Context
As my research concentrates on the perception part of Robotics, my research is in the Informatics Institute part of the
Computer Vision group.
Started
Labbook 2023.
December 23, 2022
December 16, 2022
- The TAO Toolkit 4.0 release contains new transformed-based pretrained models like CitySemSegformer and Peoplenet Transformer.
December 6, 2022
- Also read OpenCV Complete Guide to Object Tracking and Object tracking using OpenCV.
- Re-Identification is only covered in the two DeepSort and FairMot post already studied yesterday.
- The last tutorial shows 6 of the 8 implemented in OpenCV. In OpenCV 4.2 also MOSSE and CSRT are available. The GOTURN tracker (available since OpenCV 3.2) is the only one based on a CNN.
December 5, 2022
- Learn OpenCV has a tutorial on multi-object tracking and reidentification.
- According to the teaser, the most popular models for re-ID are Sort, Deepsort, JDE, Tracktor, ByteTrack and FairMot.
- There is also tutorial on SORT and DeepSort.
- DeepSORT is an anchor-based approach, FairMOT is a anchor-free approach.
- After the MOT20, there is also MOTS-CVPR22, which is a synthetic dataset based on Grand Theft Auto V, which also contains night-scenes.
- DeepSort performs visually very well, but has many ID switches. Not only FairMOT, but also CentrTrack should be able to autperform DeepSort.
- Combining Detection and ReID is done in a 'naive'way by MOTS-algorithm.
- FairMOT outperforms most other deep-learning MOT algorithms, because for most algorithms the feature dimension is too high (512 or 1024 features). The accuracy increases when the re-ID feature dimensions are reduced to 64.
- In the FairMot they refer to Zhengh 2017 and Chen 2018 as major steps in re-ID.
December 4, 2022
- I could not connect via ssh to the rasberry, so I followed this these steps to enable the ssh-interface. Could connect
- Also enabled VNC via these steps, because I want to see the recordings.
- Installed the VNC Viewer 6.22.826 at my Shuttle.
December 3, 2022
- With cat /proc/cpuinfo you can check that the Raspberry from the trafficlight is a Rasberry Pi 3 Model B Plus Rev 1.3. With getconf LONG_BIT you can check that it is running a 32bits OS. With lsb_release -a you can check that ist Raspbian GNU/Linux 10.
- Have a new 64Gb microSDX card (UHS-3), so I can burn a clean Raspberry version.
- Downloaded the RasberryPi imager v1.7.3 from Rasberry Pi
- From the choices of OSs, I selected the 64 bit option with Desktop, which should be compatible with 3B+.
- Yet, the download was not needed, the Imager gave its own choices. Again selected the 64bits with Desktop.
- On the softlink of Computer Techniek no new information, because I will use the camera indoors.
- At setup, selected The Netherlands which use of English language and US keyboard.
- Selected the Duckiebot username for the system. The system has quite still quite some updates to install.
- Installed motion. Switched steam_localhost to on (instead of off), but still could not reach the browser.
- Switched also webcontrol to on. Could access the control , but do not see the stream.
- Also on the localhost the pan-tilt doesn't seem to work, although the stream works fine.
- The movements are saved in ~/Pictures.
November 29, 2022
- Started up the RaspberryPi from the TrafficLight again. I worked on it before on May 2, 2020. I could still login on trafficLightXX with username duckie, not the mom or tlo mentioned in SD-card preparation.
- The trafficLightXX has a wlan0, I registered the MAC at iotroam.
- Followed instructions to configure the network.
- Tried several commands to restart the wlan, but at the end just rebooted. That works, I can ping google.nl. Yet, no graphical interface, so I could better use another system to test motion detection.
-
- Tried the NanoSaur instead. The system nicely boots up, but it has two Logitech Nano receivers and one Dell Universal Pairing stick, but those are intended to be used with IO devices as keyboards / mouses.
-
- Checked the spare Jetson Nano with the stick from NanoSaur. With both USB-power and the Power Adapter SWP01021050V the systems works. Removing the Power Adapter crashes the system. Note that this Power Adapter provides 5V at 1.5A, while the Jetson can handle on its power input Max. 4A.
- According to this post, even a 6A Sparkfun powersupply (Retired) is possible on the DC barrel.
- Note that using a 12V or 19V powersupply will fry the board.
- Checked the power consumption with jtop. The Power mode is still MAXN, and the average power consumption is 1923 mW (when idle). So, still some margin until the max 7500 mW the 1.5 A Power Adapter can deliver.
- The nvidia-l4t-bootloader still requires a reboot, so something goes wrong with the post install.
- Connected wired to internet, and put the Software Updater to work.
- Indicated the Docker daemon can restart automatically (was unselected). Post install warning is gone, apt update indicates that the system is up-to-date.
- Note that the OAK-D power supply delivers 3A, so is an even better choice.
- Found a Nao wifi-stick. Labeled it as #1. Could connect without problems to LAB42.
November 25, 2022
- The application example of color segmentation of the OpenCV course covers analysing the NIR and NDVI bands with GDAL (based on a LANDSAT image).
November 17, 2022
- aiMotive published the description dataset, which contains 360 degrees of view scenes with camera, LIDAR and radar.
November 14, 2022
- The RITA environment combines simulation with data-driven and generative models.
November 10, 2022
- Did a Breakfast Bird backing of the OpenCV Luxonis RAE robot (Robot Access for Everybody) with both a stereo camera at front and at the back.
- Expected delivery date will be June 2023.
- Note that initially there will only be tablet control, although desktop control is foreseen.
- As one of the comments mentioned: measurements of both IMU and encoded wheels will be exposed on ROS2.
November 4, 2022
November 3, 2022
- The NIPS 2022 paper Model-based imitation learning outperforms Dian Chen's latest (CVPR 2022) result Learning From All Vehicles with another 35%. The code is provided.
-
- In related work they point out to three recent papers which use transformers to generate bird-eye views:
- In the NIPS paper the learn the latent dynamics of the world model from image observations. Contrarily to prior work (e.g. Atari games), they us high-resolution observations (600x960), which makes it possible to perceive small details as traffic lights (see Mael's work) (see Mael's work) (see Mael's work) (see Mael's work) (see Mael's work) (see Mael's work) (see Mael's work) (see Mael's work) (see Mael's work).
- For the unprotected cross-turn he trajectory forecasting from Reinhart et al (ICCV 2019) seems to be most relevant: PRECOG: PREdiction Conditioned on Goals in Visual Multi-Agent Settings, including dataset and code
- Key to the MILE's work is that they first predict a 3D (so depth) from the 2D image, before they predict a bird-eye view image. This was inspired by J. Philion and S. Fidler (ECCV 2020) Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D from Nvidia, including project page and code
- They compress in the BeV feature space instead of the image space, which they found critical. They compress much further than in traditional computer vision tasks, because the the number of possible actions is actually quite limited. The latnet state is a 1D vector of size 512.
- As expert they used a RL agent which outperforms CARLA's in-built autopilot. This was work of Zhang et (ICCV 2021) End-to-End Urban Driving by Imitating a Reinforcement Learning Coach, with code.
October 20, 2022
- Outsight now has an SLAM on on chip solution.
October 14, 2022
- Watched the Getting Started with Foxglove video, which also updated 3d panel.
- Foxglove Foxglove studio cannot only load local rosbags, but also from url (and has a storage in the cloud program, if it gets big).
October 11, 2022
October 10, 2022
- Nvidia allows now to update the CUDA drivers in the Jetson JetPack 5.0 and corresponding CUDA toolkit, instead of upgrading the whole Jetpack
October 6, 2022
- Trying to do python depthai_demo.py in ~/git/depthai.
- Yet, the software requires a software update first. The install script gives warnings on SSL:
Could not fetch URL https://www.piwheels.org/simple/requests/: There was a problem confirming the ssl certificate
- I use already the latest version of pip, so most those suggestions don't apply.
- Yet, the demo works again after the update (with warnings).
September 23, 2022
- Read this review on using Jetson Orin development Kit instead of a Jetson Nano. More horsepower, but also 60W power consumption and a pricetag of $1,999. The nice to know is that the sensor interfaces are there, hidden at the underside of the Jetson AGX Orin.
September 14, 2022
September 8, 2022
- Connected the Segway Loomo with LAB42 network (MAC address could be found in Wifi advanced).
- Returning to the home page can be done by touching the side of Loomo's head.
- Found my MAC-address of my phone (about phone -> status). Phone is connected, but the Loomo app doesn't see the Segway, although they are in the same network.
- Will try the Vislab network.
-
- Worked with the Loomo before on July 7-9, July 30 and October 2 2020. On March 14, 2020 I also had troubles with connecting via the network. Solved it by using my telephone's hotspot.
August 9, 2022
- Would be interesting to see how the networks would be visualised with Guide Grad-CAM instead of guided backpropagation.
June 30, 2022
June 25, 2022
- The CVPR paper Learning from All Vehicles outperformes their own LBC an WoR by a large margin, by also using the data from all surrounding vehicles (from their perspective). Only with traffica light infractions LBC is still on the lead (so there Mael's work is still state-of-the-art).
June 14, 2022
June 10, 2022
- Creating a new environment without tensorflow-gpu-1.14 with conda env update -n tf1.14-no-gpu --file environment-no-gpu.yml.
- Checked Changelog and decided that optimized einsum should work both for v2 and v3.
- The codesnippet in einsum's documentation could be a good test for my conda environment WITH gpu.
- First running python CVM_Particle_filter_OxfordRobotCar.py in the no-gpu environment. Still, it seems that the gpu is used:
2022-06-10 08:45:33.563073: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1326] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 24259 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce RTX 3090, pci bus id: 0000:01:00.0, compute capability: 8.6)
- In the downloaded packages of the environment, I see cudatoolkit-10.1.243, but no tensorflow packages. Does it realy on already installed packages?
- The tensorflow version in /usr/lib/python3/dist-packages/tensorflow/ seems to be v2
- Still the einsum error from SAFA.
June 8, 2022
- Finished all cells, but the last one fails on module 'random' has no attribute 'choices', which has something to do with python3.5/site-packages/matplotlib/animation.py.
- Looked in the environment.yaml provided with the code. Part of the problem is that the environment.yaml expects python3.7, while the Singularity has Python3.5.2 as /usr/bin/python3. So, absl-py=0.15.0 is not available, but 0.8.0 is already in /usr/local/lib/python3.5/dist-packages.
- Same for matplotlib (3.0.3 in ~/.local/lib/python3.5/site-packages, while 3.3.4 is requested.
- Strange enough, matplotlib-inline has a higher version (4.3.2) in ~/.local/lib/python3.5/site-packages, while 0.1.2 is requested.
- The environment.yaml specifies mkl_random=1.2.2, which seems to be called by import random. That package was not yet installed. v1.0.1 was installed, together with mkl_fft-1.0.6.
- Still a black login screen. Should try a reboot.
- After a reboot I see also the warning: Moviewriter imagemagick unavailable, try to use Pillow instead. Strange, because outside the Singularity is imagemagick already the latest version.
- Used this code-snippit to use PillowWriter.
- Yet, Running the dependency gives a dead-kernel (python3), while python3.7 gives a Kernel error).
- Tried to run the code snippet in Singularity, but get two import errors (nmpy.core.umath). Removing from spatial_net import * solved that. Yet, now the tkinter error is back. Used the same matplotlib.use('Agg') again (and removed the plt.show()). So, an animation is made with the PillowWriter():
- Trying to use a conda environment, instead of singularity. Executed conda env update -n tf1.14 --file environment.yml.
- Activated the environment with conda activate tf1.14. Had to do a python3.7 -m pip install opt_einsum to get the imports running.
- The code fails on tensorflow. Added print(tf. __version__), which gave v2.1.0.
- There is only LD_LIBRARY_PATH, which I unset. Seems that my ~/.local/lib/python3.7 is in conflict. Moved that python3.7 directory to ~/tmp and now the version in the conda-environment is 1.14.0.
- Started a tmux session and started python CVM_Particle_filter_OxfordRobotCar.py at 14:29
- Note that cuda_diagnostics indicates kernel version 510.60.2 does not match DSO version 510.73.5 -- cannot find working devices in this configuration. Also nvidia-smi gives Failed to initialize NVML: Driver/library version mismatch, which is probably due to the recent lambda-upgrade.
- Reboot and try again.
- After the reboot nvidia-smi gives Driver Version: 510.73.05 and CUDA Version: 11.6
- Now the script gives:
2022-06-08 14:38:08.503227: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1763] Adding visible gpu devices: 0
2022-06-08 14:38:08.503479: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudart.so.10.1
...
2022-06-08 14:38:55.827780: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1326] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 24259 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce RTX 3090, pci bus id: 0000:01:00.0, compute capability: 8.6)
- The script only prints the first progress line, and crashes after 20min on the einsum_reduction on math_ops.matmul.
- Used the trick from nvidia forum and did cuda update -all.
- Also created the suggested ~/tmp/tftest.py to check the multiplication. After the cuda update still the same error. Tried python tftest.py, which works fine.
- Several versions of opt_einsum are available. Uninstalled opt-einsum-3.3.0 and installed opt-einsum-2.3.2
- The code fails on line 165 (sat_global_val = sess.run(sat_global, feed_dict=feed_dict)), which triggers:
File "/home/avisser/anaconda3/envs/tf1.14/lib/python3.7/site-packages/tensorflow/python/client/session.py", line 1370, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.InternalError: 2 root error(s) found.
(0) Internal: Blas xGEMMBatched launch failed : a.shape=[8,256,32], b.shape=[8,32,64], m=256, n=64, k=32, batch_size=8
[[node spatial_sat/einsum_1/MatMul (defined at /storage/avisser/data/Oxford/data_PF/code/spatial_net.py:27) ]]
(1) Internal: Blas xGEMMBatched launch failed : a.shape=[8,256,32], b.shape=[8,32,64], m=256, n=64, k=32, batch_size=8
[[node spatial_sat/einsum_1/MatMul (defined at /storage/avisser/data/Oxford/data_PF/code/spatial_net.py:27) ]]
[[l2_normalize/_125]]
0 successful operations.
0 derived errors ignored.
-
- Successfully tested the software for the OAK-D that I downloaded February 5, 2021.
- Tested it with python depthai_demo.py -s metaout previewout,12 disparity_color,12.
- With the USB-C to USB-B cable it works, with soft USB-C to USB-C I got a segmentation fault.
- The USB-3.1 cable also works fine.
June 6, 2022
June 2, 2022
- Unzipped the particle filter data and code in /storage/../Oxford/data_PF
- Additional data was needed, because Zimin also recorded the Oxford data on a regular_grid.
- Watched the first part of the 1st RoboLaunch lecture, Liam Paull's part on Duckietown and AI Olympics starts at 6:42.
- Laim first introduces robots and autonomous driving cars, including the End-to-End learning by Nvidia in 2016.
- Duckietown finally appears after 35 min.
- There is now also a Duckietown MOOC.
-
- Running the Particle Filter notebook with kernel python3 in singularity. I see no CPU warnings.
- There are 89600 satellite images, the InputData_grid is read with a radius of 50.
- Started to compute satellite descriptors around 15:00, 15min later around 10% was computed. The notebook is ready with the cross-view model around 17:00, so doing the same for the baseline will take another two hours.
June 1, 2022
- The command nvidia-smi showed driver version 510.60.02 and CUDA version 11.6
May 31, 2022
- Created a script that downloads the false_color images with a sampling space of 20m.
- The script only runs native on ws10 (running python3.8), and doesn't work in the singularity tensorflow1.14.2 container, because there python3.5 is used (and SentinelHub requires python > 3.7).
- Had some problems with matplotlib and Tkinter, so used the trick from stackoverflow and used:
import matplotlib
matplotlib.use('Agg')
import matplotlib.pylab as plt
- Result is that the images are saved (but not shown).
- 440 satellite images were downloaded.
- The results of the test / validation are:
val global accuracy = [[0.00000000e+00 5.88928151e-02 9.94110718e+01 9.94110718e+01
9.95288575e+01 9.95288575e+01 9.95288575e+01 9.95288575e+01
9.95288575e+01 9.95288575e+01 9.95288575e+01]]
val local accuracy = [[ 0. 96.93757362 99.52885748 99.52885748 99.52885748 99.52885748
99.52885748 99.52885748 99.52885748 99.52885748 99.52885748]]
- Also visualized this result:
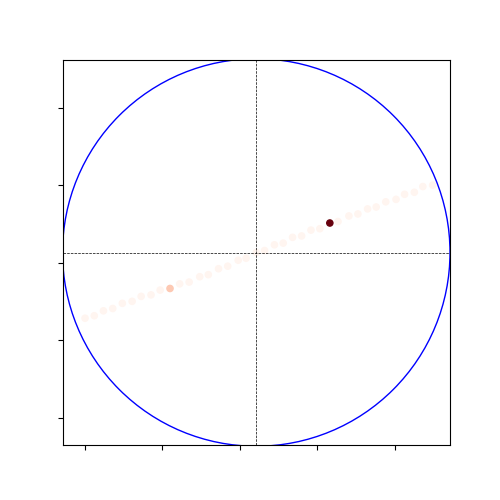
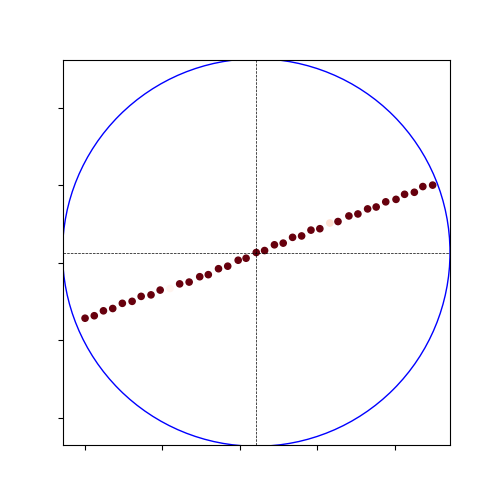
- So, the local accuracy is still high and the nearby heatmap looks precisely the same as May 20. Also there, there was not much difference between an interval of 20m and 100m.
- Downloading the samples with 5m sampling space.
-
- Checked the nvidia-drivers on ws10 with suggestions from this how-to. Not only nvidia_smi doesn't work, but also modinfo /usr/lib/modules/$(uname -r)/kernel/drivers/video/nvidia.ko | grep ^version showed that there are no nvidia kernel-drivers available.
- According to the environment.yml, I should install cudatoolkit 10.1.243 and cudnn 7.6.5
- Followed the instruction from cuda installation guide
- At least lspci | grep -i nvidia gave VGA compatible controller: NVIDIA Corporation Device 2204 (rev a1).
- The command gcc -version gave v 9.4.0.
- A sudo apt-get update indicated that several cuda-10.0 packages were automatically installed and no longer needed.
- Strange enough, cat /usr/local/cuda/version.txt gives CUDA Version 11.0.228.
- Had some problems with a broken install of python3.7 which couldn't be fixed. At the end used this answer:
sudo dpkg --remove --force-remove-reinstreq python3.7
sudo dpkg --remove --force-remove-reinstreq libpython3.7-stdlib
sudo apt-get clean
- Continued with how-to.
- The command hwinfo --gfxcard --short gave nVidia VGA compatible controller - Primary display adapter: #16
- The command apt-cache search nvidia-driver showed many drivers, from v384 to 510.
- Seems that sudo apt install nvidia-driver-510 nvidia-dkms-510 is the best option.
-
- First running python3 OxfordRobotCar_visualize_heatmap_false_5m.py
- Result:
al global accuracy = [[0. 0.11778563 0.17667845 0.29446408 0.41224971 0.47114252
0.53003534 0.64782097 0.70671378 0.7656066 0.82449941]]
val local accuracy = [[ 0. 82.74440518 84.21672556 85.74793875 87.5147232 88.63368669
90.34157833 91.10718492 91.87279152 92.93286219 93.58068316]]
- Clearly lower local accuracy (but higher global accuracy)!
- Also visualized this 5m-sampling result:
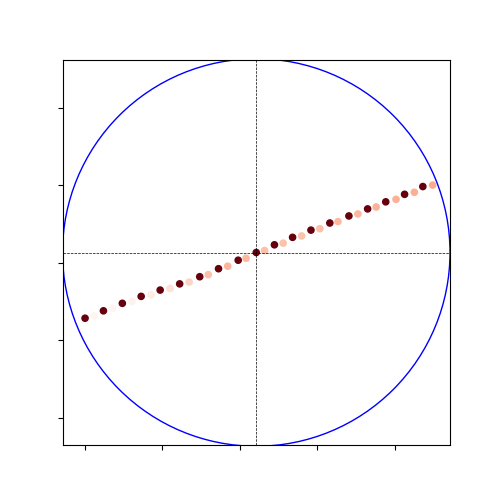
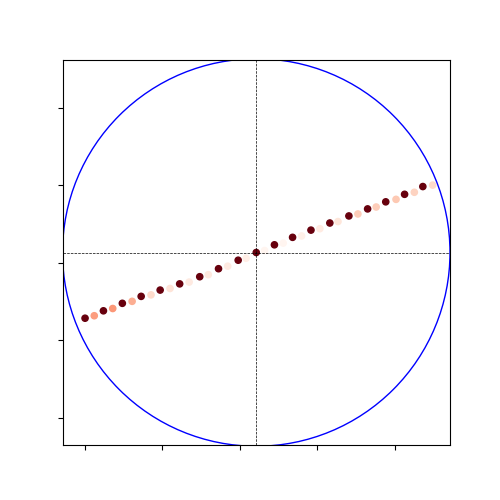
- That is cleary another result than the heatmap of May 20 (with Google-map zoom-20). The sampling is also more dense than the 20m sampling, with the uncertainty distributed along the trajectory.
- Continue with the drivers. sudo apt install nvidia-driver-510 nvidia-dkms-510 indicates that this packages are already installed (via lambda).
- Also when I try to do sudo apt install nvidia-utils-510 (to get nvdia_smi), I receive that the lambda version is already installed.
- Did python3.8 -m pip install --user gpustat, followed by gpustat and got:
NVIDIA GeForce RTX 3090 | 30'C, 0 % | 792 / 24576 MB | gdm(35M) user(156M) user(37M) user(229M)
- Looked in /etc/ld.so.conf.d/cuda-10-1.conf, and no /usr/lib/nvidia is specified. No specific nvidia-driver is available, only an general /usr/lib/nvidia which containts a file which suggests to "The NVIDIA driver provided by Ubuntu can be installed by launching the "Software
& Updates" application, and by selecting the NVIDIA driver from the "Additional
Drivers" tab."
- Used that option, restarted, but still no nvidia_smi (see also April 20). Should also use the correct command nvidia-smi.
May 30, 2022
- The best paper of ICRA created BEV from perspective views with transformers.
- This could both be relevant for my current research, and a nice subject for next year graduates.
- It is paper with code (to be released soon).
- Also read CVPR paper with the title 'the Pedestrian next to the Lamppost'
-
- With the stereo images uploaded (last May 25) to ws10, I try python3 download_satellite_images_sentinel_true_color.py again.
- Using the sentinelhub-py github to get the io_utils call right.
- The script claims it has finished while downloading 1779 images, but actually it only added 81 images to the ~/data/OxfordRobotCar/2015-08-12-15-04-18/satellite_raw directory.
- Let see some results:
- Why is this image black?
- Copied the explore_oxford_area back to nb-dual, to debug.
- The bounding boxes for the request seem to be off, for instance:
98.24000672155654,-151.26135730073517,201.75999327844346,148.73864269926483.
- Let see some results using easting / northing instead of lateral / longitudinal. That looks better:
- The Computer Science building in the center tile, and the Ana Watts building at the lower-left tile can be seen (when you now how to look). Also the Univeristy park in the upper-right tile is visible.
- Also made scripts for false_color and urban.
- False color:
- Urban color:
- Tried to store the cropped images in a separate directory, but this directory stays empty (and satellite is updated). Created wrong directory.
- Started singularity container for tensorflow1.14.2 and run OxfordRobotCar_evaluation_on_false_test_set_sampling_100m.py.
- Result:
test traversal 2 global accuracy = 0.06345177664974619
test traversal 2 local accuracy = 97.46192893401016
- This result is nearly as good as the zoom-16 result of May 16.
- Also visualized this result:
- Same pattern as May 20, so seems to be based on the sampling-strategy.
-
- According to this release blog, the sentinelhub.config can also be edited from the commandline.
- Also interesting seems to be the utilities for larger areas.
May 25, 2022
- Modified the code on ws10 to use a file-name. Yet, it is stored with a date. This example shows how to request multiple time_intervals, but have to find the date I actually get.
- In this example the actual date is requested with request.get_dates().
- Made code for this, but unfortunetly my account is already expired (and my extension not approved yet).
- Created another temporary account based on my TUD account. Stored this information in ~/data/SentinelHub/requests.
- For a WMS request, also a instance_id has to be defined in the configuration, as specified at the sentinelhub configure page.
- If you open up the configuration, you can see the different layers. Changed the WMS to layer TRUE-COLOR-S2L2A, but get_data() fails (wrong bbox)?
- Tried to add a layer "TRUE_COLOR_S2L1C", but that failed because that layer already existed. Replaced the WMS request to ask a L1C layer of the
The latest satellite image from the Betsiboka Estuary was taken on 2017-12-15 07:12:03
- Changing only to the caspian_sea_bbox (and time "latest"), I get:
The latest satellite image from the Caspian sea was taken on 2022-05-25 07:37:23
- With Oxford coordinates I get:
The latest satellite image from Oxford city was taken on 2022-05-24 11:26:44
- Searching for the period of the Oxford RobotCar period I get:
For the period 2014-2015 15 good satellite images from Oxford city area available.
The last good satellite image in this period was taken on 2015-11-12 11:24:29.
- Reduced the maxcc from 0.2 to 0.1, that leaves 2 images:
For the period 2014-2015 2 good satellite images from Oxford city area available.
The last good satellite image in this period was taken on 2015-09-30 11:11:02.
- It seems that these are the L1C images. The oldest L2A image from Oxford is 2016-11-03 (96.8% clouds).
- Visual I like 2016-11-13 (31.6% clouds). The image from 2017-01-02 has 0.0% clouds.
- This image can be found also in the L1C layer:
The last good satellite image in this period was taken on 2017-01-02 11:14:41
.
If I extend the period to 2017-12-31, the image of December 28 is given, with 0.1% clouds, but visually not attractive.
- The recording of December 18 is much better, but still has 8.3% clouds (in 2016-2017 15 good images are available. Reducing maxcc to 0.01 gave 9 images (including Dec 28). Another factor 10 (maxcc=0.001) the 4 dates are left, including 2017-11-06. That has a good cc, but Oxford is only half covered. Same problem with the image from 2017-01-05.
- So I have to select explictly 2017-01-02.
- Modified the code. Should also copy the stereo images from nb-dual to ws10 to get the time-stamps right.
.
May 24, 2022
- With Part-Aware Segmentation, also the back windshields are detected. This could be improve the collision / blocked performance of Maël's algorithm.
- In Self-Supervised Road Layout Parsing Chenyang Lu uses also a student-teacher approach to learn the road layout. As pre-processing he uses a bird-eye view conversion, which also works segmentacly. Is one of is earlier work (with code).
May 23, 2022
- Carnegy Mellon organized earlier this year autonomous racing challenge.
- There is an accomponying workshop at ICML 2022.
- The challenge is based on the OpenAI framework
-
- Searched in the OGC API documentation for how to specify the name of the image output.
- Switched to Sentinel Hub API.
- Possible options are identifier used in the True Color (masked) example.
- Another option is Batch processing, which uses a BucketName (and the use of a grid is also interesting). Should search a tutorial for Batch processing.
- For an individual image request it is possible to give an id-string for the data-input.
- The documentation gives Example 4.1 an example of downloading directoy to disk, but still with its own structure.
- Interesting is also the raw dictonary request (Example 7. Could also look in the utils if not only has plot_image, but also save_img.
- I installed the sentinelhub in ~/.local/lib/python3.8/site-packages. The file api/utils.py is not that informative (just a wrapper which loads other files), so looked into api/process.py.
- According to the documentation, I should be able to specify my own filename for io_utils.write_data()
- Made a third_request, used some print statements (cell 8) from process examples, tried to make a plot and did a write_data at the end with io_utils.write_tiff_image('TrueColor.tiff, image). That worked, I received (same tiff as the jpg fom second_request from May 17)

- The plot_image() comes from utils.py, which is actually not part of the api, but can be found at sentinelhub python examples. That probably works in a Jupyter notebook, nothing shows up when running from the terminal. So, skipped the plot_image call, I just needed a named file.
May 20, 2022
- Zimin published the heatmap visualisation on github.
- Started the tensorflow singularity and launched the jupyter notebook. The data is read from my modified readdata code.
- Had still to install matplotlib and seaborn in this singularity container.
- Had to give the explicit links to ~/data/checkpoints/safa/Models_RAL/OxfordRobotCar/our_model/model.ckpt and baseline/model.ckpt.
- The compute global descriptors is making progress (expect that it runs until 23854 - see March 28). Finished in ~1h.
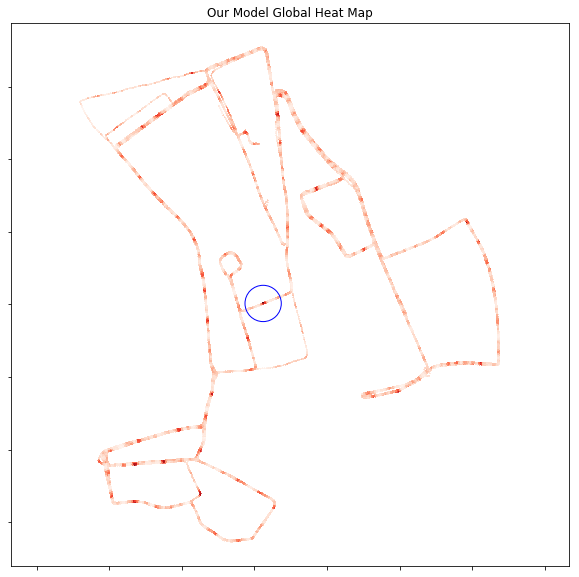
- For our model:
dist_array shape (23854, 1698)
val global accuracy = [[ 0. 48.40989399 52.65017668 54.94699647 56.83156655 58.06831567
59.42285041 61.13074205 62.72084806 64.01648999 65.37102473]]
val local accuracy = [[ 0. 82.50883392 84.7467609 86.3368669 87.63250883 88.39811543
89.16372203 89.87043581 90.51825677 91.401649 91.99057715]]
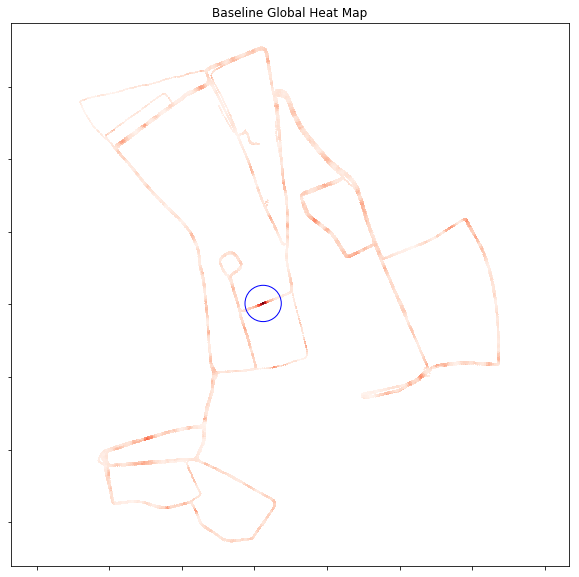
- The baseline gives:
dist_array shape (23854, 1698)
val global accuracy = [[ 0. 75.08833922 78.85747939 81.44876325 82.803298 84.09893993
85.04122497 86.04240283 86.80800942 87.63250883 88.33922261]]
val local accuracy = [[ 0. 78.56301531 82.92108363 85.63015312 86.92579505 88.33922261
89.28150766 90.10600707 90.69493522 91.46054181 92.22614841]]
- The file readdata is also updated, because also the nearest_neighbor is now also stored.
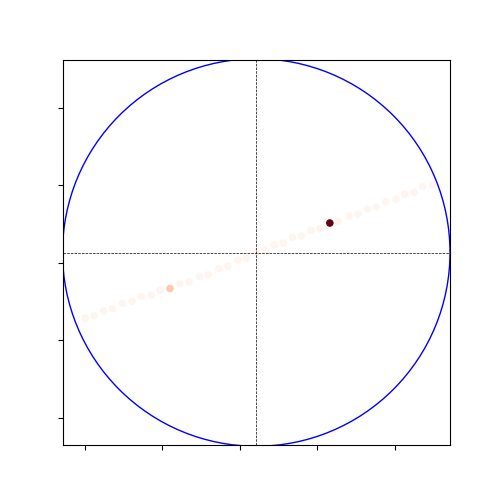
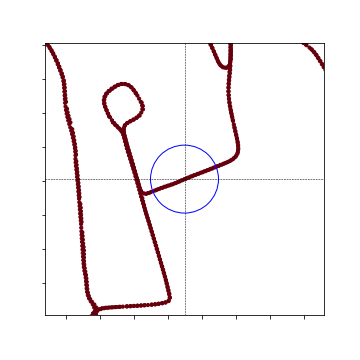
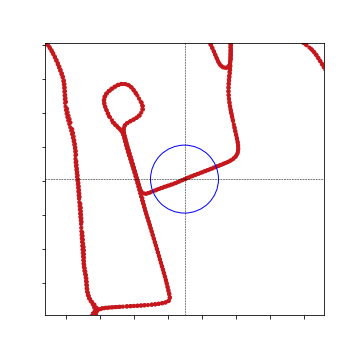
- So, only part of the plots are made (the blue circle is the range specfied by InputData(), which is set ot 50m:
Local Heat Map:
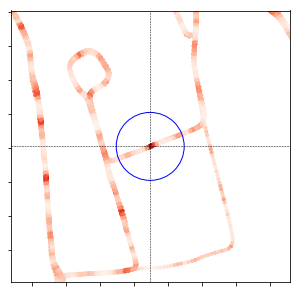
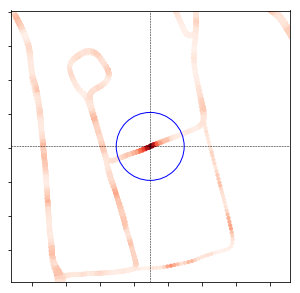
- Note that the savefig doesn't work, it only gives a white image (while the displayed image is OK. Solution suggested is to call show() after the savefig()
- Created a 100m version of that notebook. Note that the InputData gives many warnings because the sampling is 10x as sparse. The positive result is that the accuracy is calculated much faster.
- For the crossview model:
dist_array shape (3285, 1698)
val global accuracy = [[ 0. 10.30624264 10.30624264 10.30624264 10.30624264 10.30624264
10.30624264 10.30624264 10.30624264 10.30624264 10.30624264]]
val local accuracy = [[ 0. 16.90223793 29.03415783 48.93992933 65.37102473 78.38633687
88.22143698 94.99411072 97.87985866 99.64664311 99.94110718]]
- For the baseline:
dist_array shape (3285, 1698)
val global accuracy = [[ 0. 0.11778563 6.18374558 99.46996466 99.58775029 99.58775029
99.58775029 99.58775029 99.58775029 99.58775029 99.58775029]]
val local accuracy = [[ 0. 96.4664311 99.58775029 99.58775029 99.58775029 99.58775029
99.58775029 99.58775029 99.58775029 99.58775029 99.58775029]]
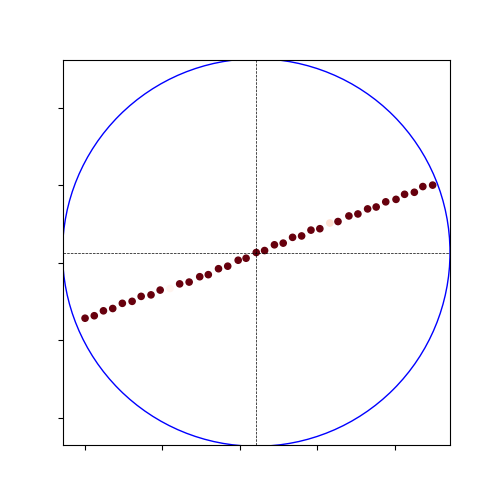
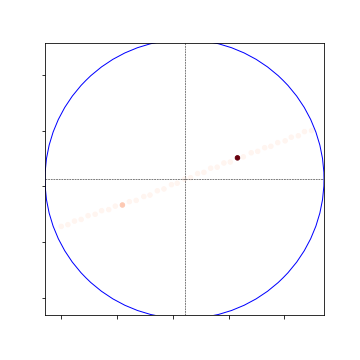
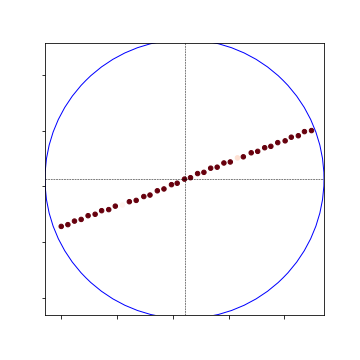
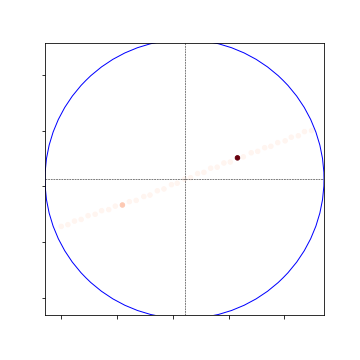
- So, the 100m crossview global heatmap is the same, but locally and nearly the localization is far more sparse:
Global Heat Map:
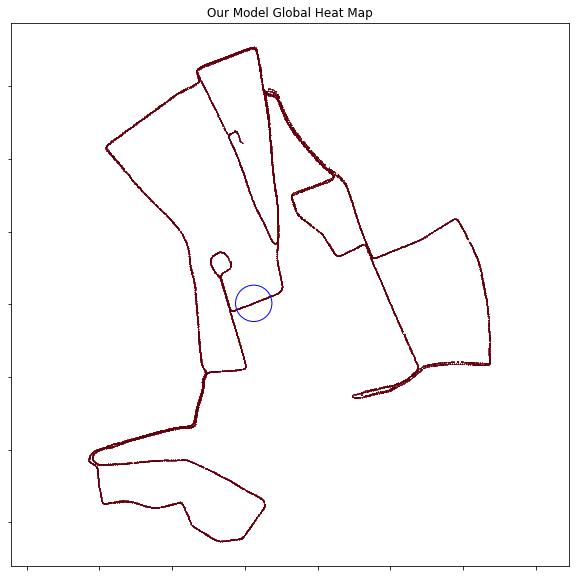
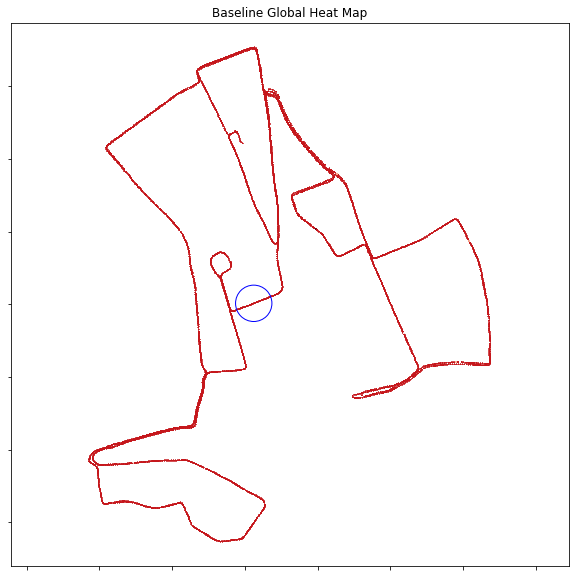
Local Heat Map:
Nearby Heat Map:
- Created a 20m sampling version of the jupyter notebook.
- For the crossview model:
dist_array shape (3285, 1698)
val global accuracy = [[ 0. 0.17667845 10.5418139 10.5418139 10.5418139 10.5418139
10.5418139 10.5418139 10.5418139 10.5418139 10.5418139 ]]
val local accuracy = [[ 0. 16.84334511 29.97644287 49.17550059 64.78209658 77.85630153
87.45583039 94.34628975 97.76207303 99.64664311 99.94110718]]
- For the baseline:
dist_array shape (3285, 1698)
val global accuracy = [[0. 0.11778563 0.29446408 0.53003534 0.64782097 0.7656066
0.88339223 1.00117786 1.00117786 1.11896349 1.23674912]]
val local accuracy = [[ 0. 86.39575972 96.40753828 99.2343934 99.58775029 99.58775029
99.58775029 99.58775029 99.58775029 99.58775029 99.58775029]]
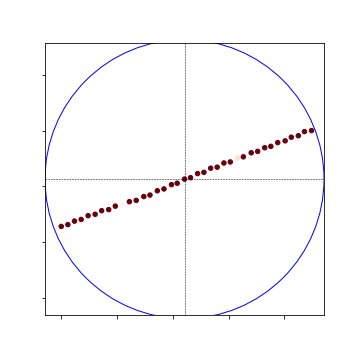
- The results for the 20m crossview look quite the same as the 100m sampling, the difference is mainly the color (more orange than red):
Global Heat Map:
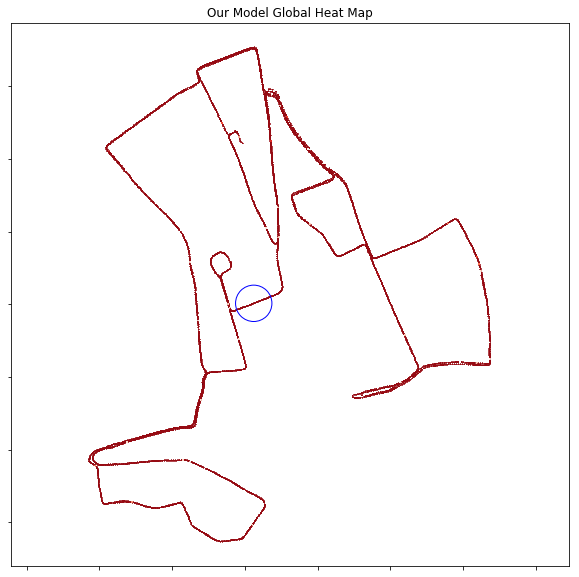
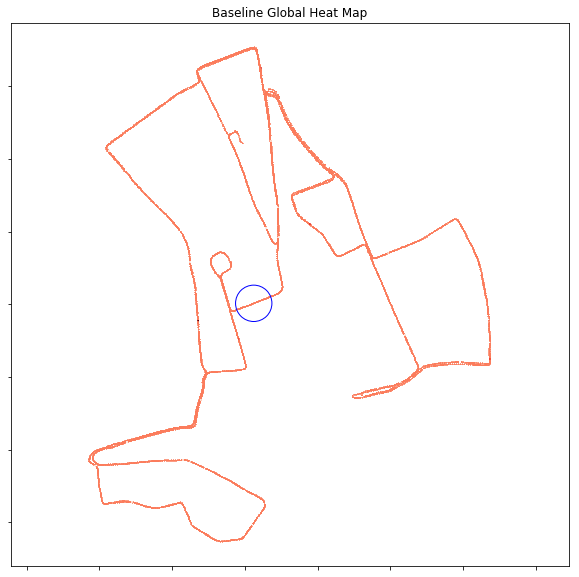
Local Heat Map:
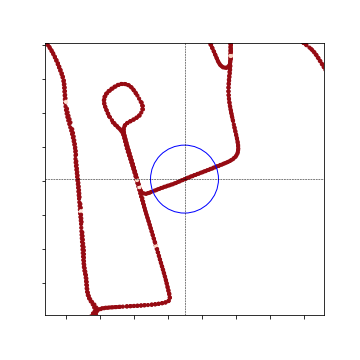
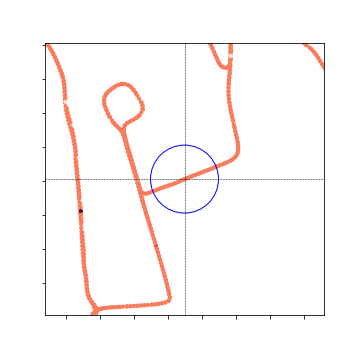
Nearby Heat Map:
- The results for the 5m crossview are now also ready:
Nearby Heat Map:
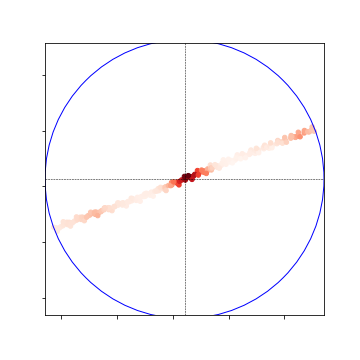
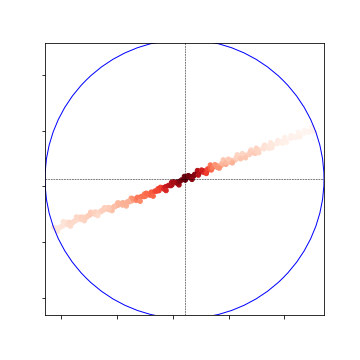
-
- Run my second_true_color_request.py on nb-dual (from ~/data/Oxford_100m_sampling.
- Also python3 download_satellite_images_sentinel_true_color.py works until remaining timestamps 34780.
- Made a first draft of a script that request the sentinel-2 images with a sampling of 100m
May 17, 2022
- Copied the download_satellite_images_zoom16.py from my nb-dual to ws10 (~/data/Oxford_100m_sampling.
- I get nice square images (623x623) if I use the following EPSG:4326 coordinates:
[
-1.2617618655,
51.7595952791,
-1.2572349187,
51.7623993921
]
- That is equivalent with EPSG:32630 (and an area of 312x312m):
[
619964.87372,
5735729.724768,
620277.279486,
5736049.015852
]
- Did python3.8 -m pip install sentinelhub on ws10.
- Made my first request script, which seems to work but returns a tiny black image.
- Requested an larger area (1500x1500m) and added other_args={"dataFilter": {"maxCloudCoverage": 20,"mosaickingOrder": "leastCC"}:
[
620372.6355945842,
5734980.224349831,
620972.6355945842,
5735580.224349831
]
- The result is a 600x600 pixel images on the same location of the last Google-map download (although a little bit more zoomed in):
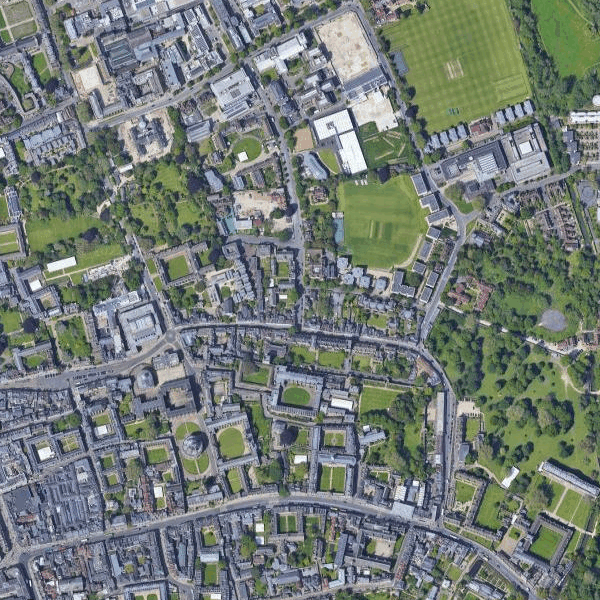
May 16, 2022
- In the zoom16 images there is much more overlap:

- On ws10, started a default tmux session (tmux ls indicated no server was running, after tmux I could do tmux ls in this session, but no other than the default session was visible). Went to /storage and started singularity shell --nv --bind /storage:/storage tensorflow1.14.2.
- Started python3 OxfordRobotCar_evaluation_on_test_set_zoom18.py, which fails because files like 2015-08-17-10-42-18/satellite/619959.8162514124_5735516.305430787.png are not in the datasplits/validation_20m.txt. Should include the fresh made images to this file.
- Made a validation_20m.txt with the first three images in the satellite diroectory. That works, but after that it starts working on the images in test1_txt.
- Only test2 contains files from this date, but even from this one many are missing (sampling 20m instead of 5m).
- Actually, the script also reads the training.txt, so I got a lot of warnings there. training.txt cannot be empty, so put image #4 in this file. Distribution is training 66%, validation 16% and testing 16%.
- Ready with the first run (3 validation images):
test traversal 2 global accuracy = 0.12610340479192939
test traversal 2 local accuracy = 93.63177805800757
- If I compare this with the previous run (April 20), the local accuracy is acutally a little bit better, but the global accuracy dropped from 43% to 0.13%.
- With the additional validation images, the local accuracy improved even further (but the global accuracy remained the same):
test traversal 2 global accuracy = 0.12610340479192939
test traversal 2 local accuracy = 95.20807061790669
- In table II of Cross-View Matching only the local accuracy values are given. That the local accuracy improves with larger sampling (@Recall?!) seems also consistent.
- It would be good to use the visualisation of the assumed positions (See Fig. 7 of the paper) to check the results qualitively.
- Made also a script for the images collected with 100m sampling and zoom-16. The result for this combination is even better (both global and local accuracy):
test traversal 2 global accuracy = 0.31525851197982346
test traversal 2 local accuracy = 97.79319041614124
May 13, 2022
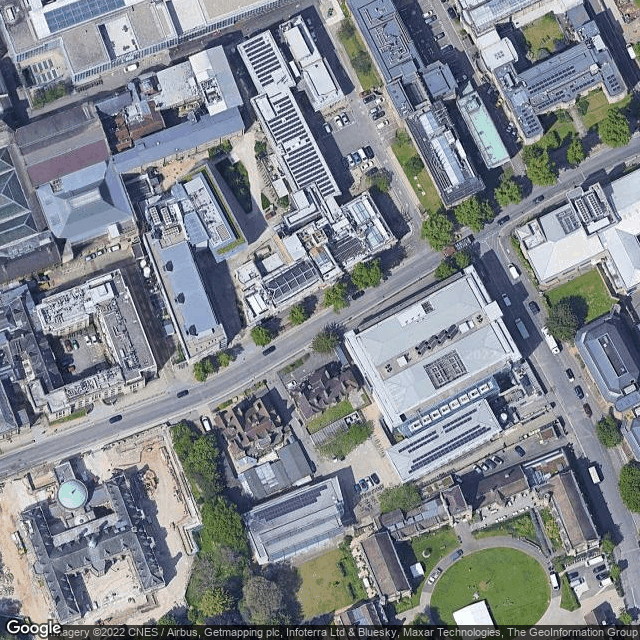
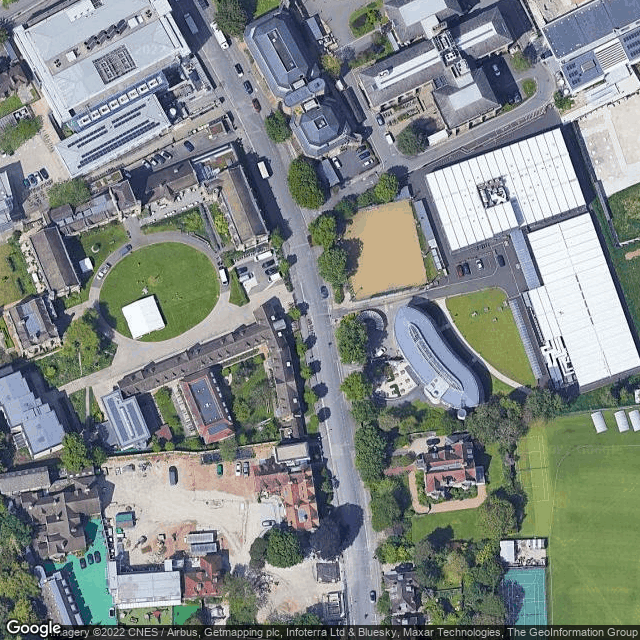
- Checked the extended corners used in the polygon for the request builder in Google maps. The upper-right corner is near the Exeter College Sports Ground, the lower-left corner is near the tennis fields along Thorn Walk, so both still in the University Park.
- Note that you have to close the matplotlib plot before the download script continues. Total timestamps 34838, remaining timestamps 34780
- A direct call to Google maps api failed on missing API key, so checked mapsplatform.
- Got access to Google Cloud console.
- With my API-key, I requested three images at respectively zoom level 16, 18, 20:
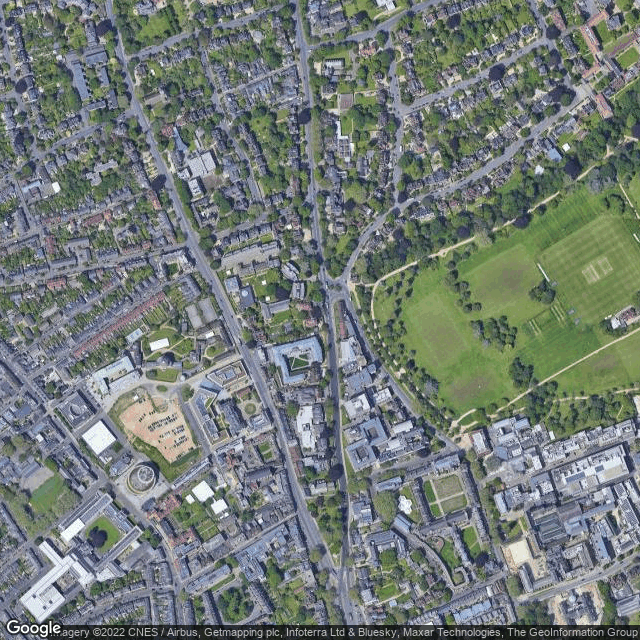


- The download script generates 1709 download requests for 2015-08-12-15-04-18. It fails with the cropping on line 166, because the directory 2015-08-12-15-04-18/ground didn't existed.
- Try the download script again, now with zoom=18 and interval=20m (instead of 5m). The result is 440 download requests.
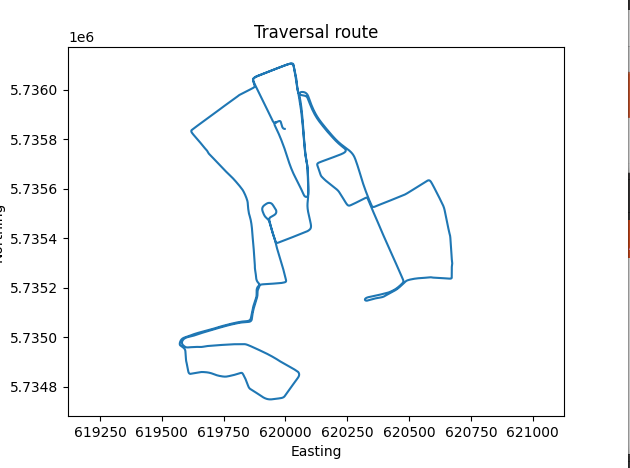
- Compared the traversal route with a rough mosaic which I made manually:
| 57360
|
|
|

|

|
|
|
|
|
| 57358
|
|

|

|

|

|
|
|
|
| 57356
|
|
|

|
|

|
|
|
|
| 57354
|
|
|
|

|

|
|
|
|
| 57352
|
|
|
|

|

|

|

|
|
| 57350
|
|

|
|

|
|
|
|
|
| 57348
|
|

|

|

|
|
|
|
|
|
| 619250
| 619500
| 619750
| 620000
| 620250
| 620500
| 620750
| 621000
|
- That is a mosaic with only 22 images, which is 5% of the total of 440. So there is still quite some overlap.
- Copied the images sampled at interval20 to ~/data/Oxford_20m_sampling/2015-08-12-15-04-18/satellite_raw on ws10.
- Should run data_preparation.py from SAFA to get from satellite_raw to satellite.
- This directory is filled at the end of the download with cropped images, if the directory exists (if not, no warning is given).
-
- Made a new directory, with zoom=16 and interval=100.
- 84 images are downloadedi (excluding one empty one I deleted).
May 12, 2022
- ws10 is in use today, so copied my latest scripts to ws8.
- Also copied 2015-08-12-15-04-18/rtk.csv to ws8.
- The command python3 download_satellite_images.py, although it gives several warnings / errors:
Unable to init server: Could not connect: Connection refused
(download_satellite_images.py:2964108): Gdk-CRITICAL **: 10:38:57.891: gdk_cursor_new_for_display: assertion 'GDK_IS_DISPLAY (display)' failed
['timestamp', 'latitude', 'longitude', 'altitude', 'northing', 'easting', 'down', 'utm_zone', 'velocity_north', 'velocity_east', 'velocity_down', 'roll', 'pitch', 'yaw']
['1439388262802747', '51.7605952791', '-1.2612564167', '111.009598', '5735841.748520767', '619997.1034669734', '-111.009598', '30U', '0.003', '-0.01', '-0.002', '-0.0020995000002143904', '0.004755699999470021', '0.043246099999987624']
totol timestamps 0
remaining timestamps 0
Traceback (most recent call last):
File "download_satellite_images.py", line 74, in
distance = np.sqrt((easting[counter]-easting[0])**2 + (northing[counter]-northing[0])**2)
IndexError: list index out of range
-
- Made a first script with request-builder. Made a first request for a 0.95 km² area at Melbourne avenue, slightly to the west of the CVACT recordings. Specified a 2000x2000 pixels images, but the resolution is not that high:

- A better located 1 km² square is specified with (EPSG:32755):
[
693617.540377,
6088557.214032,
694618.252248,
6089533.875866
]
- Looked up the moment they specified high-resolution in the webinar (around 16 min), but that was for Sentinel-1-grid. Result has only one band (HV), and the resolution is also not high enough for localization. The Sentinel2 images are in that sense more informative, but Sentinel2 has less options (only the cloud-coverage. Yet, in false-color the image is far more informative:



- Selected 1 km² at around Durham's Computer Science building. For EPSG:3857 this is:
[
-175532.803224,
7315348.470972,
-173803.454935,
7317077.851626
]

- The CSR EPSG:4326 looks like the WGS:84 Lon/Lat. Oxford is at least in this coordinate system:
[
-1.260252,
51.746987,
-1.245748,
51.75594
]

- Seems a bit too far to the South, so used the first entry of rtk.csv to select the coordinates more to Oxford-Center:
[
-1.2685,
51.747684779,
-1.2545,
51.756291779
]

- The circular hill of the Oxford Castle Mound is clearly visible near the center of the image.
- Looked at the rtk.csv. The longitude ranged from [-1.2617618655,-1.2516349187], the latitude from [51.7605952791,51.7629693921], which is an area of 0.18 km² centered at the University Parks:
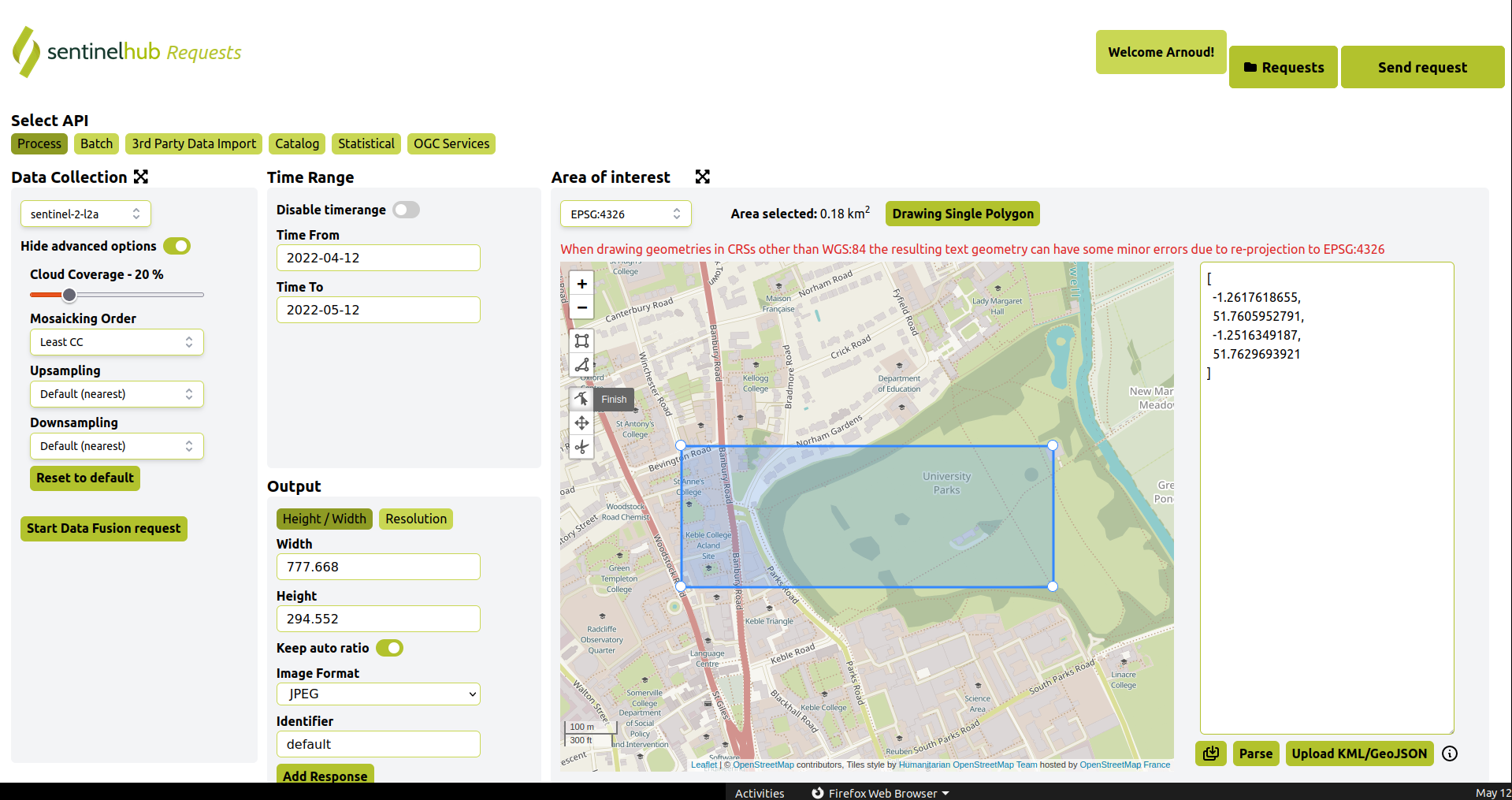
- Used the median to zoom at a factor 2 (0.74 km²):
- With this false color one the Oxford one should localize the 2015-08-12-15-04-18 trajectory:



- Actually, the median is not the center. Best to use extend the max/min with half the difference (third option above):
[
-1.2668253389,
51.7594082226,
-1.2465714453,
51.7641564486
]
- The bright white square next to large brown oval is Anna Watts building, the smaller white rectangle close to the University Park is the Information Engineering building.
-
- Looked at the download-script. It reads a list of timestamps from the directory +date+/stereo/centre.
- The traversal of 2015-08-12-15-04-18 is 64.1 Gb, which still fits on my nb-dual partition (144 Gb free space). 2h download.
- The script downloads for each timestamp an image from Google maps, with a minimal distance of 5m. This is with final_index_list in easting_final, northing_final and timestamp_final.
- It starts with creating a plot (first warning of the day):
- Yet, the route goes much further than the University Park.
- The northing, eastling corresponds to UTM30, which is EPSG:32630.
- Yet, also the min-max of the plot corresponds a drive along Parks Road, while the shape of the trajectory is much larger (Park road only the curve next the the triangle of Banbury Road and Woodstock Road.
- If I have to drawn the polygon, I get an area of 3.34 km², with
[
619070.929422,
5734583.428212,
621206.722089,
5736200.172315
]
- The corresponding satellite image (False color with 1 pixel is one meter):

May 11, 2022
- Watching the API request webinar.
- Requests can be interactive build and checked with request-builder page.
- In this request-builder you can also select cloud-coverage, see the available dates, select high-resolution, selecte the orthorectification.
- Third part of the webinar is on python interface, which can be installed with pip install sentinelhub.
- This jupyter notebook example is explained in the webinar, which shows how to build a SentinelHubRequest in python.
- Note that there is also webinar on Commercial data.
- At the end of the webinar she shows a data-fusion example not in the examples. It is a minimal notebook, which uses a (python)request created in the builder, using a custom script to merge Sentinel-1 and Sentinel-2 images based on a script in custom scripts.
May 10, 2022
- Tried to Request in another image in the southern hemisphere, based on the CVACt training list. Yet, my token was expired. Refreshed and requested an image with 3-number +/- 1:

- Although I asked for a resolution of 512x512, the result is quite pixelated. Yet, the straight line above the water could be the A23 motorway.
- Tried to zoom out (1-st number +/- 1), but received "Your request of 3906.25
meters per pixel exceeds the limit 1500.00 meters per pixel of the collection S
2L2A. Please revise the resolution"
- Zoomed 3x less, (2nd number +/- 3), which gave:

- The grey oval at the right could be Lake George.
- Also received the rtk.csv of the Oxford 2015-08-12-15-04-18 recordings.
- Downloading a Sentinel image (zoomed 2nd number) gave:

- Is this an image recorded at night?
- Looked at a good view in the EO browser and downloaded a Sentinel image from 16 March 2022 (zoomed 2nd number):

- Same problem, so try another CRS?
- Google uses WGS84 / Pseudo-Mercator (webstandard), so I tried WGS84:

- Still black!
May 9, 2022
- Looked up the download script. The maps are downloaded with zoom 20.
- Started on ws8 singularity shell --nv --writable tensorflow1.14.2, Note that I get several warnings related with the nvidia-drivers:
WARNING: nv files may not be bound with --writable
WARNING: Skipping mount /etc/localtime [binds]: /etc/localtime doesn't exist in container
WARNING: Skipping mount /usr/bin/nvidia-smi [files]: /usr/bin/nvidia-smi doesn't exist in container
- Note that outside the container, /usr/bin/nvidia-smi does exists, and that the sandbox was created without the option --nv --bind /storage:/storage, so adding the bind option gives a fatal error:
FATAL: container creation failed: mount /storage->/storage error: while mounting /storage: destination /storage doesn't exist in container
- Inside the singularity tensorflow1.14.2 sandbox the script ~/projects/autonomous_driving/tf_test.py works, but get the error that device:GPU:0 is not an available device.
- Running in this container python3.5 -m pip install matplotlib (and pyproj, but still python3.5 download_satellite_images.py fails on from robotcar_dataset_sdk.python.image import load_image.
- Cloned robotcar-dataset-sdk from github and created a link with underscores: ln -s ../../../robotcar-dataset-sdk robotcar_dataset_sdk.
- Installed python3.5 -m pip install colour-demosaicing, which gave v0.1.5. python3.5 -m pip install libopencv gave v0.0.1 (while 3.4.2 expected). Yet, no candidate for opencv itself, so import cv2 fails.
- So, exit from singularity, and run the download script from the bash-shell. After installing python3.8 -m pip install colour_demosaicing the script works, although fails on the path_to_dataset. Unfortunatelly, the OxFordRobotCar dataset is not downloaded on ws8 (yet).
- Switched to ws10. Running the download script with python3.6 and python3.7 failed, but with python3.8 I get the path_to_dataset error again. Solved that, but still need the rtk.csv file with the ground-truth locations.
-
- Reading Sentinel Hub API documentation.
- With a slide modication (adding client_id=client_id, the authentication example from authentication documentation works (after creating a new client).
- The example code in this example gives for the python-code no error nor an image:works for the curl example

- Yet, in the request the only parameter is a bounding box, not clear what is requested.
- Should watch this webinar.
- An example of an request for Sentinel L2A can be found in the documentation.
- Running this example fails on You are not authorized - failed to parse accessToken. That was an incomplete paste-error. With the right token, I got the warning to add --output to the curl command. With that I received a true_color.png:

- The request of an image can be given in a number of coordinate systems, including UTM northern hemisphere.
- Requested in an image in the southern hemisphere, based on the CVACt training list. Requested an image with 2-number +/- 1:

May 8, 2022
- My training terminal was gone, so not clear how the session ended.
- Rebooted, and nvidia-smi is finally working.
- Had some trouble to startup tmux (server not running, session cvact_training not known), but resurrect worked.
- Started training, but the script still doesn't see the GPU.
- Followed the tricks from stackoverflow, but when I uninstall tensorflow several other essential sub-packages are no longer available, including test and python to print the devices.
- Run the simple multiplication script from post, but that gives:
Cannot assign a device for operation MatMul: node MatMul (defined at :4) was explicitly assigned to /device:GPU:0 but available devices are [ /job:localhost/replica:0/task:0/device:CPU:0, /job:localhost/replica:0/task:0/device:XLA_CPU:0 ]. Make sure the device specification refers to a valid device. The requested device appears to be a GPU, but CUDA is not enabled.
- How do I enable CUDA?
- This nvidia post nicely describes my problem, but solves it with a conda install.
May 7, 2022
- The training on the CVACT continues. With only CPU the computer is still on epoch 0 after 14h training:
global 4840, epoch 0, iter 4840: loss : 0.009716358036
global 4860, epoch 0, iter 4860: loss : 0.010471209884
global 4880, epoch 0, iter 4880: loss : 0.010441813618
global 4900, epoch 0, iter 4900: loss : 0.003601055359
global 4920, epoch 0, iter 4920: loss : 0.015025936067
global 4940, epoch 0, iter 4940: loss : 0.004364710767
global 4960, epoch 0, iter 4960: loss : 0.005539384671
global 4980, epoch 0, iter 4980: loss : 0.007410933264
global 5000, epoch 0, iter 5000: loss : 0.004078543745
global 5020, epoch 0, iter 5020: loss : 0.031947154552
global 5040, epoch 0, iter 5040: loss : 0.028347223997
global 5060, epoch 0, iter 5060: loss : 0.012523281388
global 5080, epoch 0, iter 5080: loss : 0.015310260467
global 5100, epoch 0, iter 5100: loss : 0.002235709690
global 5120, epoch 0, iter 5120: loss : 0.021380070597
- In the bash-shell both cuda-11.4 (for tensorflow 2.8.0) and cuda-8.0 (for tensorflow-gpu 1.4.0) are available. Currently cuda-11.4 is used (while the Visual Localization needs tensorflow-gpu 1.4.0).
- Training will continue for 100 epochs, equivalent with at least 50 days.
- Installed tmux and tmux-resurrect. Started a new shell with the modified bashrc.
- Also with cuda-8.0 I have no nvidia-smi (while I get the correct nvcc).
- First did ubuntu-drivers devices. The recommended distro was nvidia-driver-510. Continued with sudo ubuntu-drivers autoinstall. A new kernel is build, which fails on binary package evdi: 1.7.0. Should reboot (will wait till the first epoch is finished).
- At least I now have /usr/bin/nvidia-smi, although without reboot it fails to communicated with the NVIDIA driver.
- Still in epoch 0:
global 5200, epoch 0, iter 5200: loss : 0.003182847518
global 5220, epoch 0, iter 5220: loss : 0.012785296887
global 5240, epoch 0, iter 5240: loss : 0.011000460014
global 5260, epoch 0, iter 5260: loss : 0.011926879175
global 5280, epoch 0, iter 5280: loss : 0.011231496930
global 5300, epoch 0, iter 5300: loss : 0.006225762889
global 5320, epoch 0, iter 5320: loss : 0.007265931927
global 5340, epoch 0, iter 5340: loss : 0.004800611176
global 5360, epoch 0, iter 5360: loss : 0.003130325116
global 5380, epoch 0, iter 5380: loss : 0.001038473565
global 5400, epoch 0, iter 5400: loss : 0.007879640907
global 5420, epoch 0, iter 5420: loss : 0.011283985339
global 5440, epoch 0, iter 5440: loss : 0.002208672231
global 5460, epoch 0, iter 5460: loss : 0.007409145124
global 5480, epoch 0, iter 5480: loss : 0.003927943762
global 5500, epoch 0, iter 5500: loss : 0.009880952537
global 5520, epoch 0, iter 5520: loss : 0.011097472161
global 5540, epoch 0, iter 5540: loss : 0.007695545442
global 5560, epoch 0, iter 5560: loss : 0.027583824471
global 5580, epoch 0, iter 5580: loss : 0.006925755180
global 5600, epoch 0, iter 5600: loss : 0.014283886179
global 5620, epoch 0, iter 5620: loss : 0.001369873527
global 5640, epoch 0, iter 5640: loss : 0.002840146655
...
global 7580, epoch 0, iter 7580: loss : 0.002239986090
global 7600, epoch 0, iter 7600: loss : 0.003855952993
global 7620, epoch 0, iter 7620: loss : 0.015516944230
global 7640, epoch 0, iter 7640: loss : 0.003552810289
global 7660, epoch 0, iter 7660: loss : 0.006517179310
global 7680, epoch 0, iter 7680: loss : 0.001818520017
...
global 7760, epoch 0, iter 7760: loss : 0.008099196479
global 7780, epoch 0, iter 7780: loss : 0.001813498558
global 7800, epoch 0, iter 7800: loss : 0.005605282262
global 7820, epoch 0, iter 7820: loss : 0.001660879585
global 7840, epoch 0, iter 7840: loss : 0.004508224782
global 7860, epoch 0, iter 7860: loss : 0.005950352177
global 7880, epoch 0, iter 7880: loss : 0.001458604820
global 7900, epoch 0, iter 7900: loss : 0.002336486010
global 7920, epoch 0, iter 7920: loss : 0.000774102635
global 7940, epoch 0, iter 7940: loss : 0.001072773011
global 7960, epoch 0, iter 7960: loss : 0.003783047898
global 7980, epoch 0, iter 7980: loss : 0.001079021022
global 8000, epoch 0, iter 8000: loss : 0.002549976343
Model saved in file: /media/./DATA1/projects/autonomous_driving/checkpoints/safa/Models_RAL/CVACT/100baseline/0/model.ckpt
validate...
compute global descriptors
May 6, 2022
- Running on ws10 goes to slow (without GPU), so first look if I could reproduce the results on XPS9370.
- Last run on XPS9370 seems to be March 29. In the mean time, the system has been upgraded to Ubuntu 22.04.
- The regular python3 version on the XPS9370 is now python 3.10.4, but python3.7 (version 3.7.10) is also still installed. Yet, ~/.local/bin/jupyter still points to python3.9, which is not installed. Changed that to script to python3, which starts a session (but fails on the permissions in ~/.local/share/jupyter/runtime.
- The import of CVACT_training_validation_baseline works with python3.7.
- CVACT.tar.gz was not extracted yet on XPS9370, so had to do that first. The location of the data and the model is defined only twice in the script.
- Used Models_RAL for model_root. System starts, although also here it seems that the cpu is used. System also has nvidia_smi, so the nvidia toolbox has to be reinstalled:
global 0, epoch 0, iter 0: loss : 0.754099249840
global 20, epoch 0, iter 20: loss : 0.336143672466
global 40, epoch 0, iter 40: loss : 0.376497507095
global 60, epoch 0, iter 60: loss : 0.251185119152
.
- Note that on February 23 I was still using python2 to run the cityscapes code.
- Have to find in my notes which version of nvidia toolbox I have to install.
May 4, 2022
- The training of Oxford still going strong, the process is this morning at epoch 133:
global 40385, epoch 133, iter 300: loss : 0.00777297
- The download of the dataset for STEGO is now finished:
Downloading potsdam
100% [................................................] 1034169614 / 1034169614
Downloading cityscapes
100% [..............................................] 63189289453 / 63189289453
Downloading cocostuff
100% [..............................................] 41507380637 / 41507380637
Downloading potsdamraw
100% [..............................................] 18608451086 / 18608451086S
- The End-to-End pipeline illustration cannot be found in Pei Sun's CVPR 2020 paper. Maybe it was used in the presentation.
- Found a high resolution version at this survey. It gives credits to most of the figures, except this one. Yet, I replace the courtesy to Ardi Tampuu Yet, I replace the courtesy to Ardi Tampuu
- ws10 will be used for Optitrack experiments, so I will have to reboot.
- Current state:
global 40728, epoch 135, iter 40: loss : 0.01226962
global 40748, epoch 135, iter 60: loss : 0.00689032
global 40768, epoch 135, iter 80: loss : 0.03589888
global 40788, epoch 135, iter 100: loss : 0.01933584
- Installed tmux-resurrect and saved it with Ctlr-b Ctrl-s. With Ctr-b Ctl-r I should be able to restore.
- Read A boom with a view article, which highlights the latest developments in earth observation. The author (from SkyWatch), indicates that there are three possibilities to download images with an API: SkyWatch EarthCache, Airbus UP42 and Sentinel Hub.
May 3, 2022
- The training of Oxford still going strong, the process is this morning at epoch 123.
- Found config/eval_config.yml in ~/git/STEGO/src. Changed in the config pytorch_data_dir to /storage/./data/STEGO. Download has started.
- Potsdam is 1 Gb, cityshapes seems to be 60 Gb. At least much more than the sorted subset I downloaded earlier.
- Download is frozen halfway:
Downloading potsdam
100% [................................................] 1034169614 / 1034169614
Downloading cityscapes
51% [....................... ] 32599195648 / 63189289453
- Only 32% of the storage is used, try again. At the end of the day cityshapes is downloaded, continues with cocostuff (also 40 Gb).
- Next epoch is 124:
global 37616, epoch 124, iter 240: loss : 0.02085444
global 37636, epoch 124, iter 260: loss : 0.01696338
global 37656, epoch 124, iter 280: loss : 0.01440101
- Found the Analytical download tab from the eo-browser. Downloaded high-resolution georeferenced jpg and tiffs.
- Installing sudo apt install qgis qgis-plugin-grass to visualize georeferenced images.
- The georefenced jpg and tiff are as good in resolution (although I liked the Pleiades better). Could also download raw data from the different bands.
- The oxford_training code uses for satellite_raw PNG image data, 640 x 640, 8-bit colormap, non-interlace and satellite PNG image data, 600 x 600, 8-bit/color RGB, non-interlaced.
- It seems that Google map are Landsat 8 satellites. Both Landsat 8 and 9 images should be available from the eo-browser, but no results are found. Yet, according to sentinel-hub the resolution is 15 m for the panchromatic band and 30 m for the rest (the thermal bands is re-sampled from 100 m)
- As this post indicates, Google combines several satellite sources, with Spot, Pleiades and WorldView providing the highest resolution. For even higher resolution aerial photography.
- PlanteScope has also NIR (resampled to 3m resolution).
- Spot has 1.5m for the panchromatic band and 6 m for all other bands.
- WorldView provides supports 0.5 m for panchromatic band and 2 m for multispectral bands.
- Pleiades has the same resolution: 0.5 m for panchromatic band and 2 m for all other bands
- If I look at Durham University, Google gives credits to Landsat / Copernicus at a height of 3357m (200 m / cm)
- At half this height 1496m (100 m / cm), the credits go to Getmapping, Infoterra, Bluesky and Maxar Technlogy. Maxar indicates WorldView.
- Getmapping has images from 2019 and earlier. A picture of 100m x 100m would cost 20 pounds, 500m x 500m 47 pounds, 1 km x 1 km 81 pounds, 2km x 2km 135 pounds, 5km x 5km 650 pounds,
- Getmapping has images from 2019 and earlier. A picture of 100m x 100m would cost 20 pounds, 500m x 500m 47 pounds, 1 km x 1 km 81 pounds, 2km x 2km 135 pounds, 5km x 5km 650 pounds.
- Infoterra is a a ESA-firm which represents Spot images.
- Bluesky has both 12.5cm and 25cm Aerial Photo's, and 50cm infrared (218 pounds for 5km x 5km).
- Bluesky also has NVDI (quite old: 2006) and a Tree Map layer (also before the construction of the Computer Science building).
- RQ1: How good does the Visual-Localization-with-Spatial-Prior work with the highest resolution satellite images (so not aerial images)?
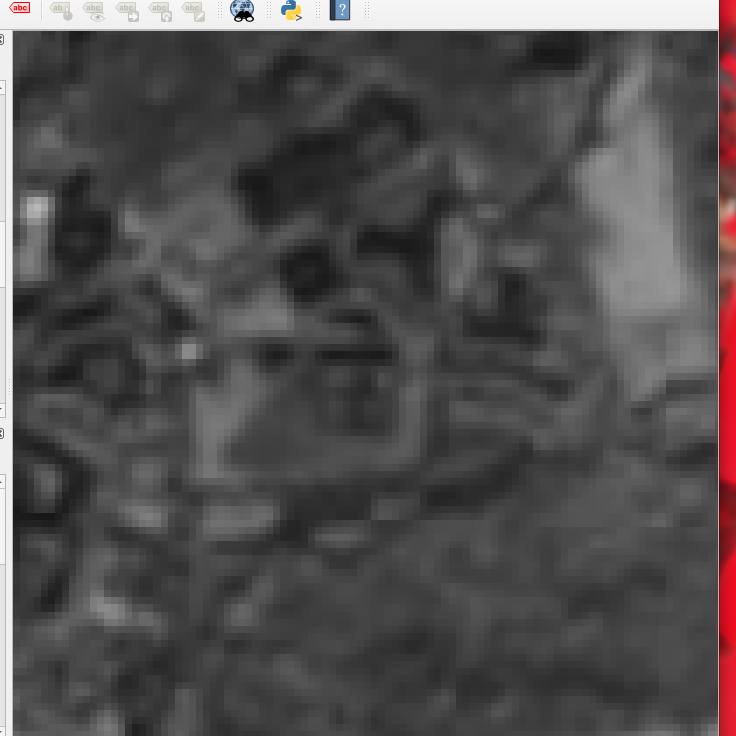
- RQ2: Which raw band matches best with the Oyster images?
- Answer RQ2, the B08 bands seems the most informative. Yet, even on the highest resolution it is nearly impossible to localize the Computer Science building (square in the center of the image):
- This are the different bands:



Band B01 (aerosol 442 nm) Band B02 (blue 492 nm) Band B03 (green559 nm) (usefull to detect clouds)



Band B04 (red 665 nm) Band B05 (far red 704 nm) Band B06 (far red 740 nm) (starting to give details)



Band B07 (far red 780 nm) Band B08 (NIR 833 nm) Band B8A (narrow NIR 864 nm) (all with details)



Band B09 (water vapour 945 nm) Band B11 (SWIR 1610 nm) Band B12 (SWIR 2202 nm) (darker again)
- See Sentinel hub for details of the bands. Note that the red and far red seem to be very informative, yet the far red bands B05-B07 have 2x lower resolution (20m) than B04 and B08 (10m).
- The reflective channel of Oyster sensor of the Durham channel is recorded with a laser with 865 nm wavelength (corresponds with B8A). The ambient channel records 800 - 2500 nm (B07/B08 and higher)
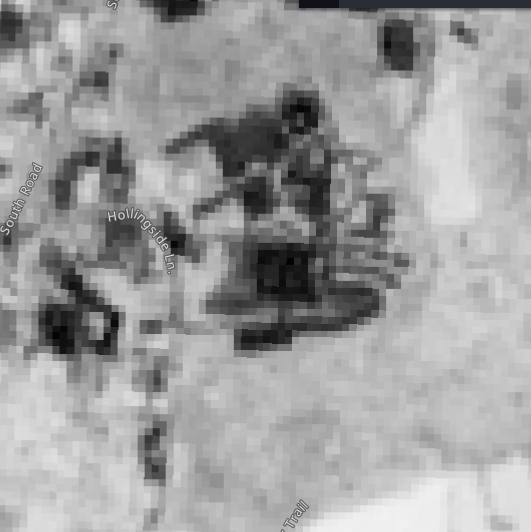
- Used a custom script (B08-B04) which makes the Computer Science building quite distinctiable. It is inspired by NDVI, which does the same, but applies that formula on the green channel.:
function evaluatePixel(sample) {
return [(sample.B08-sample.B04)/(sample.B08+sample.B04),(sample.B08-sample.B04)/(sample.B08+sample.B04), (sample.B08-sample.B04)/(sample.B08+sample.B04), sample.dataMask];
}
- The B8A-B4 works nearly as good:
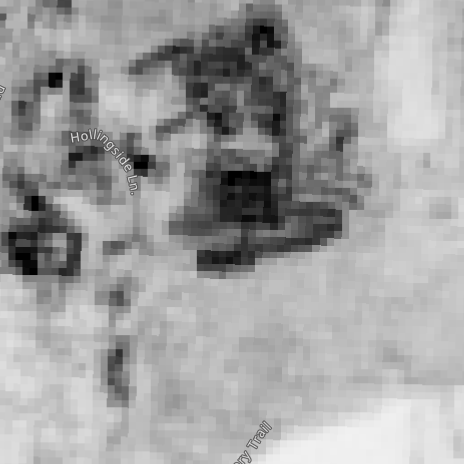
- When I use B8A-B1 I get lower resolution.
- Tried a combination (B08+B8A-2*B4). Works also fine. Next combination (B08+B8A-B3-B4) is also good. The combination (B08+B8A+B11-B3-B4) works:

but making it (B08+B8A+B11-B2-B3-B4) makes the whole image black.
- Actually, the NDVI script is a bit more complex, creating a look up table with false colours for each value of (B08-B04)/(B08+B04). Changing the highest values (val>=-.7) from (0,0.27,0) to (0,0.027,0) changes the dark green background to nearly black:
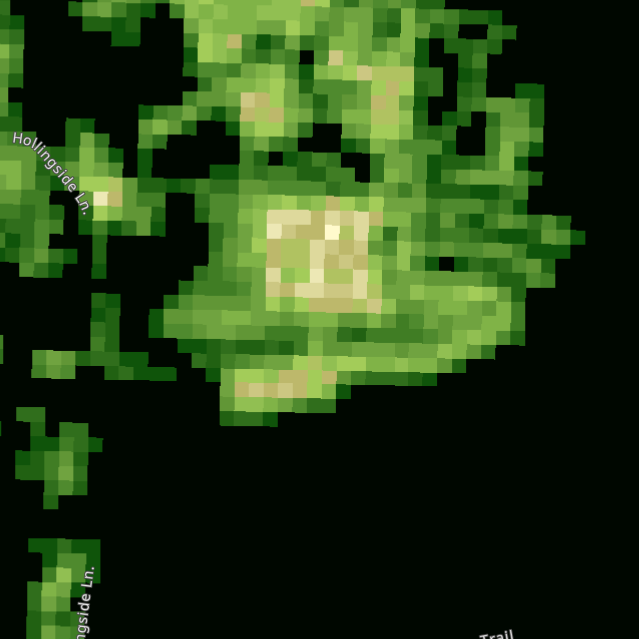
- Note that the NVDI also makes use of the SCL channel, which gives 'Scene classification data, based on Sen2Cor processor, codelist'. There is also a CLD channel, which gives 'Cloud probability, based on Sen2Cor processor'. Both channels have a resolution of 20m.
May 2, 2022
- The training of Oxford still going strong, the process is this morning at epoch 113.
- Continue with the Stego algorithm.
- Started singularity shell --nv --bind /storage:/storage /storage/avisser/singularity-containers/pytorch_cuda110/.
- On April 26 I downloaded the models (in ~/git/STEGO/models and ../saved_models).
- Specified export pytorch_data_dir=/storage/./data/STEGO, but this value is overruled by hydra by the value /datadrive in config/eval_config.yml. Couldn't find this config so fast.
April 28, 2022
- The training of Oxford still continues, the process in now at epoch 70:
global 21098, epoch 70, iter 0: loss : 0.06216348
global 21118, epoch 70, iter 20: loss : 0.08850121
global 21138, epoch 70, iter 40: loss : 0.09520401
global 21158, epoch 70, iter 60: loss : 0.03318875
global 21178, epoch 70, iter 80: loss : 0.07354280
global 21198, epoch 70, iter 100: loss : 0.1016836
- The number of epochs is set to 1000, so this goes much too slow. Seems that the GPU is really not used.
- The command nvidia-smi still not works, although it is possible to do nvidia-settings -q GPUUtilization -q UsedDedicatedGPUMemory -q NvidiaDriverVersion, which gives:
Attribute 'GPUUtilization' (robolabws10:1[gpu:0]): graphics=10, memory=1,
video=0, PCIe=1
Attribute 'UsedDedicatedGPUMemory' (robolabws10:1[gpu:0]): 24253
Attribute 'NvidiaDriverVersion' (robolabws10:1[gpu:0]): 510.60.02
April 26, 2022
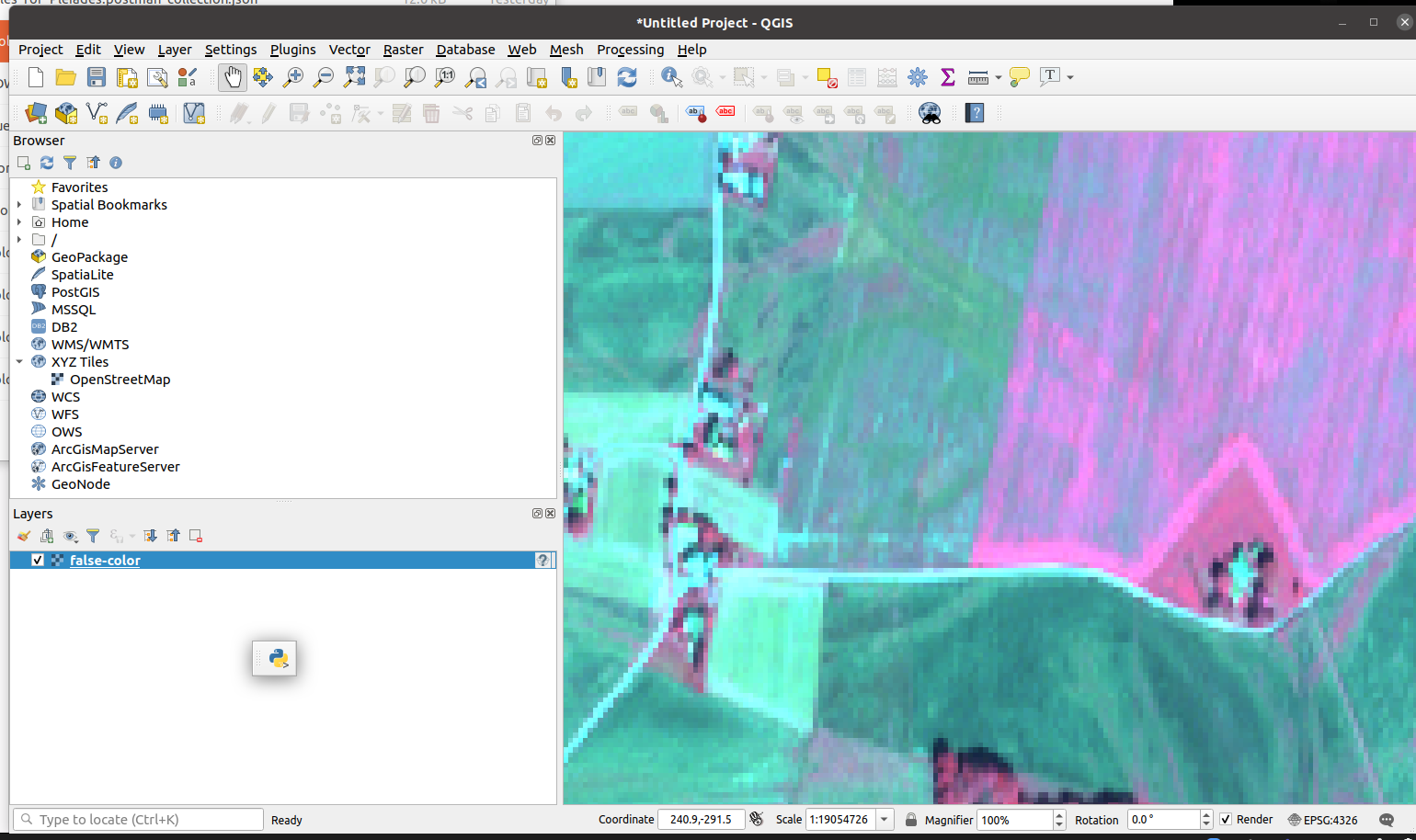
- Load the full 2m resolution image in QGIS, but unfortunetely the image is not georeferenced (getting the small OpenStreetMap world in the top-left corner of the XYZ-tiles).
- The road and roofs are a few pixels wide, which corresponds with 2m resolution. In QGIS the false colours are also displayed not in red tones but in purple tones:
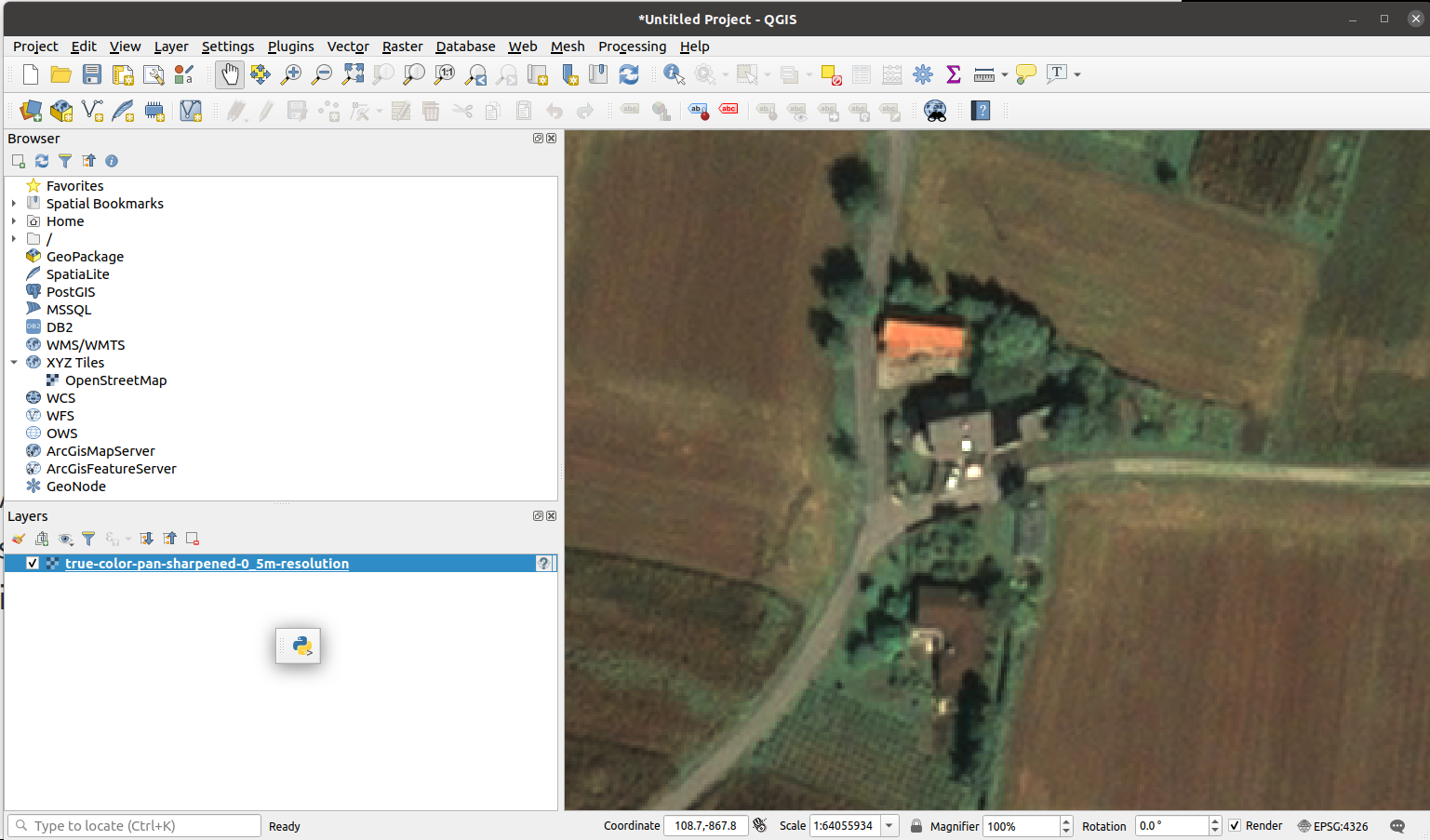
- The road and roofs are a 4x wider in the 0.5m resolution true color:
-
- The Stego algorithm is able to learn segmentation unsupervised, and is actually demonstrated on street-images and satellite images.
- Cloned this repository, and looked into the dependencies. The environment is conda based, with a cuda11.0 base.
- Did a singularity search cuda | grep 11 and downloaded the library image singularity pull library://mbalazs/default/pytorch_cuda110, made a sandbox with singularity build --sandbox --bind /storage:/storage pytorch_cuda110/ ../singularity-images/pytorch_cuda110_latest.sif and started singularity shell --nv --bind /storage:/storage ./pytorch_cuda110/.
- Note that /usr/local/cuda-11.0, so I also could try to make another cuda-choice in my bashrc.
- At least the version of python3 is correct (v3.6.9). Yet, although the name suggest diffently, I couldn't import torch. Also python3 -m pip install pytorch==1.7.1 fails (only v0.1.2 and v1.0.2) available. After updating to pip==21.0 even those are no longer visible.
- Deactivated the singularity container and went back to my regular shell.
- Installed python3.6 (actually 3.6.15) after sudo add-apt-repository ppa:deadsnakes/ppa. Yet, even python3.6 -m pip install --upgrade pip==21.0 fails. It works for python3.7, but also here pytorch fails.
- Downloaded Anaconda3-2021.11-Linux-x86_64.sh and made ~/anaconda3.
- As suggested, I deactivated the base with conda config --set auto_activate_base false. The base can always be activated with conda activate.
- Instead I did in ~/git/STEGO conda env create -f environment.yml. Creating the environment takes quite a while.
- According to this tutorial, I could also have done pip3 install torch==1.7.1+cu110 torchvision==0.8.2+cu110 -f https://download.pytorch.org/whl/torch_stable.html
- In the singularity shell, I actually did python3 -m pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 -f https://download.pytorch.org/whl/torch_stable.html, which seems to work.
- Installed most of the packages in the environment with python3 -m pip, which fails on numpy.
- Yet, installing kornia uninstalls torch-1.7.1 and upgrades to torch-1.10.2 and kornia-0.6.4.
- Installing them combined gives kornia-0.5.11 torch-1.7.1+cu110. Note that numpy==1.19.5 is already fulfilled (<1.20).
- All other could also be installed, so in principal this singularity shell is ready to go (the conda environment is still to be solved).
- Yet, still from modules import * fails on missing torchmetrics. Installed torchmetrics-0.8.0. Now the modules are imported.
- All other packages could be loaded, except the train_segmentation (which is missing pytorch-lightning. Installed v1.5.10.
- Even torch.multiprocessing.set_sharing_strategy('file_system') works, so python3 eval_segmentation.py should work (if the data is there).
- Started with python3 download_models.py (in Singularity shell).
-
- The training on the Oxford dataset is nearly ready:
global 14198, epoch 47, iter 60: loss : 0.09508304
global 14218, epoch 47, iter 80: loss : 0.13754243
global 14238, epoch 47, iter 100: loss : 0.18511596
global 14258, epoch 47, iter 120: loss : 0.19732416
global 14278, epoch 47, iter 140: loss : 0.09276758
global 14745, epoch 48, iter 300: loss : 0.16454245
Model saved in file: ~/data/checkpoints/safa/Model/Oxford/48/model.ckpt
global 14748, epoch 49, iter 0: loss : 0.15571705
global 14768, epoch 49, iter 20: loss : 0.15814728
global 14788, epoch 49, iter 40: loss : 0.21878895
global 14808, epoch 49, iter 60: loss : 0.17262554
global 14828, epoch 49, iter 80: loss : 0.19295573
global 14848, epoch 49, iter 100: loss : 0.25245574
global 15055, epoch 50, iter 0: loss : 0.11302091
global 15075, epoch 50, iter 20: loss : 0.14914204
global 15095, epoch 50, iter 40: loss : 0.07295136
global 15155, epoch 50, iter 100: loss : 0.10538303
global 15175, epoch 50, iter 120: loss : 0.34795767
global 15195, epoch 50, iter 140: loss : 0.15010676
global 15215, epoch 50, iter 160: loss : 0.08782874
global 15235, epoch 50, iter 180: loss : 0.10829046
global 15255, epoch 50, iter 200: loss : 0.09814017
global 15275, epoch 50, iter 220: loss : 0.10137342
global 15295, epoch 50, iter 240: loss : 0.15273197
global 15315, epoch 50, iter 260: loss : 0.07709845
-
- Felix is considering FRNET for segmentation.
- This github page has combined several segmentation algorithms in one Tensorflow/Keras framework.
- This was inspired by Segmentation over the years (2017). According to this post, ResNet is a far superior encoder compared to VGG16 (base of G-FRNET).
April 25, 2022
- This time the tmux session was still running. Used tmux ls to list the active sessions, and attached to the named sessin with tmux a -t training_oxford.
- The training was expected to last 6 days, which corresponds to the current progress (epoch 34/50):
global 10419, epoch 34, iter 180: loss : 0.28576458
global 10439, epoch 34, iter 200: loss : 0.23614410
global 10459, epoch 34, iter 220: loss : 0.41691649
4h later
global 10997, epoch 36, iter 160: loss : 0.56764174
global 11017, epoch 36, iter 180: loss : 0.29048502
2h later
global 11320, epoch 37, iter 180: loss : 0.33825311
global 11340, epoch 37, iter 200: loss : 0.39639008
global 11360, epoch 37, iter 220: loss : 0.22095706
- Accessed my account on sentinel-hub. In my settings they requested to upgrade my account to an ESA sponsored account for research purposes.
- Followed the instructions at Network of Resources
- Called the project 'Cross-View Matching for Vehicle Localization on Infrared Satellite Images'
- The Network of Resources form also indicated the Exploratory option of Pleiades images (2m resolution in NIR).
- To see the Pleiades examples, I first had to activate my free 29 day trail, so that I could create an access token.
- Yet, the curl command gives an internal error: MessageBodyReader not found for media type application/octet-stream. I have the feeling that I am missing some json-libraries.
- There is also a postman example, maybe I should first download the Postman API
- First checking Sentinel's API documentation.
- At least the python example of request-oauthlib works.
- Continue with Postman's authorizing requests.
- Created a free postman account and imported the json file with the Pleiades examples.
- Followed the instruction of
sentinal postman authentication, but still received the message: Couldn't complete OAuth 2.0 login, see Postman console for details. The Console can be found at the bottom of the Postman workspace, which indicates an Illegal secret!}. Copied the secret a 2nd time in its field, now I receive a token.
- For each of the examples I was able to send a request and was able to save the png I received. Storted them on nb-dual in ~/data/pleiades.
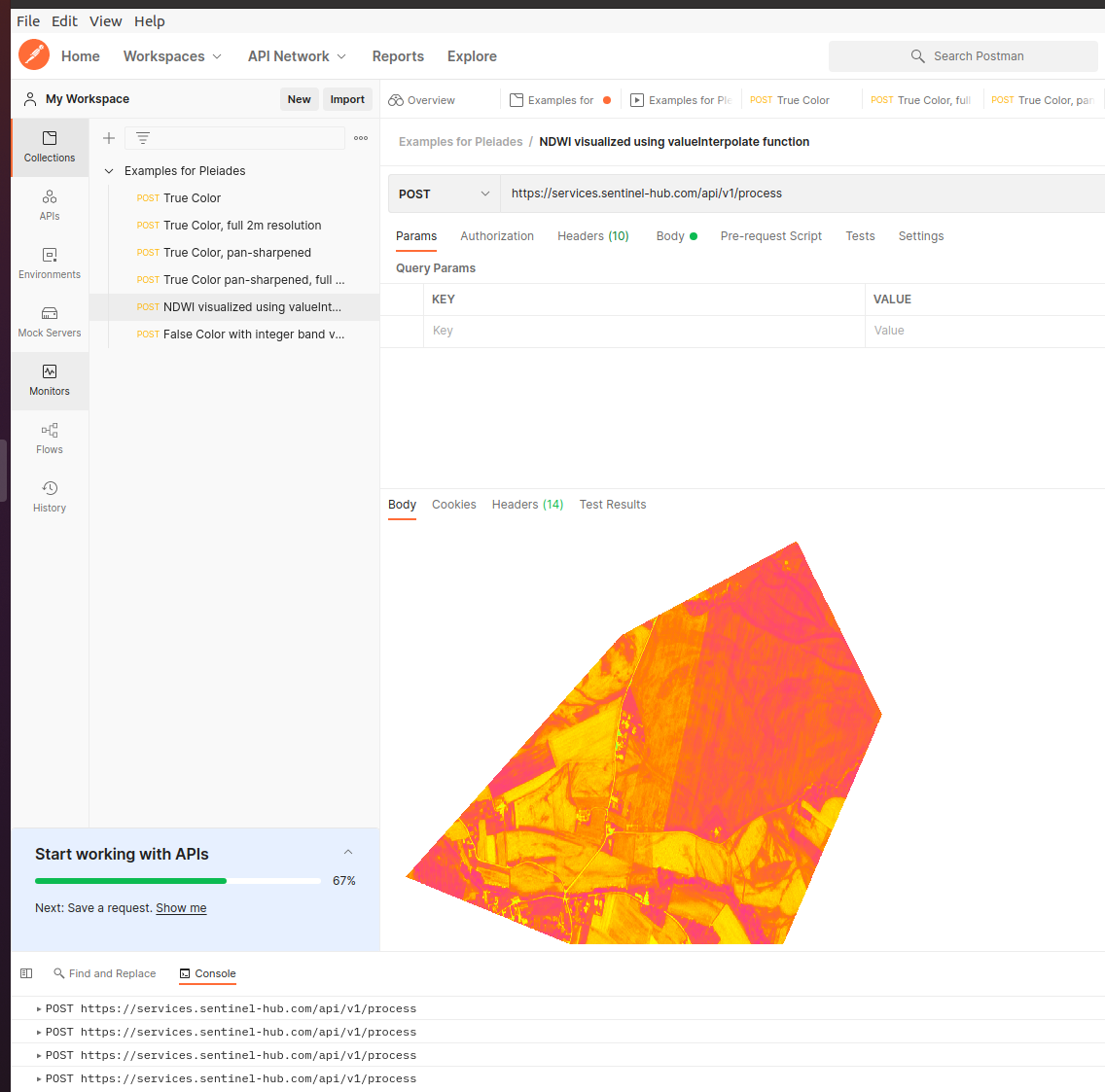
- Detached from my still running training oxford session.
April 22, 2022
- Unfortunatelly, the tmux session that I started yesterday is no longer in the list.
- Should I detach the session to be sure that it safe?
- Started a new session, put the job to the background, detached, attached. Job is still running (according to ps -n, but could bring it just back to foreground (maybe I could have done that with fg %d. Yet, I get the progress prints, so the process is still running (in the singularity shell).
- When I try fg %pid, it says no such job.
- Read this tmux guide. In principal the session should have been still running, so it looks like that ws10 rebooted. That is not the case, last reboot is from April 20. Note that the output of the training is also displayed outside the Singularity session.
- Note that there also exist tmux resurrect, which can restore active sessions after a reboot of the system (when the sessions was saved). See the usage in this tmux tutorial
-
- According to this post the high-resolution IR images should be available via satellietdataportaal
- Yet, in this Source overview, the IR images were not mentioned.
- When I look at infrared composite user story, they mention Superview satellites as source.
- To make other false color combinations, this story points to Sentinel Playground, code-de.org and wekeo.eu.
- The story itself uses a tile from IJmuiden till Limmen.
- The superview data has in NIR a resolution of 2m. The Chinese superview satellite has 4 bands, with B4 (770-890) NIR.
- The other NIR data sources have resolutions of 10m or more.
- The interface of the portal is quite handy, I could easily find my own location, select the last NIR infrared image (Feb 03, 2022).

- Registered an account on this portal. Tried to download a 11bits 50cm RGBI image, which is actually a ZIP-file of 3Gb.
- Download seems to be at location (52.1561605555556,0.0174532925199433)
- Indicated is a box. Low-left is (50.75,3.2) is Tourcoing on the border of France/Belgium. Top-right is Juist (German Waddeneiland next to Borkum).
- Could only open the tif with QGIS.
- The map shows the area around Hulst, in Zeeuws-Vlaanderen 51.2779543,4.0410246:
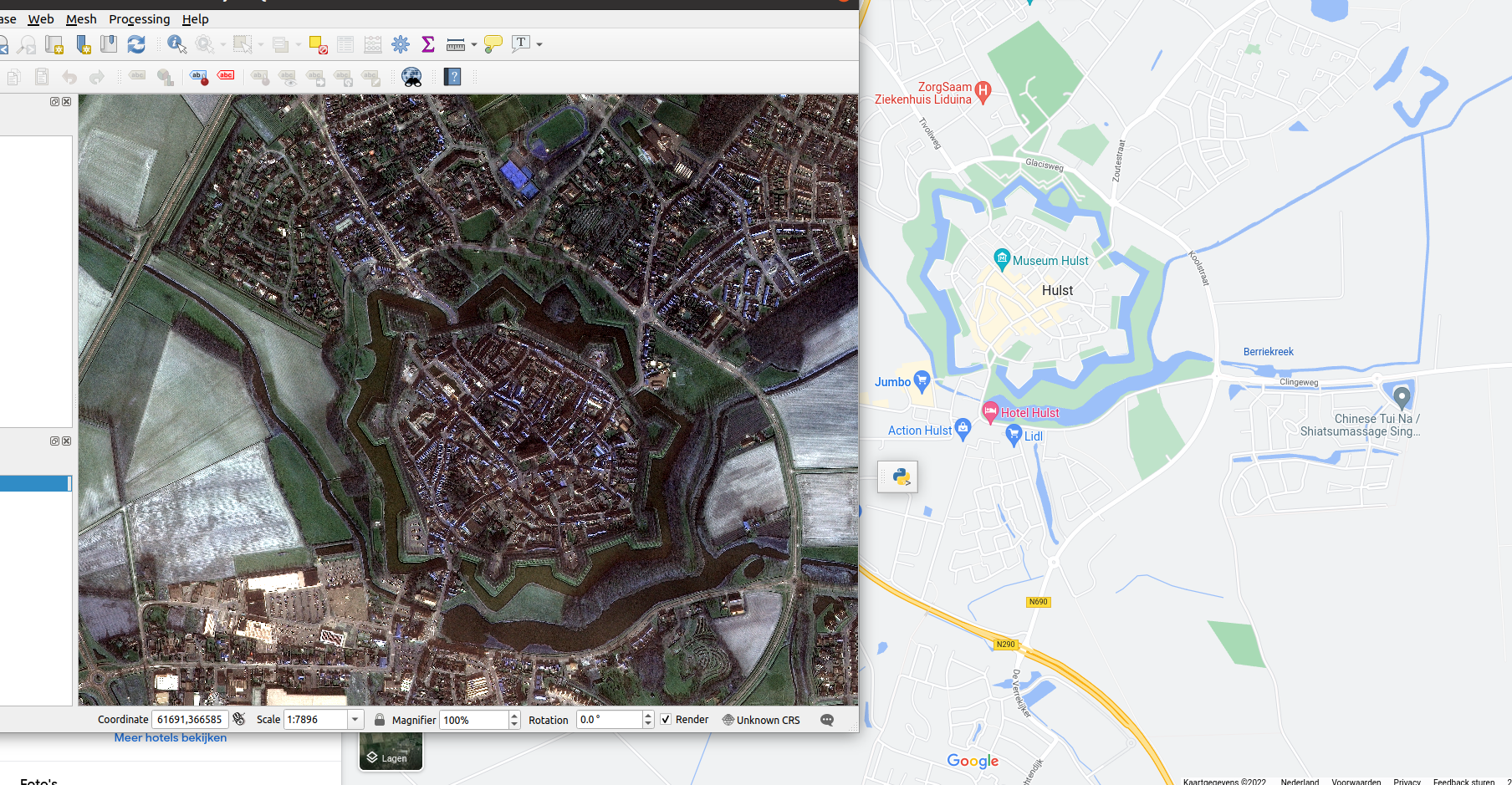
- I could have seen that by activating the OpenStreetView in QGIS.
- The IR band only lights up clearly in the purple field above the inner city.
- Also selected the IR images from Feb 3, 2022 for the TU Eindhoven campus, but it seemed that there were clouds at that date. Trying Dec 17, 2022.
- Looked for a dataset on TU Eindhoven Mobile Perception System lab.
- The EHV-track dataset is only 22 Mb, so really only contains the GPS Log.
- The EHV-ROAD contains stereo-images, so will be bigger. The 2017 recording is 5.6 Gb
- Could also use the Sentinal Playground arguments. Currently using
- The 3Me building in Delft is at 52.00068, 4.373149.
- Also registered an account at sentinel-hub.
- The run of today uses slightly different global ids:
global 298, epoch 1, iter 0: loss : 0.51593018
global 318, epoch 1, iter 20: loss : 0.55805832
global 338, epoch 1, iter 40: loss : 0.53949594
global 358, epoch 1, iter 60: loss : 0.57199770
global 378, epoch 1, iter 80: loss : 0.58510685
InputData::next_pair_batch: read fail: 2014-11-28-12-07-13/g
round/619775.3134727028_5734845.157191574.png
global 398, epoch 1, iter 100: loss : 0.53920871
global 418, epoch 1, iter 120: loss : 0.52162445
InputData::next_pair_batch: read fail: 2015-08-17-13-30-19/ground/619812.2680257955_5734971.263088638.png
global 438, epoch 1, iter 140: loss : 0.54724199
global 458, epoch 1, iter 160: loss : 0.54739034
global 478, epoch 1, iter 180: loss : 0.55239916
global 498, epoch 1, iter 200: loss : 0.54108322
global 518, epoch 1, iter 220: loss : 0.55579430
global 538, epoch 1, iter 240: loss : 0.55045307
global 558, epoch 1, iter 260: loss : 0.54008949
global 595, epoch 2, iter 0: loss : 0.54195631
global 615, epoch 2, iter 20: loss : 0.52497131
- Yet, the loss seems comparible. The iteration is nearly as far as it was yeasterday (iter 260).
- Yet, this directory contains all IR-tiles from Rotterdam
- Other nice tiles are:
- Hoorn:
 Velp:
Velp:  Stramproy:
Stramproy: 
- Leeuwarden:
 Lelystad:
Lelystad:  Den Ham:
Den Ham: 
- Giethoorn:
 Kampen:
Kampen:  Amsterdam
Amsterdam 
- There are a few tiles from around Delft:
 - Delft March 8, 2019 - same location as the next
- Delft March 8, 2019 - same location as the next
 - Delft April 22, 2021 - Note the country seat of Abswoude at 51.9655718,4.3569755
- Delft April 22, 2021 - Note the country seat of Abswoude at 51.9655718,4.3569755
 - Delft March 26, 2020 - Note the shapes of the waterways west of the Delftsche Schie at 51.9768355,4.3828668
- Delft March 26, 2020 - Note the shapes of the waterways west of the Delftsche Schie at 51.9768355,4.3828668
 - Delft August 15, 2021 - Note the shape of the waterways above Stalling 't Einde at 51.9674795,4.381036
- Delft August 15, 2021 - Note the shape of the waterways above Stalling 't Einde at 51.9674795,4.381036
- There are a few tiles from Rotterdam:
 - Rotterdam April 7, 2019 - Note the square buildings in the water at the Lamrustlaan 51.9664917,4.4899249
- Rotterdam April 7, 2019 - Note the square buildings in the water at the Lamrustlaan 51.9664917,4.4899249
 - Rotterdam May 13, 2019
- Rotterdam May 13, 2019
 - Rotterdam July 6, 2019
- Rotterdam July 6, 2019
 - Rotterdam October 3, 2019
- Rotterdam October 3, 2019
 - Rotterdam December 15, 2019 (Completly covered)
- Rotterdam December 15, 2019 (Completly covered)
 - Rotterdam August 11, 2020 (same location as April - May 2019)
- Rotterdam August 11, 2020 (same location as April - May 2019)
 - Rotterdam September 9, 2020 - Note Rotterdam Airport at @51.9525466,4.4408573.
- Rotterdam September 9, 2020 - Note Rotterdam Airport at @51.9525466,4.4408573.
 - Rotterdam March 19, 2020 (same location)
- Rotterdam March 19, 2020 (same location)
 - Rotterdam June 7, 2019 - Note the circular track of the greyhound racing track at 51.9649306,4.4757323
- Rotterdam June 7, 2019 - Note the circular track of the greyhound racing track at 51.9649306,4.4757323
 - Rotterdam September 18, 2021
- Rotterdam September 18, 2021
 - Rotterdam December 07, 2021 (Cloudy)
- Rotterdam December 07, 2021 (Cloudy)
 - Rotterdam March 8, 2022 (same location as April / May 2019
- Rotterdam March 8, 2022 (same location as April / May 2019
 - Rotterdam September 26, 2020 (same location)
- Rotterdam September 26, 2020 (same location)
- There are a few from around Eindhoven:
 - Eindhoven September 06, 2019
- Eindhoven September 06, 2019
 - Eindhoven December 09, 2019 - Note the circular ice-skating center at 51.4171611,5.480545
- Eindhoven December 09, 2019 - Note the circular ice-skating center at 51.4171611,5.480545
 - Eindhoven April 17, 2020 - Note the squares of the High Tech campus at @51.4138071,5.4667809
- Eindhoven April 17, 2020 - Note the squares of the High Tech campus at @51.4138071,5.4667809
 - Eindhoven July 13, 2020
- Eindhoven July 13, 2020
 - Eindhoven September 17, 2020
- Eindhoven September 17, 2020
April 21, 2022
- Also downloaded tensorflow-1.14 image on ws10 with singularity pull library://sylabs/examples/tensorflow-rocm:1.14.2,latest.
- Had to install scipy (v1.4.1 is max for python3.5) with python3 -m pip install --user scipy and python3 -m pip install --user opencv-python (v 4.4.0)
- Had to do python3.5 -m pip install --user --upgrade setuptools wheel first, otherwise I got the error that it could build the wheel with PEP 517.
- After also installing tensorflow-probabilities the training seems to start.
- Note that the training could take 6 days. Killed the session, and started again with tmux:
2022-04-21 11:54:24.062662:
load model...
Model initialialized from: ~/data/checkpoints/safa/Models_RAL/Initialize/initial_model.ckpt
load model...FINISHED
global 0, epoch 0, iter 0: loss : 0.55013335
global 60, epoch 0, iter 60: loss : 0.53280777
global 80, epoch 0, iter 80: loss : 0.51456654
global 100, epoch 0, iter 100: loss : 0.54046142
InputData::next_pair_batch: read fail: 2014-11-28-12-07-13/ground/619775.3134727028_5734845.157191574.png
global 120, epoch 0, iter 120: loss : 0.57049286
global 140, epoch 0, iter 140: loss : 0.52529848
global 160, epoch 0, iter 160: loss : 0.51709020
global 180, epoch 0, iter 180: loss : 0.52657831
global 200, epoch 0, iter 200: loss : 0.55464292
global 220, epoch 0, iter 220: loss : 0.53767771
global 240, epoch 0, iter 240: loss : 0.49819291
InputData::next_pair_batch: read fail: 2015-06-26-08-09-43/ground/620054.5698917876_5735971.375741994.png
global 260, epoch 0, iter 260: loss : 0.56871951
global 280, epoch 0, iter 280: loss : 0.50306588
global 300, epoch 0, iter 300: loss : 0.54192019
InputData::next_pair_batch: read fail: 2015-08-17-13-30-19/ground/619817.5191730377_5734971.013410104.png
Model saved in file: ~/data/checkpoints/safa/Model/Oxford/0/model.ckpt
validate...
compute global descriptors
compute accuracy
epoch 0 val global accuracy = 0.11778563015312131
epoch 0 val local accuracy = 5.241460541813899
global 304, epoch 1, iter 0: loss : 0.53699541
global 324, epoch 1, iter 20: loss : 0.51719117
global 344, epoch 1, iter 40: loss : 0.56596327
global 364, epoch 1, iter 60: loss : 0.54775882
InputData::next_pair_batch: read fail: 2014-11-28-12-07-13/ground/619775.3134727028_5734845.157191574.png
global 384, epoch 1, iter 80: loss : 0.49039143
global 404, epoch 1, iter 100: loss : 0.55557990
global 424, epoch 1, iter 120: loss : 0.55189312
global 444, epoch 1, iter 140: loss : 0.53427649
global 464, epoch 1, iter 160: loss : 0.49939054
global 484, epoch 1, iter 180: loss : 0.55699110
global 504, epoch 1, iter 200: loss : 0.54233205
global 524, epoch 1, iter 220: loss : 0.50345600
global 544, epoch 1, iter 240: loss : 0.51835185
global 564, epoch 1, iter 260: loss : 0.53300667
-
- In the mean time searched for Sentinel images on EarthExplorer with less than 10% clouds, such as April 19, 2021:

- Also used the Creodias browser to search for good Sentinel-2 L1C images:



NDVI (based on bands (B8-B4)/(B8+B4) False Color (based on bands 8,4,3) True color (based on bands 4,3,2)
- Note the grey square, which is the Computer Science faculty building. Also note the purple Graham Sports Centre more to the right.
April 20, 2022
- Also installed singularity v3.9.8 on ws10.
- Downloaded now as regular user an image as singularity pull library://uvarc/default/tensorflow:2.1.0-py37
- Created a sandbox with singularity build --sandbox --bind /storage:/storage tensorflow2.1.0 tensorflow_2.1.0-py37.sif and started a shell in this container with singularity shell --nv --bind /storage:/storage /storage/./singularity-containers/tensorflow2.1.0/
- In the singularity shell I run python3.7 OxfordRobotCar_evaluation_on_test_set_own_model.py, which failed on missing cloudpickle package. Looked the version up in environment.yaml and installed it with python3.7 -m pip install cloudpickle==2.0.0.
- That was the only missing package, next it goes wrong in the call sat_global, grd_global = SAFA(sat_x, grd_x, keep_prob, dimension, is_training). In spatial_net.py (line 46) a call is made to the (VGG) model with model = Model(x_grd, grd_local), which fails on the tensorflow.python.framework on You must feed a value for placeholder tensor 'Placeholder' with dtype float
for [[{{node Placeholder}}]]
- Went one step back and tried out SAFA code. The data was already downloaded, so had only to download the trained models. Put the models in storage, and made two logical links in the ~/git/cross_view_localization_SAFA directory: ln -s /storage/./data/CVACT_full/Model/ Model and in ~/git/cross_view_localization_SAFA/Data the logical link ln -s /storage/avisser/data/CVACT_full/ CVACT
- The script python3.7 test_cvact.py is starting, fails to read one polarmap image, but ends succesfully:
Model loaded from: ../Model/CVACT/Trained/model.ckpt
load model...FINISHED
validate...
compute global descriptors
InputData::next_pair_batch: read fail: ../Data/CVACT/polarmap/MV1QjpgxRMJ5CEVmbb_WPQ_satView_polish.png, 19,
compute accuracy
start
SAFA_8 :
top1 : 0.7492120666366502
top5 : 0.8973435389464205
top10 : 0.9268347591175147
top1% : 0.9780504277352544
- The script in ~/git/Visual-Localization-with-Spatial-Prior/CrossViewVehicleLocalization still contained some experimental VGG.py and spatial_net.py, so copied the original version back and run python3.7 OxfordRobotCar_evaluation_on_test_set_own_model.py again. Now the script is making progress.
- Finished with:
compute accuracy
test traversal 1 global accuracy = 64.31560071727435
test traversal 1 local accuracy = 95.9952181709504
test traversal 2 global accuracy = 43.0327868852459
test traversal 2 local accuracy = 85.88992974238876
test traversal 3 global accuracy = 52.985948477751755
test traversal 3 local accuracy = 88.87587822014052
- Yet, it still seems that the run is cpu based:
run model...
2022-04-20 10:46:41.794823: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2022-04-20 10:46:41.815677: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3699850000 Hz
- Checked, and also the SAFA run python3.7 test_cvact.py showed the cpu-device only.
- Strange, did nvidia_smi in my regular shell, and the command was not found. Checked /usr/local/cuda/version.txt, which indicated version 10.1.243
- According to the tensorflow-cuda combination list, cuda-10.1 and tensorflow-2.1 are a good match.
- Did in another Singularity shell a check with python3.7 -m pip list, which revealed that actually I was still running tensorflow 1.14 (and not tensorflow-gpu 2.1):
tensorboard 1.14.0
tensorflow 1.14.0
tensorflow-estimator 1.14.0
tensorflow-gpu 2.1.0
tensorflow-probability 0.7.0
- Installed inside singularity python3.7 -m pip install tensorflow==2.1.0. The only version not updated is tensorflow-probability. According to this github page, v0.9.0 is tested with tensorflow 2.1.0, so also upgraded this package (tensorboard even automatically upgraded to 2.1.1).
- Now python3.7 test_cvact.py fails on line 52: tf.reset_default_graph(). Replaced it with tf.compat.v1.reset_default_graph(), which seems to work.
- Also replaced the calls to the placeholder with tf.compat.v1.placeholder(tf.float32), yet this gives a RuntimeError: tf.placeholder() is not compatible with eager execution
- Run the automated upgrade script on the code, but still same RuntimeError.
- Run the short tensorflow2.py script from yesterday now at ws10 (in the singularity shell). The versions reported are tensorflow 2.1.0 and keras 2.2.4-tf.
- Also libcuda is loaded succesfully, but next call is a failure, and the system falls back to cpu again:
tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1
2022-04-20 13:06:21.917605: E tensorflow/stream_executor/cuda/cuda_driver.cc:351] failed call to cuInit: CUDA_ERROR_COMPAT_NOT_SUPPORTED_ON_DEVICE: forward compatibility was attempted on non supported HW
022-04-20 13:06:21.917721: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:200] libcuda reported version is: Invalid argument: expected %d.%d, %d.%d.%d, or %d.%d.%d.%d form for driver version; got "1"
2022-04-20 13:06:21.917754: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:204] kernel reported version is: 510.54.0
022-04-20 13:06:21.917967: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2022-04-20 13:06:21.939743: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3699850000 Hz
- Checked the environment. The LD_LIBRARY_PATH point to /usr/local/cuda/lib64 (which for the moment redirects to cuda-10.1), while the USER_PATH points to /usr/local/cuda-10.1/bin, PATH to /usr/local/cuda/bin, CUDA_HOME=/usr/local/cuda, and last but not least NVIDIA_REQUIRE_CUDA=cuda>=10.1 brand=tesla,driver>=384,driver<385 brand=tesla,driver>=396,driver<397 brand=tesla,driver>=410,driver<411
- According to google, Cuda 10.1 should be combined with a driver version >= 418.39.
- apt-get install suggest nvidia-utils-390, 418-server, 440, 450-server, 470, 510.
- When I do sudo apt-get install nvidia-utils-510, I receive the mesage that this is a downgrade, and cuda-10-1 and several cuda-drivers will be removed.
- Note that /usr/local/nvidia is used in the singularity shell, but not in my normal shell. Did modinfo /usr/lib/modules/5.13.0-39-generic/updates/dkms/nvidia.ko | grep ^version, which reveales version 510.60.02
- Did a check with ubuntu-drivers devices
== /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 ==
modalias : pci:v000010DEd00002204sv00001028sd00003880bc03sc00i00
vendor : NVIDIA Corporation
driver : nvidia-driver-510-server - third-party non-free
driver : nvidia-driver-510 - third-party non-free recommended
driver : xserver-xorg-video-nouveau - distro free builtin
- Did sudo ubuntu-drivers autoinstall, but that doesn't install anything new.
- Yet, there are many packages that have to be updated, including nvidia-utils-510. So start with a sudo apt upgrade. Receive warnings taht I downgrading from lambda-versions of nvidia-510.
- Still no nvidia_smi in my path. Time for a reboot.
- The installation seems to be done with lambda stack.
- Did sudo apt=get dist-upgrade, which upgrades all AI software like magic (so no version that can be specified !?)
- Yet, the suggestion of the upgrade looks good:
The following packages will be REMOVED:
lambda-stack-cuda libaccinj64-11.1 libcuinj64-11.1 libcupti11.1
nvidia-cuda-dev nvidia-cuda-toolkit python3-pycuda python3-skcuda
The following NEW packages will be installed:
libaccinj64-11.6 libcuinj64-11.6 libcupti11.6 libnvrtc-builtins11.6
libnvrtc11.2
The following packages have been kept back:
libcublas11 libcublaslt11 libcusolver11 libcusolvermg11 libnvblas11
The following packages will be upgraded:
caffe-cuda caffe-tools-cuda cudnn-license libcaffe-cuda1 libcudart11.0
libcufft10 libcufftw10 libcupti-dev libcurand10 libcusparse11 libnccl-dev
libnccl2 libnppc11 libnppial11 libnppicc11 libnppidei11 libnppif11
libnppig11 libnppim11 libnppist11 libnppisu11 libnppitc11 libnpps11
libnvidia-ml-dev libnvjpeg11 libnvtoolsext1 nvidia-profiler
python3-caffe-cuda python3-keras python3-tensorboard python3-tensorflow-cuda
python3-tensorflow-estimator python3-torch-cuda tensorboard
- This installs at least python3-tensorflow-cuda_2.8.0 from http://archive.lambdalabs.com/ubuntu
- Now at least python3 tensorflow2.py gives:
2022-04-20 15:19:38.741785: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 21816 MB memory: -> device: 0, name: NVIDIA GeForce RTX 3090, pci bus id: 0000:01:00.0, compute capability: 8.6
- Also python3 VGG_dropout_on_dogs_tensorflow2.py now works on ws10 (after I downloaded and sorted the dog_breeds dataset):
2022-04-20 15:38:19.754430: I tensorflow/stream_executor/cuda/cuda_dnn.cc:368] Loaded cuDNN version 8303
2022-04-20 15:38:20.643248: W tensorflow/stream_executor/gpu/asm_compiler.cc:111] *** WARNING *** You are using ptxas 10.1.243, which is older than 11.1. ptxas before 11.1 is known to miscompile XLA code, leading to incorrect results or invalid-address errors.
You may not need to update to CUDA 11.1; cherry-picking the ptxas binary is often sufficient.
2022-04-20 15:38:20.644337: W tensorflow/stream_executor/gpu/redzone_allocator.cc:314] UNIMPLEMENTED: ptxas ptxas too old. Falling back to the driver to compile.
Relying on driver to perform ptx compilation.
Modify $PATH to customize ptxas location
2022-04-20 15:38:24.262618: I tensorflow/stream_executor/cuda/cuda_blas.cc:1786] TensorFloat-32 will be used for the matrix multiplication. This will only be logged once.
...
Epoch 30/30
1/1 [==============================] - 0s 17ms/step - loss: 6.6060 - accuracy: 0.2344 - val_loss: 5.1191 - val_accuracy: 0.1875
- Note that it is again a different validation accuracy, and that 20x more time is needed per step.
- Also node that tensorflow-2.8.0 should be combined with cuda-11.2 and cuDNN 8.1
- Installed sudo apt-get install cuda-11-2 libcuda-11.2.1 Note that this comes from the Ubuntu 18.04 repository http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64
- Also note that /usr/local/cuda/version.json now specifies cuda-11.2.2, but also nvidia_driver 460.32.03 (while nvidia_driver 510 is already insatlled).
- Modified the .bashrc, but import tensorflow fails on /lib/x86_64-linux-gnu/libnccl.so.2: undefined symbol: cudaUserObjectCreate, version libcudart.so.11.0
- With export LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64 the code works again.
- Also installed cuda-11.0, which matches tensorflow-2.4.0 and cuDNN 8.0
- Also with export LD_LIBRARY_PATH=/usr/local/cuda-11.0/lib64 I got undefined symbol: cudaUserObjectCreate. Even the short tensorflow2.py gives this error, while export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64 works fine.
- If I want to experiment further with VGG on tf2, I should reimplement the conv_layer's get_variable as instructed here. Yet, the dog_breeds example was working fine with the default keras VGG, so I could also try to work out that example further.
- When I run the script on ws8 it works fine, yet on ws10 (in singularity shell), it creates a GPU device, but seems not to do the quit. It does, after several minutes.
- Modified spatial_net on ws10 in script (although script_tf2 would have been better choice)
April 19, 2022
- Trying to see if I could also run VGG_dropout_on_dogs.py without the singularity environment for tensorflow 1.14.
- Call fails on vgg16 = keras.applications.vgg16.VGG16, on the keras/engine installed on /usr/lib/python3/dist-packages/tensorflow/.
- Printed the version with print(tensorflow.__version__) and print(keras.__version__): for both v2.5.0
- Did import tensorflow.compat.v1.keras as keras, but same error as before in the keras/engine.
- Did again singularity search tensorflow. Did singularity pull library://christopherm/tensorflow/tf-1.15-tfp:latest (1.8 Gb).
- When I start the same program from this sandbox, I got tensorflow v1.15.5 and keras v2.2.4-tf, followed with from keras.applications import VGG16: no module named keras. Solved that with using the full from tensorflow.keras.applications import VGG16 as before. Even the full VGG_dropout_on_dogs.py starts to run, although it fails much later.
- When I run just initialization in a tensorflow2.py script, I got the warning (which fits the later error):
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/ops/resource_variable_ops.py:1630: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
- The script fails on model2.fit, maybe because the Nvidia RTX 3090 has problems with tensorflow1 (once run in gpu mode).
- Try another image, downloaded with singularity pull library://uvarc/default/tensorflow:2.1.0-py37.
- Creating the sandbox while binding the storage works. singularity build --sandbox --bind /storage:/storage tensorflow2.1.0 tensorflow_2.1.0-py37.sif. Now I also have access to this storage when I call singularity shell --nv --bind /storage:/storage /storage/avisser/singularity-containers/tensorflow2.1.0/.
- Running the python3.7 tensorflow2.py gives v2.1.0 and 2.2.4-tf.
- Also running python3.7 VGG_dropout_on_dogs.py works in this sandbox.
- Script finds the GPU:
2022-04-19 17:35:25.540042: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1555] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce RTX 2080 Ti computeCapability: 7.5
coreClock: 1.545GHz coreCount: 68 deviceMemorySize: 10.76GiB deviceMemoryBandwidth: 573.69GiB/s
2022-04-19 17:35:25.545001: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2022-04-19 17:35:25.569277: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3099995000 Hz
2022-04-19 17:35:25.570348: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x51a43a0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
Run ends with result:
Epoch 30/30
64/64 [==============================] - 0s 364us/sample - loss: 6.4703 - accuracy: 0.1250 - val_loss: 4.6925 - val_accuracy: 0.2031
- This is again another result than previous (and the kaggle example!)
- But the positive news is that with this sandbox the code also works under tensorflow 2.1.0.
April 15, 2022
- The GPS coordinates at least point to the Durham campus are 54.7632336,-1.5713432
The Department of Computer Science building on this location is also visible in the ambient panoramas.
- With from tensorflow.keras.layers import BatchNormalization I could also add BatchNormalization layers beyond the fully connected layers:
Epoch 1/30
64/64 [==============================] - 0s 3ms/sample - loss: 8.4612 - acc: 0.0000e+00 - val_loss: 5.0226 - val_acc: 0.0000e+00
Epoch 2/30
64/64 [==============================] - 0s 892us/sample - loss: 7.8120 - acc: 0.0000e+00 - val_loss: 5.0967 - val_acc: 0.0000e+00
Epoch 3/30
64/64 [==============================] - 0s 901us/sample - loss: 8.5488 - acc: 0.0156 - val_loss: 5.1704 - val_acc: 0.0000e+00
Epoch 4/30
64/64 [==============================] - 0s 905us/sample - loss: 7.7641 - acc: 0.0000e+00 - val_loss: 5.2261 - val_acc: 0.0000e+00
Epoch 5/30
64/64 [==============================] - 0s 891us/sample - loss: 8.0184 - acc: 0.0000e+00 - val_loss: 5.2551 - val_acc: 0.0000e+00
Epoch 6/30
64/64 [==============================] - 0s 916us/sample - loss: 7.7351 - acc: 0.0000e+00 - val_loss: 5.2699 - val_acc: 0.0000e+00
Epoch 7/30
64/64 [==============================] - 0s 917us/sample - loss: 7.7412 - acc: 0.0312 - val_loss: 5.2680 - val_acc: 0.0000e+00
Epoch 8/30
64/64 [==============================] - 0s 908us/sample - loss: 7.6894 - acc: 0.0469 - val_loss: 5.2511 - val_acc: 0.0000e+00
Epoch 9/30
64/64 [==============================] - 0s 908us/sample - loss: 6.4173 - acc: 0.0781 - val_loss: 5.2452 - val_acc: 0.0000e+00
Epoch 10/30
64/64 [==============================] - 0s 892us/sample - loss: 7.8670 - acc: 0.0469 - val_loss: 5.2301 - val_acc: 0.0000e+00
Epoch 11/30
64/64 [==============================] - 0s 886us/sample - loss: 7.4361 - acc: 0.1094 - val_loss: 5.2066 - val_acc: 0.0000e+00
Epoch 12/30
64/64 [==============================] - 0s 899us/sample - loss: 7.3222 - acc: 0.0625 - val_loss: 5.1807 - val_acc: 0.0469
Epoch 13/30
64/64 [==============================] - 0s 889us/sample - loss: 7.3720 - acc: 0.1094 - val_loss: 5.1520 - val_acc: 0.0781
Epoch 14/30
64/64 [==============================] - 0s 909us/sample - loss: 7.2398 - acc: 0.0469 - val_loss: 5.1177 - val_acc: 0.1250
Epoch 15/30
64/64 [==============================] - 0s 891us/sample - loss: 7.1370 - acc: 0.1094 - val_loss: 5.0870 - val_acc: 0.2500
Epoch 16/30
64/64 [==============================] - 0s 892us/sample - loss: 7.4476 - acc: 0.0781 - val_loss: 5.0556 - val_acc: 0.2812
Epoch 17/30
64/64 [==============================] - 0s 884us/sample - loss: 6.3024 - acc: 0.1094 - val_loss: 5.0337 - val_acc: 0.3125
Epoch 18/30
64/64 [==============================] - 0s 897us/sample - loss: 7.3108 - acc: 0.1250 - val_loss: 5.0237 - val_acc: 0.3281
Epoch 19/30
64/64 [==============================] - 0s 888us/sample - loss: 6.8182 - acc: 0.1562 - val_loss: 5.0030 - val_acc: 0.3281
Epoch 20/30
64/64 [==============================] - 0s 896us/sample - loss: 6.6063 - acc: 0.0938 - val_loss: 4.9880 - val_acc: 0.3438
Epoch 21/30
64/64 [==============================] - 0s 890us/sample - loss: 7.2144 - acc: 0.0938 - val_loss: 4.9824 - val_acc: 0.3594
Epoch 22/30
64/64 [==============================] - 0s 912us/sample - loss: 7.0422 - acc: 0.1094 - val_loss: 4.9734 - val_acc: 0.3594
Epoch 23/30
64/64 [==============================] - 0s 913us/sample - loss: 6.7504 - acc: 0.1406 - val_loss: 4.9684 - val_acc: 0.3594
Epoch 24/30
64/64 [==============================] - 0s 880us/sample - loss: 7.2257 - acc: 0.1406 - val_loss: 4.9511 - val_acc: 0.3594
Epoch 25/30
64/64 [==============================] - 0s 915us/sample - loss: 6.8415 - acc: 0.2031 - val_loss: 4.9248 - val_acc: 0.3594
Epoch 26/30
64/64 [==============================] - 0s 900us/sample - loss: 6.6268 - acc: 0.1406 - val_loss: 4.8830 - val_acc: 0.3594
Epoch 27/30
64/64 [==============================] - 0s 901us/sample - loss: 6.4332 - acc: 0.1094 - val_loss: 4.8404 - val_acc: 0.3594
Epoch 28/30
64/64 [==============================] - 0s 898us/sample - loss: 5.8932 - acc: 0.1719 - val_loss: 4.7946 - val_acc: 0.3594
Epoch 29/30
64/64 [==============================] - 0s 905us/sample - loss: 6.8852 - acc: 0.1875 - val_loss: 4.7477 - val_acc: 0.3594
Epoch 30/30
64/64 [==============================] - 0s 900us/sample - loss: 7.0200 - acc: 0.1094 - val_loss: 4.7038 - val_acc: 0.3594
- The training accuracy is now 3x worse than kaggle example.
- Should also plot the model accuracy and loss, because with BatchNormalization the validation accuracy is actually 3x better than without normalization (and that is the most important criterium).
April 14, 2022
- Started a new attept to download the 16 Gb page 1 with 'DurLAR_20211209_OTHERS [dataset]' directly on ws10
- The [202111209 S Others] others is much smaller (413 Mb).
- The [202111209 S LIDAR] others is 1.1 Gb.
- The [202111209 S CAM] others is 494 Mb.
- The [202111209 S Others] contains as data.csv file gps, imu and lux. In addition, it contains the reflec and ambient directories with numbered png files, together with a timestamp.txt file.
- The image of frame 266 shows nicely the difference between the frequency of the laser (850nm) and the whole infrared (ambient), because the building on the left is clearly just out of range (only the bicycle park is visible in reflective, while the rest of the building is well distinguisable in the ambient view.


-
- In the mean time (download of 30min), looking at BatchNormalization.
- According to the v1.15 documentation this code can be called in the same way, but maybe I should call it like tf.compat.v1.keras.layers.BatchNormalization, tf.compat.v1.layers.BatchNormalization, or tf.compat.v2.keras.layers.BatchNormalization.
-
- Created the doi 10.26303/tpsz-g470 for the autonomous driving project on growkudos.
April 12, 2022
- Restarted ws10
- Downloaded the dropout example dataset on ws8.
- Strange, when I copy the command kaggle kernels output hanspinckaers/fine-tuning-vgg16-with-drop-out-loss-0-8 -p dog_breeds I only receive a part of the dataset. The first time only the training set until appenzeller was downlaoded, the 2nd time the command ended at australian_terrier.
- The data input is original from this competition. Downloaded the data with kaggle competitions download -c dog-breed-identification. Unzipped it in a storage data directory.
- Split the notebook into two scripts (sort_dogbreed_dataset.py and preprocess_dogbreed_dataset.py), which gave the expected output:
Found 8000 images belonging to 120 classes.
Found 2222 images belonging to 120 classes.
- Yet, the sorted filenames are needed later, so I had to copy most of the preprocessing code back to the script.
- It fails with tensorflow 2.5, so I had to start my sandbox again with singularity shell --writable tensorflow/. That directory is currently still in tmp, but could better rename it to tensorflow1.14.2.
- Had to do pip installs for pandas, pillow and scipy, but after I could generate the bottleneck features:
1/1 [==============================] - 3s 3s/step
1/1 [==============================] - 3s 3s/step
- That is on ws8 12x faster than on the kaggle-cluster, although I started the sandbox with the --nv argument, so cpu_utils are used (and warnings are given that I use more than 10% of the system memory).
- Started singularity shell --nv --writable tensorflow1.14.2/, which gives warnings as if I still have to install a cuda-toolbox:
Skipping mount /usr/bin/nvidia-smi [files]: /usr/bin/nvidia-smi doesn't exist in container
- So, the next run was still CPU based.
- Added the model2.compile and model2.fit. Had to include a declaration import tensorflow.keras as keras. The call fails on model2.fit, on Error when checking input: expected input_1 to have 4 dimensions, but got array with shape (64, 1000). Used a slightly other VGG16 model than the notebook, so should check the model definition (especially the input).
- Changed the model closer to the example (had to skip the BatchNormalization), and it seems to work:
_______________________________________________________________
Train on 64 samples, validate on 64 samples
Epoch 1/30
64/64 [==============================] - 0s 2ms/sample - loss: 5.9731 - acc: 0.0000e+00 - val_loss: 4.2837 - val_acc: 0.2812
Epoch 2/30
64/64 [==============================] - 0s 861us/sample - loss: 1.4787 - acc: 0.7969 - val_loss: 7.2693 - val_acc: 0.2812
Epoch 3/30
64/64 [==============================] - 0s 859us/sample - loss: 0.4012 - acc: 0.9688 - val_loss: 10.4025 - val_acc: 0.2812
Epoch 4/30
64/64 [==============================] - 0s 873us/sample - loss: 0.4612 - acc: 0.9688 - val_loss: 12.9412 - val_acc: 0.2812
Epoch 5/30
64/64 [==============================] - 0s 865us/sample - loss: 0.4688 - acc: 0.9688 - val_loss: 14.9550 - val_acc: 0.2812
Epoch 6/30
64/64 [==============================] - 0s 870us/sample - loss: 0.4539 - acc: 0.9688 - val_loss: 16.5393 - val_acc: 0.2812
Epoch 7/30
64/64 [==============================] - 0s 874us/sample - loss: 0.5639 - acc: 0.9688 - val_loss: 17.7715 - val_acc: 0.2812
Epoch 8/30
64/64 [==============================] - 0s 856us/sample - loss: 0.6981 - acc: 0.9688 - val_loss: 18.6723 - val_acc: 0.2812
Epoch 9/30
64/64 [==============================] - 0s 852us/sample - loss: 0.7420 - acc: 0.9688 - val_loss: 19.3078 - val_acc: 0.2812
Epoch 10/30
64/64 [==============================] - 0s 858us/sample - loss: 0.9598 - acc: 0.9688 - val_loss: 19.6804 - val_acc: 0.2812
Epoch 11/30
64/64 [==============================] - 0s 866us/sample - loss: 0.6177 - acc: 0.9688 - val_loss: 19.8608 - val_acc: 0.2812
Epoch 12/30
64/64 [==============================] - 0s 860us/sample - loss: 0.6506 - acc: 0.9688 - val_loss: 19.8859 - val_acc: 0.2812
Epoch 13/30
64/64 [==============================] - 0s 856us/sample - loss: 0.9077 - acc: 0.9688 - val_loss: 19.7256 - val_acc: 0.2812
Epoch 14/30
64/64 [==============================] - 0s 843us/sample - loss: 0.9758 - acc: 0.9688 - val_loss: 19.4006 - val_acc: 0.2812
Epoch 15/30
64/64 [==============================] - 0s 838us/sample - loss: 0.5152 - acc: 0.9688 - val_loss: 18.9927 - val_acc: 0.2812
Epoch 16/30
64/64 [==============================] - 0s 862us/sample - loss: 0.6959 - acc: 0.9688 - val_loss: 18.4765 - val_acc: 0.2812
Epoch 17/30
64/64 [==============================] - 0s 876us/sample - loss: 0.4199 - acc: 0.9688 - val_loss: 17.8635 - val_acc: 0.2812
Epoch 18/30
64/64 [==============================] - 0s 854us/sample - loss: 0.3788 - acc: 0.9688 - val_loss: 17.1770 - val_acc: 0.2812
Epoch 19/30
64/64 [==============================] - 0s 850us/sample - loss: 0.2505 - acc: 0.9688 - val_loss: 16.4487 - val_acc: 0.2812
Epoch 20/30
64/64 [==============================] - 0s 847us/sample - loss: 0.4894 - acc: 0.9688 - val_loss: 15.7028 - val_acc: 0.2812
Epoch 21/30
64/64 [==============================] - 0s 855us/sample - loss: 0.2648 - acc: 0.9688 - val_loss: 15.0005 - val_acc: 0.2812
Epoch 22/30
64/64 [==============================] - 0s 846us/sample - loss: 0.3800 - acc: 0.9375 - val_loss: 14.3117 - val_acc: 0.2812
Epoch 23/30
64/64 [==============================] - 0s 843us/sample - loss: 0.2729 - acc: 0.9375 - val_loss: 13.8051 - val_acc: 0.2812
Epoch 24/30
64/64 [==============================] - 0s 855us/sample - loss: 0.5020 - acc: 0.8750 - val_loss: 13.6085 - val_acc: 0.2812
Epoch 25/30
64/64 [==============================] - 0s 858us/sample - loss: 0.3933 - acc: 0.8906 - val_loss: 13.6275 - val_acc: 0.2812
Epoch 26/30
64/64 [==============================] - 0s 853us/sample - loss: 0.6359 - acc: 0.8906 - val_loss: 13.8988 - val_acc: 0.2812
Epoch 27/30
64/64 [==============================] - 0s 854us/sample - loss: 0.3130 - acc: 0.9062 - val_loss: 14.2784 - val_acc: 0.2812
Epoch 28/30
64/64 [==============================] - 0s 850us/sample - loss: 0.3869 - acc: 0.8906 - val_loss: 14.7297 - val_acc: 0.2812
Epoch 29/30
64/64 [==============================] - 0s 861us/sample - loss: 0.3576 - acc: 0.9062 - val_loss: 15.1919 - val_acc: 0.2812
Epoch 30/30
64/64 [==============================] - 0s 860us/sample - loss: 0.3064 - acc: 0.9688 - val_loss: 15.5789 - val_acc: 0.2812
- Note that without BatchNormalization the reported loss & accuracy are a factor 3x better than reported in kaggle example. Could be overfitting :-)
April 11, 2022
- Couldn't login at ws9 and ws10, so I logged in at ws8 with the general account.
- Cloned original SAFA code on ws8.
- ws8 is running python3.8. Keras is installed, but keras dropout example fails in keras_applications/vgg6/py o x = layers.Conv2D(64, (3, 3),, because the base_layer from the keras engine fails on is_tensor.
- When I check python -c 'import tensorflow as tf; print(tf.__version__)' I receive '2.5.0', (and libcudart.so.11.0). Because the SAFA code depends on tensorflow 1.14, it is time to try Singularity.
- Following the quick installation steps, but setting up cryptsetup-initramfs gave warings on Possible missing firmware /lib/firmware/i915
- Installed go v1.18 and Singularity v3.9.8 on ws8.
- Looked for pre-built images with singularity search tensorflow. There were several interesting ones, for instance library://sylabs/examples/tensorflow-rocm:1.14.2,latest. Did a singularity pull, which downloads a 3.5Gb image (for the moment in /tmp/singularity-ce-3.9.8/image). Moved that image to /storage/avisser1.
- Interacted with that image with sudo singularity shell tensorflow-rocm_1.14.2.sif. The command python3 -c 'import tensorflow as tf; print(tf.__version__)' now gives 1.14.2, as expected (and python -version gives 2.7.12 and python3 --version 3.5.2.
- Yet, unfortunately keras is not installed in this build.
- Strange, because when I do python3 -m pip install keras-applications I got:
Requirement already satisfied: keras-applications in /usr/local/lib/python3.5/dist-packages (1.0.8)
- While I tested keras with from keras.applications import VGG16.
- When I try pip3 install keras-preprocessing==1.1.2 I got:
ERROR: Could not install packages due to an EnvironmentError: [Errno 30] Read-only file system: 'INSTALLER'
- As indicated, singularity produces immutable images.
- Made a writable sandbox with command singularity build --sandbox tensorflow/ tensorflow-rocm_1.14.2.sif. Entered the sandbox with singularity shell --writable tensorflow/. Note that I have to add next time --nv to be able to use the Nvidia-drivers. In this sandbox I could do pip3 install keras-preprocessing==1.1.2 and pip3 install --upgrade pip.
- Yet, still from keras.applications import VGG16 fails.
- The right commands seems to be
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import Dropout
rom tensorflow.keras.models import Model
model = VGG16(weights='imagenet')
# Store the fully connected layers
fc1 = model.layers[-3]
fc2 = model.layers[-2]
predictions = model.layers[-1]
# Create the dropout layers
dropout1 = Dropout(0.85)
dropout2 = Dropout(0.85)
# Reconnect the layers
x = dropout1(fc1.output)
x = fc2(x)
x = dropout2(x)
predictors = predictions(x)
# Create a new model
model2 = Model(inputs=model.input, outputs=predictors)
model2.summary()
.
- This results in the following output:
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
dropout (Dropout) (None, 4096) 0
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_1 (Dropout) (None, 4096) 0
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
- The main difference with April 1 is that there is now an input layer, so the convolutional blocks now also have instantiated shapes. And I added the dropouts after the two fully connected layers, while SAFA added them after block4 and block5.
- Look if I get this VGG16 working on Dog breed identification.
- Had to install first kaggle with pip3 install kaggle.
- Had to couple my kaggle account, and specify that in a .kaggle/kaggle.json file
- They DurLAR dataset is divided in many small parts. Started on page 1 with 'DurLAR_20211209_OTHERS [dataset]', to check the GPS-format. This file is already 16 Gb.
- Maybe the S and M indicate a small and medium dataset :-).
April 7, 2022
- This article describes an U-Net-Like architecture to convert infrared images to RGB. Unfortunatelly, not a paper with code.
April 1, 2022
- Looked at the VGG-implementation. It network uses two types of layers: conv2d and max_pool. The variable x, the variable W seems to be a filter, which is initiated with weight = tf.get_variable(name='weights',...).
- Further it seems to be a standard VGG16, still looking what is intended with the -D part of VGG16-D.
- The -D part indicates the additional dropout layers after layer 11-17. The last layer is not a max_pool layer, but also only a dropout layer. Layer-14 is still a maxpool layer.
- The VGG16 code was provided by the baseline. Here is a keras-example how dropout layers can be inserted in between a pretrained VGG-model.
- Here is another example, which highlights the difference between VGG16 with top and without top.
- Looked up the original SAFA publication. They mention that they use the first 16-layers of VGG19, althought they also refer to it as VGG16. They used the ImageNet weights. The code is also available on github. The VGG.py looks still the same.
- Oxford RobotCar training takes longer (~6days). CVACT training takes shorter (~2days).
- Received a link to Boreas Autonomous Driving Dataset, which was recorded in Toronto, Canada for radar odometry. No multi-spectral camera is part of this dataset. The dataset is well documented.
- Looked if I could add dropout-layers from a default VGG16 layer. The dropout layers use the variable keep_prob, which is initialized with value 1.0 (while I expect a dropout of 0.8, as indicated in the paper).
- Added 6 dropout layers, which gives the following summary:
_________________________________________________________________
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
block1_conv1 (Conv2D) (None, None, None, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, None, None, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, None, None, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, None, None, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, None, None, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, None, None, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, None, None, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, None, None, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, None, None, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, None, None, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, None, None, 512) 1180160
_________________________________________________________________
dropout (Dropout) (None, None, None, 512) 0
_________________________________________________________________
block4_conv2 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
dropout_1 (Dropout) (None, None, None, 512) 0
_________________________________________________________________
block4_conv3 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
dropout_2 (Dropout) (None, None, None, 512) 0
_________________________________________________________________
block4_pool (MaxPooling2D) (None, None, None, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
dropout_3 (Dropout) (None, None, None, 512) 0
_________________________________________________________________
block5_conv2 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
dropout_4 (Dropout) (None, None, None, 512) 0
_________________________________________________________________
block5_conv3 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
dropout_5 (Dropout) (None, None, None, 512) 0
_________________________________________________________________
block5_pool (MaxPooling2D) (None, None, None, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
- Now I also should skip the block5_pool, and the model should be comparible.
- Got the warning tensorflow:Large dropout rate: 0.80 (>0.5). In TensorFlow 2.x, dropout() uses dropout rate instead of keep_prob. Please ensure that this is intended., so now I use (keep_prob = 1 - dropout) for Dropout(.20) instead.
- Should be able to test and evaluate following these instructions, with model.evaluate() and model.predict().
- Used transfer learning guide to set the name and trainable parameters.
- Checked the original VGG with the Functional API from this explanation. Yet, I get this error:
tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value VGG_grd/conv1_1/biases
[[{{node VGG_grd/conv1_1/biases/read}}]]
- Solved this by doing tf.initialize_all_variables() before building the model. Now I get the error:
tensorflow.python.framework.errors_impl.InvalidArgumentError: You must feed a value for placeholder tensor 'Placeholder' with dtype float
[[{{node Placeholder}}]]
March 30, 2022
- Gijs pointed me to two interesting datasets: Freiburg Thermal (including GPS) and Teledyne FLIR ADAS training set.
- The Freiburg dataset is recorded with Teledyne FLIR ADK, which has a USB-C version.
- Teledye also recommended the PathFindIR.
- The ADAS dataset was recorded with Tau 2, which has no USB-C connection.
- Yet, according to the brochure, the Tao has breakout modules and link broads, which give USB-B connections.
-
- Gijs also pointed out that the Ouster sensor gives also a NIR image.
- There are enough Ouster datasets available. DurLAR highlights the Reflective and Ambient imagery. The ambient illumination is near infrared, which makes this in 2021 this dataset the only one with this provision.
- The ambient imagery is based on the 850 nm LiDAR signal.
- They are not very specific on where the dataset is recorded (other than City, Campus, Residential, Suburb), but most likely it woud be the campus of Durham univerity itself.
- Ouster is also proud on its feature that it can capture 2D camera-like imagery.
March 29, 2022
- Also running the 3 test traversals on the baseline model (Models_RAL/OxfordRobotCar/baseline).
- Started the baseline run around 10:40. The run is finished around 11:50 (with a RTX 1080 Ti). Received some warnings that more than 10% of the memory was used by tensorflow.
- Results:
test traversal 1: global accuracy = 90.616
test traversal 1: local accuracy = 92.350
test traversal 2: global accuracy = 76.112
test traversal 2: local accuracy = 81.850
test traversal 3: global accuracy = 79.508
test traversal 3: local accuracy = 83.372
- This corresponds also nicely with the results in the 5m column of table II of Cross-View Matching for Vehicle Localization by Learning Geographically Local Representations.
-
- Looking with pip freeze what is the difference in the installations of XPS9370 and ws10.
- The code of spatial_net.py only imports explicitly VGG and tensorflow. Didn't see a VGG package, but on the XPS the installed tensorflow seems to be quite high (v2.3.1). Yet with python3 -m pip freeze | grep tensorflow I get tensorflow-gpu==1.14.0.
- When I do pip freeze | grep tensorflow on ws10, I get the python2.7 version (tensorflow-gpu==1.4.0). With pip3 I get tensorflow-gpu==2.7.0. When I do python3.7 -m pip freeze | grep tensorflow I get tensorflow-gpu==1.14.0. So, for both kernels the tensorflow packages are the same.
- It seems that vgg is loaded from Keras-Applications (on XPS9370 v1.0.8), although on ws10 I only have keras==2.7.0.
- When I do directly from VGG import VGG16 on XPS9370 I receive no module. Same with ws10. In the environment.yaml keras-application==1.0.8 is specified.
- When I do on ws10 from spatial_net import *, I see with dir() that the modules SAFA, VGG16, spatial_aware and tf are loaded. Note that VGG.py is available as script in the directory. SAFA is defined in spatial_net.py itself.
- On XPS9370 I use numpy==1.20.3, which is the same for ws10.
- Used an ssh tunnel to run the same evaluation and test notebook on ws10 as XPS9370, as specified here.
- Started 12:32, progress 0, ...,
- Seems that on XPS9370 the GPU is not used (because TF_XLA_FLAGS=--tf_xla_global_jit was not set). On ws10 receive at that moment in the log from XLA services the device RTX 3090 with compute Capability 8.6.:
2022-03-29 12:33:56.802241: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): ,
2022-03-29 12:33:56.803357: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcuda.so.1
2022-03-29 12:33:56.916507: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-03-29 12:33:56.916633: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x55868885ff80 executing computations on platform CUDA. Devices:
2022-03-29 12:33:56.916647: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): NVIDIA GeForce RTX 3090, Compute Capability 8.6
2022-03-29 12:33:56.916753: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-03-29 12:33:56.916824: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 0 with properties:
name: NVIDIA GeForce RTX 3090 major: 8 minor: 6 memoryClockRate(GHz): 1.695
pciBusID: 0000:01:00.0
- Note that on the XPS9370, no stream_executor, compiler and core messages are printed after the StreamExecutor device, other than the tensorsflow/compiler/jit warning.
- Note that with tensorflow-gpu==1.14.0 no longer installed for python3.7, pip falls back to tensorflow-gpu==2.7.0 from the general python3 installation.
- Note that I still receive a GPU properties message, when the evaluation script is running. After a while I get a connection refused on the ssh-tunnel.
- On the tunneled notebook only progress 0 is given, maybe I have to reload the page to see more.
- Reload was not a good idea, got CPU->GPU Memcpy failed, followed by a kernel restart.
- Running again, but got failed to run cuBLAS routine: CUBLAS_STATUS_ECECUTION_FAILED.
- The evaluation and test fails again on the einsum.
- Added on XPS9370 the line tf.xla.experimental.jit_scope( separate_compiled_gradients=True): to spatial_net, but still the log gives only CPU as XLA device.
- On ws10, I did python3.7 -m pip uninstall tensorflow-gpu, followed by a python3.7 -m pip install --force-reinstall tensorflow==1.14.0. Now the evaluation_on_test_set is making progress.
- Made a python version of the notebook. Is running. Results of my_model is the same as yesterday.
- Read Migrate from TensorFlow 1.x to TensorFlow 2.
- In principal I should also be able load VGG16 from keras.applications. In the environment v1.0.8 is specified.
- Replaced the own-implementation of VGG.py by from tensorflow.keras.applications.vgg16 import VGG16
- Yet, this fails on
grd_local = vgg_grd.VGG16_conv(x_grd, keep_prob, trainable, 'VGG_grd')
AttributeError: 'Model' object has no attribute 'VGG16_conv'
March 28, 2022
- Mounted the 2TB data-disk of my XPS8370 workstation.
- Unpacked in projects/autonomous_driving the Oxford_5m-sampling dataset.
- Changed in ~/git/Visual-Localization-with-Spatial-Prior/CrossViewVehicleLocalisation/scripts/readdata.py the image_root and datasplit_root.
- Also had to change the load_model_path in OxfordRobotCar_evaluation_on_test_set.ipynb.
- Downloaded ECCV and RAL models on the XPS workstation.
- The cell with InputData gives Storing the index of nearby images for all satellite images. This might take a while.
- Continue with the next cell. Could load the model (Models_RAL/OxfordRobotCar/our_model), compute global descriptors gives progress 0, ..., 7712.
- Then I got an small error (read fail: 2015-06-26-08-09-43/ground/620054.5698917876_5735971.375741994.png).
- Checked, but this image seams to exist. Yet, half of the image is missing, so it is correct that this image couldn't be read.
- Script continues with progress 7744, ..., 15808
- Next fail: 2015-04-24-08-15-07/ground/619578.3819026542_5735976.493171507.png. Also half an image.
- Continues with progress 15840, ..., 18592
- Next fail: 2015-08-17-13-30-19/ground/619817.5191730377_5734971.013410104.png
- Continues with progress 18624, ..., 19168
- Next fail: 2015-08-17-13-30-19/ground/619812.2680257955_5734971.263088638.png
- Continues with progress 19200, ..., 23360
- Next tail 2014-11-28-12-07-13/ground/619775.3134727028_5734845.1571191574.png
- Continues with progress 23392, ..., 23854
- Results:
test traversal 1: global accuracy = 64.315
test traversal 1: local accuracy = 95.995
test traversal 2: global accuracy = 43.033
test traversal 2: local accuracy = 85.890
test traversal 3: global accuracy = 52.986
test traversal 3: local accuracy = 88.876
- This corresponds nicely with the results in the 5m column of table II of Cross-View Matching for Vehicle Localization by Learning Geographically Local Representations.
March 25, 2022
- Running the Jupyter notebook from the commandline with jupyter nbconvert --to notebook --execute CVACT_training_and_validation_baseline.ipynb.
- Something goes wrong with Cuda 10.0: Could not dlopen library 'libcudart.so.10.0'; dlerror: libcudart.so.10.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/avisser/.local/lib/python3.7/site-packages/cv2/../../lib64::/usr/local/cuda-8.0/lib64.
- In my bashrc I added this link to cuda-8.0
- There is no official Ubuntu 20.04 packages, so had to use the 18.04 following the 2. Install steps of this post.
- According to tensorflow list, I should install cuDNN v7.4.
- Followed the instructions of this post. Logged in with my nvidia account, downloaded three deb (v7.4.2.24) files (18.04 based) from archives.
- Rebooted, but nvidia-smi gave driver version 510.54, combined with cuda version 11.6.
- Loading of cuda-10.0 and libcudnn-7 seems to go well. Still, the jupyer converstion goes wrong.
- Starting the notebook on ws10 and access it remotely didn't.
- Manually copied notebook code to python code CVACT_training_and_validation_baseline.py, which runs with python3.7 (with some warnings).
- Could try to set XLA_FLAGS, because of warning (One-time warning): Not using XLA:CPU for cluster because envvar TF_XLA_FLAGS=--tf_xla_cpu_global_jit was not set. If you want XLA:CPU, either set that envvar, or use experimental_jit_scope to enable XLA:CPU. To confirm that XLA is active, pass --vmodule=xla_compilation_cache=1 (as a proper command-line flag, not via TF_XLA_FLAGS) or set the envvar XLA_FLAGS=--xla_hlo_profile
- Still some dependencies on the user. The /tmp/arnoud is gone. Made in /storage/avisser/data checkpoints directory.
- The model_root expects a subdirectory Initiliaze and CVACT, so that should be Models_RAL.
- This model is successfull loaded:
Model loaded from: ~/data/checkpoints/safa/Models_RAL//Initialize/initial_model.ckpt
load model...FINISHED
2022-03-25 10:44:18.477793: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcublas.so.10.0
2022-03-25 10:45:19.617325: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudnn.so.7
- The script used 2.7 Gb memory of my Nvidia Geoforce 3090.
- After 10min, it fails on line 368: sat_global, grd_global = SAFA(sat_x, grd_x, keep_prob, dimension, is_training). This line calls SAFA in spatial_net.py (line 41): grd_w = spatial_aware(grd_local, dimension, trainable, name='spatial_grd') , which calls line 27 vec3 = tf.einsum('bjd, jid -> bid', vec2, weight2) + bias2.
- Tried to do the datapreparation of SAFA, but the datapreparation script fails on scipy.imread. According to this post, imread is removed from newer versions of scipy (environment.yml specifies scipy==1.6.2).
- Installed imageio==2.13.3, which works. Script fails on missing ../Data/CVUSA/. Yet, it seems that the polarmap and streetview are already prepared.
- Tried the training again, but same error occurred:
Internal: Blas xGEMMBatched launch failed : a.shape=[8,16,40], b.shape=[8,40,80], m=16, n=80, k=40, batch_size=8
[[node spatial_sat/einsum_1/MatMul (defined at ~/git/Visual-Localization-with-Spatial-Prior/GeolocalRepresentationLearning/scripts/spatial_net.py:27) ]
- Looked at tensorflow documentation, and added reuse=tf.AUTO_REUSE to the variable_scope. Same error. Split the einsum and addition.
- Looked in Models/CVACT/baseline. Here he model_checkpoint_path still contains an explicit user path. The baseline should be found at checkpoints/safa/Model/CVACT/100baseline_final/60 and our_model at checkpoints/safa/Model/CVACT/100_final_sig10/40/. Replaced this with a direct link to local model.ckpt. Otherwise, I could try to download cuda-10.1
- Installed cuda-10.1 and downloaded libcudnn v7.6.5.32.
- Zimin's hypothesis is that the pretrained model is for the Oxford dataset, so another resolution. I had to try the training script in CrossViewVehicleLocalization.
- Used an ssh tunnel to access the jupyter notebook directly, as specified here.
- The evaluation code is running now, started at 14:00, printing progress updates at the end. Currently it is 1.7Gb of 24.5.5.5.5.5 Gb watch -n 1 nvidia-smi
- Rebooted to activate cuda-10.1. Yet, it looks like that the notebook still loads libcurand.so.10.0, while /usr/local/cuda-10.1/lib64/libcurand.so.10.1.1.243 is available. Seems that the tensorflow package 1.14 prefers cuda-10.0 above cuda-10.1
- Removed cuda-10.0, but note that libcudnn7 relies on cuda-10.2.
- Note that /usr/local/cuda-10.0 still exists (as cuda-10.1 and cuda-10.2).
- Also the OxfordRobotCar training and validation script fails on the nearly the same location of spatial_net.py (line 17) vec2 = tf.einsum('bi, ijd -> bjd', vec1, weight1) + bias1 (same operation, other vec)>:
InternalError: 2 root error(s) found.
(0) Internal: Blas GEMM launch failed : a.shape=(64, 64), b.shape=(64, 256), m=64, n=256, k=64
[[node spatial_sat/einsum/MatMul (defined at /home/avisser/git/Visual-Localization-with-Spatial-Prior/CrossViewVehicleLocalization/scripts/spatial_net.py:17) ]]
[[train/Adam/update/_66]]
(1) Internal: Blas GEMM launch failed : a.shape=(64, 64), b.shape=(64, 256), m=64, n=256, k=64
[[node spatial_sat/einsum/MatMul (defined at /home/avisser/git/Visual-Localization-with-Spatial-Prior/CrossViewVehicleLocalization/scripts/spatial_net.py:17) ]]
March 21, 2022
- Downloaded the Oxford-car and Act datasets on ws10.
- Downloaded ECCV and RAL models on ws10.
- Also downloaded robotcar-dataset-development-kit (version 3.1). I should put this code in ./Visual-Localization-with-Spatial-Prior/GeolocalRepresentationLearning/scripts, but it is still not clear if Zimin meant all subdirectories, or only the content of the python directory.
- Checked my python3 version: v3.8.10.
- Under Ubuntu 20.04 I couldn't install python3.7 directly, so used
sudo add-apt-repository ppa:deadsnakes/ppa, followed by
sudo apt install python3.7, which gives me v3.17.13.
- Installed all required packages with python3.7 -m pip install, so all imports from the Jupyter notebook seems to work.
- Jupyter notebook starts fine, but with the default python3 kernel.
- Also installed zmq and cython, otherwise I had problem connecting to the python3.7 kernel.
- Indicated that InputData should use the files from ../datasplits instead of the local directory. After that the training should be able to start, although I receive some suspisious warnings like Not using XLA:CPU for cluster because envvar TF_XLA_FLAGS=--tf_xla_cpu_global_jit was not set. If you want XLA:CPU, either set that envvar, or use experimental_jit_scope to enable XLA:CPU. To confirm that XLA is active, pass --vmodule=xla_compilation_cache=1 (as a proper command-line flag, not via TF_XLA_FLAGS) or set the envvar XLA_FLAGS=--xla_hlo_profile..
- The train cell uses data/Initialize/initial_model.cpkt or data/CVACT/baseline/model.ckpt. Note that also in the train() an user dependent model_root is defined.
- Unpacked both downloaded models into ~/tmp/checkpoints/safa/Model. Selected for the first try Models_ECCVw
- This call fails in line 129 of train-cell, where sat_global, grd_global = SAFA(sat_x, grd_x, keep_prob, dimension, is_training) is called, which calls grd_w = spatial_aware(grd_local, dimension, trainable, name='spatial_grd'), which complains that Variable spatial_grd/weights1 already exists. Same error when I use Models_Raw.
- Unpacked CVACT.tar.gz, which created a CVACT_full directory in my data directory. The trainlist.txt specifies from this directory a grdView.png and satView_polish.png, together with two numbers (UTM position). The UTM zone is not indicated, but the dataset was recorded in Canberra, Australia, so UTM zone 55H is used. The 1st number corresponds with UTM Easting, the 2nd with UTM Northing of Canberra.
- The first images in the trainlist.txt seems to be recorded at Captain Cook Crescent (Converted 55H 694032.349448 6089189.632526 to N -35.321707 E 149.134567). At the polar view in orange the Manuku Terrace shopping mall is visible (a building with a MacDonalds inside), but the street view is clearly recorded a bit before (near the bus-stop). The MacDonalds sign is visible ahead just left of the straight lane. The footpath on the right is nicely aligned in both views:


- This is my hypothesis for the corresponding Google Streetview
March 17, 2022
- Downloading the Oxford-car dataset on XPS-8930.
- Cloned Visual-Localization-with-Spatial-Prior repository.
- Requested the two ACT datasets, as indicated on Lending Orientation to Neural Networks for Cross-view Geo-localization.
- Also downloaded robotcar-dataset-development-kit (version 3.1). I should put this code in ./Visual-Localization-with-Spatial-Prior/GeolocalRepresentationLearning/scripts, but it is not clear if Zimin meant all subdirectories, or only the content of the python directory.
- Tried the import of the Jupyter notebook CVACT_training_and_validation_baseline.ipynb. cv2 is not installed for python3, but for python2 all goes well, until from spatial_net import *
- Installed for python3 (v3.9.5) opencv-python (v4.5.5). Numpy was already installed (v1.21.4). Installed scipy (v1.8.0). Installed tensorflow (v2.8.0) and tensorflow_probability (v0.16.0). (Skipping everytime the KDE-Wallet).
- The package spatial_net doesn't have to be installed, but fails to load because cuda-11 is not in the path. In my bashrc I still point to cuda-8.0. Installed tensoflow_gpu (v2.8.0). Changed the bashrc from cuda-8.0 to cuda-11.4. Now from spatial_net import * works fine for python3.
- Actually, Zimin used python3.7.11 and tensorflow 1.14. In the profided environment.yml cuda-10.1 is specified. I have cuda-10.2 preinstalled on my machine.
- In a Jupyter environment, the baseline script works fine, until the last command train(0,100) because not ./trainlist.txt is available. The file can actually be found in ../datasplits/trainlist.txt. With an updated ImportData() the training starts with the following output:
For each satellite image, storing the index of neary images with the given radius. This will take some time.
number of satellite images 128334
number of ground images in training set 86469
number of ground images in validation set 21249
number of ground images in test set 20616
- After that ImportData fails, but that is because tensorflow has no attribute placeholder. That is something specific to v1 of tensorflow, so I will have to downgrade. This is the combination list of tensorflow.
- Installed tensorflow==1.14.0 for python3.7. spatial_net can be found in the script directory.
- Have to find out to start a Jupyter notebook with another kernel.
- There was a kernel definition in /usr/share/jupyter/kernels (python3), which I copied to ~/.local/share/jupyter/kernels and made three versions of it (3.6, 3.7 and 3.9). Unfortuanetlly only the python3.9 was able to start.
- Did python3.7 -m pip install jupyterlab (and the same for python3.6). Also installed cython and zmq.
- This failed, because there was still an egg installed in /usr/local/python3/site-packages. Removed that installation (manually), and afterwards installing traitlets and jupyter_client for each of the three python-version. Now I can switch kernel. The baseline script now fails on loading the data (which I didn't unpack yet).
March 11, 2022
- Waymo released v1.3 of its Perception dataset, which is part of the new challenges (deadline May 23).
- The github code of Bird's-Eye-View Panoptic Segmentation Using Monocular Frontal View Images could be very usefull for my student-graduation project. This code has configuration files for kitti and nuscenes.
- Freiburg's Efficient LiDAR Panoptic Segmentation makes use of the segmented kitti dataset.
-
- The download of the Coimbra rosbag wasn't finished yet (1Gb of the 8Gb).
- The download is finished, three rosbags are provided (0 and 2 from Jan 14, 1 (largest) from Jan 18)
- Looked at Google map documentation on the meaning of the different parameters. z is zoom-level, with z=15 streetlevel. You cannot turn a google map, although at Streetview you can (pitch and yaw are additional parameters).
- This is a resumé what I have found from the datasets:
- View on Delft - (Touwbrug 52.0107739,4.3582141 ), Ground: RGB, GPS (radar, lidar), Sky: Worldview or PDOK.
- SpaceNet 6 - Rotterdam harbour, (Grote Kerk Vlaanderen 51.907855735420135 4.342989921569824), Ground: RGB (Streetview), Sky: Worldview or plane.
- Freiburg Forest, (Achim-Stocker Strasse 48.0214433,7.8272391), Ground: RGB, NIR (600-900nm) , Sky: Wordview.
- SemFire - Combria, (40.234552755,-8.449214968333333), Ground: RGB, NIR - 850nm, GPS. Sky: Wordview.
- Oxford Radar RobotCar , (Parks road 51.7617426,-1.2599777), Ground; RGB, GPS (Radar, Lidar).
- Hyperspectral City 1.0 Dataset - Shanghai , NIR (450 - 950 nm) (125 channels of 4nm).
- The LightGene sensor from the Hyperspectral dataset has datacubes with all 125 channels (40Gb), which can be read out with the provided Matlab code:
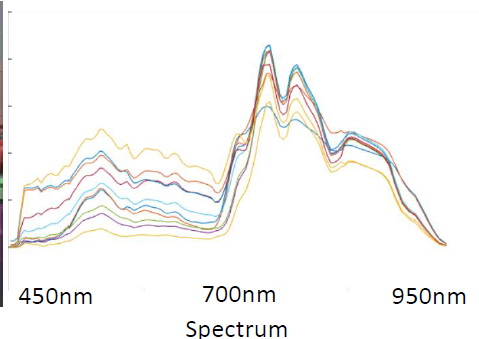
- The Freiburg dataset is recorded with Viona robot with a modified dashcam (with the Wratten 25A filter removed) (600nm - 900 nm). Yet, the transmission should be combined with the sensitivity from the unknown dashcam. On the removal, see page 3 of Towards Robust Semantic Segmentation using Deep Fusion
- The sensor platform of the Oxford RobotCar is extensively described in The Oxford Radar RobotCar Dataset paper:
1 x Point Grey Bumblebee XB3 (BBX3-13S2C-
38) trinocular stereo camera, 1280×960×3, 16 Hz,
1/3" Sony ICX445 CCD, global shutter, 3.8 mm lens,
66◦ HFoV, 12/24 cm baseline
- 3 x Point Grey Grasshopper2 (GS2-FW-14S5C-C)
monocular camera, 1024×1024, 11.1 Hz, 2/3" Sony
ICX285 CCD, global shutter, 2.67 mm fisheye lens
(Sunex DSL315B-650-F2.3), 180◦ HFoV
- 1 x NovAtel SPAN-CPT ALIGN inertial and GPS
navigation system, 6 axis, 50 Hz, GPS/GLONASS, dual
antenna
- From the European Space imaging I can get WorldView images (0.0% Clouds) from Jan 20, 2022 (WorldView 2) and Nov 2, 2011 (WorldView 3).
- Downloading Training set 1 from Hyperspectral City V1.0 Dataset
- Executed source /opt/ros/noetic/setup.sh, started roscore and run osbag play 2019_2020_quinta_do_bolao_coimbra_01.bag. Checked the gps-coordinates with rostopic echo /gps_fix. Dataset was recorded at (R. Parcelar do Campo40.234552755,-8.449214968333333).
- Created an account and explored European Space Imaging samples. Downloaded the Spectral bands package with 50cm OR2A and SWIR images (WorldView-3) around Munich.A
- Also interesting are the Resolution comparison and Product Type package.
Checked Worldview-3, August 23, 2020, no clouds (zoomed in):

- The worldview-2 collected at July 04, 2020 (no clouds) is also not very high resolution.
- These are Worldview images for Oxford:


-
- Tried to view the downloaded Munich images (recorded March 3, 2021) with qgis. According to the label, it is GeoTiff. The Readme in the Media folder contains at least the GPS coordinates (Munich airport (.48.3591006,11.7964519).
- First tried it as project, but I should have used the Data source browser.
- First looked at the 1B_30cm TIFF file. Could not incease the scale further than 1:2486. The Google Map image is better (and more recent):

- The OR2A image looks more promissing, in the sense that I could see the large trees at the park. Note that this is another location in Munich. Not that imrpessed with the HD (15 cm) from the resolution package. Not much sharper, less clear colors.
- The SWIR 3.7 sample is Munich Airport again. Nice red contrast in the fields, but not impressed by the resolution. Also the artificial coloring from Satellogic(99cm) is nice, but not that high resolution.
-
- Looked at the Google Maps additional terms. They indicate that is forbidden to:
- copy the content (unless you are otherwise permitted to do so by the Using Google Maps, Google Earth, and Street View permissions page or applicable intellectual property law, including "fair use");
- mass download or create bulk feeds of the content (or let anyone else do so);
-
use Google Maps/Google Earth to create or augment any other mapping-related dataset (including a mapping or navigation dataset, business listings database, mailing list, or telemarketing list) for use in a service that is a substitute for, or a substantially similar service to, Google Maps/Google Earth;
- Note that Amsterdam has its own Open Geodata website.
March 10, 2022
- ws10 display works again.
- Inspected the cityshapes crops I made.
- Unfortunatly, I mostly cropped the sky:

- And I cropped the color and label, but not the InstanceIds:

March 8, 2022
March 7, 2022
- Freiburg published a new paper on arXiv, on continual-slam. The algorithm is able to adapt between datasets recorded on roads in Zurich, Karlsruhe and Oxford. Code will be provided on github.
March 4, 2022
- Used convert aachen_000000_000019_gtFine_color.png -crop 768x384+40+20 aachen_000000_000019_gtFine_color.png to crop the three images specified in the file dataset/cityshapes_fine.txt, following the suggestion from here.
- Still python2 train.py --config config/cityscapes_train.config gives: ValueError: Cannot feed value of shape (3, 1024, 2048, 3) for Tensor u'resnet_v1_50/Placeholder:0', which has shape '(?, 384, 768, 3)'
- Strange, commented out the first sess.run (train.py, line 91), and the training starts:
2022-03-04 10:16:51.899108: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:300] kernel version seems to match DSO: 470.103.1
Pretrained Intialization
First file to read: Tensor("strided_slice:0", shape=(?, ?, 3), dtype=float32)
First file to read: Tensor("strided_slice_1:0", shape=(?, ?, 3), dtype=float32)
First file to read: Tensor("strided_slice_2:0", shape=(?, ?, 3), dtype=float32)
First file to read: Tensor("strided_slice_3:0", shape=(?, ?, 3), dtype=float32)
First file to read: Tensor("strided_slice_4:0", shape=(?, ?, 3), dtype=float32)
2022-03-04 10:16:55.133919 16189] Step 4, lr = 0.000001
loss = 0.0000
estimated time left: 0.0 hours. 4/100
AdapNet
....
First file to read: Tensor("strided_slice_95:0", shape=(?, ?, 3), dtype=float32)
First file to read: Tensor("strided_slice_96:0", shape=(?, ?, 3), dtype=float32)
First file to read: Tensor("strided_slice_97:0", shape=(?, ?, 3), dtype=float32)
First file to read: Tensor("strided_slice_98:0", shape=(?, ?, 3), dtype=float32)
First file to read: Tensor("strided_slice_99:0", shape=(?, ?, 3), dtype=float32)
2022-03-04 10:17:25.059059 16189] Step 99, lr = 0.000001
loss = 0.0000
estimated time left: 0.0 hours. 99/100
AdapNet
Epochs in dataset repeat < max_iteration
- So the First file to read (my additional print statement) gives not a File, but strides_slices. Seems that I have to do the convertion again.
- So, converted the txt file, and uncommented the first session run. Now the training works, although it finishes very quickly (in one step):
2022-03-04 10:25:37.741751: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:300] kernel version seems to match DSO: 470.103.1
Model Loaded
First file to read: Tensor("strided_slice:0", shape=(?, ?, 3), dtype=float32)
training_completed
- The result are 4 files in the ~/git/AdapNet/checkpoint directory: checkpoint, model.ckpt-100.index, model.ckpt-100.data-00000-of-00001 and model.ckpt-100-meta. The data file is the largest.
- Edited cityshapes_test.config, equivalent to cityshapes_train.config.
- Created a test.txt file with three berlin images (which I cropped). Converted them with python2 convert_to_tfrecords.py -f cityshapes_fine_test.txt -r cityshapes_fine_test.trfrecords.
- Added this cityshapes_fine_test.trfrecords to config/cityshapes_test.config and run python2 evaluate.py --config config/cityscapes_test.config, which fails on DataLossError (see above for traceback): Unable to open table file ./checkpoint. Seems that I needed to specify 'checkpoint: 'checkpoint/model.ckpt-100.index', although this gives:
NotFoundError (see above for traceback): Tensor name "resnet_v1_50/block1/unit_1/bottleneck_v1/conv2/BatchNorm/beta" not found in checkpoint files checkpoint/model.ckpt-100.index
- Yet, specifying checkpoint: 'checkpoint/model.ckpt-100' seems to work:
2022-03-04 11:48:15.435758: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:300] kernel version seems to match DSO: 470.103.1
total_variables_loaded: 290
mIoU: 0.0 total_data: 3
- So, evaluate only gives the IoU (zero), no qualitive results are created. In evaluate.py the line img = img - mean works, in train.py still not. Added mean = np.load(config['mean']) directly after sess.run(tf.global_variables_initializer()), which seems to repair train.py:
training_completed after 105 steps
max_iteration after 100 steps
- The mIoU is computed based on compute_iou(output_matrix), which is defined in dataset/helper.py (which used numpy).
- Saw no code to visualize the segmented images.
-
- Code requires that AdapNet is trained twice, once on rgb, and once on jet, hha or evi. That cannot be done on the cityshapes dataset, that requires the Freiburg dataset.
-
- Installed on ws10 sudo apt-get install awscli. Moved ~/data to /storage/~/data (after making /storage readable and executable) and made a symbolic link from my home to that directory.
- Tried aws s3 cp s3://spacenet-dataset/spacenet/SN6_buildings/tarballs/SN6_buildings_AOI_11_Rotterdam_train.tar.gz . , but first had to login with my aws credentials.
- Strange enough the aws configure import (suggested by aws documentation) didn't work, so used plain aws configure with my credentials from console.aws.amazon.com. Used as default region name eu-central-1.
- Downloading the Rotterdam training set of 39 Gb.
- The dataset is split in 7 directories: geojson_buildings, PAN, PS-RGB, PS-RGBNIR, RGBNIR, SAR-Intensity, SummaryData. Most are tiffs from tiles with fixed size.
- The dataset is geo-registered and ortho-rectified with a openly available Shuttle Radar Topography Mission (SRTM) Digital Elevation Model (DEM).
- SRTM data can be browsed with the earthexplorer. Found one dataset which overlaps with GPS coordinates of the church (Grote Kerk) of Vlaanderen (51.907855735420135 4.342989921569824), which was displayed in Fig. 3 (top row); SRTM1N51E004V3. The download options are BIL 1, DTED 1, or GeoTiff 1. Tried all three.
- As streetview this location is available as Google Streetview.
- The bridge on the 2nd row is located at (51.87127794215851, 4.331510066986084). That is the bridge (Botlekbrug) over the Oude Maas, at the corner with the Hartelkanaal
- This is the Google Streetview (no trees on the highway).
- Looked for other datasets that could be loaded from this data. Found no commercial satellites, but on Feb 14, 2022 was a day without much clouds: sentinel 2b. Download options are GeoTiff (3.7 Mb) or JPEG2000 (L1C Tile, 700 Mb).
- Installed qgis with sudo apt install qgis qgis-plugin-grass.
- Loaded the Sentinel 2b TIFF file, and zoomed in on the bridge, but that lacked the resolution.
- The Zip-file contains several directories. It seems that in Granule/./IMG the recordings in different wavelengths are collected. The TCI seems a format with natural colours.
- The n51 tiff seems to be giving the height in m.
- Also found the last row: (51.87179463523712, 4.376592636108398). Industry park Gadering, with as center of the Schrijnwerkerstraat.
- This is the Streetview. It is clear that we need 'red areas' (NIR) to be able localize on trees.
-
- Also looked for Google streetviews of Freiburg, but most of the city are not covered. There are only 360 degree pictures available along the route.
- For instance roundabout in the Achim-Stocker Strasse before the forest and the Europa-Park stadion next to the forest and the parkingspot before building 104 of the university.
-
- Looked at SemFire dataset recorded in Combria. The rosbag should both contain gps_fix and NavSatFix messages. The rosbag is 8Gb (downloaded to nb-dual). The dataset concists of 901 images on a country road, with on the end a low sun shining into the camera. The images are close to each other.
-
- Looked at WorldView-2 data. Resolution is quite high. Seems that I have to submit a proposal to get access.
- Yet, when I go the euspace image-library, I get images from WV02, GEO1 and WVO3, but the resolution of the image is not high enough.
March 3, 2022
- On this blog, Cruise describes their webinterface for visualisation of ros-topics: https://webviz.io/app/.
- The code is available on github.
-
- Looked at the SpaceNet dataset. The SN6 challenge is multi-sensor, and has high-resolution imagery from the port of Rotterdam. That data is collected from Maxar’s WorldView 2 satellite.
- There is even an expanded dataset, as explained in blog, with 0.25m spatial resolution from an aircraft, covering 92 km^2 and 0.5m RGBNIR data from the Maxar WorldView satellite.
- Read the CVPR 2020 paper on SpaceNet 6.
- For multispectral automative, this papers points to radar, lidar, camera data from astyx, which is now Cruise Munich. In 2018 astyx still existed, later the HiRes2019 dataset was made available (on request).
- The specifications of the dataset are not archived, only the Deep Learning Based 3D Object Detection for Automotive Radar and Camera paper (EuMA 2019)
- The SpaceNet 6 paper also mentions:
"Less permissively licensed datasets such as
xView [15], xBD [13], A Large-scale Dataset for Object
DeTection in Aerial Images (DOTA) [34], and Functional
Map of the World (FMOW) [4]"
- The paper also mentions
"Coarser datasets such as the
Sen12MS dataset [28] provide a valuable global dataset of
multi-spectral optical and SAR imagery as well as landcover labels at 10m resolution spanning hundreds of locations."
- Based on the SpaceNet 6 dataset, the EarthVision'20 workshop is held. This is the program of the workshop.
- The Annotation from the SpaceNet 6 dataset comes from TU Delft and covers the whole Netherlands: A multi-height LoD1 model of all buildings in the Netherlands (2019).
March 2, 2022
- Looking into AdapNets code. The list of images to be read is given to a TensorFlow session (concept of v1, obsolete in v2). The actual training is done with the training_op, which is specifed in the AdaptNet.py (line 121) as train with AdamOptimizer.
- The AdapNet network is initialized with filters [256, 512, 1024, 2048], with corresponds with the 3rd till 19th layer in Fig. 2 of AdapNet paper. In the paper the input is drawn as 3x384x768, while the training images from cityshapes are also higher resolution (2048x1024).
- Looked at slim code, which is a wrapper around resnet. Here the default_image_size is defined as 224x224x3 (for image classification over 1000 classes, and 513x513x3 for semantic segmentation. Between line 295 and 305 the 4 blocks of resnet-50 are defined, with depth [64, 128, 256, 512] (note the factor 4 difference with the filters.
- Read the readme of slim.
- As indicated in Pre-trained Modelssection, the ckpt file is expected in a /tmp/checkpoints directory (see cityscapes_train.config)
- In the troubleshoot section, a code snippet is given to preprocess the height and width:
image_preprocessing_fn = preprocessing_factory.get_preprocessing(
preprocessing_name,
height=MY_NEW_HEIGHT,
width=MY_NEW_WIDTH,
is_training=True)
- Should clone the slim code and first tryout the tutorial given in the jupyter notebook.
- First read the AdapNet paper.
- As indicated in Fig 2, AdapNet is not using vanilla ResNet-50. At the input side it adds an additional convolution with kernel size 3x3, at the output side it downsamples 16-times (instead of the original 32-times). Yet, the biggest change are the Multiscale blocks in the later layers, indicated in purple and turqoise in Fig. 2 (which architectures defined in the lower right of Fig 2. In the new blocks the 3x3 convolution is split in two: two separate convolutions with half the number of feature maps each.
- They compare their AdapNet with their previous work, UpNet or FastNet (IROS 2016 paper).
March 1, 2022
- Corrected my own created cityshapes_fine.txt and succesfully run python2 convert_to_tfrecords.py -f cityshapes_fine.txt -r cityshapes_fine.tfrecords --mean True as suggested in AdapNets Readme.md.
- Next command python2 train.py --config config/cityscapes_train.config fails on import yaml.
- Because on February 23 I had maybe problems with the version, I now try an older version of yaml. python2 -m pip install PyYAML== gives (versions: 3.10, 3.11, 3.12, 3.13b1, 3.13rc1, 3.13, 4.2b1, 4.2b2, 4.2b4, 5.1b1, 5.1b3, 5.1b5, 5.1, 5.1.1, 5.1.2, 5.2b1, 5.2, 5.3b1, 5.3, 5.3.1, 5.4b1, 5.4b2, 5.4, 5.4.1). First trying 3.13.
- Import goes well, fails in tensor_util.py, line 371, after a call from AdapNet.py, line 106
- The training fails because in the default config no learning rate is specified. According to paper (page 4648), the initial learning rate is 10^{-6}, although the init of AdapNet (line 23) gives a learning rate of 0.001.
- The learning rate & power is well initialized, but global_step is ignored (while should be set during __init()). overruled it with in the call with the two default values for the steps (global_step = 0 & decay_steps = 30000).
- Next is the variable initialize, which should give the path to the pretrained model.
- Downloaded the resnet_v1_50.tar.gz and unpacked it. Programs continues, but fails on the strange call (line 85) on img=img-mean, because mean is not defined. Seems to be related with the mean=True of the convert.
- Worse, the session fails because the resnet_v1_50 has shape (384, 768, 3), while the feed is (3, 1024, 2048, 3). Seems that some cropping has to be performed.
February 25, 2022
- Registered at cityscapes.
- Downloaded the gtFine annotation dataset. Created a text-file with 3 training images (from aachen). Tried to run python2 convert_to_tfrecords.py, but first have to install opencv
- Followed this suggestion and installed python2 -m pip install opencv-python==4.2.0.32
- Run python2 convert_to_tfrecords.py cityshapes_fine.txt that fails already on missing TensorRT libraries.
-
- Moved to ws10. First had to install pip2 following this suggestion: sudo python2 get-pip.py
- Installed python2 -m pip install opencv-python==4.2.0.32, which also installs numpy-1.16.6.
- Continued with python2 -m pip install tensorflow-gpu==1.4.0.
- Copied the cityshapes to ws10 and tried python2 convert_to_tfrecords.py cityshapes_fine.txt , which fails on missing cuda_8
- Installed cuda_8 with the run-scripts, still missing libcudnn.so.6.
- Following the instructions of stackoverflow and downloaded cdnn from archive.
- Now python2 convert_to_tfrecords.py -f cityshapes_fine.txt -r cityshapes_fine.tfrecords imports all libraries, but fails on File "convert_to_tfrecords.py", line 56, in convert
assert len(label.shape)==2
-
- Had a discussion on ground-satellite match.
- One option is to use the aerial images, and match them with View of Delft dataset. Most of the data was recorded on June 10, 2021.
- Another option is that the Spanish dataset covers more ground, which makes it less a problem that the satellite coverage is not that high resolution.
-
- The visual-localisation code is available on github.
February 23, 2022
- Trying to install Cuda 8.0 in my Ubuntu 21.04 workstation following these instructions.
- I also did apt get upgrade, which also installed libcudnn8.
- Run the run-script, but receive the error:
Not enough space on parition mounted at /.
Need 4569350144 bytes.
- Looked with Disk usage, only 19.1 Gb available (but Data disk not mounted).
- Moved the nvidia-run files to /media/arnoud/DATA/Nvidia and installed cuda8. Installed tensorflow-gpu==1.4.0.
- Still python2 train.py --config config/cityscapes_train.config fails on line 371 of tensor_util.py (None values not supported). Could be a wrong version of numpy or yaml.
February 22, 2022
- Zimin looked at multispectral images.
- Google has dataset catalog for the earth-engine.
- Most interesting seems the Sentinel-2 MSI images, with 10m resolution in the NIR band-8.
- Looked at Sentinel toolboxes.
- The PROBA-V Toolbox could also be interesting, the has NDVI with 100m resolution.
- The PROBA-V Toolbox code is available on github.
- The SMOS box is dedicated to Ocean Salinity, so not relevant for me.
- At least the Creodias browser allows to select Sentinel-2 L1C data based on cloud coverage (13 Feb 2022 no clouds). The image can be download in NDVI, false color and true color.


- L2A level provides some additional formats, like NDWI and NDSI. Also urban false color and moisture index is available

 on 2022-02-13.jpg)

February 18, 2022
- Downloaded the Freiburg forest dataset on my workstation.
- Installed python2 -m pip install tensorflow-gpu==1.4.0, which uninstalls tensorflow-gpu-1.8.0. For tensorflow-gpu-1.8.0 libcublas.so.9.0 was missing, for tensorflow-gpu-1.4.0 libcublas.so.8.0 is missing.
- Installing cuda 8 toolkit on a ubuntu 21.04 machine is not recommended. Better try if the code also works for the tensorflow-gpu-1.8 / Cuda 9 combination. /usr/local/cuda/9.2 is already present on my workstation.
- Actually, tensorflow-gpu-1.8 required Cuda 9.0, while I had Cuda 9.2. Looked up Latest Cuda9 / tensorflow combination and installed tensorflow-gpu-1.12.0. Still libcublas.so.9.0 missing.
- I have cuda-10.2 installed, so tensorflow-gpu-1.15.0 is also no option. Could try to install cuda-8.0 so I could use the tensorflow-gpu-1.4 as specified by CMoDE.
-
- In the article Lost in the woods a number of forest datasets are listed (all RGB).
- Could try to use Singularity to setup a different CUDA environment in user space.
- Other interesting article (from 2013) is Cross-spectral visual simultaneous localization and mapping (SLAM) with sensor handover.
-
- The SEMFIRE dataset contains images from a FLIR and Dalsa camera, which according to the accomponying chapter are a FLIR AX8 thermal camera and a
a Teledyne Dalsa Genie Nano C2420 multispectral camera. Yet, the specs only mention a colour camera (based on Sony IMX264 sensor), while the chapter also shows NDVI and NIR images.
- According to the Sony specs, also 850nm NIR are recoreded by the IMX264LQR sensor.
- The spectral sensitivity can also be found at page 4 of Dalsa specs (C2420). There is a USB3 version and a GigE version (used for the SEMFIRE dataset):
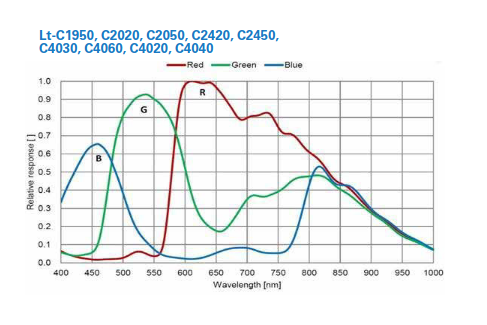
- Freiburg also used Bonn's Sugarbeets dataset, which according to this SLAM paper based on a soil-map used a downlooking JAI AD-130GE camera.
-
- Looks like the image b32-7944_Clipped.jpg is taken from 48°01'25.2"N+7°49'41.2"E/@48.0236766,7.8276558,193m.
- Another view is zoom.earth, which is a high resolution image from Microsoft maps.
- Also handy is the satellite image and open street map view provided by satellis.pro.
- The global fire map cannot zoom in far enough.
- Used usgs explorer to search for datasets, but for vegatation only the eModis Global LST V6 and NOAA CDR NDVI gave results (but as a whole world image).
- The Sentinel image is not high resolution enough (need a account for a full download):
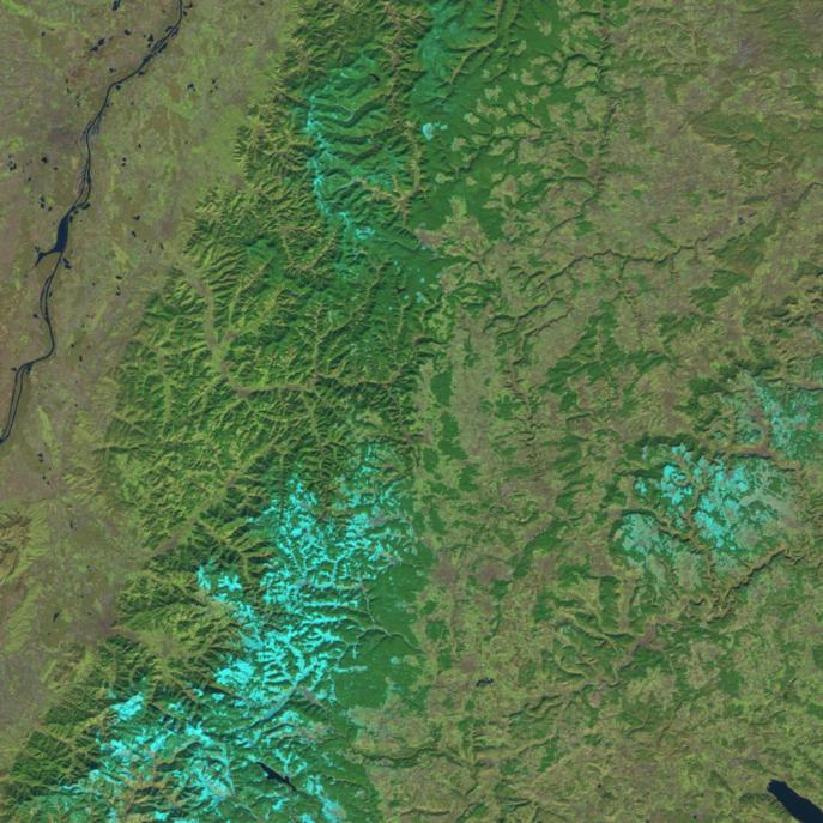
- Love these images from the digital elevation set - GMTED2010 and GTOPO30 (whole Europe):

February 17, 2022
- Looked up the origin of tracklets. Followed a trail of publications, which lead to 'We call the short single-identity tracks tracklets by Stauffer in 2003.
- Trailed I followed was:
- I also followed another trail, but that was an deadend at 2007
- In 2007 Chris Stauffer finished his Master thesis Scene reconstruction using accumulated line-of-sight. No mentioning of tracklets, although chapter 5 is dedicated on multiple camera reconstruction (following people through a room).
- His Phd thesis seems to be
Perceptual Data Mining: Bootstrapping visual intelligence from tracking behavior, MIT 2002. No mentioning of tracklets here anymore.
- Yet, Stauffer was not the first to use the world tracklet. Drummond already used the term in 1997 and 2002, and also found a reference from Walton 1990.
- Drummond points for the definition of the tracklet to a companion paper: Hybrid sensor fusion algorithm
architecture and tracklets (1997).
- In this paper he points to some his own interim reports (no longer available). He also cites Bar-Shalom(1981), who describes the correlation essential to tracklets, but without mentioning tracklet.
- Drummond also cites Covino and Griffiths (1991), also without mentioning tracklets.
- Last interesting citation is of Frenkel 1994 and 1995, also without mentioning tracklets.
-
- Downloaded Freiburg forest dataset on ws10. Seems to be 1.6 Gb large. The dataset is already split in a training and testing set. Note that not all images are of the same dimension, so have to be resized.
- Cloned the Adaptive Semantic Segmentation code on nb-dual. According to the instructions, the code was trained and tested on cityshapes data.
- Code is python2.7 based, so started with python2 -m pip install tensorflow.
- Had to add a bracket to line 73 of train.py
- The needed data preparation seems to be described in more detail in AdapNet paper.
- In figure 8 is the driven trajectory visible, which was 4.52 km long.
- The trajectory started at the Freiburg Machine Learning lab, made a sharp right turn at the Wild West Club, and entered the Milleniumswald (48.021309877509104, 7.824940020357156)
- It is possible to get an infrared image from this location from Eurnetsat, unfortunatelly the maximum zoom is 4x:
- Also cloned AdapNet. According to the Readme, this model needs a pretrained resnet_v1_50, which can be downloaded from this page, including the code to read it. In principal the model should be called with from tf_slim.nets import resnet_v1. In resnet_v1.py the tar or ckpt file is called with scope='resnet_v1_50')
February 15, 2022
- Today Weijie Wei presented a paper with code. It describes the SensatUrban dataset (Cambridge recorded with a drone), including a solution (APVNet which combines three branches ). Note that this code was the winner of the Urban3D challenge at ICCV2021.
- The dataset is comparible with semanticKitti, but now a point-cloud including RGB.
February 10, 2022
February 7, 2022
February 2, 2022
- This overview paper (cite IEEE Transactions on ITS) contained several multi-spectral datasets:
- S. Hwang, J. Park, N. Kim, Y. Choi, and I. So Kweon, “Multispectral pedestrian detection: Benchmark dataset and baseline,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2015, pp. 1037–1045
- K. Takumi, K. Watanabe, Q. Ha, A. Tejero-De-Pablos, Y. Ushiku, and T. Harada, “Multispectral object detection for autonomous vehicles,” in Proc. Thematic Workshops of ACM Multimedia, 2017, pp. 35–43.
- Q. Ha, K. Watanabe, T. Karasawa, Y. Ushiku, and T. Harada, “MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes,” in IEEE/RSJ Int. Conf. Intelligent Robots and Systems, 2017, pp. 5108–5115
- Y. Choi et al., “KAIST multi-spectral day/night data set for autonomous and assisted driving,” IEEE Trans. Intell. Transp. Syst., vol. 19, no. 3, pp. 934–948, 2018.
-
- A comparison on traffic light recognition algorithms based on classic methods is made in Table V of Overview paper, evaluated on La Route Automotive dataset.
January 27, 2022
- Had some difficulty to see how the Goal/Question/Metric method was applicable to writing a thesis, but Figure 3.2 from this guide explains a lot:

- The Treats to Validity in literature studies (in Software Engineering) are discussed this paper. Nice is in that this paper Snowballing is mentioned.
January 17, 2022
January 7, 2022
- The A203 carrier board promisses additional I/O for a Jetson boards, but most functionallity is already provided with the Nano (GPIO/SPI, etc). So it seems only handy when using a M2 Disk or CAN.
January 5, 2022
- Looking in the python-code of breadboard Starter Kit. There are two versions of Blink. The first uses the library RPi.GPIO, which is also part of PiWiring, so restricted to regular Rasberry Pi boards. The second one uses gpiozero, which can be installed with pip install gpiozero. This library has a number of default_factories to get the pin configuration, but the Jetson nano is not part of defined (yet).
-
- Used gparted to erase all partitions on the 64 Gb SD card, and started dts init_sd_card again.
- Putting power on the USB-C port.
- Although the flashing failed, the system now boots. It indicates that a reboot is needed, but for the moment I could login with the default username.
- The system seems to be up-to-date, although that ways because the repositories could be reached. Doing an upgrade for more than 200 packages. Keep on getting warnings on OC Alarm (no stable 5V). Switched the power profile to 5W with the command sudo nvpmodel -m 1. The result is that CPU2 and CPU3 are switched off, but the OC ALARM is gone (see this notes. Providing power via my workstation, still fails when I switch back to sudo nvpmodel -m 0. When providing the power on USB-C with my 45W power supply, the Nvidia Jetson works fine on 10W. Yet, during booting the realtime docker image fails to start.
- Checking with docker container list, which reports that no docker daemon is running.
- Restarted, luckily the containerd.service warnings are gone. Got a wpa_supplicant error. Tried the tricks from this post, bu receive that the ioctl is not permitted (and wlan0 is not connected after that). Maybe wrong driver?
- Did a sudo systemctl status containerd.service, but this service (and docker.service) were dead (vendor preset is enabled, but now disabled).
- Downloaded the get-docker.sh script as suggested by this post, which repairs both services. With docker image list I see 17 images, but none of them is started as container.
- Read development guide.
January 4, 2022
- Installed the code from WiringPi and Starter Kit.
- Wired up the first example (Blink a LED), but wiringPi is dedicated to genuine Rasberry Pi boards.
- Even the command gpio readall is from wiringPi.
- The GPIO naming of the Jetson is also not completely the same as the Raspberry Pi naming.
- Instead continued with the Jetson tutorial.
- Installed sudo pip3 install Jetson.GPIO.
- Yet, no rules are installed in /opt/nvidia/jetson-gpio/etc. There is only /opt/nvidia/jetson-io/boards, which defines the 40-pins for different models. Checked /boot, which seems to indicate that I have p2597-2180-a01-devkit, although there is also a dtb-file for the p3448-p3449 model. Yet, the box indicates that I have mode P3450. That cannot be found in boards, only the p3448-p3449.
- Finally found the example code at /usr/share/doc/jetson-gpio-common/samples . The script simple_out.py puts alternating an 0 and 1 on pin 18, so I moved the wire to GPIO18 and the LED is blinking.
-
- Continue with the recommended Display driver.
- I tried dmesg | grep i2c, but this returns tegra-i2c 7000c400.i2c: no acknowledge from adress 0x3c. The wires are not connected yet, so I should check again. Yet, lsmod | grep i2c shows nothing.
- Following the instructions from Jetson Hacks.
- Installed sudo apt-get install libi2c-dev i2c-tools. Continue with sudo -H pip3 install --upgrade luma.oled. Did sudo usermod -a -G gpio,i2c jetbot (spi was not a group yet).
- Did sudo i2cdetect -y -r 1, which shows that address 0x3c is used.
- Run the luma hello-world example (with rotation 0), which works (but after a few seconds also the eth0, wlan0, mem and disk are displayed, which is a program from the jetbot).
- According to this Jetson Hack, the service can be found at /etc/systemd/system/pioled_stats.service. Yet, I don't see that service there. Checked the running services with service --status-all, but I don't see that any pioled service running in the background. Yet, with systemctl list-units I see jetbot_stat.service running. Stopped this service with sudo systemctl stop jetbot_stats.service and hello world is displayed:
- It should also possible tos use CircuitPython to control the display, following these instructions.
- It seems that pip3 install adafruit-blinka was already done, so I should do the blinkatest.py.
- Strange enough I couldn't install adafruit-circuitpython-displayio-layout (no matching version found), but I could install adafruit-circuitpython-ssd1306 and adafruit-circuitpython-display-text. The latter downloads adafruit-blinka-displayio. Yet, displayio fails on importing Bitmap (future annotations not defined), while python3 is the expected v3.6.9. Yet, the three pixels example works fine.
- Seems that the future annotations is only available for python3.7. Did sudo apt install python3.7 and sudo apt install python3.7-dev, followed by python3.7 -m pip install setuptools, python3.7 -m pip install adafruit-blinka, python3.7 -m pip install cython, python3.7 -m pip install pillow, python3.7 -m pip install adafruit-blink-displayio, adafruit-circuitpython-ssd1306 and adafruit-circuitpython-display-text.
- Used this PIL example to print "Hello World" (with PIL's ImageDraw.text()).
- Also made a mini-script ~/src/i2c-display/ssd1306_turn_off.py, which nicely works.
January 3, 2022
- The Open3D library has a major update, with better integration into TensorBoard and Numpy.
- This code is also tested on Nvidia Jetson board (with Ubuntu 18.04).
-
- GeoSignum has Cloud based LiDAR processing, including Automated Tree Mapping.
-
- Put the SD-card in the Duckiebot DB21, but only the LEDs at the back light up, the start button, and the LED on the Duckiebot hat. See no light on the Jetson. Tried also to give the direct power to the Nvidia Jetson, but that doesn't work.
- Tried the SD card in another Jetson, but this is a 4Gb variant. The Nvidia flashscreen is visible, but no login appears.
- Yet, after charing a little bit longer I hear the fan starting (and I see the Jetson led light up green). Try again, with an SD card. The fan starts, but I see no Jetson led (yet).
- Looking in the mean time towards breadboard Starter Kit. Put the SD card of the JetBot in the free Jetson, and connected the GPIO cable (side extention to the outside).
- Made a wired connection and did an update / upgrade.
- Tried to get the wireless Realtek RTL8811 working, by following the instructions from this github page. Although the Readme only indicates kernel 5.9 (while the Jetson is based on kernel 4,.9), the build script seems to work (make -j2 KVER=4.9.140-tegra KSRC=/lib/modules/4.9.140-tegra/build).
- That works.
Previous Labbooks






















