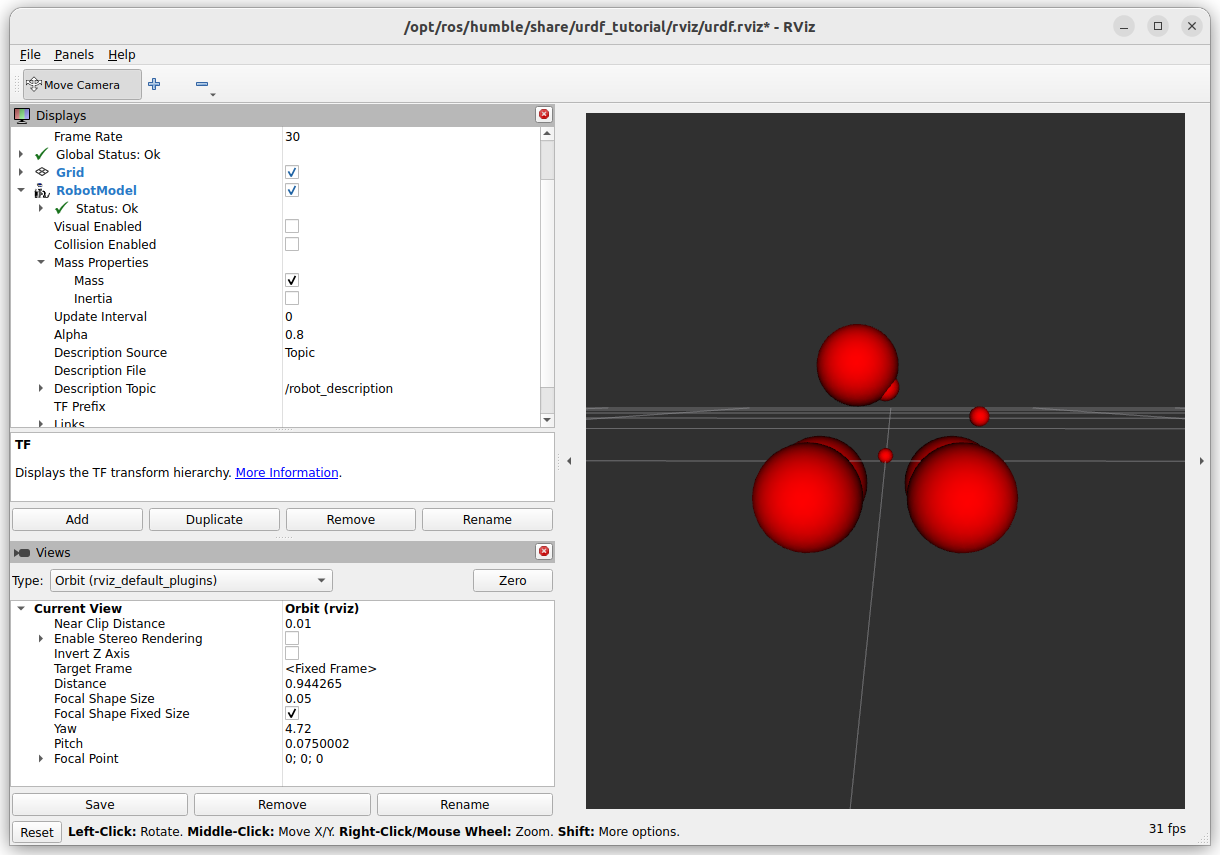
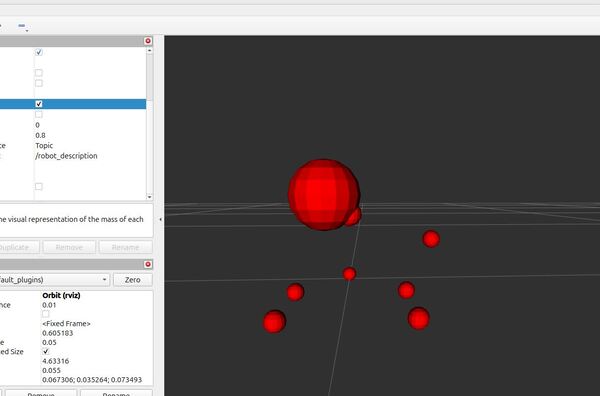
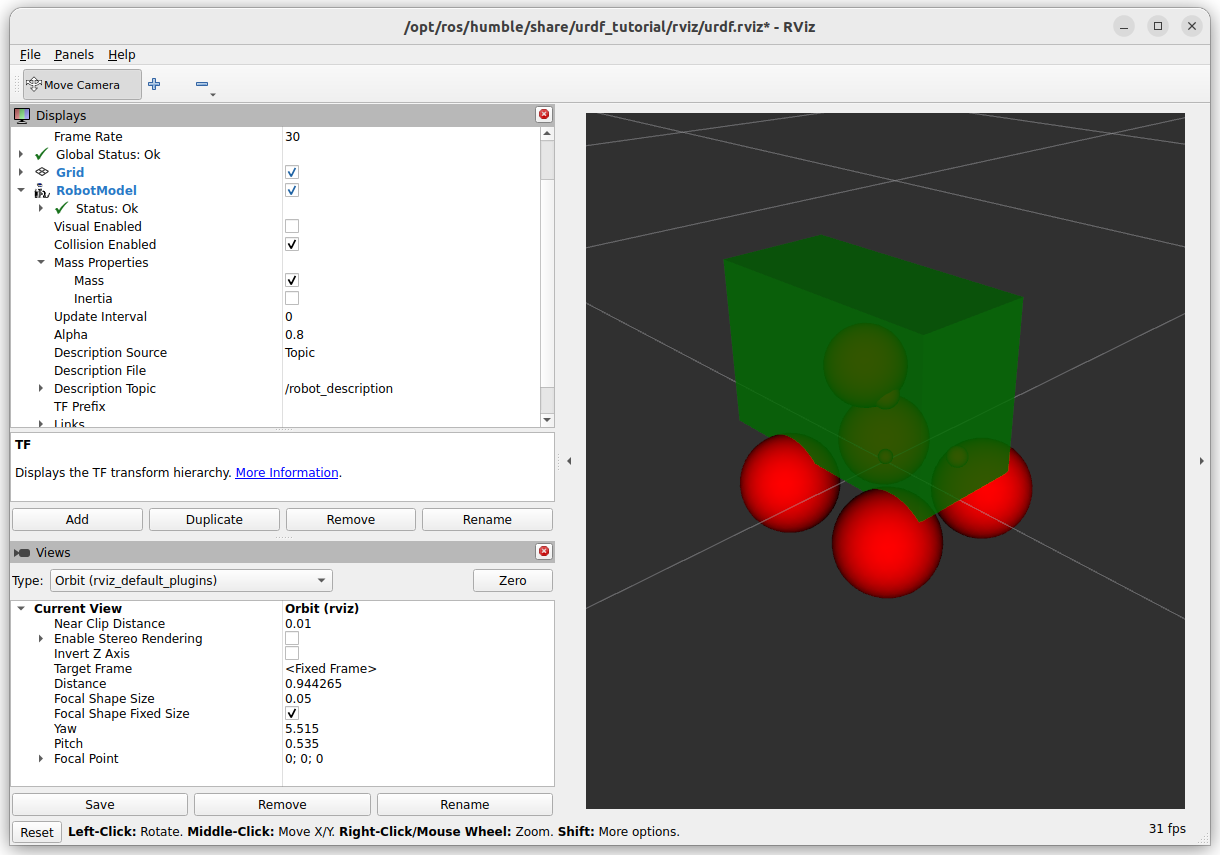
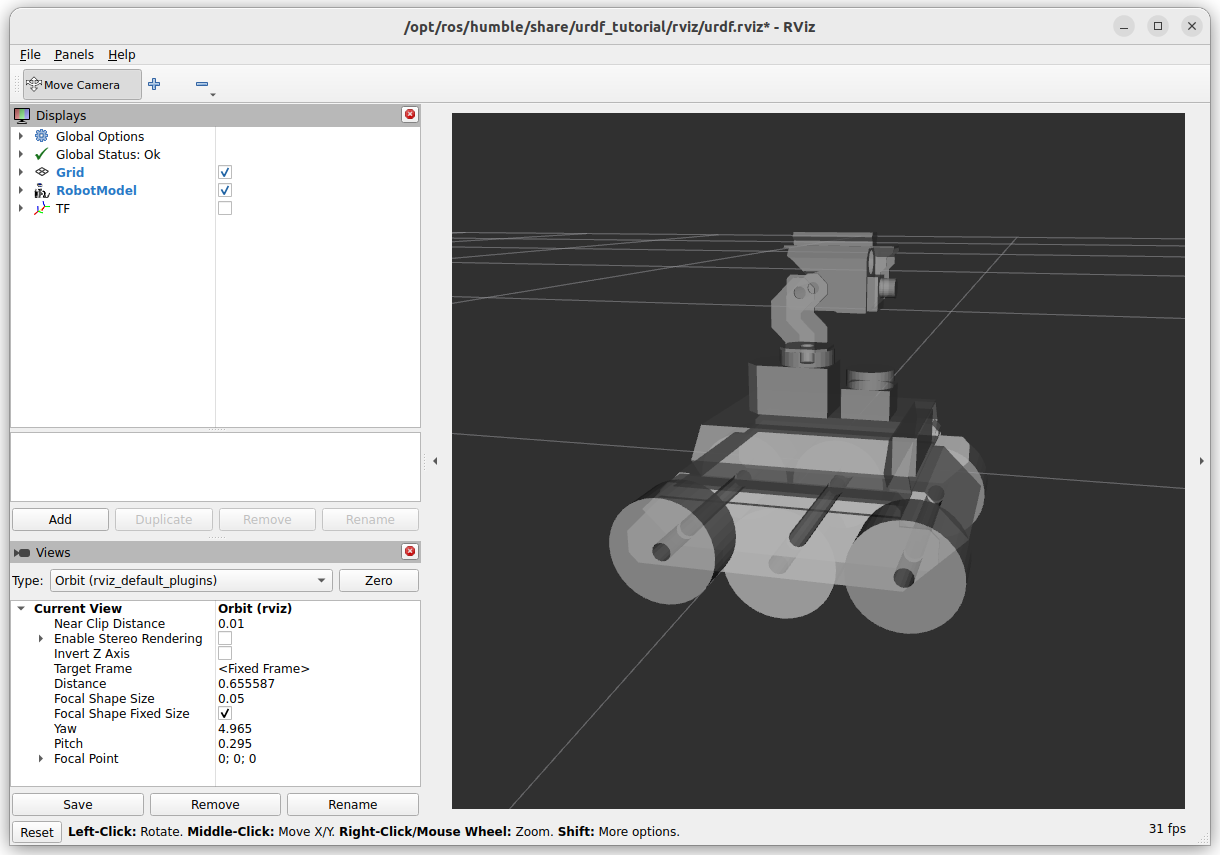
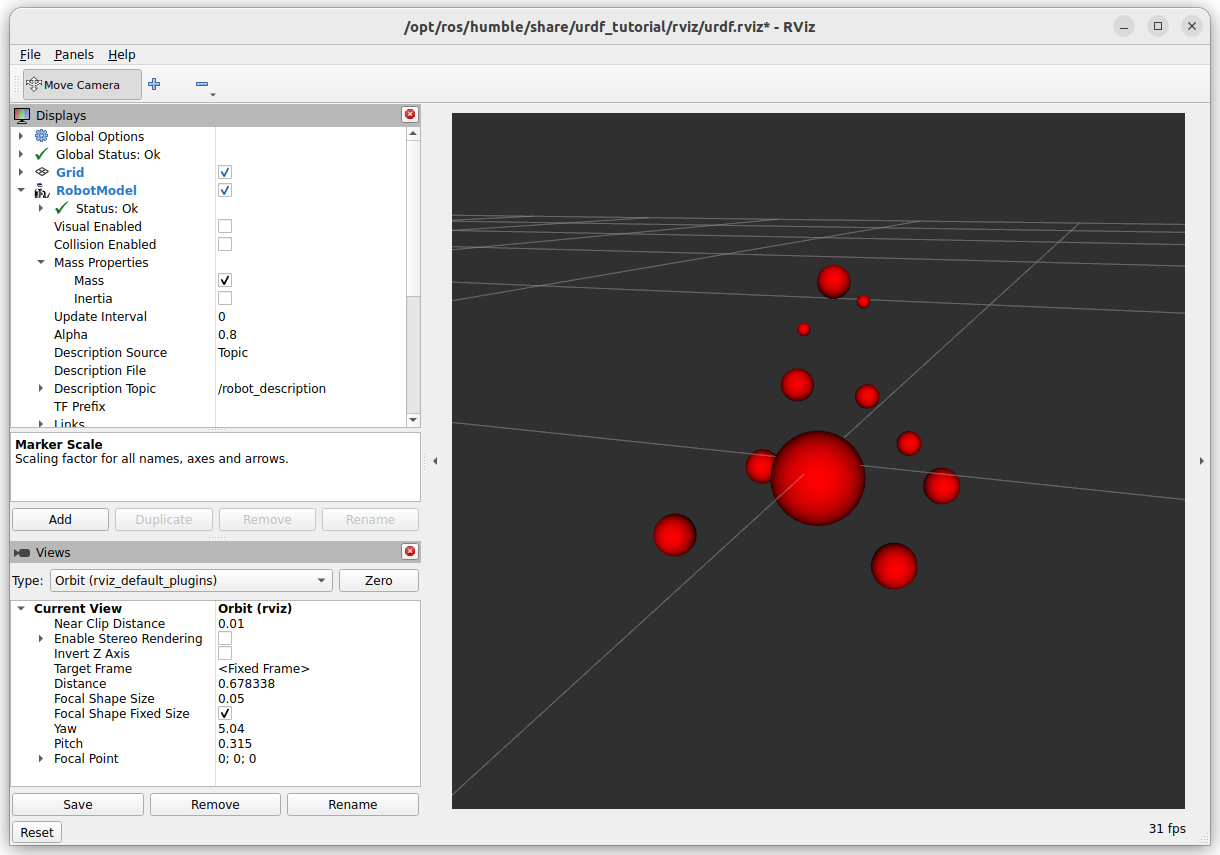
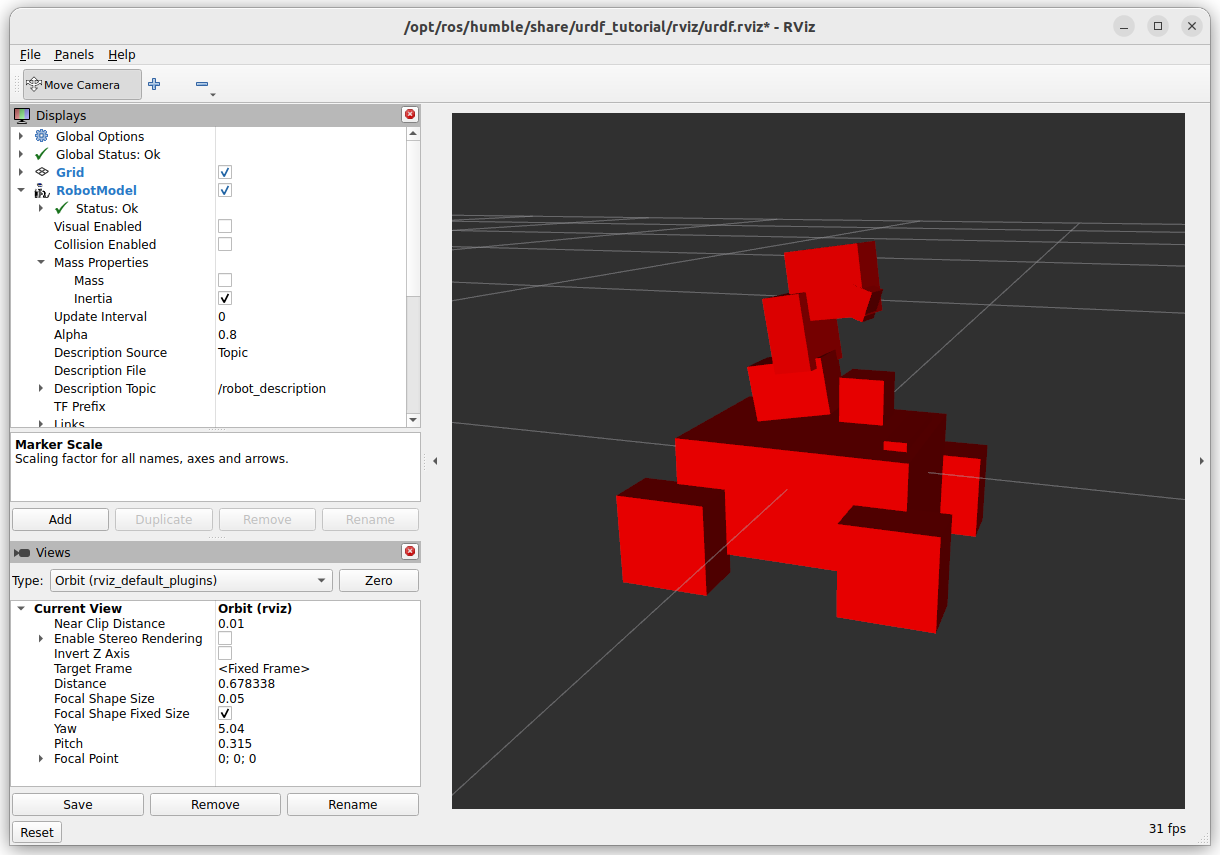
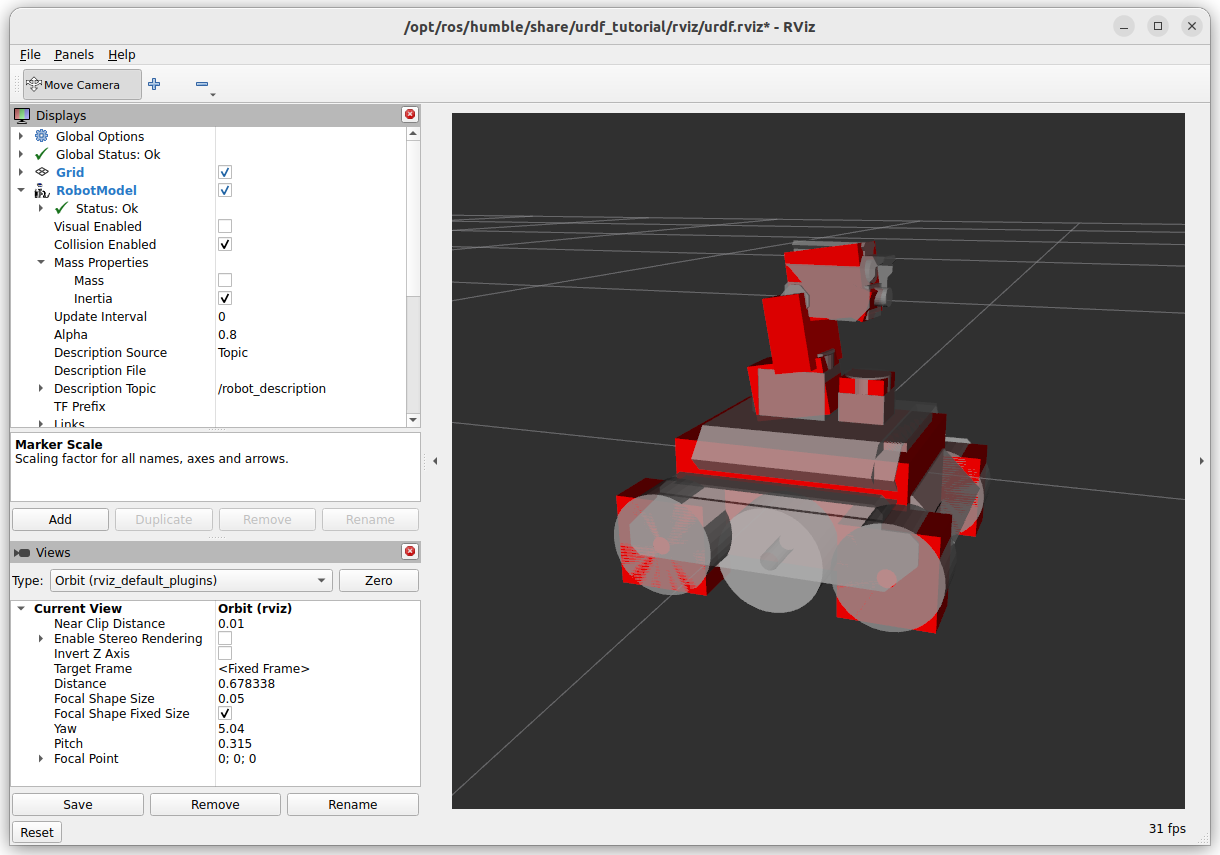
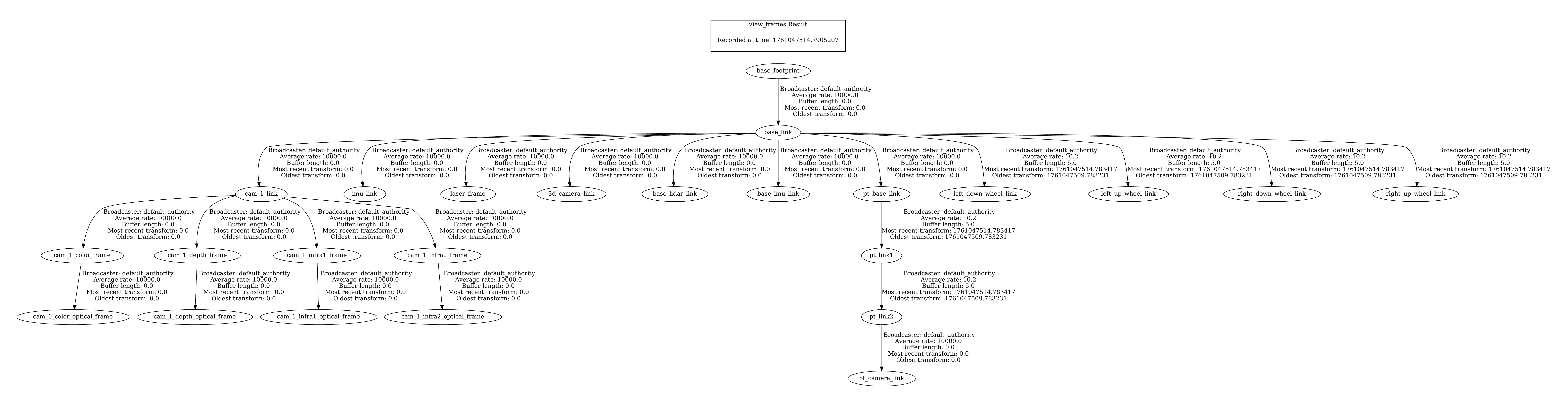





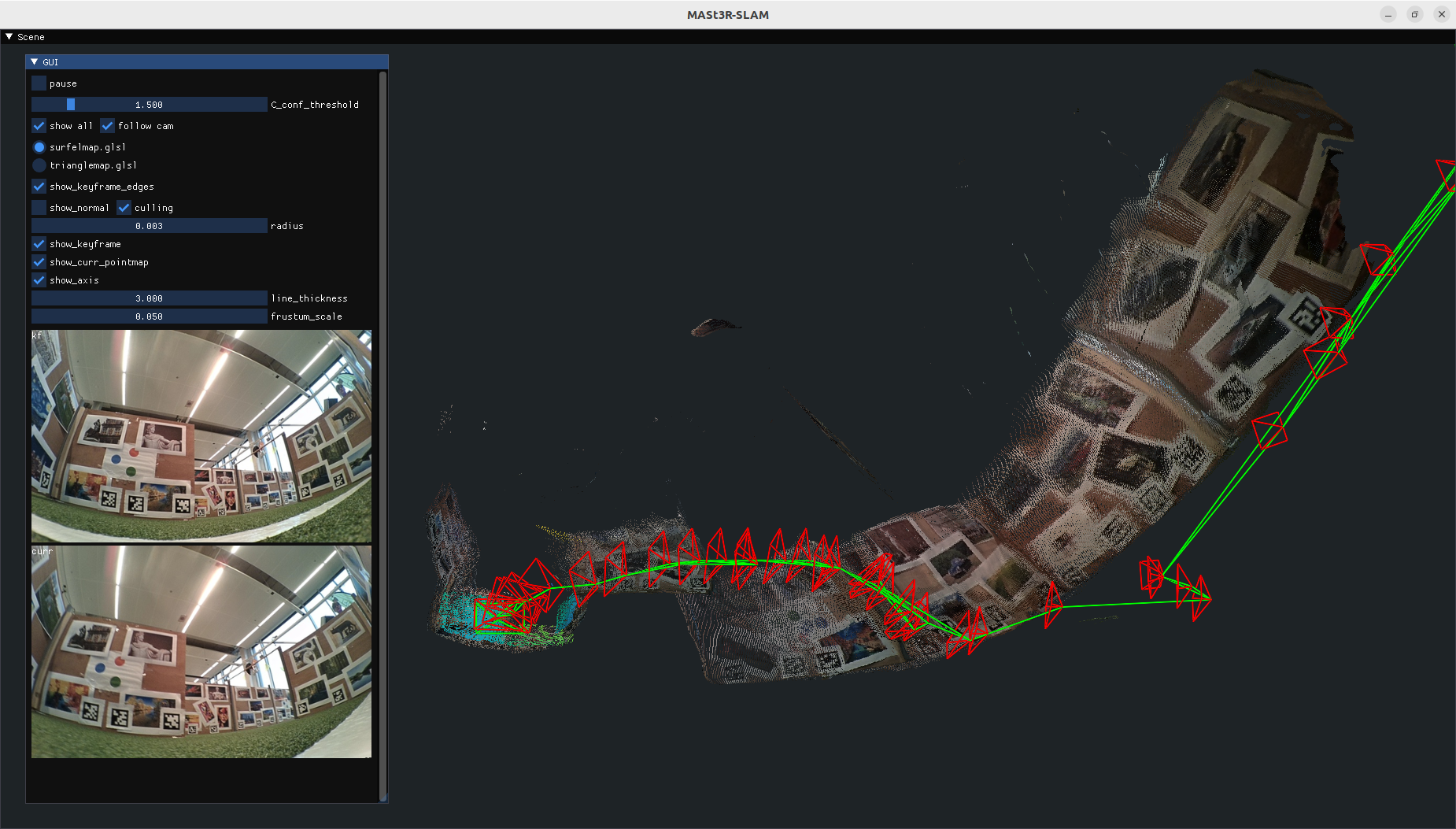
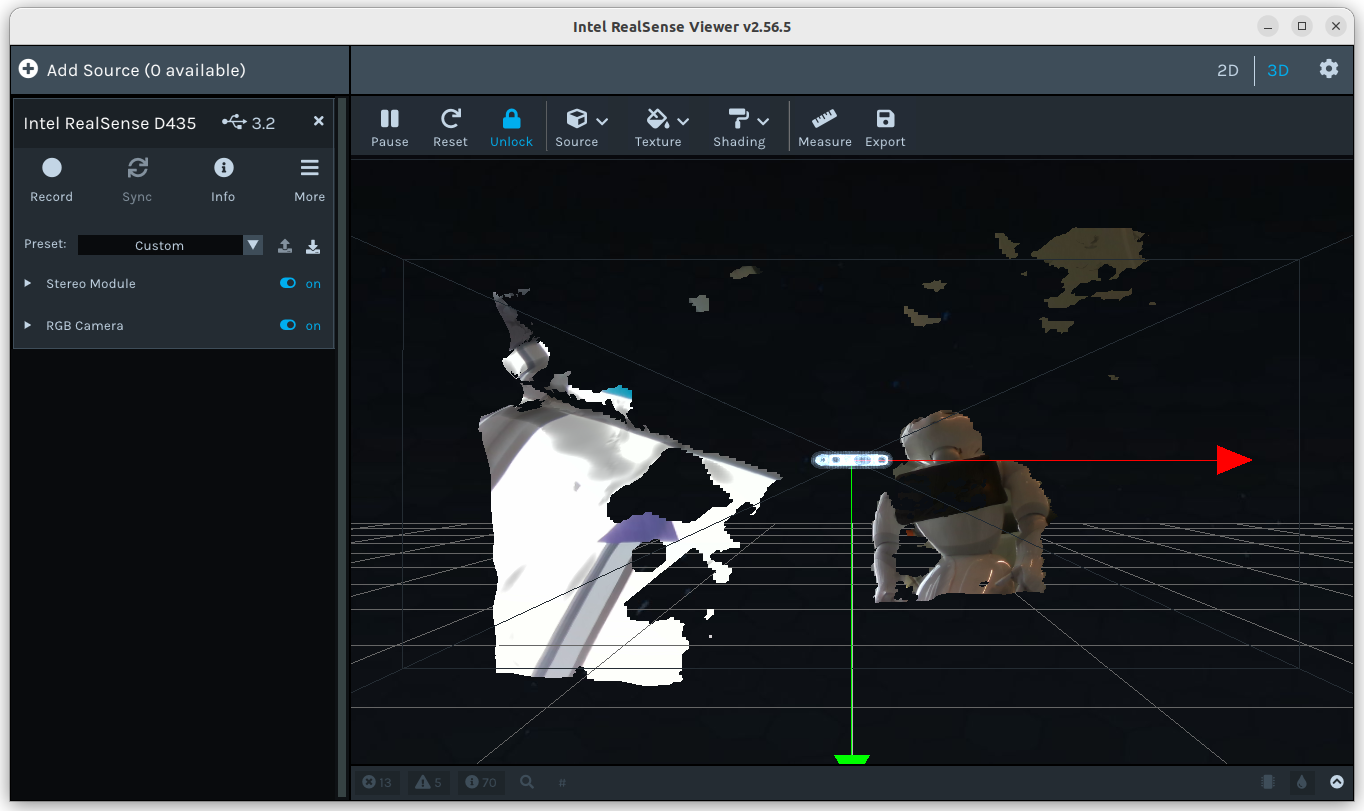










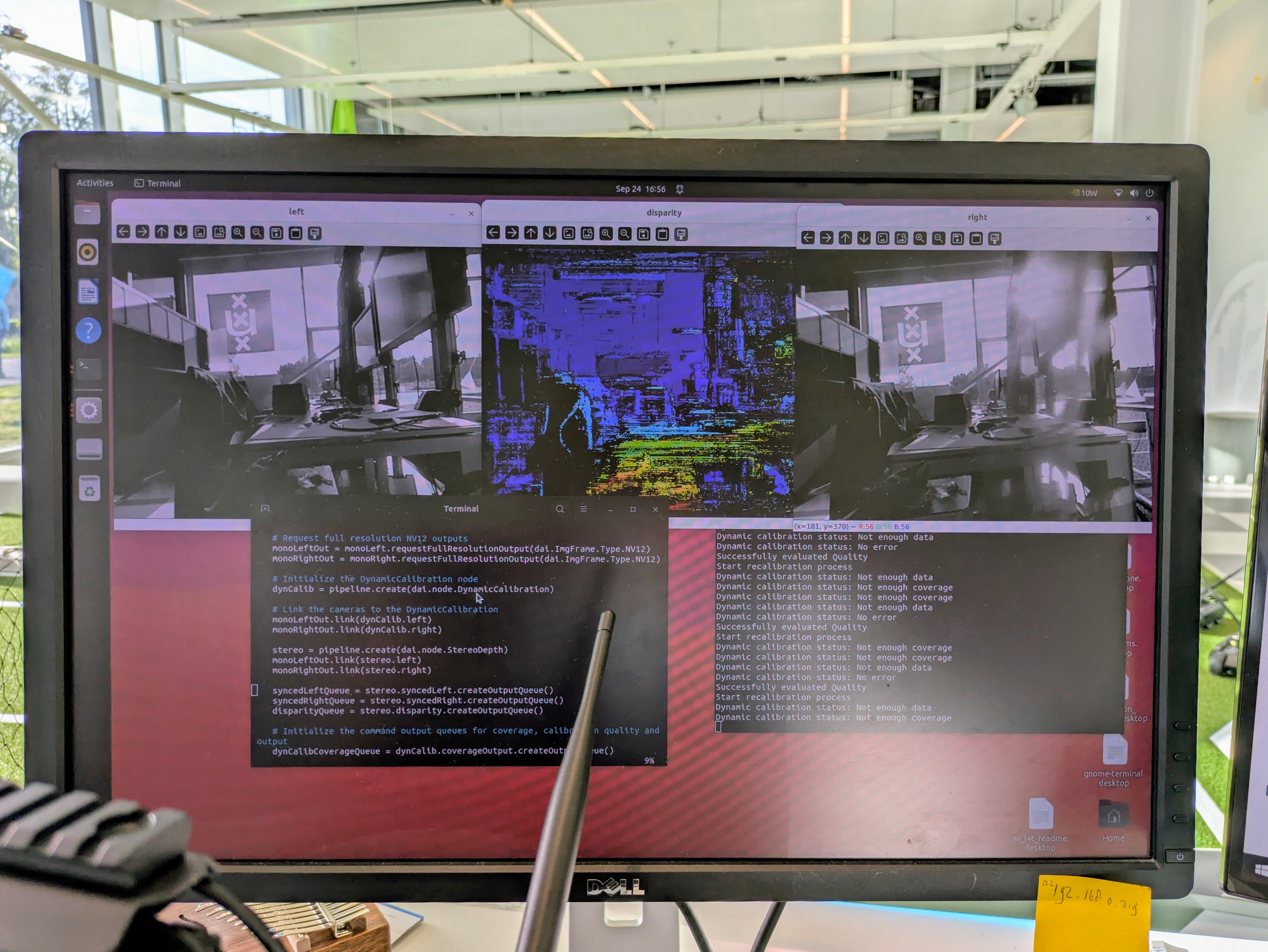
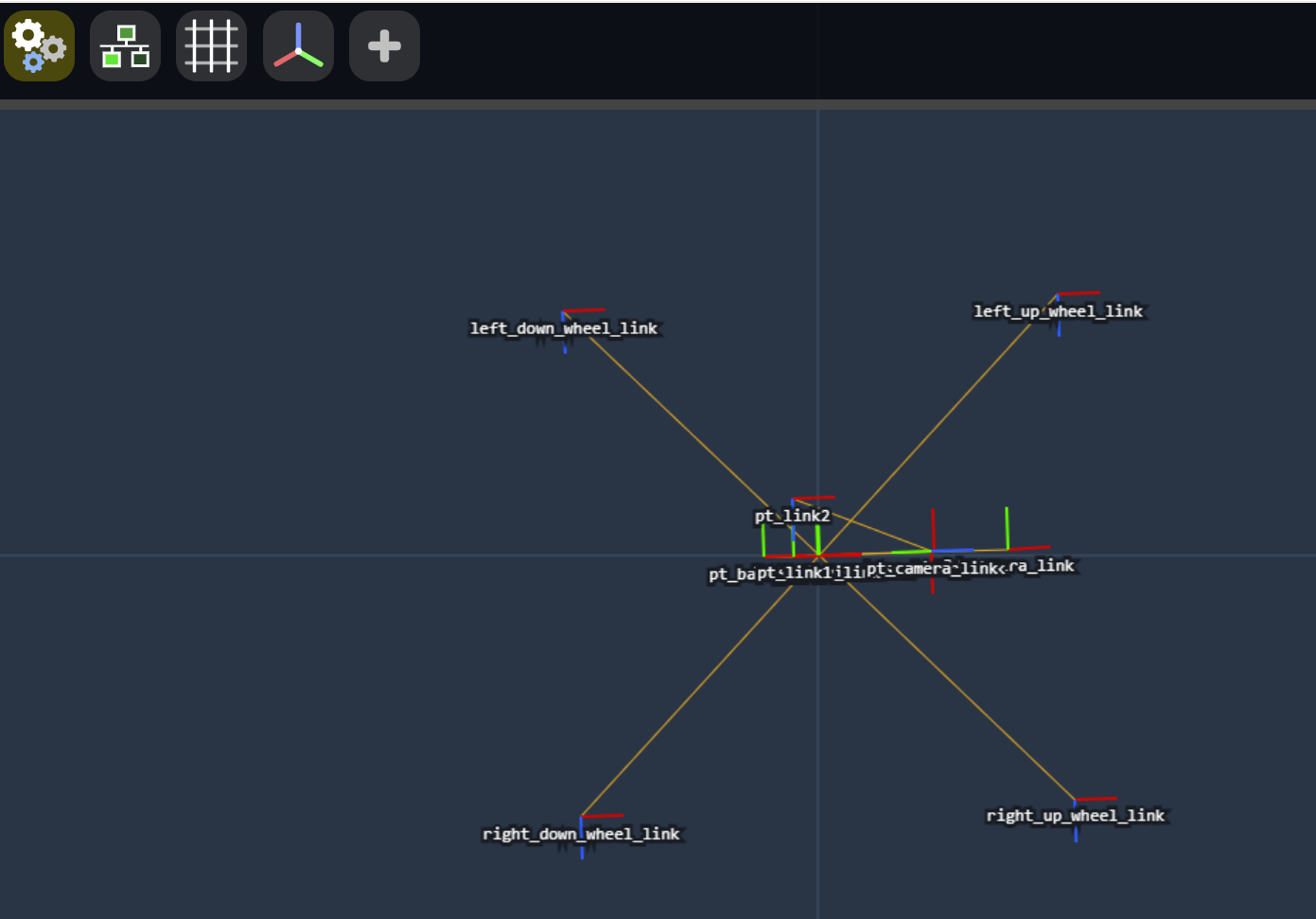







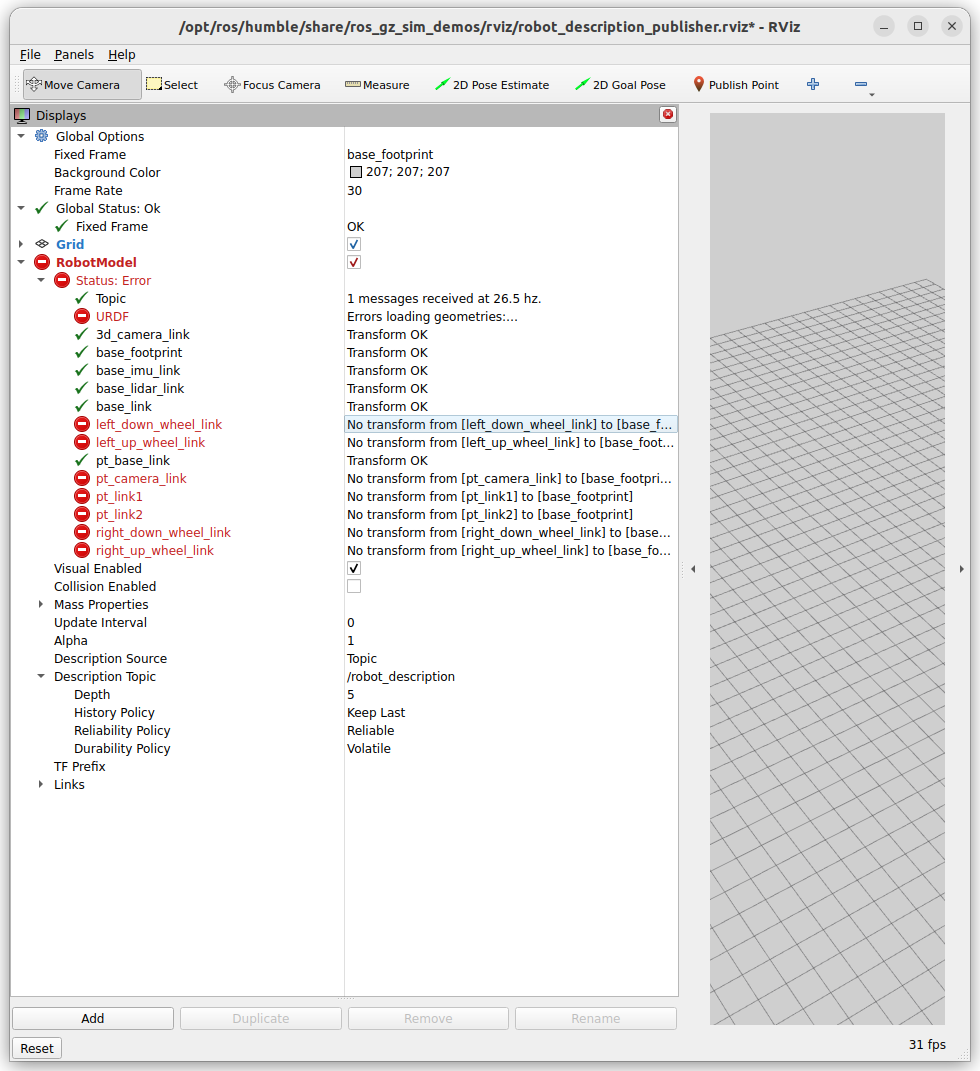
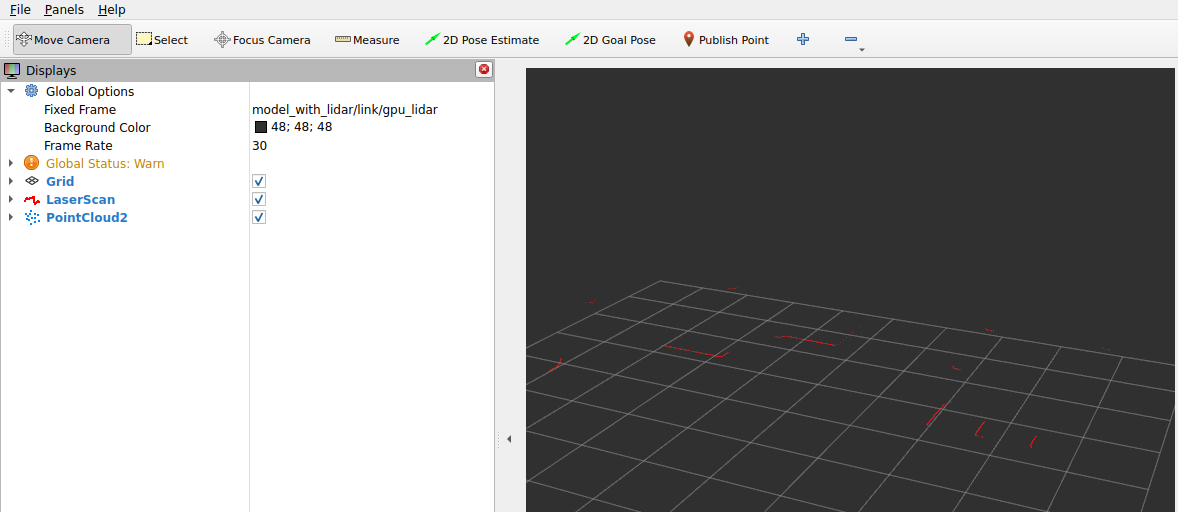
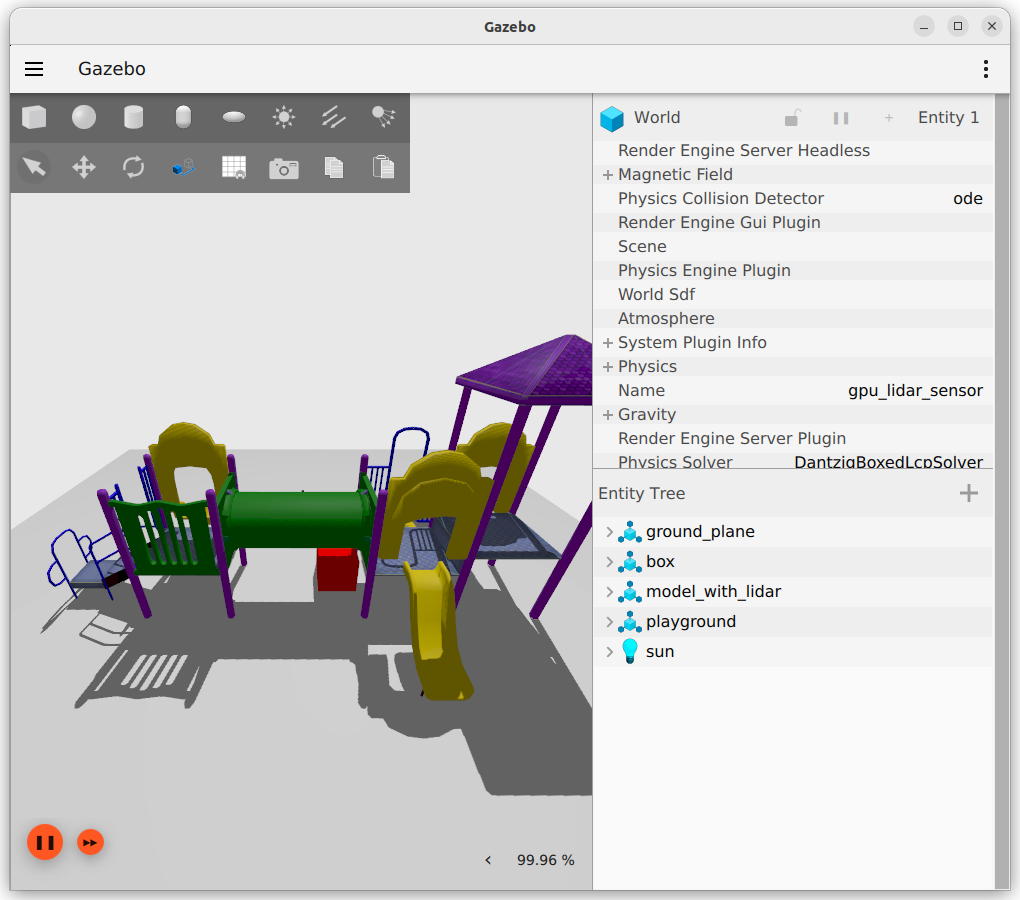
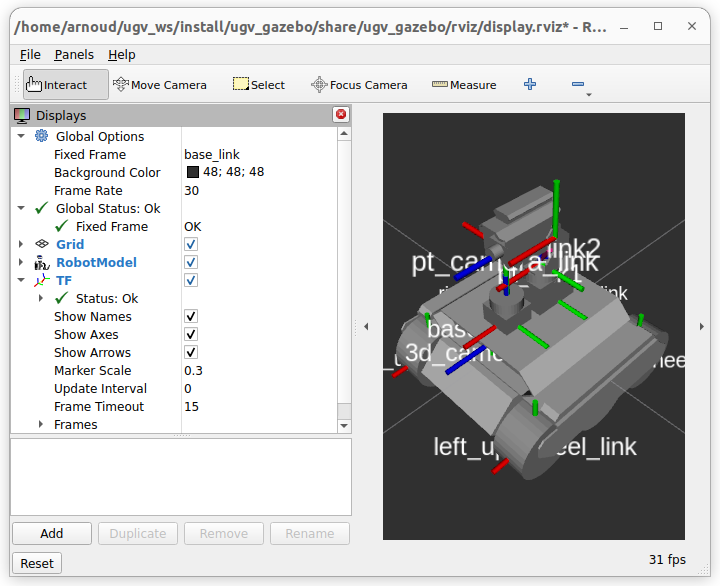
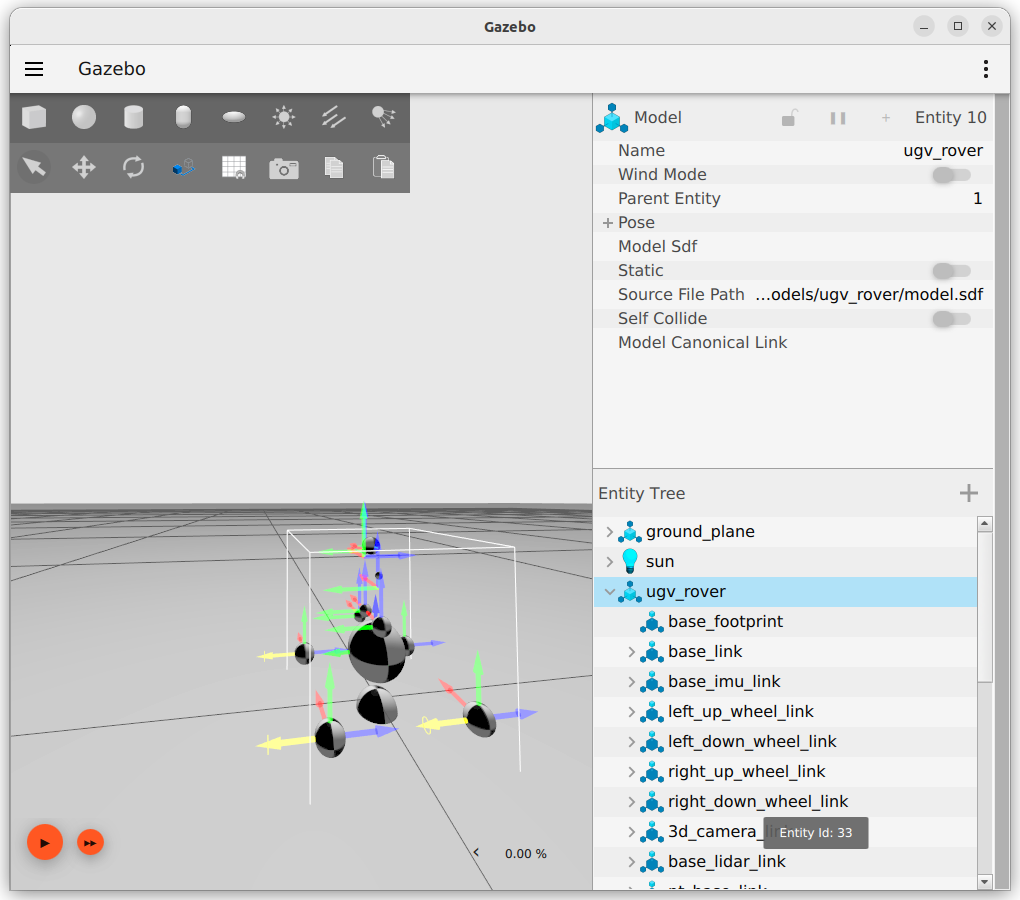






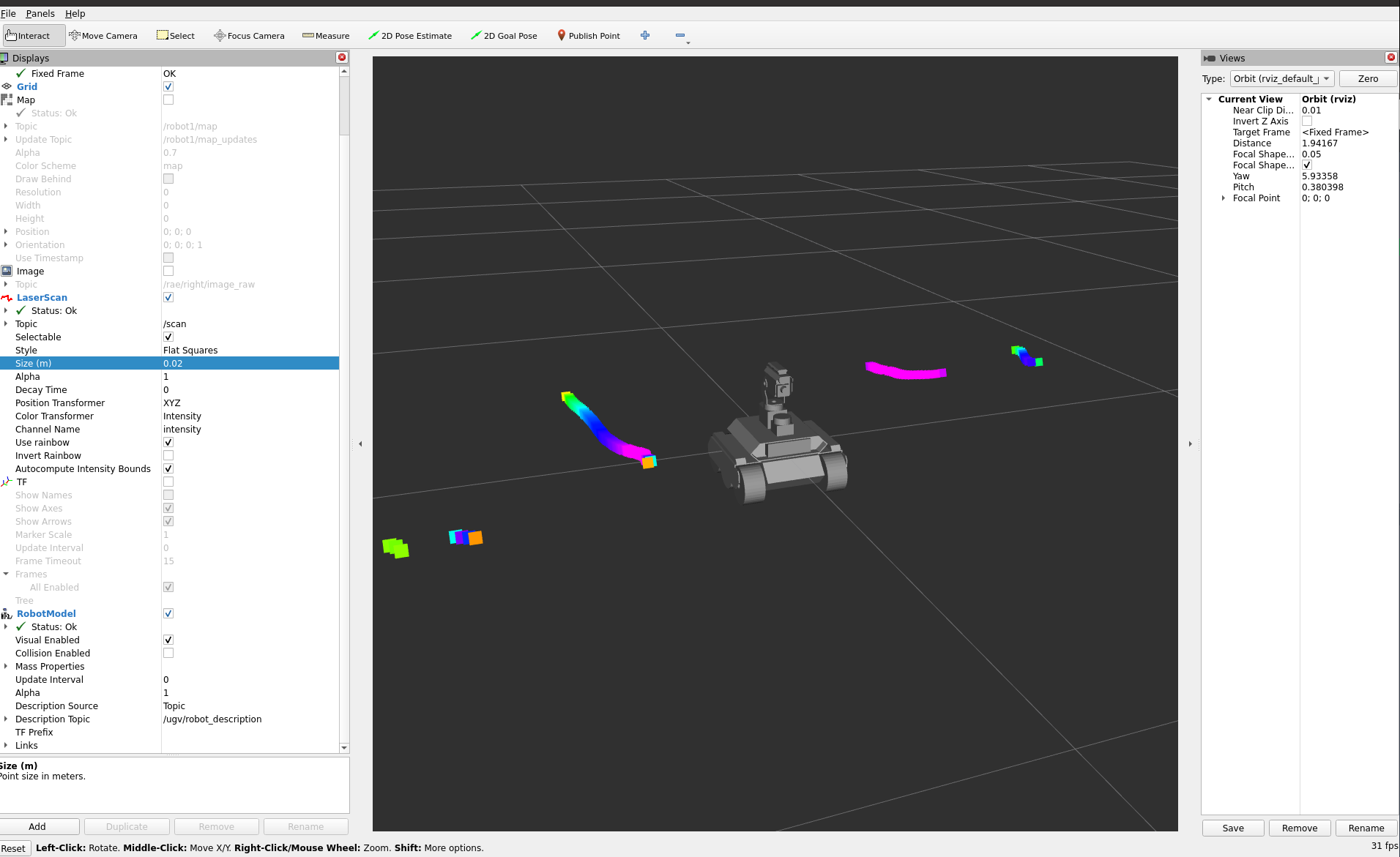
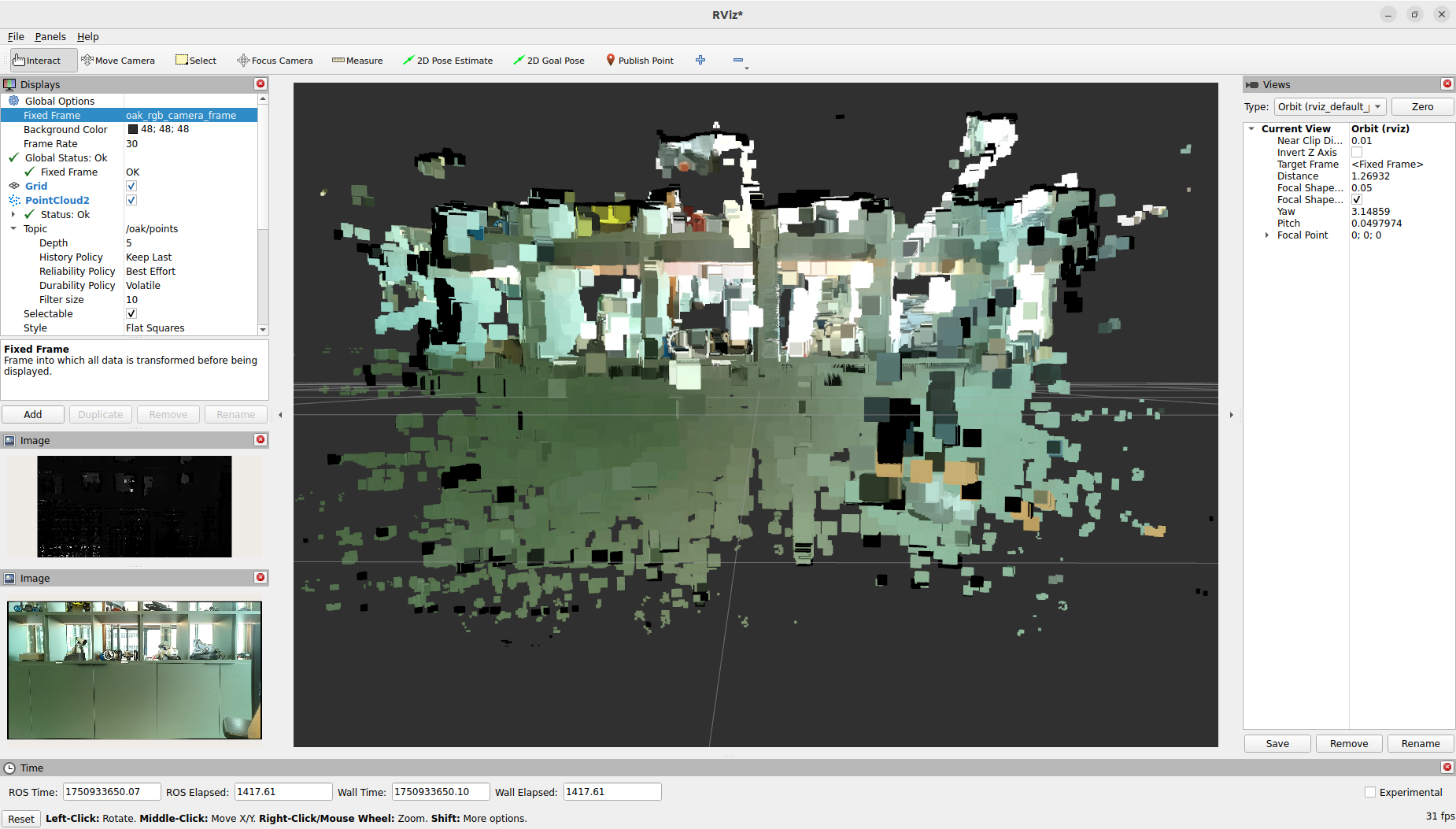
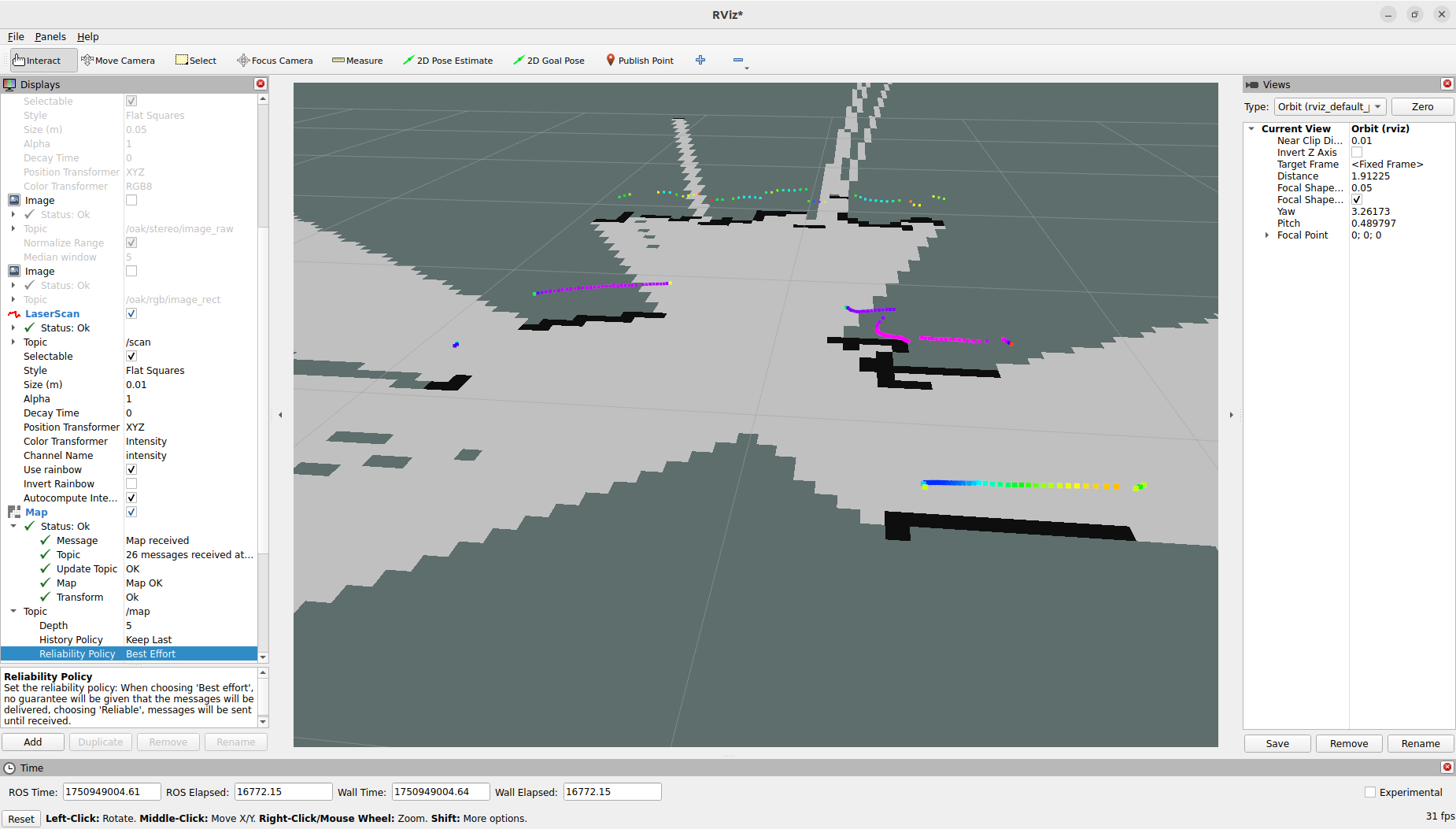
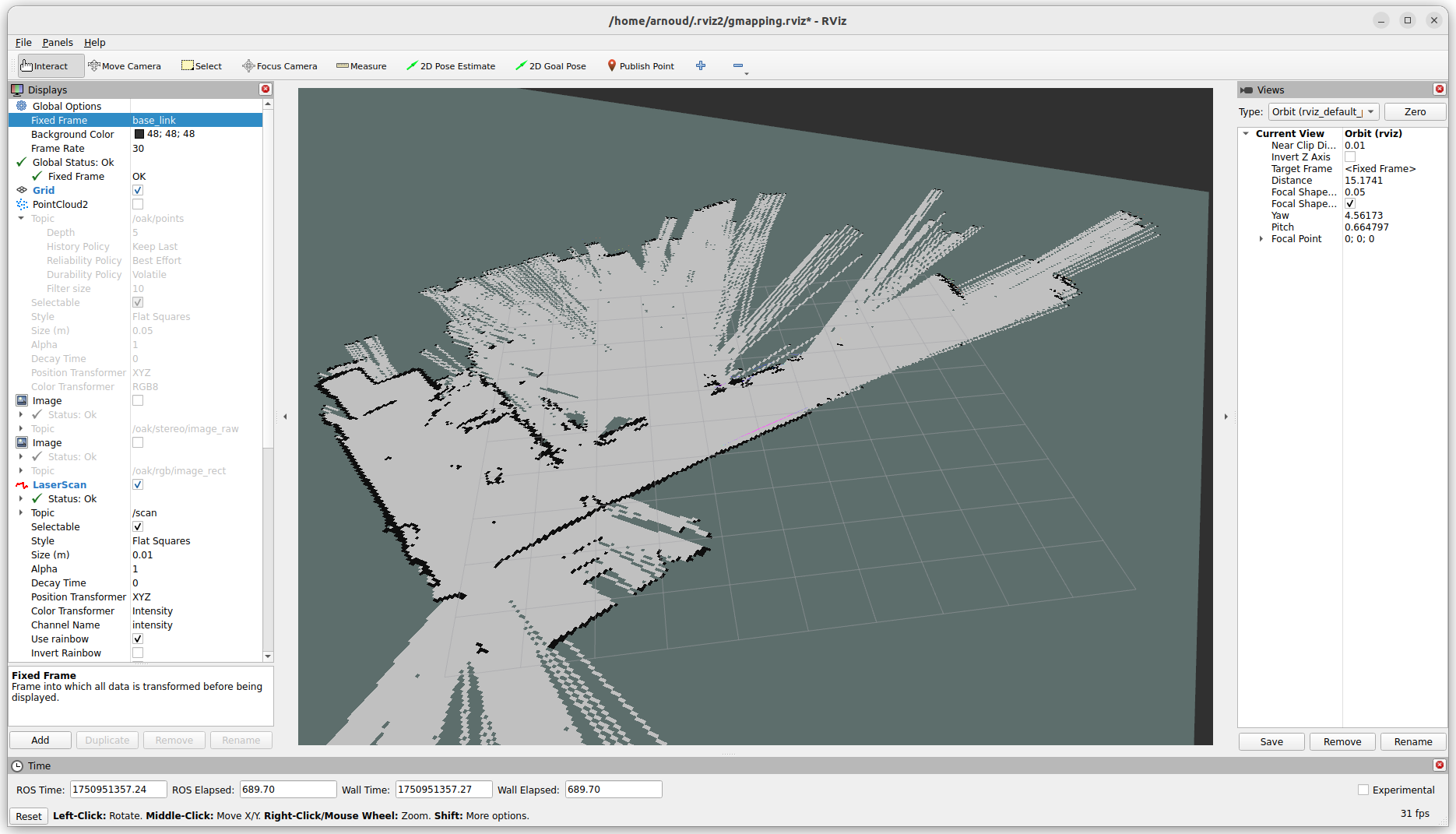
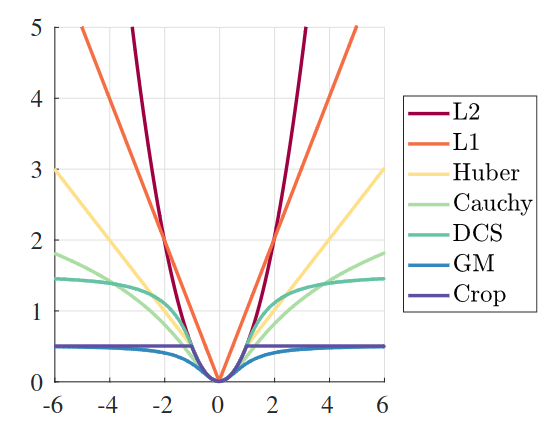

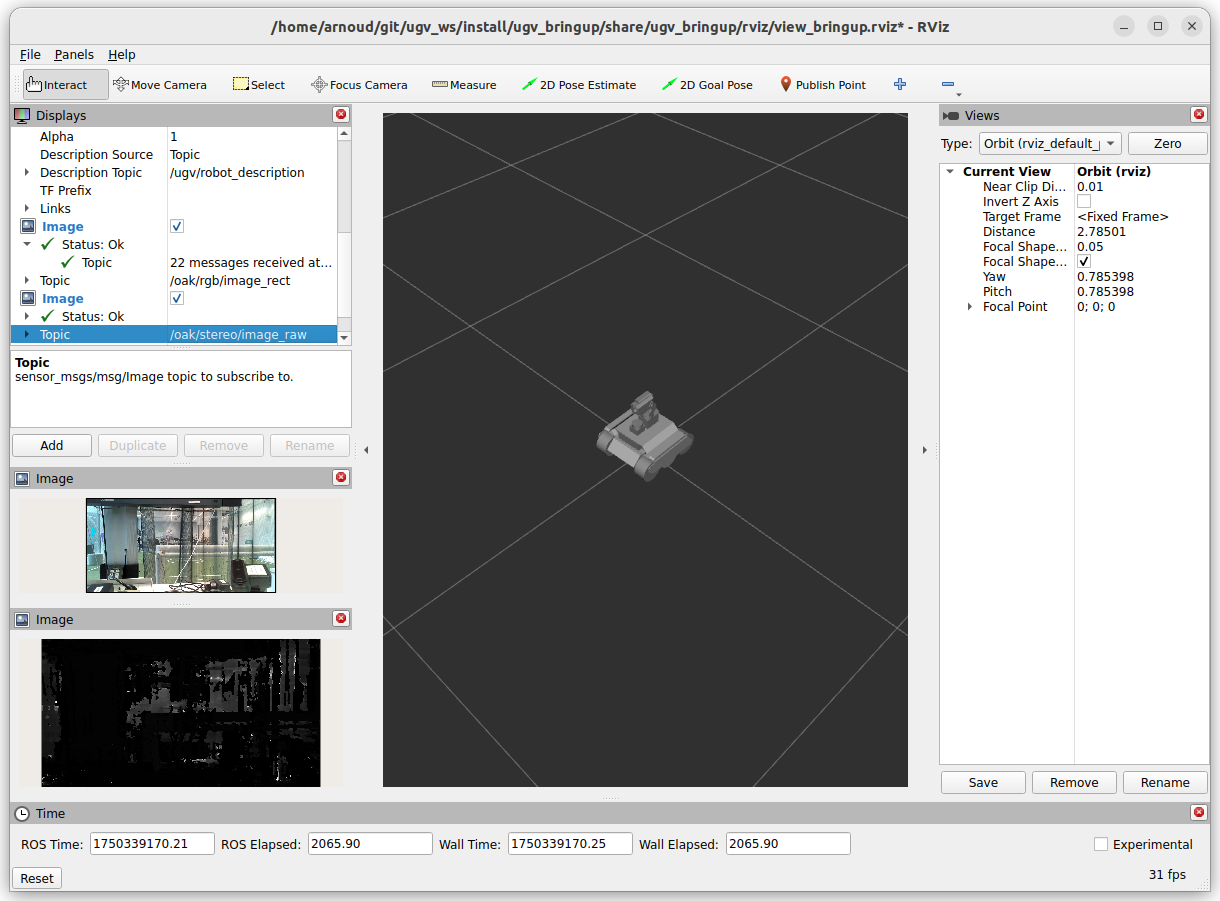
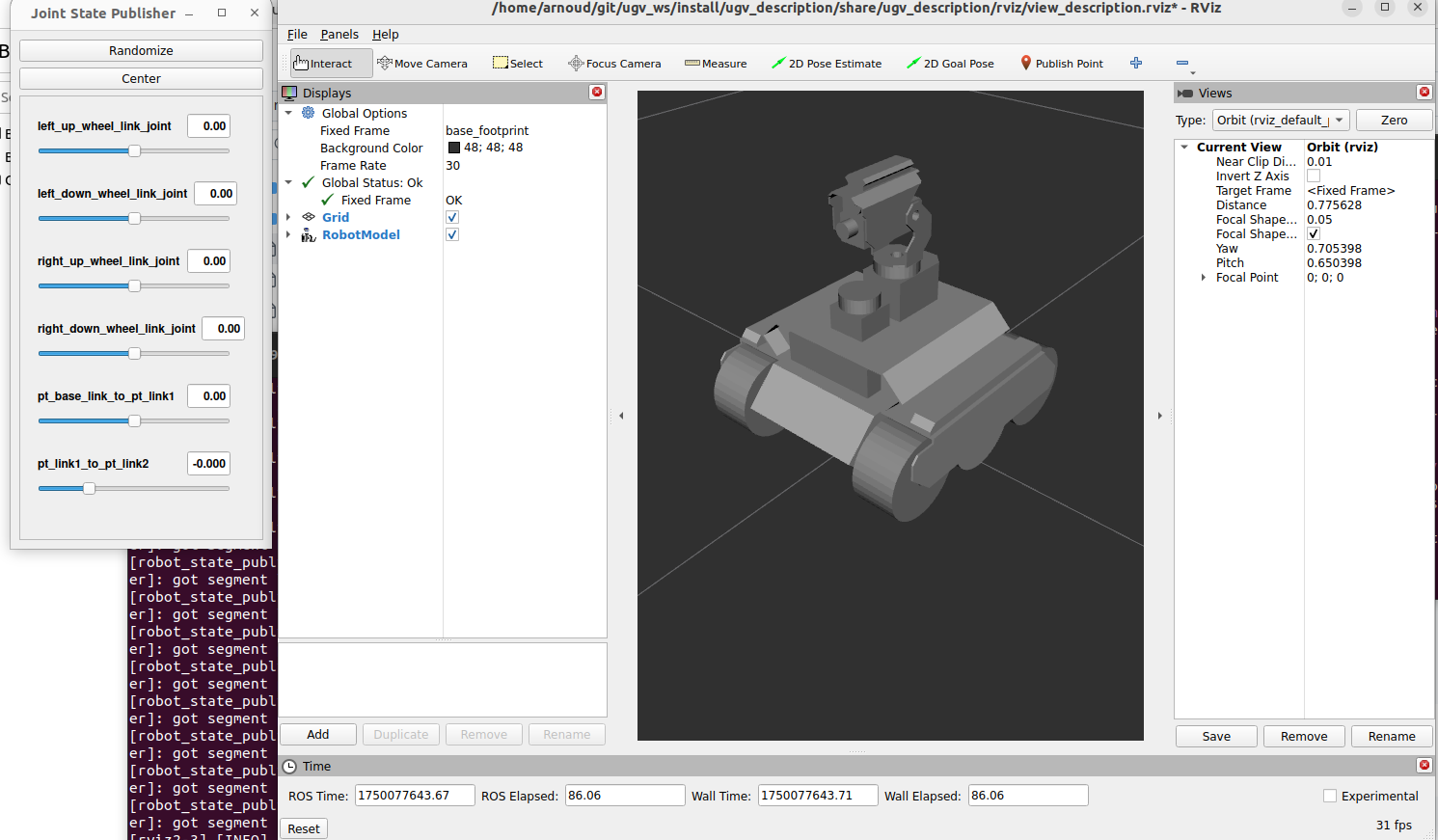
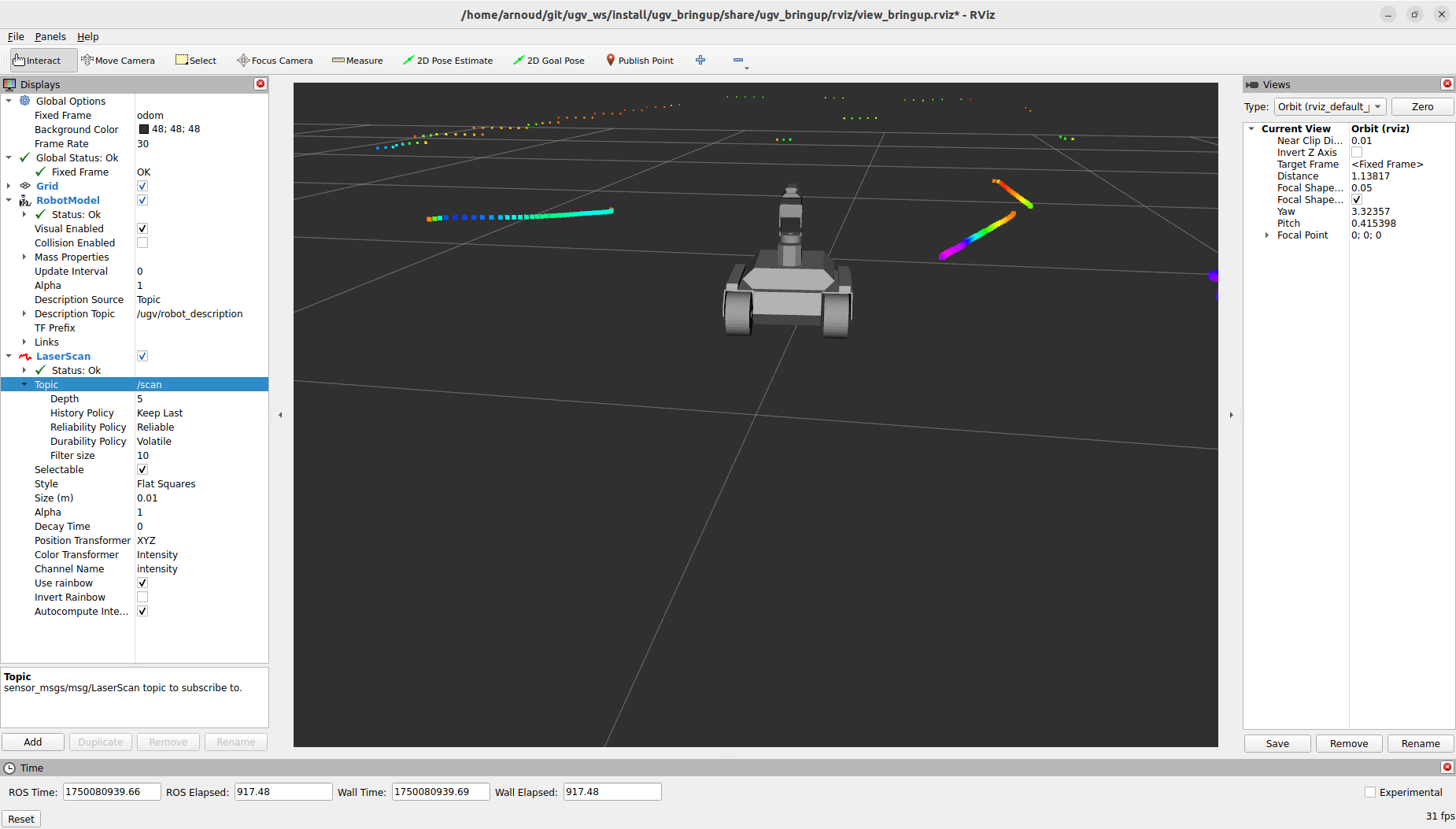


{kind=link}