Labbook Dutch Nao Team
Error Reports
The head of Princess Beep Boop (Nao4) crashed twice when an ethernet cable was plucked in, but this problem disappeared after flashing. Seems OK 13 December 2016.
- Julia has a weak right shoulder (December 2016).
Bleu hips are squicking. Seems OK September 2015.
- Bleu sound falls away. Loose connector? September 2015.
- Nao's overheats faster when using arms than using legs.
Blue skulls is broken at the bottom: should remove its head any more.
Blue has a connector at the front which is no longer glued on position. Couldn't find a connector position.
Rouge has a broken finger at its left hand.
Started Labbook 2024.
Labbook Dutch Nao Team
December 19, 2023
November 28, 2023
October 4, 2023
- Read 'Neural Network-based Joint Angle Prediction for the NAO Robot' from Jan Fiedler and Tim Laue.
September 25, 2023
- It would be nice to reproduce this result with extending a Small-Size robot with a Jetson Nano.
- The accompanying 2022 Latin American Robotics paper.
September 21, 2023
- Got a message that I used an old support system, and should report issues at Aldebaran support.
- Updated the Nao administration with the request for pickup for Moos and Ferb.
-
- Looking if Maximum Class Separation as Inductive Bias in One Matrix could be the basis for an interesting 'Leren & Beslissen project'.
- The corresponding code gives examples for the CIFAR dataset (balanced and imbalanced).
- This method replaces the softmax operation. Yolo originally doesn't use softmax, although such layer can be added, as is done with Yolov3 (see this guide.
- Nice comparion of CPU/GPU performance of Yolo variants, but I was looking for a comparison of Yolo architectures.
- According to A Comprehensive Review of YOLO: From YOLOv1 and Beyond, one changed from v2 to v3 from softmax to binary cross-entropy (20 classes).
- Interesting could be to look at YOLOR, which has a single model for various tasks (classification, detection, pose estimation).
- Instead, YOLOX has two head (one for classification, one for detection).
- Yolov7 has even a course label and fine label head.
- DAMO-YOLO has both a small head, with only one linear layer for classification and one for regression.
- Yolov8 uses the softmax function for class probabilities.
- This paper has not been studied for Yolo classification heads.
September 12, 2023
July 27, 2023
- Created a LaTeX-source zip of the NERF-paper. Started with adding the packages like xcolor first, but decided to do sudo apt-get instal texlive-latex-extra, which solved all dependencies.
- Only modification I had to do was to remove the extra space in the bibiography command (which bibtex didn't like).
July 20, 2023
- Xavier will look at this CPPR 2022 to extract the mesh from NeRFactor.
July 7, 2023
June 26, 2023
- Joey opened up the TechnoLab robot to inspect the fuse of the battery-board. The fuse could be reached by removing all boards in front, but that was quite a delicate operation, with many frigile connections that had to be disconnected. Reversing this operation failed when one the leg-connections broke.
- So, we decided to let Sam be repaired at the RoboCup.
June 21, 2023
- Looking for other studies that reported a 'limited' boost when adding synthetic data to real data. The Synthetic Data generation using DCGAN for improved traffic sign recognition (2021) used Yolo v2, and doubled the dataset (around 200 images per class, augmented with 210 synthetic images). They reported an increase of 4% (88% to 92% for Yolo v2 with Densenet backbone) and 28% (61% to 91% for Ylolo v2 with Resnet 50 backbone).
- This Deep learning-based vehicle detection with synthetic image data (2019) does the experiment the other way around, adding a percentage of real training images to a synthetic set. They report that 20% of real images is already enough. Yet, they used Faster R-CNN.
- This Application Research of Improved YOLO V3 Algorithm in PCB Electronic Component Detection used Yolo v3, and created a joint dataset (50/50 real/virtual). The dataset only contained 50 images of PCB boards, but with many components on it that had to be detected. They used aggressive data augmentation to increase the size of the training set. They showed the improvement of transfer learing from a COCO trained network to one trained with this PCB dataset, but not further experiment with how many virtual images were added.
- This Synthetic images generation for semantic understanding in facility management (2023) paper uses Yolo v4, and compares 4 datasets. Dataset 1 is pure real, Dataset 2 is pure virtual, Dataset 3 is 50/50 and Dataset 4 is 90% virtual. Both mixed datasets performed better (77% and 79%) than the pure datasets (69% and 61%).
- Note that the last 10% real data of the last paper is below the recommended 20% of the 2nd paper. Tobie and our work indicates something on the other end of the spectrum: 10% to 20% synthetic data gives a boost, which levels after that.
-
- Looked for some classic synthetic dataset papers. Learning Deep Object Detectors from 3D Models (ICCV 2015) used CAD models for AlexNet.
- It points to one of the earliest attempts to Description and recognition of
curved objects (1977).
-
- Localisation of robots with synthetic data is not that easy to find.
- The paper Monocular UAV Localisation With Deep Learning and Uncertainty Propagation (2022) doesn't mention realted work on synthetic data for localisation.
- Checked Adversarial Training for Adverse Conditions: Robust Metric Localisation Using Appearance Transfer (2018). This paper has more related work cues, although most in day/night and summer/winter augmentation. Also synthetic views from other viewpoints are referenced (in between views).
- Most interesting reference seemed Learning-Based Image Enhancement for Visual Odometry in Challenging HDR Environments, but this mainly adds dark and over-exposure lighting conditions to the dataset (using ORB-SLAM for localisation).
-
- Had some difficulty to fine the number of parameters of the different versions. Yet, Table 4 of YOLOv4-dense: A smaller and faster YOLOv4 for real-time edge-device based object detection in traffic scene gives a good overview.
June 9, 2023
June 7, 2023
May 26, 2023
- The Lite 3 is less expensive than a Nao robot.
May 23, 2023
- Encountered a paper that used the chapter Logic-based Robotics as reference. The abstract seems a bit old fashioned (refering to STRIPS), but the rest of the paper uses a point-clouds to understand scenarios from RoboCup@Home and Rescue.
April 26, 2023
- The results of the training with less lighting variation are in. Training is now perfect:
detections_count = 22, unique_truth_count = 21
class_id = 0, name = ball, ap = 100.00% (TP = 21, FP = 0)
class_id = 1, name = robot, ap = 0.00% (TP = 0, FP = 0)
for conf_thresh = 0.25, precision = 1.00, recall = 1.00, F1-score = 1.00
for conf_thresh = 0.25, TP = 21, FP = 0, FN = 0, average IoU = 91.95 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.500000, or 50.00 %
- On the real data the results are 92.89% ap on the ball:
detections_count = 641, unique_truth_count = 290
class_id = 0, name = ball, ap = 92.89% (TP = 158, FP = 51)
class_id = 1, name = robot, ap = 72.60% (TP = 46, FP = 2)
for conf_thresh = 0.25, precision = 0.79, recall = 0.70, F1-score = 0.75
for conf_thresh = 0.25, TP = 204, FP = 53, FN = 86, average IoU = 62.43 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.827455, or 82.75 %
- A possible explanation could be is this range of lighting conditions matches better with reality, so I could use this results (and this range) in the paper.
- Again the file-size of the paper is too large (70mb while the limit is 20Mb). Trying to reduce the file-size in Adobe Acrobat. That helps, the reduced size is 488 kB, which can be uploaded.
April 25, 2023
- Two open questions for the RoboCup paper:
- What happens if I use 480 new real images? Will the mAP also improve from 87 to 94%?
- What happens if I use the 2nd set on the same initial weights as the first set (or did I)?
- On the second question, for synthetic_training_cleared.sh (April 14, 12:56) I used results/yolov4-tiny_3l_synthetic.weights (April 14, 12:56) as start. That one was preceded by yolov4-tiny_3l_bgr.weights (April 6, 17:40).
- The script transfer_learning.sh (April 14, 12:19) had results/yolov4-tiny_3l_rgb.weights (April 6, 16:24) as input, and was tested on results/yolo4-tiny_3l_synthetic.weights (April 12:18)
- The script nerf_generated_training.sh (April 17, 12:33) used results/yolov4-tiny_3l_synthetic_v2.weights (April 14, 15:03) as input.
- Fig 10c is actually the training that started on April 6, but which I copied April 14 (so yolo4-tiny_3l_synthetic.weights?)
- Fig 10b is actually the one generated on April 6, with synthethic_training.sh (which not exists). Looking at the time it is synthetic_training_cleared.sh (which used synthetic_weights), while in the afternoon I created synthetic_v2_testing.sh. That training should have created synthetic_v2.weights, the input of nerf_generated_training.sh and second_nerg_generated_training.sh.
- So the second question is answered, the same starting point was used for the two generated dataset. The first step can be removed from the paper. Remains the question why the training loss starts in Fig. 10b lower than where it ends in Fig. 10a.
- A nice ablation study would be to generate an set equal to the 2nd, but now with only have the variation in lighting conditions.
- For the 1st question, I could try to download new test-data from TORSO-21, with arguments --real and --train. Yet, I did a fast count on the dataset, which shows that the dataset only contains 6677 real images (so already used).
- The date of the annotations is 17 Nov 2022, so some there could be some additions. The train.zip is 4.8 Gb, test.zip is 0.85 Gb.
- First look what is availabe at ws3.
- Seems that Rogier made a copy, because his darknet_training contains a directory v6_images. In addition there is a directory v6_labels, with subdirectory dnt_all/ds0/double_class. This directory also contains frame_d images, which I unfortunatelly also used. Should look at ws3 for images younger than 10 Jun 2021.
- The all_image.tar on ws3 is from Feb 14, 2020.
- The /storage/dnt/home/dnt/Downloads/v2/ contains several recordings which are labelled top / bottom, so those are not used before.
- Looked into ferb_2019-11-24. Most images are made during setup, from #10699-10999 a ball is visible (but always on the same location).
- Looked into rohow/specialized/moos_20191130_solo test run. Looks interesting from #1076 onwards. The ball comes closer until #1874. Moos standup is interesting from top1348 - top1602. The ball enters again in top1758-1840.
- Unfortunatelly, I could not directly copy from ws3 to ws5, and ws3 is Ubuntu 22.04 machine, which not accepts the ssh-rsa protocol.
- First the Ablation study, with the dataset generated with half the variation in lighting conditions.
- Downloaded the dataset and extracted as /data/synthetic_unity_generated/third_set/less_variation_in_light/. Created third_set.txt with ls /data/synthetic_unity_generated/third_set/less_variation_in_light/images/*.png > third_set.txt. Created the split_third_set.py, and updated the third_obj.data to point to third_testing.txt and third_training.txt. Created a third_nerf_generated_training.sh, which used synthetic_v2.weights as start (as before).
April 24, 2023
- Continue with writing the RoboCup Symposium paper.
- Looking for good examples of the second_set for the paper:







































































- So, for the moment I have selected those images:
- Maybe I should replace camera image 367 for one with stronger shadows on the wall. I would also like one with the ball more on the front. With camera image 727 I have both.
April 21, 2023
- Training is finished. This time with a mAP of 44.1%:
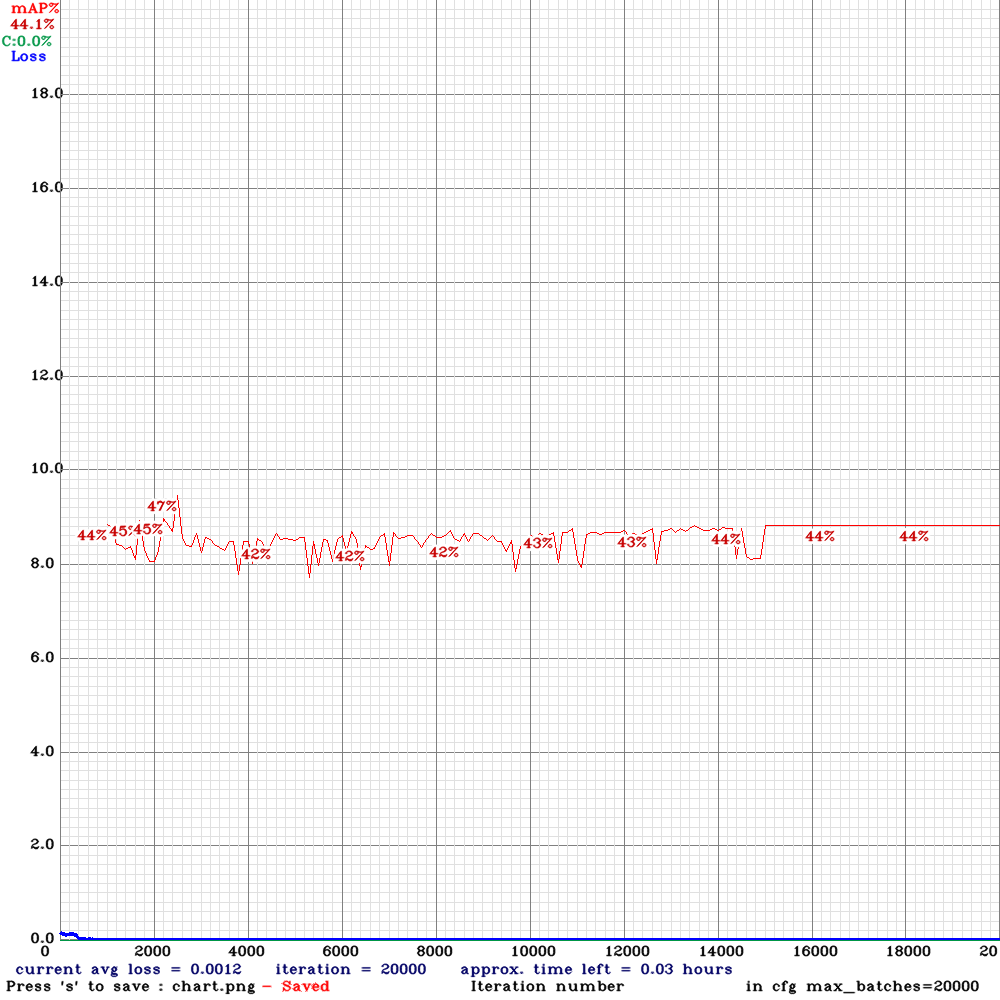
- The ball is not recognized, only the robot. Wrong training labels?
detections_count = 17, unique_truth_count = 17
class_id = 0, name = ball, ap = 0.00% (TP = 0, FP = 0)
class_id = 1, name = robot, ap = 88.24% (TP = 15, FP = 2)
for conf_thresh = 0.25, precision = 0.88, recall = 0.88, F1-score = 0.88
for conf_thresh = 0.25, TP = 15, FP = 2, FN = 2, average IoU = 66.88 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.441176, or 44.12 %
- Indeed, the labels seems to be swapped. This image has label 1 0.154296875 0.35544082605242255 0.0203125 0.030976965845909452, where the first integer means robot:

- Modified the labels (from robot to ball) manually. First did find *.txt -type f -size +0 > /tmp/non_empty.txt, followed by vi $(cat /tmp/non_empty.txt), and trained again. Now I get a mAP of 96.1% (which worries me if not some of the previous experience is included, or a few labels are still on the robot). Yet, the training curve looks nice:

- The result is not bad, but not really an improvement (84% on ball):
detections_count = 26, unique_truth_count = 17
class_id = 0, name = ball, ap = 84.00% (TP = 15, FP = 2)
class_id = 1, name = robot, ap = 0.00% (TP = 0, FP = 0)
for conf_thresh = 0.25, precision = 0.88, recall = 0.88, F1-score = 0.88
for conf_thresh = 0.25, TP = 15, FP = 2, FN = 2, average IoU = 73.74 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.419983, or 42.00 %
- Yet, the real test is on the real test-set. That looks better (92% on ball):
detections_count = 830, unique_truth_count = 290
class_id = 0, name = ball, ap = 92.05% (TP = 155, FP = 33)
class_id = 1, name = robot, ap = 77.67% (TP = 93, FP = 37)
for conf_thresh = 0.25, precision = 0.78, recall = 0.86, F1-score = 0.82
for conf_thresh = 0.25, TP = 248, FP = 70, FN = 42, average IoU = 60.65 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.848608, or 84.86 %
April 20, 2023
- Received a new dataset with 600 images.
- Extracted the tar-file in /data/synthetic_unity_generated/second_set/yolo/
April 19, 2023
- Trying to install this github yolo-labeling-tool at ws5.
- Installation of the requirements fails on mkl-service, which requires python3.7 (while ws5 has python3.6.9). Skipped this dependency for the moment.
- Running python3 main.py failed on import cv2 which raised numpy.core.multiarray failed to import. The numpy version is 1.16.5. The opencv version is not included in the dependencies.txt
- Looks like that the version of opencv is installed with apt (python3-opencv v3.2.0).
- Downgraded numpy to 1.14.5, which gets the start screen.
- Labelled all 256 images from moving. Started the training again. The mAP is a constant 50%, which could indicate that it only trains on balls (no robots):

- Yet, the result is as good (on the test set, which looks a lot on the training set):
detections_count = 52, unique_truth_count = 52
class_id = 0, name = ball, ap = 100.00% (TP = 52, FP = 0)
class_id = 1, name = robot, ap = 0.00% (TP = 0, FP = 0)
for conf_thresh = 0.25, precision = 1.00, recall = 1.00, F1-score = 1.00
for conf_thresh = 0.25, TP = 52, FP = 0, FN = 0, average IoU = 91.28 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.500000, or 50.00 %
-
- The Zip-NeRF paper points to this ICRA paper as the robotics application of NeRF. This paper extents Dense Object Nets
April 17, 2023
- Created real_trained_synthetic_testing.sh which validates the yolov4-tiny_3l_bgr.weights on the synthetic/obj.data. The results are quite good:
detections_count = 96, unique_truth_count = 53
class_id = 0, name = ball, ap = 95.13% (TP = 20, FP = 0)
class_id = 1, name = robot, ap = 94.71% (TP = 28, FP = 2)
for conf_thresh = 0.25, precision = 0.96, recall = 0.91, F1-score = 0.93
for conf_thresh = 0.25, TP = 48, FP = 2, FN = 5, average IoU = 81.26 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.949225, or 94.92 %
- Looked for clues on the --clear option of darknet.
- This blog includes hints how to integrate darknet with ROS.
- Downloaded the NeRF generated dataset. Created a list of images with .
- The python script split_train_image_bgr.py reads that list and spilt it in 80% train-set and 20% test-set.
- Training didn't make much progress, which is not strange because no labels are provided. Because the ball is always at the same location creating such label should be easy.
- Could look at this github yolo-labeling-tool to do it interactive.
- I also need a script to copy that label to a txt-file for each img in the directory.
April 15, 2023
- The rendering from Zip-NeRF from Google Research is quite impressive.
- The corresponding paper can be found at arXiv.
April 14, 2023
- Finally had time to look at the result of last weeks training. The training with the clear option finished succesfully:

- The resulting mAP is 92.3%, slightly below the previous training result of 94.9%.
- Run the transfer_testing.sh script which executes ../darknet/darknet detector map bgr_obj.data cfg/yolov4-tiny_3l.cfg results/yolov4-tiny_3l_synthetic.weights. This gives the result:
detections_count = 2155, unique_truth_count = 290
class_id = 0, name = ball, ap = 93.53% (TP = 147, FP = 7)
class_id = 1, name = robot, ap = 91.04% (TP = 113, FP = 71)
for conf_thresh = 0.25, precision = 0.77, recall = 0.90, F1-score = 0.83
for conf_thresh = 0.25, TP = 260, FP = 78, FN = 30, average IoU = 64.03 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.922847, or 92.28 %
- The bgr_obj.data points to train_bgr.txt and test_bgr.txt respectively. The test_bgr points to images_bgr/frame_?_*.png. The train_bgr.txt points to images_bgr/2?_0?_2018__15_44_10_*_upper.png and some images_bgr/frames_saves?_*.png, which is equivalent with the original train.txt and test.txt (only the bgr variant).
- I should have used synthetic/obj.data.
- Created , which used the weights trained with clear on the synthetic dataset. Result is far from optimal:
detections_count = 256, unique_truth_count = 53
class_id = 0, name = ball, ap = 76.21% (TP = 17, FP = 1)
class_id = 1, name = robot, ap = 58.54% (TP = 17, FP = 5)
for conf_thresh = 0.25, precision = 0.85, recall = 0.64, F1-score = 0.73
for conf_thresh = 0.25, TP = 34, FP = 6, FN = 19, average IoU = 59.62 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.673751, or 67.38 %
- Created a synthetic_training_cleared.sh which should start training with the previous weights, but this returns directly with a mAP. That was because I used ../darknet/darknet detector map instead of detector train. With train (and the -clear flag the training starts again.
- The chart at localhost:8090 starts with C:0.0%, but the intermediate mAP came as high as 98% and ended with a mAP of 96.2%
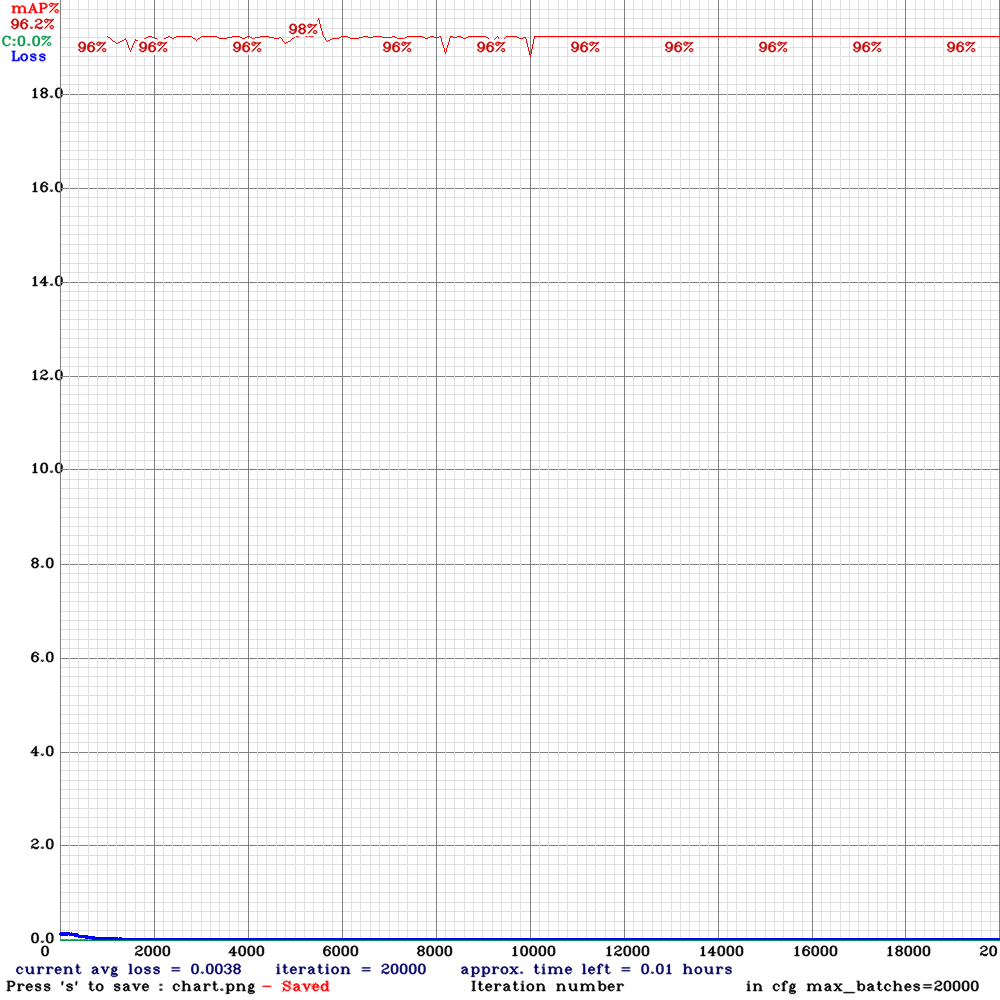
- Created synthetic_v2_testing.sh, which gives:
detections_count = 68, unique_truth_count = 53
class_id = 0, name = ball, ap = 95.65% (TP = 21, FP = 0)
class_id = 1, name = robot, ap = 96.67% (TP = 29, FP = 0)
for conf_thresh = 0.25, precision = 1.00, recall = 0.94, F1-score = 0.97
for conf_thresh = 0.25, TP = 50, FP = 0, FN = 3, average IoU = 87.32 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.961594, or 96.16 %
- Also run the synthetic trained network on the real data:
detections_count = 773, unique_truth_count = 290
class_id = 0, name = ball, ap = 92.78% (TP = 154, FP = 33)
class_id = 1, name = robot, ap = 80.99% (TP = 92, FP = 28)
for conf_thresh = 0.25, precision = 0.80, recall = 0.85, F1-score = 0.82
for conf_thresh = 0.25, TP = 246, FP = 61, FN = 44, average IoU = 62.52 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.868848, or 86.88 %
- Added Yolo v8 to the reference list of the paper.
April 7, 2023
- I already used the train_test_split function of scikit-learn, so I could also use k-Fold Cross validation because I have as much data as I want.
April 6, 2023
- Working on this synthetic dataset.
- Downloaded the dataset and extracted it in /data/synthetic_unity_generated/first_600.
- Uploaded this dataset (zip is not allowed format) to roboflow as a public project.
- The files are 2560 x 1259 with 8-bit/color RGBA, so I used the pre-processing option to reduce them to 640 x 480:
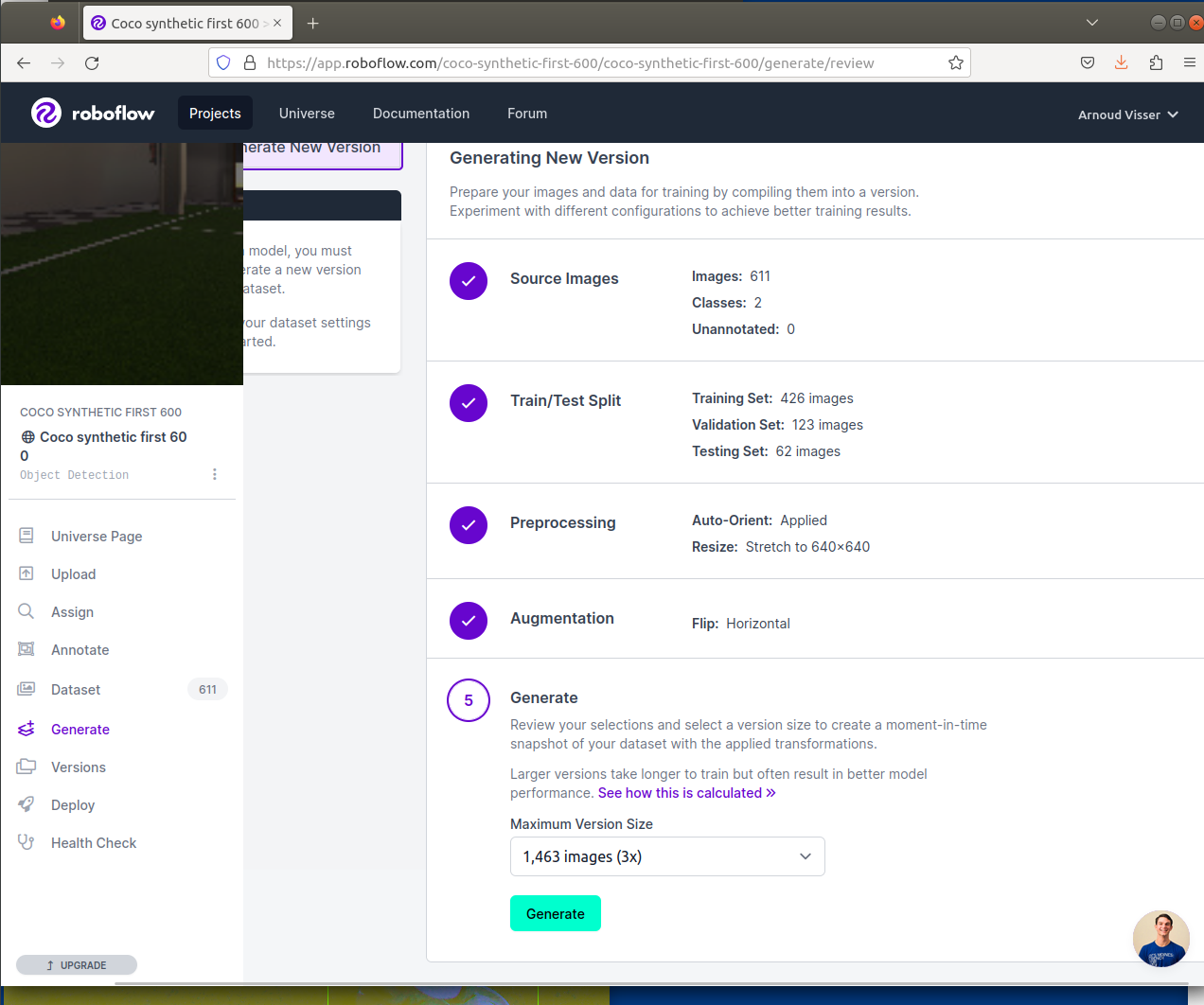
- There are several options for data augmentation:

Flipping horizontal looked interesting, but at the end the version 2 is a dataset without augmentation. Only strange issue is that the dataset contains 611 images, instead of the original 600.
- Exported the dataset in darknet format:

Extracted the dataset in ~/darknet_training/doubleclass/synthetic. The dataset contains three directories (train, valid, test). Made a synthetic/obj.data with this content:
classes= 2
train = ./synthetic/train.txt
valid = ./synthetic/valid.txt
names = ../doubleclass/cfg/double.names
backup = ../doubleclass/backup/
- Created the file ./synthetic/train.txt by the command ls ./synthetic/train/*.jpg > synthetic/train.txt. Did the same for valid.txt and test.txt
- Created synthetic_training.sh that starts training, the training curve looks good (mAP of 89.4% after 4000 iterations).
- In the mean-time I read Yolo v4 tactics. This includes point 4, using pretrained yolo4 weights. Should train again on the real dataset, but now pretrained on the synthetic dataset.
- Result looks good:
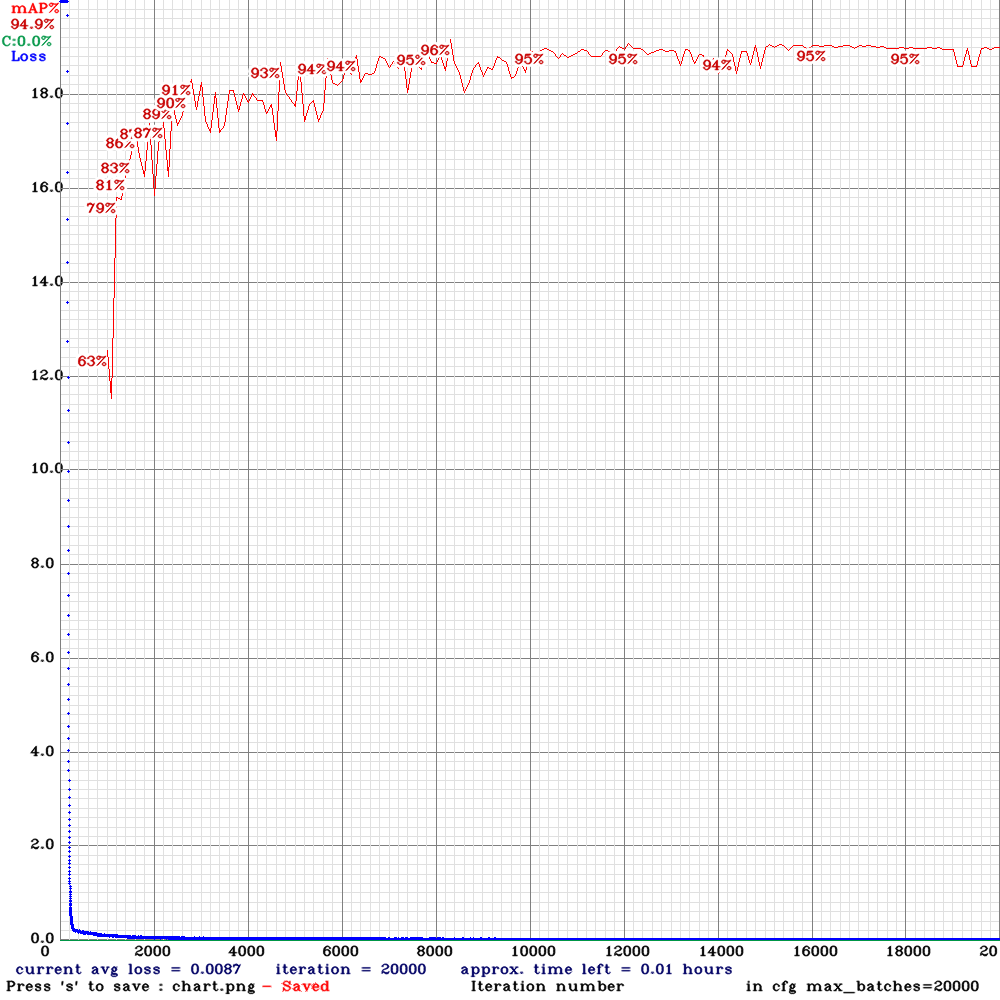
- Running the validation also gives good results (note the smaller validation set, now that it properly split):
detections_count = 96, unique_truth_count = 53
class_id = 0, name = ball, ap = 95.13% (TP = 20, FP = 0)
class_id = 1, name = robot, ap = 94.71% (TP = 28, FP = 2)
for conf_thresh = 0.25, precision = 0.96, recall = 0.91, F1-score = 0.9
for conf_thresh = 0.25, TP = 48, FP = 2, FN = 5, average IoU = 81.26
IoU threshold = 50 %, used Area-Under-Curve for each unique Recal
mean average precision (mAP@0.50) = 0.949225, or 94.92 %
- Tried to make new_train.txt for images_bgr, but it seems that not every image has a corresponding *.txt label, and some are jpg instead of png.
- Copied the train.txt (with yuv-images) to train_bgr.txt. Yet, the transfer_learning script complains that images_bgr/frames_saves1_78.png cannot be loaded by OpenCV, while ls works. Problem is that those files are not readable for others.
- Now training starts, but directly stops. Are the results to good? The suggestion is If you want to train from the beginning, then use flag in the end of training command: -clear, so I try that.
- The positive news is that it starts with a lower loss and a higher mAP:
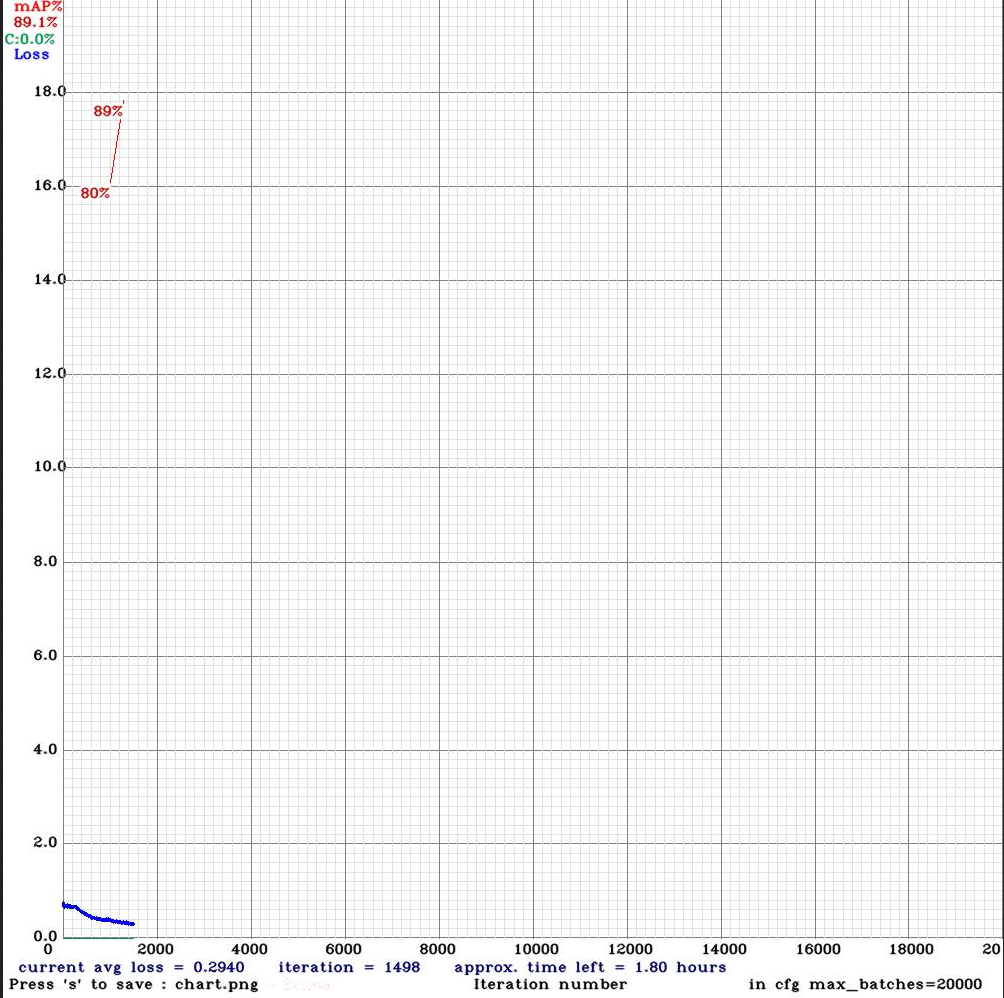
- The negative news is that -clear is not an option often mentioned for darknet, if I Google it.
April 5, 2023
- The weigths can also be found at DNT github.
- Linked ~/git/DNT2017/config/yolo_detector as ~/git/darknet_yolo/backup.
- The yolov3-tiny_3l.cfg is read, which tries to load yolov3-tiny_3l_best.weights. Made a link to both best86*.weights, but both on getUnconnectedOutLayers.
- Corrected the call in evaluate as suggested by stackoverflow.
- Now the evaluate continues, but fails to load DNT_2/train.csv. This directory is specified in config.py.
- Found the dataset on the old Google-drive, including a readme.
- Actually, Rogier worked on ws5.
- Created on ws5 a directory darknet_training/doubleclass. Copied cmd.sh there, because I want to test (and not train).
- Had to make links from test.txt, obj.data, cfg/, results/, images/ and ../darknet.
- Now source cmd.sh works, which gives as result ap = 85.71% (TP = 126, FP = 3) for the ball, and result = 86.86% (TP = 109, FP = 68) for the robot.
- This is in accordance with Figure 7 of the report, for Tiny Yolo-v3/3L.
- Running yolov4-tiny_3l.cfg fails, because that file is not available in the results-directory (but is available in the cfg-directory). Looks like yolo4 has to be trained. The yolov3-tiny_3l.cfg are the same in cfg and results. Running with the yolov4 in cfg gives an ap of 0.0, so the yolov3 weights don't work. Will try to train.
- Started the training and looking at the progress on localhost:8090. The approx time left is 1.91
- To get the training working I had to make a link to train.txt and create a backup-directory.
- Read the blog from Sanna Persson again, who indicates that there should be both a img_dir and label_dir.
- Actually, the images-directory both contains *.png and *.txt files. The file images/27_07_2018__15_44_10_0469_upper.txt has bounding boxes for two robots:
1 0.053125 0.36354166666666665 0.10625 0.4479166666666667
1 0.709375 0.5447916666666667 0.33125 0.9104166666666667
- The first integer is the class (1 = robot), the next two floats are the middle of the bounding boxes (in scale to the image-size), followed by two floats for the height and width of the bounding box.
- The dataset in Unity has the bounding boxes specified absolute and in one big json file. Should look for a convertion tool, such as roboflow
- Saw no code to display the bounding boxes, although in the site-package/albumentations there is a bbox_utils.py
- The training is ready, with a mAP of 87.6%:

- Tested it with ../darknet/darknet detector map ./obj.data ./cfg/yolov4-tiny_3l.cfg results/yolov4-tiny_3l_final.weights, which gave:
class_id = 0, name = ball, ap = 84.17% (TP = 120, FP = 7)
class_id = 1, name = robot, ap = 90.98% (TP = 113, FP = 56)
- Note that a ball ap = 84.17% is not equivalent with the 87% in Fig. 7, should also have copied the mAP a few lines lower.
- Note that the file ../darknet/darknet_video.py has functionality to display bounding boxes. Is activated with parameter --ext_output. Works also for ../darknet/darknet_images.py
- With the call ../darknet/darknet detector test ./obj.data ./cfg/yolov4-tiny_3l.cfg results/yolov4-tiny_3l_final.weights images/27_07_2018__15_44_10_0469_upper.png a prediction.jpg is created. Converted that image from yuv to rgb with opencv (confidence is not readable, but the output indicates resp. confidence 99% and 100%:

March 31, 2023
- Solved the error when running python3 evaluate.py by creating a new directory darknet_training, which contains a directory 'doubleclass', which is actually a logical link to darknet_yolo. Inside darknet_yolo I made a logical link to results/tiny_3l_20210326 called backup.
- Everything loads, but I get the error:
File "~/git/yolo-v3-dnt/evaluate.py", line 123, in
main()
File "~/git/yolo-v3-dnt/evaluate.py", line 65, in main
dnmodel,_,_,outlayers = load_dn()
File "~/git/yolo-v3-dnt/evaluate.py", line 39, in load_dn
output_layers = [layers_names[i[0]-1] for i in net.getUnconnectedOutLayers()]
File "~/git/yolo-v3-dnt/evaluate.py", line 39, in
output_layers = [layers_names[i[0]-1] for i in net.getUnconnectedOutLayers()]
IndexError: invalid index to scalar variable.
- Hypothesis: a none matching cfg and weights. The weights are probably not doublehead.
March 28, 2023
- Rogier his code can be found on github.
- Looked at his labbook at overleaf.
- Rogier worked on ws7. he used bit-bots image set 1077.
- Categorized images no longer available on the DNT google drive, the ferb-save-testmatch.tar.gz is still there.
- Rogier account is no longer present on ws7
- Cloned on my personal account on ws7 yolo-v3-dnt github.
- Seems to be based on this blog.
- Rogier used a miniconda yolo-v3 environment. Just running python3 evaluate.py fails on No module named 'albunations'
- Looked at PyTorch implementation which was the basis, which includes a pip install requirements.txt.
- Unfortunatelly, this requirements.txt is gone.
- So, I followed the instructions from albumentions.ai and did pip install -U albumentations.
- Created a requirements.txt. Included (for python3.10) albumentations-1.3.0, torch-2.0.0, torchvision-0.15.1 and matplotlib-3.7.1.
- Next alumentations failed on missing library imgaug, which can be solved with pip install -U albumentations[imgaug].
- Now everything is installed, but the script expects NetParameter file: ../darknet_training/doubleclass/cfg/yolov3-tiny_3l.cfg.
- Note that Rogier has also darknet_yolo which has that yolov3-tiy_3l.cfg file in its cfg-directory.
March 27, 2023
- Looked at several example-code on how to fine-tune Yolo v3.
March 13, 2023
- Joey has made a nice Unity model of the robolab. An assignment would be to generate training data for Yolo.
Generating training data is possible with Unity Perception, as described in this this paper.
- A first application would be ball-detection with yolo. Unity can work with pretrained models as MobileNet and Yolo (ONNX-based), although the repalced their TensorFlow with Baracuda.
- Jaime Alemany has written an interesting PhD-thesis (in Spanish) which uses UsarNaoQi from Sander van Noort.
February 2, 2023
- Switched off the sound again with Chrographe connected to tom.local (*.47).
- Also updated the time again.
- Looked into the logs again, but still only LShoulderPitch errors.
February 1, 2023
- Tom, a v5 robot, made alarming sounds (and red/purple eyes).
- Connected with Choregraphe 2.8.6.23 (nb-dual Ubuntu-partition).
- Switched on Show all logs in Log viewer, but no errors pop up.
- Tried the different dances, but the Tai Chi is different in this version. After an initial movement the dance stops (and the music continues).
- The other dances (Headbang and Disco) go well, although Disco is not good for its fingers.
- While looking for the logs, I saw that the date was wrong (although the right timezone was set in the webinterface).
- Logged in as root and did /usr/sbin/ntpdate -s ntp.ubuntu.com, which sets the correct time and date.
- There is /var/log/naoqi/naoqi-crash.log, which only gives 2009-09-16 22:19:36 UTC: Starting NAOqi.... The head-naoqi.log gives on its tail oscilating messages:
[I] 1253140216.698756 3563 ALBodyTemperature: The LShoulderPitch is hot.
[I] 1253140216.700090 3563 ALBodyTemperature: Temperature of LShoulderPitch is: 38 degrees Celsius.
[I] 1253140216.732754 3563 ALBodyTemperature: The LShoulderPitch is no longer hot.
- With the students, Tom alarms again. Set the sound to zero with advanced webinterface.
Previous Labbook