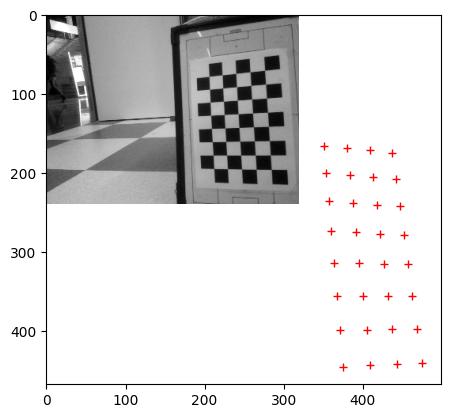
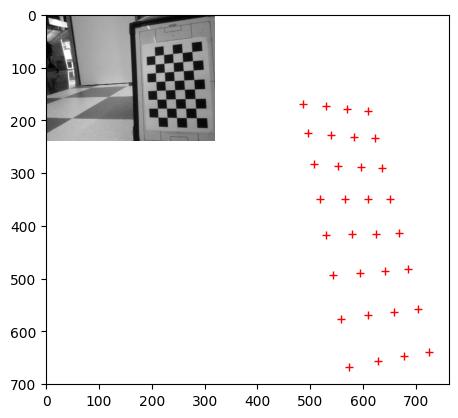
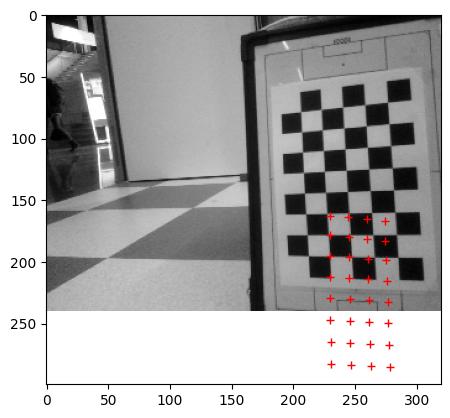
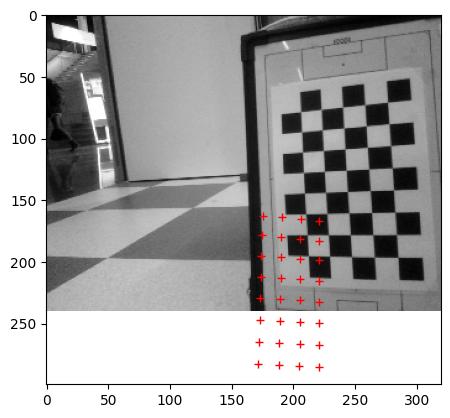
The head of Princess Beep Boop (Nao4) crashed twice when an ethernet cable was plucked in, but this problem disappeared after flashing. Seems OK 13 December 2016.
Julia has a weak right shoulder (December 2016).
Bleu hips are squicking. Seems OK September 2015.
Bleu sound falls away. Loose connector? September 2015.
Nao's overheats faster when using arms than using legs.
Blue skulls is broken at the bottom: should remove its head any more.
Blue has a connector at the front which is no longer glued on position. Couldn't find a connector position.
Sven Benke published HyenaPixel, which has a larger attention network than ViT.
November 7, 2024
Testing repaired UTM-30LX with nb-dual. Had to do sudo apt install --fix-broken to get urgbenri working.
The wiring has quite some loose ends: the two power-lines just have to go into the white block:
Couldn't connect, so I had to do sudo chmod o+rw /dev/ttyACM0 to get it working:
November 6, 2024
Repair request should not be send to Aldebaran, but to United Robotics ticket.
Made a pick-up request for Daphne (right angle broken).
November 1, 2024
Tested the first example BreezySLAM with the provided dataset on nb-ros (python3.6). Porting it to the NaoHead would require that the code runs under python2.7.:
First had to convert the png with mogrify -format png exp2.pgm
Yet, examples/urgtest.py fails:
./urgtest.py
breezylidar.URG04LX:hokuyo_connect:_connect: serial_device_connect: Unable to open serial port /dev/ttyACM0
That is strange, because /dev/ttyACM0 exists, and has following permisions crw-rw---- 1 dialout (user is in dailout group).
Running it as root gives other failures:
breezylidar.URG04LX:hokuyo_connect:_connect:_get_sensor_info: response does not match:
breezylidar.URG04LX:hokuyo_connect:_connect:_get_sensor_info_and_params: unable to get status!
breezylidar.URG04LX:hokuyo_connect:_connect: could not get status data from sensor
On January 25, 2023 I also did first sudo chmod o+rw /dev/ttyACM0 before running rosrun urg_node getID /dev/ttyACM0 from ROS noetic.
First downloaded the Hokuyo viewing tool UrgBenriPlus 2.3.2 (rev. 343 - 22 July 2024) from UTM-30LX page, but that is the Windows version.
The tool urgbenri didn't work out of the box. Also had to install sudo apt install libqt5concurrent5:i386. The tool complains that it cannot load the canberra-gtk3-modules, although they are already installed. Maybe I need the 386 versions.
At least the tool can connect to the URG-04LX, although with 7 fps. nb-ros is very slow, so will try a reboot.
After the reboot, it could read-out the sensor with 10 fps:
Now the BreezyLidar example works. python3 urgtest.py
===============================================================
Model: URG-04LX(Hokuyo Automatic Co.,Ltd.)
Firmware: 3.3.00(16/Apr./2008)
Serial #: H0901625
Protocol: SCIP 2.0
Vendor: Hokuyo Automatic Co.,Ltd.
===============================================================
Iteration: 1: Got 682 data points
Iteration: 2: Got 682 data points
Iteration: 3: Got 682 data points
Iteration: 4: Got 682 data points
Iteration: 5: Got 682 data points
Iteration: 6: Got 682 data points
Iteration: 7: Got 682 data points
Iteration: 8: Got 682 data points
Iteration: 9: Got 682 data points
Iteration: 10: Got 682 data points
10 scans in 0.895180 seconds = 11.170941 scans/sec
Also python3 urgplot.py works:
351 scans in 34.807755 sec = 10.083960 scans/sec
206 displays in 34.807755 sec = 5.918221 displays/sec
For the SLAM example I also have to install roboviz. After that BreezySLAM with live-measurement of my Hokuyo URG-04LX:
Keb did several experiments in LAB42, with a the URG-04LX mounted on a rolling platform.
Results inside Lab42:
Results corridor outside ILR:
The first two experiments show clearly that with the limited range of the Hokuyo URG-04LX no progress can be seen when traveling along a flat wall (BreezySLAM uses no encoder or IMU updates).
Results corner around the display:
Results outside Star-Cafe:
The second two experiments show that with the limited range of the Hokuyo URG-04LX the hall of LAB42 has a too wide open space.
Results inside lactation-room:
The last experiments show the limited space of this room fits well with the limited range of the Hokuyo URG-04LX, although there are still some problems in the one corner.
It would be nice to see if BreezySLAM could be integrated with the NaoHead.
July 25, 2024
A new cable was made to connect the Hokuyo laserscanner again to the control board in Pique's head.
The J6 connector should be connected from left to right (U-shape, so opening up): brown, blue, yellow, green, purple. The other side is nicely documented on the Hokuyo itself.
Started Rouge, she waked up correctly, although she started a diagnosis before going into Nao Life. She suggested to restart naoqi.
She is connected to another network than LAB42, I assume the VISLAB network.
The Laser head doesn't say its name / ip when the chest-button is pushed, but with a wired connection I could login (both ssh and webinterface) and connect to the wireless access-point LAB42.
I still had the Monitor 1.14.5, which has a lasermonitor plugin. Powered by the motherboard, the range is a bit limited. Measured the max-range powered via the board in the head, which gave a max range of 1m37.
No difference if I connect an external 5V battery via the mini-USB entrance. That makes no scense, according to August 16, 2011 experiment, the mini-USB is for data only, the Hokuyo is not powered via this port.
Note that the 1m37 measured today is twice as far as 70cm measured in August 2011.
The original Hokuyo download page no longer exist, only a web-archive version from 2013.
I should be carefull with my old phone, because sphero-bb app is hard to get working
In the app-store I see Sphero Play and Sphero EDU. Trying Sphero Play first.
Play can connect to several robots, but not mainly the BOLT and SPRK+.
According to legacy page, I could use the EDU app to control the BB-8. That works, the robot can be found in the Drive tab when you select other robots. You can only connect / control with the head on the robot. Drove a circle on the field with head and at my seat without.
Yet, bleak gave an error bleak.exc.BleakError: device 'dev_2B_0D_E4_86_83_93' not found. Checked (native Ubuntu on nb-dual), bluetooth is on, BB-8BF4 is visible but not coupled.
Looked into the bleak documentation and did a discover. The BB-8 is visible as C0:D0:AC:38:8B:F4
The 2nd script fails on the connect.
In the app, you can see both the MAC address and the firmware version of the BB8 (v 4.69.0)
Disconnected the robot from the app, now python read_model_number.py (2nd script) works (modle number: 30). Also python hell_word.py now works.
With some modifications, I also get find_by_name working (from common-mistakes)
Also got on_collision working. It drove 3s forwards, collided, but didn't executed the event-code. Note that the documentation of roll can be found in the code: For example, to have the robot roll at 90°, at speed 200 for 2s, use ``roll(90, 200, 2)``. Inside the roll there is already a sleep and stop_roll(). No event or error-handling. The raw interface can be found in control/v2.py.
The red warning is also executed without the event. Will try to add a stop_rolling between the roll commands.
Looked at this code, which used bluepy package. The code worked with python2, flashing the BB8 through all its colors.
Modified the pygame to use WASD keys. Could drive around, until again the robot became red and disconnected.
Second try, could drive further, until again a disconnect.
The commands are quite robust, but low-level. The roll command is give with Response. The implementation is based on this DeveloperResources.
They mention v1.50 of the API. Only could found v1.20:
Note that with this documents you can go quite low level (HACKING mode).
Interesting that the Sphero also has a locator, which keeps track of its position.
The original script already asked for some sensor data (0x80), not clear wahat is asked and how to interpret.
Made a give_battery_status.py which gives this answer:
Sensor data 0x80
('cmd:', 'ff ff 02 11 00 0a 00 50 00 01 80 00 00 00 00 11')
('Notification:', 16, '753effff000001fe')
Battery status
('cmd:', 'ff ff 00 20 01 01 dd')
('Notification:', 16, 'ffff0001090102034601f70000b1')
Wrote two scripts that drove a reasonable square and circle. Because it is based on timing, and the stabilisation sometimes need its time, the size of the shapes is not constant. The size of the square can be controlled with a variable several_times, the circle depends on the start speed.
Looking into the Spherov2 code again. The function start_captering_sensor_data() is the list sensors = ['attitude', 'accelerometer', 'gyroscope', 'locator', 'velocity'] for the BB8. On a high-level, there are functions like get_acceleration(), get_gyroscope(), get_location(), get_velocity(). get_orientation() gives the attitude data.
According to this post, the robot has to spin first, before the sensors return sensible returns.
After a spin(10,1) the sensor finally provide output with drive_with_sensor.py:
location : {'x': 0, 'y': 0}
orientation : {'pitch': -1, 'roll': 13, 'yaw': 0}
acceleration: {'x': 0.285888671875, 'y': 0.023193359375, 'z': 0.95849609375}
velocity: {'x': 0.0, 'y': -1.2000000000000002}
gyroscope: {'x': 18.1, 'y': 0.2, 'z': -22.0}
Made a script to drive shortly forward (droid.roll(0,50,1.5)). When the robot was stopped, it moved 15 cm (16 cm according to its internal position)
July 9, 2024
The team description of this year's teams can be found on this page
June 19, 2024
Scale-space is mentioned by Szeliski's textbook at page 13, on the developments in the 1980s (page 13), together with image pyramids and wavelets.
Szeliski point to Livingstone 2008 for more recent developments.
April 19, 2024
Run the C++-test test_absolute_pose, which gave the following output:
the random position is:
1.54419
1.15296
-0.0856827
the random rotation is:
0.993945 -0.0644002 0.0890272
0.0592623 0.996486 0.0591997
-0.0925268 -0.0535653 0.994268
the noise in the data is:
0
the outlier fraction is:
0
running Kneip's P2P (first two correspondences)
running Kneip's P3P (first three correspondences)
running Gao's P3P (first three correspondences)
running epnp (all correspondences)
running epnp with 6 correspondences
running upnp with all correspondences
running upnp with 3 correspondences
setting perturbed poseand performing nonlinear optimization
setting perturbed poseand performing nonlinear optimization with 10 correspondences
results from P2P algorithm:
1.54419
1.15296
-0.0856827
results from nonlinear algorithm with only 10 correspondences:
0.993945 -0.0644001 0.0890272 1.54419
0.0592622 0.996486 0.0591997 1.15296
-0.0925268 -0.0535653 0.994268 -0.085684
timings from P2P algorithm: 1e-07
timings from Kneip's P3P algorithm: 1.78e-06
timings from Gao's P3P algorithm: 5.78e-06
timings from epnp algorithm: 0.0001006
timings for the upnp algorithm: 0.00052978
timings from nonlinear algorithm: 0.0025872
As you can see above, the two P3P algorithms proposed both 4-solutions, starting with the correct one.
The test-algorithm starts with 4 generators: generateRandomTranslation(), generateRandomRotation(), generateCentralCameraSystem(), generateRandom2D3DCorrespondences().
Those function are defined in random_generators.cpp. The value given to generateRandomTransition() is maximumParallax. The test-functions are not described in documentation.
The value given to generateRandomRotation() is a maxAngle.
The function generateCentralCameraSystem() can be found in experiment_helpers.cpp. The camOffsets are pushed to zero Vector3d, the camRotations to the identity Matrix3d.
Note that in experiment_helpers.cpp also the function printBearingVectorArraysMatlab() can be found.
The generateRandom2D3DCorrespondences() function generate a point-cloud (# of points dependent on last variable - MatrixXd). The points are projected back into the camera frame. In test_absolute_pose.cpp a point-cloud of 100 points is generated. Looked in the p2p-code in ~/git/opengv/src/absolute_pose/methods.cpp and only the first two indices are used.
The test.py should correspond with test_relative_pose.cpp. The output of this program:
the random position is:
-0.818189
0.202536
0.538095
the random rotation is:
0.988596 -0.102914 0.109935
0.101839 0.994682 0.0153596
-0.110931 -0.00398872 0.99382
the noise in the data is:
0
the outlier fraction is:
0
the random essential matrix is:
-0.0546358 -0.379038 0.136485
0.311972 -0.0414653 0.616801
-0.2005 -0.560732 -0.0246306
running twopt
running fivept_stewenius
running fivept_nister
running fivept_kneip
running sevenpt
running eightpt
setting perturbed rotation and running eigensolver
setting perturbed pose and performing nonlinear optimization
setting perturbed pose and performing nonlinear optimization with 10 indices
results from two-points algorithm:
-0.818189
0.202536
0.538095
results from nonlinear algorithm with only few correspondences:
0.988596 -0.102914 0.109935 -0.931662
0.10184 0.994682 0.0153589 0.230626
-0.110931 -0.00398794 0.99382 0.612724
timings from two-points algorithm: 1.4e-07
timings from stewenius' five-point algorithm: 0.00011242
timings from nisters' five-point algorithm: 6.504e-05
timings from kneip's five-point algorithm: 0.00014702
timings from seven-point algorithm: 2.184e-05
timings from eight-point algorithm: 2.148e-05
timings from eigensystem based rotation solver: 6.88e-05
timings from nonlinear algorithm: 0.00057746
In both cases a dataset of 10 points are generated (except for the ransac-versions in python)
Created a test_absolute_pose.py script. The call to p2p succeeds, only I do not understand the resulting translation yet:
Testing absolute pose p2p
position: [-0.13413449 1.87667699 1.71165287]
rotation
[[ 0.87665093 -0.451454 0.16635031]
[ 0.41130393 0.88259478 0.22771809]
[-0.24962416 -0.13120874 0.95941234]]
point 1: [ 4.39152919 -0.60308257 6.17587763]
point 2: [-4.76463631 5.20196229 -5.22388454]
translation: [6.12950017 0.30154485 7.83239161]
Done testing absolute pose
Initialized the Absolute points in the same way as in the C++ code:
Testing absolute pose p2p
position: [ 0.21771928 -1.17899291 -1.17499367]
rotation:
[[ 0.92593016 -0.3732565 -0.05773148]
[ 0.29406573 0.80836128 -0.50997783]
[ 0.23702043 0.455227 0.85824804]]
point 1: [-2.11728067 -0.15822875 6.00035911]
point 2: [-4.87346772 -5.06891149 -0.65433273]
bearings 1: [-0.02116632 0.65180197 0.75809378]
bearings 2: [-0.89208484 -0.15667061 0.42383837]
translation: [ 0.21771928 -1.17899291 -1.17499367]
Done testing absolute pose
April 18, 2024
Cloning opengv on the Ubuntu 22.04 WSL on nb-dual.
Had to reboot, because several services, including wsl, didn't restart.
First a vanilla make, after that trying to activate the python-wrappers.
Activated the option in CMakeList.txt, but do not see anything build.
Changed to the ~/git/opengv/python directory, but python3 tests.py fails on No module named pyopengv
This directory has its own CMakeList.txt. Running cmake .. on it fails on unknown command pybind11_add_module
Made a fresh python_build directory, but cmake now fails on:
CMake Error at python/CMakeLists.txt:2 (add_subdirectory):
The source directory
~/git/opengv/python/pybind11
does not contain a CMakeLists.txt file.
CMake Error at python/CMakeLists.txt:7 (pybind11_add_module):
Unknown CMake command "pybind11_add_module"
This problem is a known issue. Instead of using conda, I used the sudo apt-get install python3-pybind11. Also gave the ~/git/opengv/python/pybid11 a CMakeLists.txt file with only find_package(pybind11 REQUIRED) in it. Started the fresh build.
One warning, but is seems that the compilation worked:
/git/opengv/python/types.hpp: In instantiation of ‘pybind11::array_t pyopengv::py_array_from_data(const T*, size_t) [with T = double; size_t = long unsigned int]’:
~/git/opengv/python/pyopengv.cpp:55:28: required from here
~/git/opengv/python/types.hpp:19:23: warning: narrowing conversion of ‘shape0’ from ‘size_t’ {aka ‘long unsigned int’} to ‘pybind11::ssize_t’ {aka ‘long int’} [-Wnarrowing]
19 | py::array_t res({shape0});
| ^~~~~~
[100%] Linking CXX shared module ../lib/pyopengv.cpython-310-x86_64-linux-gnu.so
lto-wrapper: warning: using serial compilation of 3 LTRANS jobs
[100%] Built target pyopengv
In the ~/git/opengv/python directory, I made a symbolic link to the library just build with ln -s ../python_build/lib/pyopengv.cpython-310-x86_64-linux-gnu.so. Now python3 tests.py works:
Testing relative pose
Done testing relative pose
Testing relative pose ransac
Done testing relative pose ransac
Testing relative pose ransac rotation only
Done testing relative pose ransac rotation only
Testing triangulation
Done testing triangulation
All those test start with a RelativePoseDataset(10, 0.0, 0.0). Once generated, this class can be queried on bearing_vectors1, bearing_vectors2, position, rotation, essential, points.
The function test_triangulation() seems a good one to test first.
There is even a P3.5P solution, where only the X or Y coordinate of the fourth point are needed to estimate the focal length.
The documentation of OpenGV can be found on github.io
The library is build on top of a general Adapter class. No documentation is given for the python binding. To be tested tomorrow.
Note that inside ROS RTABMAP, there is a dependency on OPENGV.
If I check the Docker file, the dependency on OpenCV originates from SuperPoint.
April 16, 2024
Note that the Nao v6 has actually a smaller HFOV than the Nao v5: 56.3 ° versus 60.97 °.
April 15, 2024
Momo had to be flashed again.
Had problems with starting up a jupyter notebook from WSL Ubuntu 22.04. Luckily jupyter lab seems to work, although I also receive some "Kernel doesn't exist" warnings.
Yet, I could run the latest Nao_Position_Speed_Comparison notebook.
Converted the notebook to python code, converted it from python3 to python2 code, removed the get_ipython calls, so the script is now running on momo.
Run both algorithms 5x:
('Execution time ClassicFaster:', 0.00013799999999997148, 'seconds')
('Execution time Classic:', 0.00017100000000014326, 'seconds')
Run both algorithms 50x:
('Execution time ClassicFaster:', 0.0012420000000001874, 'seconds')
('Execution time Classic:', 0.00158299999999989, 'seconds')
Run both algorithms 500x:
('Execution time ClassicFaster:', 0.012411999999999868, 'seconds')
('Execution time Classic:', 0.015867999999999993, 'seconds')
Run both algorithms 5000x:
('Execution time ClassicFaster:', 0.12346999999999997, 'seconds')
('Execution time Classic:', 0.1613230000000001, 'seconds')
Run both algorithms 50.000x:
('Execution time ClassicFaster:', 1.230644, 'seconds')
('Execution time Classic:', 1.5887760000000002, 'seconds')
Run both algorithms 500.000x:
('Execution time ClassicFaster:', 12.2808, 'seconds')
('Execution time Classic:', 15.890538999999999, 'seconds')
This is actually 2x to 3x slower than my measurements on January 18, but both this algorithms contain function calls to get spreadFromDirections() and angleFromDirections() (both three calls), which I had done as preprocessing on January 18.
The Nao v6 camera has on horizontal FOV of 60.97 deg, so I displayed the 6 bands of 10 deg on the image (with the center marked with blue): .
The 4 landmarks can be found at resp. the pixels 36, 54, 149 and 250, which corresponds with -23,622, -20,175, -2,094 and +17.130 deg: .
Bundled those four observations together and rotated them until they overlapped with the location of the objects. The group was rotated 325 deg, which is equivalent with an orientation of 35 deg, in correspondance what I measured this morning. The start of the bundle is around 9cm more to the side than the inner penalty area, although not so much shifted to the goal as I expected. Note that +17.13 deg (observation of the NaoMark #119), is equivalent with 0.29875 rad, nearly the value of alpha (-0.27844 rad - 15.95 deg) - a difference of 1.18 deg. The difference between observation and alpha could originate from the z-rotation from the CameraTop to Feet transform of -0.07379 rad (0.422786 deg): Note that I made a 180 error with the field, the #119 NaoMark is in the other diagonal.
Copied the group and oriented them again (2nd check). The orientation of the group is now 136 deg, equivalent with a rotation of 34 deg. Rotating the -2,094 deg observation to horizontal gives a orientation of the group of 183 deg:
Note that there was also Localization with Obstacle Avoidance
Challenge at RoboCup 2009. For this challenge three points (random). Fig. 13 of B-Human workshop paper indicates the locations used (near the middle circle).
April 12, 2024
Unfortunatelly, the big video stored on ws9 is gone, so couldn't get screenshots from that.
Made a new (red) circuit with Momo, from where each of the NaoMarks are recognized (and an other landmark) is visible. After a while the robot got overheated again, so only the first images are recorded with stiffness.
In this case I marked the position with read tape behind the robot's heels, indicating both position and orientation. The camera is located 9cm before this position.
I made several trails until I was satisfied with the view, so the last view of that NaoMark is the actual location.
The first point (#119 at (-535,-202.5) was measured at (-350,-180), which means that the NaoMark #119 is observed at (185,22.5) cm - in polar (186.4,6.94°), which is 0.121 rad. NaoMark #119 is observed at alpha = -0.278, so the orientation of the Nao head should be 0.399 rad (22.86°). Measured the orientation of on the field, which indicates (37 -38 °). Also two intersections are visible, the T-intersection at (-450, -202.5) and the L-intersection at (-450, -307.5). The T-intersection that should be observed at a relative location of (100,22.5) cm - in polar (102.5,12.68°), which is 0.221 rad, or 0.178 rad from the head-orientation. Yet, this T-intersection is nearly at the center of the image, even 10 pixels to the left (not to the right). Note that I still have to correct the 9cm diplacement of the head. The L-intersection should be observed at (100,127.5) cm - in polar (162.0,51.89°), which is 0.906 rad. Minus the orientation of the head gives 0.507 rad is 29.05 ° - (too) close to the open-angle of the camera (half HFOV is 30.485 ° or 0.532 rad. With that orientation the L-intersection should be at 8 pixels from the left, while it is 32 pixels from the left.:
Position of CameraTop relative to the feet is: [0.07339192181825638, 0.010115612298250198, 0.4096010625362396, -0.02601604536175728, 0.11428432911634445, -0.007379069924354553]
Position of CameraTop relative to the torso is: [0.06596976518630981, -0.0003063603362534195, 0.18257859349250793, -1.1641532182693481e-10, 0.14208801090717316, -0.004643917549401522]
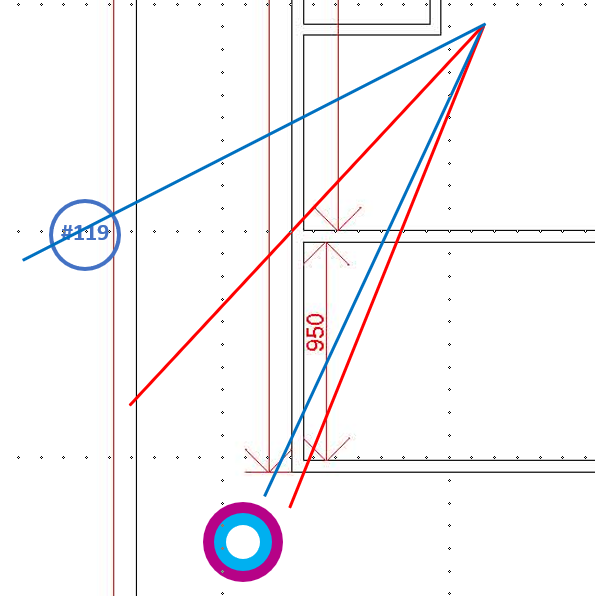
mark ID: 119
alpha -0.278439998627 - beta -0.0527534894645
width 0.05303619802 - height 0.05303619802
heading 7
{
"predictions": [
{
"x": 149.5,
"y": 159,
"width": 31,
"height": 32,
"confidence": 0.842,
"class": "T-Intersection",
"class_id": 1,
"detection_id": "1c381d45-309a-4f1b-8b93-89d61fdc98d5"
},
{
"x": 36,
"y": 128,
"width": 22,
"height": 20,
"confidence": 0.688,
"class": "L-Intersection",
"class_id": 0,
"detection_id": "7efc1bc4-0211-4216-a9a7-3f3265c0d226"
}
]
}
The second point (#80) was measured at (x,y):
Position of CameraTop relative to the feet is: [0.06782502681016922, 0.0368414968252182, 0.39404362440109253, -0.1259964406490326, 0.23490406572818756, -0.023657994344830513]
Position of CameraTop relative to the torso is: [0.07517172396183014, 0.0014961211709305644, 0.16944049298763275, 9.313225746154785e-10, 0.3277019262313843, 0.019900085404515266]
mark ID: 80
alpha 0.426044434309 - beta -0.217658475041
width 0.0514763072133 - height 0.0514763072133
heading 0
The third point (#85) was measured at (x,y):
Position of CameraTop relative to the feet is: [0.06679154187440872, -0.009784342721104622, 0.4092438817024231, 7.050950807752088e-05, 0.12165237218141556, 0.0333169586956501]
Position of CameraTop relative to the torso is: [0.06772751361131668, 0.0036369352601468563, 0.18032070994377136, 1.862645371275562e-09, 0.17583593726158142, 0.053648002445697784]
mark ID: 85
alpha -0.110557094216 - beta -0.0702708810568
width 0.0608356371522 - height 0.0608356371522
heading 7
The fourth point (#114) was measured at (x,y):
Position of CameraTop relative to the feet is: [0.04699055850505829, -0.008408595807850361, 0.411502867937088, 0.00873508583754301, 0.07985550165176392, 0.053913045674562454]
Position of CameraTop relative to the torso is: [0.07062236219644547, 0.004553393926471472, 0.17638647556304932, -1.862645371275562e-09, 0.2325941026210785, 0.06438612192869186]
mark ID: 114
alpha -0.362479001284 - beta -0.0253700036556
width 0.05303619802 - height 0.05303619802
heading 0
The fifth point (#84) was measured at (x,y):
Position of CameraTop relative to the feet is: [0.046611715108156204, -0.009782876819372177, 0.4166818857192993, 0.04117007926106453, -0.04867382347583771, -0.0630883276462555]
Position of CameraTop relative to the torso is: [0.060750510543584824, -0.004483846481889486, 0.18803197145462036, 0.0, 0.05618388578295708, -0.07367396354675293]
mark ID: 84
alpha 0.212339758873 - beta 0.0551696680486
width 0.040557090193 - height 0.040557090193
heading 0
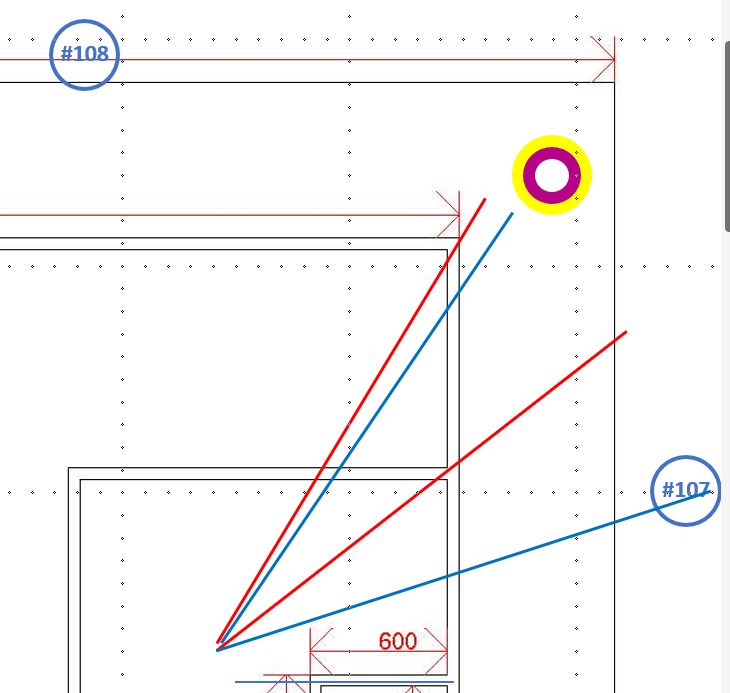
The sixth point (#107) was measured at (x,y):
Position of CameraTop relative to the feet is: [0.05486590415239334, -0.013877270743250847, 0.4109554588794708, 0.06352350115776062, 0.029536372050642967, -0.041775330901145935]
Position of CameraTop relative to the torso is: [0.06481074541807175, -0.0038847229443490505, 0.1837834119796753, -4.656612873077393e-10, 0.12367994338274002, -0.05986786261200905]
mark ID: 107
alpha -0.354289621115 - beta 0.0920165628195
width 0.0670751929283 - height 0.0670751929283
heading 26
The seventh point (#108) was measured at (x,y):
Position of CameraTop relative to the feet is: [0.04823441058397293, 0.005639837123453617, 0.42199671268463135, 0.019613005220890045, -0.07664643228054047, 0.01734265126287937]
Position of CameraTop relative to the torso is: [0.05860936641693115, 0.00017735298024490476, 0.19023242592811584, 3.637978807091713e-12, 0.0193680040538311, 0.0030260086059570312]
mark ID: 108
alpha 0.40810573101 - beta 0.183831825852
width 0.0686350762844 - height 0.0686350762844
heading 8
The eight point (#68) was measured at (x,y):
Position of CameraTop relative to the feet is: [0.07310034334659576, -0.011376416310667992, 0.40672504901885986, 0.05720367282629013, 0.11460099369287491, -0.017237771302461624]
Position of CameraTop relative to the torso is: [0.06628204137086868, -0.0020369512494653463, 0.1821727454662323, 0.0, 0.14822395145893097, -0.03072190470993519]
mark ID: 68
alpha -0.162228390574 - beta -0.0612101666629
width 0.0561559721828 - height 0.0561559721828
heading 18
The nineth point (#145) was measured at (x,y):
Position of CameraTop relative to the feet is: [0.056823812425136566, -0.01228808518499136, 0.4122491478919983, 0.05585203319787979, 0.015317902900278568, -8.553490624763072e-05]
Position of CameraTop relative to the torso is: [0.0635882019996643, -0.0006854983512312174, 0.18526208400726318, 0.0, 0.10066992789506912, -0.010779857635498047]
mark ID: 145
alpha -0.32679656148 - beta 0.0620155744255
width 0.0577158592641 - height 0.0577158592641
heading 26
The tenth point (#116) was measured at (x,y):
Position of CameraTop relative to the feet is: [0.07111740112304688, -0.0037125577218830585, 0.4035223424434662, 0.03567863628268242, 0.18692344427108765, -0.002596075413748622]
Position of CameraTop relative to the torso is: [0.07151903212070465, -0.0009904636535793543, 0.17529506981372833, 0.0, 0.24793392419815063, -0.01384806539863348]
mark ID: 116
alpha 0.365793764591 - beta -0.136716112494
width 0.0499164201319 - height 0.0499164201319
heading 18
Let see if I can get the correct position of this image:
It is recorded on 2005 SLAM challenge position (-210,90), with the orientation from that point to origin. The distance to the origin should in this case be 228.47cm, and the angle from the origin 23.1986 degrees. The 228cm corresponds roughly with my measured 4x 59cm=236cm, I should have used 4x 57cm.
Uploaded this image to Gijs has the Field mark detector based on Yolo v8 XL.
Both intersections were corrected identified, although the right one with quite low confidence:
predictions": [
{
"x": 30,
"y": 79.5,
"width": 18,
"height": 19,
"confidence": 0.789,
"class": "X-Intersection",
"class_id": 2,
"detection_id": "b5d2b2ee-55fc-44eb-a841-4061816c0fce"
},
{
"x": 219.5,
"y": 65,
"width": 15,
"height": 14,
"confidence": 0.339,
"class": "X-Intersection",
"class_id": 2,
"detection_id": "b3adb13d-e9e6-49a5-bbac-34dcda0aaa00"
}
]
The expected result should be something like [2.3, 0.75, 0.38], but is something different:
[1.7657730923703654, 1.9459492379956858, 0.32030671443237474]
[1.7657730923703656, 1.945949237995686, 0.32030671443237474]
[-1.765773092370378, 1.9459492379956742, 0.32030671443237535]
('Execution time for Cartesian:', 0.0006980000000000042, 'seconds')
('Execution time for Spherical:', 0.0006339999999999957, 'seconds')
('Execution time for Classical:', 0.0010830000000000006, 'seconds')
I used this script, with g = [0,1,0] and focal lenght of 310.
It is recorded on 2004 SLAM challenge position (160,100), with the orientation from that point to origin. The distance to the origin should in this case be 188.68cm, and the angle from the origin 32.0054 degrees. The 189cm corresponds roughly with my measured 4x 47.5cm=190cm. So, expected vector is [1.9, 0.75, 0.38]. This recording was with functional Crouch, so the measurements in the logfile count. Note that this is the vector to the top-camera, while the recording was with the bottom camera (which is according to the specs 45.9mm lower, 8mm to the back and tilted 39.7 deg, which is equal to 0.692895713 rad:
Position of CameraTop relative to the feet is: [0.018861109390854836, 0.01083555817604065, 0.4378065764904022, -0.02850840799510479, -0.5012563467025757, 0.01773613691329956]
Position of CameraTop relative to the torso is: [0.02344038523733616, 0.00010688875045161694, 0.20985136926174164, 2.3283064365386963e-10, -0.450035959482193, 0.004559993743896484]
The result is of the calculation is:
[0.06300193387473892, 1.5725877596592652, 0.007176963936349509]
[0.06300193387474175, 1.5725877596592652, 0.007176963936349508]
[-0.06300193387429351, 1.5725877596592528, 0.007176963936346502]
Used the script> I received on Feb 28, which gives better values:
[2.2887494183024484, 1.3955349009119404, 0.6723625167661637]
[2.288749418302448, 1.3955349009119402, 0.6723625167661637]
Now the x and z are actually a bit too large.
April 8, 2024
Made a first recording of the red trajectory (Challenge2004 points). Started at the center, and moved the robot 2x60cm towards the yellow-on-top landmark. Turned towards the point before the DNT-goal (3x 50cm), next 3x 45cm, followed back to the origin with 4x47.5cm. From there directly towards the other goal (4x 52.5cm), turning to the last point, followed by 3x 40cm, turning to the origin (actually turned too far, towards the yellow point on the goal-axis) and in 3x 37cm back to the origin. This is the logfile and image sequence:
No landmarks detected (too far), and the camera angle is too high. This is from the last raw the bottom camera, which is slightly better (unfortunatelly the balance of the robot is not constant (tendensy to fall to the front).
Made a full circle again, now in "Crouch" with stiffness (1.0). This is the logfile. Unfortunatelly the motors became to hot at the second half of the recording, so after that the robot is no longer constant:
Lets see what the top camera sees for the last part:
Made a full circle again, now the Black circuit in "Crouch" with stiffness (0.9).
Also with stiffness 0.9 I got problems with heated joints after the 8th recording This is the logfile. No NaoMarks found. Halfway (recording 22) the motors were OK again, but that only meant that the stiffness was on (Crouch is only asked at the initialisation(:
Also made a video recording of half an hour, which is huge. Checking if this suggestion works: ffmpeg -i input.avi -vcodec msmpeg4v2 -acodec copy output.avi
The video is reduced to 2% of its original size:
April 4, 2024
Flashed Momo to NaoQi 2.8.7
Adjusted the script to record the position. Also detected the NaoMark again. At precise 1m from the top-camera the width-heigth was 0.109.
With the feet at 0.0, the width-height was 0.103 (distance top-camera to mark was 0.96m (checking via chess-board ground-tiles.
At 0.50m the width-height was 0.195
At 1.50m the width-height was 0.072
At 2.00m the width-height was 0.056
At 2.50m no landmark was detected
Added a StandInit to the script, the width-height at 1.5m is still 0.072
Note that I also printing the heading. When standing, the heading decreased from 13.0 to 6.0 (before the NaoMark was at the bottom of the image, now it is on the lower 1/4.
For the Gutmann dataset (2002) five points were used: [(0,0), (50, 0), (50,-50), (-100,0), (-100,50)] - all cm from the origin at the center of the field.
The positioning of the green markers can be traced back to 2003 Rules.
The 2004 SLAM challenge also five points were used: [(160,100), (180, -30), (50,-100), (-210,0), (-100,50)] - all cm from the origin at the center of the field.
The 2005 SLAM challengeanother five points were used: [(130,120), (220, -150), (130,120), (-210,90), (270,0)] - all cm from the origin at the center of the field.
No passing challenge in 2006
This 2007 overview paper highlights several earlier papers, for instance IROS 2004 from Dirk Schulz and Dieter Fox, where the green landmarks are clearly visible in Fig. 1.
Another nice ICRA 2005 paper cited is from Daniel Stronger and Peter Stone, callibrating the distance estimate to the beacon.
For EKF, the point to a paper from Middleton et al (2004). They also point to Dieter Fox's RoboCup 2004 paper, but that is using Particle filter to track to ball.
Bayesion localisation is already mentioned in the classic 1998 paper, including green markers. For localization, they point back to the tour-guide robotMinerva and Elfes PhD-thesis on Occupancy Grids
A first use of a EKF for localisation can be traced back to Leonard and Durrant-Whyte: 1991.
They cite several others that used EKF before them.
Marked the 3 sets of datapoints on the field: yellow Gutmann, red Challenge2004, black Challenge2005.
Connected Moos to LAB42, but Moos fails to standup due to 'Motors to hot'.
Made the first recording with the bottom camera (Moos is looking up) at the center point of Gutmann, looking towards the yellow goal (height of the bottom camera is 40cm):
Moved the robot to the 2nd point of Gutmann, 50cm forwards (height of the bottom camera is still 40cm). Rotated the robot 90 degrees towards the 3rd point:
Moved the robot to the 3rd point of Gutmann, 50cm forwards. Rotated the robot 135 degrees back towards the 1st point:
Moved the robot back to the 1st point of Gutmann, along the diagonal. Rotated the robot ~15 degrees back towards the 4th point (the robot is not stiff, it has a slightly different pose now):
Moved the robot to the 4th point of Gutmann, along the other diagonal. Rotated the robot in steps of 30~45 degrees towards the 5th point:
Moved the robot to the 5th point of Gutmann, 50cm forward. Rotated the robot in two steps of ~45 degrees back towards the 1th point. Moved the robot in two steps of 50cm back to the first point, so the last image should be the same as the first. Yet is clear that the head changed its angle:
Conclusion: On each of the recordings there is a landmark visible (or a goal). On each image there is a Nao tag, although sometimes (see 3rd point) the tag is occluded by the landmark. Still, I like to keep it there, because the overlap allows to estimate the angle to this landmark.
Checks to be made:
Is the middle circle better visible for the 2004 and 2005 challenge?
What is a good pattern to walk for those two challenges?
Can the Nao tags be recognized from this distance?
Unfortunately, the Aldebaran LandMarkDetection API only works for the current camera image, you cannot query a recorded image.
April 2, 2024
Looking if I can repair the wired connection of nb-ros, see April 2 entry of Computer Systems.
Switching to ws9, which is a Ubuntu 22.04 machine. After sudo apt install ffmpeg the command
ffplay rtsp://user:pw@ip:8554/CH001.sdp works also on this machine, although I get a warning:
[swscaler] deprecated pixel format used, make sure that you set range correctly
Next is to record this stream. Tried the gst-launch-1.0 command, which gives an error on the H.264 plugin:
ERROR: from element /GstPipeline:pipeline0/GstDecodeBin:decodebin0: Your GStreamer installation is missing a plug-in.
Additional debug info:
../gst/playback/gstdecodebin2.c(4701): gst_decode_bin_expose (): /GstPipeline:pipeline0/GstDecodeBin:decodebin0:
no suitable plugins found:
Missing decoder: H.264 (High Profile) (video/x-h264, stream-format=(string)avc, alignment=(string)au, codec_data=(buffer)01640032ffe1007767640032ad84054562b8ac5474202a2b15c562a3a1015158ae2b151d080a8ac57158a8e84054562b8ac5474202a2b15c562a3a10248521393c9f27e4fe4fc9f279b9b34d081242909c9e4f93f27f27e4f93cdcd9a6b4010007afcb2a400000fa00000ea618100000202fbf00000405f7ebdef85e1108d401000468ce3cb0, level=(string)5, profile=(string)high)
Installing this plugin with sudo apt install gstreamer1.0-libav solves this issue.
Read Chapter 2 of Wildberger's Divine Proportions (2005). In section 2.3 Diophantus shows up, who is famous for finding whole-number solutions are sought for equations, which explains why Wildberger mentions him. Chapter 2 gives some background on equations with multiple variables. Central is section 2.4, where Wildberger points out that for two linear equations with two variables, or the determinant is non-zero, or the coefficents of both equations are proportial (multiple solutions), and when non-proportional (and a zero determinant) there is no solution. This resonates with Diophantus who considered negative or irrational square root solutions "useless", "meaningless", and even "absurd". There is no evidence that suggests Diophantus even realized that there could be two solutions to a quadratic equation. It was also hard for Diophantus to come to a 'general' solution, each algebraric problem from Diophantus had its own solution method. Whitberger hopes to be more 'general' for geometric algebra.
March 28, 2024
Preparing the setup for the experiments for next week.
Found the 6 landmarks of the Gutmman experiment (although one landmark has to get the correct colors again, because it has the 2008 colors).
Although playing with white boarders, they used 4 landmarks in the 2004 rules. Note that year they also had a SLAM challenge, where they have stop at 5 marked spots.
In 2005 there was also a SLAM challenge, with 5 poses a little bit further on the field. From the 2005 rules it is clear that the landmarks are placed 15cm from the line.
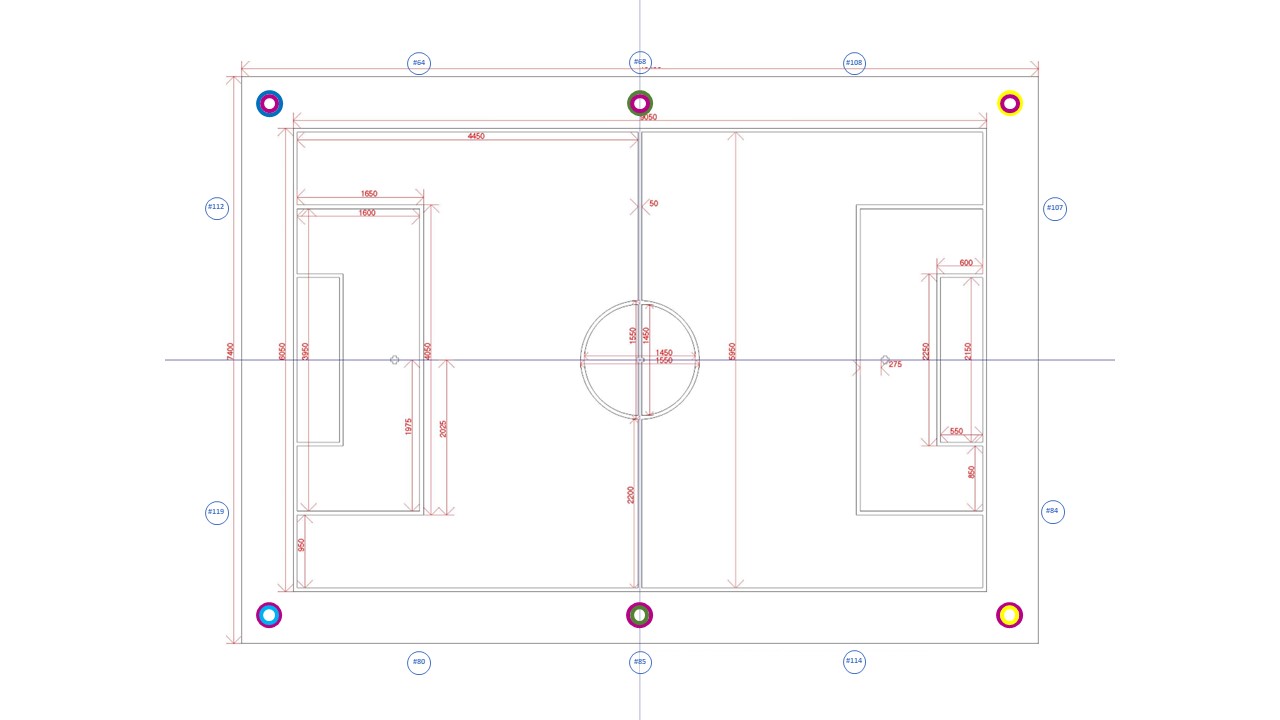
Put Nao tags all around the field. The center of the tag has for each landmark a slightly different height:
tag #68
15.7 cm
tag #64
16.4 cm
tag #108
16.3 cm
tag #107
15.8 cm
tag #85
15.6 cm
tag #80
16.8 cm
tag #84
15.6 cm
tag #114
16.0 cm
tag #112
15.5 cm
tag #119
16.0 cm
The tags are placed 90cm on the virtual penalty-area lines and the center line, 90cm from the outer line.
Put Aibo landmarks around the field (Guttmann style), 30cm from the outer line (2x 30cm in the corner):
The non-magneta color are at top at the bottom. The bottom tags are resp. #80, #85, #114 (left to right), the top tags #64, #68, #108. On the left (top to bottom) #112, #119, on the right #107, #84.
Mounted the GeoVision webcam above the field: In this image most tags (except those near the window) are at 1m distance (I later reduced that to all 90cm).
Changed the connection to nb-dual, and could record the new situation with the GeoVision Utility: Note the calibration patterns at the bottom of the pillars, next to the goals, at the window, on the ground. I also placed 8 balls on the field, and the OptiTrack calibration corner
March 27, 2024
Checked the user manual of the GeoVision IP-camera. Downloaded V9.0.1 from the GV-IP Device Utility from GeoVision site.
Succes, the Device Utility tool recognizes the camera, displaying its ip-address and indicating that it has Firmware version v1.06. Note that version v1.10 is available for the GV-EBD4700. The GeoVision itself is according to the Utility tool from the GV-FE420/FE3401 series. The time is off (Jan 2000). Using the Check Firmware update button fails, although the manual indicates version v1.07 for these cameras.
From the User Manual I recognize that the type is GV-FE421 / 521 / 2301 / 4301.
The ip-adress was modified, so printing a new label. Had to update my ethernet 6 adaption settings (from automatic to manual). Was using a 169.254.180.* subnet. Changed that to 192.168.0.*, now I have a view:
Switched to nb-ros.
The command gst-discoverer-1.0 rtsp://user:pw@ip:8554/CH001.sdp -v --gst-plugin-spew gives:
Analyzing rtsp://user:pw@ip:8554/CH001.sdp
Done discovering rtsp://user:pw@ip:8554/CH001.sdp
Analyzing URI timed out
Properties:
Duration: 99:99:99.999999999
Seekable: no
Live: yes
Tags:
video codec: H.264 (High Profile)
minimum bitrate: 11258880
maximum bitrate: 11258880
bitrate: 14834178
The command gst-launch-1.0 rtspsrc rtsp://user:pw@ip:8554/CH001.sdp -v --gst-plugin-spew doesn't work, I should have given the url as location:
Setting pipeline to PAUSED ...
Pipeline is live and does not need PREROLL ...
Progress: (open) Opening Stream
Progress: (open) Opening Stream
ERROR: from element /GstPipeline:pipeline0/GstRTSPSrc:rtspsrc0: Resource not found.
Additional debug info:
gstrtspsrc.c(7460): gst_rtspsrc_retrieve_sdp (): /GstPipeline:pipeline0/GstRTSPSrc:rtspsrc0:
No valid RTSP URL was provided
ERROR: pipeline doesn't want to preroll.
Setting pipeline to PAUSED ...
Setting pipeline to READY ...
Setting pipeline to NULL ...
Freeing pipeline ...
libavutil 55. 78.100 / 55. 78.100
libavcodec 57.107.100 / 57.107.100
libavformat 57. 83.100 / 57. 83.100
libavdevice 57. 10.100 / 57. 10.100
libavfilter 6.107.100 / 6.107.100
libavresample 3. 7. 0 / 3. 7. 0
libswscale 4. 8.100 / 4. 8.100
libswresample 2. 9.100 / 2. 9.100
libpostproc 54. 7.100 / 54. 7.100
[rtsp @ 0x7f5c48000b80] max delay reached. need to consume packet
[rtsp @ 0x7f5c48000b80] RTP: missed 6 packets
[h264 @ 0x7f5c48004840] mb_type 69 in P slice too large at 18 670
[h264 @ 0x7f5c48004840] error while decoding MB 18 67
[h264 @ 0x7f5c48004840] concealing 6815 DC, 6815 AC, 6815 MV errors in P frame
[rtsp @ 0x7f5c48000b80] max delay reached. need to consume packet
[rtsp @ 0x7f5c48000b80] RTP: missed 51 packets
[h264 @ 0x7f5c48004840] negative number of zero coeffs at 69 14/0
[h264 @ 0x7f5c48004840] error while decoding MB 69 14
[h264 @ 0x7f5c48004840] concealing 5868 DC, 5868 AC, 5868 MV errors in I frame
[rtsp @ 0x7f5c48000b80] max delay reached. need to consume packet
[rtsp @ 0x7f5c48000b80] RTP: missed 46 packets
[h264 @ 0x7f5c48004840] out of range intra chroma pred mode
[h264 @ 0x7f5c48004840] error while decoding MB 31 67
[h264 @ 0x7f5c48004840] concealing 6802 DC, 6802 AC, 6802 MV errors in P frame
[rtsp @ 0x7f5c48000b80] max delay reached. need to consume packet
[rtsp @ 0x7f5c48000b80] RTP: missed 51 packets
[rtsp @ 0x7f5c48000b80] max delay reached. need to consume packet
[rtsp @ 0x7f5c48000b80] RTP: missed 5 packets
[h264 @ 0x7f5c48004840] negative number of zero coeffs at 123 25
[h264 @ 0x7f5c48004840] error while decoding MB 123 25
[h264 @ 0x7f5c48004840] out of range intra chroma pred mode
[h264 @ 0x7f5c48004840] error while decoding MB 116 62
[h264 @ 0x7f5c48004840] concealing 11763 DC, 11763 AC, 11763 MV errors in I frame
[rtsp @ 0x7f5c48000b80] max delay reached. need to consume packet
[rtsp @ 0x7f5c48000b80] RTP: missed 75 packets
Input #0, rtsp, from 'rtsp://user:pw@ip:8554/CH001.sdp':
Metadata:
title : streamed by the GeoVision Rtsp Server
comment : CH001.sdp
Duration: N/A, start: 0.594500, bitrate: N/A
Stream #0:0: Video: h264 (High), yuvj420p(pc, progressive), 2048x1944, 7.50 fps, 16.58 tbr, 90k tbn, 15 tbc
Stream #0:1: Audio: pcm_mulaw, 8000 Hz, 1 channels, s16, 64 kb/s
Also mplayer rtsp://user:pw@ip:8554/CH001.sdp works, although I get a warning about a codec, and the image has additional bands:
Creating config file: /home/arnoud/.mplayer/config
MPlayer 1.3.0 (Debian), built with gcc-7 (C) 2000-2016 MPlayer Team
do_connect: could not connect to socket
connect: No such file or directory
Failed to open LIRC support. You will not be able to use your remote control.
Playing rtsp://user:pw@ip:8554/CH001.sdp.
Resolving ip for AF_INET6...
Couldn't resolve name for AF_INET6: ip
Connecting to server ip[ip]: 8554...
librtsp: server responds: 'RTSP/1.0 401 Unauthorized'
rtsp_session: unsupported RTSP server. Server type is 'unknown'.
libavformat version 57.83.100 (external)
libavformat file format detected.
[rtsp @ 0x7f5e411592a0]max delay reached. need to consume packet
[rtsp @ 0x7f5e411592a0]RTP: missed 6 packets
[h264 @ 0x7f5e404c47c0]mb_type 50 in P slice too large at 35 67
[h264 @ 0x7f5e404c47c0]error while decoding MB 35 67
[h264 @ 0x7f5e404c47c0]concealing 6798 DC, 6798 AC, 6798 MV errors in P frame
[rtsp @ 0x7f5e411592a0]max delay reached. need to consume packet
[rtsp @ 0x7f5e411592a0]RTP: missed 41 packets
[h264 @ 0x7f5e404c47c0]out of range intra chroma pred mode
[h264 @ 0x7f5e404c47c0]error while decoding MB 90 4
[h264 @ 0x7f5e404c47c0]concealing 7127 DC, 7127 AC, 7127 MV errors in I frame
[rtsp @ 0x7f5e411592a0]max delay reached. need to consume packet
[rtsp @ 0x7f5e411592a0]RTP: missed 77 packets
[h264 @ 0x7f5e404c47c0]P sub_mb_type 19 out of range at 32 67
[h264 @ 0x7f5e404c47c0]error while decoding MB 32 67
[h264 @ 0x7f5e404c47c0]concealing 7057 DC, 7057 AC, 7057 MV errors in P frame
[h264 @ 0x7f5e404c47c0]concealing 7680 DC, 7680 AC, 7680 MV errors in P frame
[rtsp @ 0x7f5e411592a0]max delay reached. need to consume packet
[rtsp @ 0x7f5e411592a0]RTP: missed 133 packets
[h264 @ 0x7f5e404c47c0]out of range intra chroma pred mode
[h264 @ 0x7f5e404c47c0]error while decoding MB 25 36
[h264 @ 0x7f5e404c47c0]concealing 10776 DC, 10776 AC, 10776 MV errors in I frame
[rtsp @ 0x7f5e411592a0]max delay reached. need to consume packet
[rtsp @ 0x7f5e411592a0]RTP: missed 65 packets
[lavf] stream 0: video (h264), -vid 0
[lavf] stream 1: audio (pcm_mulaw), -aid 0
VIDEO: [H264] 2048x1944 0bpp 16.667 fps 0.0 kbps ( 0.0 kbyte/s)
Failed to open VDPAU backend libvdpau_i965.so: cannot open shared object file: No such file or directory
[vdpau] Error when calling vdp_device_create_x11: 1
==========================================================================
Opening video decoder: [ffmpeg] FFmpeg's libavcodec codec family
libavcodec version 57.107.100 (external)
Selected video codec: [ffh264] vfm: ffmpeg (FFmpeg H.264)
==========================================================================
Clip info:
title: streamed by the GeoVision Rtsp Server
comment: CH001.sdp
Too many video packets in the buffer: (139 in 33658559 bytes).
Maybe you are playing a non-interleaved stream/file or the codec failed?
For AVI files, try to force non-interleaved mode with the -ni option.
==========================================================================
Opening audio decoder: [alaw] aLaw/uLaw audio decoder
AUDIO: 8000 Hz, 1 ch, s16le, 64.0 kbit/50.00% (ratio: 8000->16000)
Selected audio codec: [ulaw] afm: alaw (uLaw)
==========================================================================
AO: [pulse] 8000Hz 1ch s16le (2 bytes per sample)
Starting playback...
Too many video packets in the buffer: (139 in 33658559 bytes).
Maybe you are playing a non-interleaved stream/file or the codec failed?
For AVI files, try to force non-interleaved mode with the -ni option.
Movie-Aspect is undefined - no prescaling applied.
VO: [xv] 2048x1944 => 2048x1944 Planar YV12
A: 0.0 V: 0.6 A-V: -0.588 ct: 0.000 0/ 0 ??% ??% ??,?% 0 0
[h264 @ 0x7f5e404c47c0]mb_type 50 in P slice too large at 35 67
[h264 @ 0x7f5e404c47c0]error while decoding MB 35 67
[h264 @ 0x7f5e404c47c0]concealing 6798 DC, 6798 AC, 6798 MV errors in P frame
A: 0.0 V: 0.7 A-V: -0.708 ct: -0.012 0/ 0 ??% ??% ??,?% 0 0
[h264 @ 0x7f5e404c47c0]out of range intra chroma pred mode
[h264 @ 0x7f5e404c47c0]error while decoding MB 90 4
[h264 @ 0x7f5e404c47c0]concealing 7127 DC, 7127 AC, 7127 MV errors in I frame
A: 0.0 V: 0.8 A-V: -0.768 ct: -0.018 0/ 0 ??% ??% ??,?% 0 0
[h264 @ 0x7f5e404c47c0]P sub_mb_type 19 out of range at 32 67
[h264 @ 0x7f5e404c47c0]error while decoding MB 32 67
[h264 @ 0x7f5e404c47c0]concealing 7057 DC, 7057 AC, 7057 MV errors in P frame
A: 0.0 V: 0.8 A-V: -0.828 ct: -0.024 0/ 0 ??% ??% ??,?% 0 0
[h264 @ 0x7f5e404c47c0]concealing 7680 DC, 7680 AC, 7680 MV errors in P frame
A: 0.0 V: 0.9 A-V: -0.888 ct: -0.030 0/ 0 ??% ??% ??,?% 0 0
[h264 @ 0x7f5e404c47c0]out of range intra chroma pred mode
[h264 @ 0x7f5e404c47c0]error while decoding MB 25 36
[h264 @ 0x7f5e404c47c0]concealing 10776 DC, 10776 AC, 10776 MV errors in I frame
A: 0.0 V: 1.0 A-V: -1.008 ct: -0.042 0/ 0 ??% ??% ??,?% 0 0
[h264 @ 0x7f5e404c47c0]negative number of zero coeffs at 92 1
[h264 @ 0x7f5e404c47c0]error while decoding MB 92 1
[h264 @ 0x7f5e404c47c0]concealing 7509 DC, 7509 AC, 7509 MV errors in I frame
A: 0.0 V: 17.9 A-V:-17.880 ct: -0.828 0/ 0 26% 0% 0.0% 0 0
[h264 @ 0x7f5e404c47c0]negative number of zero coeffs at 18 71
[h264 @ 0x7f5e404c47c0]error while decoding MB 18 71
[h264 @ 0x7f5e404c47c0]concealing 6559 DC, 6559 AC, 6559 MV errors in P frame
A: 0.0 V: 17.9 A-V:-17.944 ct: -0.834 0/ 0 26% 0% 0.0% 0 0
[rtsp @ 0x7f5e411592a0]max delay reached. need to consume packet
[rtsp @ 0x7f5e411592a0]RTP: missed -42375 packets
[rtsp @ 0x7f5e411592a0]RTP: PT=60: bad cseq 1610 expected=bb97
[rtsp @ 0x7f5e411592a0]max delay reached. need to consume packet
[rtsp @ 0x7f5e411592a0]RTP: missed -42374 packets
[h264 @ 0x7f5e404c47c0]concealing 15360 DC, 15360 AC, 15360 MV errors in I frame
No pts value from demuxer to use for frame!
pts after filters MISSING
A: 0.0 V: 17.9 A-V:-17.944 ct: -0.840 0/ 0 27% 0% 0.0% 0 0
[rtsp @ 0x7f5e411592a0]max delay reached. need to consume packet
[rtsp @ 0x7f5e411592a0]RTP: missed 15 packets
[h264 @ 0x7f5e404c47c0]P sub_mb_type 6 out of range at 85 62
[h264 @ 0x7f5e404c47c0]error while decoding MB 85 62
[h264 @ 0x7f5e404c47c0]concealing 7388 DC, 7388 AC, 7388 MV errors in P frame
Note the additional bands at the left and right when using mplayer:
The command gst-launch-1.0 rtspsrc location=rtsp://user:pw@ip:8554/CH001.sdp ! decodebin ! videoscale ! videorate ! video/x-raw-yuv, width=512, height=486, framerate=15/1 ! jpegenc ! avimux ! filesink location=video.avi
as suggested in honours report still fails, but when I use video/x-raw it seems to work:
Setting pipeline to PAUSED ...
Pipeline is live and does not need PREROLL ...
Progress: (open) Opening Stream
Progress: (connect) Connecting to rtsp://user:pw@ip:8554/CH001.sdp
Progress: (open) Retrieving server options
Progress: (open) Retrieving media info
Progress: (request) SETUP stream 0
Progress: (request) SETUP stream 1
Progress: (open) Opened Stream
Setting pipeline to PLAYING ...
New clock: GstSystemClock
Progress: (request) Sending PLAY request
Progress: (request) Sending PLAY request
Progress: (request) Sent PLAY request
Got context from element 'vaapipostproc0': gst.gl.GLDisplay=context, gst.gl.GLDisplay=(GstGLDisplay)"\(GstGLDisplayX11\)\ gldisplayx11-0";
Got context from element 'vaapipostproc0': gst.vaapi.Display=context, gst.vaapi.Display=(GstVaapiDisplay)"\(GstVaapiDisplayGLX\)\ vaapidisplayglx0";
Redistribute latency...
The result was a video.avi, which I could display.
Also tried the gscam, which starts, I could see the topics published, but it seems that no new images are published (tried both rviz and image_view)
nb-ros gets terribly slow, time clean some things up.
nb-ros works without problems again.
I actually used the wrong ip, it is not strange that gscam didn't work. Yet, it would be nice if that was also visible in an error message.
In my GSCAM_CONFIG I had added also a format string, so that could have explained the problem. Yet, still no images, although I see a "Processing ..." message, which according to the gscam documentation indicates that gscam is happenly publishing. Yet, the GSCAM_CONFIG is still different from the one that works for the gst-lauch. For instance, the stream is piped to ffmpegcolorspace, while for gst-launch I used ! jpegenc ! avimux
The video looks impressive, the repository seems not be open yet.
March 21, 2024
Attended the presentation of Prof. Mubarak Shah. His work on the DeepFashion dataset is interesting, if you could predict a look by combining a style and pose. Could this also be done with a Nao robot?
The project is still available Wayback Machine, yet unfortunatelly only the welcome page and not the project updates.
I could ping the ip address, but displaying the RTSP stream via VLC (as suggested on stackoverflow fails.
This page suggest to do ffplay rtsp://username:password@server:554/path under Linux. Rebooting.
Could also ping the system from Ubuntu.
Tried ffplay, but got none response.
Installed mplayer, which gave more information:
Player 1.3.0 (Debian), built with gcc-9 (C) 2000-2016 MPlayer Team
do_connect: could not connect to socket
connect: No such file or directory
Failed to open LIRC support. You will not be able to use your remote control.
Playing rtsp://user:pw@ip:8554/CH001.sdp.
Resolving 192.168.1.222 for AF_INET6...
Couldn't resolve name for AF_INET6: ip
Connecting to server [ip]: 8554...
connection timeout
libavformat version 58.29.100 (external)
libavformat file format detected.
[tcp @ 0x7ff901e2b640]Connection to tcp://ip:8554?timeout=0 failed: Connection timed out
LAVF_header: av_open_input_stream() failed
Looking if rtsp-stream, which makes the stream available via HLS.
Checking the honours-report, I found that the installed additional libavcodecs with sudo apt-get install ubuntu-restricted-extras
They use the tool gst-launch, which can be installed with sudo apt-get install gstreamer-tools.
Yet, when called with gst-launch rtspsrc I get the response: ERROR: pipeline could not be constructed: no element "rtspsrc".
Yet, this documentation indicates to use gst-launch-1.0 rtspsrc , which gives:
(gst-launch-1.0:40182): GStreamer-WARNING **: 16:19:38.076: 0.10-style raw video caps are being created. Should be video/x-raw,format=(string).. now.
WARNING: erroneous pipeline: could not link videorate0 to xvimagesink0, neither element can handle caps video/x-raw-yuv, width=(int)512, height=(int)486
Run gst-inspect-1.0 rtspsrc, which shows the details of the plugin (usr/lib/x86_64-linux-gnu/gstreamer-1.0/libgstrtsp.so, v1.16.3, which is the latest version for Ubuntu 20.04.
Switched to nb-ros, which has Ubuntu 18.04 and ROS Melodic. Tried the suggested rosrun gscam gscam -s 0. Seems to work, although I had to modify the video/x-raw-yuv to video/x-raw. gscam seems to start OK:
[ INFO] [1711038757.387249784]: Publishing stream...
[ INFO] [1711038757.389062696]: Started stream.
The description of the gstreamer-tools was more informative.
Tried gst-discoverer-1.0 rtsp://user:pw@ip:8554/CH001.sdp -v --gst-plugin-spew, which gives:
Analyzing rtsp://user:pw@ip:8554/CH001.sdp
0:00:10.156645218 14369 0x562d1df274f0 ERROR default gstrtspconnection.c:1004:gst_rtsp_connection_connect_with_response: failed to connect: Operation was cancelled
0:00:10.157060197 14369 0x562d1df274f0 ERROR rtspsrc gstrtspsrc.c:4702:gst_rtsp_conninfo_connect: Could not connect to server. (Generic error)
0:00:10.157209044 14369 0x562d1df274f0 WARN rtspsrc gstrtspsrc.c:7469:gst_rtspsrc_retrieve_sdp: error: Failed to connect. (Generic error)
March 20, 2024
Stijn looked at the the notebook I received on January 3. The bug was that the optic distances were not recalulated for the calibration image. Now the distance is estimate on 572mm, which is close to the value I measured on March 13.
The x,y is the projection of the middle of the diagonal. The x is 134mm, which is the vector from the green dot to the blue one (nearly halfway the diagonal of 0.276586mm, 7x30 and 6x30 calibration blocks). The y is only 1mm (nearly on the diagonal). So, this is a possible solution.
So the middle of the diagonal between the green and blue dot is (163.0, 121.5) pixels, very close to the (160, 120) pixels - the middle of the image.
With the latest version of the notebook directly the position from the middle of the diagonal is computed. The result is [0.0014948266980226263, -0.004736693652417606, 0.5718525665221574]
Finished Chapter 1 of Wildberger's Divine Proportions (2005). In section 1.6 the ancient Greeks show up. I agree that points and lines are more basic elements than circles, but in this chapter their role is replaced with triangles, with the one with a straight angle given a special case (like circles vs elipses). Further lines are only straight in a perfect world, arcs can be find in many applications.
March 18, 2024
Finally had time to do some reading in Wildberger's Divine Proportions (2005). Finished up to section 1.3.
March 13, 2024
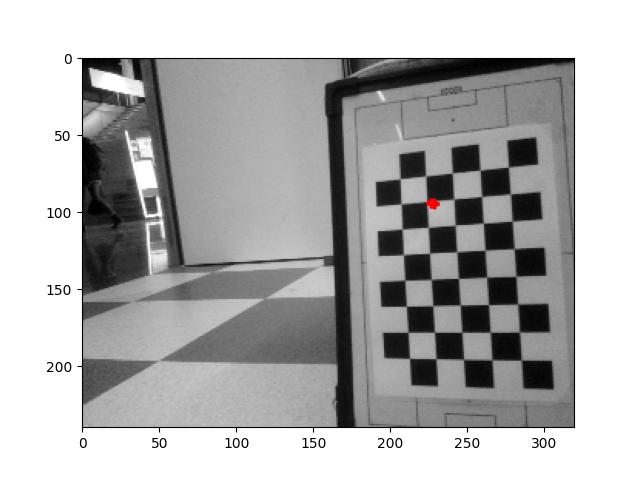
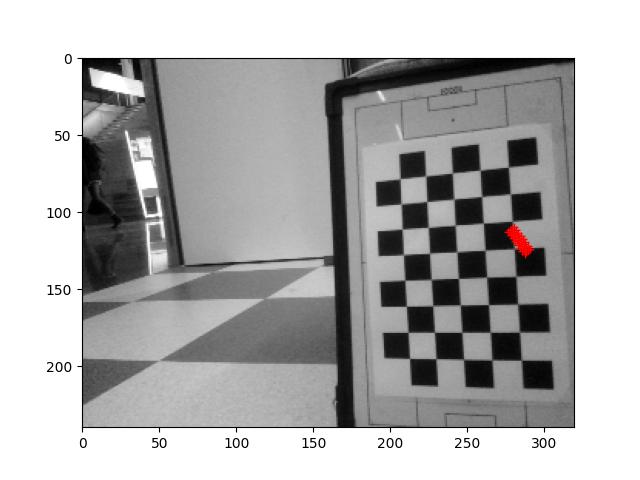
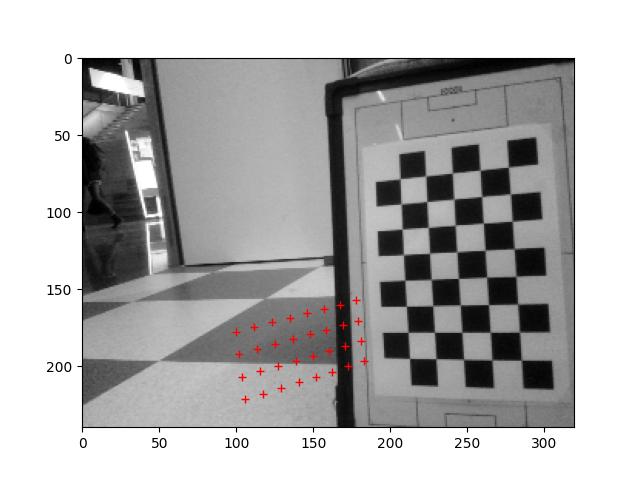
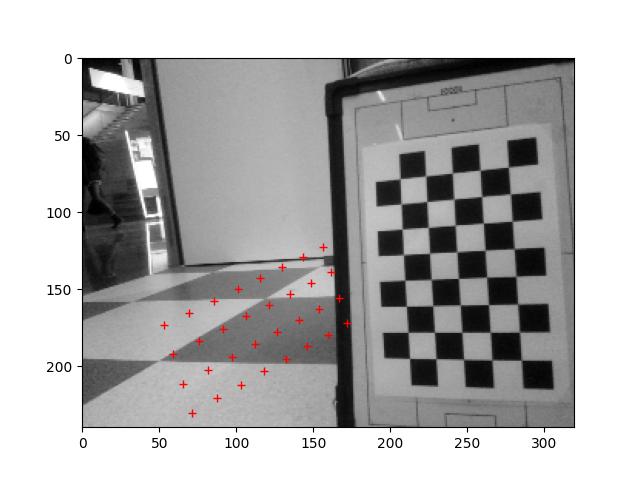
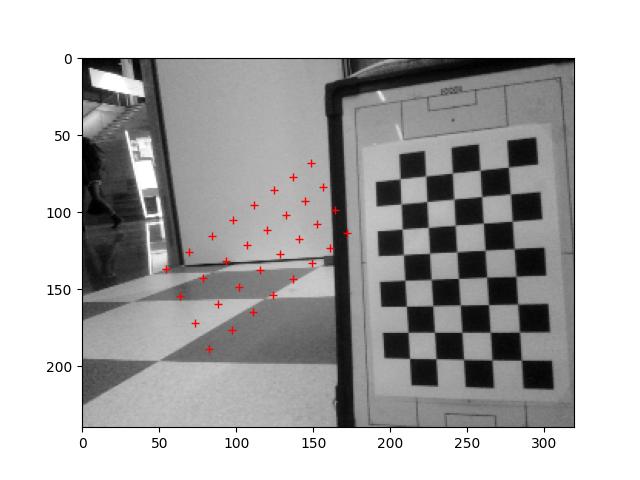
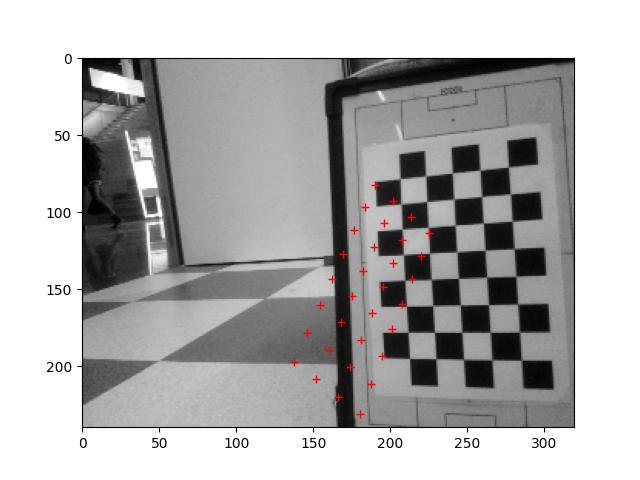
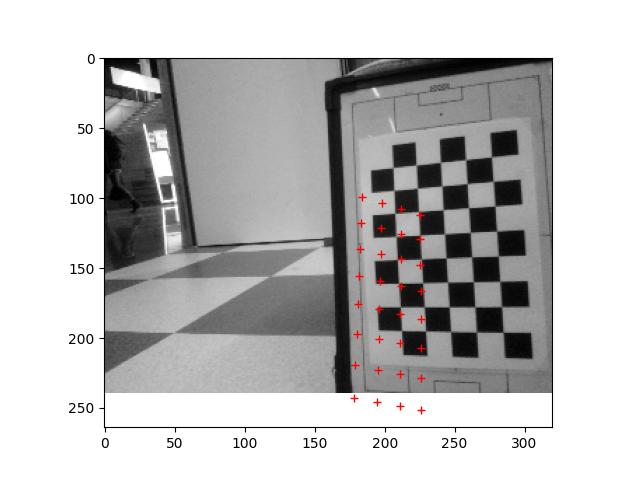
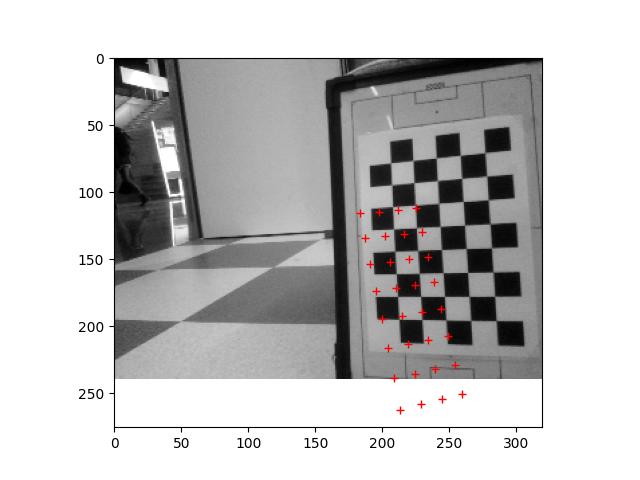
Run the 2024_03_13_Point_Position.ipynb, which calculates the positions of the center of the field, the penalty spot and the corner of the penalty area:
The centre spot is found quite well (few mm off). For penalty area there is an error of 10%. Could be the distortion of the iPhone.
Time to calculate the position from the calibration pattern with this code. The heigth of the top-camera is 32cm.
Looked back at the notebook I received on January 3. The result is that all estimates are in the 7.4 cm range (0.073, 0.074, 0.075). All for a direction of G of (0.0, 0.0, -1.0).
March 13, 2024
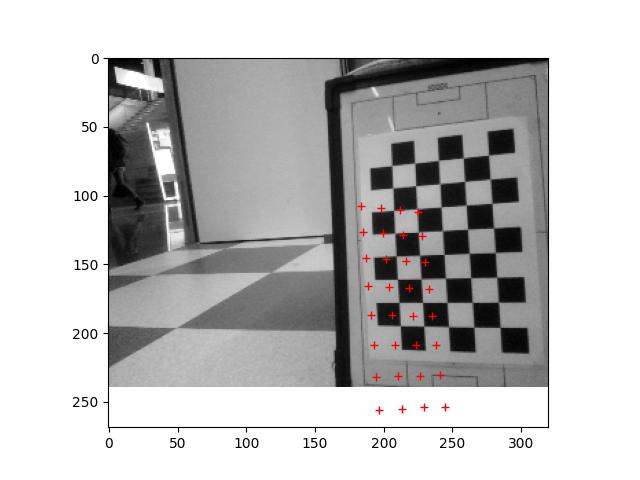
Testing the Focal_Length script from 21 Feb 2024.
Used this code to measure 4 points at the calibration image:
The four corners are at:
107 77
218 75
109 172
220 169
Checked the locations and corrected them a few pixels:
p0 = [ 105, 74] # green
px = [ 218, 71] # red
py = [108, 172] # magneta
pd = [221, 169] # blue
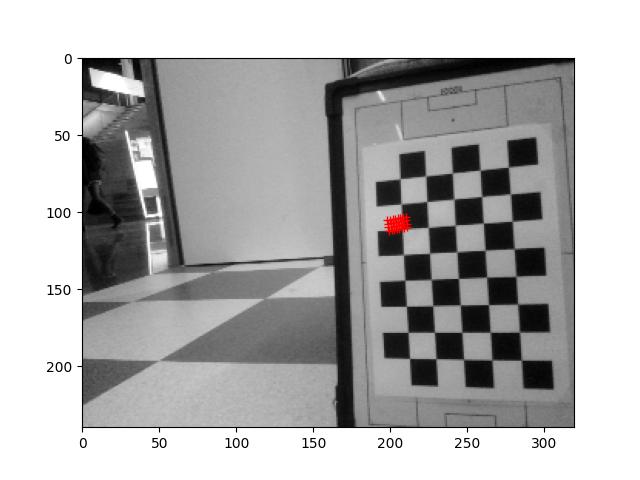
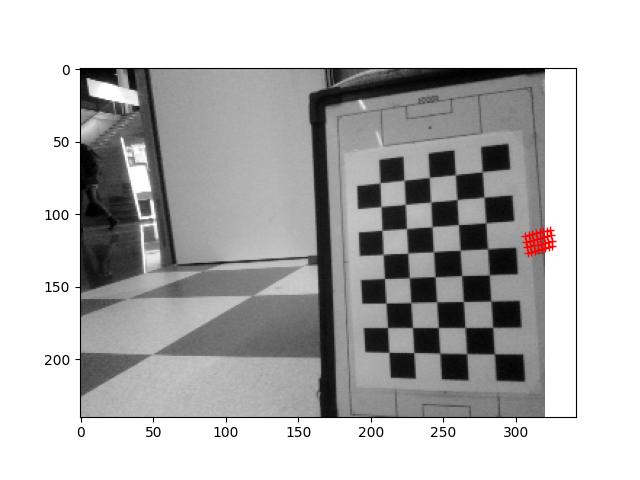
I measured with a ruler the distance from the top-camera to the calibration-paper (573mm). With this values I get a focal length of 310±2 pixels.
The three calculations (only used points p0, px, py as input, so I only had three distances), were 308.437, 312.113, 309.376
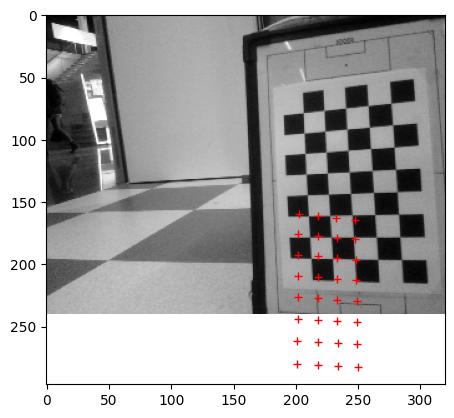
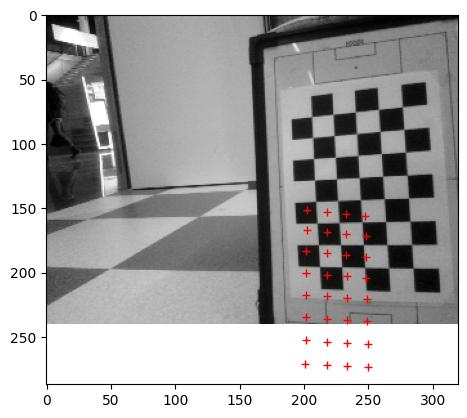
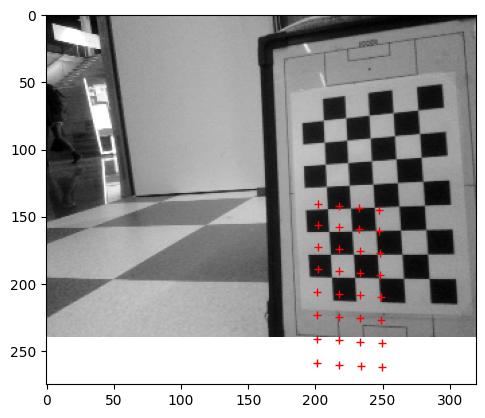
Adjusted in the VAMR the main.py to the correct square size (30mm) and adjusted the ../data/K.txt with the measured focal_length. Set the center of the image to (160,120) for the (320,240) image.
The result of the projection is as follows:
Gave a negative offset to x,y of -0.01:
Gave another negative offset to x,y,z of -0.01, because the pattern was also a little too big:
Not enough progress, so another negative offset to x,y,z of -0.02:
Tried a large offset on z alone of -0.1:
Wrong direction, so now a positive offset on z alone:
The z is now nearly the distance I measured for the calibration_pattern (583mm instead of 573mm). Yet, this image (top1) was actually measured closer (around 30cm). Gave a negative offset to x alone: -0.01.
That was too much. Gave a small positive offset to x and a small negative to y: ±0.005
Changed the sign of y. It is now a small negative value:
Increasing that small negative value with 0.02:
Increasing that negative value with 0.1:
Pose is now: -0.27981365 0.03236553 1.64141854 0.23986139 -0.12784288 0.58357325 [x-axis, y-axis, z-axis, x, y, z]
March 7, 2024
Run the camera calibration of opencv on the recorded images of yesterday. The result is not yet very convincing:
There were some extra recordings in the directory. Removed them but the result stayed the same.
The major problem seems to be the distortion parameters. The intrinsic camera matrix could still be usefull.
The intrinsic camera matrix found was:
[[295.29220318, 0. , 66.95675859],
[ 0. , 294.80631935, 60.09715144],
[ 0. , 0. , 1. ]]
This distortion seems to be wrong:
[[-1.06218485e+00, 2.77352462e+00, 9.41841234e-04,
4.04204303e-02, -2.35096080e+00]])
Added three images, but it the intrinsic camera matrix stays the same. Not strange because, this are the bottom, instead of the top-images. I removed a switchCamera from the script, because otherwise I had to do switch-camera in Choregraphe every time. Yet, still there are swapped. Added those three image to the calibration. Now a new intrinsic camera matrix is found:
[ 0. , 0. , 1. ]]
[[227.2295894 , 0. , 1e8.0264481 ],
[ 0. , 225.12302634, 100.75290004],
The new distortion vector is:
[[-0.10119761, 0.41299474, -0.00889553, -0.04518196, -0.24353712]]
The result is much better:
This was undistorted and rectified with this camera matrix:
[185.97145538, 0. , 83.80305436],
[ 0. , 219.23623798, 99.65795964],
[ 0. , 0. , 1. ]]
The total error improved with those 13 images from 0.9151 to 0.3038, while the range error improved from [0.15-1.568] to [0.07-0.846].
I couldn't not have seen that from the errors, because the total error improved with firt 10 images from 1.3158 to 0.3976, while the range error improved from [0.42-1.681] to [0.10-0.809].
Actually, this was done with a A3 print, where the squares were 35mm big (while I had specified 31mm). Rerun with the correct scale gives:
intrinsic_camera_matrix =
array([[231.87707508, 0. , 107.11343624],
[ 0. , 229.59405068, 100.41433318],
[ 0. , 0. , 1. ]])
Laminated the official A4_chessboard, with 30mm squares. Laminating guarantees that it the print is flat
Finding ChessBoardCorners fails, so I should try with a larger white boarder.
Problem was not the boarder, but the chessboard. Instead of 9x6, this one has 8x5 inner corners. Modified the code, which works:
intrinsic_camera_matrix =
array([[215.67955024, 0. , 66.28512101],
[ 0. , 214.36674177, 102.57425589],
[ 0. , 0. , 1. ]])
with error after correction:
total error: 0.4483108638979353
range error: 0.07 - 1.061
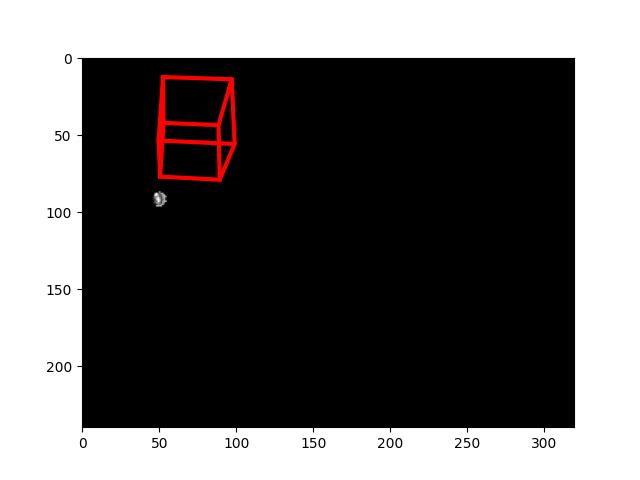
Running the projection code of VAMR exercise. This only uses the first 2 components of the distortion, but their values are much smaller than ours. The result is not that good:
Two things were wrong. The code used another chessboard (9x5), and the pose of the image recording is read from poses.txt. The calibration board was nearly 62cm in front of the robot. For the angles I used the alpha/beta from mark ID 64 (see March 1). Made the correct pattern, defined the pose as if in the origin, but the result is still quite distorted:
Set the distortion back to [0.0 0.0]. Now I understand the projection:
Rotated the pose 1.57 rad. That gives the same projection (expected a rotation of 90 deg). Yet, the first entry has index 0. So, modified the 2nd entry (corresponding to index 1). I enlarged the last entry (expecting a rotation, but it seems a zoom):
Enlarged the third entry, to see if this gives a rotation:
Maybe it is time to look at the rvecs, tvecs returned by calibrateCamera().
Filled in the rvecs and tvecs for this image, but that doesn't improve the transformation:
Moved the rotation around the z-axis back to nearly 90 deg and added an offset to x the transformation:
That was too much. Removed the offset to x, but swapped the y,z:
Even worse. Swapped y,z back Added a negative the offset of -10 to both x,z:
Rotation was a bit off, so added the z-value of rvecs. Further gave an negative offset of -1 to x alone:
The pattern is still much to small. I have to zoom. Further gave an negative offset of -1 to z alone:
The pattern became bigger, but also shifted to the right. Gave again an negative offset of -1 to both x,z:
The pattern became bigger, shifted to the right. Gave again an negative offset of -0,1 to both x,y,z. Also gave a negative -0.2 to z-rotation:
The pattern has nearly the right size. Now get the orientation right,Gave again an negative offset of -0,1 to y only. Gave again a negative -0.2 to z-rotation:
The pattern is nearly the right height. Gave again an positive offset of +0,1 to x only. Gave again a negative -0.4 to z-rotation:
Increased height slightly with a negative +0.3 on y. Gave again a negative -0.4 to z-rotation:
Found the pattern to narrow. Decreased the rotation around the x-axis with -0.03 and a negative -0.3 to z-rotation:
Overshoot with the rotation around the z-axis, so reduced it again with half of the rotation +0.15. The decrease on x made the pattern higher, not broader. Undid the modification on x-axis and did it on y-axis instead:
The current pose is -0.27981365 0.03236553 1.64141854 0.32986139 0.03484288 0.31357325, which I interpret as [x-axis, y-axis, z-axis, x, y, z]
Yet, this exercise already provides the calibrated camera-matrix, so I have to calibrate the Nao camera first.
Picked the chessboard that comes with Duckiebot, which has squares of 31mm:
The calibration is a wrapper around ROS1 Noetic camera_calibration. Looked at the Duckiebot Lecture. The ROS-calibration I have used before (April 1, 2020), but that is a process were the board is shown from different angles. Not clear how this can be done from one position for the Duckiebot.
Received the calibration script from Stijn. Converted the notebook with jupyter nbconvert --to script 2024_02_21_B_Camera_Calibration.ipynb (after installing sudo apt install jupyter-notebook jupyter-nbconvert on WSL Ubuntu 20.04.
Made a recording on Phineas. Yet, the bottom camera missed most of the chessboards, only one contained the OpenCV chessboard (partly):
So, A3 is a bit too large for nearby recordings. Tried record_top_bottom.py script, which fails on Subscriber "" doesn't exist
Just restarting naoqi didn't help, so did a reboot.
After that I could record top images:
March 1, 2024
The g-vector is in camera-coordinates, so should be [0,1,0]. With focal_length=300 the position of the right point in this images becomes. The ground truth should be something like [2.0, 0.75, 0.42]. Have to fix a recording the looking height and angle today:
[1.8689182894798262, 0.4178514179975671, 0.425527759797326]
[1.8689182894798262, 0.4178514179975672, 0.425527759797326]
[1.8689182894798262, 0.417851417997567, 0.42552775979732604]
('Execution time for Cartesian:', 0.00019700000000000273, 'seconds')
('Execution time for Spherical:', 0.0002269999999999911, 'seconds')
('Execution time for Classical:', 0.00022500000000000298, 'seconds')
With a smaller focal_length=200 the x gets smaller and the y bigger, so there is not much room there to optimize. First make sure that the g-vector is measured:
[1.2579578996663074, 0.554101762679377, 0.42757413213090417]
[1.2579578996663077, 0.554101762679377, 0.4275741321309042]
[1.2579578996663072, 0.5541017626793804, 0.42757413213090417]
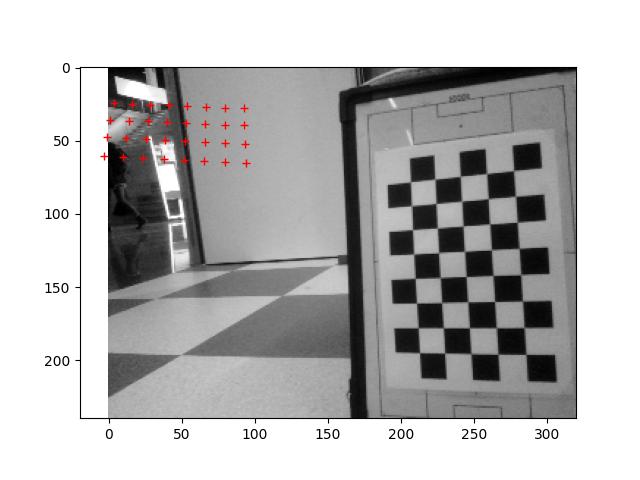
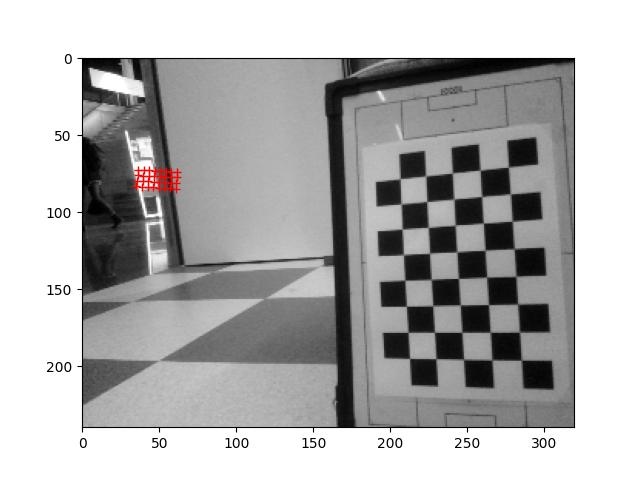
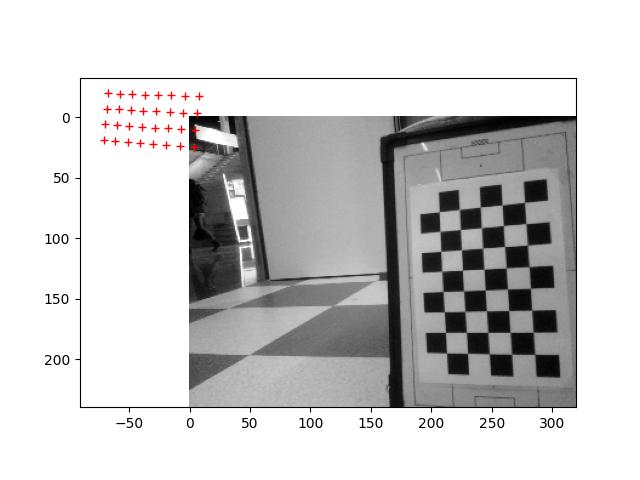
Run the ALLandMarkDetection example, but the result is Error with getData. ALValue = []. The Nao marks were laying flat on the floor, 1m before the robot, 25cm to the left and right.
Will try to have them vertical. After some checking that the angle of the head was right the Nao marks were recognized:
\*****
mark ID: 64
alpha 0.105 - beta -0.130
width 0.097 - height 0.097
mark ID: 68
alpha -0.394 - beta -0.127
width 0.103 - height 0.103
Test terminated successfully.
Added a third mark flat on the floor, in the middle of the grey square. Was also recognized:
mark ID: 119
alpha -0.132 - beta 0.128
width 0.087 - height 0.087
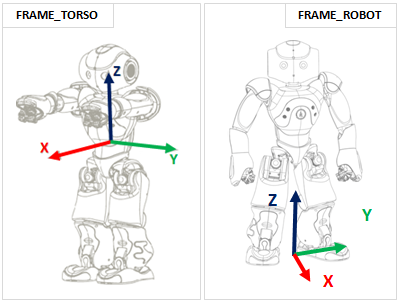
Added some code to the heading and the CameraPoseInFrameTorso, CameraPoseInFrameRobot and CurrentCameraName. The heading is less informative then hoped, according to documentation it should describes how the Naomark is oriented about the vertical axis with regards to the robot’s head:
[0.041618168354034424, 0.0054557775147259235, 0.16003167629241943, -3.725290742551124e-09, 0.35537365078926086, 0.13034796714782715]
[0.03313220292329788, 0.08003256469964981, 0.38497084379196167, -0.01542726345360279, 0.3661254048347473, 0.5185939073562622]
CameraBottom
mark ID: 64
alpha 0.105 - beta -0.130
width 0.097 - height 0.097
heading 6.000
mark ID: 68
alpha -0.394 - beta -0.127
width 0.105 - height 0.105
heading 0.000
mark ID: 119
alpha -0.132 - beta 0.128
width 0.087 - height 0.087
heading 0.000
The z from the CameraPoseInFrameRobot is quite informative. I am bit surprised on the angles. The rotation on the x-axis of the CameraPoseInFrameTorso seems to indicate that robot is looking straight, yet the CameraPoseInFrameRobot are all non-zero. Try to rotate the Torso 45 degrees, and keeping the head straight:
[0.022778037935495377, -0.032346054911613464, 0.16284701228141785, 2.9802322387695312e-08, 0.28634363412857056, -0.9572582244873047]
[0.012420577928423882, 0.03314564377069473, 0.3894890546798706, 0.04016384109854698, 0.22873975336551666, -0.5476271510124207]
CameraBottom
mark ID: 64
alpha 0.331 - beta 0.019
width 0.100 - height 0.100
heading 0.000
mark ID: 68
alpha -0.144 - beta 0.019
width 0.092 - height 0.092
heading 0.000
mark ID: 119
alpha 0.091 - beta 0.271
width 0.087 - height 0.087
heading 0.000
Note that there should only an offset difference between the CameraPoseInFrameRobot and InFrameTorso:
Run almotion_getPosition.py:
[-0.006128489971160889, -0.017168181017041206, 0.4340411424636841, 0.04378081113100052, -0.4417737126350403, -1.0146034955978394]
This was the top-camera relative to the World frame.
Extended the example with the position of the bottom-camera relative to the other frames:
Position of CameraBottom in World is:
[0.002508077770471573, -0.027322011068463326, 0.3894929587841034, 0.04077320173382759, 0.22780482470989227, -0.9866423010826111]
Position of CameraBottom relative to the feet is:
[0.012235380709171295, 0.03314674645662308, 0.3894929587841034, 0.04077322036027908, 0.22780483961105347, -0.5458199381828308]
Position of CameraBottom relative to the chest is:
[0.022827647626399994, -0.03231106698513031, 0.16284701228141785, -1.4901161193847656e-08, 0.28634360432624817, -0.955723762512207]
So, the last two values are the same as the CameraPoseInFrameTorso, CameraPoseInFrameRobot printed with the Nao marks.
Also tried almotion_cartesianArm1.py, but Phineas failed to wakeUp (still broken). Created a script query_transformation, that queries the position without husing SensorValues. The transform (Head-Torso) is:
[0.5299849510192871, 0.8167315721511841, -0.2281786948442459, 0.0, -0.7501595616340637, 0.5770177841186523, 0.32297226786613464, 0.0, 0.3954448103904724, -1.4901161193847656e-08, 0.9184897541999817, 0.1264999955892563, 0.0, 0.0, 0.0, 1.0]
With UseSensorValues=True the values are the same. The 16 values are actually the homogeneous matrix. The example program almotion_getTransform.py actually prints it as matrix (modified to query the Head-Torso tf):
0.529984951019 0.816731572151 -0.228178694844 0.0
-0.750159561634 0.577017784119 0.322972267866 0.0
0.39544481039 -1.49011611938e-08 0.9184897542 0.126499995589
0.0 0.0 0.0 1.0
Did a call to ALVisualCompassProxy.getMatchingQuality(). 100% inliers, 9 keypoints are matched. Still no deviation, but the matchInfo contains information.
Updated the script. Without turning, I get the output:
Quality of Matching: 100.000000 % inliers
Number of keypoints matched: 24
No deviation data in the memory (yet). ALValue = None
Found matchInfo data in memory.
Number of reference keypoints: 29
Number of current keypoints: 30
Number of matches: 24
Average match-distance: 0.000000
Number of inliers Y-axis: 24
Number of inliers Z-axis: 24
Have the feeling that a ALVisualCompassProxy.moveTo() is needed to get a Deviation update.
Checked the C++ code. They not use moveTo(). Yet, the set the referenceImage with pause() and initiate the resolution explitly.
The resolution is actually an enumeration: as specified here kQVGA has value 1.
Could not find any python example of the VisualCompass, so my ALVisualCompass.py is not made for nothing.
February 29, 2024
The speed improvement of 20% is nice, but should be put in perspective. One solution would be to implement that code in Rust.
Another option is to look at a geometrical algerbra implementation. The awasome GA page indicates two packages which have a python implementation of GA.
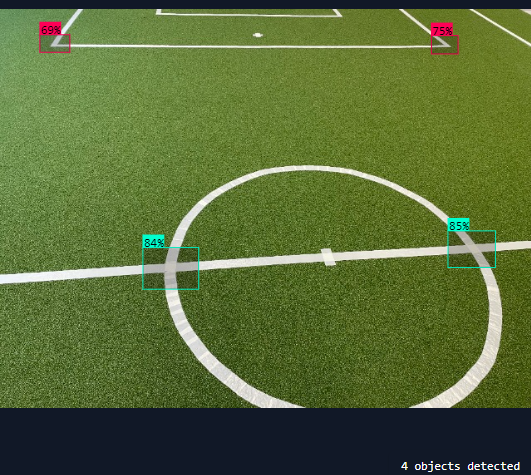
Gijs has trained a new version of the Field mark detector, now with Yolo v8 XL. The accuracy improved with 8%. For the three test images more intersections could be found.
The left X-crossing actually has a confidence of 48%
Did also an inference on the first Circle with the roboflow api, instead of the universe. Note that the x,y are much larger, so in this case the image is evaluated in full resolution (and not resized as in the roboflow universe). This explains the difference in results between the two methods (with the same model):
{'time': 0.8304823879998366, 'image': {'width': 4032, 'height': 3024}, 'predictions': [
{'x': 169.3125, 'y': 472.5, 'width': 141.75, 'height': 141.75, 'confidence': 0.8600128889083862, 'class': 'T-Intersection', 'class_id': 1, 'detection_id': '803547f1-d26a-4c8b-b96e-cf42bbafc687'},
{'x': 3502.40625, 'y': 124.03125, 'width': 90.5625, 'height': 90.5625, 'confidence': 0.8218392133712769, 'class': 'T-Intersection', 'class_id': 1, 'detection_id': '2ea6a28c-97dc-41b6-ac5d-66d26b07d712'},
{'x': 2431.40625, 'y': 190.96875, 'width': 98.4375, 'height': 106.3125, 'confidence': 0.8073841333389282, 'class': 'L-Intersection', 'class_id': 0, 'detection_id': '52873be5-d934-4ed2-9c2a-2c1d989fe846'},
{'x': 1356.46875, 'y': 1376.15625, 'width': 129.9375, 'height': 192.9375, 'confidence': 0.8027990460395813, 'class': 'X-Intersection', 'class_id': 2, 'detection_id': '6f710bd2-d823-4c80-a82a-66be7d0bf56b'},
{'x': 3327.1875, 'y': 196.875, 'width': 86.625, 'height': 102.375, 'confidence': 0.732304573059082, 'class': 'L-Intersection', 'class_id': 0, 'detection_id': '1b75edec-0fda-4841-be24-4891ef4d3d55'},
{'x': 3148.03125, 'y': 2764.125, 'width': 224.4375, 'height': 441.0, 'confidence': 0.58615642786026, 'class': 'X-Intersection', 'class_id': 2, 'detection_id': '4f3888e5-741b-4b2a-9602-d7ab47354582'}]}
Checked my WSL versions. My Ubuntu 22.04 has no python2 installed (yet),
I actually see two Ubuntu 20.04 versions. The LTS version has python2 and can import naoqi.
Did a pip3 install inference-sdk, which installed v 0.9.8 (and a few other packages).
Now python3 inference_roboflowXL_latest.py works for WSL Ubuntu 20.04 LTS (although no intersections were found, because Phineas was not looking at the field).
Try again at the field. Combined a recording (python2) with a inference (python3). One intersection was recognized:
{'time': 0.7488942249999582, 'image': {'width': 320, 'height': 240}, 'predictions': [
{'x': 113.0, 'y': 54.5, 'width': 16.0, 'height': 17.0, 'confidence': 0.7674422860145569, 'class': 'X-Intersection', 'class_id': 2, 'detection_id': 'b15195b1-5214-4587-bbd4-83634f68d603'}]}
The position was actually 2m from the center, 60cm to the right, slightly rotated head
As 2nd position was I place Phineas straight 2m from the center (height 40cm). Now two X-Intersections are recognized:
{'time': 0.7859433979997448, 'image': {'width': 320, 'height': 240}, 'predictions': [
{'x': 50.5, 'y': 191.5, 'width': 17.0, 'height': 19.0, 'confidence': 0.8084676265716553, 'class': 'X-Intersection', 'class_id': 2, 'detection_id': '1fbc4914-9fab-41b4-80c0-fe7d9336dcff'},
{'x': 285.0, 'y': 184.5, 'width': 16.0, 'height': 17.0, 'confidence': 0.7733885645866394, 'class': 'X-Intersection', 'class_id': 2, 'detection_id': '1a077778-4867-44c9-af55-d3f4d611449b'}]}
Time to calculate this distance. Looked if I could find the focal_length in pixels from Nao v6 specifications. Only noted that the AutoFoucs is by default disabled.
Checked the SPL 2024 rules: the two intersections should be 1.5m from each other (parameter J). Checked it on the field with a ruler.
Made a first version (with focal_length of 300). The result is consistent for the three methods, but x,z seems to be swapped and I expect a zero y:
[0.4327684334361374, 0.7165431941750662, 1.9181221484063473]
[0.432768433436139, 0.7165431941750658, 1.9181221484063473]
[0.43276843343613897, 0.7165431941750665, 1.9181221484063475]
Changing the focal length only changed the z-component. For focal_length=3000 I get:
[0.4327684334417105, 0.7165431941750652, 19.181221484063528]
[0.4327684334361517, 0.7165431941750653, 19.181221484063528]
[0.4327684334360871, 0.7165431941750598, 19.181221484063176]
Changed the focal_length to 65.7, expecting at least a correct height. Now I get a difference between the three methods:
[0.7697316452619173, 0.6984208658474038, 0.5215730713180746]
[0.7697316452619172, 0.6984208658474039, 0.5215730713180746]
[0.43276843343613886, 0.7165431941750656, 0.4200687505009901]
('Execution time for Cartesian:', 0.0001429999999999973, 'seconds')
('Execution time for Spherical:', 0.0002679999999999974, 'seconds')
('Execution time for Classical:', 0.0002030000000000018, 'seconds')
At least the two X-Intersections are recognized on the right locations:
For tomorrow, see if I can add the inverse kinematics to the image. Here is an example of almotion_getPosition.py which should give the position of the top camera, from Cartesian control page.
Note that with a LandMark detection also CameraPoseInFrameTorso, and CameraPoseInFrameRobot are published, see for more info frames:
I could modify the almotion_cartesianArm1.py script to get the head trajectory with getTransform(effector, frame).
Printed out the Nao marks (also nice for Behavior-Based Robotics).
Could use this publication as citation for the Nao mark, although there conclusion is that QR-codes are better than Nao marks.
Earlier work from Aldebaran is published here, but that is localization with bar-codes (prior to the Nao marks)
February 28, 2024
Looked at Roboflow project, but saw no optionto download the labels.
There is an option to download the model as pt, which contains the labels.
Looked what I have done last week. Opened a WLS Ubuntu 22.04 terminal and went to ~/src/distance.
Oldest file first. Running python3 hello_inference.py failed on a missing bracket.
Running python3 230-yolov8-object-detection.py failed on missing get_ipython (for run_line_magic)
Running python3 yolo8_object_detection.py ~/src/distance/models/field_mark_yolov8.xml ~/src/distance/annotated_points.png CPU failed on tensor with negative dimension -71.
Looked at ~/src/distance/models/field_mark_yolov8.xml. At, the end, the rt_info has the attribute names with the value "{0: 'L-Intersection', 1: 'T-Intersection', 2: 'X-Intersection'}".
Still, something goes wrong in detect()
Actually, the value should be {0: 'Ball', 1: 'GoalPost', 2: 'L-Intersection', 3: 'Penalty', 4: 'Robot', 5: 'T-Intersection', 6: 'X-Intersection'}. Yet, still fails on the post_processing step.
The call python3 inference_roboflow.py still works.
Also tried python3 onnx_inference.py, which still fails on the image reshape.
Tried to use thumbnail to resize annotated_points.png, but the size is actually smaller ((382, 470), so it stays the same. Still, the problem is that a tensor(float) is expected, while uint8 are given. The code of hello_inference has some preprocessing steps to convert to floats.
Received the calculations of Stijn in this script (converted to python2.7). The difference in position is minimal, the Spherical calculation is actually slightly slower.
[1.4577153056471355, 0.5902774294597717, 0.9611778996370347]
[1.4577153056471346, 0.5902774294597719, 0.9611778996370347]
For 5.000 calculations:
('Execution time for Cartesian:', 0.1328990000000001, 'seconds')
('Execution time for Spherical:', 0.13663500000000006, 'seconds')
For 500.000 calculations:
('Execution time for Cartesian:', 13.398447, 'seconds')
('Execution time for Spherical:', 13.777861, 'seconds')
Tried if the spl field_mark model could recognize the kitchen floor of Stijn, but that fails (0 objects detected)
For today's recordings the field_mark model works fine. For CenterCircle1:
To finish the day, the Classical method is 20% slower (5000 iterations):
[1.4577153056471346, 0.5902774294597717, 0.9611778996370343]
('Execution time for Cartesian:', 0.13376300000000008, 'seconds')
('Execution time for Spherical:', 0.137783, 'seconds')
('Execution time for Classical:', 0.16041700000000003, 'seconds')
February 22, 2024
Trying to reproduce last weeks progress.
On nb-dual (Ubuntu 22.04 WSL), entered directory ~/git/openvino_notebooks/notebooks. Started jupyter lab and copy and pasted the sugggested URL with port 8888 in a browser.
Loaded 001-hello-world-ipynb. Could execute all cells.
Followed the instruction of build samples and looked at the first part of Linux build instructions on github.
Started with:
git clone https://github.com/openvinotoolkit/openvino.git
cd openvino
git submodule update --init --recursive
Next would be cd samples/python/hello_classification. The command python3 -m pip install -r ./requirements.txt indicates that both opencv-python and numpy are already installed.
Running the example can be done with python hello_classification.py . The model and image can be found in ~/src/distance.
Run the example with python3 hello_classification.py ~/src/distance/models/field_mark_yolov8.xml ~/src/distance/annotated_points.png CPU, which gave the result:
[ INFO ] Creating OpenVINO Runtime Core
[ INFO ] Reading the model: /home/arnoud/src/distance/models/field_mark_yolov8.xml
[ INFO ] Loading the model to the plugin
[ INFO ] Starting inference in synchronous mode
[ INFO ] Image path: ~/src/distance/annotated_points.png
[ INFO ] Top 10 results:
[ INFO ] class_id probability
[ INFO ] --------------------
[ INFO ] 16761 655.9997559
[ INFO ] 16760 655.9997559
[ INFO ] 16775 655.9997559
[ INFO ] 16762 655.9997559
[ INFO ] 16763 655.9997559
[ INFO ] 16779 655.9997559
[ INFO ] 16778 655.9997559
[ INFO ] 16767 655.9997559
[ INFO ] 16769 655.9997559
[ INFO ] 16768 655.9997559
[ INFO ]
[ INFO ] This sample is an API example, for any performance measurements please use the dedicated benchmark_app tool
Compared Gijs his code in onnx_inference.py with the hello_classification.py example.
Small difference onnx.load() vs onnx.core.read_model()
Another small difference: PIL.Image.open() vs cv2.imread()
Gijs is using a onnx.runtime.InferenceSession, while hello_classification uses openvino directly.
Copied the hello_classification.py as hello_inference into ~/src/distance. Added at the end onnxruntime code. Providing the img as read with cv2.imread() gave the error Actual: (tensor(uint8)) , expected: (tensor(float))
The onnx file contains the width, the xml file the compiled model. Looking into the code of 230-yolov8-optimization (step 5)
Note that in step 6 they did a resize to (224, 224)
Added the preprocessing and postprocessing of 230 code. Seems to work, I only get the error related with 4th channel:
Can't set the input tensor with name: images, because the model input (shape=[1,3,640,640]) and the tensor (shape=(1.4.640.640)) are incompatible
Added a convert("RGB") to the Image.open(), which seem to work. The next error is in post-processing: Trying to create tensor with negative dimension -71: [0, -71]
Looked at the shape of the boxes. With yolov8n.onnx the shape is (1, 84, 8400), while with the field_mark_yolov8.onnx the shape is (1, 7, 8400)
The yolov8n.onnx seems to work on annotated_points.png (no warnings), have to see the result.
Tried to load the metadata.yaml, which has the names. Unfortunatelly this fails. Maybe just load the pt for yolov8n, and create the 7 names manually for the field_mark.
Could also look at the online model for the names.
February 14, 2024
One option could be to run yolo from nb-dual, because running it natively would require cross-compilation with Naoqi C++, as indicated here.
An example of such attempt can be found at this Bsc-thesis (Hochschule der Medien Stuttgart, Jan 2016)
This thesis remarks that the ALVisionRecognition module can also be trained to learn to identify objects, when annotated image are available.
At the end, the detection isn't performed with the CNN on the robot, but grabs the image remotely (on the robot) and uses the cafe-framework on his laptop.
It uses a yolov8s model, and reaches a mAP of 68.8%, a precision of 73.5% and a recall of 71.5%. It was trained with 3344 images (2348 training / 658 validation / 338 test). Yet, not all contained intersections. There are 181 images with L-intersections, 128 images with T-intersections, and 186 X-intersections.
Did on my WSL Ubuntu 22.04 partition pip install inference-sdk
Run the inference_roboflow.py on annotated_points.png, which gave a T-intersection with 70% confidence in the web-interface. Yet, loading cv2 fails on libGL.so.1: cannot open shared object file: No such file or directory
When installing inference-sdk, package opencv_python_headless-4.9.0.80-cp37 was installed. Note the python version (should be cp310).
This discussion indicates that indeed opencv_python_headless should be installed, but not for the latest release.
Downgrading with pip install opencv-python-headless==4.8.1.78.
Next problem is Unable to import Axes3D. This may be due to multiple versions of Matplotlib being installed (e.g. as a system package and as a pip package). As a result, the 3D projection is not available.
Did apt list --installed | grep matplot, followed by pip install opencv-python-headless==4.8.1.78.
The result (after adding an additional print statement) is python3 inference_roboflow.py
{'time': 0.12775821300010648, 'image': {'width': 382, 'height': 470}, 'predictions': [{'x': 204.0, 'y': 226.0, 'width': 34.0, 'height': 36.0, 'confidence': 0.6900203824043274, 'class': 'T-Intersection', 'class_id': 1, 'detection_id': '9cf3dbf6-433e-45e9-9b3e-613953ae5353'}]}.
Downloaded field_mark_yolov8.onnx. Install v2023.3.0 with pip install openvino. Checked the installation with python3 -c "from openvino import Core; print(Core().available_devices)", which gives ['CPU'] (note that the e-GPU is not connected).
The onnx is not enough for openvino, I also need the xml with the configuration. Should try hello image classification first.
Running jupyter lab notebooks/001-hello-world/001-hello-world.ipynb, which fails on missing module tqdm.
Running pip install -r requirements.txt, which also install openvino_dev, tensorflow, onnx, keras, and much more! Note that it up / downgraded numpy and pandas (from resp. 1.22.4 to 1.26.4 and 2.2.0 to 2.1.4). But tqdm-4.66.2 isi now installed.
The notebook still fails, on AttributeError: 'FloatProgress' object has no attribute 'style', which indicates Widget Javascript not detected. It may not be installed or enabled properly. Reconnecting the current kernel may help. This can be solved with pip3 install --upgrade ipywidgets, followed by jupyter nbextension enable --py widgetsnbextension and a restart of jupyter-server. Recognized the 'flat-coated retriever' from this image:
Next example to test is 230-yolov8-object-detection.ipynb, which looks at this image:
In this notebook it converts the yolov8n.pt to yolov8n.onnx (with ONNX) and a directory yolov8n_openvino_model, which contains yolov8n.xml
Tried to export an xml from the onnx file, but I get: TypeError: model='models/field_mark_yolov8.onnx' must be a *.pt PyTorch model, but is a different type. PyTorch models can be used to train, val, predict and export, i.e. 'yolo export model=yolov8n.pt', but exported formats like ONNX, TensorRT etc. only support 'predict' and 'val' modes, i.e. 'yolo predict model=yolov8n.onnx'.
Used this example to convert to an openvino model.
Did pip install onnxruntime and tried to run python3 onnx_inference.py, but that fails on the image format:
img = img.reshape(1, 3, 640, 640)
ValueError: cannot reshape array of size 179540 into shape (1,3,640,640)
Found a multi-hypothesis localization Msc-thesis from 2018 from Universidad de Chili.
February 7, 2024
Discussion today about the content of the paper. Most interesting for RoboCup would be a comparison of the pose according to the IMU + head-kinetics vs the estimate of our algorithm, with the OptiTrack as ground truth.
The object-detector on the iPad is based on the Lindeberg derivatives method, a higher order derivate of the Laplacian (with an additional scale derivative(..
Stijn checked the code from yesterday (measure_classic_3D_Position_execution_time_v1.py). It seems that I forgot the term (1 - s_1) in the CrossCosinus law and used cos() where I should have used sin(). In his calculations the height is 0.745m again.
February 6, 2024
Prof. Nardi has written this overview paper
of strategies of game-playing in different RoboCup leagues (both real and simulated).
Ferdinand was flashed, so I lost the previous scripts. Made a new ~/scripts directory.
Found run_thousand_times_with_time.py back. Ferdinand was flashed, so I lost the previous scripts. Made a new ~/scripts directory.
Wildberger uses the Cross law to calculate the spread (Q_2 + Q_3 - Q_1)^2 = 4 Q_2 Q_3 (1 - s_1), so: s_1 = 81/130, s_2 = 49/50, s_3 = 49/65.
Added some code to do checks of the angles from our own example:
angle between those distances from spread 0.077709078294 and cos 0.278763480919 is 73.8135807514 degrees
angle between distance 1 and gravity from spread 0.301358242234 and cos 0.54896105712 is 56.704233693 degrees
angle between distance 2 and gravity from spread 0.086563793294 and cos 0.294217255262 is 72.8893934853 degrees
Added some extra code, which gives:
quadrance L 211177.749937 or distance L 459.540803343 in pixels should be equivalent with 0.26 meters
distance 1 3663.34580677 in pixels should be equivalent with distance 2.07265579646 meters, which gives a height of 0.934848479392 meters
distance 2 3203.80500343 in pixels should be equivalent with distance 1.81265579646 meters, which gives a heigth of 1.27934118329 meters
So, this is still not the expected 0.745 meters. Also the distance seems 4x larger than x, which seems to be originate from the focal_distance of 3062 pixels.
This unraveled blog gives a recent overview of the different variants of Yolo.
January 26, 2024
Reading the xYOLO paper, which shows 70x faster ball detection on a Raspberry Pi 3. The algorithm is from the Humanoid team Black Sheep, altough only Yolo-v3 in their github.
The corresponding dataset can be found at bit-bots repository. The major trick they found was to replace the last layers of the Darknet backbone with XNOR layers. Doing that for the first layers didn't work. Because later version of Yolo no longer use the Darknet backbone, I don't know if this also works for Yolo v8.
January 24, 2024
According to their linkedin post, is Yolo-OBB less sensitive to background noise. Maybe good to try for RoboCup soccer.
Couldn't find directly a publication on Yolo v8 OBB, this litchi detector paper seems to be the best match.
January 18, 2024
Trying to run the 3D_distance script on Ferdinand, but it has problems with the Python3 syntax.
Installing 2to3 package and running 3to2 -w 3D_distance.py, yet this also fails on p1_optic.
Problem was the python2 print-statements in the python3 code. Corrected this, converted the file and send it to Ferdinand.
Still fails, but on missing package statistics, which can not be installed:
Could not install packages due to an EnvironmentError: [Errno 30] Read-only file system: '/usr/lib/python2.7/site-packages/docutils-0.18.1.dist-info'
As alternative, I could use sum/len, as suggested here.
Seems that I am blacklisted, by trying to reach Ferdinand via ssh as root. Could still reach Ferdinand via ethernet-wire (ip is easy to find with RobotSettings tool).
The mean and stdev were only used at the end, in commented out code. So, I could run 3D_position.py on Ferdinand.
Execution of 5x this script is 0.00601 seconds, including printing.
Rewrote calculations to function, without print-statements. Executing this 5x is done in 8.9 10^-05 seconds, 50x in 0.000544 sec, 500x in 0.00545 sec, 5000x in 0.0533 sec, 50.000x in 0.532 sec, 500.000x in 5.33 sec.
The calculation of this function are based on equation (7)-(9) of our paper, which seems derived from the Triple spread formula. (actually the cross-law).
For this problem, Michael adds the note that Wildberger calculates in his Trigonometry Challenge paper for the classic approach A2 C A1, and for the rational approach A3 C A2.
January 17, 2024
To measure clock time was easy (time.time()) but the call to time.process_time() was not working on the Nao robot.
Luckely the call time.clock() actually works. This is the script
y = [108, 172] # magneta.
January 15, 2024
Checked the status of Appa. After switching batteries, I now changed heads. With the Appa head the body of Ferdinand booted without problems, but the Appa body didn't boot with the head of Ferdinand.
So, it is not a SW problem, or a battery problem. It is probably a fuse on the main-board in the body. Maybe an error with old- and new-chargers.
Checked my archive. It was also Appa which was repaired in June, 2023. The repair was a failure from the battery board fuse. RMA 01213358
At nb-dual, in my Ubuntu 22.04, I installed jupyter-notebook and jupyter-nbconvert. Converted the notebook to python with command jupyter nbconvert --to script 2024_01_03\ 3D_Position.ipynb.
That runs fine on nb-dual when I run it with python3:
-942.5 1776.5
-434.5 836.5
[-942.5, 1776.5, 3062]
[-434.5, 836.5, 3062]
0.301358
0.086564
0.077709
0.067600
0.489 m
0.004 m
0.745 m
Copied the file to Moos (directory ~/code) and run it succesfully with python3.
According to CPU benchmark, E3845 efficiency is 5,958 MOps/Sec Integer Math and 1,349 MOps/Sec Floating Point Math. Also interesting is the Physics measure of 127 Frames/Sec
According to this post, a great overview of compatibility is github page with code and this webpage. See there point 5, how CUDA code can be translated to SYCL code, which can run on Intel integrated graphics (although the Bay Trail will be too old, combined with crosscompilation to the ARM-chip of the CPU to make it extra hard).
This French thesis from 2014 compares in section 2.3.5.1 N-Jets with other spatio-temporal cuboids, such as histograms of partial derivatives and histograms of optical flow. The classic SIFT/SURF/ORB miss the temporal component, and are described in section 2.3.4.
January 4, 2024
Checked the Jupyter notebook with Rational Trigonometry code. Reproduces fine. The height of this image is 0.745 m:
Related to the Geometrical Algebra paper is Rational trigonometry via projective geometric algebra (2014), who is actually not cited in Francisco G. Montoya's paper. This paper concludes: "This translation of a small sampling from Part I: Preliminaries of [Wil05] demonstrates
that the algebra P(R 2,0,1) is a natural environment for presenting these results. Statements
and proofs are often shorter and more direct than the analogous calculations involving
coordinates. One also notices otherwise hidden connections, such as the underlying, exact
duality of quadrance and spread. I am not aware of any result in universal geometry which
cannot be translated to PGA; "
Looked at my BBR course and installed pip install opencv-python==4.2.0.32 and pip install opencv-contrib-python==4.2.0.32. Also installed pip install matplotlib, which gave v3.7.4.
The trick to go from an numpy array to the tuple needed for opencv's cv2.circle() is simply tuple(p1). Point p1 is now annotated red on the inner circle, point p2 is annotated blue:
Tried adaptive thresholding, but there are too many spikkles in the field (higher blur?!), so actually a fixed high treshold works best:
Let see if we can found the largest contour. In this image 3695 contours are found. There are 4 contours with a area larger than 10.000 pixels. One of them is the white/black soccer ball, the other the origin. Two circles can be found at the center-circle:
Should look for a way to remove straight lines, for instance based on this example.
Looked at the actual shape of the largest contours. Actually, the circle is drawn from the blue line:
Looking at this Canny edge example. Running the code (don't forget to remove cv2.imshow()) as is, only one line seems to be detected:
Yet, the preprocessing could be improved, the result after the Erosion/Dilation doesn't look that good. Using the previous threshold gives more or less the same result. Actually 31935 lines are found. Could try to filter on length.
With a minimum length of 300 (instead of 30) pixels, 715 lines are found. A minimum of 900 gives 33 lines. A minimum of 1200 gives 23 lines. A minimum of 200 gives 4 lines. Yet, all 4 lines are actually the same line:

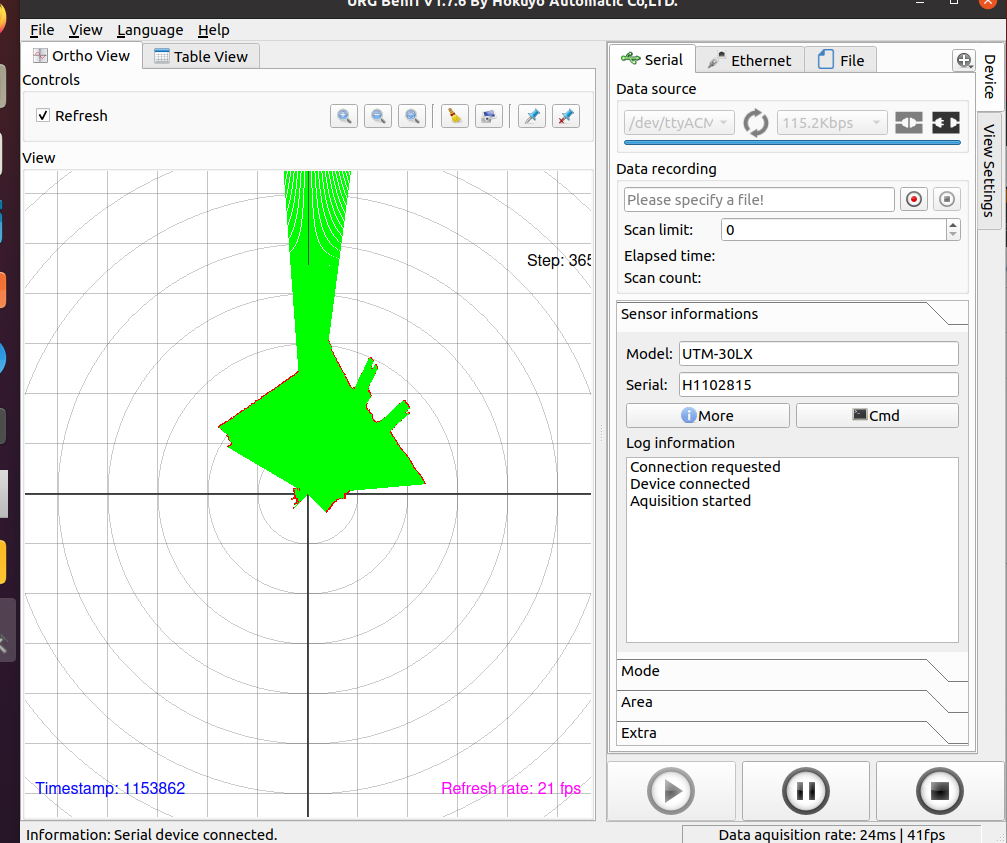
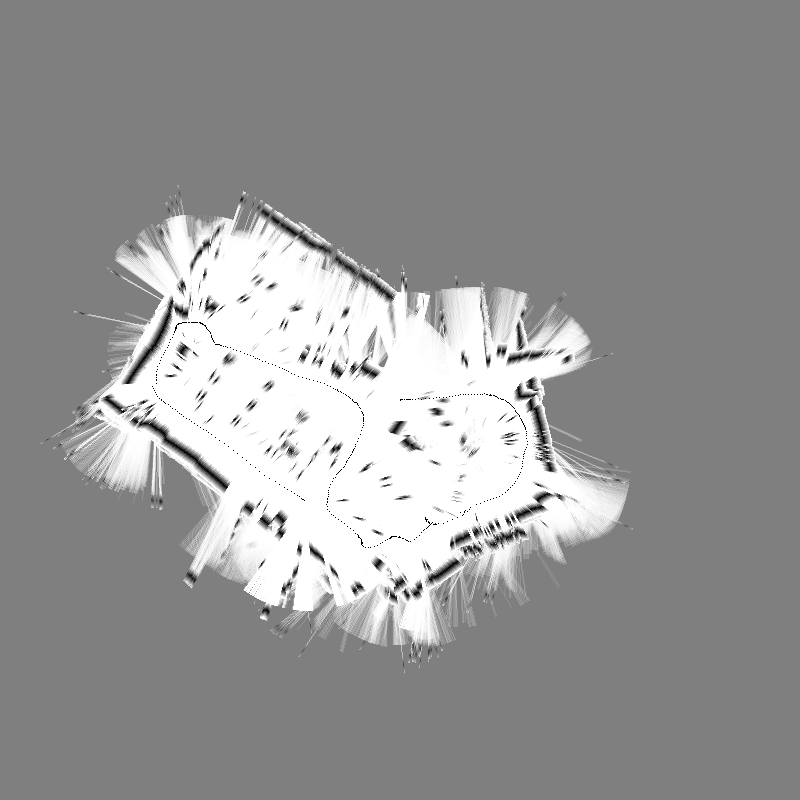
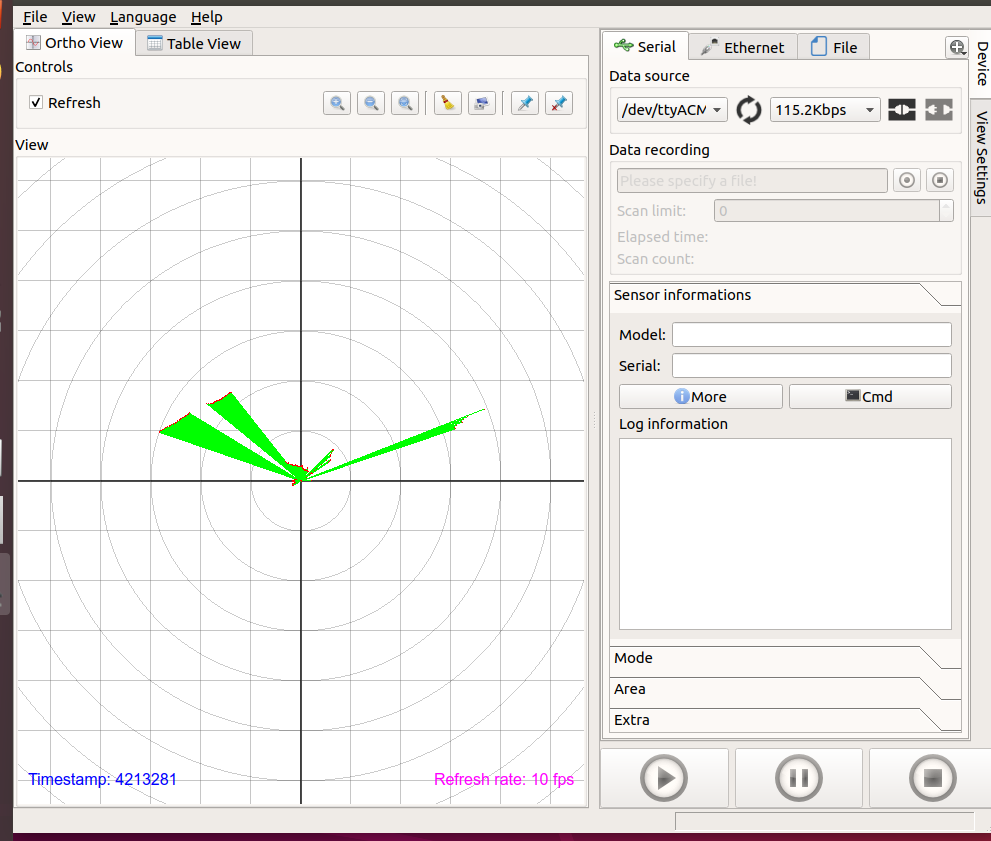
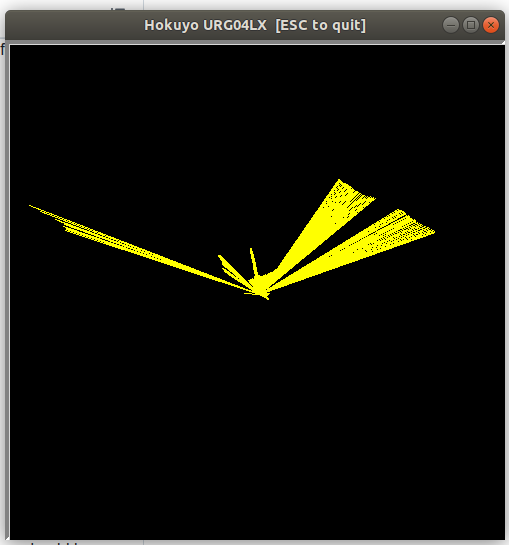
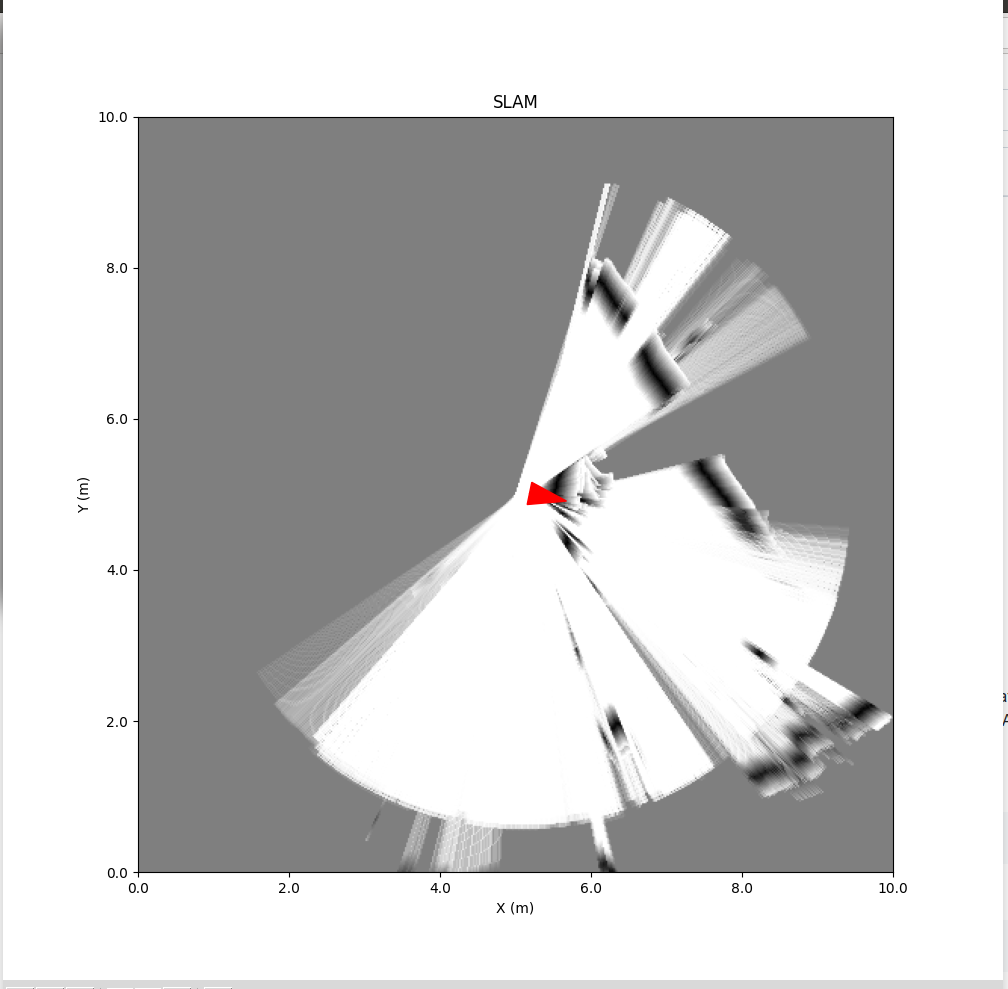
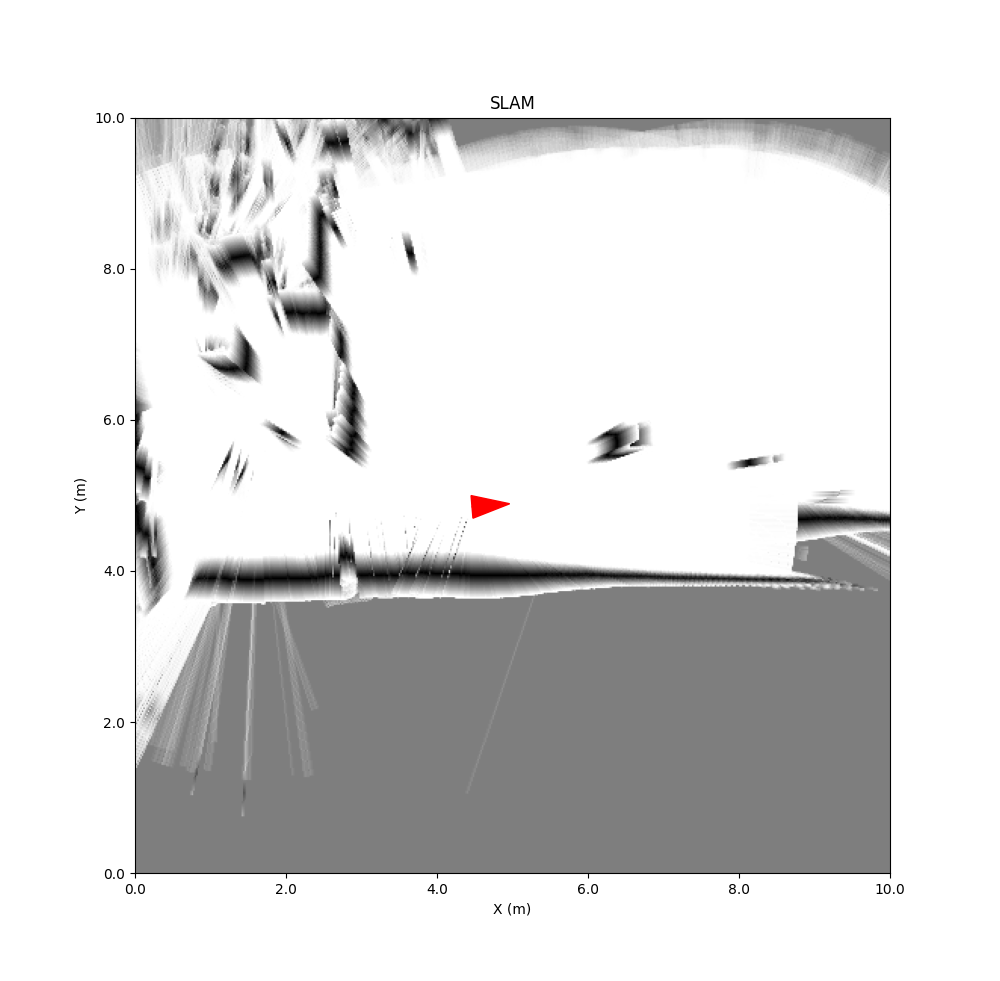

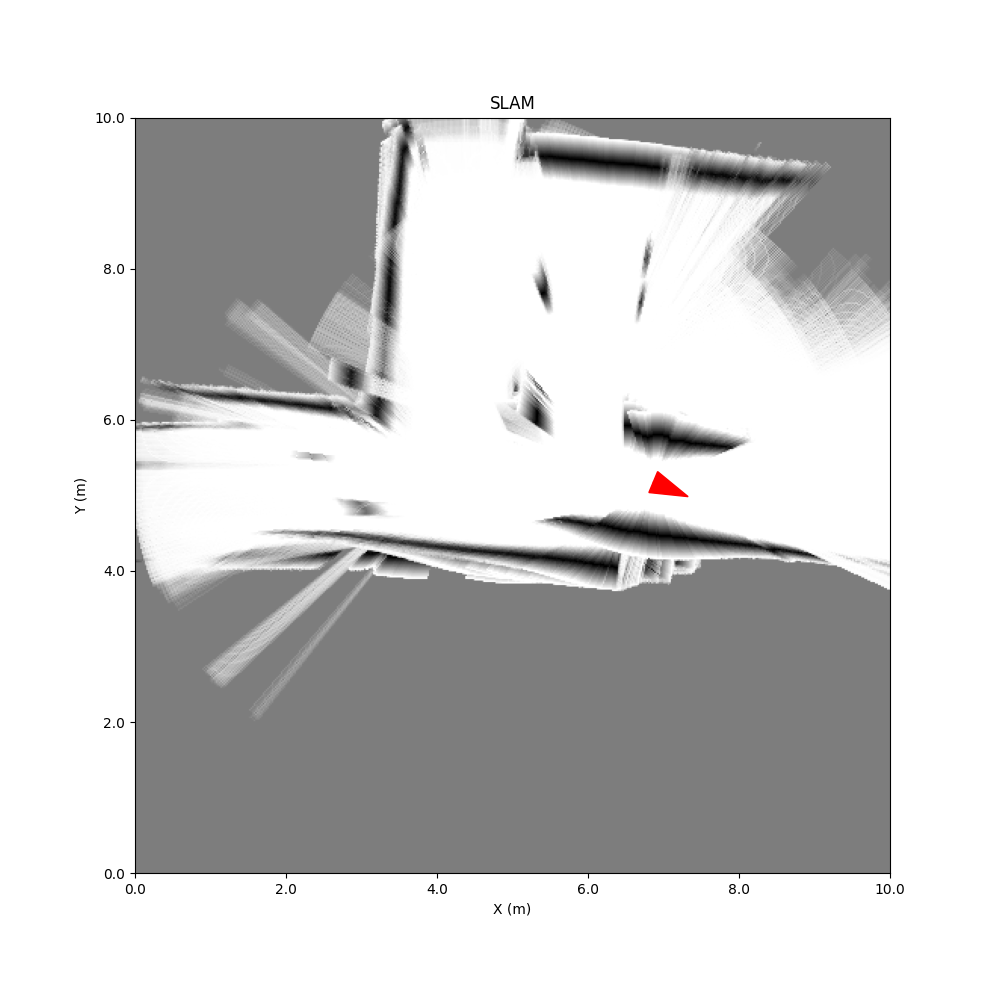

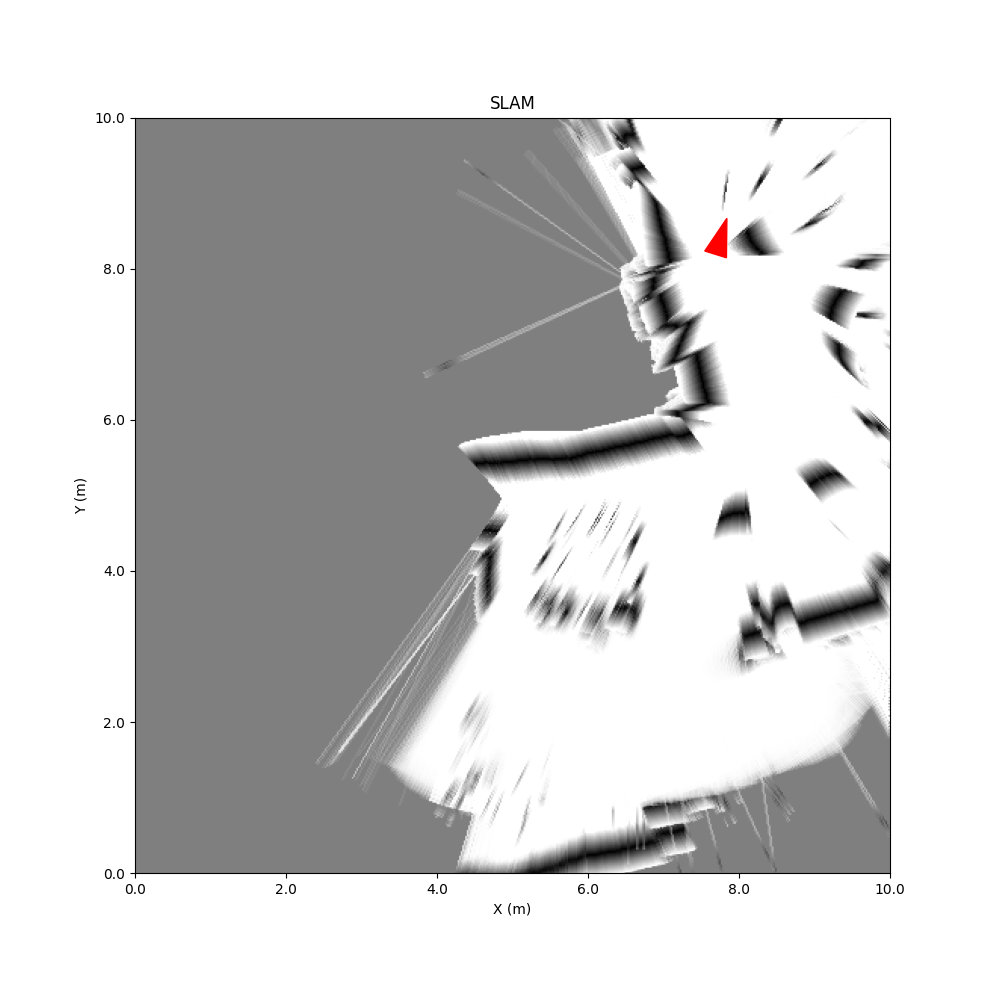

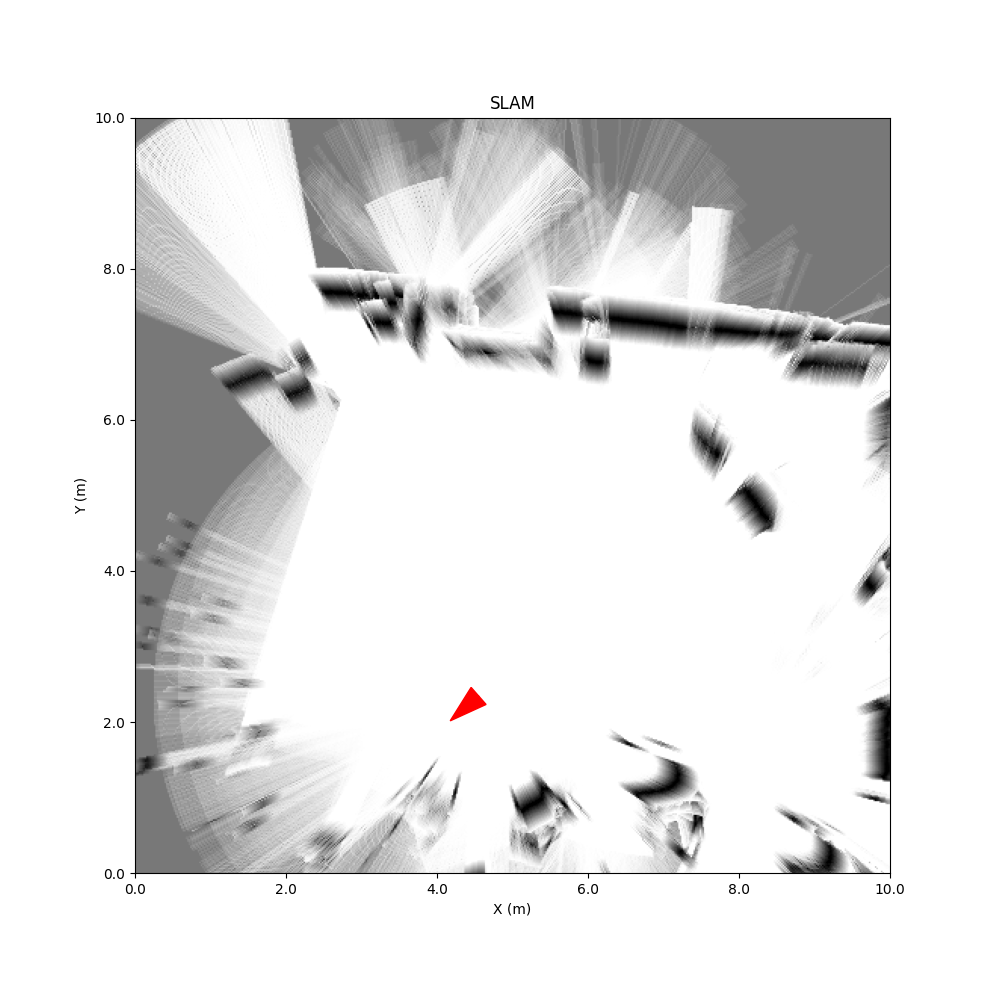

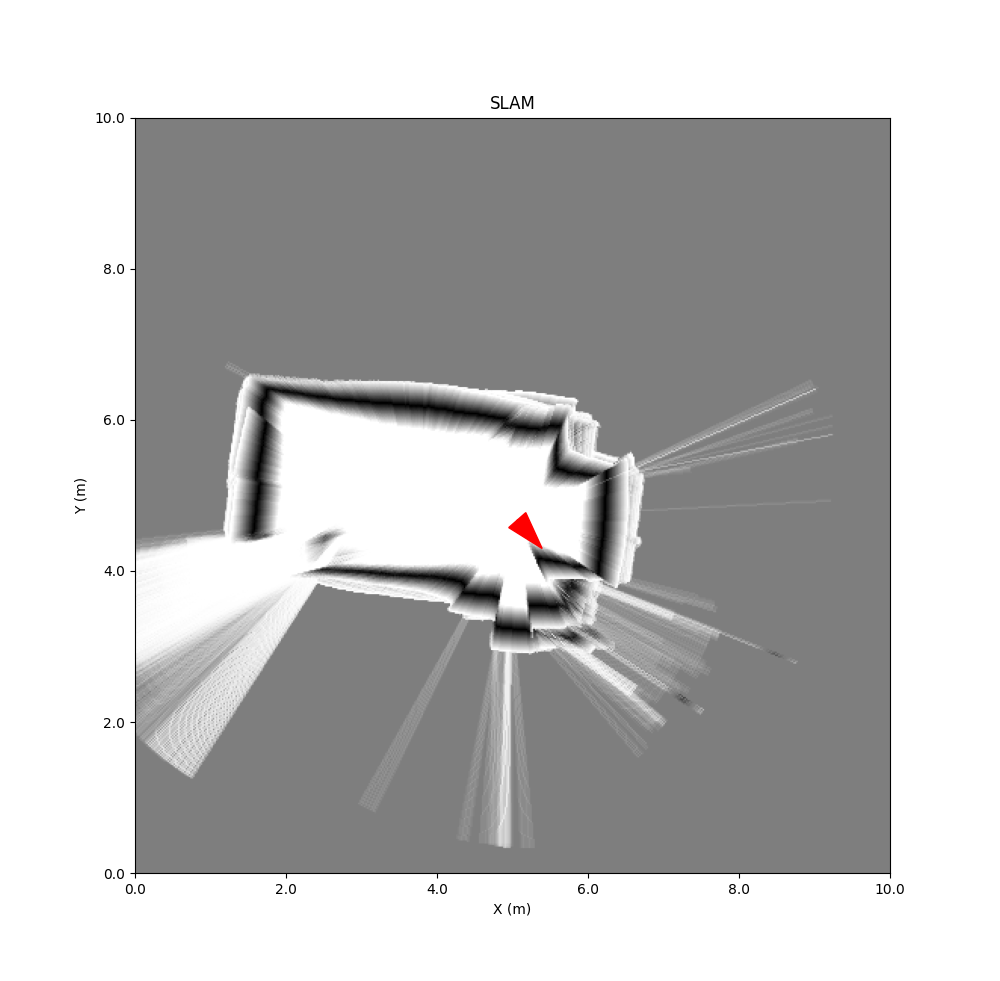



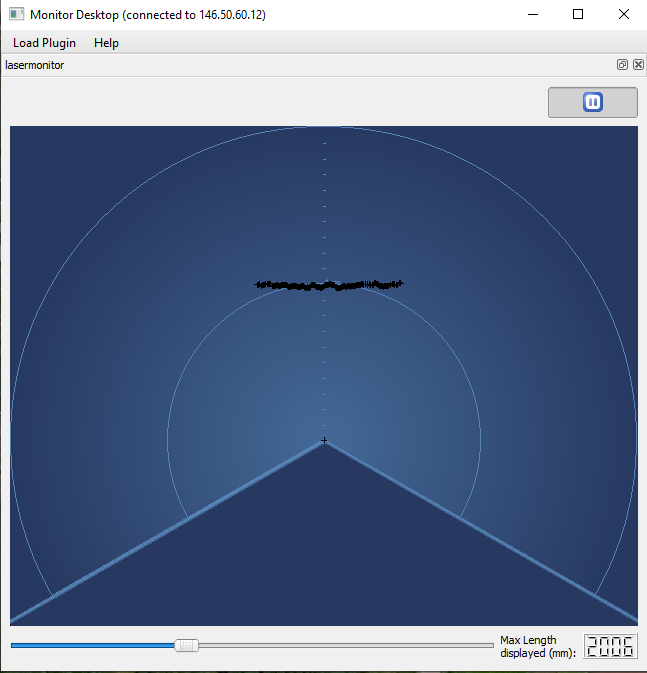
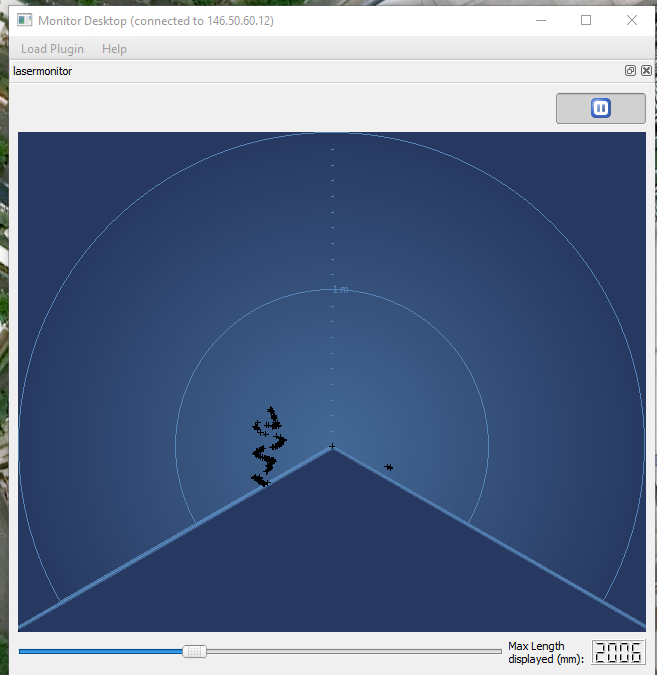

 .
.
 .
.