Results:
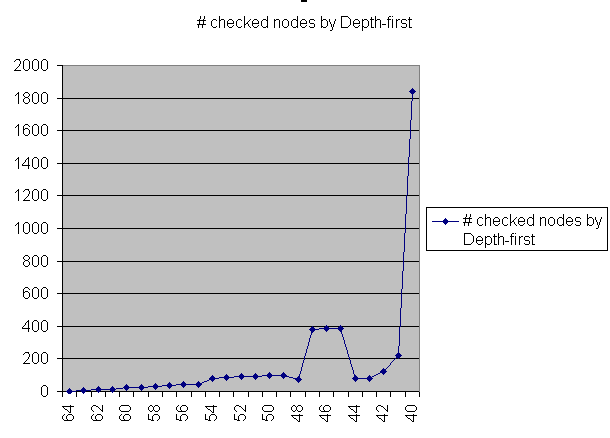
We have measured the number of checked nodes by the depth-first search algorithm, given a certain number of nodes as a starting path. On the x-axes are the number of pre-given points, and on the y-axes the number of checked nodes by depth-first. We have split our results in two graphs. This because otherwise the smaller numbers would all fall away relative to the bigger numbers further on in the graph.
graph 1
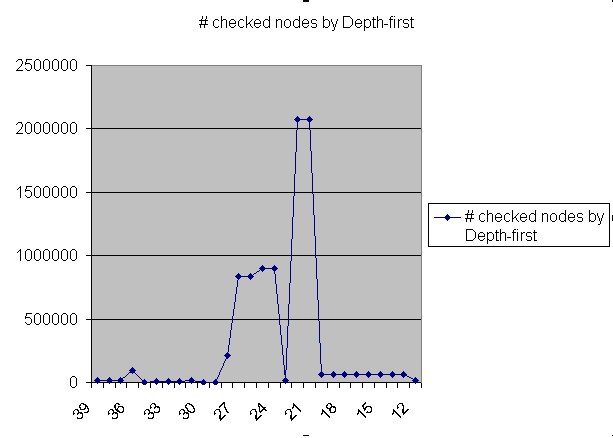
graph 2
As can be seen the problem is very solvable with depth-first in java. Our algorithm checked at an average of 1 million nodes per second (on our home computer). Only at when given very few starting points the number of to be checked nodes by depth-first increased very fast. The complete results can be seen in raw data. The results when given very few starting points are not shown here because of the size of the numbers. The lowest we reached was 7 pre-calculated points, which resulted in a calculation time of about 30 minutes. (In this time the computer was normally used, causing a 5% CPU-usages drop for the programme).
When the depth-first has to build up a path completely on it's own there are too many possible paths (from which most ofcourse will not lead to a solution) and will take too long to calculate.
We will also try to explain the abnormalities in the graph. These abnormalities are caused by the order in which depth-first checks the nodes from a given point, and the fact that there are sometimes more possible solutions given a certain starting path.
The order in which depthfirst checks the nodes is given by the picture below:
8 |
7 |
|||
1 |
6 |
|||
x |
||||
2 |
5 |
|||
3 |
4 |
Let's say depth-first search get's N pre-calculated points. From this point on solutions can be found following step 1 (as the next step from N) of step 8. Depth-first search now first expands the search tree using step 1. But in this sollution a lot of jumps to spot 8 have to made (causing depth-first to wrongly search nodes 1 through 7 several times) which causes a high number of checked nodes.
Let's now say depth-first search get's N+1 pre-calculated points. This extra point it got isn't step 1 (as depth-first followed with N points), but step 8. Now maybe the solution from step 8 includes a lot of jumps to spot 1, leading to a much lower number of checked nodes.