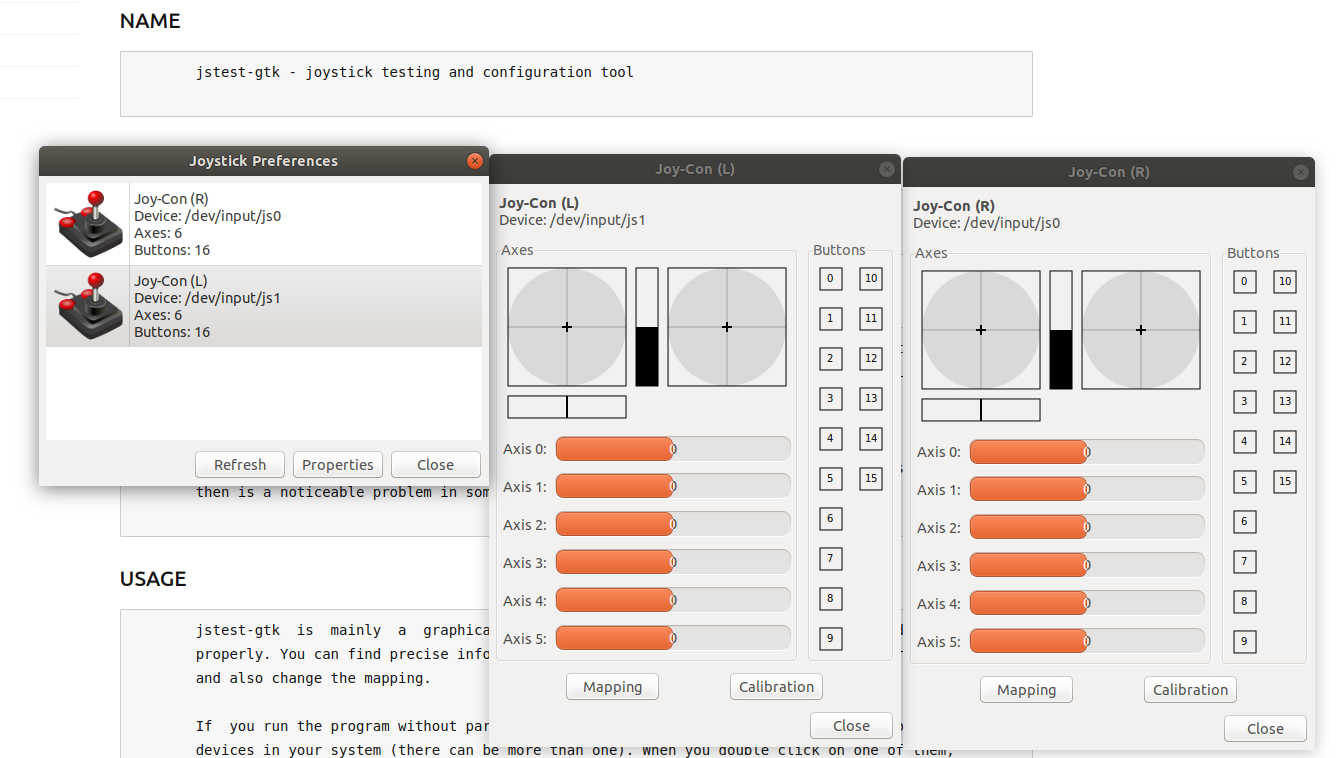
Tested the robot with the Joy-Con controllers. There is a preset for this controller, used the combination. Left is forward / backward (inverted axis), right controller is used to turn. The Y-button-2 toggles the headlight, the X-button-0 the Speaker, the B-button-3 seems to be the Microphone, although I only hear the motor.
Tested on nb-ros, but after a while the computer gets slow.
Was able to connect both Joy-Con controllers again (by removing and reconnecting them).
FrodoBot gave a camera-view, but didn't respond to the controller. 2nd try, with keyboard not even gave an image anymore.
Try again, with nb-dual (native Ubuntu).
Installed jstest-gtk.
Testing Joy-Con(L). The stearing appears on Axis 4 and 5, and gives -32767 for forward on Axis4. The Control bindings from the Dashboard indicate NaN when waiting on input.
Tried a calibration, which changed the input-range from -1 to 1, but still NaN in the Controller Bindings of the Dashboard.
Looked at Joy-Con(R). Y seems to be button-3, X is button-1, A is button-0, B is button-2.
Lets try with the X-box controller (Windows first). Otherwise, try Yuzu mapping.
Unfortunatelly, the server seems to be down, the Bot is offline.
October 5, 2024
Found several chargers that fit the Frodobot. The connector indicates 12V, but specifications indicate 18-25V. The chargers needs also to be 4A, to get 93 WH.
The Frodobot was actually still charged, just was not patient enough with holding the button.
Yet, the dashboard stills indicates that the bot is not available.
October 4, 2024
Testing the dashboard. It gives 'bot not available'.
Control with the sdk is possible. Don't forget to run the ~/git/vSLAM-on-FrodoBots-2K/recording/setbot.sh and hypercorn main:app --reload in ~/git/earth-rovers-sdk.
At nb-dual (native Ubuntu) the two controls can finally be found, only the left should be used.
Yet, it seems that only the Emergency stop is correctly configured:
Detected joystick: Joy-Con (L)
Use Joy-Con to control the car.
Move the left stick for forward/backward and rotation.
Press 'Minus' button for emergency stop. Press 'Plus' to resume. Press 'Home' to exit.
Successfully sent command: linear=0, angular=0, lamp=0
Logged data in TUM format: 1728060419.551000 0 0
Emergency stop activated
nb-ros had some troubles. After a reboot the terminal worked again. Did a sudo apt update.
October 3, 2024
Tried to add yesterday's recording to IEEE dataport, but only the non-visual records can be uploaded.
Uploading the files to figshare, using manage files.
This dataset is currated by Qi, so it has sequence of images, instead of movies.
Received the Joy-Con yoystick from Qi. Tested it with jstest-gtk, which seems to work, although both sticks continue to display the search pattern:
The data is all part of one project, but that is not visible from outside. Added links between the files. Also made a blurred version of the rear-camera:
September 26, 2024
Downloaded yolox_s.pth from github, and moved those weigths to ~/second_icra_experiment/YOLOX_outputs/yolox_s/best_ckpt.pth
Now the command python3 ~/git/vSLAM-on-FrodoBots-2K/run_video.py image --path TUM_Dataset/rgb/front/ --exp_file /home/arnoud/.local/lib/python3.8/site-packages/yolox/exp/default/yolox_s.py --save_result works.
Combined the pngs into a movie-file with
cat *.png | ffmpeg -f image2pipe -i - output.mkv
Next export PYTHONPATH=${PYTHONPATH}:~/git/Lite-Mono
Takes half an hour, but succeeded with executing python3 ~/git/vSLAM-on-FrodoBots-2K/video_depth_prediction.py --video_path TUM_Dataset/rgb/front/output.mkv --output_path output_video_depth.avi --load_weights_folder ~/pre-trained-models/lite-mono/lite-mono-8m --model lite-mono-8m
Result:
Met at ICRA@40 one of the participants of the Earth Challenge, Arthur Zhang from UT Austin (team Longhorns).
Did some experiments with modifying the calibration of the front camera of the FrodoBot.
Making the focal length 2x as small (f=[200,300,400]):
Making the focal length 2x as large (f=[500,600,800]):
Also modified the skew from Eq. (2.57) of Szeliski's book (s=[100,200,400]):
Experimented also with the radial and tangential distortion (k1, k2, p1, p2, k3), see OpenCV calibration:
September 4, 2024
Today a good discussion with the people from FrodoBot.
Actually, there are multiple competition taken place at IROS.
Went into the WSL Ubuntu 22.04 particition. Updated the earth-rover-sdk, which should now be v4.3.13 (extra information for missions), updated this morning.
Activated a Pay by Mb, but after 2h hours, grabbing only one image, my credit was already depleted by 3 euro (equal to a unlimited day).
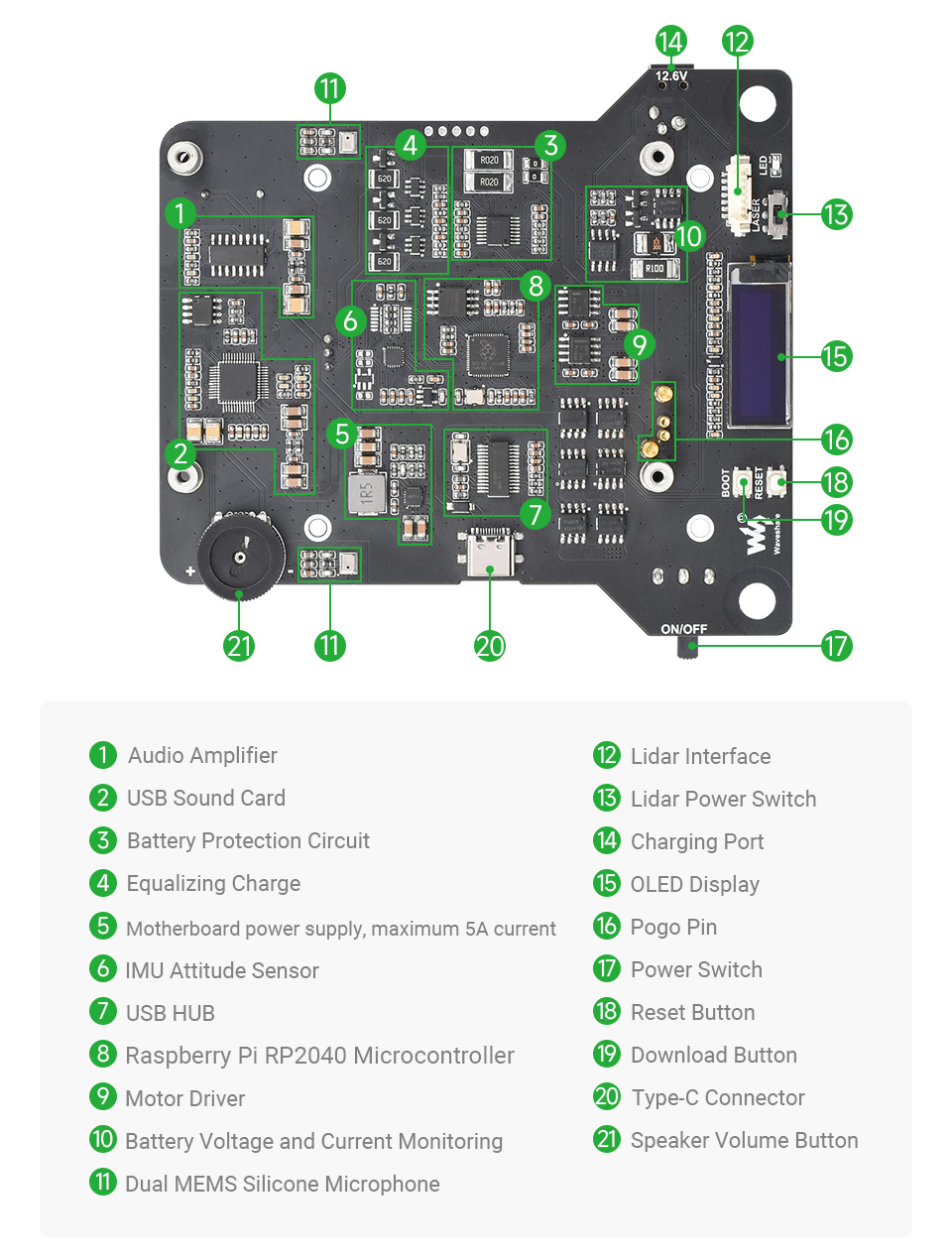
The main-board of the FrodoBot is a TC-RV1126 Stamp Hole Core Board, which is build around a Rockchip RV1126 processor. That is a Quad-core ARM Cortex-A7, which additional a NPU for PyTorch algorithms. It is build on top of a BuildRoot Linux system, and supports 3 cameras (2 on the custom Ox6E), but also Ethernet and Wifi (not on custom 0x6E). Several IO interfaces are provided, only one official USB 2.0 OTG (and plugins as USB 2.0 host).
It supports a MIPI_DSI interface for the Display, which is also not on the custom 0x6E.
July 31, 2024
Received an invitation for a survey on 'Robotability: computing plausibility of robot deployment in the wild'. Seems to be based on this extended abstract on arXiv:2404.18375v1.
The paper comes with a github, which contains a HardWare and Software list (ROS1 based). Both lists are not very specific.
Recorded 12 images for calibration. When doing a request, the audio-stream and video-stream in Frodobots SDK stops. First recording is bad anyway: Format seems OK, but much smaller (and black). Could use the Dashboard to see if it was a good recording. Lets see how to use that in opencv calibration software.
Worked with OpenCV tutorial, which works fine for the 8x5 fixed board.
Yet, the reprojection shows that only 6 images are used, and but the norm cannot be calculated. The calibrateCamera() function returned a value of 3.171087, without an indication what a workable value could be.
Created a function to calculate the average sum of Euclidean distance, because the norm calculation of OpenCV never returned. Result:
Read image front_camera_recording_31_07_2024_11_17_03_12.png
Read image front_camera_recording_31_07_2024_11_14_33_04.png
Read image front_camera_recording_31_07_2024_11_16_53_11.png
Read image front_camera_recording_31_07_2024_11_14_42_05.png
Read image front_camera_recording_31_07_2024_11_13_14_02.png
Read image front_camera_recording_31_07_2024_11_16_20_08.png
Read image front_camera_recording_31_07_2024_11_16_44_10.png
Read image front_camera_recording_31_07_2024_11_14_20_03.png
Read image front_camera_recording_31_07_2024_11_16_36_09.png
Read image front_camera_recording_31_07_2024_11_17_45_13.png
Read image front_camera_recording_31_07_2024_11_15_48_07.png
Calibration result: 3.1710869705777776
Height - Width: 320 480
ROI: (0, 0, 0, 0)
project points: 0
Average sum of EuclidianDistances : 3.209075927734375
project points: 1
Average sum of EuclidianDistances : 2.130724334716797
project points: 2
Average sum of EuclidianDistances : 2.9747968673706056
project points: 3
Average sum of EuclidianDistances : 2.3748769760131836
project points: 4
Average sum of EuclidianDistances : 1.7771297454833985
project points: 5
Average sum of EuclidianDistances : 3.9156360626220703
total error: 2.730373318990072
This are the six images where the corners could be found:
This are the six images where not all corners could be found:
So, I have to record the images closer by, or use a larger chessboard.
Also tried the example code from OpenCV, which also defines the square_size. The same good images were found, but now the calibration finished:
RMS: 1.7587458090793322
camera matrix:
[[2.35588986e+03 0.00000000e+00 2.33527863e+02]
[0.00000000e+00 7.45546509e+02 1.77065916e+02]
[0.00000000e+00 0.00000000e+00 1.00000000e+00]]
distortion coefficients: [-7.43327022e+00 7.07643289e+01 2.50064523e-01 2.58636889e-03 3.19107274e+03]
The result for the first of the six good images (original, corners, undistorted:
This are undistorted versions of the six images where not all corners could be found:
When looking to the ground pattern, still quite some distortion is there.
Added the square_size to the original code; now a ROI is found:
Calibration result: 45.459618728245886
Height - Width: 320 480
ROI: (188, 165, 45, 42)
Crop height in range 165 207
Crop width in range 188 233
There is still some difference in the subpixel kernel. The calibration result and RMS should be the same. Also the camera_matrix should be equal (or the kernel is important):
camera matrix:
[[116.20368417 0. 225.86856249]
[ 0. 29.67793984 150.06270441]
[ 0. 0. 1. ]]
distortion coefficients: [-2.66804579e-02 2.50713343e-04 1.05037900e-02 -2.03329176e-03 -7.39008767e-07]
This camera_matrix model clearly doesn't work on the validation image:
Changed the kernel size from 11x11 to 5x5. The result is even worse:
Calibration result (RMS): 62.43071056211107
camera matrix:
[[133.50431767 0. 239.50001051]
[ 0. 186.16863993 159.4999816 ]
[ 0. 0. 1. ]]
distortion coefficients: [-5.37941574e-02 5.83210780e-04 -7.94211267e-03 -1.80775280e-02 -1.61955665e-06]
Height - Width: 320 480
ROI: (4, 18, 46, 80)
If I use the 5x5 kernel but without multiplying with the square_size I got even worse results:
Calibration result (RMS): 61.13449826289332
camera matrix:
[[133.52362107 0. 239.50000967]
[ 0. 186.12125986 159.50001221]
[ 0. 0. 1. ]]
distortion coefficients: [-4.28695404e-02 3.08188009e-04 -2.15478474e-03 -1.20585057e-02
-5.75866933e-07]
Height - Width: 320 480
ROI: (2, 51, 76, 33)
Made an error with (h,w). When correctly defined I get:
Calibration result (RMS): 2.042224627414515
camera matrix:
[[476.80163398 0. 215.80100286]
[ 0. 393.40592637 135.31378937]
[ 0. 0. 1. ]]
distortion coefficients: [ 2.78038215e+00 -5.15627383e+01 3.82495029e-01 -4.73224787e-02
2.29678621e+02]
Height - Width: 320 480
ROI: (216, 180, 30, 29)
Lets see what camera matrix Qi Zhang will find with more images. His intermediate result was:
camera matrix:
[[268.26404607 0. 136.33706814]
[ 0. 236.65326447 159.24308533]
[ 0. 0. 1. ]]
distortion coefficients: [-0.16671656 -0.29542598 0.00111289 0.13717033 0.14070511
Webbrowser of the SDK indicates "Failed to retrieve tokens"
Went to my FrodoBots Dashboard. My robot is offline. The Blue LED of the GSM is blinking.
Tried my first movement. The suggested command is 10cm forwards and 45 degrees turn (more or less)
The request for data gives:
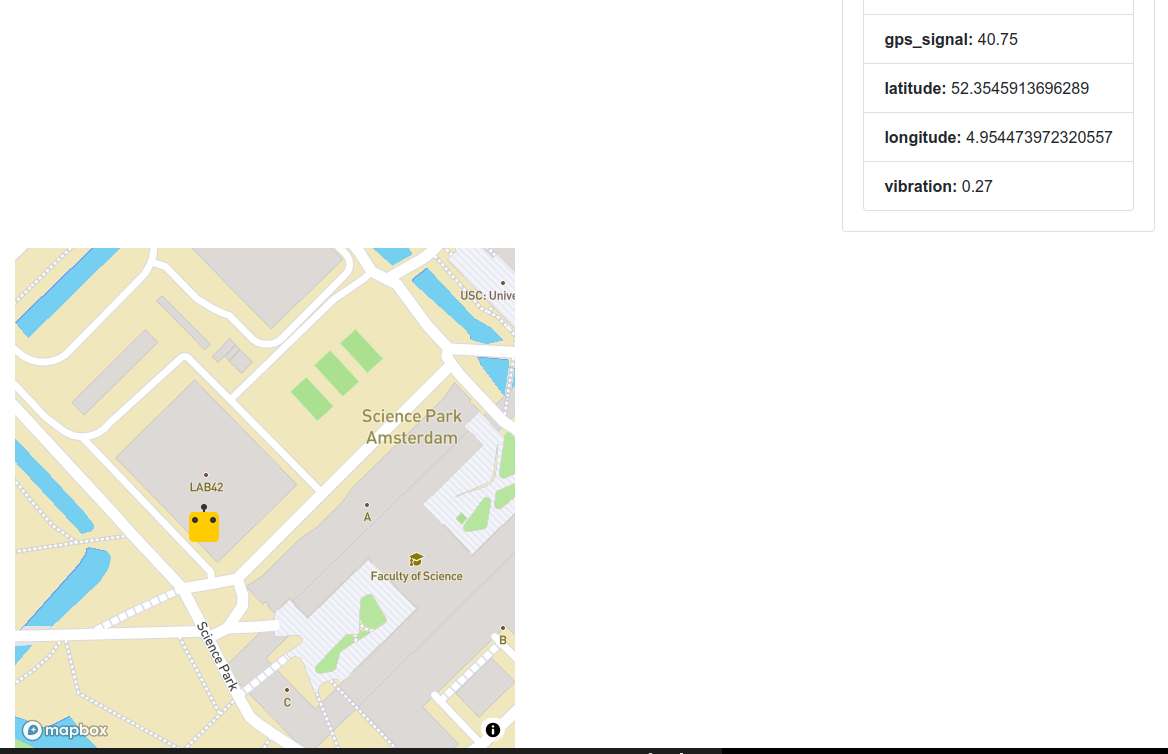
{"battery":100,"signal_level":5,"orientation":86,"lamp":-1827685240,"speed":0,"gps_signal":34,"latitude":1000,"longitude":1000,"vibration":0.2}
The request for a screenshot gave a {"video_frame": "xxx", "map_frame": "yyy", "timestamp":1722345758"}, but in the directory where I started the hypercorn servers I also saw that a screenshot.png and map.png was stored. The map.png is still empty white, but the screenshot.png gives an image from the front-camera.
Moved the robot outside. The GPS-signal went up, the latitude and longitude became less than the default 1000, and the image at bottom became filled with a map from mapbox:
I controlled the robot with manual drive interface, so when I requested the via the hypercorn server the drive interface lost its map and the hypercorn server crashed:
~/.local/lib/python3.8/site-packages/pyppeteer/connection.py:69> exception=InvalidStateError('invalid state')>
Traceback (most recent call last):
File "~/.local/lib/python3.8/site-packages/pyppeteer/connection.py", line 73, in _async_send
await self.connection.send(msg)
File "~/.local/lib/python3.8/site-packages/websockets/legacy/protocol.py", line 635, in send
await self.ensure_open()
The code to send the video_frame as JSONResponse can be found in line 224 of main.py
It would be intersting to see if Diffusion4RobustDepth algorithm would outperform LiteMono. Yet, speed versus accuracy will remain an issue for our real-world system.
It gives at least a more quiet view on the nuScenes and DrivingStereo dataset (qualtitative result)
For the nuScenes dataset 4 state-of-the-art algorithms are listed. The Depth Anywhere was already without this boost the winner.
I saved it on my native Ubuntu of nb-dual on ~/data/FrodoBots-2K/output_rides_10/
The merge failed on missing space on the device. Removed the zip. The result is a 10Gb rgb.ts
After the merge, there is still 500Mb left on the device. Maybe I should merge part of the rides
Qi uses the algorithms downloaded on his local computer. For instance, Lite-Mono requires a pretrained model.
Lite-Mono is a paper with code and pre-trained models. Downloaded lite-mono8m and unzipped it in ~/pre-trained-models/lite-mono/lite-mono-8m_640x192
Run PYTHONPATH=${PYTHONPATH}:~/git/Lite-Mono; python video_depth_prediction.py --video_path ~/data/FrodoBots-2K/output_rides_10/rgb.ts --output_path output_video_depth.avi --load_weights_folder ~/pre-trained-models/lite-mono/lite-mono8m_640x192 --model lite-mono-8. Actually, I had to use in /home/* instead of ~
So the prerequisite is to download the Lite-Mono code. This also requires to do python -m pip install timm.
Activated it on a single run (ride_28152_20240406071004), which required 2h30 to process on my laptop (no GPU). But the result is nice:
The last recording (ride 28152) was from the same city.
There are two video playlist, one panorama for the front and one fisheye for the back:
July 2, 2024
Next dataset is download is outdoor_drive_10 (12Gb).
Looks like I did the last download from my native Ubuntu drive, because my current WSL is quite empty after I needed a WSL1 reinstall for Vision for Autonomous Robots course.
Connected my Discord account to frodobots testdrive, where a support team is active.
Would be interesting to couple the test-drive at Holland-America Terminal with the Scene generated from Satellite with Sat2Scene (paper with code). Yet, that would require the generation of a point-cloud.
June 25, 2024
Looked at the provided helpercode, which is a Jupyter notebook with more details on the csv-files and how to display the frames.
No details about calibration or rectification. Also no details on which outdoor_ride contains which city.
Looked at the Discord group. On June 18 a user was also asking for the camera intrinsics and extrinsics from a chekerboard calibration.
June 24, 2024
Unzipped the output_rides_23.zip, the smallest (2Gb) archive from the FrodoBots-2K dataset.
This archives contains several recordings, I looked at the latest. The directory is called ride_40305_20240504100410, where the last part of the name indicates the date of the recording (used epochconverter.com to covert the unix-timestap 1714817062.533 (first frame) to Saturday 4 May 2024 10:04.
That created a lot of frames (killed it at frame #9604). According to the front_camera_timestamps_40305.csv, there were #17926 frames. This is frame #9604:
Created a new SceneLib2/data/SceneLib2.cfg with the settings:
cam.width = 1024;
cam.height = 576;
cam.fku = 195;
cam.fkv = 195;
cam.u0 = 512;
cam.v0 = 288;
cam.kd1 = 9e-06;
cam.sd = 1;
Only the cam.width and height are known. I have set cam.u0 and v0 to half this value, a kept the rest as initial. Difficult to estimate those without calibration.
Running ./MonoSlamSceneLib1 doesn't work, not even for the original *.cfg. Trying a reboot, because it seems that no Linux display pops up. Also xclock fails.
Rebooting helped. Was able to perform MonoSLAM on the outdoor_ride23, although no features were found:
Hypothesis is that also the kernels have to be scalled for the higher resolution. A good first attempt would be to see if the ffmpeg conversion could also reduce the resolution (for another drive in this set).
June 19, 2024
At IROS 2024 there will be Earth Rover challenge. The dataset for this competition can be found here. Maybe nice to combine with ICRA@40 (deadline June 30).
Already on March 2022 there is complaint that several issues posted on github are not solved, and ROS1 seems abandoned.
On July 2022 somebody was working on a Raspberri Pi, yet no arm-libraries are available. Also an issue with ROS2 Galactic was mentioned.
The only SDK still available is python (v1.0.7). The documentation is gone. The WayBack machine could also not find https://radariq-python.readthedocs.io/.
The youTube Getting Started shows how to use their RadarIQ Controller, with is no longer available for download.
I think to remember that I downloaded that viewer when I bought the sensor, but cannot find it in the Autonomous Driving labbooks. I also didn't install it on my home computer. Found the pledge (Dec 2020), with delivery around April 2021.
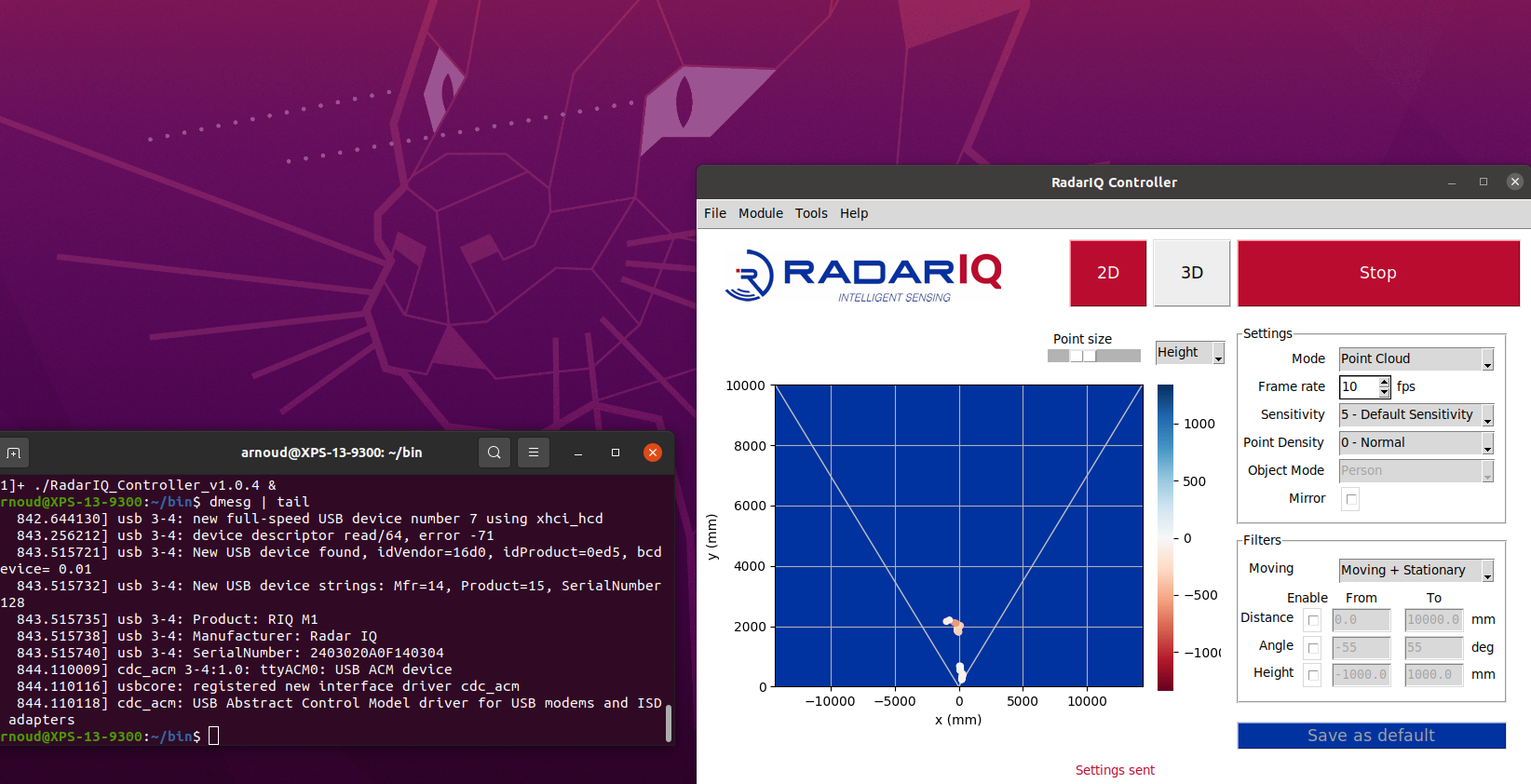
Found v1.0.4 (also the latest download from RadarIQ getting started of the RadarIQ_Controller on nb-dual (native Ubuntu 20.04 partition) - March 2022.
The controller gives some font warnings, but starts up nicely. No RadarIQ models found, so time to connect the sensor. The viewer starts from the command line, but from the File Explorer it complains that it is shared library, not a executable.
Connected it with USB-micro to USB-B, linked to a USB-B to USB-C converter. The third time I see the device registered with dmesg | tail. At that moment the viewer also sees the RadarIQ module:
I already installed radariq, because from radariq import RadarIQ also worked. Even the Usage example worked nicely, printing all rows.
Looked into the package at ~/.local/lib/python3.8/site-packages/radariq, but no examples inside the package (that has to be found at the private github page).
Found the radariq_ros in ~/ros2_ws/tmp/radariq_ros (March 31, 2022).
Followed the instructions in the readme of this directory. Made ~/radariq_ws/src. The colcon_build was sucessfull (some rosidl policy CMP0148 warnings). Rviz starts, showing the radariq module as a blue square (RoboTModel succesfull loaded). The point-clouds are not visible, because the frame [radar] does not exist. With ros2 launch radariq_ros_driver transfer_base_radar.launch.py (and transfer_base_link) the TF tree can be build. Still no point-clouds visible.
The radariq_object.launch.py should display the radariq_markers (don't have those). ros2 topic list also don't show that topic. /radariq is one of the topics, yet I see no echo.
Looked at start of view_radariq_pointcloud.launch.py. Three nodes are started, including point_cloud_publisher. Yet, it fails on trying to do riq.set_certainty (conflict with latest python-package version).
Commented that line out, point_cloud_publisher still fails, but now more fundamenatlly. Tries to do create_cloud, which calls pack_into() with three items (instead of the four expected). Seems a python version problem.
At the same time an error occors with get_logger().error(error) (argument should be string, not error).
Looked with pip show radariq. I have v1.0.6 installed (v1.0.7) is the latest. Also note that radariq-ros-driver depends on this package, but that package cannot be found (not with pipy.org search, nor with pip install radariq-ros-driver==. From package radariq itself only v1.0.6 and v1.0.7 are available to be pip installed.
June 5, 2024
The Autonomous Grand Challenge has now several submissions on Open Review, which is not that strange because the deadline was moved forward to June 3.
For the Occupancy and Flow the following submission is made:
The Thorgeon Rechargeable Li-ion Battery 18650 3.7V 1200Mah are too long to fit into the AI Racer PRO. The Thorgeon batteries are 69mm long, which was specified as package-dimension.
I ordered the batteries I used before 18650 batteries which are less than 67mm (actually 65mm).
Ordered the Thorgeon Rechargeable Li-ion Battery 18650 3.7V 1200Mah for the DART. Also ordered the brass rings.
For velocity readings, they recommend to both include magnets and a white ring on the wheels. To read those two clues, also a Hall sensor and IR sensor is needed. Do not see that in the part list.
The Hall sensor is just three outputs, connected to the Arduino. Could be a U1881, just like this design
The IR sensor gate seems to be HW-201. The same shop also has Hall sensor, which has some extra resistance and/or capacity. The sensor itself is a3144. The last one is a unipolar sensor.
The u1881 seems to have its connectors at both sides, instead of one side. So, the a3144 seems a good choice.
Instead used the SD card from NanoSaur (and the Wifi-stick from DB21).
Did some updates, but the screen became black during the procress. Started up again without problems.
Display worked on the big screen.
The China3DV is finished, the HuggingFace leaderboard is published.
For the Mapless Driving challenge no innovation award has been given. Only the first prize for Ren Jianwei, Shuai Jianghai, Li Gu, Zhao Muming from Xiaomi Automobile, Beijing Forestry University.
For the Occupancy and Flow challenge the innovation award went to Zhang Haiming, Yan Xu, Liu Bingbing, Li Zhen from Chinese University of Hong Kong (Shenzhen) and Huawei-Noah, for designing a multi-modal fusion distillation Paradigm, uses a multi-modal teacher network to distill the student network at multiple scales, and effectively utilizes simulation data sets for joint training, achieving good performance. The first prize went to Zhou Zhengming, Liang Cai, Hu Liang, Wang Longlong, He Pengfei from Xiaomi Robot.
April 2, 2024
The two CVPR competitions I have selected, have a sibling track at China3DV, where the deadline is already on April 10.
A team description paper is required, but are not visible (yet). The leaderboard will be published at the competition end at HuggingFace.
Both papers are high-impact papers (821x and 3247x resp.). I should check if this also applied to intersections.
Another innovation are the maneuver based decoder. At the highway it can be clustered to 2x3 maneuvers, how many do we use in our paper (my hypothesis: the same ammount, because we concentrate on the lane chosen when approaching the intersection. That works for breaking and switching lanes, but less clear how to classify the maneuver when other lanes crosses ours).
Saw two interesting intersection-papers that cite Social LTSM:
The first paper concentrates on Australian tangential roundabouts, with 4 clear conflict points.
The second paper is the other extreme, using drone data from 4 Indian intersections, including busses, two-wheelers and rickshaws, creating an overload of possible conflict points.
The second paper also cites Convolutional Social Pooling. A new paper to check is:
The introduction is organized in physics, planning and pattern-based predictions, which orginates from Human motion trajectory prediction. Does this also apply to vehicles at intersections? The Human Motion paper applies it to the application domain for self-driving vehicles, but especially towards vulnerable road users.
March 15, 2024
Yesterday one of the ICAI-PhDs presented SALUDA: Surface-based Automotive Lidar Unsupervised Domain Adaptation
Found a 12V - 1A Netgear charger, which connector fits (together with the other 12V chargers - less mA).
See no charger-led lighting up when connecting.
The 18650 batteries that I are less than 67mm (checked due to the note on the JetRacer page).
Looked at the Mini Pupper 2 - Lidar instructions. The LD Lidar is mounted on a 3D printed Lidar holder. The wiring is not specified, although the last OAK-D figure gives some clue.
The DART uses the YDLiDAR X4, which has a (micro?)-usb connector, although on the parts image also a 6-pin breakout board is visible (with 4-pins connected).
It seems that JetRacer ROS also uses a 6-pin connector to their LiDAR (connection 12):
The instruction manual only shows one part of the connection of the Lidar cables:
Received a TTL converter from the CO2 program of the Technical Center. The red led on the board lights up, but I don't see any drivers installed. The connectors on the LD Lidar are too close to each other to connect with the break cables. I could try the ones from the Qualcomm board, because those cable are smaller.
As the figure in section 5.3 of the LDRobot STL 06P datasheet indicates: the red wire is the TTL Tx with the LIDAR data output. The connector is a ZH1.5T-4P1.5mm
Plugged the CO2 TTL converter into nb-ros (Ubuntu 18.04). The device was recognized with lsusb as a QinHeng Electronics HL-340 USB-Serial adapter.
According to dmesg | tail the ch341-uart converter was attached to ttyUSB0, so it seems to work under Linux.
In section 5.6 they show a demo application; they connect the LD SPL-06 via a connector board (micro USB-ZH connector). The board is not specified.
On the ldrobot github, they specify a serial port module like a cp2102 module.
With this package, you start the ld06 node with ros2 launch ldlidar_stl_ros2 ld06.launch.py, followed by ros2 launch ldlidar_stl_ros2 viewer_ld06.launch.py. This is the same package as the Mini Pupper uses.
Cannot find a cp2102 module with ZH or JST connector.
On the JetRacer ROS. they use another LDrobot Lidar (A1), which they launch with roslaunch jetracer lidar.launch. The A1 is not in the list of supported sensor on the ldrobot github.
For the moment the LDROBOT STL-06P we have seems to be OK. 12m range, diameter 38mm, 5V, 290mA. Communication interface is UART@230400.
The RoboShop.eu has only the LDROBOT D300, also 12m range, which is a Development Kit with contains < href=https://www.ldrobot.com/images/2023/05/23/LDROBOT_LD19_Datasheet_EN_v2.6_Q1JXIRVq.pdf>LD19 Sensor (same interface), which seems to be Triangular LiDAR, instead of DTOF LiDAR. The Develop Kit has also a serial cable, a charging cable and a complaint board or speed control plate (i.e. control board). The D200 is based on the LD14P LiDAR, and has a USB adapter board and a serial test cable.
The battery was not specified. At Conrad you can specify the batteries with t-plugs. The lowest capacity pack was quite thick, so 7,4 V 3000 mAh 20C Eco-Line seems a better choice. Dimensions (l x b x h) 139 x 25 x 46 mm.
Actually, the 7,4 V 1800 mAh looks bigger, but has smaller dimensions (l x b x h) 87 x 35 x 17 mm.
Actually, there seem to be several synonyms on the plug system. You could also select the technology (LiPo) and Belastbaarheid.
When I select Softcase and Capacity and Belastbaarheid I got one option: Hacker LiPo 7.4V.
Note that also a BEC-plug is mentioned, but at build-instruction they only showing connecting the t-plug:
For the twisted Gaussian you nicely see the recording of the risks on the grid, comparible with the approach of Yue.
The naturalsitic driving article covers more complex scenarios (crossings with single lanes and only two vehicles). It predicts future trajectories, selects some key-points on both trajectories, calculate Gaussians with uncertainty for those keypoints, and calculates risk if the Gaussians from both vehicles overlap.
Another option is to add other perspectives, such as risks associated with angle and acceleration, such as:
The 2017 paper has local path candidates for both the ego-vehicle and the surrounding vehicles, which gives a gollission risk map for where they overlap. Yet, for a 3-lane highway scenario, not a complex crossing.
The 2020 paper concentrates more on the acceleration, but also on the high-way (following behavior). Nice from this paper is that they also tried to classify the behaviors of the surrounding vehicles.
The last possible extension is take the bidirection into account, like:
The studied scenario is at least a unprotected left turn (for a limited number of lanes and surrounding vehicles). Looks a bit like a particle filter how they do the predictions.