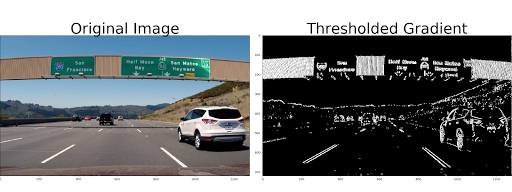
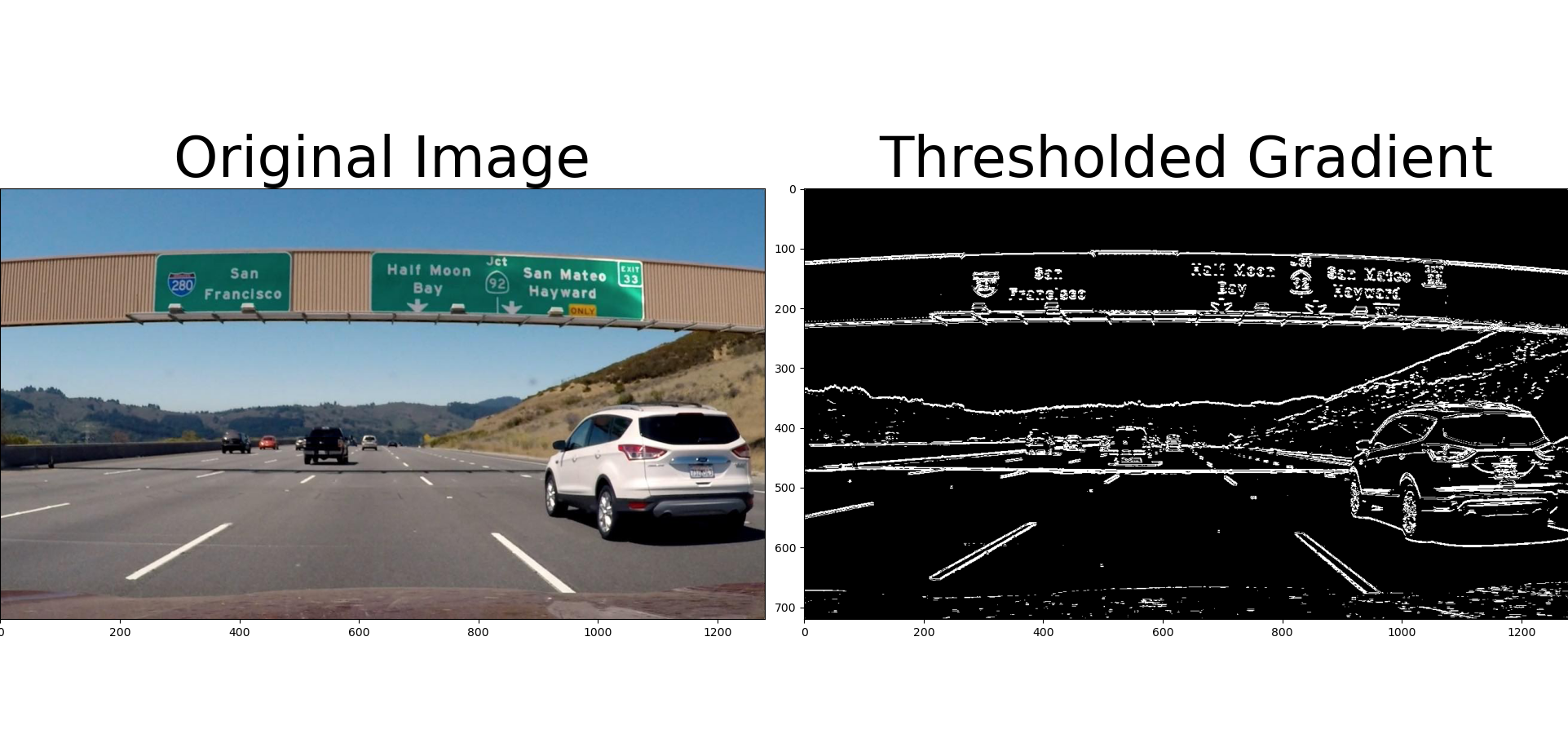
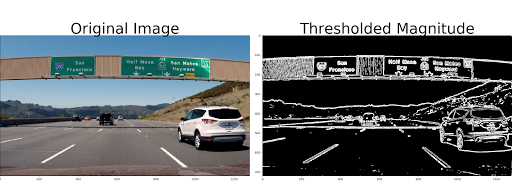
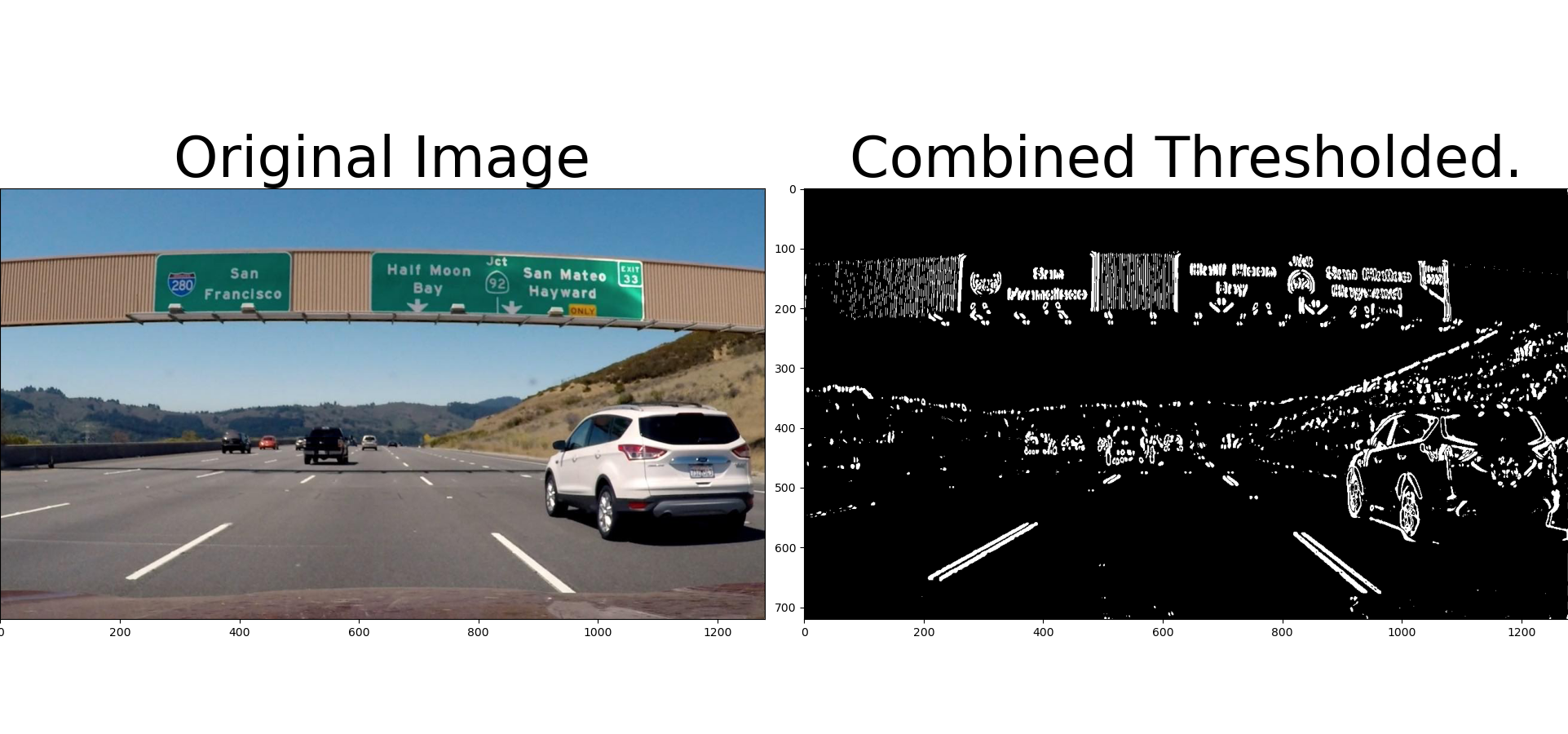
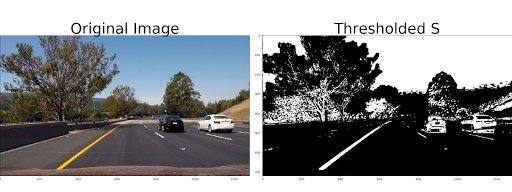
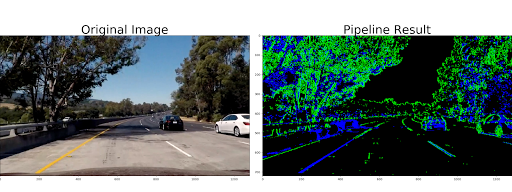
The code now nicely complains when it cannot find the correct egg file. Code assumes that the CARLA directory is installed next to the code, so I made a symbolic link in my ~/git to the latest CARLA directory (the egg-file is loaded in multiple *.py files.
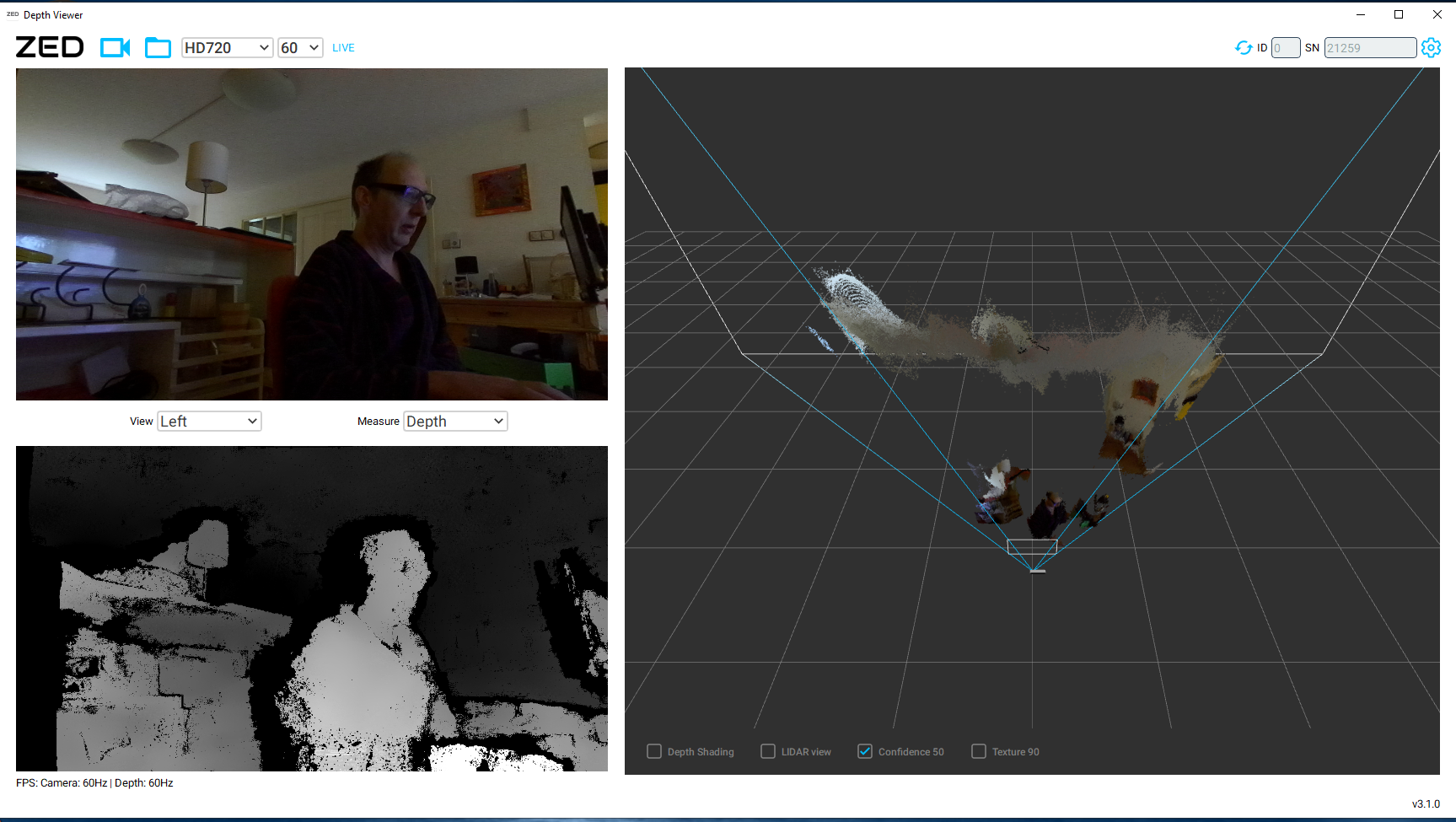
The command python3 main.py --benchmark --synchronous --fps 24 --weights weights/ --config benchmark_config_v1.json Town02 starts nicely, but waits on a CARLA simulation to start.
Unfortunatelly, ./CarlaUE4.sh fails on warning: Not allowed to force software rendering when API explicitly selects a hardware device.
Installed Anaconda3-2020 and created the MCAS from the new MCAS.yml file. Still the same ColorConverter problem.
Created an 'empty' conda-environment for python3.5. First tried it by modifying the given MCAS.yml, but that gave too many conflicts.
Within a the 'empty' MCAS35 environment, still the CARLA egg could be read (while python version was 3.5.5). Unzipped the egg file (in /tmp and copied the /tmp/carla contents into ~/AutonomousDriving/CARLA/PythonAPI/carla. Now the ColorConverter error is gone. Had to remove some python3.7 specific print statements.
Some packages were missing, so installed pip install pygame==1.9.6. For tensorflow version 2.3.0 was required, while python3.5 had only 1.14.0. After that still from tensorflow.keras.models import load_model failed (also after installing pip install keras==2.4.3).
Switched back to MCAS (python3.7) environment. With the egg unpacked the benchmark starts. Still, got Failed to find CARLA directory, followed by hanging on INFO: listening to server 127.0.0.1:2000
December 21, 2020
Trained on Town01 for 50 epochs. The last tree epochs the val_loss didn't improve anymore (converged to a value of 0.36897).
Could not scroll to the output in tmux. The logfile is binary. Maybe I should also upload them to TensorBoard Dev to inspect them.
That works, I could inspect logfile with more detail. It seems that the training converged nicely after 10 epochs / 15k trainings. The epoch_val_loss reached its minimum value after 30k training.
With python2.7 I couldn't add a name to upload command. Also update-metadata (as suggested in the documentation) doesn't work.
Tried python3 main.py --benchmark --synchronous --fps 24--weights weights/ --config benchmark_config_v1.json Town02, but this fails on import carla. Should Install Carla first (section B).
I had Carla already installed in ~/AutonomousDriving/CARLA/. Adding the PythonAPI to PYTHONPATH helps. Next the import fails on ColorConverter, which is a known issue. Without root-permission I couldn't use the easyinstall (note that python3 complains that it cannot find CARLA egg file), instead used pip3 install -U -r ~/AutonomousDriving/CARLA/PythonAPI/carla/requirements.txt. This installed three packages, but not ColorConverter.
Problems seems to be that my python3 is v3.6.9, while the egg file is for v3.5.
ColorConverter is also part of matplotlib, but that doesn't help.
December 19, 2020
Have now access to robolabws8. Copied the dataset/20200621 to ws7. This directory contains all images used for training the steeringmodels.
Started training with command train.py -N 1000 --split 0.8 --model Xception --epochs 1 --batchsize 32 --scale 20 --info TEST_RUN1 ~/carla/dataset/20200621/. Yet, with from tensorflow.keras.applications import ResNet50, ResNet101V2, ... it failed on the import of 'EfficientNetB7'.
As indicated in the Readme, EfficientNet is only included in the Tensoflow-GPU version 2.3 and higher. Yet, the model chosen here is Xception, so removing EfficientNetB7 from the import in train.py solves this issue.
The training is ready in a minute (which I doubt). Seems that it only trained one epoch (as requested). Loss improved from inf to 1.61090. Increased to 10 epochs. After 10 epochs val_loss improved from 1.58471 to 1.58232. Script hangs on terminate called without an active exception. Control-C or Control-Z doesn't help. Killed the session from an other terminal with tmux kill-session -t town01.
Thomas was training the networks over 50 epochs, with train loss below 0.01 (see Table 6 on page 45).
December 17, 2020
Tried to reproduce Thomas work on Town02, with the command python3 main.py--benchmark --synchronous --fps 25 --weights weights_Xception/ --configtest_config.json Town02, but Thomas github doesn't contain main.py.
Followed the Installation instructions (now on robolabws7), but ~/AutonomousDriving/CARLA/PythonAPI/*/*.py also contains no main.py.
For the Raspberry the GND is on pin 6, while for 96boards the GND is on pin 1 and 2. So, this will require careful rewirring.
Looked at the code of sense hat, but it seems that the device is controlled via glob (for the led-frame) and RTIMU (for the IMU and the three other sensors).
Via glob the code makes contact with /dev/i2c* and /sys/class/graphics/fb*
According to this post, a working pin layout is:
any ground pin
1, 2 - 3v and 5v power
3, 5 - BCM
2 and 3 - I2C
16, 18 - BCM
23 and 24 - Joystick
27, 28 - BCM
0 and 1 - EEPROM
December 3, 2020
Found this Edge computing platform which demonstrates end-to-end learning / driving with 95% reduction in latency and power consumption.
Interesting is that camera based approaches perform poorly in 3D localisation, and LiDAR is limited because the far measurements are quite sparse. The idea of the paper is to convert multi-sensor depth estimates into pseudo LiDAR points, to get dense enough point-clouds to reliable generate 3D frustrums.
Yet, it seems that the Bird Eye's View map (BEV) is only based on the LiDAR data, not on the depth estimates from the camera. The LiDAR backbone chain is fed with a 2D BEV image, which is processed by customized ResNet (deeper and thinner than ResNet-18).
The Table with results shows that most LiDAR and fusion based show good performance on the BEV object detection benchmark (between 70% and 90% performance). For the hard 3D object detection this performance sometimes drops to 50%, although the presented MMF algorithm still reaches 68.41%. On easy BEV the MMF algorithm reaches an average precision of 89.49%.
In a more recent work, Arnoud de la Fortelle used two CNN-branches processing the Laser and Camera feeds, to be fused by a dual head network which estimates the translation and rotation.
Couldn't find any recent convergence plot in Thomas labbook, but his experiments are monitored online, so the plot of Epoch loss can be created on request. The results look great, except the green line which represents the validation run of DenseNet121
November 25, 2020
Found this interesting paper, which applies hierarchical semantic segmentation for scene understanding.
November 24, 2020
Rebooted the RB5 system.
Tried camx-hal3-test.
That fails on writing permissions on /data/misc/camera. Made this directory owned by video instead of root, and added myself to the group with sudo usermod -a -G video robolab. Still, the commands cat /proc/meminfo /data/misc/camera/meminfo*.txt failed.
Performed the test again with sudo camx-hal3-test, which still works fine.
Started dbus-launch --exit-with-session weston-launch after setting export GDK_BACKEND=wayland, but this fails with the error message falling back to eglGetDisplay.
Added the setting export WAYLAND_DISPLAY=wayland-0, but now wayland-backend.so complains that it cannot open shared object file. Same after export XDG_RUNTIME_DIR=/run/user/1007
November 23, 2020
Found Deep Evidential Regression, which claims to find the confidence without out-of-distribution sampling. The code is provided as supplemental material, which is based on TensorFlow.
Looked again at my weston implementation on RB5. Changed in ~/.config/weston.ini both @bindir@ and @libdir@ to the actual path, and now I get a weston-terminal. The gnome-terminal and google-chrome still fail.
Even better: cheese works! Although it also complains that no device is found.
Resetted MESA_DEBUG, WAYLAND_DEBUG and LIBGL_DEBUG. A critical failure that I get is from GLib-GIO-Critical: G_IS_DBUS_CONNECTION failed. If I execute it as root, I get the error: Unable to init server, connection refused.
Following lubosz, I set GDK_BACKEND=wayland. Nautilus gives 4 critical errors (including Glib-GIO-CRITICAL), but I get a nautilus starts and can be used to explore visually the file system. cheese still fails to connect to the camera.
Checked Webcam troubleshoot page again. I have four /dev/video* devices. Tried vlc, which fails with Failed to connect to socket /run/user/1007/bus, which is the DBUS_SESSION_BUS_ADDRESS. Followed by Could find the Qt platform plugin "wayland". Yet, there is a /run/user/1007/dbus-1 directory.
Launched weston now with dbus-launch --exit-with-session weston-launch. The Glib-GIO-CRITICAL error is gone. Still, I receive cheese-CRITICAL: cheese_camera_device_get_name: CHEESE_IS_CAMERA_DEVICE failed.
November 21, 2020
Followed the readme of Thomas van Orden and installed Carla 0.9.8 via option B. Tested until ./CarlaUE4.sh.
Luc de Raedt gave an interesting talk how you could combine Neural Nets, Probability and Logic Inference with this DeepProbLog NeurIPS 2018 paper.
Also watched the NXP video on ADAS use cases. I liked the look-through truck use case and see around the corner use case.
November 13, 2020
So, I continue with building Wayland from source on the Qrb5165 ARM-processor, as suggested at Wayland freedesktop.
Installed meson and did meson build/ --prefix=/usr. Yet, the file meson.build checks if the symbol SFD_CLOEXEC is defined in sys/signalfd.h, and this include file is not present on my ARM-system.
The QRB5165 is a board which combines a CPU and a GPU. The CPU is Kryo 585, which is a ARMv8-A core.
Tried to install the missing headers with sudo apt-get install linux-headers-generic.
Had to do a huge sudo apt-get update; sudo apt-get upgrade (which was including all ros-dashing updates).
Also did a git pull, which updated the meson.build of documentation.
The version 4.15.0 kernel-headers for my Ubuntu 18.04 system.
Now /usr/include/linux/signalfd.h exists, but /usr/include/sys contains only the file capability.h. SFD_CLOEXEC is defined in /usr/include/linux/signalfd.h.
Made as root a symbolic link from /usr/include/sys/signalfd.h to /usr/include/linux/signalfd.h, but still the meson build fails.
Did a new ./configure, which reports that SFD_CLOEXEC is declared. Meson reads the configuration, but apperantly not good enough.
Followed the instructions on Freedesktop's building Wayland and configured again with ./autogen.sh --prefix=/usr, followed by a simple make, which seems to work.
Also the installed worked. Suggestion was to add LD_LIBRARY_PATH to /etc/ld.so.conf, but /usr/lib is already added by the configuration file /etc/ld.so.conf.d/aarch64-linux-gnu.conf.
The make install in ~/git/wayland-protocols installs the protocols in /usr/share/wayland-protocols/unstable, next to the stable-directory.
The only executable made so far is /usr/bin/wayland-scanner, which can generate glue-code.
Continued with building ~/git/weston. The build directory was already made by a previous call of meson build/ --prefix, which could be remade by ninja -C build/ reconfigure. Added a missing library with sudo apt-get install libxcb-xkb-dev, but the ninja -C build/ install still fails on missing EGL/eglwaylandext.h. That seems to be part of Mesa EGL.
Followed the installation instructions from Mesa 3D. Couldn't build because meson was too old. Found several versions. The one in /usr/bin was installed with apt-get (old version 0.45). The new version (0.56) was installed in ~/.lccal/bin, but that was not added to my path in ~/.bash_profile Now it is.
Downloaded v20.2.2 of mesa. That requires libdrm_nouveau >= 2.4.102, while this system has 2.4.101.
Downloaded v20.1.8 instead. That one supports v2.4.101 of libdrm_nouveau.
Installed sudo apt-get install bison flex and optional packages such as llvm libzstd-dev libvdpau-dev.
The requested options from Wayland (OpenGL ES 2, GBM, wayland- and drm-drivers) are set by meson.
Continue with ninja -C build/ (which compiles 1726 files).
The command sudo ninja -C build intall installs the headers in /usr/local/include/EGL and the libraries in /usr/local/lib/aarch64-linux-gnu.
Now I can go back to ~/git/weston, do a ninja -C build/ reconfigure, ninja -C build/ and sudo ninja -C build/ install.
I have now 31 new weston-executables in /usr/bin/, only weston-simple-dmabuf-drm is still from the original version.
First tried the X-option. Configured the local display with export DISPLAY=127.0.0.1:0 and typed weston. v 9.0.90 started, read ~/.config/weston.ini, but loading /usr/lib/aarch64-linux-gnu/libweston-10/x11-backend.so fails with fatal: failed to create compositor backend.
Tried instead weston-launch after sudo chmod +s /usr/bin/weston-launch. As background I have the sky (standard weston.ini loads Aqua.jpg, but that one was not available in gnome/backgrounds. Used Road.jpg instead). I have four crosses that point gnome-terminal, weston-terminal, google-chrome, weston-flower, but nothing happens when I click on them. Could be that resolution is wrong, because also there is no road.
Could exit from weston-launch with the Ctrl+Alt+BackSpace key.
The used icons were 24x24, while /usr/share/icons/gnome/ had the option 16x16 and 32x32.
Weston also installed a /usr/share/weston/background.png
Found good icons in Tango and Adwaita directories. Have the feeling that I get no response because of permissions of old files in XDG_RUNTIME_DIR, in my case /run/user/#.
Enabled the logmessages, as suggested on Running Weston section. Main problem seem to be that msm_drm library is not loaded. I had two versions of libdrm, an older one in /usr/lib and a newer one in /usr/lib/aarch64-linux-gnu. Yet, it seems that it is looking for the library in a dri-subdirectory.
In meson_options.txt there are several interesting options, such as -Dimage-jpg and -Dlauncher-logind.
Yet, both option seems to be true on default. What is more interesting is the option backend-default. Default setting is -Dbackend-default=drm, now I will try -Dbackend-default=wayland.
Yet, with that option set, I get a failed to create compositor backend, even after export WAYLAND_DISPLAY=wayland-0.
Read the drm documentation, and tried weston --backend=drm-backend.so. Now I get the error: drm backend should be run using weston-launch binary, or system should the logind D-Bus api.
Set the default to auto. Also activated the documentation, by pip3 install sphinx breathe sphinx_rtd_theme
Documentation is made, but man weston-launch still founds nothing.
The new AI Driving Olympics have been started. Submissions have to be uploaded before 5 december.
For the new challenges (Lane Following with Duckies and Lane Following with other vehicles), only one submission is made, the other entries are still the baseline.
The first webinar was presented by Andrea Censi (ETHZ) and Liam Paull (U. Montréal).
The advanced perception challenges is organized by NuScenes. The Lidarseg Challenge will be opened at November 15th.
November 5, 2020
Watched the TNO webinar on self-driving cars. The MCAS project was mentioned by Jan-Pieter around 15:11.
November 4, 2020
Read the original CARLA paper (CoRL 2017), which is already cited 943 times. Interesting is that they compare three classic approaches (modular pipeline, imitation learning, reinforcement learning). Even the modular pipeline is quite advanced, with a semantic segmentation network based on RefineNet to recognize road, sidewalk, lane marking and dynamic objects (i.e. other cars and pedestrians).
All three approaches are well trained, but it is difficult to say how generic the conclusions will be. Yet, the major message of the article is that the CARLA environment could be used for this sort of benchmarking.
Looked the most influencial articles which cite this article.
The ICRA 2018 is from the same authors, going further with imitation learning, and applying it on a remote controlled car. While in the original paper the succesrate for IL dropped from 83% to 38%, in this paper the drop is from 88% to 64%. Note that these are values for the navigation with dynamics scenario, while we experiment in navigation without dynamics. Another difference is that in this paper the training is still in Town1 and the validation in Town2, while we use the combination Town3 / Town10.
In another CoRL 2018 paper from the same author the modularity is tested, by comparing approach with intermediates on segmentation and waypoint leveli (still Town1 / Town2).
This ECCV 2018 paper is interesting because it analysis in detail what the predictive power of error rate is on the success rate (still Town1 / Town2).
The CoRL 2019 paper Learning by cheating uses both the CoRL 2017 benchmarks as the more recent NoCrash benchmark, which is based on ICCV 2019 paper. This last paper compares to original imitation learning (CIL) with 3 state-of-the-art methods (which include affordances, semantic segmentation and on-policy interaction). In the ICCV 2019 they extend CIL with a double head, which allows to control the speed. They are able to get successrates of 92% to 90%, which was the moment to introduce a more challinging scenario (NoCrash). This NoCrash scenario seems to be still based on Town1 and Town2 (although also reference to Town3 can be found on accomponying code). Nice is that for the first time also the standard deviation is added to the NoCrash results. On the empty road they have successcores of 97% to 90%.
The PMLR 2020 paper Learning by Cheating even claims a 100% performance on the CoRL2017 benchmark (solved problem). For the NoCrash empty scenario they showed an impressive 100% to 70% successrate. Note that for earlier Carla versions the result were even better (more than 30% difference in completion rate between the versions).
Tried it out, but strange enough pip3 and python3 don't point to the same version on WSL of my home-computer.
Installed the required packages for main.py via pip and python, including seaborn.
I could reproduce the cut-in prediction numbers as presented by TNO in their precentation of 23 september (accuracy of 97% on the dataset of 7284 cases (with 1945 cut-ins).
October 27, 2020
Installing gnome on the RB5. After installing gnome, I should be able to start a Gnome-Wayland session.
Strange, manual starting XDG_SESSION_TYPE=wayland dbus-run-session gnome-session fails. Partly this was due because the XDG_RUNTIME_DIR was claimed by the root, so replaced that with export XDG_RUNTIME_DIR=/run/user/$(id -u) in my .bashrc.
The error is process org.freedesktop.systemd1 exited with status 1, so looked at the suggestions in this post.
The command systemctl --user status dbus.service shows that the dbus-daemon is running.
I changed the .bash_profile as suggested in https://wiki.archlinux.org/index.php/GNOME#Wayland_sessions, but could better follow the suggestion of FranklinYu.
Running the gnome-session-binary with option --debug shows that there is a critical error: We failed, but the fail whale is dead. Sorry. This is a reference to lifting a dreamer:
Which actually means that there is not enough Gnome to show an error-message in Gnome.
Trying to install lightdm, instead of gdm3. Testing it with lightdm --test-mode --debug. Fails on No such interface 'org.freedesktop.DisplayManager.AccountService' and greeter display server failed to start.
Installed lightdm-gtk-greeter, but that doesn't help.
Tried if weston --tty=1 --connector=29 --idle-time=0 still worked. This failed, because the drm backend should be run using weston-launch binary as root.
Running weston with sudo doesn't help, because the XDG_RUNTIME_DIR is not set for the root. Switching to the root with su helps, weston still works.
It is possible to start weston as service: weston.service.
Used the Gentoo wiki suggestions to add my user to the weston-launch group. That doesn't work. Should try to use weston-launch.
Edited /etc/environment to add XDG_RUNTIME_DIR to the environment variables of the root (thanks to this post). Now sudo weston --tty=1 --connector=29 --idle-time=0 works.
Just weston-launch also works. Yet, weston-launch -- --modules=xwayland.so fails on no directory section in weston.ini.
It would be good if I would create /etc/xdg/weston/weston.ini. According to the man-pages, I could specify in the core-section the different modules. Yet, in /usr/lib/aarch64-linux-gnu/weston I only see cms-colord.so, cms-static.so and screen-share.so, no xwayland.so
I lost my wireless settings.
Looked at Linuxbabe's tips: iwconfig sees no wireless extensions for wlan0. sudo ifconfig wlan0 up doesn't help. sudo wpa_supplicant -c /data/misc/wifi/wpa_supplicant.conf -i wlan0 indicates that another wpa_supplicant is already running.
Wired up with ethernet-cable. Installed gnome-session-wayland. Tried gnome-session --session=gnome-wayland, but nothing happens.
Tried sudo systemctl restart gdm3, but that gives only a blinking prompt. Needed a hardware reboot after that.
Now going all the way: install ubuntu-desktop.
The xserver crashes with a segmentation fault, propably the display-drivers.
According to this post, wayland could be disabled in /usr/lib/udev/rules.d/61-gdm.rules.
Was looking into which display drivers are used, but all tricks like lshw and lspci show no information, so it seems that all graphics are done by the processor.
Interesting is this check sudo systemctl status display-manager, which indicates loaded lightdm.service, inactive (dead)
Interesting, by doing sudo dpkg-reconfigure gdm3 I see that also the initscript of gdm3 fails.
So, I continue with building wetson from source, as suggested at Wayland freedesktop.
The Weston has quite some dependencies. One I couldn't resolve was the logind service, but luckely there was no build option for that.
After configuring with meson, still the compilation fails on missing include-directories.
The Learning by Cheating benchmark is very interesting (and already quite good).
Read Matlab News item, which indicated the benefit of thermal imaging.
Powered up the Qualcomm RB5, and looked if I could connect via de adb shell.
Had some problem with starting up, but after some wiggling and pushing the power button the leds get green.
Tried to connect to device from Ubuntu 18.04 via WSL, but adb devices shows no device.
Same from my native Ubuntu 14.04. Also installed adb for windows, following these instructions. Powershells complains that this version (39) doesn't match this client (41).
Connected to the VGA monitor, I get no terminal.
Connected to a HDMI monitor. Now the PowerShell sees the device. WSL doesn't.
Connected native Ubuntu machine. That one saw the device, but complaint that it didn't had permission because the udev rules where wrong. Followed the instructions from Android developer and installed android-sdk-platform-tools-common (after sudo add-apt-repository universe). Yet after that command no complaint anymore, but also no device!
Also checked the Tunderbolt USB-C cable, that also works. Connecting to USB-B at the RB5 and USB-C on side of the nb-dual doesn't work.
Further explored the tutorials. Found out that the Wenston desktop still needs a HDMI screen. Could start a terminal and show the snapshot I produced earlier (note that the protection is still on the lens):
Starts with cloning r2.1 from tensorflow. Yet, the build of the aarch64 library fails on missing flatbuffers.h
Checked < a href=https://www.tensorflow.org/lite/guide/build_arm64>tensorflow instructions, and found out that I first should do ./tensorflow/lite/tools/make/download_dependencies.sh. Now the aarch64 library starts to be build.
Continue with the instructions for OpenCV for Wayland.
The model that needs is in the directory above the build. The RB5 has 4 video's in /dev/video*, althought no /dev/video2 as indicated in project. Added Linux webcam, which is visible with lsusb.
Checked the Ubuntu Webcam page, but Cheese and vlc didn't work. Vlc indicates that it doesn't work as root, so I should create an user.
Changed the index of OpenCV VideoCapture, but all failed on inappropriate ioctl for device.
October 21, 2020
Looked if I could connect the Raspberry Pi Sense Hat to the Qualcomm RB5 board, but the 40 pin low speed connectors have a different physical dimension (at the RB5 board 2mm, while the Rapsberry GPIO connector is larger (2.54mm or 0.1 spacing)).
Looked if there are converters, but couldn't find such converters.
I connected the board to HDMI screen and a keyboard. I could login to the Ubuntu 18.04.2 LTS shell with default credentials.
Modified the /data/misc/wifi/wpa_supplicant.conf as suggested in set-up-network. Note that the default location of this file is /etc/wpa_supplicant.conf. After rebooting I am connected.
Installed apt-get install usbutils git bc.
Was able to do camera-testing with camx-hal3-test, with the commands specified in run camera-capture. The snapshot*.jpg can be found in /data/misc/camera. Couldn't inspect it yet, because I have no gui running (yet).
Run the ROS2 publish/subscribe demo, which worked, although a bit ackward because I had only one terminal.
Couldn't find the github repository for Hello-World. Instead used git clone https://github.com/quic/sample-apps-for-Qualcomm-Robotics-RB5-platform.git and tried Device-info project.
The Makefile only works if you create first a ../bin directory. Here I can see that I have 8 cores running at 1.8 GHz.
Next I tried the GPIO-samples. With the command ./qrb5165_platform -led green 255 I could turn on the LED between the two USB-connectors. The color red is the right, the color is to left of the green led in the middle (but on my RB5 platform all three leds are green).
Also tested ./qrb5165_platform -button and pushed the Volume- button. This is reported to be Key 114.
Tested ./qrb5165_platform -temp, which reported SoC temperature: 39.10.
Strange, the camera led is red, and vcgencmd get_camera gives supported=1 detected=1. The camera led starts off, but before my raspistill command already goes on. I have the feeling that the duckiebot camera-node is claiming the camera.
Checked the ip-adress with hostname -I. Better to use sudo ifconfig.
I have the same issue as April 24: no ip4 address (only ip6).
Tried several things, but in the end I edited /etc/wpa_supplicant/wpa_supplicant.conf because I made a typo in the robolab password.
Now I get a ip4 address, which I could use to do ssh duckie@ip4-address.
Charging the battery while working, but receive now regular under-voltage detected warnings.
This is a new laptop, so I have to install dts again. Next time.
Thomas Wiggers github page for MCAS can be found here.
Thomas van Orden github page for MCAS can be found here.
The loomoguy shows how to set the Segway into developer mode in video. Have to find a way to switch back to user mode. Found the Loomo developer mode switch at the bottom of the settings. The Segway reboots.
The servo from the JetRacer arrived. Replacing the servo worked, the JetRacer could be controlled from the basic_motion notebook.
Calibrated the steering by disconnecting the axis from the servo, put the steering / offset to zero and reconnected the axis again (straight up). This looks good, I have the full left/right control.
Couldn't test with the gamepad, because I couldn't find the usb-dongle.
Tested the camera with gst-launch-1.0 nvarguscamerasrc ! 'video/x-raw(memory:NVMM),width=3820, height=2464, framerate=21/1, format=NV12' ! nvvidconv flip-method=0 ! 'video/x-raw,width=960, height=616' ! nvvidconv ! nvegltransform ! nveglglessink -e, camera also worked.
Updated the packages, didn't upgrade to Ubuntu 20.04 (yet).
Didn't see the 12.6 V power supply, did all testing on batteries.
September 29, 2020
Alex Kendall's work on predicting futures resonates well with Gavves's ERC grant.
Adding port-forwarding to my ssh command to ws7 worked ssh user@ws7 -L 8888:localhost:8888.
I could now start the jupyter notebook examples/visualisation/visualise_data.ipynb and access it from my Windows machine with http://localhost:8888/notebooks/visualise_data.ipynb (with a Window's Xserver running).
The location of the dataset is specified by an environment variable: os.environ["L5KIT_DATA_FOLDER"] = "/home/user/git/lyft/l5kit/l5kit/l5kit/data/prediction-dataset"
The trajectory of the complete sample dataset can be visualised, including the trajectory of a single vehicle :
Also tried the agent_motion_prediction example, including the traffic lights. Generating and Loading the chopped dataset failed, so maybe I must unpack the training set (downloaded the first part). Anyway, this cell (after the disclaimer) costs quite some time.
The cell hangs on 3%, but the next ones execute without problems:
September 28, 2020
Finished watching of Alex Kendall's CVPR workshop keynote. He not only gives a nice overview of several key-developments of autonomous driving (including video's of the ALVINN from 1989. Yet, more important is his comment on 18:50, where he claims that in simulation the photo-realism is not important, but the diversity is. They especially created simulation models for training, instead of validation of algorithms as most people do.
Interesting for us is the effect of including intermediate representations to make the policy learning more efficient, as described in the ICRA 2020 paper "Urban Driving with Conditional Imitation Learning".
Looked in our Pure database for autonomous driving publications of our institute. Found for instance:
Read the whitepaper to determine how large a dataset with 1000 hours of driving would be.
That information is not in the whitepaper, but after registration I saw that there is a small sample dataset of 51Mb available. The training set itself is so large that it is provided in two parts (78.4 Gb in total).
Created a ~/git/lyft/l5kit/l5kit/l5kit/data/prediction-dataset directory with three subdirectories (scenes, aerial_map, semantic_map) and moved meta.json from the semantic_map directory to the prediction-dataset directory. Also downloaded the first part of the training set (8.4 Gb).
Installation via github was the developer way, should still run pipenv sync --dev (if possible - no it wasn't). Otherwise I have to fall back on the user option, so now running pip3 install l5kit, which also downloads all dependencies.. Also should check how to do the visualisation to a remote display.
Running jupyter notebook examples/visualisation/visualise_data.ipynb and looking if http://robolabws7:8888/?token= worked, but that gave a connection error.
September 23, 2020
Watched the first part of Alex Kendall's CVPR workshop keynote, where he indicated human-intermediate representations based on semantics, motion and geometry (5:12).
September 20, 2020
Found the report "Ethics of Connected and Automated Vehicles" of Prof. Martens. The table on page 65-70 shows which part of the recommendations are relevant for respectively the manufacturers, policymakers and researchers.
This video of Nvidia shows the prediction of a lane change. A little more information is available in blog. For instance, the work is based on PredectionNet, which is presented at Nvidia's GPU Tech Conference. PredictionNet is trained on Carla Town 01. The converted the camera and radar data into bird-eye views (including map lines and past trajectories) and predict future trajectories).
Followed the unofficial instructions with apt-get -y install docker.io. That goes well, although the next optional steps fail.
Yet, The command to build the docker image ( sudo docker build -t ubuntu:18.04-sdkmanager .) fails, because unzip cannot be found. Failure is earlier, in the RUN apt-get update.
Problem seems to be that the docker has no dns or internet. Tried the tricks of using the host network, partly because docker --network is not available for the older (14.04) version of docker and also the system-wide fix fails. Testing the fix still gives no servers could be reached.
Should try it from native 20.04.
Rebooted my XPS13 to native 20.04
Followed the instructions and created a docker image, which I could reach with ssh hostPC@127.0.0.1 -p 36000. Started in this image sdkmanager and created a rb5-arm64-image with command (1).
In the mean time reading some background information on EDL mode, which stands for Emergency Download Mode.
Yer, still no response. Even tried adb reboot edl, but no devices found.
As survey of lane-position detection techniques the Handbook suggested J.C. McCall's article from 2006. Note Table 1 with a comparison of techniques from 1992-2004.
The sdkmanager is a script which downloads many packages. On Ubuntu 20.04 this failed, but on Ubuntu 18.04 I could create an image that could be flashed to my RB5 board.
Downloaded latest distribution with wget https://download.01.org/opencv/2020/openvinotoolkit/2020.4/l_openvino_toolkit_runtime_raspbian_p_2020.4.287.tgz.
Installation works fine, until Building and Run Objects.
The Build command is missing a subdirectory at the end of cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_CXX_FLAGS="-march=armv7-a" /opt/intel/openvino/deployment_tools/inference_engine/sample.
Making the Makefiles fails on missing /usr/bin/g++. Installed that with sudo apt install g++.
No example image was given, so I downloaded wget https://docs.openvinotoolkit.org/2019_R1/face-detection-adas-0001.png from OpenVINO Object detection documentation.
Result is Successful exection and a out_0.bmp.
Strange enough, I couldn't find ADAS-documentation no longer in 2020.4 documentation.
August 1, 2020
At home I had both a wired as unwired connection to internet.
Did an apt-get update; apt-get upgrade
Did an apt-get install console-setup
Now I could do dpkg-reconfigure console-setup, as suggested by rasberrypi-spy.
Selected the largest font (16x32), which works fine for the OLED.
July 30, 2020
Connected the Loomo via the Extension Bay with nb-ros. First tried the USB 2.0 cable. Note that this intended for power only. Didn't see any new device, when I did lsubs and dmesg | tail -40.
Connected the USB File Transfer cable. That cable was directly recognized by Linux:
[23192.996506] usb 3-2: new high-speed USB device number 6 using xhci_hcd
[23193.163994] usb 3-2: New USB device found, idVendor=067b, idProduct=2501
[23193.164006] usb 3-2: New USB device strings: Mfr=1, Product=2, SerialNumber=3
[23193.164012] usb 3-2: Product: USB-USB Bridge Cable 2.0
[23193.164018] usb 3-2: Manufacturer: Prolific Technology Inc.
[23193.164023] usb 3-2: SerialNumber: 0
With ls usb it present itselves as:
Bus 003 Device 006: ID 067b:2501 Prolific Technology, Inc. PL2501 USB-USB Bridge (USB 2.0)
Yet, didn't see any partition over this bridge.
Connected an ethernet cable via two USB-ethernet adapters. I get an inet6 address, no inet4 address.
Switched to wired connection to link-local. Now I receive inet address 169.254.6.146
According to Carter manual, the Segway should have ip address 192.168.0.40
Did a scan with avahi-browse -rt _workstation._tcp, which only showed nb-ros.local.
Did a scan with nmap -sP 169.254.6.0/24, which only finds one host. The scan nmap -sP 169.254.0.0/16 scans many hosts, but still only finds 169.254.6.146 (killled after 20m).
Connected the Air Live switch, but the wired connection is still 169.254.6.146. Connected the DNT Linksys and gave nb-ros 192.168.1.5. Still, the only machines in the domain where nb-ros and the gateway (DNT Linksys).
The ethernet address of the Segway can be found in RMP 220 manual.
The DNT Linksys uses normally in 192.168.1.* domain. Switched that to 192.168.0.*, but still only two hosts in this domain.
Conclusion, USB could only be used for sensors, which should be accessed via the tablet.
You can reach the video settings via sudo su and vi /boot/config.txt
Made a typo in the hdmi_timings, so pixels were scrambled for my OLED. Using those timings makes that my monitor is no longer usable.
Read the rasberry video documentation. The option hdmi_safe=1 seems one to try.
The option hdmi_safe, but gives a low resolution on only the monitor.
Tried instead hdmi_group=2, combined with hdmi_mode=82, which also should give a resolution of 1920x1080 (as the OLED). Only works for the monitor.
The settings specify an HDMI_ASPECT of 16:9, but pixel_freq is not 1920x1080x60, but 65.3 Hz. Should try what happens at 124416000
First trying hdmi_mode=85 and hdmi_mode=86.
With pixel_freq at 124416000 the OLED starts (although not perfect).
Put the pixel_freq back at 135580000, but put the frame_rate at 65. OLED works fine, still no monitor.
Looked for more information at spotpear, but that is the same information.
Connected to my XPS 13 9300. When duplicated, it worked both for 1920x1200 as 1920x1080. When extended, it only knew 1080x1920 (but at 59,994 Hz). Display was recognized as T779-108x1920.
Connected the display to my nb-ros, and this directly works. Checked video modes with xrandr -q, but only one video mode is given (1080x1920+1920+0) on 60Hz.
Also connected the monitor to nb-ros, the system both supports 1920x1080 and 1920x1080i at 60 and 50 Hz.
Started with source /opt/intel/openvino/bin/setupvars.sh.
Next I did cd ../../install_dependencies;./install_NCS_udev_rules.sh.
Next step is test the installation. Yet, the command ./demo_squeezenet_download_convert_run.sh -d MYRIAD gave the following error:
[ INFO ] Loading model to the device
E: [ncAPI] [ 482098] [classification_] ncDeviceOpen:1011 Failed to find booted device after boot
[ ERROR ] Can not init Myriad device: NC_ERROR
Error on or near line 217; exiting with status 1
I am not the only one with this problem. Looked in /etc/udev/rules.d/97-myriad-usbboot.rules, but ID 03e7:2485 is listed:
UBSYSTEM=="usb", ATTRS{idProduct}=="2485", ATTRS{idVendor}=="03e7", GROUP="users", MODE="0660", ENV{ID_MM_DEVICE_IGNORE}="1"
.
The device is also visible with lsusb:
Bus 001 Device 003: ID 03e7:2485 Intel Movidius MyriadX
Yet, the myriad rules specifies that the stick is readable for the GROUP users, so added myself to this group newgrp users, as suggested by Tudor. Now ./demo_squeezenet_download_convert_run.sh -d MYRIAD worked:
Top 10 results:
classid probability label
------- ----------- -----
817 0.6708984 sports car, sport car
479 0.1922607 car wheel
511 0.0936890 convertible
....
Unfortunatelly, no inference time is given. Script also works with -d CPU, but not with -d GPU:
[ INFO ] Creating Inference Engine
[ ERROR ] Failed to create plugin /opt/intel/openvino_2020.4.287/deployment_tools/inference_engine/lib/intel64/libclDNNPlugin.so for device GPU
Please, check your environment
[CLDNN ERROR]. No GPU device was found.
Did a check with dd /opt/intel/openvino_2020.4.287/deployment_tools/inference_engine/lib/intel64/libclDNNPlugin.so, but the following libraries were missing:
libinference_engine.so => not found
libinference_engine_lp_transformations.so => not found
libinference_engine_legacy.so => not found
libinference_engine_transformations.so => not found
libngraph.so => not found
Setting the environment variable export LD_LIBRARY_PATH=/opt/intel/openvino_2020.4.287/deployment_tools/inference_engine/lib/intel64/ solved this, except for libngraph.so.
Setting export LD_LIBRARY_PATH="/opt/intel/openvino_2020.4.287/deployment_tools/inference_engine/lib/intel64/;/opt/intel/openvino_2020.4.287/deployment_tools/ngraph/lib" solves the ldd-check, but still No GPU device was found..
Tried in ~/inference_engine_demos_build the command ./intel64/Release/security_barrier_camera_demo -d "MYRIAD" -i "/opt/intel/openvino/deployment_tools/demo/car_1.bmp" -m ~/openvino_models/ir/intel/vehicle-license-plate-detection-barrier-0106/FP16/vehicle-license-plate-detection-barrier-0106.xml which works, yet also here the option -d "GPU fails.
Think that has something to do with the CUDA version. The security_barrier_camera_demo is linked to /usr/local/cuda-10.1, but 9.2 and 10.2 are also available.
The script /opt/intel/openvino/bin/setupvars.sh should set LD_LIBRARY_PATH, but it doesn't.
Explictly set LD_LIBRARY_PATH with export LD_LIBRARY_PATH=$INSTALLDIR/deployment_tools/inference_engine/lib/intel64:$INSTALLDIR/deployment_tools/inference_engine/external/hddl/lib:$INSTALLDIR/deployment_tools/inference_engine/external/gna/lib:$INSTALLDIR/deployment_tools/inference_engine/external/mkltiny_lnx/lib:$INSTALLDIR/deployment_tools/inference_engine/external/tbb/lib:$INSTALLDIR/deployment_tools/ngraph/lib:$INSTALLDIR/opencv/lib, but this only works for -d "MYRIAD" and not for -d "GPU" (device not found).
Found some posts that only Intel GPU are considered (which actually is also present). Suggested was to install NEO access from Intel compute runtime with apt-get install intel-opencl-icd. Doesn't help. Tried Troubleshooting OpenCL on Linux.
The strace showed that /etc/OpenCL/vendors/nvidia.icd was read and /usr/lib/x86_64-linux-gnu/libnvidia-opencl.so.1 was opened.
Also /etc/OpenCL/vendors/intel.icd was read, just before Failed to create plugin. Tried to move each of the /etc/OpenCL/vendors files away, but still no success.
Added cuda-9.2 and /usr/local/cuda-10.2/lib64/ at the start of LD_LIBRARY_PATH, but still no device found.
Tried to install ncsdk on ubuntu 14.04, but this fails on dependency Cython>=0.23
July 25, 2020
Unpacking The Intel Neural Compute Stick 2. The site developer.movidius.com doesn't exist anymore, but found NCSDK documentation on github.
Just a simple make install fails, because Ubuntu 20.04 is not supported.
Adding the following two lines in ./install.sh helps:
f [ "${OS_DISTRO,,}" = "ubuntu" ] && [ ${OS_VERSION} = 2004 ]; then
[ "${VERBOSE}" = "yes" ] && echo "Installing on Ubuntu 20.04"
The script ./install.sh calls apt-get install -y requirement_apt.txt, which fails on python-pip (which is no longer available for 20.04). Used the get-pip.py trick of linuxize.
Still, the NCSDK needs tensorflow==1.11.0, is quite old.
Installed python3.7 by sudo add-apt-repository ppa:deadsnakes/ppa followed by sudo apt-get install python3.7. Still the only available tensorflow packages are >=2.2.
I am afraid that I have to install tensorflow from source.
Did a git clone https://github.com/tensorflow/tensorflow.git and git checkout r1.11, but for a ./configure I had to install bazel.
Next I have to choose my CUDA and cuDNN version. CUDA 9.2 is already installed, according to this download page cuDNN 7.6.5 is a good combination with CUDA 9.2.
I also said yes to TensorRT. Next I had to choose between TensorRT versions. V5 and v6 didn't had support for CUDA 9.2, so downloaded TensorRT v4 (for Ubuntu 16.04). Seems to work, but couldn't find library, so skipped TensorRT support.
Still, the configure now works, but bazel build //tensorflow/tools/pip_package:build_pip_package fails, because no cuda value is defined in any .rc file.
Changed branch. The branches are not called r1.11.0, but v1.11.0. Yet, with v1.11.0 --config=v1 fails on missing cuda definition, and in v2.2.0 bazel tries to run some python2 code.
Try tomorrow to get the OAK-D working, that seems to be more update than the NCSDK.
July 23, 2020
Although LatticeNet is designed for @Home, the low memory footprint seems also attractive for autonomous driving.
Toshiba announces camera based LiDAR prototype, which will come to market in 2020.
In the RobotTest.py from Adafruit-Motor-HAT you can change the address. Had also to modify Robot.py, because otherwise the default I2C could not be found (indicated same as jetbot code i2cbus=1: Adafruit_MotorHAT(addr, i2c_bus=1)). With address 0x60 the Remote I/O occurs again, with address 0x3C the PiOLED goes blank (spiked with white pixels).
Also the Object Following demo fails, because the ssd_mobile_v2_coco.engine is not present.
The collision avoidance data_collection couldn't initialize the camera.
Looked with ls /dev/video0, and device exists. Checked dmesg | grep -i video and dmesg | grep
-i camera.
Nice is the improvement table 1 of 2Detection champion. Multi-scale training gave 3% improvement, feeding the network with full-resolution images (1280x1920) gave the largest improvement (6%).
Checked M2 SSD slot of my XPS 8930 workstation, but that slot is used for the SSD, so no place for Aaeon AI core XM 2280.
July 20, 2020
As described in Computer Systems labbook, I was able to install the OpenVino toolkit as in the WSL app of Ubuntu 18.04.
Now the directory /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64 exists, which seems to be also usable for Ubuntu 20.04.
Should look if there the M2 slot is still available in my XPS 8930 for AI Core XM 2280 of 22x80mm.
Copied the openvino/deployment_tools from my 18.04 app to my 8930 workstation. Now source bin/setupvars.sh is succesfull.
The demo_squeezenet_download_convert_run.sh still tries to install several packages. The package libpng is no longer available for 18.04 or higher , so sudo add-apt-repository ppa:linuxuprising/libpng12 solves this. Later solved this by modifying this script nicer with:
if [ $system_ver = "18.04" ] || [ $system_ver = "20.04" ]; then
sudo -E apt-get install -y libpng-dev
The next demo demo_security_barrier_camera.sh calls the script ../model_optimizer/install_prerequisites/install_prequisites.sh caffe, which try to install libgfortran3 (instead of the modern libgfortran5). Solved this with line:
elif [[ $DISTRO == "ubuntu" ]] && [[ $system_ver == "20.04" ]]; then
sudo -E apt update
sudo -E apt -y install python3-pip python3-venv libgfortran5
python_binary=python3
Yet, this script uninstalls libpng-dev, and installs libpng12-dev instead. At the end it fails on a missing symbol in /usr/local/lib/libopencv_imgcodecs.so.3.2.
The script creates everytime a new demo in /inference_engine_demos_build/security_barrier_camera_demo. Added /usr/local/lib/libopencv_imgcodecs.so.3.2.0 at the end of the file CMakeFiles/security_barrier_camera_demo.dir/link.txt. Now make works.
The freshly made target can be called with the command ~/inference_engine_demos_build/intel64/Release/security_barrier_camera_demo -d "CPU" -d_va "CPU" -d_lpr "CPU" -i "/opt/intel/openvino/deployment_tools/demo/car_1.bmp" -m_lpr ~/openvino_models/ir/intel/license-plate-recognition-barrier-0001/FP16/license-plate-recognition-barrier-0001.xml -m ~/openvino_models/ir/intel/vehicle-license-plate-detection-barrier-0106/FP16/vehicle-license-plate-detection-barrier-0106.xml -m_va ~/openvino_models/ir/intel/vehicle-attributes-recognition-barrier-0039/FP16/vehicle-attributes-recognition-barrier-0039.xml
Also tried the same call with the other available target device "GNA". For Vehicle and Licence plate DetectionOutput layer is not supported by the GNAPlugin, for the Vehicle attributes the Softmax layer, and for the License plate the CTCGreedyDecoder.
The two extra models were optional, so ../intel64/Release/security_barrier_camera_demo -d "CPU" -i "/opt/intel/openvino/deployment_tools/demo/car_1.bmp" -m ~/openvino_models/ir/intel/vehicle-license-plate-detection-barrier-0106/FP16/vehicle-license-plate-detection-barrier-0106.xml also works, although the result is a bit different. Note that the only the brand of the car is anonymous!
July 19, 2020
Followed the instructions on DepthAI Python API, but python3 test.py fails on missing device.
Followed the instructions from Installing OpenVINO. Ubuntu 20.04 is not supported (yet), but the default option of the install script is to ignore this.
The dependencies are quite extensive. The install_dependencies fails on a few packages. Installed the dependencies listed in the script manually, had to replace a few packages with newer version (i.e. python3.8 instead of python3.6).
Yet, the script
The toolkit is installed in /opt/intel/openvino_2020.4.287/, the latest version can be accessed via /opt/intel/openvino.
Unfortunatelly, the script opt/intel/openvino/bin/setupvars.sh doesn't work, because there is no directory deployment_tools/inference_engine/lib/. There the distribution depend parts should be present, which will become availabe via the environment variable IE_RELEASE_LIBRARY. Without this environment variable sudo ./build_demos.sh in opt/intel/openvino/deployment_tools/inference_engine/demos doesn't work.
Looked at the install package, but everything is in rpm packages for bionic and xenial, so not for Ubuntu 20.04 (focal or 14.04 (trusty). Should install it on my Rasberry Pi.
July 16, 2020
Thomas Wiggers found the repository of the Waymo 3D Detection challenge winner, including two papers to describe their approach. Read PV-RCNN paper. PV-RCNN takes advantages from both the voxel-based feature
learning (i.e., 3D sparse convolution) and PointNet-based
feature learning (i.e., set abstraction operation) to enable
both high-quality 3D proposal generation and flexible receptive fields for improving the 3D detection performance.
The trick is to use keypoints as intermediate step. Note that this method is purely LiDAR based.
The OAK-D is now available on KickStarter. Subscription is possible until August 13.
The AI-part is based on the Intel Myriad X. Depth AI sells several camera's, including Raspberry PI versions and the predecessor of the OpenCV module that will be shipped only in December. That camera is 299$ and directly available.
The Myriad X is running Models from OpenVINO Zoo. In the Zoo you can find for instance a model pretrained on person-vehicle-bike detection.
The Intel Myriad X is the same chip that is the basis of the Intel Neural Compute Stick.
On the Spatial AI competition Brandon Gilles gives a detailed answer on what we can expect from the object location in 3D space. The OAK-D can operate in two modes: as Monocular object detection fused with stereo disparity depth and as fully Stereo AI. For the Monocular Depth the minimum depth is 70cm, which will be reduced to 35cm in December. In Stereo mode the minimal distance is currenlty 20cm. For both methods the theoretical limit is 33m, although 10 to 20m will be a more realistic limit.
The tutorial how to convert a model which is not in the OpenVINO Model Zoo onto your OAK.
In the tutorial the conversion is done in a Notebook, this section shows how you can use Intel Movidius tools.
July 14, 2020
Google also build their own version of DuckieTown: PixeloPolis.
Installed the RealSense D435 on a Jetson Nano. Was an issue of simple following the instructions (for Ubuntu 18.04). Tested it with realsense-viewer:
July 9, 2020
In the Google App store there is another ROS control app, based on this project, which is now maintained at github repository. This app seems also RosJava based.
Watched this Video of Loomo Development. It selects an Basic Activity as New project, and adds only implementation 'com.segway.robot:basesdk:0.6.746' as dependency (see Development Environment setup).
To use the fisheye camera, I should first send an email to be authorized.
That is a pity, because FisheyeSample is one of the Latest Segway Samples.
There is also a Loomo Academy version (5000 euro). Yet, that only gives the Extension Bay and 30 licenses to the software. In the video, they use the Extension Board only for an USB lamp.
I could try to install Google Play from APK mirror.
The LoomoGuy (from Segway) also explains how to have a adb connect IP, to develop apps wirelessly.
Followed the LoomoGuy instructions, and installed choco with command Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1')) in PowerShell with admin rights.
After that you can install choco with coco install adb and I could check the connection with the Loomo with adb devices:
Succesfully installed the Firefox browser. I also tried to install Google Play Store, which didn't work. Also installed Google Play services, but also those services crashed. Maybe because it were different version (Play Store v20.9, services v20.24).
The USB-2 from the Extension Bay is not visible as ADB device, so it doesn't have a direct connection to the Android tablet.
According to carter hardware guide, the RMP registers itselfs with an IP adress, so I could try to use a USB-Ethernet connecter on this port. According to Extension Bay documentation, the USB device chipset supports USB-ethernet (and uvcvideo, usb-audio, etc).
Look at Android Loomo ROS Core. In principal this ROS Core is made for ROS Kinetic, on Ubuntu 14.04 I should use ROS Indigo of Jade. On my Linux notebook I have installed Hydro and Indigo.
According to my labbook, my Linux for Windows on my workstation has still Xenial (16.04).
Yet, although EOL, the command sudo apt-get install ros-indigo-rosjava-build-tools ros-indigo-genjava still works.
The documentation of ROS Android Studio is not available for Indigo, but I see nothing specific for Kinetic. Did sudo apt-get install openjdk-8-jdk. Note that the update for librealsense2-gl is kept back.
Downloading the 866Mb of Android Studio (v4.0 (build 193.6514223)).
Running the script /opt/android-studio/bin/studio.sh, which going to download again all SDK elements (like the Android emulator).
The studio downloaded by default the latest packages (Android 10.0+ API 30 (R)), so also download Android 9.9 PAIAPI 28 (Pi), as suggested in Ros documentation.
The default SDK location was /root/Android/Sdk, so I moved that to /opt/android-sdk and updated that in the Android Studio configuration.
Added that location to my PATH with echo export PATH=\${PATH}:/opt/android-sdk/tools:/opt/android-sdk/platform-tools:/opt/android-studio/bin >> ~/.bashrc and echo export ANDROID_HOME=/opt/android-sdk >> ~/.bashrc
Cloned the rosjava_core repository with https://github.com/rosjava/rosjava_core.git. Switched between the branches with git checkout indigo and git checkout kinetic.
The command bazel build //... fails in the indigo-branch because there is no WORKSPACE. But the same command fails also for the kinetic (on a incompatible depset).
The indigo-branch has a CMakeLists.txt, so creating a build directory and doing there cmake .. creates the Makefiles (after installing the missing package with sudo apt-get install ros-indigo-rosjava-test-msgs.
Did first make, followed by sudo make install. The command install everything in /usr/local, which is fine for /usr/local/share/rosjava_core and /usr/local/share/maven/org/ros/rosjava_core, but modifying /usr/local/env.sh and /usr/local/setup.sh seems a bit overdone.
The next instruction (step 3) is outdated, but git clone https://github.com/mit-acl/android_loomo_ros_core.git ~/segway_ws/src is a good replacement.
The command catkin_make tries to install Android SDK build tools in /opt/android-sdk, so made that directory also writeable with sudo chmod o+w -R /opt/android-sdk (would have less a security problem if the android-sdk was locally installed).
The catkin_make calls make -j4 -l4, which fail on missing android_10:releaseCompileClasspath.
Edited segway_ws/src/build.graddle and added to allprojects:
repositories {
google()
}
Now the build is succesfull.
When connected with the Loomo head, I was able to push the green play button. Saw not really something happening, so not clear which directory installed the app.
After the installation I switched the Loomo to developer mode, and the Loomo Ros app appeared. The app shows the node it tries to connect to, and dies when the publishing switches are (automatically) activated.
Could be that this is due to no ros-core running on the laptop, it could be the non-synchronized time-server (step 0 - very important), it could be that the Loomo was still connected to the internet.
Looked intor the time-server. First hint was to synchronize time before starting the servers, so looked at the steps explained in this blog.
Installed the time-server with sudo apt-get install ntp, and checked the used servers with ntpq -p.
The Loomo Ros core app was based on the tutorial published by Segway robotics.
They suggest as optimal configuration to use a USB-C to ethernet for the Loomo, connect that to a wired to wireless router, connect a Jetson to the same router and connect your PC via WIFI to this router.
July 6, 2020
Finished the assembly of the SeeedStudio Jetbot Smart Cart Kit. Yet, I had difficulties with both the camera, PioLED display and the motordrive.
Reconnected the camera with the blue markings on both side to the outside, now I see a device when I do ls /dev/video0, as suggested in this post.
Could even start even start a G-stream with the command gst-launch-1.0 nvarguscamerasrc ! 'video/x-raw(memory:NVMM),width=3820, height=2464, framerate=21/1, format=NV12' ! nvvidconv flip-method=0 ! 'video/x-raw,width=960, height=616' ! nvvidconv ! nvegltransform ! nveglglessink -e.
July 3, 2020
Pre-ordered Qualcomm Robotics RB5 Platform, including the vision kit. Seems like a good choice to mount on the Segway Loomo.
The Loomo Extension Bay has arrived!
Finally I have JetBot SD card image downloaded and I could burn it on a SD stick. The verirfication of Etcher halted at 76%, but the card boots fine.
Also the Jupyter Lab launcher and terminal works fine, I could install the latest JetBot repository:
After Step 6 (configure power mode) I also updated the Ubuntu software. Updated 384 packages such as binutils, docker.io python2.7 python 3.6. Also highly relevant seems nvidia-l4t-jetson-io. At the 6 packages were hold back: fwupd fwupdate fwupdate-signed libgl1-mesa-dri mesa-va-drivers
mesa-vdpau-drivers.
July 2, 2020
Created an highway version of DuckieTown:
Followed the instructions of assembling the SeeedStudio Jetbot Smart Car Kit, until the step where they mounted the Nvidia Jetson.
Continued with the Software instructions. Yet, the internet was not stable enough in the robolab to download the image.
Continued with assembling Silicon Highway Jetbot. The second step requires a soldering iron.
June 30, 2020
Received the RealSense LiDAR camera L515. The getting-started points to the linux distributions, but Ubuntu 20.4 (focal) is not (yet supported), so I had to put some effort to get it working on my native Linux workstation.
Yet, the source suggest to build the library from Microsoft's vcpkg. This repository is a bit newer (14 hours), instead of 3 days. Also it contains another set of directories.
This downloads an https://github.com/IntelRealSense/librealsense/archive, so this is only a way to install. Yet, the installation failed. This installation only applied the fix_openni2.patch and fix-dependency-glfw3.patch, before it started Configuring x64-linux-dbg and x64-linux-dbg.
Checked in the mean time Build from source instructions. The ./scripts/patch-realsense-ubuntu-lts.sh should also work for Ubuntu 20.04.\
Started with udo apt-get install git libssl-dev libusb-1.0-0-dev pkg-config libgtk-3-dev.
Next sudo apt-get install libglfw3-dev libgl1-mesa-dev libglu1-mesa-dev.
The command ./scripts/setup_udev_rules.sh was also succesfull.
Step 4 is /scripts/patch-realsense-ubuntu-lts.sh. The script succesfully installs an updated kernel, but fails on the end with:
Package required libusb-1.0-0-dev: - found
Package required libssl-dev: - found
Unsupported distribution focal kernel version 5.4.0-37-generic . The patches are maintained for Ubuntu16/18 (Xenial/Bionic) with LTS kernels 4-[4,8,10,13,15,18]
Boldly continue with mkdir build && cd build followed by make ../ -DBUILD_EXAMPLES=true.
Started build with make, followed by sudo make install.
Testing the installation with realsense-viewer. Directly started with an firmware update. After the firmware update I activated the Depth, RGB and Motion module. Seems all to work.
Tried to do the same on nb-ros. This is an Ubuntu 14.04 machine. I could not add the trusty repository to list of servers, but sudo apt-get install librealsense2-dkms was not needed from an earlier install (for the realsense D435). Yet, sudo apt-get install librealsense2-utils fails on a missing dependency on librealsense2-gl, which depends on libglfw3.
This is a known issue, because github provides the script ./scripts/install_glfw3.sh. This downloads the source of glfw3 in /tmp and compiles it, although it needs cmake>=3.0 for it.
That can be solved with adding another repository with sudo add-apt-repository ppa:george-edison55/cmake-3.x.
Now the script ./scripts/install_glw3.sh works, only apt-get is not aware of it.
This can be solved (nerd-points) with sudo apt-get install librealsense2, followed by sudo apt-get download librealsense2-gl, followed by dpkg --ignore-depends=libglfw3 librealsense2-gl_*.deb.
After this installation you should remove the libglfw3 dependency by editing the entry of librealsense-gl with sudo vi /var/lib/dpkg/status and an optional apt-get -f install.
Now sudo apt-get install librealsense2-utils works.
Tested realsense-viewer, but received the complaint that two udev rules for the same device existed.
Viewing the point-cloud in the 3D window gave the error that the Z16 image format was not supported:
An hot switch of the L515 for the D435 gave an hard crash of the realsense-viewer (even no core-dump after I forced the window down). Had to kill the terminal and reboot.
Removed the entry /lib/udev/rules.d/60-librealsense2-udev rule, because that rule was also not present on my workstation.
In the mean time I connected the D435 to my Ubuntu 20.04 workstation. The camera requested a firmware update (which a forum post said that this could solve the Z16 problem - which wasn't the case). The D435 camera firmware was updated from 05.10.6 to 5.12.5.
The Z16 pixel format is propriate from Intel, which was earlier provided by the package realsense-uvcvideo. Yet, this package is not available anymore.
The last challenge not only included a simulation, but also a 18th scale 4WD monster truck. Signed in to be notified when the next generation is launched (2020 season). The AWS DeepRacer Evo comes with dual stereo cameras, allowing the car to detect objects on the track, and LIDAR.
From TNO, now also the engineers Mauro Comi (Reinforcement Learning, intention prediction.), Ron Snijders (Carla - OpenScenario), Willek van Vught (Knowledge graphs, Grakn).
Thomas O augmented the Carla @ AWS instructions including the commands to create the ssh-tunnel and to start the simulation. The instructions can be found here
At my account, I selected the EC2 compute service.
In the EC2 dashboard you see one running instance. The connect button shows the ssh command you should use.
Made a ssh-connection with the provided "carla.pem".
This environment has the following configurations:
=============================================================================
__| __|_ )
_| ( / Deep Learning AMI (Ubuntu 18.04) Version 29.0
___|\___|___|
=============================================================================
Welcome to Ubuntu 18.04.4 LTS (GNU/Linux 5.3.0-1019-aws x86_64v)
Please use one of the following commands to start the required environment with the framework of your choice:
for MXNet(+Keras2) with Python3 (CUDA 10.1 and Intel MKL-DNN) ____________________________________ source activate mxnet_p36
for MXNet(+Keras2) with Python2 (CUDA 10.1 and Intel MKL-DNN) ____________________________________ source activate mxnet_p27
for MXNet(+AWS Neuron) with Python3 ___________________________________________________ source activate aws_neuron_mxnet_p36
for TensorFlow(+Keras2) with Python3 (CUDA 10.0 and Intel MKL-DNN) __________________________ source activate tensorflow_p36
for TensorFlow(+Keras2) with Python2 (CUDA 10.0 and Intel MKL-DNN) __________________________ source activate tensorflow_p27
for Tensorflow(+AWS Neuron) with Python3 _________________________________________ source activate aws_neuron_tensorflow_p36
for TensorFlow 2(+Keras2) with Python3 (CUDA 10.1 and Intel MKL-DNN) _______________________ source activate tensorflow2_p36
for TensorFlow 2(+Keras2) with Python2 (CUDA 10.1 and Intel MKL-DNN) _______________________ source activate tensorflow2_p27
for PyTorch 1.4 with Python3 (CUDA 10.1 and Intel MKL) _________________________________________ source activate pytorch_p36
for PyTorch 1.4 with Python2 (CUDA 10.1 and Intel MKL) _________________________________________ source activate pytorch_p27
for PyTorch 1.5 with Python3 (CUDA 10.1 and Intel MKL) __________________________________ source activate pytorch_latest_p36
for PyTorch (+AWS Neuron) with Python3 ______________________________________________ source activate aws_neuron_pytorch_p36
for Chainer with Python2 (CUDA 10.0 and Intel iDeep) ___________________________________________ source activate chainer_p27
for Chainer with Python3 (CUDA 10.0 and Intel iDeep) ___________________________________________ source activate chainer_p36
for base Python2 (CUDA 10.0) _______________________________________________________________________ source activate python2
for base Python3 (CUDA 10.0) _______________________________________________________________________ source activate python3
In one terminal, I started ./CarlaUE4.sh from /opt/carla-simulator/bin
In another terminal, I started python3 spawn_npc.py from /opt/carla-simulator/PythonAPI/examples (after source activate carla). The result is:
14x ERROR: Spawn failed because of collision at spawn position
spawned 10 vehicles and 36 walkers, press Ctrl+C to exit.
Yet, after a few minutes I receive: done.
Traceback (most recent call last):
File "spawn_npc.py", line 249, in main
world.wait_for_tick()
RuntimeError: time-out of 10000ms while waiting for the simulator, make sure the simulator is ready and connected to 127.0.0.1:2000
In the other terminal I had crash:
4.24.3-0+++UE4+Release-4.24 518 0
Disabling core dumps.
Failed to find symbol file, expected location:
"/opt/carla-simulator/CarlaUE4/Binaries/Linux/CarlaUE4-Linux-Shipping.sym"
LowLevelFatalError [File:Unknown] [Line: 102]
Exception thrown: bind: Address already in use
Signal 11 caught.
Malloc Size=65538 LargeMemoryPoolOffset=65554
CommonUnixCrashHandler: Signal=11
Malloc Size=65535 LargeMemoryPoolOffset=131119
Malloc Size=123824 LargeMemoryPoolOffset=254960
Engine crash handling finished; re-raising signal 11 for the default handler. Good bye.
Segmentation fault (core dumped)
Seems that also somebody else was working at the same time. When I logged in I was the only user, but with ps x -u ubuntu | grep sshd I see 10 instances. Restarted both Carla and npc-script. That worked. After lunch the sessions were broken, so I gave the instance the reboot that was requested.
After the reboot, I stopped the instance. Directly afterwards it was running again, so it looks like somebody else was using the same machine.
The instance that we have, is a g4dn.2xlarge. At Advanced Computing page the performance of this G4 instance is given: 1 Xeon processor with 16 vCPUs and 1 Nvidia T4 Tensor Core GPU.
June 9, 2020
Could invest the posibilities to cooperate with 3DUU lab in Delft.
June 4, 2020
Quite shocked that the Tesla 3 in Taiwan not only failed to notice the overturned truck, but also didn't slow down for the driver of the truck warning the traffic 100m in front of the truck. See this report.
June 2, 2020
My student's MaskRCNN101 solution reached position 27 of 30 serious submissions.
Pure Yolo v3 (the focus of Thomas W) had the lowest score, but that was probably a submission issue with getting the bounding boxes in the right format.
Yolo v3 makes already use of Feature Pyramid Networks, detection on three scales. In addition, Yolo v4 adds a path-aggregation to the architecture (the feature fusion neck).
Also Mask RCNN (the focus of Thomas O) could be found in top 10 rankings. Yet, although the backbone and framework is often given, it is less clear what tricks were actually essential for a high ranking.
In most cases frameworks were used (i.e. mmdetection, SimpleDet) which have many posibilities for finetuning.
The winners combined five models (HRNet, ResNetv1b, ResNetv1d, ResNeXt and Res2Net), used a multi-stage cascade, combined classification and localization with the DoubleHead method and Feature Pyramid Networks.
On the 2nd place in the leaderboard is Yusuke Shinya, which also used mmdetection as backbone. The code is available on github, and combines RetinaNet with ResNet50.
Trying to install https://mmdetection.readthedocs.io/en/latest/install.html#requirementsmmdetection on Jetson Nano.
This requires conda, which is not directly available. Used conda4aarch64 script, which installs several executables in a directory of chosing. I specified /tmp/c4aarch64_installer and added /tmp/c4aarch64_installer/bin to my PATH.
Now I could do conda create -n open-mmlab python=3.7 -y. Yet, because PyTorch is only available for Python3.6, I also made conda create -n mmdetection python=3.6 -y
In this conda environment, I continue with pip install torch-1.5.0-cp36-cp36m-linux_aarch64.whl. Hope this goes well, I should have used pip3 install.
Cancelled and follow the instructions to the letter. Receive numpy-1.18.4 and future-0.18.2.
Made torchvision from source, as suggested in the instructions. import torchvision works.
Tried to run conda from another terminal, but conda didn't like the modified path. In the conda environment, I did conda install conda.
Continued with python3 setup.py install without sudo, because that is outside the conda envrinment. Solving that outside the conda environment, although I had to use sudo -H pip install because the site-packages were not writeable.
Continued with mmdetection. The command pip install -r requirements/build.txt was already met, the command pip install "git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI" failed on matplotlib. The trick is to install sudo apt install libfreetype6-dev.
The command pip install -v -e . failed on missing opencv-python, which I tried to solve with apt-get install python3-opencv. Yet, this failed.
Followed the instructions from this post. Instead of downloading the zip, I did git clone --branch 4.2.0 https://github.com/opencv/opencv.git. The opencv_contrib-4.2.0.zip I downloaded, because I expected that they would be extracted in the same directory. Instead, the directory is specified in the CMAKE command.
Building failed on 97%, without a clear error message on the NVCC (Device) object modules. Tried if sudo make install still worked, or that an essential part was missing. That succeeds.
Also the pip install -v -e . in ~/git/mmdetection succeeds!
May 28, 2020
Read IEEE Spectrum article on autonomous vehicles with less intensive use of resources and sensors.
May 20, 2020
Under Linux, I was able to flash the SDHC card (under Windows the disk was empty).
Followed these instructions to install tensorflow, although with numpy=1.18.0.
Nearly there with waymo quick start, yet the configure fails on missing tf.__version__. That can be solved by setting EXPORT TF_VERSION=2.1.0 explictly before calling ./configure.sh.
Everything worked, until running the test which failed on missing symbol. Trick was copy the setting for TF_VERSION==14.0.0 to above this version.
Running the three python utilities at the same time gave an time out. The number of jobs can be configured in .bazelrc, according to this post (or the parameter --jobs 4.
The steps of the metrics computation went without problems, although I had to find a binary of bazel on aarch64. The binary is the bazel_real in /usr/local/lib/bazel/bin, the other are scripts that I copied from a linux distriution.
The installation of tensorflow from the jetpack 4.4 failed on the pre-installed numpy version (1.16 instead of 1.18). After manually updating the numpy version the whl worked. Yet, the ./configure.sh still couldn't find it, because both python3 and pip3 are provided by archiconda3, which had put itself in front of the path (and couldn't be removed with modifying the ./bashrc.
With /usr/bin/puthon3import tensorflow succeeds, but complains on missing tensorrt libraries (v6 are available, but v7 is needed). Those libraries are only available for aarch64 on the jetpack image, so I have to flash a new disk tomorrow.
May 16, 2020
Updating the Segway to v3.9.15.
May 14, 2020
Thomas is making great progress on the Waymo challenge. Looking into the requirements of a submission. In this form we should fill in the following information:
Unique method name in 25 characters.
Method paper link
Sensor_type and object_type are challenge dependent (there are five challenges).
Not clear what they intent with latency_second and frames_excluded.
Past frames seems only important for the tracking challenges.
The procedure of submission is described in quick start. Three submissions per month are allowed agains the test-set (but as many as we want on the validation set).
Current leader has based his submission on mmdetection, the champion of the COCO Detection Challenge in 2018. This method can be combined with several methods and backbones, the leader Danil Akhemetov combined Cascade RCNN Resnet 50 with HRNet. Yet, many other combinations are possible (21 methods x 3 backbones + 1).
This paper describes a detection pipeline has typically the following components:
Backbone
Neck
DenseHead
RoIExtractor
RoIHead
The last component makes the task-specific predictions of the bounding boxes needed in the 2D detection challenge.
Two heads can be combined to create a two-stage detector!
Although slower, Cascade Mask R-CNN and Hybrid Task Cascade showed better predictions than pure Cascade R-CNN.
The runner up is using RetinaNet.
Number three combines (baseline of Waymo employee) uses Faster RCNN Resnet 101
Followed the quick start installation instructions to evaluation part. All prerequisites where already there, except TensorFlow. Seems that this can be installed later with pip3 install numpy tensorflow.
With the command bazel test waymo_open_dataset/metrics:all the real download starts. Bazel finds 18 targets and 44 packages to fetch (including 28Gb of JDK).
The source code has 394 packages as requirements, including carla.
They have a lot of equipment to connect your controller to real car (via (via a 4th generation CAN bus to connect to the OBD-II port).
The computation of the metric seems to work, although all values are 0:
RANGE_TYPE_CYCLIST_[0, 30)_LEVEL_1: [mAP 0] [mAPH 0]
RANGE_TYPE_CYCLIST_[0, 30)_LEVEL_2: [mAP 0] [mAPH 0]
RANGE_TYPE_CYCLIST_[30, 50)_LEVEL_1: [mAP 0] [mAPH 0]
RANGE_TYPE_CYCLIST_[30, 50)_LEVEL_2: [mAP 0] [mAPH 0]
RANGE_TYPE_CYCLIST_[50, +inf)_LEVEL_1: [mAP 0] [mAPH 0]
RANGE_TYPE_CYCLIST_[50, +inf)_LEVEL_2: [mAP 0] [mAPH 0]
Continue with pip3 install numpy tensorflow, luckely numpy=1.18.4 and tensorflow=1.14.0 are installed.
p3 install numpy tensorflow
With the command bazel test waymo_open_dataset/metrics:all the real download starts. Bazel finds 18 targets and 44 packages to fetch (including 28Gb of JDK).
Yet, configure still says that TensorFlow is not installed. Checking the steps in this post. No nvidia-smi, so the native gpu-drivers seems not to be installed. The command sudo apt update; apt upgrade updates 66 packages (mainly python3-6 related). The good thing is that the nvidia-settings are updated.
The command sudo ubuntu-drivers autoinstall didn't work, so checked the latest version at graphics-drivers repository and installed sudo apt install nvidia-drivers-430.
Everything is installed, but nvidia-smi fails. Also lsmod fails:
lsmod | grep nvidia
libkmod: ERROR ../libkmod/libkmod-module.c:1657 kmod_module_new_from_loaded: could not open /proc/modules
According to askubuntu, this is to be expected from WSL. Could check for the new Ubuntu App, seems that the new version of WSL has even more close Linux experience.
According to faq even WSL2 doesn't support GPU's yet.
As expected, the bazel build in the TensorFlow option fails on @local_config_tf//:libtensorflow_framework.
In the Python bazel test the build works, but the 3 test fails.
Tried to connect to the watchtower. The command ping watchtower01.local didn't work.
Did an ip-scan with nmap -sP 192.168.178.0/24. Seven computers connected to this wlan, but none of them watchtower.
Did on watchtower sudo ifconfig. The wlan only provided a ip6 address.
Used the trick of raspberrypi forum and created /etc/sysctl.d/local.conf with net.ipv6.conf.all.disable_ipv6=1. After reboot I have ip 192.168.178.46.
Followed the steps of duckietown software developement. There are 9 containers running and several stopped. Tried step 2.3, but the File Server was already running on port 8082. Tried step 2.4, but docker couldn't find the rpi-docker-python-picamera container. Also a pull of this container fails on requires 'docker login'.
Strange, the code of this container can be found on github.
With docker image ls I saw that I had image duckietown/rpi-python-picamera, so I was able to run docker -H 192.168.178.46 run -d --name picam --privileged -v /data:/data -p 8081:8081 duckietown/rpi-python-picamera:master18
Looking at the portainer.io list. There are actually two containers, a picam and ros-picam. Both were stopped, but when started I see in the logs the error picamera.exc.PiCameraMMALError: Failed to enable connection: Out of resources. In portainer.io is also the port visible (8081), yet on another ip 172.17.0.2.
Tried to stop other containers which also could use the camera, but I stopped one container too much because my portainer.io interface is now empty.
Even docker image ls showed nothing, so I did sudo reboot now.
Only 5 containers are running after the reboot, only from the health-stack. Still out of resources. There is an /data/image.jpg from 15:30 today! Yet, it is zero byte file!
Tried raspistill -o May12.jpg, but received Camera control callback: No data received from sensor.
According to the forums, I should reconnect the sunny connections, try another camera, try another board ....
May 3, 2020
Following the steps from Duckiebot Development using Docker (Unit E-2, 2.4 and 2.5). The picamera container was already running (started from the raspberry).
nvidia-docker was not known, so I tried the command: docker run -it --rm \
--name ros \
--net host \
--env ROS_HOSTNAME=$HOSTNAME \
--env ROS_MASTER_URI=http://DUCKIEBOT_IP:11311 \
--env ROS_IP=LAPTOP_IP \
--env="DISPLAY" \
--env="QT_X11_NO_MITSHM=1" \
--volume="/tmp/.X11-unix:/tmp/.X11-unix:rw"\
rosindustrial/ros-robot-nvidia:kinetic
which seems to work, but fails at the end on /ros_entrypoint.sh: permission denied..
Switched to the running picam container with command docker exec -it ros-picam. The command roswtf gives the info that no ROS master seems to be running.
In the /home/software directory of the picam-container several scripts are available, including set_ros_master.sh.
The command roscd duckietown works, and there is the camera.launch
The 2*.sh scripts are for the lab of ethz.ch
Sourced both /opt/ros/kinetic/setup.bash and catkin_ws/devel/setup.bash. Still no master ros running. The command roswtf came this time further, but failed on missing /rosout/get_loggers service.
Tried the script what_the_duck, which is running 688 test. The camera test fails, but that is because I am in the picam container as root. Next time I should add --user="mom" to the docker exec command.
The script ./run_pi_camera.sh starts now the nodes, but dies because it is out of resources (other container still running).
May 2, 2020
Assembled the traffic-light, as indicated at manual.
The LEDs startup white, as indicated. Tried to run docker run -dit --priviliged --name trafficlight duckietown-lights. Results are blinking red, green and oranges, except for one LED (although it was white during startup). No control as far as I can see.
Looking for the instructions of the Watchtower setup Step 15 of the WT19-B version explains the camera setup. Step 26 explains the camera mounting. Model WT19-A is without cooling-fan (but still with Rasberry Pi 4 B+, instead of mine Pi 3 B+). Version WT8 has a Pi 3 B+, but another wooden enclossure.
An intersection demo which uses the traffic-light can be found in Part D- demos.
Details of the student project with code can be found on github.
Looked at scripts, but the students also start with docker -it IMAGE_NAME /bin/bash. For the IMAGE_NAME dt18_03_roscore_duckiebot-interface_1 this works, for dt18_00_basic_watchtower_1 the exec fails because the file /bin/bash is unknown. Yet, doing a simple rostopic list fails for the roscore.
Executing duckietown/rpi-duckiebot-ros-picam:master18, which works (master19 was not found).
Yet, Unit D-5 describes the navigation over a free intersection: Unit D-7 indicates what happens with traffic signs and traffic lights. The Robotarium documentation of the traffic lights is rudimentary (start blinking). The documentation of the 2017 project can be found here.
All demos provided can be found here, including traffic light coordination. Here is the code for the duckiebot at the intersection. This relies on both the April tag and signal detector. The signal detector seems to be based on led detector, which runs the same detector with two parameters, one for the leds on the other cars and one for traffic lights. The only difference is the expected Area of the light.
Mounted the overview camera on top of the pole. Used stick to guide the camera wire through the pipe.
The additional equipment in Watchtower WT19-B is not a start-stop button, but a RGB-sensor (TC534725).
Tried to test the camera. Followed the steps at raspberry documentation. Even enabled the camera with sudo raspi-config added the user to the group of device /dev/vchiq with sudo usermod -a -G video mom. Tried a reboot, but still the camera-led is off abter rebooting, and switches on when I give the command raspistill -o cam.jpg and still get the failed component bug. Looked at the suggestions at raspberry forum. I tried vcgencmd get_camera but get supported=1 detected=1.
Did a sudo full-update. Still no effect. Tried the trick suggested in this post and added w1-gpiol; w1-therm as first /etc/modules. Didn't had to blacklist i2c-bm2708, I got my first testshot!
The Groove Start package is including a button. Is probably needed for Groove Doppler radar, which connects with a Groove cable. Kit contains GrovePi board. Seed also sells GPIO extension cables (to mount the Sense Hat on top of the DuckieBot.
Started the docker image with docker run -it --name ros-picam --network=host --device /dev/vchiq -v /data:/data duckietown/rpi-duckiebot-ros-picam:master1. I don't get a shell, but all services start, including "Published the first image".
The last two datasets are associated with two challenges, which both end this month. Waymo's challenge is associated with CVPR 2020, Nuscenes challenge with ICRA 2020. Both challenges are clear on their evalution metrices:
Looked at Lesson 8.5, Search from prior. They used the variables left_fit and right_fit as global variables to communicate between the functions (and the previous iteration).
Activated the environment with conda activate carnd-term1 followed by a jupyter notebook. The kernel crashes, but that seems to be due to cv2.imshow('img', img), with plt.imshow(img) the code works (but doesn't wait on cv2.waitKey(500)).
Copied the camera_calibration.py solution to examples, and modified the code. Created the calibration values to ../camera_cal/wide_dist_pickle.p. Don't see much of a difference for the distorted and undistorted image. Yet, the matrix mtx has non-zero diagonal elements, so I guess it works.
Next steps:
Use color transforms, gradients, etc., to create a thresholded binary image.
Apply a perspective transform to rectify binary image ("birds-eye view").
Detect lane pixels and fit to find the lane boundary.
Determine the curvature of the lane and vehicle position with respect to center.
Warp the detected lane boundaries back onto the original image.
Output visual display of the lane boundaries and numerical estimation of lane curvature and vehicle position.
April 25, 2020
Mounted the SenseHat and tried to perform Hello World on the LEDs.
SenseHat library loads fine (after installing it yesterday), but programs fails on permission denied on /dev/input/event3. As suggested in this post, I added mom to the input group, but that doesn't help. Program works fine when executed with sudo. Rebooting helps, I have my "Hello world" running over the LEDs.
Continued with Sensing the environment. Received a message # Ensure pressure sensor is initialised. Found the solution in this issue and changed the group of i2c-dev module with sudo chgrp input /dev/i2c-1 (was part of the root group). First time the pressure gave value 0, but after calling the temperature (33.5 degrees!) I measured a pressure of 1021.04 millibars and humidity of 29.5%.
Strange enough that didn't work for my workstation (only 3 hosts up), but worked fine for my nb-dual. Could do ssh duckie@192.168.175.45 (using the wired lan for my duckiebot).
The command sudo ifconfig showed that the wired ip has an ip4 address, but the wlan0 only received an ether address (b8:27:eb:00:61:70). Couldn't ping to that address.
Received some errors on dts challenges info, but this seems to the certificate error of the website challenges.duckietown.org (certificate expired this morning).
Could ping donald.local.
Could start the command dts duckiebot demo --demo__name joystick --duckiebot_name donald, but no response on the joystick. Could dts duckiebot keyboard_control donald, see the arrows light up, but no response. Motors not wired up correctly? The duckieboard shows a red light, with sometimes a green blimp.
Tried mission control, had the choice between calibration and default. I could take over. No response on run-test for calibration. Switched to default. Could use the arrow keys to request forward and backward speed, but I see no response from the robot.
Luckely my USB-jumper cable arrived. Tested it on the broken duckieboard, both leds become green. The Raspberry Pi 3B+ didn't boot, but that was because it had no SD-card.
Created a SD-card for the trafficlights, as explained in manual. Had to specify the type of robot. According to help I had the choice between watchtower and duckiebot, so I used that option (and used the watchtower setup instead of the trafficlight setup). In the watchtower setup images for master18 and master19 are downloaded (mixed).
With the watchtower image loaded the Raspberry Pi boots without problems.
The command sudo ifconfig shows that I am connected both wired and wirelessly.
Made a typo in my wireless AP on the duckiebot SD. Repaired the typo and rebooted. That seems to work, 192.168.178.48 is my wireless address.
First received some time-outs, but connected the watchtower with the wire, and was able to do sudo docker pull duckietown/traffic-lights:master19
Looking how I can test the traffic-light software / duckieboard.
According to DT18 manual, I should have chosen the duckiebot type when creating the SD-card.
Launching could be done by a git-checkout and make.
Although I already downloaded the docker image already with docker pull duckie/traffic-lights, and the image was visible with docker image ls, the call docker run duckietown/traffic-lights downloads the image again. Maybe the latest version is different from the master19 version.
The docker image starts, does a roslaunch traffic_light traffic_light.launch veh:=ff479a4f3d9 it only crashes because no RGB_LED instance can be found (which is right, those where not connected yet).
No idea to stop this run. Next time I should run it with option -i and -t
The Raspberry Sense Hat can be stacked above a Duckiebot v1.1.
The Sense Hat comes with spacers, which could also be usefull for the Duckieboard (board is not complety parallel when only connected via GPIO).
When used as sensor board, the sense could also be mounted in the middle (although the LEDS would not be visible). That would require additional spacers and a stacking header.
If I like to extend the sensor suite further, I can buy GrovePI starter Kit.
The information from Raspberry PI I should install the Sense Hat software with sudo apt install sense-hat. Didn't work, but following hardware documentation I started with a sudo apt update. That works, and python3 and python3-numpy are also installed, next to python3-sense-hat.
Got the third 18650 battery and mounted it in the JetRacer. It is now charging.
April 22, 2020
The DuckieBot Hut provided with the TrafficLight is v1.1, instead of v2.1 provide with the DuckieBot. This could also work, but the Hut v1.1 is higher so would not fit under the topplate. Better wait till the v2.1 arrives.
Tried to start carla on my nb-dual, but /opt/carla/bin/CarlaUE4.sh gives the warning Xlib: extension "NV-GLX" missing on display ":1" and the error screen Vulkan device not available.
Executing sudo apt install mesa-vulkan-drivers solved this issue, I see a roundabout in CarlaUE4.
Running client_example.py from carla driving
-benchmarks a connection, but fails to read data. Same with benchmarks_084.py. Maybe the vehicles are spawned on the wrong location?
In its blueprint library, Carla has software for depth camera's, rgb camera's, segmented camera's, lidar's, imu's, gnss', lane_invasion, obstacles and radar.
Looking at the examples in carla/PythonAPI. Run spawn_npc.py, which tries to spawn 10 vehicles and 35 walkers. I saw one jeep appearing in the world, but many failed due to a collision at the spawn position.
The tutorial.py spawned succesfully a number of vehicles, including two police cars (Dodge chargers), but terminated after destroying the agents.
Looked at Advanced rendering options and saw that Vulkan is still experimental under Linux. Tried CarlaUE4.sh -opengl -quality-level=Low instead. The clouds are now moving. nsubiron gives in forum post a table with expected FPS up to three cameras
Bought three 18650 batteries, but the one with USB-charger is slightly longer, so doesn't fit.
Made the short bar shorter and the long one longer. Now the wheels are parallel (long bar), and with the steering servo at 0 (45 degrees) the wheels are nearly straight. Still I need an offset of 0.4 to get good behavior. Strange enough the wheels only move when you change the steering angle (nothing happens when you change the offset but keep the angle the same). Also I would expect a different sign. The offset seems to be multiplied with the same gain.
The model is linear, but the control should be a cosine (steering will always have more effect to the left).
With an offset of 0.3 the teleoperation notebook also seems to work. Yet, no forward or backward movement.
Camera gives a good view. The widget at the end of the interactive regression notebook doesn't show, but the cells is still downloading its model.
The tips are:
If the car wobbles left and right, lower the steering gain.
If the car misses turns, raise the steering gain.
If the car tends right, make the bias more negative (with increments of -0.05)
If the car tends left, make the bias more positive.
See no output in the road_following notebook.
April 12, 2020
Assembled the JetRacer AI Kit. Encountered two problems. First I had not bought the 18650 batteries, which means that I have to remove the control board again. Assume that this will be rechargeable batteries. Further the connector of the Wifi card was broken (not my fault this time, got it broken out of the package). Soldered it back on, should test if this works.
Waveshare has provided a USB microcard reader, but downloading the 7.4 Gb jetcard image from github on my old Windows laptop anyway (because it has Etcher already installed). My old Windows laptop froze, so installed Etcher on my Windows partition of nb-dual.
Inserted the card into the AI Racer. Could login, connect to the wireless and use the connection (also when the ethernet cable was disconnected).
The robot also works without batteries. Tried the basic_motion notebook. Yet, car_steering=0.3 is far left, car_steering=-1 is still a few degrees to the left. The nvidia_racecar doesn't accept offsets outside the [-1,1] range.
Followed the instructions from WaveShare (step 5), and installed their drivers (including the ads1115.py and ina219.py).
The carla/Update.sh is another 10Gb. Out of memory again. Heared from Thomas that there is also a deb CARLA installation.
Performed make clean in ~/git/carla and make ARGS=clean in ~/UnrealEngine.
Followed the instructions of Quick start and sudo apt-get install carla. Only 6Gb needed! Installation succeeded.
April 8, 2020
Made a new Unreal Engine account, and linked it as instructed to my github account. Joined the Epic Games community on Github, and now the UnrealEngine 4.24 is visible on github. Cloned the repository on the suggested place ~/UnrealEngine_4.24. Performing ./Setup.sh.
I had 26 Gb disk space available, still the Setup script fails at 51% because the disk is full.
Installed filelight to check where all the disk space is used. Very handy tool.
Removed Matlab2018a and 2018b, and ~/git/opencv/build. Have now nearly 80Gb free. The Unreal directory after Setup is 49.8 Gb. The make process fails after more than one hour compiling on disk-space. Removed the rest of ~/git/opencv, so that the compilation can continue. After compilation the directory is 77.3 Gb big, more than 33% of the partition.
Ordered a Duckieboard (LED / Motor) and a 5.5inch Capacitive Touch AMOLED.
Started again the roscore_duckiebot_interface with command docker exec -it 326e41b596b2 bash. Yesterday I had initiated a new catkin_ws, but /home/duckiebot-interface/catkin_ws is now filled other (very usefull) packages. The new catkin_ws can be found in ~/catkin_ws, which is actually /root/catkin_ws.
Run source /opt/ros/kinetic/setup.bash. roscore was already running. Continued with commands from Teleop tutorial: rosparam set joy_node/dev "/dev/input/js0", followed by rosrun joy joy_node. That works. roscd joy gives /opt/ros/kinetic/share/joy, although the launch file was at /home/duckiebot-interface/catkin_ws/src/joy_stick_driver (could be local find, because I executed rosrun in that directory.
The packages wheels_driver cannot be found, but that was due to performing the wrong source catkin_ws/devel/setup.bash. Now roslaunch wheels_driver wheels_driver_node veh:=donald starts. Yet, the driver_node crashes in wheels_driver/src/wheels_driver_node.py (line 41), where the parameter "use_rad_lim" is requested via a socket connection.
Retried the experiment with the USB-connection hand by hand. The Raspberry Pi didn't like the voltage swings and rebooted. Got it stable, Hut Led became green, the front and back bumbers LEDS lighted up, Raspberry Pi booted nicely. Bumber LEDS got out before I could start wheel_driver_node, but at the end I saw the same error message.
April 6, 2020
Could still connect to my duckiebot, via the wired connection. Didn't tried the wireless yet. Didn't had time yet to test the movement.
The command dts duckiebot demo --demo_name joystick --duckiebot_name donald didn't work, because donald.local is not known. Checking the lookup via avahi-browse --all --ignore-local --resolve --terminate but there the addresses in the 192 domain are given, while I can only reach the duckiebot via the docker 172 domain. Looking up the addresses at the duckiebot with sudo ifconfig, and both eth0 as wlan0 only have inet6 addresses.
Tried the suggestion in this rasberry pi post. After removing the local.conf I receive an inet address on eth0, but still not on wlan0. Doing avahi-resolve-address 172.17.0.1 showed XPS-13-dual.
Forced the connection by giving at nb-dual the command avahi-publish -a donald.local 192.168.178.42. Now the demo_joystick can be started. Is equivalent with the command roslaunch duckietown joystick.launch veh:=donald.
Tried to reproduce the command on the duckiebot. The process running is /usr/bin/python /opt/ros/kinetic/bin/roslaunch, but the directory /opt/ros/kinetic doesn't exist, so that is part of a docker container.
Inspected the containers with docker container ps. Activated the rosbridge container with docker exec -it 7ec9a432b17 bash. Could now do python /opt/ros/kinetic/bin/roslaunch, but joystick.launch was not found. Same for container ros_core_duckiebot-interface.
Followed the instruction of Duckbot operational manual, until I had to place a duckiebot prepared memorycard into the Raspberry Pi slot.
Have to follow the instructions of Unit C-1 first (laptop setup).
Registered DuckieTown community as one of the 13 Dutch members (and the only one of the UvA). Strange enough, the UvA was already kwown :-), but I couldn't find a previous account.
The command dts tok set didn't work directly, had to first set dts --set-version master19. Then tok set worked. Adding a wifi-network with spaces in its name worked with single quotes.
Installation went wrong because no space was left at my dual-boot laptop. Removed some huge packages from Install, and tried again. Now it works.
Unpacking the downloaded docker images on the Raspberry took ages, but finally I had a constant green light.
Could login directly via keyboard and monitor, but didn't found donald.local. Did a reboot, and now I could ping to donald.local, but had to use the ip for ssh and 192.168.178.42:9000/#/containers. I have 2 healthy and 7 running containers from 4 stacks. The Raspberry light is now constant red.
Running the next test, trying to Simple program to run via Docker. First steps (pulling from rpi-rasbian, running apt-get update, running apt-get install -y python) seems to work (python2.7 is setting up). With docker -H donald.local run -it --network=host my-simple-python-program I receive I am executing on the host donald.
Also activate the dashboard, so next test will be to move the robot.
April 3, 2020
Applied the suggested Sobel code, still they expected another result. Result looks good to me:
Looked at the solution. Didn't performed an OR on the parameter orient, so I missed the Y-gradient:
For the Magnitude of the Gradient I had the solution directly (although I used np.square()):
By using thresholds (20,100), (30,100), (0.7,1.3) I get the combined Filter:
Was missing import pickle in the code, further the HLS Quiz was easy:
With a bit of pickle and plt.show() the code also worked fine on my Shuttle:
April 2, 2020
The code of the Lesson 6.12 on Correction of the Distortion is available on github. Added jupyter to my environment and executed conda env update -f environment-shuttle.yml. A lot of other packages are installed, but in principle this update worked.
The code is a jupyter notebook, so I also have to install chromium with sudo apt install chromium-browser.
Chromium crashed with a strange error message Failed to move to new namespace: PID namespaces supported, Network namespace supported, but failed: errno = Permission denied
Trace/breakpoint trap (core dumped). Installed google-chrome, but same error message.
Will try the Jetson (didn't wake up from sleep on the keyboard, so had to reboot on power).
Three lines of code from the notebook from github are enough for the quiz. Could take the challenge, because the Duckybot was provided with a chessboard pattern, but decided to continue. Next deadline is in 7 days.
To get rid of the swrat error, I installed sudo apt install nvidia-driver-435.
I was quite happy with my undistorted image, but as the automatic grader complains that it expected another transformation:
April 1, 2020
The reviewer was happy with the submission of the Finding Lanes project. One level up.
Had finally time to also look at the introduction lessons of the Nano degree. Was invited to be Beta-tester of Introduction to C++ course and do some quizzes. Looked some video's of the interview with Bjarne Stroustrup, but got bored at actual introductions 7 and 8 (explaining an include).
The post of using a GUI to tune the Canny edge parameters was more interesting, that could have saved me some time yesterday night.
Lesson 6.7 of Camera Calibration explains the Pinhole Camera Model, including the equations for the 5 parameters the use for radial (k_1 to k_3) and tangential distortion (p_1 and p_2).
Tried to run the example code of Lesson 6.10 on my Ubuntu environment of my Windows Shuttle. I had already downloaded conda and the Starter Kit, but not created an environment yet (checked with conda env list). Executing conda env create -f environment-gpu.yml. Yet, a receive a lot of conflicts. Made a new environment-shuttle.yml, and first tried to see what happens if I increase the python version from 3.5.9 to 3.6.10. Didn't help. Made minimal environment with only numpy, opencv-python and matplotlib. That seems to work.
The code works fine on my Jetson, when I use /usr/bin/python3. Yet, I had to add plt.show() to the provided code to actually see the result. Also on my Shuttle I could execute the file and Found the corners, but no imae is shown. Downloading VcSrv (v1.20.6) from sourceforge. Setting export DISPLAY=127.0.0.1:0, and the image is shown:
March 31, 2020
Deadline day for the first Udacity assignment!
Starting python on the Jetson, gives conda-forge's v3.6.10, which loads without problems the VideoFileClip from the moviepy.editor, so I will try to run the code directly from python.
Running the code with conda-forge's v3.6.10 from the Starter-Kit fails on import cv2. Running it on the test_images with /usr/bin/python3 works fine.
Did a loop over the test_images, but overwrote the original files. Had to restore each file seperatly with command git checkout --[file].
Tried to solve missing moviepy with pip3 install moviepy. Yet, inside the Started-Kit environment pip says the requirement is already forfilled. Deactivated the conda environment. Still moviepy is fullfilled, but as a side-effect it is starting to install pillow, proglog and numpy (PEP 517). That succeeds. Still no moviepy found. Checked the system path, only /usr/lib/python3.6/dist-packages included.
Tried to do the hard way, and copied moviepy from ~/archiconda3/lib/python3.7/site-packages. Also copied missing dependencies on proglog, tqdm and imagio_ffmpeg to /usr/lib/python3.6/dist-packages. The last one fails because it cannot find a ffmpeg.exe.
Tried it the other way around, and copied cv2 from python3.6 to python3.7. Inside conda enviroment the import still fails, outside environment it is missing matplotlib. After solving this, opencv loads but complains on not well configured configurations.
On the forum I saw the good suggestion to start a new kernel which includes the packages from the current environment.
The opencv build from source is finally ready. Left for the moment the files in /tmp/build_opencv, to allow tests.
Made the report and modified the code to protect against when no left or right lines are found. Udacity requires original code, so had to look back to my code for Foundations of more than a year ago.
With those parameters the test-images are less well processed (only 2/6 correct): solidYellowLeft and whiteCarLaneSwitch. Removed the blur, only 1/6 correct. Increased low_threshold from 50 to 100. Better results, although only solidYellowLeft. Increased high_threshold to 200. Not much difference.
Looking at Hough parameters. Increased rho from 1 to 6. Suddenly 4.5 good lines. Changed theta from 180 to 60 (and lowered hightreshold back to 150. More or less 5 good. Increased threshold from 1 to 160. Small improvement, still problems with crossing lines at whiteCarLaneSwitch. Changed min_line_length to 40. Crossinglines are now gone, but now some lines are gone. Increased the maxLineGap to 25, the missing lines are back but crossing again. Trying a max_line_gap of 10. So, I have good baseline with rho = 6
theta = np.pi/60
threshold = 160
min_line_length = 40
max_line_gap = 20
A min_line_length = 50 works also fine, although the video shows some waggling. Increased the max_line_gap to 20. Test image seems OK.
Included a calculation of a fraction. Typical value is 0.85, so will use this default. Challenge works fine, elsewhere some missing lines and wrong orientations. Lower the gap to 15
Also added some code to find the longest line segment (left and right), and couple segments with the same orientation to that line. For the test images that works fine, for the video you see some outliers (with locations and orientations I cannot explain, I would expect that those are outside the masked area and outside the orientation range, so should be filtered).
March 30, 2020
Including packages incrementially to the environment seems to work. Added succesfully tensorflow_gpu-1.15. Continue with the package scikit-image. Those packages install also many dependencies, should check them with conda list --explicit.
scikit-image fails on scipy, on the PEP 517 error. matplotlib fails on missing freetype.
Before repairing scikit-image, I looked at the conda list. Packages already included are i.e. python-3.7.2, requests-2.19.1-py37.
Instead of scikit-image, first trying to install matplotlib, including its dependencies on scipy==1.1.0 and pyqt==4.11.4. The last package could not be found, so try it without.
At archlinuxarm there are packages for python-pyqt, but those are for the Qt3D and Qt5 toolkit, not for Qt4. This works, matplotlib is installed (succeded2).
Extending with jupyter, pillow, scikit-learn. That works fine (succeeded3), except that finds existing scipy-1.4.1 installation, which it uninstalls for scipy-1.1.0.
Continue with h5py, eventlet, flask-socket (succeeded4).
Continue with seaborn, pandas, ffmpeg (succeeded5)
Continue with the pip-installs: moviepy, opencv-python, requests. Moviepy is OK (v1.0.2) is downloaded, opencv-python fails. Without, it succeeded (no 6).
The previously most difficult package (scikit-image) works, so only one package left (opencv-python-aarch64).
Tried to install directly from provided whl, but got error that this is not a supported wheel on the platform.
Looked at this post, and checked the points brought up.
The OpenCV available on my installation is according to dpkg -l | grep libopencv v4.1.1-2.
Coupled Python3 to OpenCV with sudo apt-get install python3-numpy. v1.13.3 was installed.
Had to call python2 (python gave v3.7, which couldn't import cv2). Typing print cv2.getBuildInformation() showed that both in lib/python2.7 as lib/python3.6 the dist-packages/cv2 where available. The command import cv2 fails, because the default python3 is /home/dlinano/archiconda3/bin/python3 (v3.7), while /usr/bin/python3 is the v3.6 with opencv. Saw the GStreamer support, but CUDA is not mentioned.
When I start /usr/bin/python3, I see /usr/lib/python3.6/dist-packages/cv2/python-3.6 in my sys.path. Adding this directory to ~/archiconda3/bin/python3 makes that I can import cv2.
Still, according to FAQ, no ARM version is available, so no version is found to satisfy the requirements.
Tried to build it from source, with this script from github. This will install v4.2.0 from OpenCV. Install was still on 26% after finishing the NVIDIA course on Getting Started withe Jetson Nano.
Rerun the Hello Camera notebook again. That still works (if you plug in the right camera and select the correct device).
Now also run the classification_interactive notebook, which had a training accuracy of 0.95 in 10 epochs (with 30 ups and 30 downs). Correctly classified my tumbs in the live_execution widget.
The image regression project predicts the location of the nose, but could also be used to follow a line in mobile robotics. The python notebook has no problem with loading and using opencv from python.
Finished the course, got my Certificate:
Wasted a lot of time on getting the Starter Kit to work. Without activating the conda environment of the Starter Kit, the Jupyter notebook of the first project works fine (thanks to the DLI Image). Could execute the first cells without problems / warnings.
The pipeline of Matt Hardwick works fine, I could reproduce his results of his post, as suggested in the Knowledge area of the course. Only had to add line_image = pipeline(image) and plot.imshow(line_image). You see for the solidYellowLeft, that the right line is curved towards the white car on middle lane.
Finally, I need the Starter Kit. For the video's, I need to import moviepy.
The Carla simulator looks quite promising, promised to look the ros-bridge.
March 27, 2020
Anaconda channel c4aarch64 has no tensorflow package. The channel gaiar has, but this is tensorflow 1.8.0, without explicit gpu support. Seems that there is no tensorflow-gpu package for aarch64
Trying an environment with the channel of jjhelmes included, but this channel only contains basic aarch64 packages (and many advanced tensorflow-gpu packages for x64 systems).
According to stackoverflow, cp36 stands for CPython3.6. Using now conda update instead of conda create to prevent the prefix exits error. Specified python 3.6.10, which is downloaded. Transaction fails on missing envs/*/bin/python3.6 on package conda-forge:aattr-19.3.0, which is strange because I don't use package conda-forge. Should try to build a minimal enviroment first, and try to slowly extend.
Started with python-3.6.10, followed by tensorflow-gpu-1.13. The first one went well, the second had several dependencies (such as numpy-1.18)
March 26, 2020
Got an update from The Robot Report, which points to a new article from MIT CSAIL with their photorealistic simulator, called Virtual Image Synthesis and Transformation for Autonomy (VISTA).
Removed conda-forge from the channels in the environment.yml, now the transaction can be verified (no problem with python any more). Yet, they complain that tensorflow is not a wheel for this platform.
March 25, 2020
To let the Finding Lane Lanes project stand out, Udacity suggests to take a video myself!
The cheat-sheet suggest the following websites as reference:
The project's code depends on the Starter Kit. I should activate the Python 3 carnd-term1 environment.
Created conda env create -f environment-gpu.yml in my Linux for Windows environment on my Windows Shuttle.
Downloaded on the Jetson Nano from github the script Archiconda-0.2.3-Linux-aarch64.sh, which adds conda into the bashrc.
The command conda env create -f enviroment-gpu.yml failed on missing packages (scikit-image, pyqt, jupyter, qtconsole, python, seaborn, statsmodel).
Following the instructions of stackoverflow to install scikit-learn. Directly installing scikit-learn fails on scipy (1.4.1, which is based on PEP 517). Try again with scipy==1.1.0, as suggested by stackoverflow. Seems to go wrong on fortran, so installed gfortran. That works, scipy v1.1.0 is installed. Next complained is on cython. Installed cython-0.29.16. Successfully installed scikit-learn with sudo -H pip3 install scikit-learn
Watched the P1_example.mp4 video which shows the expected output on solidWhiteRight.mp4. Should also be able to process solidYellowLeft.mp4. Also watched the challenge.mp4, which is curved and includes a bridge in a lighter colour. I also received the Circuit from WaveShare, which is a nice environment to take a video myself!
No Knowledge questions on the Jetson, although a nice post on using two computers for the Simulator and ROS, coupled via a SSH tunnel.
The environment.yml installs tensoflow-gpu==1.13, while stackoverflow suggests for the nano sudo -H pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v42 tensorflow-gpu==1.14.0.
Checked for Jetpack 4.3, but there only v1.15 and v2.0.0 is available. For Jetpack 4.2 also v1.13.1 and 1.14.0 are available.
According to this post, JetPacks are not installed on Jetsons, only L4T packages. I checked cat /etc/nv_tegra_release and saw revision 3.1.
Continued with sudo -H pip3 install scikit-image. This fails on dependency matplotlib, which fails FreeType.
First trying other packages, such as numpy, protobuf and keras. Numpy also claims PEP 517, so finger crossed. It works.
Created a environment-nano.yml which points to tensorflow_gpu-1.13.1+nv19.5-cp36-cp36m-linux_aarch64.whl. Still the same missing packages when using conda. Should add extra forges.
Following the suggestions of Jetson Docker file creation, and added gaiar and c4aarch64 as channels. Most missing packages solved, except scikit-image, pygq=4.11.4 and python==3.5.2.
Moved scikit-image to the pip section of the environment-nano.yml. That worked, so also moved pyqt and python to this section. Conda starts downloading the packages. Transaction failed, because conda-forge required python3.7.
Moved python (without version) back to dependencies. Got the ValueError, which I solved by giving the environemt a new name. Still ~/archiconda/envs/car-starter-kit/bin/python3.7 is missing.
Installed the wireless module by following the instructions of step 7 and 8 of hardware-setup. Most difficult were the self-tapping screws of the antenna's, as indicated in blog.
The wireless module works fine, could connect to my 5 GHz home network (and 2.4 GHz was also visible).
Enrolled in Self-Driving nanodegree, the first project is Finding Lane Lanes (suggested deadline March 31). They expect 15h/week for this period.
March 23, 2020
Looking into the Udacity courses. Had in the budget a Nano degree, but couldn't find it directly back.
There is also a prepation Nanodegree of 4 months (10 hrs/week). That is mainly Bayesian Thinking, C++ Basics and finalizing with a Image Classifier.
The Nanodegree is 6 months (179 euro per month). The course starts with finding lanes on the road, via Kalman Filtering and Planning to System Integration. The final project is to drive Carla (a real car) around the Udacity test track.
Unpacked the Nano Jetson. Following the instructions on Getting Started. Luckily, I received a 64Gb microSD card and a Raspberry Pi micro-USB power supply together with my Nano Jetbot Kit.
Could connect to the internet via the wire. With Silicon Highway Jetbot also a Intel 8265 wireless card included. Following the instructions from the jetbot wiki to install this card. The wireless card should be mounted under the heatsink.
In the meantime Ubuntu is updating its packages (via the wired connection).
Camera setup is with a Logitech C270 webcam, or a Rasberry Pi V2 camera. The last one is included with the Silicon Highway Jetbot. First try a simple Logitech webcam (QuickCam Communicate DeLuxe).
The Card image of the Introduction Card is not the same as the default Jetson Card image. It is missing the Jupyter Notebooks. Trying to install the required packages and start Jupyter as service.
Had some problem with the instructions to install numpy by pip3, but the next step requires to install TensorFlow, which uses a specific version of numpy. That installation wheel seems to work. Still, downloading the Course image, which is substantial larger (21 Gb instead of 5Gb).
Reading to the classes. The performance of the Jetson Nano is compared with Google TPU board in this article with impressive FPS for both platforms. The same article mentions the existance of ros deep learning integration.
The Jupyter Notebook works fine with the QuickCam:
Trying to do the same with the ZED camera, but no blue light lights up. The first cell still runs, but the second cells of the Jupyter notebook fails. Installing the ZED SDK for Jetpack 4.3.
The Depth Viewer works, the usb-camera Notebook still fails (camera not switched on, while it is a regular uvc_camera).
March 20, 2020
Installed a NVIDIA RTX 1080 in my home-computer. Still the same message from Zoom Depth Viewer. Updated my NVIDIA drivers to v442.74 from v390.85. Now the Depth Viewer works:
March 18, 2020
Checking out the ZED camera on Linux 18.04. Downloaded v3.1.0 for CUDA 10.2. Needed the version for CUDA 10.0. Downloaded another 1Gb.
The software is installed in /usr/local/zed.
Strange enough, the tutorial examples aren not part of /usr/local/zed/samples. Cloned from github.
The Hello Zed tutorial fails on import pyzed.sl as sl.
In the root of the Tutorials is a CMakelists.txt. Running cmake .;make makes all seven tutorials. Hello Zed fails because my laptop has no Nvidia GPU (CUDA was from the experiments with the TPU). My desktop at home as a Nvidia GPU, but not sure if a Tesla C2050 supports CUDA 9.0 or higher.
Otherwise there are the ZED SDK versions for the Jetson Nano.
My GPU is on the list, with a compute capability of 2.0. Downloading CUDA 10.2. Both the Zed and Zed-2 (100$ more expensive, including magnetometer and Wide angle FOV) requires at leat a compute capability of 3.0. There is also a Zed-mini (for the JetBots). Max range of the mini is 15m (and has USB-C cable!). Is actually 50$ more expensive than a Zed!
Try to isntall the ros-wrapper. Yet, installing ros-melodic-roslint and ros-melodic-stereo-msgs is not enough. Also installed python-rospkg and ros-melodic-roslib, still the build fails on ros-pkg. Seems that is related with the use of python2 instead of python3 as interpreter. Not completely true, ROS melodic is still in transition to Python3.
I am not the only one with this problem. rospkg is installed, but not in /usr/lib/pymodules. Instralling it manually via pip install doesn't work, because no version is found. Should be part of the core. Updating my ros-packages. That helps, only an error in the build of the realsense package.
Yet, starting roslaunch zed_wrapper zed.launch, gives an error cannot load command parameter [zed_description] returned with code [2]..
The Zed Viewer works fine under Windows, the Depth Viewer reports that the graphics driver needs to be updated.
Running the first part of the example works, for the second part I need Visual Studio (Zed_Camera loads mexZed.mexw64, which is build from ../src with the cmake_gui).
With nb-dual the /usr/local/zed/tools/ZED_Explorer works fine, the ZED_Depth_Viewer reports that no NVIDIA card is detected. The ZED_Sensor_Viewer (resolution 1K), reports no sensor. That is the same for Windows, so this tools requires an ZED-2.
March 15, 2020
Saw this overview paper with tools for development and validation of automated driving. Autoware, Gazebo and USARSim were mentioned.
March 14, 2020
The ZED stereo camera arrived today.
Also the High Silicon Jetbot arrived. Need to contact the 3D print shop.
Connected the Loomo to the Robolab wifi. Couldn't connect to my phone. Connected via my telephone's hotspot. That works, Loomo downloaded Segway Robot System 3.9.14. After rebooting I tried to use the hotspot of the Loomo, but directly after connecting the system disconnected.
Used my telephone's hotspot to let the robot follow me through the lab.
The Type C connection in the head (and a head-lock).
March 13, 2020
Nice quote of Melanie Mitchell on autonomous driving: "There are a few types of vehicles currently at level 2 and 3 (of autonomous driving). The makers and users of the cars are still learning what situations are included in the 'certain circumstances' in which the human driver needs to take over".
The NVIDIA Carter is based on the Segway RMP 210, which is no longer sold by Segway. The platform is still available from Stanley Innovation. The Segway Loomo is great, but seems to be Android based, not ROS based, although MIT made Android ROS Core as a bridge.
They have three worlds (simple, mcity and citysim (gazebo7 and 9).
February 19, 2020
The OpenAI RoboSchool contains a number of robot models (such as the ant used by Fabrizio) which are improved (more realistic physics). The code is already 3 years old. The Zoo also has an Atlas model. It would be nice to see if driving a golf-car (DARPA challenge) could be learned with an Atlas robot.
Found Fabian Flohr's thesis on Orientation Estimation for Autonomous Driving. Maybe also relevant for orientation estimation of the truck in the scenario.
January 23, 2020
Velodyne announces a $100 automative lidar, according to IEEE Spectrum. The Velabit will be available for customers mid-2020.
January 16, 2020
Read an interesting article about augmented reality for autonomous vehicles, although the vehicles are fed with I2V messages as if it were V2V messages (so only the status, not full sensor augmentation).
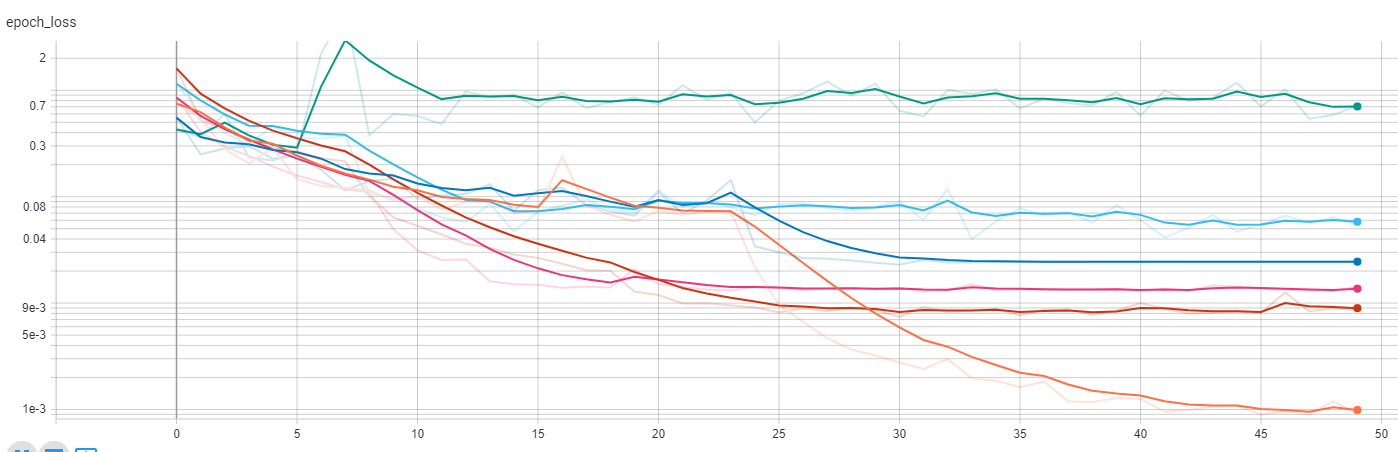
 .
.







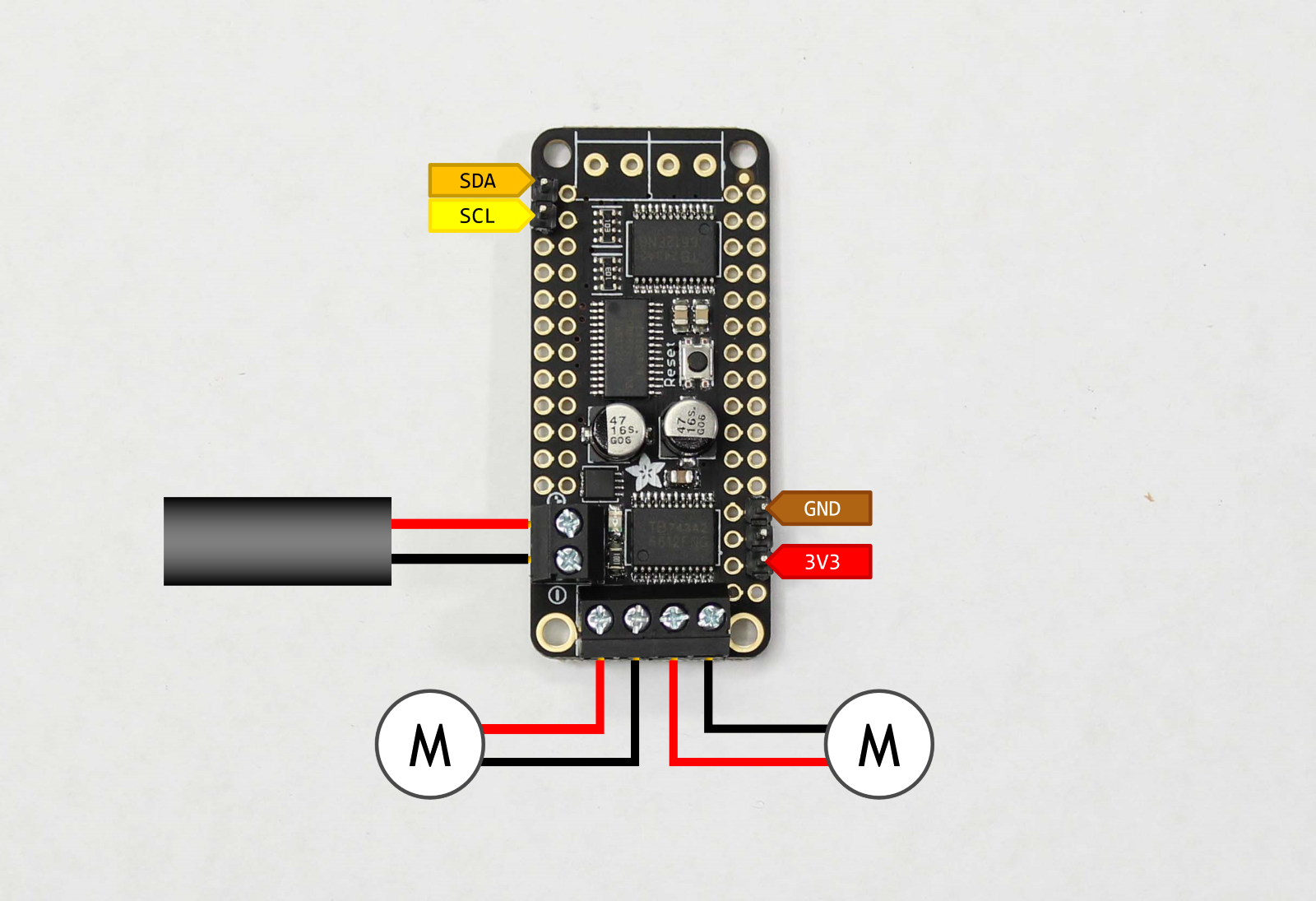{kind=link}
{kind=link}
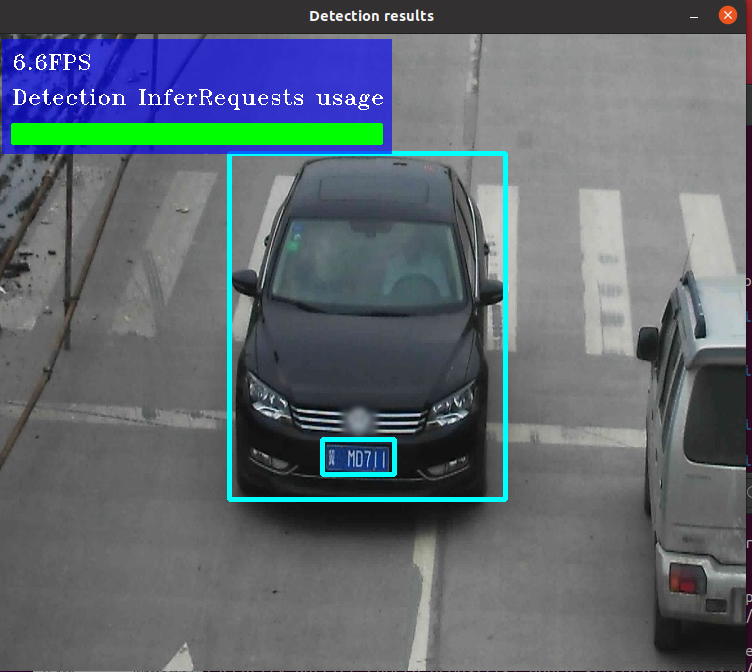

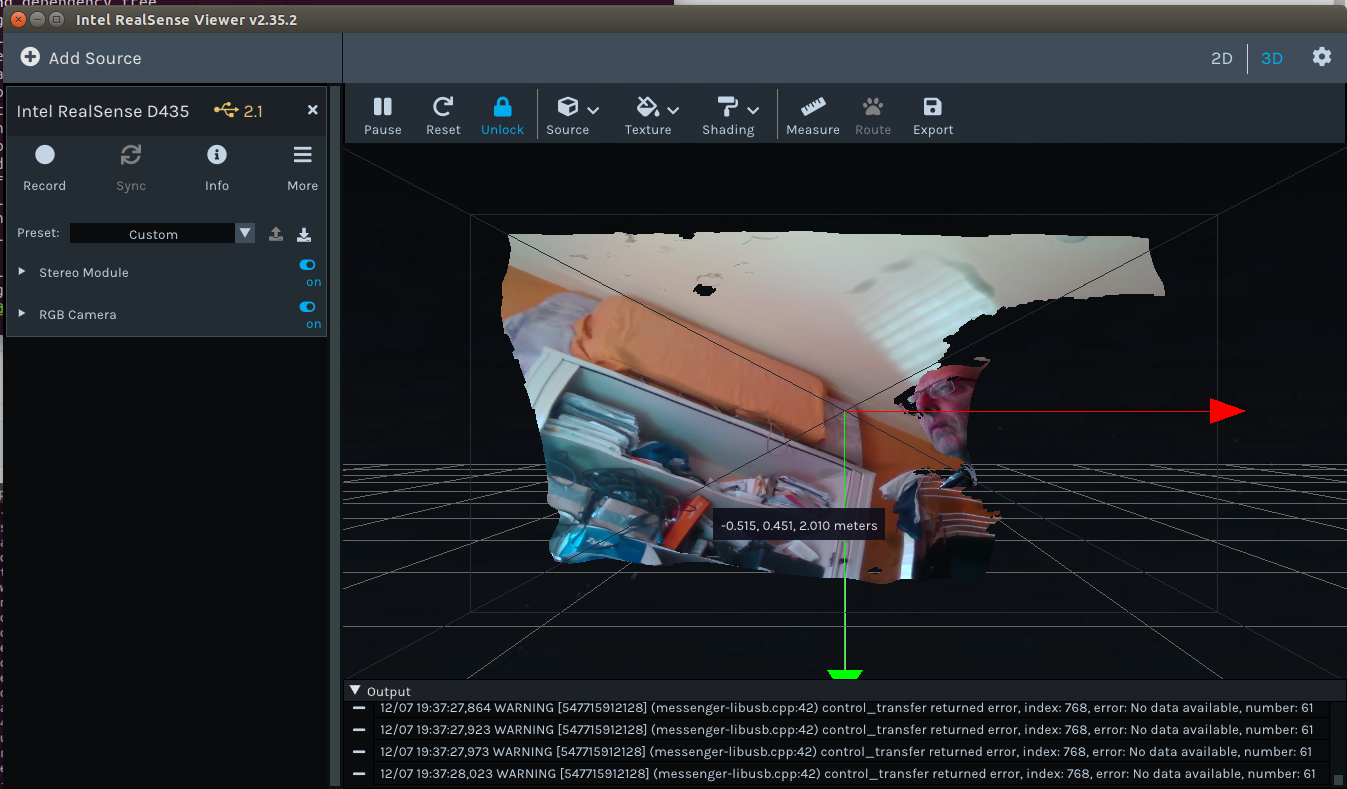

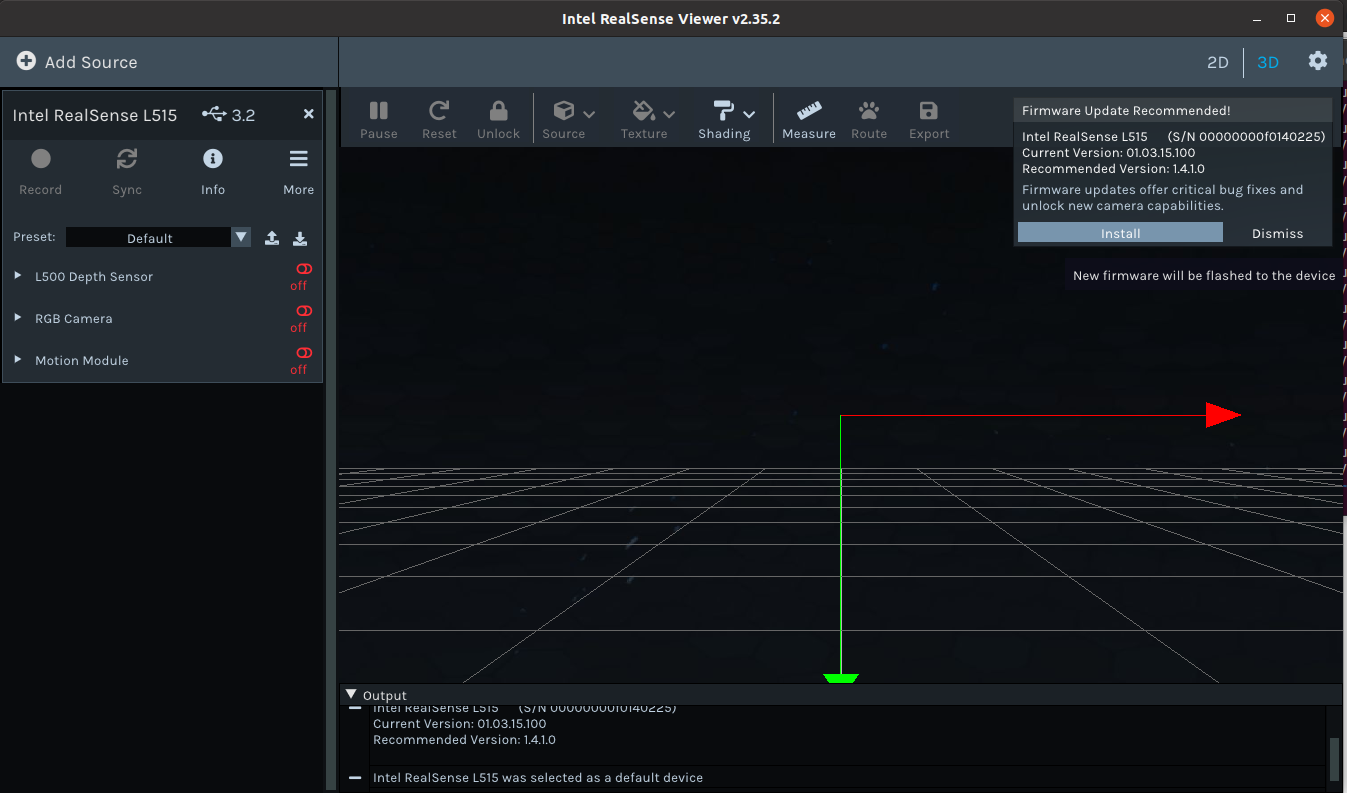
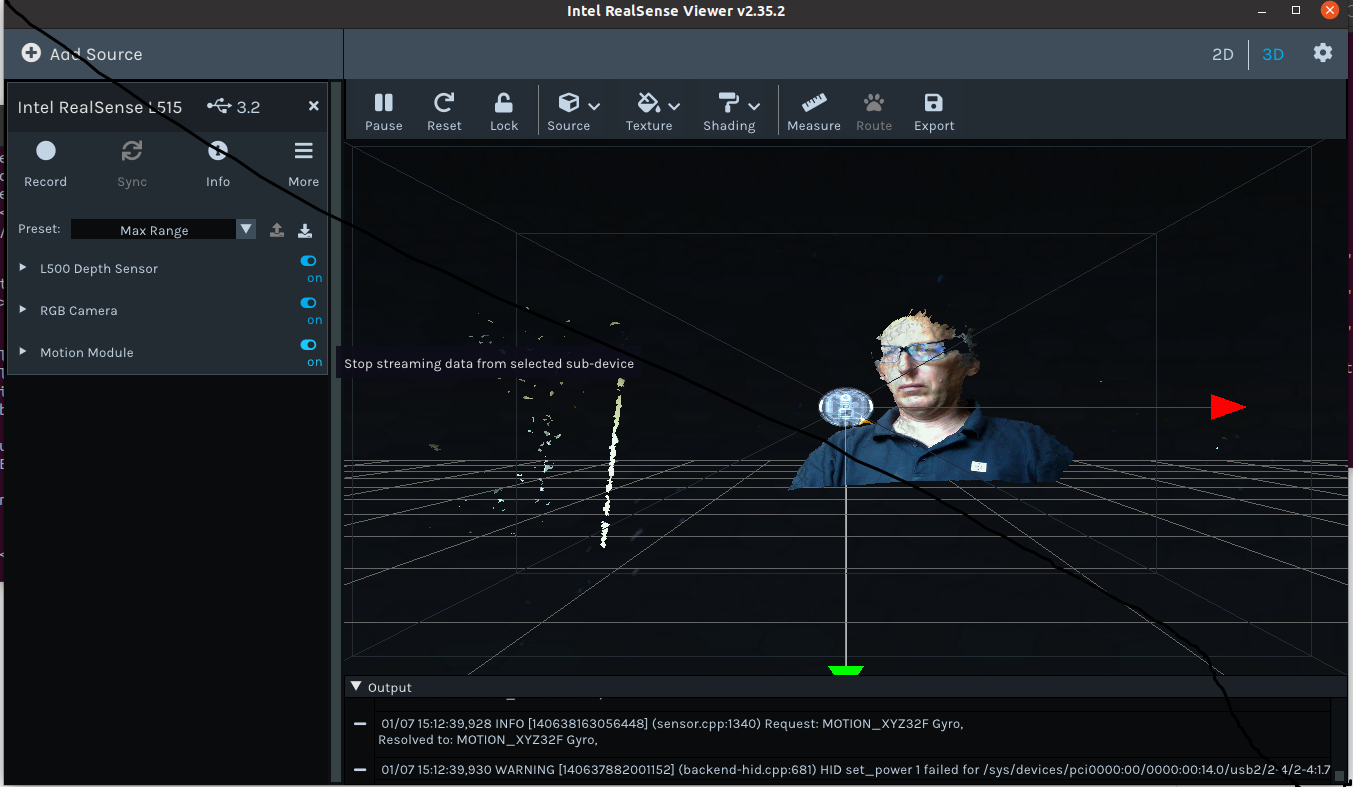
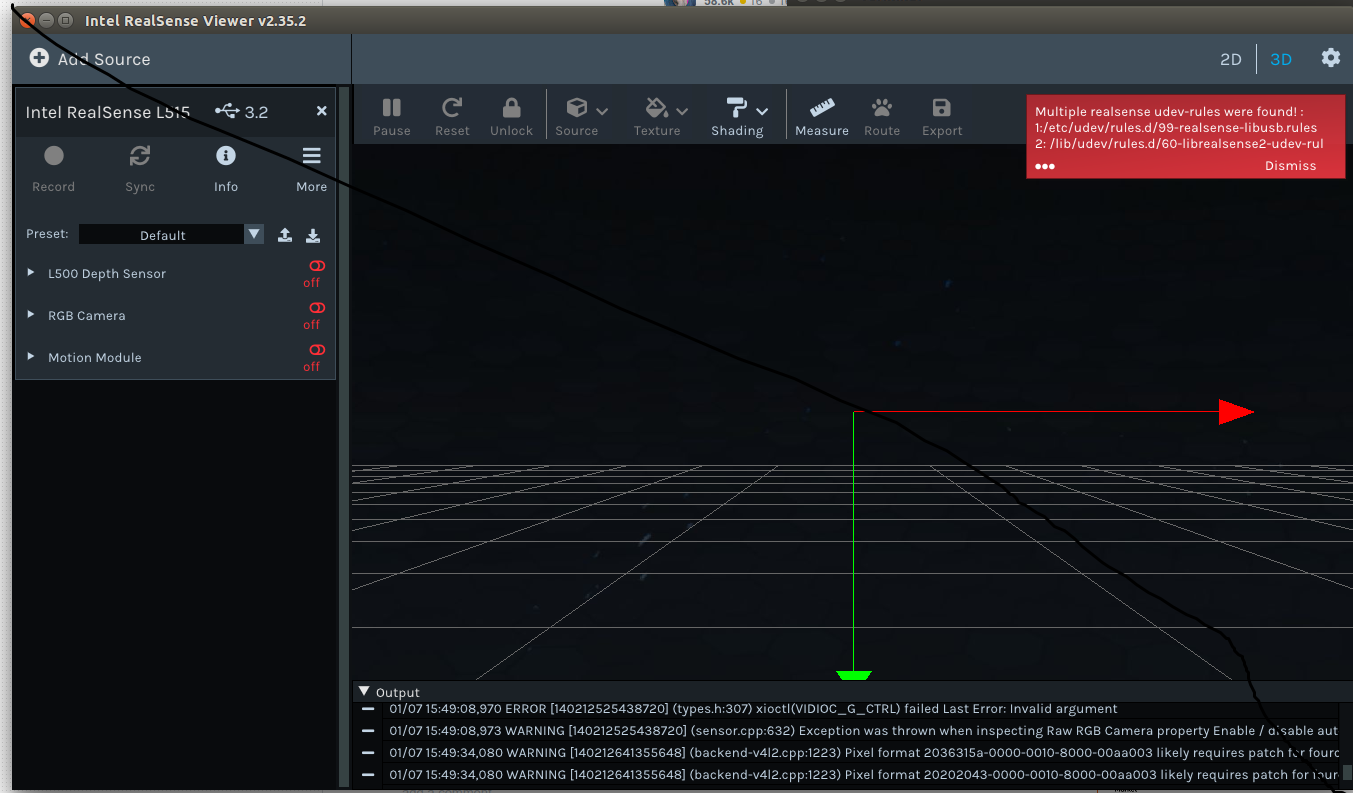
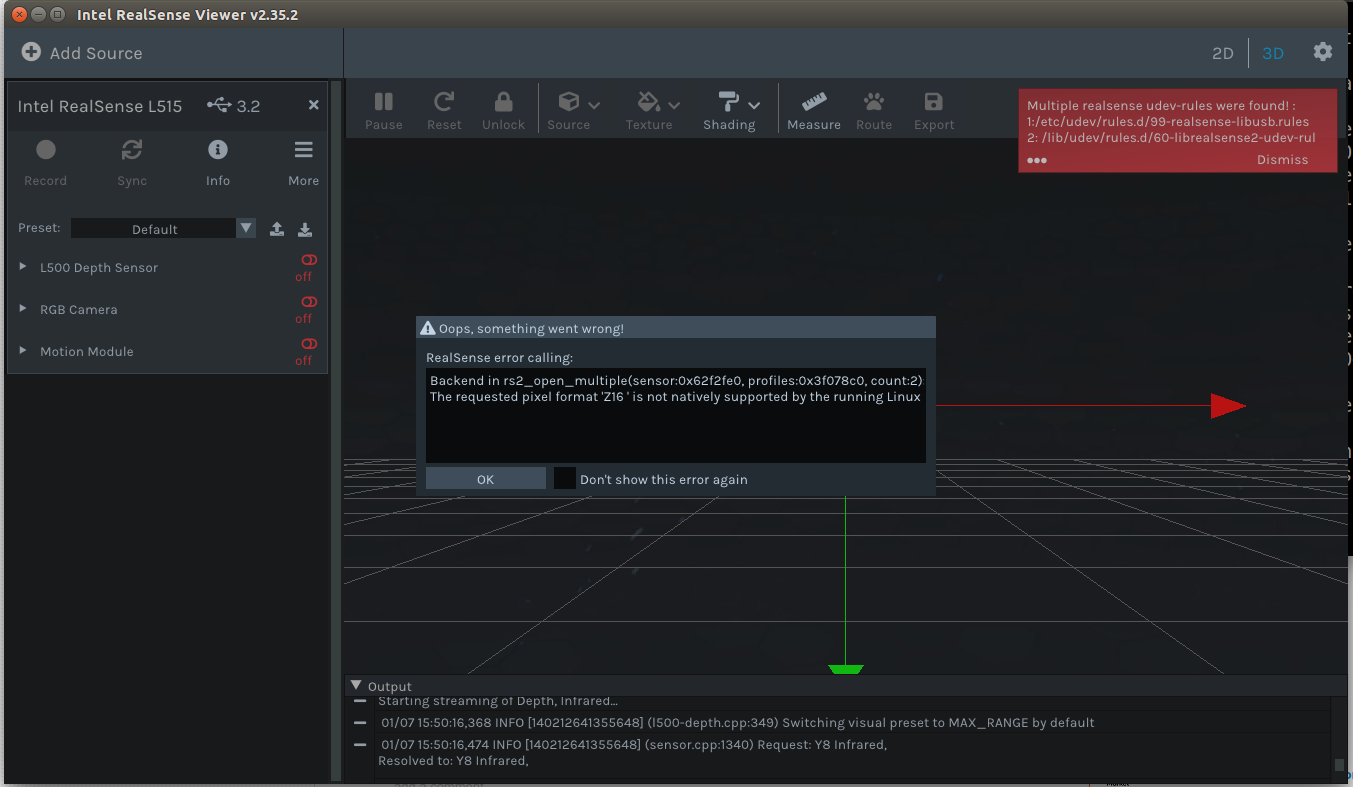
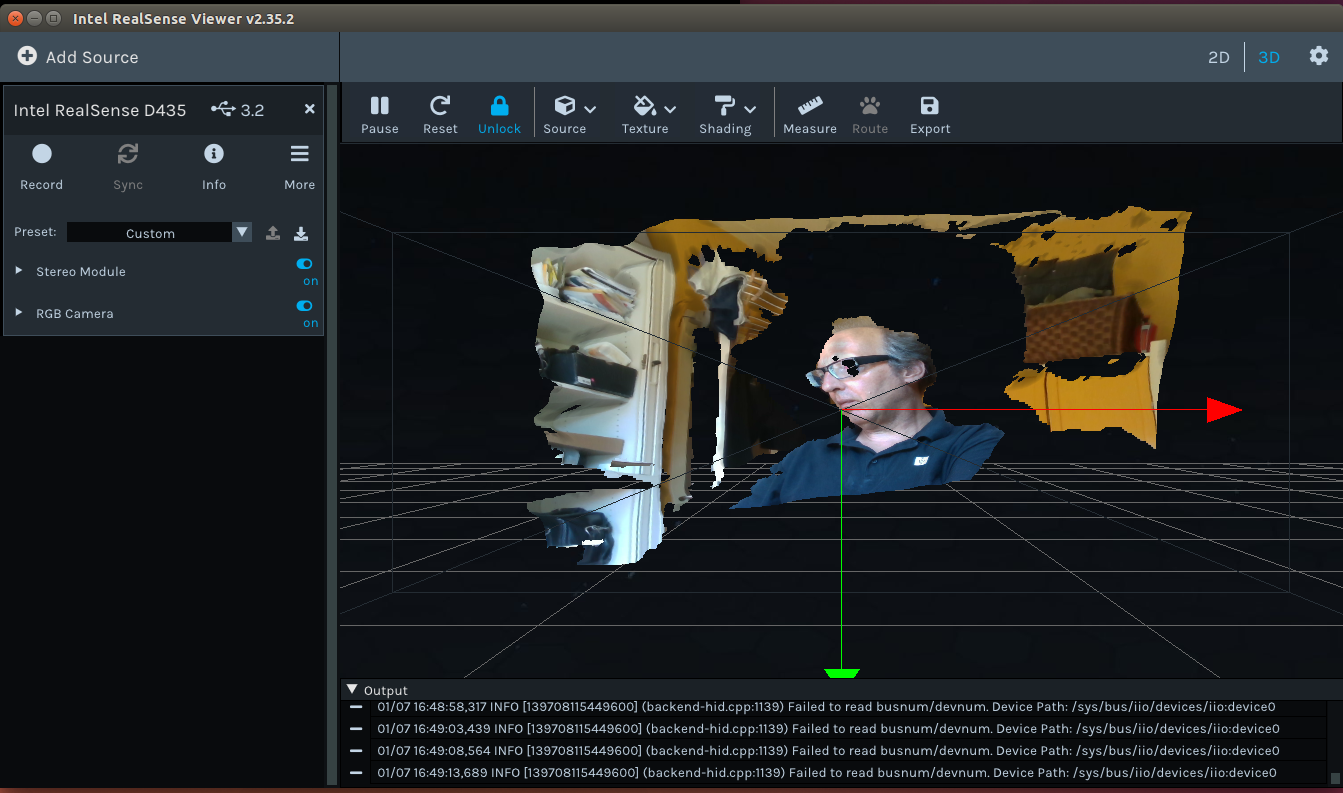
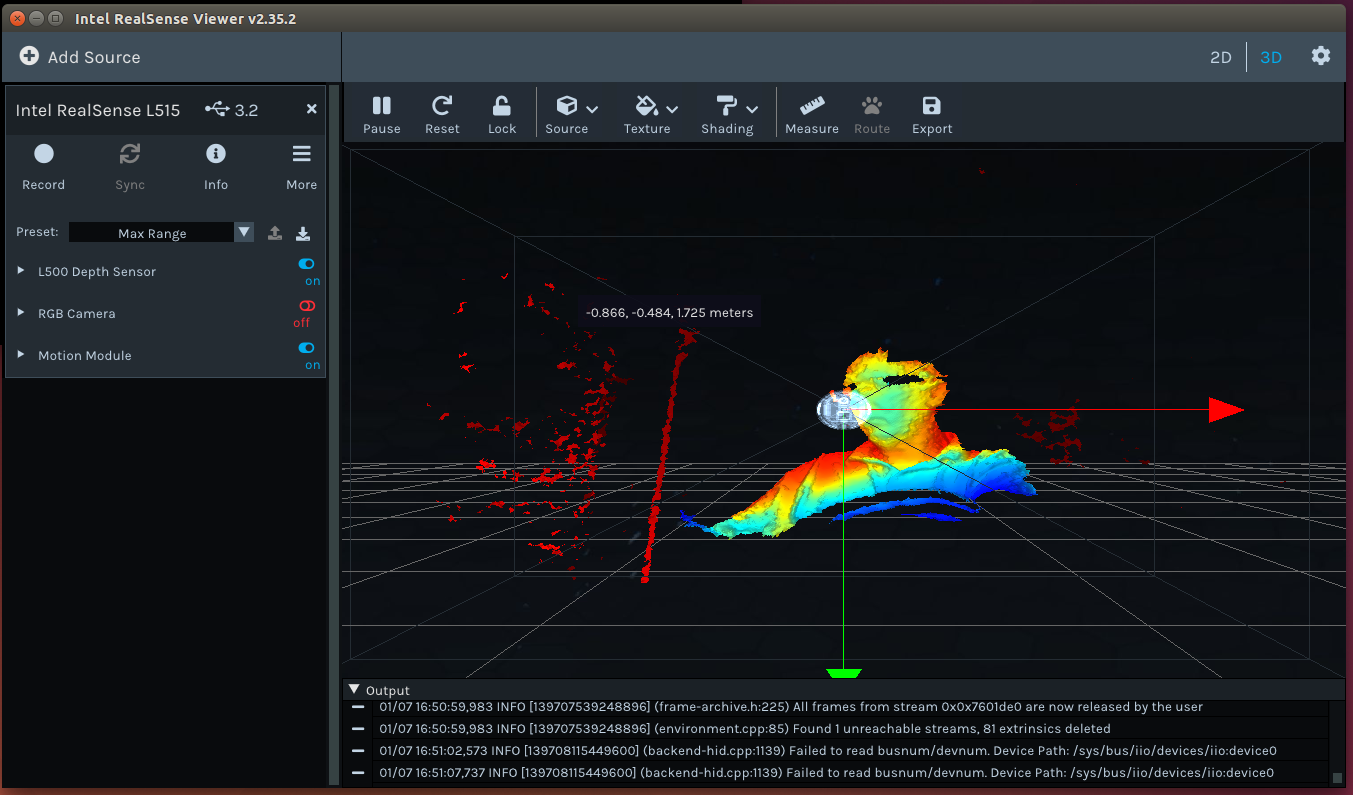
{kind=link}