AdaFruit has an extensive manual for its FT232H board.
The FT232H switches off when connected with breakout wires.
December 24, 2021
Included the code from the example. That gives me the output:
[capture-1] Parameter names:
[capture-1] general.cam_pitch
[capture-1] general.cam_pos_x
[capture-1] general.cam_pos_y
[capture-1] general.cam_pos_z
[capture-1] general.cam_roll
[capture-1] general.cam_yaw
[capture-1] general.camera_model
[capture-1] general.camera_name
[capture-1] Parameter prefixes:
[capture-1] general
My function declares a parameter before reading it, maybe I shouldn't
The zed_wrapper is not only launched with the launch argument camera_name, but also with the config_camera_path, which contains a yaml which declares general.camera_name.
Added also a config-file. The value is red, the camera_name is now pal4.
On the other hand, overriding doesn't seem to work. I will submit a temporary 'working' version, and then put all configuration into the yaml.
Testing with rviz. According to rviz, the topic /dreamvu/pal/pal/get/left is published (indicated pal as name, which is added to the namespace), also only the map and base_link are available, no tf is published between the baselink and the camera_center.
December 23, 2021
Trying to debug the get_parameter problem of the dreamvu_camera_node.
Start with an update, to get the latest versions of the rox-foxy packages.
Node also has the option to list the parameters: see this example.
The cmakefile.txt was modified, so run colcon with argument --cmake-clean-cache. Yet, now the rosidl_generator_cpp fails on missing lark package. A simple pip3 install lark solves this issue.
The rviz_plugin_plugin_zed keeps on failing on missing rviz_rendering_extras, so build only the pal_camera node with --packages-select: colcon build --symlink-install --cmake-args=-DCMAKE_BUILD_TYPE=Release --packages-select pal_camera.
Run the node with ros2 launch pal_camera pal_camera.launch.py.
Strange, now it seems to work with the values from the launch file:
[capture-1] [WARN] [1640275863.657378385] [dreamvu.pal.pal_camera_capture]: The parameter 'general.camera_name' was available and set to the value: /dreamvu/pal/
[capture-1] [INFO] [1640275863.657385188] [dreamvu.pal.pal_camera_capture]: * Camera name: /dreamvu/pal/
So, with the argument camera_name:='/dreamvu/pal3/' this name is used for the namespace, but not for as argument.
[capture-1] [WARN] [1640276382.609380215] [dreamvu.pal3.pal_camera_capture]: The parameter 'general.camera_name' was available and set to the value: /dreamvu/pal/
Running ros2 launch -s pal_camera pal_camera.launch.py shows the available arguments that could be given to the launch file.
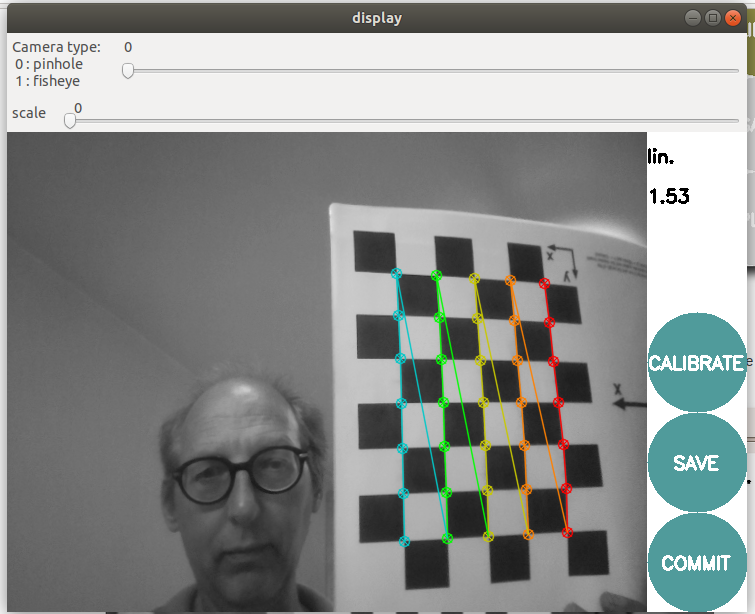
Looked up the recommended display driver. It is specified how the 4 I2C pins should be connected to the Raspberry Pi GPIO pins. Connect the green wire to GND, the red wire to VCC, the orange to SCL and yellow wire to SDA.
So, on the Adafruit FT232J board (the I2C mode is still off!), I should connect the green to GND (two options), the red wire to 3V, the orange to D0 and the yellow wire to D1.
text = "HELLO WORLD"
font = terminalio.FONT
color = 0x0000FF
# Create the text label
text_area = label.Label(font, text=text, color=color)
# Set the location
text_area.x = 100
text_area.y = 80
# Show it
display.show(text_area)
# Loop forever so you can enjoy your image
while True:
pass
Yet, I receive an AttributeError: I2CDisplay object has no attribute try_lock. I also tried it with address 0x3D, but same error. Don't see it in the code, so maybe I should add busio (checked, no).
Tried this piece of code, which actually still works:
from adafruit_bus_device import i2c_device
my_device = i2c_device.I2CDevice(board.I2C(),0x3C)
That is strange, because that is precisely the call where it fails (line 239 of adafruit_ssd1306).
So, the call was wrong. It should have been:
i2c = board.I2C()
display = adafruit_ssd1306.SSD1306_I2C(width=128,height=64,i2c=i2c, addr=0x3D)
This fails on later (in the poweron function): it does self.i2c_device.write. The call fails in the pyftdi i2c driver, on controller.write, which tries send_ack, but receives NACK from slave.
Tried to reduce the frequency from 400,000 to 50,000 (in ~/.local/lib/python3.8/site-packages/board.py, as suggested by Mark M.
Repeated the installation procedure for Windows, which works fine (but also shows an blank EEPROM). Flashed the EEProm with FT_PROG, and set C8 and C9 as suggested. Now Ftdi().open_from_url('ftdi:///?') returns ftdi://ftdi:232h:FT65827P/1 (USB <-> Serial Controller).
Under Windows, it now works (with the default 0x3C address). Yet, display.show(text_area) doesn't accept arguments.
Followed the instructions at adafruit ssd1306:
# Clear the display. Always call show after changing pixels to make the display
display.fill(0)
# update visible!
display.show()
# Set a pixel in the origin 0,0 position.
display.pixel(0, 0, 1)
# Set a pixel in the middle position.
display.pixel(64, 32, 1)
# Set a pixel in the opposite corner position.
display.pixel(127, 63, 1)
display.show()
No complains, but also nothing visible. Should try another display and/or another controller (Nvidia Jetson).
Run the whole example, but receive NACK from slave again.
Seems to be that the pins should be stable, the LED went out quite often.
Run the three_pixel example with (128,32) as resolution under linux (don't forget to set export BLINKA_FT232H=1, otherwise you receive GENERIC_LINUX_BOARD not supported).
The paper also uses the COCO dataset, but filtered out the dynamic objects like backpack and books and concentrated on static sper-categories Furniture and Appliance.
The results of this paper are also not decisive. For the house Anto, 5 of the 8 rooms are classified correctly, two are undecided and one room is classified clearly wrong. The average precision over 4 houses is 59%.
The second paper improves the yolo grid from rectangular to square, with a method called m-Yolo. The detection on chairs improved with relation to FP from 0.29 to 0.12.
The first paper is a paper with code, called mp-Yolo, although the code seems not to be from the authors themselves.
In the original paper Yolo v2 is used, while the code now uses Yolo v3 (which makes sense because v3 can handle all input formats.
The Object Detection in Equirectangular Panorama aper concentrates on outdoor scenes (persons, cars, boats). They use stereographic models on the panoramic images, although I have not seen as strong distortion in my panoramic images (indoor is close by?). There main performance improvement is on the back-projection of the bouning boxes.
More mature seems to be the code panoramic-object-detection. This is code for autonomous driving (Kitti, Carla), but at least includes the idea of padding left/right (instead of zeros), which would be great for my problem, although based on Faster R-CNN.
December 9, 2021
Made a launch file. The parameters are given to the program, as visible in the file in /tmp.
Made code to read and use the parameters. Yet, when I look at the initiation, that is fails:
[capture-1] [INFO] [1639062601.822010738] [dreamvu.pal3.pal_camera_capture]: ********************************
[capture-1] [INFO] [1639062601.822123096] [dreamvu.pal3.pal_camera_capture]: DreamVU PAL Camera v1.2.0.0
[capture-1] [INFO] [1639062601.822131646] [dreamvu.pal3.pal_camera_capture]: ********************************
[capture-1] [INFO] [1639062601.822137354] [dreamvu.pal3.pal_camera_capture]: * namespace: /dreamvu/pal3
[capture-1] [INFO] [1639062601.822142689] [dreamvu.pal3.pal_camera_capture]: * node name: pal_camera_capture
[capture-1] [INFO] [1639062601.822147917] [dreamvu.pal3.pal_camera_capture]: ********************************
[capture-1] [INFO] [1639062601.822152674] [dreamvu.pal3.pal_camera_capture]: *** GENERAL parameters ***
[capture-1] [INFO] [1639062601.822178431] [dreamvu.pal3.pal_camera_capture]: * Camera model: pal_usb
[capture-1] [INFO] [1639062601.822213214] [dreamvu.pal3.pal_camera_capture]: * Camera name: /dreamvu/pal/
[capture-1] [INFO] [1639062601.822250592] [dreamvu.pal3.pal_camera_capture]: * Camera position x: 0
[capture-1] [INFO] [1639062601.822269615] [dreamvu.pal3.pal_camera_capture]: * Camera position y: 0
[capture-1] [INFO] [1639062601.822289027] [dreamvu.pal3.pal_camera_capture]: * Camera position z: 0.06
[capture-1] [INFO] [1639062601.822302019] [dreamvu.pal3.pal_camera_capture]: * Camera orientation roll: 0
[capture-1] [INFO] [1639062601.822323102] [dreamvu.pal3.pal_camera_capture]: * Camera orientation pitch: 0
[capture-1] [INFO] [1639062601.822346227] [dreamvu.pal3.pal_camera_capture]: * Camera orientation yaw: 0
From this log it is clear that the default values are used, but that the given camera_name is used as namespace, and the node name is also from the launch file. The call was ros2 launch pal_camera pal_camera.launch.py camera_name:='/dreamvu/pal3/' cam_roll:=1.57, which leads to the /tmp-file:
dreamvu/pal3/pal_camera_capture:
ros__parameters:
cam_pitch: 0.0
cam_pos_x: 0.0
cam_pos_y: 0.0
cam_pos_z: 0.06
cam_roll: 1.57
cam_yaw: 0.0
camera_model: pal_usb
camera_name: /dreamvu/pal3/
The Node is called with this code. My hypothesis that the parameters are in a different namespace (ros_camera_capture instead of ros__parameters):
capture_node = Node(
package='pal_camera',
namespace=camera_name,
executable='capture',
name='pal_camera_capture',
output='screen',
parameters=[{
'camera_name': camera_name,
'camera_model': camera_model,
'cam_pos_x': cam_pos_x,
'cam_pos_y': cam_pos_y,
'cam_pos_z': cam_pos_z,
'cam_roll': cam_roll,
'cam_pitch': cam_pitch,
'cam_yaw': cam_yaw
}]
Tried to change to parameter 'general.camera_name': camera_name, but at that moment the capture node gives:
[capture-1] what(): parameter 'general.camera_model' has already been declared
Tried it the other way around, and replaced getParam("general.camera_model", mCameraModel, mCameraModel, " * Camera model: "); to getParam("camera_model", ...);, but that also gives:
[capture-1] what(): parameter 'camera_model' has already been declared
Used ros2 param list, but only /rviz: use_sim_time was active.
Running the previous working version again, which I now query with ros2 param list. That gives:
Exception while calling service of node '/dreamvu/pal3/pal_camera_capture': None
Time to commit and go home.
December 8, 2021
Started an rviz2 outside ros2_ws with ros2 run rviz2 rviz2 -d ~/ros2_ws/install/dreamvu_pal_camera_description/share/dreamvu_pal_camera_description/rviz2/pal_usb.rviz.
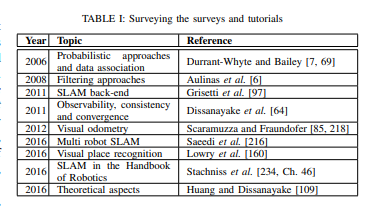
Now I am able to display the PointCould2:
Activated the local_setup.bash from ~/ros2_ws/install/dreamvu_pal_camera_description/share/dreamvu_pal_camera_description, and the PointCloud works fine. Something specific of my setup.
Yet, when I do ros2 launch dreamvu_pal_camera_description display_pal_camera_with_sensor_subscription.launch.py, rviz2 crashes again.
Modified the pal_camera_node, so that it uses the camera_name for its messages and frames. That works, only there is an additional meter between base_link and the map. It reads parameters (but the launch doesn't give it yet, so this are the default values:
[INFO] [1638977164.118318946] [pal_camera_node]: *** GENERAL parameters ***
[INFO] [1638977164.118342262] [pal_camera_node]: * Camera model: pal_usb
[INFO] [1638977164.118368845] [pal_camera_node]: * Camera name: /dreamvu/pal/
[INFO] [1638977164.118377227] [pal_camera_node]: ***** STARTING CAMERA *****
That additional meter (on the table), was easy to find in pal_camera_node.cpp, and clearly indicates that this transform can best be set outside (so listen first):
Only thing that puzzled me were the frames without '/' before dreamvu. Yet, both the launch and urdf include this character, so that is a rviz2 thing.
December 7, 2021
Collecting all files for a git-submit. package.xml has a dependency on ros_launch, while this dependency is commented out in CMakeList.txt. Should check when doing a fresh install.
For the rest the list is complete, although I could also create a gazebo.launch.py.
Trying to test ros2_pal_camera_node. Run fails because libraries are not accessible. Made a copy of lib-directory, but subdirectories are not added to LD_LIBRARY.
Changed the logic link script so that the libraries are not linked in the subdirectory. That works, although the script now fails on PAL_MIDAS_NANO again.
Added the dreamws/bin at front again, which points python3 to python3.6 (PAL_MIDAS_NANO error is gone).
Visualizing the images in rviz2 works fine, but rviz2 in the ros2_ws environment crashes on no material for PointCloudMaterial0Sphere.
Yet, also a lot of images are dropped. When I look at rviz, both a pal_camera_center and a dreamvu/pal_camera_center is present. Should make the namespace defined by the camera_name parameterizable for the camera_node:
In the camera_node a static transform from base_link, to pal_mounting_link, to pal_camera_center is defined. The pal_mounting is not visible in rviz. I should subscribe to see if a robot-description is published, and only publish my own static transformation when necessary (tomorrow).
Looking at the zed_desc.urdf.xacro. Seems that this file is used directly, without the need to convert the aliases from xacro to urdf.
The description defines a base_link. The next definition is the camera_center_joint (from base_frame to zed_camera_center).
The zed_camera_center has (0,0,0) as origin, the joint is parameterized with (cam_pos_x,cam_pos_y,cam_pos_z), although those values are by default also 0.0
The base_frame is redefined as base_link in the zed.launch.py. The (cam_pos_x,cam_pos_y,cam_pos_z) are still defined as 0.0 in the launch file.
The launch has two actions, the definition of the path to config/common.yaml and the launch of the node itselfi with the script launch/include/zed_camera.py.
In this last script the robot_state_publisher is called (together with the zed_wrapper_node.
In common.py is defined which coordination frames are published. By default, this is set on true for odom->base_link and map->odom. The zed.yaml specific definition are only min_depth and max_depth.
The display_zed.launch.py starts the zed_node, with the parameter publish_urdf=true.
Converted the zed_descr.urdf.xacro to zed_descr.urdf (after sourcing the setup from foxy and ros2_ws). The urdf is parsed OK, although base_link, zed_camera_center, zed_left_camera_frame and zed_right_camera_optical_frame are not defined (as expected).
The zed_left_camera_frame is just a link with a name, the baseline is included in the Joint (center to camera_frame). Also the optical_frame is just a name, with no translation but only rotated camera_frame.
Made a version of the launch file that only starts the description. Running it with commandline arguments starts (ros2 launch ./zed_camera_frames.launch.py camera_name:=zed camera_model:=zed config_camera_path:=~/ros2_ws/install/zed_wrapper/share/zed_wrapper/config/zed.yaml xacro_path:=~/ros2_ws/install/zed_wrapper/share/zed_wrapper/urdf/zed_descr.urdf.xacro), but the transforms are still missing, also after including the optional (base_frame:=base_link publish_urdf:=true config_common_path:=~/ros2_ws/install/zed_wrapper/share/zed_wrapper/common.yaml).
Yet, the Map2Base is initiated in zed_camera_component.cpp. Once I start ros2 launch ./transfer_base_link.py all six transformations are OK:
With this command rviz2 can use the RobotModel from the Description Topic /zed/robot_description instead from file as source. Still needs the map to base_link transformation in the background:
Made a pal_camera_description.launch.py script, which can be called with three non-optional arguments ros2 launch ./pal_camera_description.launch.py camera_name:=pal camera_model:=pal xacro_path:=~/ros2_ws/install/pal/share/pal/urdf/fourth.urdf.xacro. The result is a pal_mirror link with three children:
[INFO] [robot_state_publisher-1]: process started with pid [96334]
[robot_state_publisher-1] Parsing robot urdf xml string.
[robot_state_publisher-1] Link pal_mounting_bottom had 0 children
[robot_state_publisher-1] Link pal_mirror_protection had 0 children
[robot_state_publisher-1] Link pal_mounting_top had 0 children
[robot_state_publisher-1] [INFO] [1638797705.340136644] [pal.pal_state_publisher]: got segment pal_mirror
[robot_state_publisher-1] [INFO] [1638797705.340208091] [pal.pal_state_publisher]: got segment pal_mirror_protection
[robot_state_publisher-1] [INFO] [1638797705.340223951] [pal.pal_state_publisher]: got segment pal_mounting_bottom
[robot_state_publisher-1] [INFO] [1638797705.340230890] [pal.pal_state_publisher]: got segment pal_mounting_top
The topic could be read, although the transformation are a bit off:
The transform could be off because they transforms also run still in the background. The pal_mounting_top has a z-translation of 0.36m absolute and 0.3 relative. The pal_mounting_bottom has a z-translation of 0.16m absolute and 0.1 relaive (both from pal_mirror). pal_mirror has map as parent. Absolute and relative position 0.06m. The pal_mirror_protection is the only one with a negative z: -0.14 mabsolute and -0.2m relative to the pal_mirror. That is strange, because the static_transform gives as positive 0.02m. So, the transfer is not used, because in the xacro a negative value of -0.2 is used.
Made a version (sixth) which is actually quite good (when launched with an additional offset of 6cm by ros2 launch ./pal_camera_description.launch.py xacro_path:=~/ros2_ws/install/pal/share/pal/urdf/sixth.urdf.xacro cam_pos_z:=0.06. The offset is intentionally, because you can mount the pal-camera in two ways (broadside down or up). In that case it is smart to use the camera_center as origin:
Starting to make a package for github.
Wrote a Readme.md. Changed the camera_name (which correspondents to the name space) from pal to /dreamvu/pal, so that the robot_description and joint_states are in correspondence with the topics published by the pal_camera_node.
December 3, 2021
Continued with the pal-description on nb-dual.
The version in ~/ros2_ws/src/pal/urdf/pal.urdf.xml still contained an error (missing '/>' for the cylinder object), which I had repaired in ~/ros2_ws/install/pal/share/pal/urdf/pal_v3.urdf.xml.
Made an ~/ros2_ws/install/pal/share/pal/urdf/pal_mesh.urdf.xml, which loads fine (after source ~/ros2_ws/install/local_setup.bash). In the background two static_transformers are launched. The mesh appears on top of the pal_link (16cm above the map), and not the pal_mounting_link (6cm above the map).
Combined the two description in one file. Rviz complained when two robots objects were there, and found two roots (pal_mounting link and pal_mirror). Created a 2nd_pal_mounting_joint to connect the links pal_mounting link and pal_mirror. That works.
Lowered the mirror from 6cm to 3cm, which fits nicely.
Lowered the mesh from 16cm to the origin. Now both models overlap, with the top_mounting just above the mesh, and the bottom_mounting just below the mesh.
December 1, 2021
The Nvidia Robotics Teaching Kit makes use of standard Jetbot.
Zed also has a gateway based on the Nvidia TX2 NX Xavier NX.
November 25, 2021
Made my second urdf. Yet, only the top is above the plane, the mirror stays inside the plan (although I specified the origin. The top doesn't change color.
Tried to load the base_robot example to test if the frame is red, but here there is an error with loading the urdf (even after installing ros-foxy-xacro. Doing an sudo apt upgrade.
Problem is the parsing of components like ${255/255}. Run check_urdf basic_mobile_bot_v1.urdf (after installing liburdfdom-tools). Problem seem to be more the missing meshes.
Followed the whole tutorial, and launched ros2 launch basic_mobile_robot basic_mobile_bot_v1.launch.py. Now I get a red robot with wheels. Received some warnings on invalid frames (drivewhl_r_link and drivewhl_l_link), although that is only a few times at the beginning, so maybe a startup issue. That are the two frames which can be interactively adjusted via the joint_state_publisher_gui. Still, my model has no red and the basic_mobile_bot cannot be loaded from file.
Replaced the mesh for a box-geometry, but still the xacro properties are not read. Also check_urdf complained. Run xacro basic_mobile_bot_v3.urdf.xacro -o basic_mobile_bot_v3.urdf, and now the urdf is succesfull parsed.
Model is only correctly displayed when I run static_transfers in the background. The bottom is still a bit bellow the grid, and I would like to have all transforms from the camera_center (and the camera_center to base_link, and base_link to odom and odom to map):
For this design I used a sphere with a radius of 4.5 cm, a protection-band with a radius of 4.5 cm and 1.8 cm height, a top with a radius of 1.85 cm and 1.0 cm height, and finally a bottom with a radius of 5.0cm and a height of 2.7 cm.
Trouble on my nb-dual is that it uses ',' instead of '.' for floats. The behaviour is different for boxes vs cylinders and spheres. Changed the region format from US to NL. Now it also works for my computer, although the sphere is 2cm heigher.
November 24, 2021
Started docker -run -p 6080:80 --shm-size tiroh/ros2-desktop-vnc:foxy on my Ubuntu 21.04 desktop.
Started rviz and loaded myfirst robot from the ros official tutorial. The cylinder is visible!.
November 23, 2021
Started again with a simple ros2 description for the dreamvu.
Started ros2 launch ./transform_r2d2_axis.py (after a source /opt/ros/foxy/setup.bash
Started rviz2. Added a robot model. Switched from topic to file. Loaded pal_v5.urdf.xml. Nothing in view. Same for without_rod. Without legs works, although I receive some warning about the frame head, box and rod.
When I add the box transform the square in rviz becomes blue.
Also added the other missing transforms. No warnings a printed, rviz2 gives an transform OK on axis, body, head, box and rod. With the transformation running without_legs is still the only one that displays the blue cube.
As soon as I make the box a cylinder, the object disappears.
Even this cylinder is not visible, but rviz2 complains that the transform from base_link to map is missing.
The urdf_tutorial has a github repository with a ros2 branch, but the launch directory has no display.launch, only a demo.launch.py (which starts a robot_state_publisher with rod and box, but no urdf_tutorial.state_publisher.
Continued with the mobile robot urdf tutorial. Packages is build without problems, yet the wheels are not there (while the front_caster coordination frame exists):
The blue jetbot is ready to be upgraded from 18.04.4 to 20.04.03 LTS. Wait with this upgrade.
The latest JetPack is 4.6, while the blue jetbot still has 4.3. Nvidia is not explicit on which Ubuntu version each JetPack is based.
Trying out to follow the instructions from nanosaur on my blue jetbot.
Downloaded the script and saved it as ~/Install/nanosaur.sh before running it.
In principal ros-foxy should be Ubuntu 20.04 based, but the script doesn't complain. Maybe I should have done sudo apt -y full-update.
The script downloads a large docker-compose (1.5 Gb).
Seems that I also have to do this on my desktop, according to these instructions.
Not much instructions there, so moved on to driving with keyboard. First had to do sudo apt-get install ros-foxy-teleop-twist-keyboard. After that the command works (but the robot doesn't move. See no environment variable which docker to start, or the address of the nanosaur.
The Jetbot is driving a webinterface, but this are the original Jupiter notebooks.
Run nanosaur info on my Jetbot. Returned that the nanosaur_webgui and watchtower were Up, but that the nanosaur_core had exited.
When I run nanosaur wakeup, I receive that the watchtower is up-to-date, but nanosaur-core failed on a mount error.
Run nanosaur logs. The webgui complains that the port is already in use (by the Jupiter notebooks).
Raffaello indicated that the naonaur software is build for JetPack 4.6, which is 18.04 based.
Stopped the JupyterLab with systemctl stop jetbot_jupyter.service. Dit nanosaur stop, followed by nanosaur start. THe ROSboard works, although without the nanosaur_core it has as ros topics only parameter_events and rosout:
November 22, 2021
Ellipsoid SLAM uses the Victoria Park dataset (and one of their own), see Autonomous Robots 2016 (laser scan based on landmarks).
Möller uses a panoramic dataset in his 2007 paper, although no url is given. On his personal webpage he points to two databases: living and grid (2017). The accompanying MinWarping article extensively describes the calibration of the warping and effect on localization in a room.
Very nice is this article on unsupervised semantic clustering for localisation (vision based).
realsense-viewer works, but used the librealsense2.so.2.50 from /lib/x86_64-linux-gnu/
After building from source the system works, and could I display color and depth images in rviz.
Starting roslaunch realsens2_description view_d435_model.launch failed on missing module defusedxml.
After a pip install defusedxml the description works. Yet, I don't see any /camera/depth/color/points, also not with one of the D435i cameras.
Solved. Needed to add that as an option to the start command
roslaunch realsense2_camera rs_camera.launch filters:=pointcloud, as described in the readme of the github:
The D435i does not work for everybody, while it works fine on mine.
Updated the D435i firmware. Also updated the firmware of mine D435 from 5.12.05.00 to 5.13.0.50.
After connecting to another USB-port (USB-C in the back), the setup worked for everybody.
Followed the urdf tutorial. package is build without problems, yet the launch fails on:
[state_publisher-2] module = __import__(self.module_name, fromlist=['__name__'], level=0)
[state_publisher-2] ModuleNotFoundError: No module named 'urdf_tutorial.state_publisher'
[ERROR] [state_publisher-2]: process has died [pid 66608, exit code 1, cmd '/home/arnoud/ros2_ws/install/urdf_tutorial/lib/urdf_tutorial/state_publisher --ros-args -r __node:=state_publisher'].
When I run python3.8 state_publisher it works, so I this is a problem with python3 pointing to dreamvu/python3.6
Modified the bashrc so that no dreamvu binaries or libraries are loaded (only in the AMENT_PREFIX_PATH). Still same error.
/usr/bin/python pointed to python3.6, so moved that to python3 (which points to python3.8)
Still same error.
Finally found my previous r2d3.urdf.xml (in ros2_ws/install/pal/share/pal/urdf.
Loading the r2d2 fails (parse error), but my modified r2d3 loads (manually in rviz2).
Copied r2d3 to pal_v2.urdf.xml. That still works (although legs overlap the axis).
Renamed it to pal_v5, and removed the legs. nothing visible anymore.
When I remove the joint, there are two root links found.
Even back to original, nothing is visible anymore. r2d3 still loads.
Removed first the two legs, after that the box and rod. Still visible.
Removed head. Still works. Also removed the body. No complains, but still a rectangle instead of cylinder.
Restarted rviz2. Nothing visible with only the axis. But pal_v5_without_legs.urdf_xml shows a small box at the center probably the head).
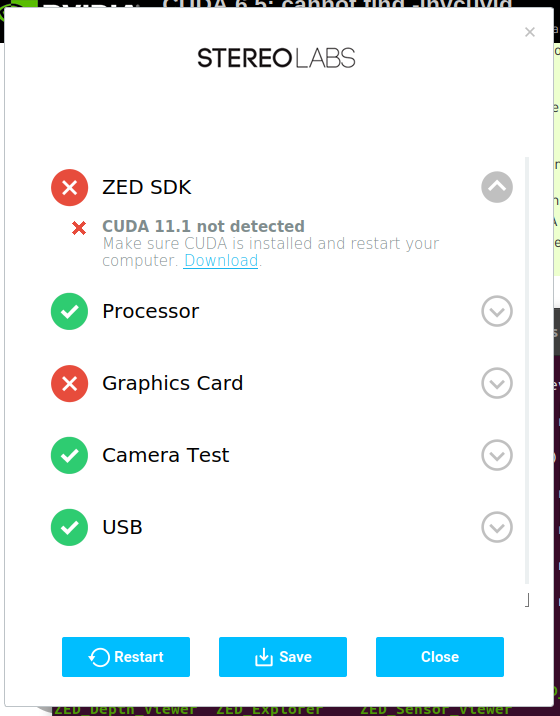
The ZED SDK 3.6 needed CUDA 11, so that was installed automatically. The driver (v460.91) was OK (capable of running Cuda 11.2).
Still, the script complains on /usr/local/cuda (not a directory) and fails to install the python-api. So, colcon build of the wrapper fails on missing Cuda 11.
Install cuda-11-2 (or cuda-11-5) failed, which couldn't be fixed with broken packages. At the end it were some old v460 drivers that held the installation back. Installing nvidia-kernel-source-495 solved this issue.
Reboot
Still, /usr/local/zed/zed/zed-config.cmake finds cuda-10 instead of 11. Moved the cuda-10 binaries and includes from /usr/local to /usr/local/cuda-10.
Did my best to direct FindCUDA to the right path (e.g. CUDA_SDK_ROOT_DIR). At the end lowered in FindZed the CUDA version from 11 to 10. That compiles.
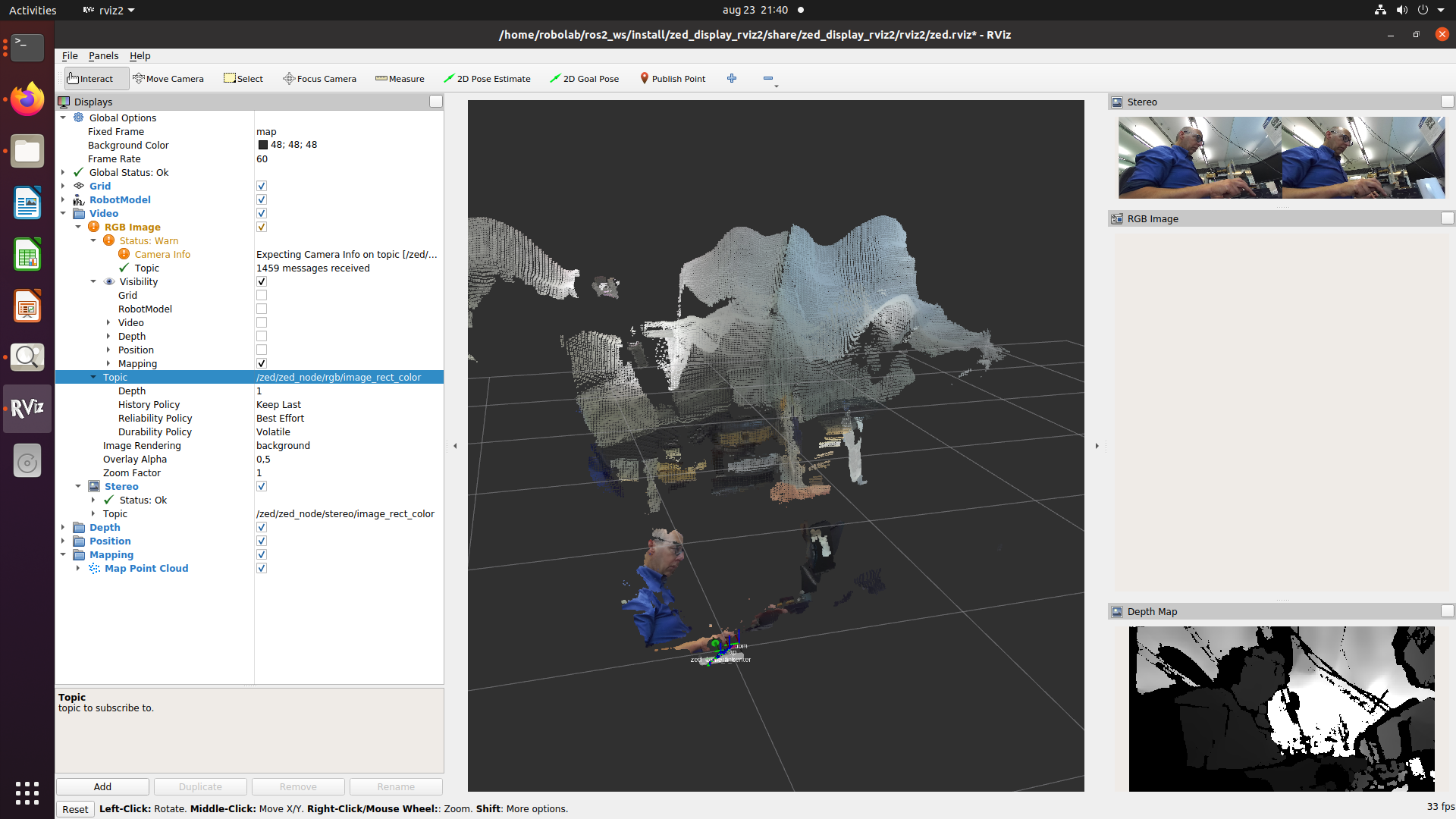
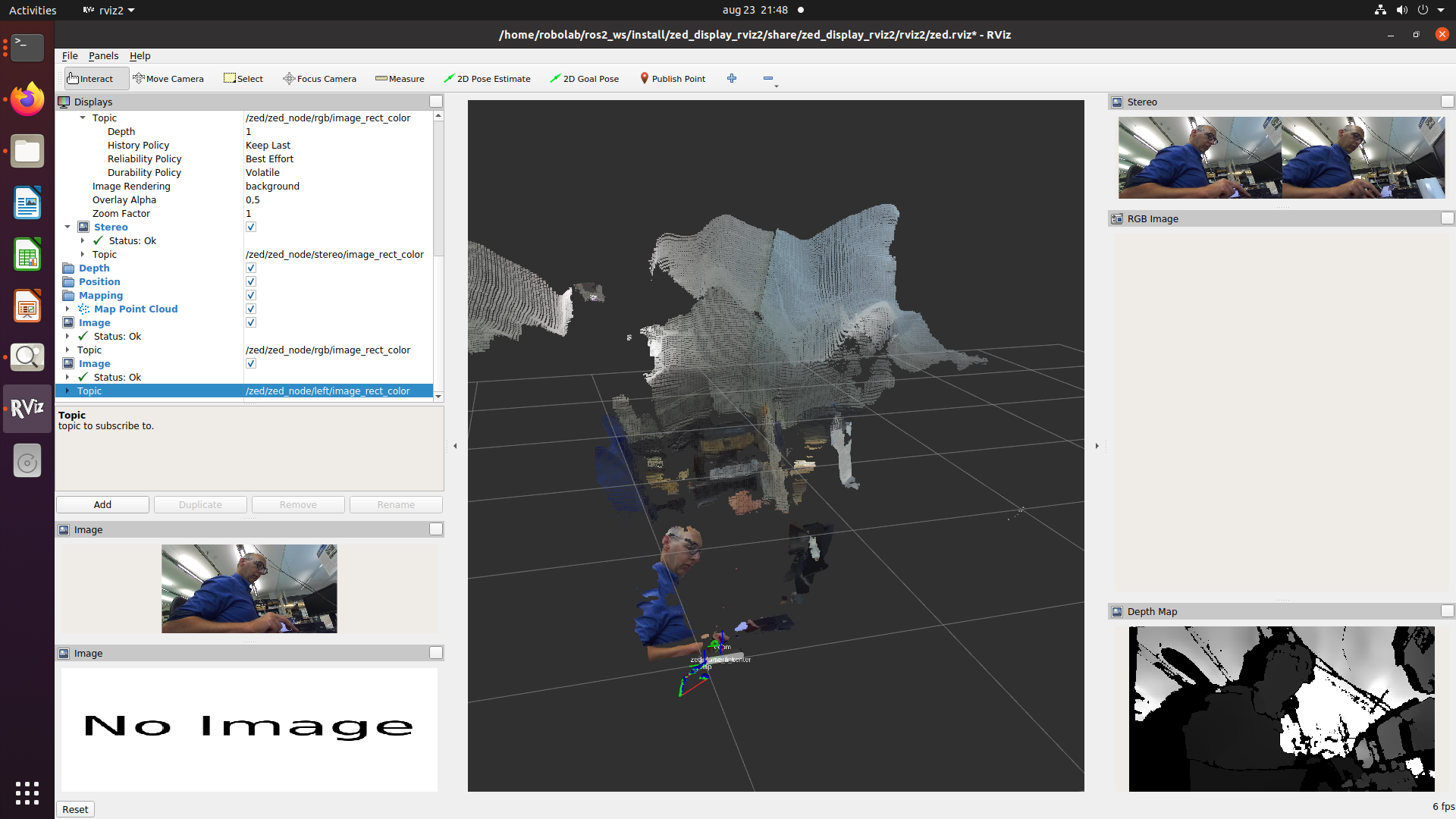
It also runs (although the rgb and depth are not displayed because the map frame doesn't exist. Strange, because I can display the map as tf in rviz2 (seems to follow me as the human in view).
Looked at the different coordination frames. The camera_center overlaps with the base_link, and has the blue z-axis up and the green y-axis forward. The left and right camera_frames are moved 6cm, and with a relative rotation (quartenion) of (0;0;0;1). So, now still the blue z-axis is up, but the red x-axis forward. The optical frames have a relative translation of 0, but both frames are rotated with (-0.5;0.5;-0.5;0.5) to their camera_frames. Now the blue z-axis is forward and green y-axis down.
Looked at the pal package that I have ported.
readme - file from March, contains the old catkin based make instructions. (Remove or rewrite for ros-foxy)
export.log - file from March - SolidWorks message (remove)
urdf.rviz - rviz configuration file, indicating that the RobotModel should be loaded, and that there is a fixed Frame pal (can be made fresh by saving good rviz view).
config/controller_join_pal.yaml - contains empty list. zed_wrapper/config also contains yaml files. common.yaml defines ros_parameters in sections on general, video, depth, pos_tracking, mapping and debug. Each version has its own yaml, zed.yaml defines only for ros_parameters: camera_model, camera_name, min_depth and max_depth
package.xml - updated for ros-foxy
CMakeLists.txt - updated for ros-foxy
meshes/pal.SLT - contains the NDA model
urdf/pal.csv - original - points to meshes/pal.SLT
urdf/pal.urdf - updated with extra links - still points to meshes/pal.SLT
launch/gazebo.launch - still original
launch/display.launch.py - updated for ros-foxy
I made on September 17 a SensorModel from scratch.
Made one again. Loaded in Rviz2 the pal.urdf.xml from file, but get an failed Model parse. Log shows Error reading end tag. Correcting missing '/>' in v2. Now pal_mounting_joint not found.
File is now loaded, but no cylinder is visible.
Downloaded the R2D2 from This tutorial, but I receive several parse errors (floats without 0)
Modified the urdf. Now a huge box is visible (partly below the grid). I receive warnings that no transforms are known from the box to map (and the body, head, legs).
When I add a transformation from the map to the axis, it is clear that the boxes are the two legs. The body and head are not connected yet.
Added static transforms for every link (only the box was not needed). Now a blue box is visible at the axis.
Lifted the head. The boxes are visible, the sphere is not! Should try a box for my Pal.
November 11, 2021
The eyes of the RoboSaur are 0.96 inch displays. AdaFruit has such displays, but the ones at the shopping list are less expensive (no Z-Wave Plus).
I could reuse the Jetson, Raspberry Camera and AdaFruit motor control board from Silicon Highway Jetbot. Only note that the camera has now a 160-degree FoV - Camera lens attachment.
Looking at the zed-description by starting calling ros2 launch zed_display_rviz2 display_zed.launch.py.
In rviz2 is visible in the RobotModel that all coordinate systems are on top of each other, and that 6 transforms are missing (base_link to map, zed_camera_center to map, zed_left_camera_frame to map, zed_left_camera_optical_frame to map, + 2x right to map).
Launching ros2 launch zed_wrapper zed.launch.py on nb-dual fails on missing GPU.
Moved to my XPS workstation. docker run -p 6080:80 --shm-size 512m 187eb7dc7e5a gave a warning of no space left on /root, and a very small screen at 127.0.0.1:6080. Restarting helped. Yet, when I wanted to do a git install from zed-ros2-wrapper, I got that no space is left on the docker device. Restarting with a 2x larger shm-size. Didn't help. Did a docker system prune --all --force and reclaimed 87Gb. Yet, now the image couldn't be found any more locally.
Started with a fresh docker run -p 6080:80 --shm-size=512m tiryoh/ros2-desktop-vnc:foxy again.
The colcon build of zed-ros2-wrapper failed on FindZed, so downloaded the Zed SDK v3.6.1. This version is based on Cuda 11.4, nvidia-smi didn't work yet in the docker, so I hope that the Cuda dependency is part of the Zed installation.
Actually, it does, although the it fails to detect a GPU because lspci was missing. Installed pciutils (NVIDIA 1080 is visible) and tried again. The script downloads the cuda-bin, but at the end the python dependencies fail because cuda is not installed (which is correct, no nvidia-smi
There is already Cuda 11.5, so I had to go to cuda archives. Suggestion was to do sudo apt-get install cuda, but that gives 11.5 again. Instead did sudo apt-get install cuda-11-4. The nvidia-smi still has some problems, but the Zed SDK install script works now.
Had to install sudo apt-get install ros-foxy-diagnostic-updater, but after that the zed_wrapper was build with some minor pedantic warnings.
Running ros2 launch zed_wrapper zed.launch.py fails on missing xacro, so also installed zed_ros2-examples.
Installed python3 -m install xacro , sudo apt-gt install python3-rosgraph and sudo apt-gt install python3-roslaunch. Had to reinstall ros-foxy-desktop again. Still Log couldn't be loaded from , when I do xacro share/zed_wrapper/urdf/zed_descr.urdf.xacro. Did a sudo apt-get upgrade.
Problem seems that Zed needs ros-foxy-diagnostic-updater, which installs ros-foxy-rosgraph-msgs, which doesn't hold the Log message anymore. Installing sudo apt-get install ros-foxy-xacro solved this issue.
Yet, the zed-wrapper gives an error (Camera.cpp:221) with no-CUDA capable device is detected.
Had a lot of trouble with sudo add-apt-repository (import apt_pkg failed), which was at the end the problem that I linked python and python3 to python3.6 for the DreamVu camera.
Needed to reboot, so first did docker commit 7f921e3b3de9 arnoud/foxy-zed:version1
Started a container with docker run -p 6080:80 --shm-size=512m nvidia/cuda:11.4.2-devel-ubuntu20.04.
Configured docker that I can set docker context use rootless. The result is that the nvidia/cuda:11.4.2 had to be downloaded again. Yet, it doesn't work for this context, so switched back to docker context use default..
Starting to install ros-foxy-ros-base, ros-foxy-rviz2, ros-foxy-image-transport, ros-foxy-camera-info-manager, ros-foxy-image-view, ros-foxy-v4l2-camera.
Also installed python3-rosdep2 and python3-colcon-common-extensions.
Had to create a non-privileged user as root, otherwise the script doesn't work. Added that user also to the sudo group. Now the Zed SDK is being installed. Although at the end no udevadm is available. Doing sudo apt install udev solved this.
The zed_ros2_wrapper compiles, but is missing libnvcuvid.so, which should be part of the driver. Installing nvidia-driver-495, which installs a lot of packages. Luckily the required library is one of those.
The installation leads to fixed installs, because it tries to safe cuda.so, while it is in use.
Saved the two needed libraries in ~/lib, and reinstalled them manually after removing the nvidia-driver again (so that I could install other packages).
Made sure that there is also a udev rules at my host. Now the ZED camera is visible with lsusb. Still the wrapper cannot connect, and the graphical interface has no display.
Tried to start the docker image with capabilities=video,graphics,display, but to no avail.
tried to install the ZED SDK on Ubuntu 21.04, but pyzed has no install option, nor qt5-default.
On Ubuntu 21.04 the ZED_Diagnostic in /usr/local/zed/tools starts, which gives only one orange (multiple version of CUDA detected: recommended to use only Cuda 11.04. The right USB is faster than the middle one.
November 2, 2021
Connected the DreamVu camera to my Jetson racer, but it looks like the USB-ports are not USB-3.0 compatible, because the device is not visible with lsusb. According to the specs the USB-ports of the Nano are USB-3.0 compatible, so maybe the DreamVu needs USB-3.1.
Yet, Explorer opens in Blocking mode. No images are shown.
The Jetson nearly freezes, before exiting with reporting that detectNet failed to initialize, because it was build for compute level 5.3 (and received 7.2 - please rebuild).
Tried python3.6 test_py_installations.py, but imageio is missing. Here no requirement, imageio is explictly installed in setup_python_env.sh (without version number).
Installing open-python gives v4.5.4.58, which seems a bit modern for libPAL.so
pip complains about uff 0.6.9, which requires protobuf>=3.3.0, while 3.0.0 is installed. Should look if I have to reduce the version of uff or upgrade protobuf.
Try to install opencv-python-headless==4.4.0.46. Strange enough python3.6 -m pip doesn't work, while pip3.6 directly seems to work. Maybe I should have done python3.6 -m pip install --upgrade setuptools first. Yet, buildig a fresh wheel takes ages. After more than an hour it works. Updated pip and setuptools for python3 (found in dreamvu/bin).
Starting to build a new wheel for opencv-python=4.4.0.46. Finished the wheel.
Running python3 test_py_installations.py works, while python3.6 test_py_installation.py gives a core-dump (illegal instruction). Explorer gives an initializaion failed.
Running python3 main1.py fails, because PAL_PYTHON.so is missing. test_py_installations.py only checks jetson_inference_python.py, but doesn't import PAL_PYTHON.
November 1, 2021
Started the ros2-foxy docker again at my XPS-workstation. The image seems quite empty, maybe I should start a container on top of the image, although that is precisely done via the docker run command. Maybe I should had done docker start instead, although docker container ls or docker ps showed no available containers. After the run commander the container is visible. My home only contained a Desktop directory. Downloaded the 18.04 SDK via the DreamVu website (wget didn't work).
Unfortunatelly also did source setup_python_env.sh in installation, which added dreamvu_ws to my ~/.bashrc. Removed the activation (but kept the addition to LD_LIBRARY_PATH. Did an apt-get update and installed usbutils. The DreamVU camera is visible with lsusb. Explorer fails on missing libopencv_videoio.so.3.4.
The command source etc/dreamvu/logic_link.sh fails because ~/.local/etc/dreamvu doesn't exist.
Build also fails on missing libpython3.6m.so and libv4l2.so.
Installed libpython3.6 by sudo add-apt-repository ppa:deadsnakes/ppa followed by sudo apt-get install python3.6-dev. Also installed python3-pip. Added libv4l2 by sudo apt-get install v4l-utils.
Receive now for the Explorer the errors Camera Data not available, Initialization failed.
Installing the PUM*.zip removes the Camera Data errors, but the Initialization still fails.
For an unknown reason the /etc/udev/rules.d/pal5.rules where not created (forgot sudo?). Made the script executable and removed the reboot. Still not.
Tested python3.6 main1.py, which fails on the provided PAL_PYTHON library. Downloaded the correct one, installed it in ros2_ws lib and activated by added this directory to PYTHONPATH.
python3.6 was still missing numpy and opencv, so install numpy--1.17.0 and opencv-python==4.4.0.44. The command worsk, but also reports that Camera initializaion failed.
Did a docker commit, docker stop, docker start, which should be equivalent with a reboot. Still same error.
Yet, in the Ubuntu 21.04 the udev rules where not activated. Activated those, rebooted and tried Explorer. Received the DualEnet error. Reinstalled the PUM, disconnected the device. Receive now VIDIOC_DQBUF resource temporaily unavailable error. Rebooted again. Same error.
Tried python3.6, receive again teh DualEnet error. Deactivated dreamvu_ws environment, still same error. Receive a warning that only 1 GB of Filesystem space is left.
The docker container is gone, although I see with docker image ls an image without tag (8.5 Gb large). The image starts, but I was not able to connect via een vnc-server. Stop worked, but I received no log messages by startint anymore. Rerunning it with option -p 6080:80 solved this. Still, Camera initializaion failed (both Explorer and main1.py)
Trying in the docker python3.6 test_py_installations.txt, which indicates that imageio is missing. Installing imageio==2.9.0 fails because no space is left on device.
Moved the tlt directory to DATA-disk, could update openio in the docker and commit.
Made python a link to python3 and python3 to python3.6m. python3.6 main1.py works, while Explorer still fails.
Both Explorers (nb-dual and XPS-workstation) are linked to libpython3.6m.so. The only difference that I see is that libOpenCL.so comes at the XPS-workstation from /usr/local/cuda-9.2
Tried if I could run python3.6 main1.py in Docker. That fails. Tried test_py_installations.py. Failed on torch. Installed torch==1.4.0, torchsummary==1.5.1 and torchvision==0.5.0. Last installed Pillow==6.1.0. Now test_py_installations.py says Python Installation is successfull. Still Camera initializaion failed. Run all requirements. Onnx was not installed, nor tensorflow, and many others. Still same error. Did a docker commit and stopped.
October 30, 2021
Looking at the ros-bag which I recorded on July 30. On nb-ros I could still do rostopic echo -b ~/projects/TNO/repaired.bag /dreamvu/pal/get/type_of_room.
Created export_images.launch by following the instructions from the tutorial. Note that I had to place the bag in /opt/ros/melodic/share/image_view, and that the images are placed in ~/.ros. Checked with rosbag info repaired.bag, which indicates that there are 501 left images and 307 type_of_room classifications in the repaired.bag.
The timestamps printed by the extract_images.launch are the current timestamps.
Downloaded the script ros_readbagfile from rosbag tutorial. The type_of_room messages are nicely stored in a yaml file, have to find the corresponding timestamps of the images. Modified the script so that it only prints the timestamps of the images.
Inspected the images. The camera is picked up at frame0084.jpg (bad image), but the walking starts around frame 120. At frame 189 I leave the living room and enter the hall. At frame 209 I enter the kitchen. In frame 240-260 I have a frontal view on the microwave oven. At frame 279 I enter the hall again. Frame 290 and 297 are bad again. At frame 306 I enter the bathroom. At frame 316 the sink should be visible. Frame 328 is bad again. At frame 339 I enter the toilet. In frame 342 the sink should be visible. Frame 370 has a clear view on the toilet. Frame 376 is bad again. At frame 384 I enter the hall again. At frame 403 I enter the children bedroom. Frame 418 till 500 are all the same (frozen).
So, the real experiment starts at frame 120 (type_of_room message 86).
Used some of the tricks this github site to visualize a nice confusion matrix (on nb-ros).
October 29, 2021
Did a git pull to get the latest version of yolov5 (version 6 I hope).
Run python3.8 detect.py --source data/dreamvu/kitchen/left.png, receive warning that Pillow is not found for python3.8 (but is satisfied thanks to the dreamvu_ws/lib/python3.6/site-packages). The yolov5s.pt is processed in 69ms (224x640 image).
Running it with python3.6 gave several missing libraries (installed pandas, but there were more). Did python3.8 --weights=yolov5s6.pt --source data/theta_z1R0010004.JPG, but the result is processed in 0.079s. Did I made my recordings on July 14 with nb-ros instead of nb-dual?
The Pillow in dreamvu_ws was actually v8.4.0. Uninstalled this version.
October 28, 2021
Interesting new depth camera from Leopard imaging. Comes with C# drivers, and ISAAC ROS Argus camera node for ros-foxy. Note that x86_64 is not supported!
The dataset from Freiburg Forest can be found at deepscene. Question is if this data is including GPS, and if detailed satellite images can be found from the Freiburg Forest.
October 27, 2021
Starting on the NUC again. Started a vanilla-shell, connected the PAL camera via USB-C, Explorer works (although an segmented view).
Running the script in installations/camera_data didn't help, running the setup script in PUM*.zip did.
Started ros2 run pal_camera capture. Now ros2 topic list shows the camera images and point-cloud messages.
Yet, with image_view nothing shows up, also no message on publishing. Access to the PAL camera is locked, Explorer only starts to work when the capture node is killed. Explorer also still works after sourcing the foxy/setup.
Restarting the NUC, because of a software update (including rviz).
Note that the Explorer complains that it couldn't load libcudart.so.10.1 (which could be ignored when no nvidia-GPU is on board. Yet, the NUC should have a GeoForce RTX 2060 onboard (checked with sudo lshw -C display).
Explorer also works with combined foxy and ros2_2s setup.
Checked nvidia-smi, CUDA version 11.2 is installed.
Downloaded the official 20.04 package with wget http://archive.ubuntu.com/ubuntu/pool/multiverse/n/nvidia-cuda-toolkit/nvidia-cuda-toolkit_10.1.243-3_amd64.deb, followed by sudo dpkg -i nvidia-cuda-toolkit_10.1*.deb, followed by sudo apt --fix-broken install. Now only libcudnn.so.7 is missing according to the Explorer.
Downloaded from nvidia archive cuDNN runtime library for CUDA 10.1. That works, although the deb is officially for Ubuntu 18.04. Also installed the dev-version of the library, maybe that was not needed. Explorer no longer complains on libcudnn and reports that it has found a Nvidia GPU with Compute Capacity 7.5. Yet, the NUMA node gives a negative value, and common_runtime/gpy/gpu_device.cc:1858 reports that it adds visible gpu devices: 0 (which seems to be OK, because at line 14-2 it reports that it created a job at the localhost/replica.
Note that the PAL-Firmware directory is already in LD_LIBRARY_PATH.
Started the Explorer from the PAL-*-20.04 zip. Now I receive the DualEnet Error again. The main difference, is that the 20.04 is using libpython3.8.so, while the 18.04 is using the libpython3.6m.so (both from /usr/x86_64-linux-gnu). In 18.04 I also installed PAL_PYTHON.cpython-36m-x86_64-linux-gnu.so in my lib). With 20.04 no PYTHON code is delivered. The dependency is in libPAL.so only, not in the other libraries. The node also works without the LD_LIBRARY_PATH set (needed for Explorer?). Building it with fresh links (so also the correct include files, the CameraProperties are quite different!) doesn't help. Explorer also works fine without LD_LIBRARY_PATH.
The code works now fine, by replacing mPubLeft.getNumSubscribers(); to count_subscribers(mPubLeft.getTopic());. Released v1.1.9 of the code.
One remaining addition is to check if there is a connection from map to base. Line 2852 of zed_camera_component.cpp has an example.
The full chain is not working, but published v1.2.0.0 with an explicit update with every grab from map to pal_camera_center. Tested it on the NUC after a full reboot, works fine.
October 26, 2021
Looked on scholar for Spot navigation papers, but could only find this paper which was submitted to ICRA 2022, which concentrates on three
Intel RealSense D435i cameras mounted on the robot. No explicit citation of Spot papers. The paper also mentions a dataset, but this dataset is not published yet.
Best paper I could found, is the IROS 2020 paper which describes NASA JPL contribution to the DARPA Subterranean Challenge, which extented Spot capabilities with the neBula extension.
October 19, 2021
This post discussed the coordinate transformation of the zed-camera quite extensively.
This Turtlebot tutorial goes from perspective image to panoramic images, it would be nice to do the reverse.
Could not find a ros-package to do the reverse, although this paper describes the process (this seems to be the JavaScript code, including an example from a street from Amsterdam)
Mounted the pal camera on the Segway robot. Collected images and even a point-cloud from rviz:
Also tried to load the visualisation of the camera, but loading from file fails (because pal-resources couldn't be found, should have sourced the ros2_ws first).
Had started a pal display at the background, so could start in vanilla rviz a robot model based on the /robot_description topic. Yet, when I do that, drawing the point-cloud fails on No techniques available for material [PointCloudMaterial0Sphere]. This also happens without the robot_description, this is just the difference between the system installed rviz and the configuration in my ros2_ws (check, the ros2_ws has no rviz2 package, only rviz_plugins).
Starting ros2 launch pal display.launch.py works fine, until I start the capture node, than rviz crashes without any warning.
Starting ros2 launch pal display.launch.py, switching the topics off, and starting the capture node works. The PointCloud2 are read, although not displayed (missing PointCloudMaterial). I also saw the depth and right image, before it crashed. Note that in the background a tranformation to the center and to the left coordination-frame is running.
Note that the capture node reports that it is still publishing point-clouds, also when the camera is not connected and the warning Not able to grab a first frame from the PAL camera is given (bug-report).
Found most recordings back on nb-ros at ~/packages/PAL-Firmware-v1.2-Intel-CPU/tutorials. Most recordings were from May 21, except room2 (June 29).
In git/yolov5/runs/detect are several experiments recorded with the Theta Z1. exp7 is a succesfull one in the kithcen.
The other runs are done on nb-dual or my workstation?
The yolov5_ros.py script from July 28 is in ~/git/yolov5 on nb-ros.
October 15, 2021
Continue with the installation instruction on the docker-image on my Linux-workstation.
Had to modify a number of versions in python requirements to get it installed for python3.6.
At least python3.6 test_py_installations.py works.
Running PAL's Explorer fails on missing libopencv v3.4.
Also compiling the cpp tutorial code still fails on missing opencv includes. The python examples are not part of the zip file. The PYTHON directory is part of PAL's 18.04 zip, but not part of the 20.04 zip.
Added PAL's lib to both PYTHONPATH and LD_LIBRARY_PATH. Now only libopencv v3.4 is missing.
Looked in pkgs.org for libopencv-core, but v3.4 is between 18.04 (v3.2) and 20.04 (v4.2). Looked what is available with apt list -a libopencv-core-dev, which on nb-dual only returned 4.2.
Uploading the required opencv 3.4.4 to github. The libopencv-imgproc.so is too large to be done via the webbrowser, so first had to create a personal access token.
Modified the repository that the node is now build. Running still fails because the libraries are not available on runtime. Added both lib/dreamvu and lib/opencv to LD_LIBRARY_PATH, and ros2 run capture starts in my docker environment. Unfortunatelly, I receive the error that the Primary Camera Data is not available!. Should try to install my PUM.zip
That removes the Primary Camera error, yet OpenCV (4.2) ../modules/videoio/src/cap.cpp:303 could not set prop 3 = 3120 in function set. Hypothesis: problem with running in a docker environment!
Testing on the NUC. Compilation works out of the box. Unfortunatelly, now I receive the PAL_DualEnet error again. Made python3 a link to python3.6, to no avail. Also made python a link to python3, still no success.
Added the PAL/lib with PAL_PYTHON library to PYTHONPATH, still no result.
On August 19 it start working again when I added dreamvu_ws/bin to the top of the PATH. This directory contains all side-packages of the virtual environment. My installation has put most side-packages in ~/.local/lib/python3.6/site-packages. Putting this directory onto the top of the PATH didn't help.
Creating dreamvu_ws environment. When doing pip install --upgrade setuptools pip I got the warning that launch-ros 0.11.4 requires pyyaml, which is not installed. That is part of the python_requirements_without_pkg_resources.txt.
Note that on NUC I use the 18.04 PAL UDK zip, instead of the 20.04 zip.
After running the camera_data/setup_python_lib.sh Explorer works (dreamvu_ws not activated)! Also python main1.py works.
Also ros2 run pal_camera capture starts, although the node complaints that the PAL settings are not (yet) on the default location ~/.local/etc/dreamvu/.
Tried to visualize the published topics with image-view, but see nothing. Running ros2 topic list fails on missing rclpy. Changed python3 back to python3.8, and ros2 topic list works again. Opened a new terminal, Exploer still works (no dreamvu_ws activated, no ros-foxy sourced). Also python3.6 main1.py works. Still, the only topic which seems active is /tf.
Committed my latest modifications, and made sure that it still compiles.
October 12, 2021
Tried to install ros-foxy-ros-base on my XPS workstation, which now runs Ubuntu 21.04. That doesn't work, because there is no Release for hirsute.
Unfortunatelly, even the development version ros2-rolling isn't ready for Ubuntu 21.04.
Look if I can use a docker environment to do the trick. Following this tutorial.
Started the System Tools -> Lx Terminal from the lower left.
All ros2-packages from github repository are already installed, except ros-foxy-image-view.
After doing a sudo apt update I could install ros-foxy-image-view and the two python3 packages.
Downloading the PAL USB SDK with wget.
October 8, 2021
Continue with the last parts of the ros2 dreamvu node. On August 27 I had a version based on cv_camera which also published point-clouds.
Looked in the code, and in line 284 of pal_capture.cpp I start creating a PointCloud2 message.
Copied that code, and it compiles. Starting to test. The first time rviz2 crashed, the 2nd time rviz2 starts, but doesn't display an image (no warnings, image_view works). Tried to add PointCloud2, but don't see the topic. The topic is visible with ros2 topic list.
Adding the topic by hand is responded by the dreamvu node with ublishing a first point-cloud of the PAL camera but the rviz2 status is Showing [0] points from [0] messages.
What is different compared with Monday?
Without the PointCloud, the code still works. Is it the Publish, or the Grab? With the point-cloud advertised, it still works. Uncommenting all, publishing the images goes well. Only difference was an additional source ros2_ws/install/local_setup.bash.
The point-clouds are published, the update of the camera's seem to slow down. rviz2 crashes, after displaying the warning No techniques available for material [PointCloudMaterial0Sphere].
According to this old post that error seems to be related with OpenGL support. rviz2 opens with rviz2]: OpenGl version: 4.6 (GLSL 4.6), followed by [rviz2]: Stereo is NOT SUPPORTED. That could indicate that point-clouds are also not supported :-).
Trying to follow the build instructions in /tmp/ros2_ws. Yet, compilation fails on templates. Tried to increase the CMAKE_CXX_STANDARD to other options as indicated in the cmake documentation, but still there is a conflict between the foxy includes and /usr/include/c++/9. The file pal_camera_capture.cpp compiles. Problem was a missing bracket in a comment in pal_camera_node.cpp.
Was looking to bcpp to clean up my files, but even with the option -i 2 too large indents are made.
Node starts nicely, the topics are published, the first image is grabbed. It only seems that no subscribers are found, because the original node works fine, while this one receives no subscribers.
Added the udev installation to my readme. Sensor only works on the USB-C port.
Python3.6 is already installed, although I have to add export PYTHONPATH=~/packages/PAL-Firmware-v1.2.-Intel-CPU/lib to get it working. Still, the PAL_PYTHON.so in the Firmware is still the one linked to opencv_core.so.3.2, so had to replace it with the version I received.
That works. Now I have to install the missing python packages. Installed python3.6 -m pip install numpy-1.17.0 and python3.6 -m pip install opencv-python=4.4.0.44. Still python3.6 main1.py gives PAL_MIDAS::Init failed.
Did python3.6 test_py_installation.py. Also had to install python3.6 -m pip install imageio==2.9.0, python3.6 -m pip install torch==1.4.0, python3.6 -m pip install torchvision==0.5.0, python3.6 -m pip install scikit-image==0.14.5, python3.6 -m pip install scipy==1.5.2, python3.6 -m pip install Pillow==6.1.0. After Pillow python3.6 test_py_installation.py works.
Yet, python3.6 main1.py still gives the PAL_MIDAS error, while the Explorer gives the PAL_DualEnet error. Also installed the other dependencies with python3.6 -m pip install -r python_requirements_without_pkg_resources.txt. Now Explorer starts, but fails on PAL_MIDAS. Funny end, python3.6 main1.py now fails on PAL_DualENet! The C++ examples compile without problems, yet 001_cv_png.out also fails on PAL_DualEnet. From the other dependencies only mesa-common-dev was missing. Also adding /packages/PAL-Firmware-v1.2.-Intel-CPU/lib to LD_LIBRARY_PATH didn't help. Time to go home.
Starting with implementation of the point-cloud publisher. Note that there is in ros-foxy a new point_cloud_msg_wrapper, although this is not part of the standard ros-foxy distribution.
October 5, 2021
Restarted my visualisation pipeline. ros2 launch pal display.launch.py only works (not dropping messages) when ros2 launch ./transform_pal_left.launch.py and ros2 launch ./transform_pal_center.py are started. It is pal_center, and not pal_right, because my current (v6 code) publish the right images with FrameId of pal_camera_center. In principal this is correct location for the coordination frame of the camera, although for the correct orientation of the image the view should still be rotated 90 deg (plus an additional 30 deg for the right panorama). The v6 code also the transform from the pal_mounting_link to the base_link, but that transform is currently not used, although an transform from the map to be base_link is expected by rviz2.
Changed the left FrameID also to pal_camera_center. Note that the right image is smaller than the left image in rviz2. Cleaned some other stuff (saved v7). Code is now ready to receive some additional functionality (depth and point-cloud).
Load the properties from file. They are also stored to a global variable, but in the ros1-code from these properties only the colorspace is used (not even the width / height).
The ros1-package also should have a detect node, which publishes the topic /dreamvu/pal/persons/get/detection_boxes. Have not seen that part of the code.
The node should also subscribe to /dreamvu/pal/set/properties.
Added the code for the depth-panorama. Seems to work:
Unfortunatelly, the Rosject is not opening, nor in Firefox, nor Chrome (with a complaints on mobile devices).
With this link the Roject could be loaded. Nice to see also many warning messages in this project, such as messages dropped, and missing model.config from /home/user/.gazebo/models/mpo_700.
October 1, 2021
Creating the CamInfo message. The FrameId refers not to a topic or a frame-count, but to a coordinate-frame. For the zed-camera the coordinate frames are defined in zed_wrapper/urdf/zed_descr.urdf.xacro. Note that for the zed-camera the left and right image are shifted half a baseline, and that the coordinate frame of the camera (optical_frame) is rotated 90 deg around the x and z axis.
The function getCamera2BaseTransform get the transformation from mCameraFrameId to mBaseFrameId. I will use mCameraCenterFrameId, to make a better distinction between the base and the center (6 cm higher) of the pal_camera.
The zed_component nicely gives a warning when no base-frame could be found, so when the TF chain is broken.
I should make the warning Not able to grab a frame from the PAL camera a once message. Looks like that the grab-thread already starts before the main tread is finished with initialisation.
The code compiles. First I received many warnings, but with an PAL:Init() for both left (spin_once) and right (spin) only the right topic is published. Also created ros2 launch ./transform_pal_center.py, but even ros2 run image_view image_view --ros-args --remap image:=/dreamvu/pal/get/right is not working. Checking the spin. The spin seems to work. The topic is advertised, but I don't see the first grab.
Replaced the thread with simple loop-function. That works, the right image can be seen with ros2 run image_view image_view --ros-args --remap image:=/dreamvu/pal/get/right. Unfortunatelly, this is not the case for rviz2. Started a static transform from map to both pal_right and pal_camera_center, to no avail. Copied both files (cpp and hpp to backup v5).
Also publish the left image, now with FrameID "pal_left" (as before). Visible with image_view, not with rviz2.
Adding a transformStamped, as in v4. This creates a transform from pal_camera_base_link to base_link. Yet, in the description I have named it pal_mounting_link. Started also ros2 launch pal display.launch.py, but the left and right are not visible.
Changed the transform from pal_mounting_link to base_link. Now I receive one (right image), but it seems that the grab_loop finishes without CTRL-C. Looks like the mTfBroadcaster is not initialized. Initializing the mTfBroadcaster solves the issue:
Saved the version in backup as v6.
Split the code in a node and a small exec (pal_camera_capture.cpp), which calls the node (equivalent with the wrapper). The node is a class with its own namespace and variables. Code still works.
September 27, 2021
The flexible USB 3.1 cable works with cheese and the Intel RealSense D435.
Started ros2 launch ./transform_pal_left.launch.py, combined with ros2 run dreamvu_pal_camera capture and ros2 run rviz2 rviz2, which means that v3 still works:
Created a rudimentary PalCameraNode class, to start cleaning up the code. Nicely prints DreamVU PAL Camera v4.
September 24, 2021
Got access to an Intel NUC, with Ubuntu 20.04 and ros-foxy-desktop.
Added sudo apt-get install ros-foxy-v4l2-camera.
Connected a Intel RealSense as webcam, but the available pixel format (Z16) is not supported to be converted to rgb8.
Connected a Logitech C930e webcam. This one supports YUYV 4:2:2, so ros2 run v4l2_camera v4l2_camera_node works!
When I start ros2 run rviz2 rviz2, I receive the error Messag Filter Dropping message.
This post suggest to add a fixed frame to the camera frame.
That works. Created a transform.launch.py with a static_transform_publisher between map and camera. Now the image of the C930e webcam is displayed by rviz2.
That also works on nb-dual, I could display my webcam with ros2 run v4l2_camera v4l2_camera_node:
With a transform from map to pal_left finally the image from the dreamvu_pal is displayed!
Copied the content of ~/ros2_ws/src (both pal and dreamvu_pal_camera) to the NUC.
Created a build.sh in ~/row2_ws. The pal package is build, dreamvu_pal_camera complains on missing libopencv 3.4.
Added a joint_state_node_gui to the launch.py. That gives a gui, but because all joints are fixed, there is nothing to control.
The gazebo.launch also launches a static_transform publisher, from base_link to base_footprint. Maybe I could launch a transform_publisher to model the tf from map to pal_mounting_link with this code:
map_tf_node = Node(package = "tf2_ros",
executable = "static_transform_publisher",
arguments = ["0", "0", "0", "0", "0", "0", "map", "pal_mounting_link"])
Now I have a rviz2 screen without warnings (saved v5 of display.launch.py):
Started ros2 run dreamvu_pal_camera capture but still receive: rviz2-4] [INFO] [1632407636.213696855] [pal_rviz2]: Message Filter dropping message: frame 'pal_left' at time 1632407633,954 for reason 'Unknown'
Starting to look at Sander van Dijk's ros2_v4l2_camera package. Started the node with ros2 run v4l2_camera v4l2_camera_node. Also this camera frames are dropped!
In this issue Sander points out that only YUYV and GREY are supported.
Time to inspect the rviz2 side!
September 22, 2021
Copied the robot description package from a catkin_ws to a ros2_ws. The CMakeList.txt mainly consists of installing the config, launch, meshes and urdf, so should be easy to port to the ament build-system.
The command colcon build --symlink-install --cmake-args=-DCMAKE_BUILD_TYPE=Release works directly, the directory ros2_ws/install/pal/share/pal/launch/ is created, but still ros2 launch pal display.launch cannot find this package in ros2_ws/install. Adding ament_package at the end (see base outline) helps, but I also had to rephrase the install command. Ament includes an ament_index in the share, which was also done in zed_display_rviz2. Still the package is not found.
Modified the package.xml: now the package can be found.
Thought that the ros_ws/install/pal/share is now correct, but this directory contains now the display.launch and the pal.urdf in this directory, instead of its subdirectories.
When I call ros2 launch pal display.launch the launch file is called, but the seen as Invalid. The zed_display_rviz2 uses py scripts to configure the launch of the nodes, as described in ROS2 launch-system tutorial.
For the moment, I will first try minimal modifications following the migration guide. Changed type to exec. Still a problem, maybe the textfile which is no longer supported. The ros-foxy robot state tutorial uses a python launch-script. Replacing textfile with value makes it not yet a valid launch file. Commented all nodes out. Now it is valid.
The joint_state_publisher is not a known package, the robot_state_publisher is. It is only missing the robot_description parameter, but invalids on $(find pal).
The robot_state_publisher seems to need the content (xml-object) as parameter, so made a display.launch.py based on the robot state tutorial. Seems to work. Several topics are published (/joint_states, /robot_description, /tf, /tf_static), although only /tf_static gives an echo (empty transform). The launch file has currently only one Node, which gives the output:
[robot_state_publisher-1] Parsing robot urdf xml string.
[robot_state_publisher-1] The root link pal has an inertia specified in the URDF, but KDL does not support a root link with an inertia. As a workaround, you can add an extra dummy link to your URDF.
[robot_state_publisher-1] [INFO] [1632320682.566620378] [robot_state_publisher]: got segment pal
Solved this warning with this piece of code (inspired by example):
<link name="pal_mounting_link">
<!-- dummy link without inertia -->
</link>
<joint name="pal_mounting_joint" type="fixed">
<parent link="pal_mounting_link"/>
<child link="pal"/>
</joint>
Rewrote the display.launch.py (v2) to add multiple actions to the LaunchDescription. Still works.
Added a rviz2-node to display.launch.py (v3). This launches rviz2. By default the RobotModel is included in the display. Adding a RobotModel display with /robot_description as topic works mostly, although an Status:Error is given because both links have no transform to the map (yet):
Saved this configuration in install/pal/share/pal/, although the original urdf.rviz is still in src/pal.
September 21, 2021
Received a ros1-package with the robot description of the pal-camera.
Made the package for ros-noetic with command catkin_make --only-pkg-with-deps pal.
Could start the rviz visualisation with roslaunch pal display.launch. After installing some missing python packages with python3 -m pip install rospkg and python3 -m pip install PyQt5 the display was extended with a joint_state_publisher_gui (center or randomize).
After apt install ros-noetic-gazebo-ros, python3 -m pip install pycryptodomex and python3 -m pip install gnupg the command roslaunch pal gazebo.launch works without warnings. Both a fake_joint_calibration and a tf_footprint_base (static_transform) are published.
Started the ros1 camera node with roslaunch dreamvu_pal_camera pal_camera_node.launch. The node died because of qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "~/packages/PAL-Firmware-v1.2-Intel-CPU/installations/dreamvu_ws/lib/python3.6/site-packages/cv2/qt/plugins" even though it was found. The topic is advertised, but roslaunch pal display.launch recieves no images.
Strange, the ros-node doesn't have direct dependency on qt. The executable capture has not even a dependence on a qt library. Where is the qt plugin loaded? Seems to be part of cv2. Started rqt_image_view without problems, which loads its plugins from /usr/lib/x86_64-linux-gnu/qt5/plugins/. Moved the qt directory from installations/dreamvu_ws/lib/python3.6/site-packages/cv2 to ~/tmp. Without this directory the ros1-node starts without problems. Can now display both the robot model and depth image. Also displaying the PointCLoud2 works fine, although the robot model of the camera is hovering nearly 10cm above the table. Note that the framerate drops to 1 FPS when point-clouds there is a subscriber for point-clouds (default resolution):
Rviz died when I selected unreliable transmission of point-clouds (to increase the frame-rate) and the ros-node died when I selected boxes to display the points.
September 20, 2021
Filled in the tf message with the transform ids from base_link to pal_camera_base_link.
Note that in display_zed.launch (line 60) not only publish_urdf is set on try, but also the camera pose is initiated with all zeros. A little bit lated the share_directory for zed_descr.urdf.xarco is set (which is ros2_ws/install/zed_wrapper/share/zed_wrapper/urdf/).
This sort of works, no complains anymore from ros2 run rviz2 rviz2 on the tf messages, but still the pal_left images are dropped for Unknown reasons. Could go into the rviz code to look, or try ros2 v4l2 implemention.
Copied this version to backup v3.
September 17, 2021
Continue with porting ros2_ws dreamvu_pal_camera. Started with source /opt/ros/foxy/setup.bash and colcon build --symlink-install --cmake-args=-DCMAKE_BUILD_TYPE=Release, but compilation fails on line 307 on a publish without a infomsg.
Created the content of the infomsg inspired by the fillCamInfo of zed_components.cpp. Note on line 1828 the fourth column [Tx Ty 0] is set for a stereo pair. That requires the baseline of the dreamvu camera (should look what the zed camera uses as baseline (and unit). In /usr/local/zed/settings/SN21259.conf the BaseLine is specified as 119.865 (and TY=0.43668 TZ=0.299628, although this values are not directly used in zed_components.cpp)
Most of the values are in correspondence with ros2_ws/install/dreamvu_pal_camera/calibrations/PUM82D21007.yaml.
The VideoQoS is set by the zed_camera parameter based. Default seems to be RMW_QOS_POLICY_RELIABILITY_RELIABLE and RMW_QOS_POLICY_DURABILITY_VOLATILE, but I should check.
The pal_camera now compiles. ros2 run dreamvu_pal_camera capture gives warning Camera calibration file /home/arnoud/ros2_ws/install/dreamvu_pal_camera/share/dreamvu_pal_camera/calibrations/PUM8D210007.yaml not found, which is correct, because the file is in ros2_ws/install/dreamvu_pal_camera/calibrations/PUM8D210007.yaml. The two topics (left image and camera_info) are visible with ros2 topic list. Also ros2 run image_view image_view --ros-args --remap image:=/dreamvu/pal/get/left works. Saved this version in backup as v2.
Also tried ros2 run rviz2 rviz2, which fails again on Message Filter dropping message: frame 'pal_left' at time 1631871972,213 for reason 'Unknown'. Look if it helps to publish a tf.
When I start ros2 launch zed_display_rviz2 display_zed.launch.py I see also topics like /tf and /tf_static, together with /zed/robot_description to display the zed-sensor. I also don't get camera updates, so I have to check. The output of zed_display is hard to interpret, because of the many warnings on nvalid frame ID "map" passed to canTransform argument target_frame - frame does not exist from ine 133 in /tmp/binarydeb/ros-foxy-tf2-0.13.11/src/buffer_core.cpp. Yet, at the start it displays for instance Camera resolution: 2 - HD720, Video QoS Reliability: RELIABLE, Video QoS Durability: VOLATILE, Depth quality: 1 - PERFORMANCE, Depth downsample factor: 0.5 (same QoS for Depth as Video). Also important Base frame id: base_link, Map frame id: map, Odometry frame id: odom, Spatial Mapping Enabled: FALSE
The zed_wrapper also stores its settings in install/zed_wrapper/share/zed_wrapper/config/common.yaml, so I should move my pal calibration directory. Changed the setting for zed to mapping is true, to see if the warning is gone then.
Tried to start /usr/local/zed/tools/ZED_Explorer, which didn't seem to work. Previously I had to reboot, so tried that. Again it looks like nothing is happening, but after 60 seconds the stream is displayed. So the ZED camera WORKS. Looked with dmesg | tail what causes the delay, and only see:
[ 459.166503] systemd-journald[8114]: Received client request to flush runtime journal.
[ 569.374297] uvcvideo: Non-zero status (-71) in video completion handler.
Problem is probably the missing GPU, previously I have tested the wrapper on ws10 with GPU!
Started the wrapper seperately with ros2 launch zed_wrapper zed.launch.py. The command ros2 topic list shows that only the /tf and /zed/robot_description topics are published. The wrapper indicates:
zed_wrapper-2] 1631878500.223408217 [zed.zed_node] [INFO] *** CAMERA OPENING ***
[zed_wrapper-2] No NVIDIA graphics card detected. Install an NVIDIA GPU, CUDA and restart your computer after completing installation.
[zed_wrapper-2] 1631878585.561132539 [zed.zed_node] [WARN] Error opening camera: NO GPU DETECTED
[zed_wrapper-2] 1631878585.561226981 [zed.zed_node] [INFO] Please verify the USB3 connection
[zed_wrapper-2] CUDA error at Camera.cpp:94 code=100(cudaErrorNoDevice) "void sl::Camera::close()"
[zed_wrapper-2] CUDA error at Camera.cpp:148 code=100(cudaErrorNoDevice) "void sl::Camera::close()"
[zed_wrapper-2] CUDA error at Camera.cpp:183 code=100(cudaErrorNoDevice) "void sl::Camera::close()"
[zed_wrapper-2] CUDA error at CameraUtils.hpp:691 code=100(cudaErrorNoDevice) "void sl::ObjectsDetectorHandler::clear()"
[zed_wrapper-2] CUDA error at CameraUtils.hpp:707 code=100(cudaErrorNoDevice) "void sl::ObjectsDetectorHandler::clear()"
[zed_wrapper-2] CUDA error at CameraUtils.hpp:713 code=100(cudaErrorNoDevice) "void sl::ObjectsDetectorHandler::clear()"
[zed_wrapper-2] CUDA error at CameraUtils.hpp:716 code=100(cudaErrorNoDevice) "void sl::ObjectsDetectorHandler::clear()"
[zed_wrapper-2] CUDA error at CameraUtils.hpp:718 code=100(cudaErrorNoDevice) "void sl::ObjectsDetectorHandler::clear()"
[zed_wrapper-2] CUDA error at CameraUtils.hpp:726 code=100(cudaErrorNoDevice) "void sl::ObjectsDetectorHandler::clear()"
[zed_wrapper-2] CUDA error at Camera.cpp:198 code=100(cudaErrorNoDevice) "void sl::Camera::close()"
[zed_wrapper-2] in void ai::NNImageResizer::clear() : cuda error [100]: no CUDA-capable device is detected.
[zed_wrapper-2] in void ai::NNImageResizer::clear() : cuda error [100]: no CUDA-capable device is detected.
[zed_wrapper-2] in void ai::NNImageResizer::clear() : cuda error [100]: no CUDA-capable device is detected.
[zed_wrapper-2] in void ai::NNImageResizer::clear() : cuda error [100]: no CUDA-capable device is detected.
[zed_wrapper-2] in void ai::NNImageResizer::clear() : cuda error [100]: no CUDA-capable device is detected.
[zed_wrapper-2] in void ai::NNImageResizer::clear() : cuda error [100]: no CUDA-capable device is detected.
Trying to add a tf2_ros/transform_broadcaster to pal_camera. ros2 run dreamvu_pal_camera capture now also publishes /tf. The transform itself is empty:
transforms:
- header:
stamp:
sec: 1631882736
nanosec: 599538154
frame_id: ''
child_frame_id: ''
transform:
translation:
x: 0.0
y: 0.0
z: 0.0
rotation:
x: 0.0
y: 0.0
z: 0.0
w: 1.0
Starting ros2 run rviz2 rviz2 gives still a warning on the global status, that Frame [map] doesn't exist. I receive the warnings:
at line 259 in /tmp/binarydeb/ros-foxy-tf2-0.13.11/src/buffer_core.cpp
Error: TF NO_CHILD_FRAME_ID: Ignoring transform from authority "Authority undetectable" because child_frame_id not set
at line 265 in /tmp/binarydeb/ros-foxy-tf2-0.13.11/src/buffer_core.cpp
Error: TF NO_FRAME_ID: Ignoring transform with child_frame_id "" from authority "Authority undetectable" because frame_id not set
at line 271 in /tmp/binarydeb/ros-foxy-tf2-0.13.11/src/buffer_core.cpp
Error: TF SELF_TRANSFORM: Ignoring transform from authority "Authority undetectable" with frame_id and child_frame_id "" because they are the same
If I inspect the PAL Technical Manual, I see that the horizon is 62.29 mm above the ground, with an opening angle of 52 deg down, and 58 deg up.
The camera has 12 segments, so the difference between left and right is not an translation, but a rotation of 30 deg (0.523598776 rad).
In this ros-hydro tutorial the urdf defines the links, geometry, mesh, inertia, and fixed joints.
As this tutorial indicates, the standard way is a chain from map to odom to base_link to sensor_base. For camera's there is an additional suffix frame, where z is forward, x to the right and y down.
Created a urdf from laser, with link, collision, visual and joint. Represented the pal camera with a cylinder of radius 0.05m and a length of 0.10m. Stored that urdf in install/dreamvu_pal_camera/share/dreamvu_pal_camera/description. Have not defined a pal_camera_center_joint yet, as the camera_depth described here.
A better example can be found in ros2_ws/install/zed_wrapper/share/zed_wrapper/urdf. This example is called from the zed_display_rviz2 launch file with this code:
# URDF/xacro file to be loaded by the Robot State Publisher node
xacro_path = os.path.join(
get_package_share_directory('zed_wrapper'),
'urdf', 'zed_descr.urdf.xacro'
)
Added a SensorModel to rviz, which waits for topic where the urdf is published.
Found a nice visualisation of the point-clouds surrounding the robot at the Robot report. They point to the ros-melodic package from clearrobotics, which describes in their documentation the 5 depth cameras (black-white), including details such as that the frontleft camera is looking over the robot's right shoulder.
The Spot-controller can convert the 5 surrounding images to a bird-eye view, as illustrated at Operating-Spot: .
Continue with the ROS2-driver for the DreamVU. First test is the DreamVU Explorer, which works.
Looked in the code of rviz. In rviz_common/src/rviz_common/frame_manager.hpp a discoverFailureReason is mentioned, with reference tf::FilterFailureReason. Yet, this function is not used. What is used is FrameManager::frameHasProblems, which calls the transformer.
The FrameManager is created in VisualizationManager, with a pointer to the TransformationManager which is just created in the same function.
Copied some of the cv_camera logic into ros2_ws/src/dreamvu_pal_camera (spin_some instead of executer.spin).
Did a colcon build --symlink-install --cmake-args=-DCMAKE_BUILD_TYPE=Release, which failed on package image_geometry (missing ament_package). Did source /opt/ros/foxy/setup.bash to solve this.
The command ros2 run dreamvu_pal_camera capture does a PAL::Init and PAL::LoadProperties, but ros2 topic list shows no advertisement.
Added an advertisement, but linking fails on missing get_message_type_support_handle sensor_msgs::msg::Image
Adding image_transport to CMakeList.txt solves this issue. The topic is advertised (but no images are yet to show with ros2 run image_view image_view --ros-args --remap image:=/dreamvu/pal/get/left).
Created an image-message and publish this, but image_view complaints:
ERROR] [1630676430.394786735] [image_view_node]: Unable to convert 'bgr8' image for display: 'Image is wrongly formed: step is smaller than width * byte_depth * num_channels or 1322 != 1322 * 1 * 3'.
That was a mistake in cv::Mat, CV_8UC1 instead of CV_8UC3. Now ros2 run dreamvu_pal_camera capture works!
Yet, ros2 run rviz2 rviz2 doesn'i work. Yet, note that the Global status is in warning, because no tf data is received.
Note that all images are published with image_transport, so with camera_info.
Checked the documentation. The standard url for the CameraInfoManager should be file://${ROS_HOME}/camera_info/${NAME}.yaml, with should be interpreted as file://~/.ros/camera_info/dreamvu_pal_camera.yaml. Probably package://ros_package_name/calibrations/camera3.yaml is a better choice, or in our case package://dreamvu_pal_camera/calibrations/PUM8D210007.yaml
Copied sony2_calibration as example. Note that I also created such a calibration file on July 22.
August 30, 2021
In this blog, Scythe Robotics state that a 60dB range is insufficient for the cameras to hande the stark lighting differences between shadows and direct sunlight, as encountered outdoors. Luckily, we are not in Texas.
August 27, 2021
Continue with getting the timing of the pal-messages. The pal_camera_node.cpp has no ros2 CameraPublishers yet, I was modifying the pal_capture in cv_camera.
Starting the test again with ros2 run cv_camera pal_camera_node --ros-args --params-file src/cv_camera/pal_camera.yaml. Output only shows initalization succeeded, the command ros2 topic list only shows /parameter_events and /rosout.
I probably tested it without PAL-camera, the Capture::open was hanging on cap_.open, which should only be called for a non PAL-camera. Now the dreamvu camera is publishing five topics:
/dreamvu/pal/get/camera_info
/dreamvu/pal/get/depth
/dreamvu/pal/get/left
/dreamvu/pal/get/point_cloud
/dreamvu/pal/get/right
Viewing the topic with ros2 run image_view image_view --ros-args --remap image:=/dreamvu/pal/get/left works fine.
Strange enough ros2 run rviz2 rviz2 doesn't work, while ros2 launch zed_display_rviz2 display_zed.launch.py. Yet, adding an image that listens to /dreamvu/pal/get/left doesn't work.
Added the latest version of image_transport in my ros_ws by git clone --branch ros2 https://github.com/ros-perception/image_common.git.
Build that version, and started the pal_camera_node. Reports that it is using the latest version of transport.
Unfortunatelly, ros2 run image_view image_view --ros-args --remap image:=/dreamvu/pal/get/left now fails on undefined qos_profile_t.
Yet, ros2 run rviz2 rviz2 works again! Yet, still the same error message: [INFO] [1630063258.731671534] [rviz]: Message Filter dropping message: frame 'camera' at time 1630063256,311 for reason 'Unknown'.
First tried to install image_view from source by git clone --branch ros2 https://github.com/ros-perception/image_pipeline.git. Fails on missing image_geometry. Installed ros-foxy-image-geometry. That works for the include, but now I have a linking error.
Also did git clone --branch ros2 https://github.com/ros-perception/vision_opencv.git. Had to do python3 -m install pytest to get this working. Still problems with package image_proc, so put a COLCON_IGNORE there. That results in stereo_image_proc which fails. The command source install/local_setup.bash complains on missing those two packages, but ros2 run image_view image_view --ros-args --remap image:=/dreamvu/pal/get/left works (although it doesn't report that it uses the CameraSubscriber. Instead it uses the subscription without the CameraInfo.
When I run ros2 run rviz2 rviz2 --ros-args --remap initial_reset:=true rviz does not reports that it makes use of the latest image_transport.
Also added git clone --branch ros2 https://github.com/ros2/rviz.git
.
That build fails on missing resource_retriever, which is strange because ros-foxy-resource-retriever is already installed.
Also added git clone --branch ros2 , but the include directory is still not found. Made an explicit link in rviz_render/include.
Still, rviz fails to build, for instance due to
tionEventCallbacks’ has no member named ‘message_lost_callback’
210 | sub_opts.event_callbacks.message_lost_callback =
.
Folllowed the instructions, and created a clean rviz2_ws, followed with colcon build --merge-install, but precisley the same errors. Removed the rviz_ws again.
Made an version where left is a publisher without CameraInfo. The stream is visible with image_view, but fails with rviz (still the dropping message).
August 26, 2021
After the reboot, the ZED_Explorer works again. But after sourcing the ros_ws and starting rviz, the camera is no longer seen on the usb-port. Also ZED_Explorer is no longer working. New reboot.
The ZED_Diagnostic can run all tests, but ZED_Explorer starts only after a very long time.
Trying again after sourcing foxy/setup.bash. Still starts after a while. Same after sourcing the ros_ws.
Trying ros2 launch zed_wrapper zed_launch.py, but that fails on a Camera detection timeout.
Increased the camera_timeout_sec in zed_wrapper/config/common.yaml from 5 sec to 50 sec (keeping the retries on 5x) and launched the zed_wrapper again. Still an Error in opening the camera, the only topics published is the /zed/joint_states and zed/robot_description. The zed_wrapper also complains on the missing GPU for NNImageResizer and sl:ObjectsDetectorHandler. No success, even after a long wait.
August 24, 2021
The CUDA requirement can be found in both the zed_wrapper and zed_components CMakeLists.txt. Yet, I don't see a dependence in the code.
Only the zed_components relies on the ZED_LIBRARIES and CUDA_LIBRARIES.
Looked into the code of zed_components. Multiple threads are started, and multiple Timers are initiated.
Most relevant seems the GrabThread, which sets the mFrameTimestamp at line 3270, using a function sl_tools::slTime2Ros(), which is probably still the same as for ros: sl_tools.cpp:
ros::Time slTime2Ros(sl::Timestamp t)
{
uint32_t sec = static_cast(t.getNanoseconds() / 1000000000);
uint32_t nsec = static_cast(t.getNanoseconds() % 1000000000);
return ros::Time(sec, nsec);
}
The Images with info are published at line 4300, which again makes use of a sensor-lab function sl_tools:imageToROSmsg(), which can be found at line 213 from sl_tools.cpp, which sets all header information and encodings.
The timestamp is in principal the timestamp as recorded in mZed.retrieveImage(), which is method of sl::Camera.
Tried if I could make the zed_wrapper on nb-dual. Replaced find_package(CUDA REQUIRED) by the more modern project(zed_components LANGUAGES CUDA), but CMake complaint that it couldn't compile the simplest test program (path to libdevice not specified).
Still, was able to make the wrapper, although the linking failed on missing jpeg libraries.
Checked the /usr/local/zed/tools. The ZED_Explorer works, the ZED_Depth_Viewer needed another nvidia library. With this library the ZED_Depth_Viewer starts, but with a warning on the screen "No NVIDIA graphics card detected. Install an NVIDIA GPU, CUDA and restart your computer."
The ZED_Sensor_Viewer reports no camera, but that could be due that I have a classic ZED without additional sensors.
The ZED_diagnostic first complained about the USB (connected via an USB-2 hub), but after a direct connection there was only a GPU and CUDA missing:
Calibrating the camera was fun, and provided a calibration file in /usr/local/zed/settings/SN21259.conf.
The tool ZEDfu also starts, although it doesn't show any live stream, but could also be used to load a prior map.
Seems like a good tool to make maps for the 3D Looking glass.
Seems that still the ros_ws/install/zed_interfaces/share/zed-config.cmake is used, while I also have copied the original ones to /opt/ros/foxy/shared/zed/cmake. There the static libraries of turbojpeg.a are specified, but I need the dynamic libturbojpeg.so. The ones in /opt/ros/foxy were not readable, so I made them readable, removed the CUDA reference, and removed them from install/zed_interfaces. Now the wrapper builds (although from src/zed-ro2-wrapper, not ros_ws itself).
Removed the corrupted build and install, and now the zed-wrapper could be build from ros_ws.
Also installed zed_display_rviz2 from zed-ros2-examples. Only rgb-convert had a CUDA dependence. Yet, no image is displayed. Strange enough, also ZED_Explorer works no longer, even after removing pal-Firmware from the PATH. ZED_Diagnostics still works.
When I only start the wrapper with ros2 launch zed_wrapper zed_launch.py I got a timeout (and request to check my USB-connection). Time for a reboot.
August 23, 2021
Trying to install ZED visualisation software for ros2.
Checked on ws10, but nvcc --version indicates v11.1, while nvidia-smi indicates v11.2. There is no /usr/local/cuda/version.txt, and dkpg -l shows cuda-toolkit 11.1.1. Downloading the ZED SDK for Cuda 11.1.
The installation path is /usr/local/zed. Entered all default answers to the installation script, except the Object Detection module (which would have installed cuDNN 8.0 and TensorRT 7.2).
Installing the Python API failed on missing CUDA installation (seen as a warning).
Started /usr/local/zed/tools/ZED_Explorer, but camera is not directly detected (expected the need to reboot), but after a few seconds it was there (and gone again).
Also /usr/local/zed/tools/ZED_Depth_Viewer is waiting for the camera. Checked with w and top if I was the only user, and rebooted. Now the ZED_Depth_Viewer worked fine.
Installing rox-foxy-ros-base by following the instructions again, followed by installing ros-foxy-rviz2, ros-foxy-image-transport, ros-foxy-camera-info-manager and ros-foxy-image-view.
Continue with the zed_ros2_wrapper. First had to install python3-rosdep2 and python3-colcon-common-extensions.
Launching the node gives many warnings. Also the Depth_Viewer no longer gives a view, while the ZED_Explorer gives a segmenation fault.
Rebooted, the ZED_Explorer works again. Used the Settings icon in the upper right Corner, and checked the firmware (current 1523 - which is latest version).
After the source /opt/ros/foxy/setup.bash and source ~/ros_ws/install/local_setup.bash ZED_Explorer still works.
Also installed zed_display_rviz2, which is part of zed-ros2-examples. The command ros2 launch zed_display_rviz2 display_zed.launch.py starts both rviz and the wrapper. Received some warnings on Invalid frame ID "map". Also, I receive the stereo, but not the RGB Image, nor the Depth map.
This can be issue with the reliability prolicy ("sensor data" vs "reliable", but I remember some issue with image transport (most of the non-published topics had camera_info).
Note that the zed_wrapper is designed to make maximal use of the nodelet package, in order to run multiple algorithms in the same process with zero copy transport between algorithms.
Checked the zed_node indicates GPU ID: -1 and rviz reports that Stereo is NOT SUPPORTED. Other that encountered this issue where redirected to Quality of Service policies.
Continue with the video tutorial after lunch. Checked ros2 topic list on what is published. The command ros2 run image_view image_view --ros-args --remap image:=/zed/zed_node/stereo_raw/image_raw_color works, many of the other topics not.
The settings in rviz2 are in correspondence with the suggestions in the the tutorial.
When I call the suggested ros2 run zed_tutorial_video zed_tutorial_video --ros-args -r left_image:=/zed/zed_node/left/image_rect_color -r right_image:=/zed/zed_node/right/image_rect_color no debug info is printed, while ros2 run zed_tutorial_video zed_tutorial_video --ros-args -r left_image:=/zed/zed_node/stereo_raw/image_raw_color gives me rectified images with a timestamp of 10Hz.
Looked in the zed_camera_component. The stereo-stream is published by a general image_transport publisher, while the other video streams are published by a image_transport camera_publisher. The QoS is the same. The confidence map is not even an image_tranport, but directly publisher sensor_msg::msg::Image.
Modified zed_camera_component, so that both mPubRGB and mPubDepth are published without CameraInfo. The video plugin gives a warning (and doesn't show the RGB image), while the Depth image is now visible. When I use the image-plugin (instead of the Video-plugin), the image is displayed. If I use the same plugin with CameraInfo (i.e. /zed/zed_node/left/image_rect_color, I got 'No Image'.
Anyway, the code of the zed_wrapper looks far more professional, so it shold be a good example.
Looked in the code of image_transport. Strange enough the CameraInfo doesn some the same custom_qos, but instead one derived from this provile with from_rmv(). Tried to change that, but that this call required a qos, not a profile.
Downloaded image_transport, and build it from source. The version of image_tranport of the ros2 branch is higher than the Debian install (v3.1 instead of 2.3).
Removed the installed image_transport. The zed_wrapper is build, but the during exection not (source ros_ws/install/local_setup.bash solves this). Now I have a working rviz2 for zed:
August 20, 2021
Seems that I still used some old ROS1-style code in my ROS2-node, because advertise is the first call to be replaced in Migration Guide.
The ROS2-style for point-clouds starts with #include "sensor_msgs/msg/point_cloud2.hpp", and the call pointpub_ = node_->create_publisher("/dreamvu/pal/get/point_cloud", 1);. The new topic is visible with ros2 topic list.
Created also the content of the point-cloud message. Checked it with ros2 topic echo /dreamvu/pal/get/point_cloud, results seems at first look OK. Saved this version backup/v3.
Could store the point_clouds in a rosbag and visualize them with this ros-noetic code
Zed has a nice rviz2 wrapper for depth images. Did rosdep install --from-paths src --ignore-src -r -y, but that only installed ros-foxy-xacro
So, instead I installed sudo apt-get install ros-foxy-rviz2
Tried to launch ros2 run rviz2 rviz2 -f pal -d pal.rviz, but I received many complains from the PluginFactory, including "The plugin for class 'rviz/Image' failed to load." Same for class 'rviz/PointCloud2'.
Yet, simply ros2 run rviz2 rviz2 works fine. Image is one of the default plugins, as can be seen from more /opt/ros/foxy/share/rviz_default_plugins/plugins_description.xml, as PointCloud2. I could add those Displays, only I couldn't change the topic. The topic could be changed in the field directly right of the topic (no need to open the topic).
When I start rviz, I receive the message that there is a subscriber on the point-clouds, but directly after that I receive that rviz is dropping messages (both camera and pal) for reason 'Unknown'.
Seems to be an issue with the timestamp. There seems to be some issue with system clock vs node clock, but this seems to be changed between ros2-versions (and c++ vs python). Didn't find clear example code.
In ros-noetic roslaunch dreamvu_pal_camera pal_rviz.launch works fine. Tried roslaunch dreamvu_pal_camera pal_rviz.launch together with ros2 run rviz2 rviz2, but the ros1-messages are not visible (also not with ros2 topic list.
Installed ros-foxy-ros1-bridge, and initiated the bridge by sourcing first the /opt/ros/noetic/setup.bash followed by /opt/ros/foxy/setup.bash. The command ros2 run ros1_bridge dynamic_bridge starts, by I only see created 2to1 bridge for topic '/rosout' with ROS 2 type 'rcl_interfaces/msg/Log' and ROS 1 type 'rosgraph_msgs/Log', not for the other messages (also not after restarting roslaunch dreamvu_pal_camera pal_camera_node.launch.
August 19, 2021
Succesfully linked the PAL::LoadProperties into Capture::loadCameraInfo.
Next step would be PAL::Init(). First trying the Explorer, but this one gives DualEnet error again. Looked with lsusb if there is a 3CAM, but with the cable they used in the demo-room the DreamVu PAL is not visible. Used the IAS one with original cable. Now (directly connected on the right usb-c with an usb-b adapeter) the 3CAM is visible.
Changed the link in the dreamvu_ws venv directly to /usr/bin/python3.6, instead of to the more general /usr/bin/python3. In the venv I could do Import PAL_PYTHON. Still, the Explorer gave a PAL_MIDAS::Init() error. Yet, python main1.py works.
Reconnected the II-demo camera, forced the usb-connector a bit deeper (spinning starts) and the camera is visible with lsusb and a get an image with python main1.py (although distorted, because I didn't apply the calibration step).
Deactivated, installations/dreamvu_ws/bin/python main1.py still works.
Added export PYTHONPATH=/home/arnoud/packages/PAL-Firmware-v1.2-Intel-CPU/installations/dreamvu_ws/lib64/python3.6/site-packages/ to ~/.bashrc and just python main1.py also seem to work (although I get an DualEnet error, while the dreamvu_ws/bin/python call stills works).
Put this bin on the top of the PATH. Explorer calls python3, so removed the python link in dreamvu_ws/bin/. Now, python --version gives 3.8, and python3 --version gives 3.6.
Modified pal_capture that if the device_id = -1 (default 0), the PAL:Init is called. Created a pal_camera.yaml, but ros2 run cv_camera pal_camera_node --ros-args --params-file ./pal_camera.yaml doesn't seem to work (although this is suggested in the tutorial.
After adding some log-messages reading the parameter file works, and the PAL-camera is succesfully initialized.
The driver of cv_camera initializes one camera_node with one topic, while the pal should publish multiple topics. A design choice has to be made, multiple camera instances or multiple topics. For the moment: multiple topics.
The images are grabbed, and the topic is visible, but ros2 run image_view image_view --ros-args --remap image:=/dreamvu/pal/get/left shows nothing.
Found the bug, forgot to publish after successfull grab. Got left image streamed!
Created a function grab_and_publish, which publishes also the right and depth image. The right image is correct, the depth image still needs the right conversion.
Seems to work, although the image fills the whole screen (also after reducing the saved settings to 1322x454) because it is full resolution (5290x1819):
August 18, 2021
Looking at the cv_camera. There exists also a foxy version. The noetic source contains 4 files, one of them capture.cpp (like dreamvu_pal_camera).
The readme file pointed for the ros2 driver to an older fork on github, which was build for dashing, but uses the rclcpp interface of ros2.
It also has a colcon based CMakelists.txt, which works (after source /opt/ros/foxy/setup.bash).
Also had to install sudo apt-get install ros-foxy-image-transport ros-foxy-camera-info-manager. After that the cv_camera packager for ros2-foxy is build. Receive some warnings on using image_transport.h instead of image_transport.hpp and possible conflicts from libopencv_core.so.4.2 with libopencv_core.so.3.4. The node is called with the command ros2 run cv_camera cv_camera_node
Switched python3 from python3.6 to python3.8 to be able to do ros2 topic list, which shows that both /camera_info and /image_raw are published.
After installing sudo apt-get install ros-foxy-image-view the command ros2 run image_view image_view image:=/image_raw works.
The cv_camera code is build as follows. The node calls the driver.setup() once, followed by a loop with driver.proceed() and spin_some(). The driver.setup() creates a new Capture instance and set the width, height, etc. The driver.proceed() is just a camera->capture(), camera->publish() and rate->sleep(). The camera->capture does a read(bridge.image), followed by a rescale and a timestamp. The bridge is a private path of the Capture class, but not further initiated during the creation of the class.
Removed the origin of the warnings during compilation. Still works.
Made a copy of cv_camera_node called pal_camera_node. Only difference for the moment is a RCLCPP_INFO print after succesfull setup.
August 17, 2021
Installing ros2-foxy on nb-dual, following instructions.
Had to do python -m pip install argcomplete before I could do source /opt/ros/foxy/setup.bash.
The command colcon build works, but fails on missing cv_bridge.
Installed cv_bridge with sudo apt-get install ros-foxy-cv-bridge.
Made symbolic links to dreamvu installation include and lib, and the node is succesfully build.
Made the dependencies user independent. Defined the PROPERTIES_FILE_PATH as ~/.local/etc/dreamvu/SavedPalProperties.txt. The ~ is a shell feature, so I have to find XDG_CONFIG_HOME. Yet, this is variable not defined (in contrast to XDG_CONFIG_DIRS).
Run the node with ros2 run dreamvu_pal_camera capture.
It is save to use getenv("HOME"), because without HOME ros Failed to get logging directory anyway.
August 16, 2021
It would be interesting to test my room classification on a subset of the Hypersim dataset.
Facebook also tried to integrate different AI-techniques for robotics in their Droidlet framework.
For Reinforcement Learning, the wrapper that used OpenAI gym interface for Webots simulation.
Segmenting the off-road path is according to David Cerny well described by Sharma 2019 and Holder 2016
David Cerny's works was inspired by World Models, where a small controller combines current Vision with a RNN Memory to decide good actions. The current Vision is compressed to smaller abstract feature vector by a Variational Autoencoder (VAE).
July 30, 2021
Made a round through the villa. At two sides of the living-room is recognized, but in the middle the couch or clock is not always visible. If the dreamvu camera is high enough, the sink in the kitchen is visible. The microwave is recognized as refigerator, but only with a frontal view. For the toilet the camera has to be a bit lower, to see the toilet. The beds in the bedrooms are quite reliable recognized.
Made a bag-file with command rosbag record /dreamvu/pal/get/type_of_room/dreamvu/pal/get/left /visual_image, as indicated in documentation. Note that no visual_image messages are produced.
My nb-ros froze at the end of the session. After rebooting, the rosbag was still active, so repaired the bag with commands as indicated in this post. Could see the results with command rostopic echo -b repaired.bag /dreamvu/pal/get/type_of_room.
Continued with python3.8 -m pip install -r requirements. Although no explicit requirement, grpcio-1.24.1 is uninstalled, which is required by grakn-client. yolov5 install grpcio-1.39.0 instead. Installed grpcio-1.24.1 back.
The command python3.8 detect.py --source data/images/bus.jpg directly works.
Connected the dreamvu camera. With lsusb the camera is directly visible.
Downloaded the DreamVu packages, concentrating on the VIL-ROS-Package for the moment (v1.1).
Followed the instructions of this tutorial. Created ~/dreamvu_ws and builded the turtlebot from the ros_tutorial. Created a dreamvu_pal_camera C++ package and copied pal_camera_node.cpp to src. Build works without problems, so file is not seen yet.
Continued with foxy publish-subscribe tutorial. Modified the CMakelists.txt, and now pal_camera_node.cpp is tried to be compiled. Yet, it breaks on the ROS1 calls.
The original pal_camera_node.cpp makes a spinOnce() call, but in C++ this functionallity can only be called from the executor. Made the following minimal main():
int main(int argc, char** argv)
{
rclcpp::init(argc, argv)
rclcpp::executors::SingleThreadedExecutor executor;
auto pubnode = std::make_shared();
The actual code is in the PublisherNode() class, which currently publish a message (not an image yet).
The code works with executor.spin(), without the topic is not published (but the spin_once is not embedded in a while loop.
Added PAL::Init() to the code, and modified the CMakeLists.txt to include libPAL.so and libPAL_CAMERA.so. Linking now fails on missing libopencv_cores.so.3.4.
Did on nb-ros ldd devel/lib/dreamvu_pal_camera/capture, but also libPAL_DE.so, libPAL_SSD.so and libPAL_DEPTH.so are linked.
Copied the required includes and libraries to /usr/local/. Also added /usr/local/lib to LD_LIBRARY_PATH, so that the Explorer can find all libraries. Still, the initialization fails, because of python dependencies.
The PAL-initialization of the foxy ros-node now works, next would be a Grab(). But, as the Explorer fails to Grab, I will try the tutorial grep example first.
Compiling and linking tutorials/001_cv_png.out works, but running gives an cv::Exception of videoio of OpenCV 4.2. Checking with ldd shows that 4.2 and 3.4 libraries are mixed, while on nb-ros they are all 3.4. Time to create the missing symbolic links in /usr/local/lib. That works, 001_cv_png.out runs, but is unable to initialize PAL camera.
Executing python3.8 -m pip install -r python_requirements.txt, with grpcio downgraded to 1.24.1 and pkg-config removed. Note that it downgrades torh to 1.8.1
Downloading cycler and colcon_zsh takes ages.
Connected the DreamVU, and now I got het PAL_MIDAS_NANO error.
July 28, 2021
Scaled up to a resolution of 5290x1819, and 1 person, 1 potted plant, 1 laptop, 1 vase are detected at home. Yet, the boxes are still drawn in the ceeling, so it looks a drawing issue.
Removed the init and predict from icnet, so I could try yolov5_ros.py now in ~/git/yolov5. Currently, around 0.27s are needed for the inference on the highest resolution (with weights yolov5s.pt).
Running in ~/git/yolov5 works.
Used det[:, :4] = scale_coords(resized_img.shape[1:], det[:, :4], img.shape).round() to get the labels correctly drawn over the image:
Backed this version up as v7.
The comp_ehow is ros-package with NLP interface, but is quite old (2010, ros-fuerte), java-based and requires that a Cyc ontology is installed.
kitchen = wn.synsets('kitchen')
for ss in kitchen:
print(ss, ss.definition())
gave Synset('kitchen.n.01') a room equipped for preparing meals
Checked oven vs kitchen: has a simularity of 0.0833
Wordnet has synsets for the complete list of rooms listOfRooms = ['kitchen', 'living-room', 'bedroom', 'toilet', 'bathroom']
Most objects also have a synset, except [sports ball,
baseball bat,
baseball glove,
tennis racket,
wine glass,
hot dog,
potted plant,
dining table,
cell phone,
teddy bear,
hair drier]
Those are all two word description, so I looked up the last word. That works fine, except that the default descriptions of bat, racket, hot dog, plant, table, bear are not the descriptions one would expect indoors. Still, for the simularity measure it could still work.
Unfortunatelly, the simularity for all objects in "1 person, 1 cup, 1 potted plant, 1 laptop, 2 vases" with the rooms is the same, so the cummulative is for every room 0.646. Also the sentence "1 person, 1 chair, 1 couch and 1 tv" gives the same cummulative for each room (0.536)
Run python3.6 detect.py --source data/images/theta_m15/R0010298.JPG, which gave 1 person, 1 toilet, 2 sinks. Finally a room with another score, because toilet-toilet has distance 1.0
Changed to wup_simularity, but same result. For other simularity measures I should download an information content file first.
The jcn_simularity finally gave other values for each room, although bathroom scored quite low (and toilet-toilet gave 1e+300).
Best behavior for lin_similarity, although bathroom had lowest score (1.0786) and toilet the highest (1.4977) - ic-semcor.dat. Another information content (ic-brown.dat) gave the same order (1.083 vs 1.606). A short description of the information content files is given for wordnet 3.0.
With ic-bcn.dat bathroom is no longer on the last place (living-room 1.06, bathroom 1.10). With ic-treebank bathroom is back to last place (bathroom 1.00, living room 1.049). Based on Shakespear's work (ic-shaks.dat), living-room is last again (living-room 0.94, bathroom 1.00). So British National Corpus, world edition seems the best choice.
The toilet also wins with "1 person, 1 chair, 1 couch and 1 tv"
Tried the reuters and webtext corpus, still the toilet. (creating an ic from a corpus takes quite some time). So, bnc is for the moment the winner.
Removed toilet as room, and person as object. Removed the plural 's'. Still, the kitchen (with "1 person, 1 tv, 1 sink, 1 refrigerator") has not kitchen on top. Time to go rule base.
Made a list of typical labels for each room, and without distinctive objects the type of room is chosen to be the hall.
Also the publisher works fine. Only updating from yolov5s.pt to yolov5x6.pt gives problems with the tensors. yolov5x.pt gives the 2nd time a core dump. yolovl.pt works fine. yolov5l6.pt again has a problem. yolov5m.pt gave after a while a core dump, but works fine the 2nd time. yolov5s6.pt has a problem with tensors.
July 27, 2021
Continue on nb-ros with modifying the icnet_ros script to call yolov5 instead of icnet.
Initiated the camera with source ~/catkin_ws/devel/setup.bash, followed by roslaunch dreamvu_pal_camera pal_camera_node.launch.
Defined export ROS_PYTHON_VERSION=3 and launched python3.6 icnet_ros.py. Fails on missing utils.plot, so continued with creating symbolic links.
At least the downloading of the yolov5 model works. Initialisation is finished, the script fails on the callback (bridge.imgmsg_to_cv2), which is called from python2.7 again.
Trick is to source the other catkin-environment: source ~/catkin_build_ws/install/setup.bash --extend followed by python3.6 icnet_ros.py. That works, although the system freezes if I am using the high-resolution images again. Checking with rosrun image_view image_view image:=/dreamvu/pal/get/left showed a low resolution (with still the non-default EQUI_RECTANGULAR perspective).
Renamed my script yolov5_ros.py and copied the original icnet_ros.py back, the script goes no further after icnet ros init succesfully. Trying python2 icnet_ros.py. That is not stramge, because it weights on the cv_camera. With the dreamvu camera and the right INFER_SIZE it works for a while (followed by an core dump).
The command python3.6 yolov5_ros.py works now fine, running 3.72 fps, although it only initializes yolov5, and still calls icnet for inference.
Yolov5 makes a tensor from a numpy array, but I have a opencv img, so I should use from_blob(). Yet in the recent documentation I only see from_buffer() and from_float(). Converting it with numpy_img = np.asarray(img, 'float32') first seems to work (no complains on the yolo preprocessing).
Calling the model I got the error Sizes of tensors must match except in dimension 1. Got 2 and 1 in dimension 3 (The offending index is 2), so applied the transpose as suggested in this post. Still, same warning.
Saved the opencv img to file and read it again (to be save), and performed the transpose as used by yolov5 after a read. That seems to work.
Printed the result. Now reports for the ros image-stream in the II demonstration lab: Image: 1 person, Done (0.155s).
Tried to show some pictures on the large screen, but the frequency collided. Sometimes it sees a suitcase, even 2 cows. Showed the computer, but not recognized as TV. The chair is also not recognized.
Increased the resolution to 1322x454. Now also a laptop is recognized.
Cleaning up code, save intermediate version in backup.
My nb-ros is unstable, sometimes freezes so that I have to reboot.
Moved to nb-ros. Tried roslaunch dreamvu_pal_camera pal_camera_node.launch, which fails on an Attempt to unload library that class_loader is unaware. Because the PAL_PYTHON libray is python3.6, I switched /usr/bin/python3 back to python3.6. That gave again the netifaces error, which I solved with python3.6 -m pip install netifaces==0.10.9 (because netifaces==0.10.4 was already part of ros-noetic, so didn't want be installed).
Installation was hard anyway (including apt-get update), because apt_pkg could not be loaded, and sudo apt-get install python3-apt --reinstall didn work. At the end, cd /usr/lib/python3/dist-packages/;ln -s apt_pkg.cpython-38-x86_64-linux-gnu.so apt_pkg.so repaired this. Still, roslaunch dreamvu_pal_camera pal_camera_node.launch doesn't work on nb-dual
The command set cv_camera/device_id 0; rosrun cv_camera cv_camera_node also doesn't work on nb-dual, because device_id0 cannot be opened. On nb-ros the same command works fine. Yet, also cheese cannot find any device on nb-dual.
Installing sudo snap install vlc # version 3.0.16 on nb-dual. Also here the list of devices is empty. So back to nb-ros.
Now return the images with the predictions. The person and chair are detected in the ceeling. That could be the low resolution, or not correct cropping / drawing of the images. Could scale up the resolution, or store this image and see what detect.py finds.
I could try pal_camera_node with the 3.* opencv bridge libraries.
July 23, 2021
Testing if rosrun image_view image_view image:=/dreamvu/pal/get/left/image_raw started working yesterday because of the timestamp added to the message. Commented this line out, and rebuild the node.
Node is killed because not all classes could be loaded. (starting this morning with a reboot, and continue installing missing packages to be able to build all packages in my catkin_ws).
Testing with python3 main1.py. Complained that the camera was not connected (while I connected via an USB-hub). When I directly connected the camera it works again. Now roslaunch dreamvu_pal_camera pal_camera_node.launch also works. Fortunatelly or unfortunatelly, also rosrun image_view image_view image:=/dreamvu/pal/get/left/image_raw works, so it is not the timestamp.
Moved my modified version to ~/projects/TNO and unzipped the original package into catkin_ws. Copied my pal_camera_node.launch in the original package, and to my surprise now image_view also works for the original package! Note that this was not the case on July 21 and July 2 (also on nb-ros). On May 7 I tried rosrun image_view image_view image=/dreamvu/pal/get/depth on the Jetson. This view now also works on nb-ros (although quite slowly!). Not clear what the change is that makes the view now working while it didn't work before. No major changes in this week, as far as I can see.
All catkin packages are now build, including voxblox_ros.
Try to calibarate with a larger checkerboard (50mm squares). First with the webcam. Starting rosparam set cv_camera/device_id 0; rosrun cv_camera cv_camera_node. Calibrating with rosrun camera_calibration cameracalibrator.py --size 11x8 --square 0.050 image:=/cv_camera/image_raw camera:=/cv_camera works fine. There is a small difference between the 31mm calibration and 50mm calibration.
Running rosrun camera_calibration cameracalibrator.py --size 11x8 --square 0.050 image:=/dreamvu/pal/get/left gives no recognized chessboard squares (also not in fisheye mode).
Added this code-snippet before GrabFrames:
PAL::CameraProperties properties;
unsigned int flags = PAL::PROJECTION;
properties.projection = PAL::EQUI_RECTANGULAR;
PAL::SetCameraProperties(&properties, &flags);
Also with EQUI_RECTANGULAR projection the chessboard squares are not recognized.
Back to python3.6 icnet_ros.py. Fails on missing rospkg.
Instead do python2 icnet_ros.pY, which seems to init succesfully. Waits on rosparam set cv_camera/device_id 0; rosrun cv_camera cv_camera_node. icnet_ros script fails on wrong resolution. Subscribe to dreamvu image. Fials on (1819, 5290, 3) vs '(1218, 3544, 3)' (standard pal_camera_ros cannot find the current resolution settings.
Put a file on the default location ~/catkin_ws/src/dreamvu_pal_camera/src/SavedPalProperties.txt. With resolution 3544x1218 the icnet_ros script warns about memory usage (above 10%) and although the detection is running the responsiveness was so low that I had to reboot. With resolution 660x227 both in the script and SavedPalProperties.txt the responsiveness is good (and no warnings).
Continue with calling the yolo detector from the icnet_ros framework.
Added the additional imports. Installed python2 -m pip install pathlib. Tried python2 -m pip install torch>=1.7.0. That fails. python2 -m pip install torch torchvision --user installs torch v1.4.0 and torchvision 0.5.0. Fingers crossed that this will be enough. No, there is no alternative for builtins. Looked if I could solve the rospkg problem in python3 with sudo apt-get install python3-catkin-pkg-modules. Problem is solved with sudo apt-get install python3-rospkg-modules, thanks to this post.
Still python3 icnet-ros.py fails on cv_bridge_boost, which is called from python2.7, from python2/rospy/topics.
Followed the instructions from this post, and explicitly defined export ROS_PYTHON_VERSION=3.
Following the instructions of this post, which describes precisely my problems with cv_bridge. That trick works. No problems with cv_bridge anymore, although cv2.resizeWindow is still called from python2/rospy/topics. Made the whole vision_opencv stack, because that should contain the whole interface for interacting with OpenCV from ROS. Still, cv2.resizeWindow fails.
Read the cv_bridge tutorial. The other cv2 calls work fine, so just commented out the resize and the script works fine.
July 22, 2021
The DreamVu PAL camera should not only publish an image_rect_color image (left and right), but also for each side a CameraInfo message, so that the image processing pipeline could do its work. The parameters in the CameraInfo message are described in the ROS wiki. They recomment to use image geometry package when performing operations on this info.
A subset of this information can be queried from the DreamVU PAL camera:
The timestamp can be found in the Camera Structure.
height, width from Resolution
distortion_model is a string, so could be used for Projection (equi-rectangular vs perspective).
For stereo images the Rectification matrix is the most important. For the DreamVu it should be 22.5° rotation around the Z-axis.
The cv_camera_node is publishing camera_info, and tries to lead the camera calibration from ~/.ros/camera_info/camera.yaml
There is a tutorial for Monocular camera's and Stereo Camera's. My calibration checkerboard of 7x5 with 0.031 mm squares, which could be easily parametized to the camera_calibration script with the parameters --size 7x5 --square 0.031:
The calibration was succesfull, but not clear if the result was saved. Copied the printed information into ~/.ros/camera_info/webcam.ini. Converted the ini-file with rosrun camera_calibration_parsers convert webcam.ini camera.yaml. Information seems to be enough, because cv_camera can now read the ~/.ros/camera_info/camera.yaml (after changing the name from [narrow_stereo] to [camera].
Looked in the code of cv_camera. The camera_info is loaded in the loadCameraInfo function, which makes use of #include camera_info_manager/camera_info_manager.h. This information is used to rescale the image, using height, widht, K[0],K[2],K[4],K[5], P[0], P[2], P[5], p[6]. Both the image and info is published in on function call, making use of the image_transport.publish(). The information is the acquired from info_manager_.getCameraInfo(), with only the stamp and frame_id overwritten.
Found also a good C++ example to publish camera_info. Looked at the original pal_camera_node.cpp, and noticed that publishpicture-function doesn't update the stamp / frame, and that it converts to the color-images to 3-channel CV_8UC3. The "mono8" or "mono16"-encoding is not used.
Made a version of pal_camera_node.cpp which also publishes camera_info messages (although the matrices are still zero). The published topics are now:
/dreamvu/pal/get/depth
/dreamvu/pal/get/left/camera_info
/dreamvu/pal/get/left/image_rect_color
/dreamvu/pal/get/openni_depth
/dreamvu/pal/get/point_cloud
/dreamvu/pal/get/right/camera_info
/dreamvu/pal/get/right/image_rect_color
Run the command rosrun camera_calibration cameracalibrator.py --approximate 0.1 --size 7x5 --square 0.031 right:=/dreamvu/pal/get/right/image_rect_color left:=/dreamvu/pal/get/left/image_rect_color right_camera:=/dreamvu/pal/get/right left_camera:=/dreamvu/pal/get/left, but this fails on Waiting for service /dreamvu/pal/get/left/set_camera_info ....
Used the ros-melodic trick to run without camera_info service: rosrun camera_calibration cameracalibrator.py --approximate 0.1 --size 7x5 --square 0.031 right:=/dreamvu/pal/get/right/image_rect_color left:=/dreamvu/pal/get/left/image_rect_color -c dreamvu_pal_camera. Switched to fisheye model, but the image is not sharp enough to recognize the chessboard corners:
Converted the topic back to image_raw and did ROS_NAMESPACE=dreamvu/pal/get rosrun sreo_image_proc stereo_image_proc. Yet, I receive the warning:
[ WARN] [1626966317.897459670]: [image_transport] Topics '/dreamvu/pal/get/right/image_color' and '/dreamvu/pal/get/right/camera_info' do not appear to be synchronized. In the last 10s:
Image messages received: 150
CameraInfo messages received: 150
Synchronized pairs: 0
Yet, I noted that the timestamp was not set in the original pal_camera_node.cpp, so look what happens if I add this timestamp.
Also with this timestamp nothing happens. Yet, rosrun image_view image_view image:=/dreamvu/pal/get/left/image_raw gives a responsive video-stream:
July 21, 2021
The cv_bridge from /opt/ros/melodic on nb-ros is linked to opencv .3.2 libraries.
Copied the relevant files from lib, include, share from nb-ros to nb-dual.
Modified ~/catkin_ws/build/dreamvu_pal_camera/CMakeFiles/capture.dir/flags.make. Now I get warnings about missing libopencv_imgcodecs.so.3.2, needed by /opt/ros/melodic/lib/libcv_bridge.so (try using -rpath). In addition, I got errors on libboost. Not that the version installed by dreamvu is v3.4.4.
Moved to nb-ros. Installed yolov5. Did sudo apt-get install python3-pip, python3.6 -m pip install --upgrade pip (to prevent an error with skbuild) and python3.6 -m pip install -r requirements.
Again, no problems here, python3.6 detect.py --source data/images directly worked.
Copied my modifications on detect_ros.py. Fails on missing rospkg.
Installed python3-rospkg, but that removes many ros-packages.
Installed ros-melodic-rospy, which removes python3-rospkg.
Had to update my the ros gpg key, but on nb-ros I get an invalid argument. Did it again on nb-dual, and saw that it was signed by info@osrfoundation.org.
With this email adress you can look it up in keyserver.ubuntu.org. Clicked on the pub key and copied the whole PGP block to a file, which I added with sudo apt-key add ros.key. That worked.
The imports of detect_ros.py work now, time to add some functionality.
Streams are loaded around line 88. Will make a LoadRosTopic() class with the same structure as LoadSteams() and the example of icnet_ros.py
It seems that the pretrained models contain 80 classes, which corresponds with data/coco.yaml, which are shown in Custom Data tutorial. From those 80 classes you could expect 61 indoors.
names: [ 'person', 'bicycle',
'bench', 'bird', 'cat',
'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ] # class names
The LoadStream starts multi-threads in the init, and reads 'i' frames in the update functions.
Maybe easier to replace the ImagePredict of icnet_ros with a single yolov5 prediction.
Reinstalled sudo apt install ros-melodic-ros-base and started roscore.
Sourced ~/catkin_ws/devel/setup.bash and started roslaunch dreamvu_pal_camera pal_camera_node.launch. Image transport was missing so did sudo apt-get install ros-melodic-image-common. With rostopic it can be seen that the dreamvu images are published.
Called python3.6 icnet_ros.py, which fails on missing tensorflow. Installed this with python3.6 -m pip install tensorflow==1.8 (instead of v2.5.0). The program starts, although with the same TensorSlice error as July 2.
Switched the model back to CityShapes. Now the code fails on cv_image = self.bridge.imgmsg_to_cv2(data), where the dynamic module does not define function (PyInt_cv_bridge_boost). Note that the rospy calls are handled by python2.7.
Started rosparam set cv_camera/device_id 0; rosrun cv_camera cv_camera_node, but same error.
Yet, rosrun image_view image_view image:=/cv_camera/image_raw works, while nothing happens with rosrun image_view image_view image:=/dreamvu/pal/get/left (not even a crash). Strange, because rostopic hz /dreamvu/pal/get/left that the images are published with enough speed.
The nodelet can be started with rosrun image_view image_view image:=/cv_camera/image_raw. Modified the pal_camera_node.cpp, so that /dreamvu/pal/get/left/rect_color and right/color are published. That would allow to use rosrun image_view stereo_view stereo:=/dreamvu/pal/get image:=rect_color, although I should also publish /dreamvu/pal/get/disparity.
Created a version that publishes disparity messages, but there is a discrepancy between the intended stereo_msgs/DisparityImage and sensor_image/Image. See also this discussion. There is stereo_image_proc which could generate Disparity images as expected by ros, although in that case camera_info from both left and right are needed. The depth_image_proc can convert depth images to disparity images (and disparity view can colorize them.
Checked with ptpcam --list-devices, but the DreamVu Pal-camera is no PTP device.
The Theta m15 is recognized as ptpcam device, but ptpcam --list-devices could not open a session to request the vendorID/prodID.
The Luxonis OpenCV 3D-camera is also no ptpcam device, nor the Structure, Asus Psion, Softkinetic DS325 or Intel RealSense D435.
Run on nb-dual python3.8 detect_ros.py, which runs a detection in the two images in data/images.
Continued with adding code-snippets of icnet_ros.py. Could not only load rospy and sensormsgs, but also load cv_bridge without problems.
Note that yolo5 detect could already subscribe to rtsp://, so could also process the video-stream of the Theta Z1 when it is wifi-mode.
At the end I should be able to do python3.8 detect_ros.py --source image:=/camera/image or python3.8 detect_ros.py --source image:=/dreamvu/pal/get/left, but on July 2 I had still problems with raw transport.
Starting rosrun cv_camera cv_camera_node doesn't work because there is no /dev/video0 (due to my kernel modification for the Theta Z1?).
Used the command catkin_make -DCATKIN_WHITELIST_PACKAGES="" to build all packages. The dreamvu_pal_camera package was still pointing to the PAL-mini directory, so modefied CMakeLists.txt directly. Compiling goes well, linking gives a conflict between libopencv_imgcodecs.so.4.2 with libopencv_imgcodecs.so.3.4 (See also May 28), due to the dependencies of /opt/ros/noetic/lib/libcv_bridge.so.
Made a copy of /opt/ros/noetic/share/cv_bridge/cmake/cv_bridgeConfig.cmake into PAL_Firmware-v1.2-Intel-CPU/cmake_template, and modified catkin_cmake/src/dreamvu_pal_camera/CMakeLists.txt that this Config is loaded (with list(APPEND(CMAKE_MODULE_PATH PAL_Firmware-v1.2-Intel-CPU/cmake_template)) Still warnings, but the package is build.
Tried roslaunch dreamvu_pal_camera pal_camera_node.launch, which starts but crashes on class_loader.
Checked with ldd catkin_ws/devel/lib/dreamvu_pal_camera/capture. All libraries are found, but both 3.4 as 4.2 are loaded.
July 19, 2021
Repeated the instruction of this tutorial on nb-ros (Ubuntu 18.04, ros-melodic).
The theta z1 is assigned to /dev/video2. The gst_viewer responds impressive quickly.
Made also the cv_camera in my catkin_ws by using catkin build cv_camera. Had to install sudo apt-get install ros-melodic-camera-info-representation first.
With the webcam cv_camera gives a fast video, but with rosparam set cv_camera/device_id 2 the system again comes to a hold.
As I found out in the video, the gst_loopback is symbolic link to the modified gst_viewer, but when called with this name it creates another video pipe than when called as gst_viewer. In principal the video stream is send to a v4l2sink, which should display the theta live stream on /dev/video0, and should also be visible with a viewer like vlc.
Tried it (the theta is now on /dev/video1, but for both devices I receive v4l2 stream error: cannot open device: Operation not permitted. Solved this thanks to this post with snap connect vlc:camera :camera.
vlc is now able to stream my webcam, but for /dev/video1 it shows a frozen image. Could look at the middle part of the pipeline, to see if the autovideoconvert or video format make a big difference.
Downloaded the ptpcam code in ~/svn. Had to install libusb-dev, but after that it seems to work. Could see the camera when I do ptpcam --list-devices, and see the properties with ptpcam --list-properties. When I did ptpcam --show-property=5003 while in Live mode I receive Device busy, but when I switch to Camera mode I receive 'Image size' is set to: "6720x3360". Property seems not to be setable. ptpcam -o shows paossible operations. ptpcam -c captures an image, ptpcam -L list the files on the camera, ptpcam --get-file=HANDLER downloads the file (ptpcam --get-file=0x00000017 worked, while ptp -g=0x00000017
not.
July 16, 2021
Unpacked the Theta Z1. Connected to my nb-dual. According to dmesg | tail the device is recognized and assigned usb 3-4.3. Yet, I don't see a new camera in the list ls /dev | grep video.
Activated sudo modprobe v4l2loopback, as suggested in tutorial, but no change, and dmesg | tail reports Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7.
According to post, it is a UEFI secure boot protection. The file /proc/sys/kernel/sysrq contained first number 176, but now 177. The file /proc/sysrq-trigger didn't exist. Trick seems also to work no longer.
At the sudo apt update I got a screen to configure my secure boot. Created a password. After that, there are no longer cameras available (empty list ls /dev | grep video, which means that also the webcam is gone).
Running sudo modprobe v4l2loopback gives nos modprobe: ERROR: could not insert 'v4l2loopback': Operation not permitted.
Switched to the Aaeon board. When connected to the hybrid USB-2, the camera doesn't show up on lsusb, and I couldn't activate the Live mode on the camera itself. Once connected to the USB-3.0 connector of the Aaeon board, I could select the Live mode and device is visible from lsusb.
Node that during make install in v4l2loopback, I receive the warning that no certs/signing_kep.pem could be found (but I can safely ignore this warning).
Now, after sudo modprobe 4vl2loopback, the device /dev/video0 shows up.
Had to install sudo apt-get install libuvc-dev to get the ./gst_viewer working. There is quite a lack of more than I minute in the video stream.
Continue with the cv_camera. Had to install sudo apt-get install ros-melodic-roslint
Would be interesting to see if the Ricoh Theta Z1 could give 360 images that are easier to grab with a ROS-interface. Reserved the Z1 for this Friday.
Followed the instructions of tutorial and build in ~/catkin_ws the cv_camera and theta_z1 packages on nb-dual with Ubuntu 20.04 and ros-noetic. The v4l2loopback created four /dev/video* devices. In gst_viewer.cc I selected /dev/video0. When running the modified gst_viewer I received the output THETA not found. The ros cv_camera nodelet nicely showed my integrated webcam stream.
When selecting device_id 2, I receive the IR stream of my XPS (two red lights are blinking).
The DreamVU was not seen as device (or it should be /dev/media0
The older Theta m15 is not seen as uvc device.
Yet, I run yolov5 on previous recorded shots. In the living room (near the door), I detect 1 person, 1 chair, 1 couch and 1 tv (with --weights yolov5x6.pt. In the kitchen (low viewpoint) it detects 3 TVs (cabinets at the wall). In the bathroom 3 sinks are detected. The sink is actually detected both on the left and the right, with oval mirror above as understandable false positive. In the music storeroom the three stacked Marshall speakers are seen as a refrigerator. In the children room 1 chair, one bed, 1 tv are recognized. In the parent bedroom only 1 bed is recognized. In the toilet 1 toilet is recognized (too low to recognize the sink).
Run the previous versions and compared the speeds yolov3-tiny needs for inference 0.249s, yolov5s6 0.263s, yolov5m6 0.335s, yolov5l6 0.461s, yolov3 0.494s, yolov3-spp 0.506s, yolov5x6.pt 0.699si (all on the 3584x1792 JPG from the Theta m15).
July 13, 2021
The USB-C to USB AB connector doesn't work, still get a device descriptor read/64, error -71 and usb ssb1-port: attempt power circle.
Also with the USB-AB to USB-B adapter, the DreamVU camera is not recognized by the Aaeon board. The problem seems to be in the wiring of the cable, USB-AB is configured as to be a device, not a host.
July 12, 2021
Found a USB 3.0 micro AB cable, but that was not enough to power the Aaeon board (CPU kept running, but shutdown when I was using the mouse).
Connected the Aaeon to the Robolab, and solved the the ros GPG key problem.
In the background the automatic upgrade was hanging, so should not forget to do sudo dpkg-reconfigure -plow unattended-upgrades again.
Updating 800+ packages, including ros-melodic and ros-dashing.
Finishing the rest of the install script of DreamVU. Rebooted and tried the Explorer, but that fails on Camera Data not available. Installed the PUM.zip, removes the CameraData error, but still the Camera initialization failed.
Problems seems to be the USB 2.0 ports. With dmesg | tail, I see that with the hybrid connector there are an attempt to associate, but the TX power is limited. On the other ports the device is not abble to respond to the USB device. Ordered a micro AB cable to USB-C (USB 3.1). The cable is rated uptil 2A. The DreamVu rated current is 500 mA. Hope that the USB-C parts fits.
July 10, 2021
Found at home a 5V DC-in @ 3A 5.5/2.1mm jack, which also provides enough power for the Aaeon Up board, even when the DreamVU camera is attached.
Board has an USB3.0 micro type AB connection, so I could finally use that cable from my work (higher speed).
The ICNet-tensorflow still works with the cityshapes model, although I receive a warning that the shape cannot be divided by 32, so it is padded to (1248, 3552). I also receive a warning that allocation of 328060992 exceeds 10% of system memory.
Modified the code that s now also use the ake20k dataset, but still no match can be found in ./model/ade20k/model.cpkt-27150.
Running python demos-ade20k.py. This call also fails, but with another ArgumentError:
Assign requires shapes of both tensors to match. lhs shape= [128] rhs shape= [256]
[[Node: save/Assign_151 = Assign[T=DT_FLOAT, _class=["loc:@conv3_sub1_proj_bn/beta"], use_locking=true, validate_shape=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](conv3_sub1_proj_bn/beta, save/RestoreV2:151)]]
In icnet_ros, the call is self.net.predict(img).
Modified yolov5/detect.py to detect_ros.py. Added import rospy; from sensor_msgs.msg import Image, but this fails although ros-noetic-rospy is already installed. Running source ~/catkin_ws/devel/setup.sh solves this for python3.8 detect_ros.py --source data/dreamvu/kitchen/left.png.
Could add ros as protocol to webcam, by defining startswith('image:='), in the same way as image_view.
Could not start roscore on nb-dual, because netifaces is not known to python (see June 2). Changed the link of python3 from 3.6 to 3.8. Now roscore works.
Started rosrun libuvc_camera camera_node, which fails on permission denied on /dev/bus/usb/003/004.
Changed udev rules, but that fails for the moment. Changed permision of bus with chmod. Now I receive unsupported mode.
Tried to do roslaunch webcam ros-xps-webcam.launch, but webcam is not kwown as package yet (although part of webcam_ws/src. Unfortunately, catkin make hangs on dreamvu camera.
Got an Aaeon Up board, which is used to control one of the TNO's Traxxas Rustler 4WD racers, which is controlled with a PixHawk controller. The board is powered by a 5V DC-in @ 4A 5.5/2.1mm jack.
That board has as Ubuntu 18.04. Downloaded the DreamVU software and unpacked in ~\packages. Started with the installation ./opencv.sh.
Did python3.6 -m pip install -r requirements.txt.
That fails. Try the standard setup_python_env.sh. Fails on bytearray of tensorflow==2.3.1.
There exists a variation of BlitzNet, which configures BlitzNet as student, which two teachers; Faster R-CNN (object detection tutor) and Mask R-CNN (semantic segmentation tutor).
They not only point to scene reconstruction work, but also omnidirectional SLAM.
The recent code is for outdoor usage (trained on CARLA).
I found Matterport3D: Learning from RGB-D Data in Indoor Environments, which is a panoramic dataset for region-type classification. Their Table 5 shows that the classification improves a lot when using panoramic images, compared to single images. They are not specific on their classification algorithm, other than ResNet-50 based. The code of the region classification can be found on github. A machine with GPU is needed, so I first have to repair my workstation.
July 7, 2021
Could also look at CenterNet, which claims to have a very good speed-accuracy trade-off. Code is available on github. It also has Lidar based extension CenterPoint (2nd in the Waymo Real-time 3D detection challenge).
July 5, 2021
Modified the PROPERTIES_FILE_PATH to another location (~/catkin_ws/src/dreamvu_pal_camera), and reduced the RESOLUTION_WIDTH and HEIGHT to (3544, 1218).
Now python icnet_ros.py works (with INFER_SIZE = (1218, 3444, 3)), although with the cityshapes model:
Judith Dijkman used NIR for the detecting of drowning people.
July 2, 2021
The new SPOT backback will be called SnowGirl.
Impressive new framework for semantic object tracking. Seems to be validated on vehicle datasets, not indoors.
On nb-dual, Ubuntu 20.04 partition, I could grep a DreamVu image with python main1.py in the dreamvu_ws environment.
Cloned ICNet-tensorflow, which has a nice example of a coupling of a CNN with ros kinetic in icnet_ros.py. The main module of the icnet_ros_node subscribes to topic /camera_array/cam0/image_raw, builds a bridge to opencv, and shows the image with the predictions.
Went to the catkin_ws workspace. Run roslaunch dreamvu_pal_camera pal_rviz.launch failed on missing netifaces. Installed that package with python -m pip install netifaces, but ros noetic uses another version of python.
Did an experiment in the kitchen. First a shot on Spot (60 cm), then with the SpotBoy backpack (58cm + 20 cm), followed by a Coffee tube on top (58 + 20 + 20cm = 98cm). Only on top of the Coffee yolov5 was able to recognize a microwave, refrigerator and sink. Strange enough, my laptop was seen as sink (are the classification correlated?).
Followed the instructions from pip user installs and installed netifaces for ros with export PYTHONUSERBASE=/opt/ros/noetic/lib/python3/;sudo python3 -m pip install --user netifaces --ignore-installed. Claims that netifaces-0.11.0 is installed, but not in opt/ros/noetic/lib/python3, nor /usr/lib/python3/dist-packages, /usr/lib/python3.6, ./local/lib/python3.8/sit e-packages nor ./.local/lib/python3.6/site-packages.
Moved to nb-ros. catkin_make fails, because catkin_ws is last build with catkin build. catkin build can build dreamvu_pal_camera, with 2 warnings on the version of opencv (3.2 vs 3.4).
The command roslaunch dreamvu_pal_camera pal_rviz.launch starts, but node dies on PAL_MIDAS_NANO.cpp (assertion m_pModule failed). Same error on June 3. Activating the dreamvu_ws environment helped. Now rviz shows a live camera feed. While making a screenshot my laptop nb-ros went black. Rebooted, and tried again. Also without screenshot my laptop goes blank.
Made a launch file pal_camera_node.launch with only the camera_node
The camera publishes several topics, including /dreamvu/pal/get/left. Tried rosrun image_view image_view image:=/dreamvu/pal/get/left, but only receive message using transport "raw".
Modified icnet_ros.py from ICNet-tensorflow-ros. Is build for kinetic, which I now use for melodic. Fails on missing rospkg.
First had to do sudo apt-get install python-pip, followed by python2 -m pip install tensorflow==1.8. Also installed scipy (v1.2.3).
The command python icnet_ros.py fails on missing ./model/cityscapes/. Luckely, there is the command python script/download_weights.py --dataset ade20k.
How to choose the model is indicated in demo-ade20k.py:
model_type = 'trainval_bn'
model_weight = './model/ade20k/model.ckpt-27150
The script now fails on Unsuccesfull TensorSliceReader 'Failed to find any matching files for ./model/ade20k/model.cpkt-27150'. Maybe I should adjust the INFER_SIZE. Adjusted the size to (5290,1819,3). Same error.
Downloading the cityscapes model. With this model I get the error cannot feed value of shape (1819, 5290, 3) to Tensor with shape (5290, 1819, 3).
Program runs, but I receive the warning 'Allocation of 79347712 exceeds 10% of system memory'. Should modify PROPERTIES_FILE_PATH in pal_camera_node.cpp
June 29, 2021
Tried room1 with yolov5x6: (2 persons, 1 umbrella). The print on the back of my laptop is seen as umbrella. Strange that I haven't seen door as object yet.
The hall, before room2, on spot, only (1 person) is detected (with yolov5x6).
Unfortunatelly, also in the kitchen only my laptop was seen as TV, nothing kitchen related (1 person, 3 chairs, 1 tv)
At least in the parents bedroom, a bed is recognized (1 person, 1 chair, 1 bed, 1 tv, 1 laptop).
Also the children bedroom, the bed is recognized (1 person, 1 chair, 1 bed).
With yolov5l6 the chair nearby is recognized (1 person, 4 chairs).
June 28, 2021
Did an autoremove to create some space at the workstation, but as a result no old kernel options are available anymore.
Doing a do_release_update to go from kernel 5.4 (Ubuntu 20.4) via 5.8 to 5.11 (Ubuntu 21.4)
Still no response on the keyboard or mouse.
On my nb-dual, I installed yolov5 without problems under python3.8.
The detection on the example data/images/bus.png worked fine:
Also tried it on the dreamvu recording in the living before the door. Two objects were detected (1 person, 1 bed), myself as person and the top of the waistbin as bed. That would have resulted in a classification as bedroom.
Yet, first tried the other pretrained model. With --weights yolov5x.pt (2 persons, 2 backpacks, 1 chair, 1 sink, 1 clock) also the other person in the room could be found, the waistbin is now a sink, but now also the clock, chair and backpacks are recognized. The classification would be the kitchen now!
With --weights yolov5x6.pt (2 persons, 1 backpack, 1 chair, 1 bed, 1 tv, 1 clock) another part of the waistbin is now classified as bed, and the door as TV!
With --weights yolov5l6.pt and as input the scene before the couch, (3 persons, 3 chairs, 1 couch, 2 tvs) are recognized. Clearly a living room!
Next I try the hallway before the kitchen, but I only receive (2 persons, 3 chairs) (tried weights yolov5m and yolov5m6). Didn't find a recording inside the kitchen.
June 27, 2021
Installing ICNet-tensorflow-ros on my workstation with GPU, which run Ubuntu 20.04. Did python2 -m pip install googledrivedownloader, followed by python2 script/download_weights.py --dataset=ade20k to get the trained model for the ADE dataset.
Did python2 -m pip install tensorflow-gpu==1.8.0, but running python2 demo-ade20k.py showed that I was missing libcublas-dev-9-0. That one is not available for Ubuntu 20.4.
Went to the cuda-toolkit archives and downloaded the package (1.2 Gb).
Had to clean up my /tmp, because my system was full.
Install some other packages, but cuda fails on kernel version mismatch. Try a reboot.
After the reboot, the computer no longer responds to keyboard or mouse.
Firebots now uses karto SLAM, instead of gmapping. A comparison between those two algorithms is made in this paper.
Another comparison, with an UTM30LX laserscanner, is this 2019 paper.
June 26, 2021
This Bsc thesis describes the controversy between YoloV4 and YoloV5 quite good. In contrast of what the name suggests, both algorithms are not from the same author, and are developed independently from YoloV3. Yet, YoloV5 was developed by a company, which didn't publish its result. Still, YoloV5 is popular because it is more than competitive and python based. To add to the confusion, YoloV5 itself has multiple versions and models, and is given a doi via Zenodo.
There are two scripts in ICNet-tensorflow-ros, one to download the data and one to download the model. Did python2 -m pip install googledrivedownloader, followed by python2 script/download_weights.py --dataset=ade20k to get the trained model for the ADE dataset.
Run python2 demo-ade20k.py but that failed on non-matching tensors. Yet, I had replaced the input image (but not yet the input size), so first tried it on the original ./data/input/ladybug1.png. Strange enough, the ladybug image is not part of the repository, nor present in one of the other repositories.
The ICNet-tensorflow had 4 examples images. Tried with ade20k.jpg (256x256), but still two errors:
2021-06-26 15:14:42.487507: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 AVX512F FMA
InvalidArgumentError (see above for traceback): Assign requires shapes of both tensors to match. lhs shape= [128] rhs shape= [256]
[[Node: save/Assign_151 = Assign[T=DT_FLOAT, _class=["loc:@conv3_sub1_proj_bn/beta"], use_locking=true, validate_shape=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](conv3_sub1_proj_bn/beta, save/RestoreV2:151)]]
Should try this with tensorflow-gpu==1.8.0.
June 25, 2021
Looked at segmentation labeler, which works great in the webbrowser, but doesn't seem to have automatic segmentation.
According to this Arxiv paper, segmentation of panoramic images is harder.
The code with Arxiv paper is actual only the dataset (and cylindric conversion). Dataset is more usefull for autonomous driving. The segmentation network applied is ICnet
Of ICnet there is also a ros implementation. The script/download_ADE20k.sh works, which should give a good trained model for this task. The model is trained for 150 semantic categories included for evaluation, which include stuffs like sky, road, grass, and discrete objects like person, car, bed.
Should try to run python3 demo-ade20k.py on left.png. The demo script says python3, although the configuration says python2.7, ubuntu 16.04, tensorflow 1.8 and ros kinetic. Without version pip3 installs tensorflow 2.5. Also needed cv2, so did python3 -m pip install opencv-python-headless. That installs v4.5.2.
Script fails on tensorflow has no attribute placeholder.S Could be the version, could that tensorflow-gpu is needed. Should also not forget to set INFER_SIZE correclty.
The placeholder is a known issue between v1 and v2. Yet, tf.disable_v2_behavior() no longer works for v2.5. The lowest stable version for python3 seems tobe 2.2.3, so I try if disable_v2_behavior exists for this version. Should have used tf.compat.v1.disable_v2_behavior() for v2.5 (see documentation). Also with tensorflow 2.2.3 and disabled v2_behavior, there is no placeholder.
Installing python2 -m pip install tensorflow==1.8.0. Now it seems to work, it only fails to load ./model/ade20k/model.ckpt-27150, which I didn't download yet.
June 24, 2021
Nvidia released a new version of their simulation environment Isaac-Sim, including ROS2 support, multi-camera support and ground truth on bounding boxes and segmentation.
The Colorado School of Mines has nice video of a Spot robot exploring an old mine.
Interesting Forest navigation talk by Patrick Wolf. Page 212 in proceedings.
Google Research published DeepLab2, a state-of-the-art panoptic segmentation framework.
June 22, 2021
Installed the ros-tool VoxBlox on nb-ros, which has ros-melodic. Had to rename both build and devel because those directories were build with catkin_make
Make failed on missing pcl-conversions, so did sudo apt-get install ros-melodic-pcl-conversions, which installs several other packages. Installation fails on non-configured libpcl-dev (which is actually already installed). Previous install asked for a reboot, so try this first.
Did several attempts to remove the conflict, at the end with sudo dpgk -P libopenni0. Instead of pcl-conversions, I installed the whole package with sudo apt install ros-melodic-perception-pcl. That worked, the catkin build completes succesfully (although two catkin directories were ignored).
June 18, 2021
The results are now evaluated and rendered the Atlas with python3.6.
The result is the same print of performance metrics, although results/release/semseg/test_final contains for each scene a txt, three ply, a json and two npz files. The ply are the mesh-files, the npz contains the tsdf. The _attributes.npz should contain the semseg vertex.
The mIOU performance metric is not printed, because the semantic label head is not activated. The SemSegHead class can be found in atlas/heads3d.py and is appended when "semseg"is in the cfg.MODEL.HEADS3D. The HEADS3D is now specified as "tsdf", changed it to "semseg" ("color" was the third option).
Installed python3.8 -m pip install scikit-image==0.17.2 and started python3.8 --model results/semseg/final.ckpt --scenes .../atlas/meta/sample/sample1/info.json --voxel_dim 208 208 80 (the default voxel_dim is for training [160, 160, 64], validation [256, 256, 96] and testing [416 416 128]). On my workstation with a GTX 1080 --voxel_dim 256 256 96 also works, while --voxel_dim 320 320 128 fails, as --voxel_dim 280 280 112 and --voxel_dim 272 272 104. The --voxel_dim 264 264 96 works again!
tsdf can be visualised by the ros-tool VoxBlox. But there exist also npzviewer for python.
npzviewer fails to run under python3, on MainWindow has no attribute keysCombo. Tried both python3.6 and python3.8. python2.7 has no support for pyqt5, the unofficial wheel python-qt5 fails. Tried downgrading from v 5.15.4 to pyqt5==5.14.2 ... 5.12.3. v5.9.2 and v5.10.1 give a different error (No module named sip, while sip is installed). Removed python3-sip, installed sip==4.19.8, keysCombo error is back. Removed the offending lines from ~/.local/lib/python3.6/site-packages/npzviewer. Now the npz file is loaded, but only a textual summary is given (no 3D visualisation):
With the inference with the SemHead, the ply, npz and attributes.npz are overwritten, the metrics, transfer, txt and trim.ply are still from the previous run. Running an evaluate over the same directory (old run was copied to /tmp. The later 4 are indeed overwritten by the evaluate script. Still no mIOU in the json file. Also no reference to mIOU in the code.
The results with the larger voxel differ from the previous run. For scene 707 the RSME is 20% lower (better: 0.163 instead of 0.193), the prec is better (0.638 instead of 0.461), recall even worse (0.466 instead of 0.489), but still a better f1 score (0.538 instead of 0.474). The l1 improved a lot (0.276 instead of 0.818).
June 17, 2021
Trying to evaluate and render the Atlas results with python3.7, but here the initialisation of numpy fails. It use numpy 1.17.4 from /usr/lib/python3/dist-packages.
As indicated in this post, mixing different numpy versions in the same dist-packages is not a good option.
Removed python3-numpy, which also removed all my ros-noetic packages which were dependent on it.
Installed numpy==1.17.4 on both python3.6, python3.7 and python3.8. python3.7 had no previous numpy-version, python3.6 had numpy-1.18.5, python3.8 had numpy-1.19.5
Did python3.7 -m pip install pyrender==0.1.43, which also installed 6 other packages.
Next failure is on PIL in dist-packages. Did sudo apt-get remove python3-pil, which removed v7.0.0, followed by python3.7 -m pip install pillow=7.2.0 (v6.2.2 and v8.2.0 were also available).
Followed with python3.7 -m pip install torch==1.5.0. Also installed matplot-lib-3.4.2. Had to remove python3-kiwisolver and do python3.7 -m pip install kiwisolver.
Installed scikit-image, open3d==0.10.0.0. The rendering runs, but fails again on importing OpenGL.osmesa.
python3.6 has scikit-image==0.14.5, python3.7 has scikit-image==0.18.5. Upgrading python3.6 scikit-image to 0.16.2. Still the marching_cubes error. Upgrading to 0.17.2. That seems to work!
Compared the Atlas results with the article. The RMSE can be found in Table 2 (page 10) with 2D metrics. The result on the ScanNet testset (RMSE 0.268) correspond well the value reported (RMSE 0.251) from the whole dataset. The prec and recall can be found back in Table 3 (page 11) with the 3D metrics. The prec corresponds (0.427 vs 0.413), but the recall is MUCH lower (0.482 vs 0.711). This means that also the F-score is much lower. Also the l1 score is much HIGHER (0.863 vs 0.172). Have not recoreded the mIOU, although that is maybe the most important benchmark.
Read the submitted paper 'An online knowledge base to model real-world, indoor environments for
robots conducting a search operation with uncertainty' and the draft 'Evaluating a level of autonomy for an AI-based robotic system'. The first describes the knowledge graph TNO has build for Spot, the 2nd paper gives some background on the SNOW-project.
With python3.6 evaluate.py --model results/release/semseg/test_final/ the evaluation fails on a mismatch in skimage.measure, but with python3.8 the evaluation works.
Eveluation alone already takes 3h. The result that is reported on the test-set of the ± 100 scenes are:
prec 0.482
recal 0.427
fscore 0.441
l1 0.863
RMSE 0.268
Downloaded the pretrained model and tried to run inference.py. This fails on the pytorch module. Atlas needed pytorch==1.5.0, torchvision==0.6.0 and pytorch-lighting>=0.8.5. Checked with pip3 list -o, but I have resp. torch 1.5.0, 0.6.0 and 1.3.3 (while 1.8.1, 0.9.1 and 1.3.5 are available). I have to check if torch and pytorch are actually the same!
Seems that pytorch-lightning is only supported under python3.6. Tried python3.6 -m pip install pytorch-lightning>=0.8.5, but this fails on a conflict between tensorflow 2.3.1 vs numpy 1.19.5. Tensorflow 2.3.1 requires a numpy version <1.19.0 and >=1.16.0.
Checked the available version of numpy with python3.6 -m pip install== and installed v1.18.5. Downgraded pytorch-lighting to v0.8.5, installed pyrender==0.1.43, pyquaternion==0.9.5, trimesh==3.7.6, open3d==0.10.0, fvcore, detectron2==0.3 (the latest version for torch1.5).
Still detrectron2 is missing libtorch_cpu.so, while libtorch.so is available in ~/.local/lib/python3.6/site-packages/torch.
Did a downgrade of pytorch-lightning (to 0.8.5) under python3.8, and now it works (although my GPU is out of memory - but that is a known issue, which can be solved with adding --voxel_dim 208 208 80 to the inference command).
Inference without specifying --scences runs it on the complete scannet test-set (>scene707).
Was asked to review the paper belonging to dataset
The evaluation was performed with the Evo package, to compare trajecory outputs of SLAM and odometry.
AdapNet++ from Valada and Wolfram Burgard has an extensive comparison on different benchmarks agains several state-of-the-art algorithms: Self-Supervised Model Adaptation for Multimodal Semantic Segmentation. The algorithm is partically strong in thin objects like poles, due to its multi-scale modules, although this also show a clear improvement for objects far away. For indoor scenes, the algorithm excels for thin structures as legs of chairs.
The conclusion of the multi-channel fusion is that the depth information is valuable indoors, but too noisy outdoors to do late fusion. With intermediate fusion still (the SSMA modules) still a 1% improvement can be gained. The infrared information is outdoors better than depth, but still not as informative as RGB.
At the end AdatNet++ is also used to distinguish 13 categories of rooms, including bedroom, hallway, kitchen. A SE-ResNetXt-101 architecture is used for thei classification head.
June 10, 2021
My workstation is finally ready with extracting the depth images, continue with preparing the data for Atlas.
The proposed method was designed to be efficient enough to be run on a single GPU. The encoder starts with a standard ResNet-50, with two skip branches to be used by the decoder. After that, feature maps at different scales are combined with multiscale residual units. Standard pooling reduces resolution too much for segmentation, so new efficient Atrous Spatial Pyramid Pooling (eASPP) is used. In the decoder phase two side branches are used to calculated auxiary loss functions, which are only used during training, not during testing. As a bonus, Valada is also able to prune the non-used connection in the network, which is not trivial because both the encoder and decoder contain skip and short-cut connections. This is done for each sensor-stream, whereafter the stream are combined with SSMA blocks, working both on the output of the encoder and the output of two skip-branches. As channels they used RGB, HHA and depth.
Did a git clone of ip_basic. The requirements for this python-package were already fulfilled. Unpacking the Kitti depth completion dataset in /media/arnoud/DATA/projects/autonomous_driving/Kitti/depth. There is a directory called depth_selection with the test_depth directories and val_selection directory. The devkit, train and val are missing. Only test_depth_completion_anynomous is used in the demos/depth_completion.py script. Made a my_depth_completion.py which points to the correct data-directory. Had to include ~/git/ip_basic to my PYTHON_PATH, but after that all 999 laserscans are processed (in a minute). The result can be seen in ~/git/ip_basic/demos/outputs/depth_val_000. Nicely filled in depth maps, but not colored:
The 3D Scene Visualizer has code with more options to display depth maps. When running pip3 install -r requirements.txt vtk-9.0.1 and pykitti-0.3.1 are installed.
The KITTI setup is not that explicit which parts of the raw, odometry and object dataset are used in the demos. The button 3 toggles Red/Green 3D.
Looked in depth_completed_point_clouds.py, which requires that your run save_depth_maps_raw.py first. The demos script expects the data in ~/Kitti/raw/2011_09_26_0023.
This drive 0023 (1.9 GB) can be found at the data category Residential
Unzipped this dataset in /media/arnoud/DATA/projects/autonomous_driving/Kitti/raw/2011_09_26/2011_09_26_drive_0023_sync. This direcotry contains 4 image_0* directories, a oxts directory and velodyne_points directory.
Modified scripts/depth_completion/save_depth_maps_raw.py to point to the correct data-directory. Added ~/git/scene_vis/src to PYTHONPATH. Received a warning on tensorflow, so did manual pip3 install tensorflow (was not in requirements). Installation gave a warning that pytorch-lighting is competible with all version of tensorflow >= 2.2.0, except 2.5.0.
Script fails on missing calibration, so also downloaded that part of the dataset. Processing all 473 images (00:48 minutes).
Run the my_depth_completed_point_clouds.py, which gives the overlaid point cloud (points coloured based on RGB). Clicking '3' makes the whole image purple, but is not that usefull for an overlay:
Valada's work is also validated on both the ScanNet and the SUN 3D dataset, which seams most appropriate for the TNO case. For ScanNet they also had to apply the filling algorthm of ip_basic.
June 8, 2021
I read 3D-to-2D Distillation for Indoor Scene Parsing, which also uses the scannet dataset, and gives impressive segmentation results. The code is available on github. Note that they use from scannet the preprocessed franes 25k dataset, which is only 5.6 Gb (instead of 1.2 Tb).
Note that Wolfram's AdaptNet was tested on NIR images in the Freiburg Forest dataset.
Wolfram also points to HHA encoding of Gupta, which is alternative way to encode depth (better suited for CNNs). The abbreviation HHA stands for horizontal disparity, height above ground, and the angle the pixel’s local surface
normal makes with the inferred gravity direction. The code is available here.
For the miniSpot project, Vivien will concentrate on learning to walk, Frank on dynamic obstacle avoidance and Leon on scene reconstruction.
June 6, 2021
After extracting all poses from both the scans and scans_test directory, I found out that also the depth images should be extracted to get the prepare_data.py of Atlas working.
The script is based on this post:
#!/bin/zsh
# A simple script with a function...
After downloading the full set of test-scans, and extracting all color images, I found out that also the pose should be extracted to get the prepare_data.py of Atlas working.
June 4, 2021
The download from ScanNet is still not finished. The whole dataset is 1.2 Tb, luckily my Data partition is 2.1 Tb. Looked in scannet/scans/scene0000_01, and the directory structure does NOT have the structure YET as required by Atlas.
Yet, scannet comes with SensReader, which can export the color images.
The train/test split can be easily found from github. From scannetv2_val.txt I see that I have only downloaded 50% of the scenes yet.
Downloaded the Labels with command python2 download-scannet.py --label_map -o ./scannet/
Tried python2 reader.py --filename==scene0000_00.sens --export_color_images --output_path ., but had to do python2 -m pip install imageio==2.6.1 first (last imageio version with python2 support). Also had to do python2 -m pip install opencv-python==4.2.0.32
Download script stopped during downloading scene0337_02. Downloaded that final scene manually. Modified the *.txt files. Originally scannetv2_train.txt contains 1201 scenes. After removing all scenes above 337, 606 scenes remain.
Wrote a script to extract all downloaded scenes. From scannetv2_val.txt 105 of the 312 scenes remain. The numbers of scannetv2_test.txt are all above 700, so downloaded those files manually. Those scans are downloaded in scannet/scans_test.
Looked at papers cited by Wei Zeng. The OmniDepth paper contains no link, but the FCRN paper has an accomponying code. The examples are from standard images, not panoramic.
With a 2nd setup DreamVu Explorer also displays an undistorted view on my nb-dual.
The command python test_py_installation.py works, but import PAL_PYTHON not. Putting the PAL_PYTHON library in ./lib solved that.
The LUT_dimensions.h stands for Look Up Table, with the 4 supported resolutions. That configuration file is not used to create the Explorer properties window.
The four images in the /usr/bin/data/lut are resolution 5290x3638 (1.png) to 660x454 (4.png), with the segment patterns:
If I load perform sess = rt.InferenceSession("dualenet.onnx") as suggested in the onnx tutorial, I get the same error messages.
Can also ask for input_name = sess.get_inputs()[0].name (answer is input1). Equivaletn, get_outpus() gives as answer output1.
The command rt.device() shows how the model is evaluated. At nb-dual the answer is CPU, on my workstation the dreamvu_ws sitepackages are no longer in the PACKAGE_PATH. deactivated the venv and installed pip3 install onnxruntime==1.5.2. Strange enough the device is also reported as CPU. In addition, I installed pip3 install onnxruntime-gpu==1.5.2. If I now import onnxruntime as rt, I got the error that libcudnn.so.8 cannot be found (which is one of the requirements). On my nb-dual, I could try to install onnxruntime-trt (or OpenVino if I want to use my NeuralStick).
With sudo apt-get install libcudnn8 I get a GPU answer when I do print(rt.get_device()).
Replaced the symbolic link in installations/dreamvu_ws/bin/python3 from /usr/bin/python3 to /usr/bin/python3.6, now PAL_PYTHON can be imported again and Explorer is working again in the dreamvu_ws.
Also installed pip3 install onnxruntime-gpu==1.5.2, but now Explorer crases in PAL_MIDAS_NANO.cpp:100. Same for python main1.py, but now for PAL_DUAL_ENET.cpp:40.
Looked at onnx_test_runner. The command python3 -m onnx.backend.test.cmd_tools generate-data -o /tmp/onnx_testdata worked, but the model is no longer available.
June 2, 2021
The deadline of Special Session is unfortunatelly too early.
Trying the setup at my workstation again, after a 2nd calibration setup.
Yet, now Explorer gives an Cameral initializaion failed error (even after a reboot).
On May 19 I had it working (although slow and distorted)!
Switched USB port. On the right port lsusb now reports an e-con systems See3CAM_CU135. The Exporer now reports another error on PAL_DualEnet:Init(). Deactivating the dream_ws solved this. The image looks good, 4 FPS.
The difference is between the two is the python environment (python 3.8.5 works, python 3.6.13 not).
Tried import PAL_PYTHON in both environments. python 3.8.5 doesn't know this module, python 3.6.13 is missing numpy.
Solved the broken pip install with adding PIP_NO_CACHE_DIR=off pip3 install numpy.
Continue dreamvu installation with pip3 install -r python_requirements.txt. Only had to remove the pkg-resources line.
Finished the installation, and now Explorer also works in the dreamvu_ws environment.
The command IMPORT PAL_PYTHON now also works. Running python3 main1.py in PYTHON/tutorials also gave a left and right image.
Added the conda hook to my bashrc, but deactivating gets me from both the base as dreamvu_ws environment.
Installing pytorch 1.5.0 and cudtoolkit 10.2 with conda in the base/dreamvu_ws environment.
The conda install opencv failed on dependency conflicts of urllib3 and cardet. Problem is that the python from Anaconda is v3.8.8, while opencv needs not higher than v3.8.0
Outside the conda environment, I installed sudo apt-get install cuda-toolkit-10-2.
Unfortunatelly, after this my disk is full. Could win a lot of space moving Part4 to my /media/arnoud/DATA disk. Also removed anaconda2 and anaconda3 directories.
Installed pip3 install torch torchvision torchaudio, which installed torchvision 0.9.1 (instead of 0.6.0). Repaired that with pip3 install torchvision==0.6.0 and pip3 uninstall torchaudio.
Installing NVIDIA/apex failed on to modern gcc, so I manually linked /usr/bin/gcc to gcc-8 (same for g++). Originally it was a link to gcc-9.
Downloaded the sample scene and unpacked it in DATAROOT /media/arnoud/DATA/projects/roborescue/data.
Requested access to scan-net and received a script to download a python2 script to download 1.2 Tb of data.
June 1, 2021
Run the ros-example: roslaunch dreamvu_pal_camera pal_rviz.launch. It works, although with a framerate of 1 FPS:
Recorded a bag file following the tutorial. According to rosbag info the bag contains 2 images from depth and left, and on right image. There are also two pointclouds in the bag.
The CPU is only used for 15%, while 75% of the memory is used (5.6 Gb of the 7.4 Gb).
Created a export_image.launch, which should read a depth image. That fails on missing conversion from 32FC1 to bgr8. Tried it with the left image, that works! The two frames are stored in ~/.ros (which can be changed by parameter _filename_format.
Emily found the page describing all frames known to Spot.
May 28, 2021
Downloaded the corrected PAL_PYTHON.so, and now import PAL_PYTHON works.
The example PYTHON/tutorials/main1.py stores a left and right image. The other examples correspond with the cpp equivelents. main2.py changes the white balance, main3.py stores a depth and disparity images, main4.py stores a point cloud.
The stereo_panorama.py in code_samples shows a window with the active panorama, the people_detector also detects humans in that window.
The PeopleDetector from the API is called, the image is not fed into an existing framework.
Continued with the ROS-package. My nb-ros is quite clean again, so the old ros-indigo installation is gone. The documentation of the package points to kinetic, while the installation/ros.sh script points to melodic-desktop.
Melodic is the ros-version for 18.04, so I am running the installation/ros.sh.
Note that this script also install libopencv3.2
Build the ros-nodes, although I receive warnings that /opt/ros/melodic/lib/libcv_bridge.so needs libopencv_imgcodecs.so.3.2, which conflicts with so.3.4. Same warning for libopencv_imgproc and libopencv_core.
May 27, 2021
Frank ter Haar mentioned that they had already done some object recognition at TNO. Looked at his publications.
Worked with Frank ter Haar and his DreamVU PAL-USB camera to see what goes wrong.
Had perform the camera specific installation, which overwrittes the current installation.
After running the setup for my camera again the calibration problems vanished. The only problem is that you see the effect of mozaicing the different segments on nearby objects. The icon on the back of my laptop should not have double lines:
Still, this is only a detail, the panoramic images seem very usefull for robot navigation.
See for instance the normalized disparity image in front of room 2. Both the open door and the corridor are clearly visible:
Collected images and point clouds on all locations 1m from the door at the Villa.
The python example code didn't work, but that was because PAL_PYTHON.*.so was not correctly linked (libopencv_core 3.2 instead of 3.4)
May 20, 2021
Updated nb-ros from Ubuntu 14.04 to 18.04. Installed DreamVU PAL v1.2 without any problems.
Still, both Explorer as tutorial example 001_cv_png.out fail to initialize camera.
Inspecting with dmesg | tail. Receive messages:
usb3-port2: attempt power-cycle
usb3-2: new high-speed USB device number 12 using xhci_hcd
usb3-2: Device not responding to setup address.
usb3-2: device not accepting address 13, error -71
usb usb3-port2: unable to enumerate USB device
May 19, 2021
Trying the installation of DreamVU PAL v1.2 installation on my Linux-workstation with GPU support (Ubuntu 20.04).
This time I pointed python3 to python3.6 before doing anything else. In principal this works, yet outside the venv. Inside the venv pip crashes on posixpath.py line 80.
Same result as on my Ubuntu 20.04, segmented view, FPS of nearly 4, onnxruntime removing initializers.
Did a ros2 run my_robot_tutorials minimal_cpp_node on the Hello from ROS2 example.
Roscpp and roscpy are easily replaced in the CMakeLists.txt with rclcpp and rclpy. Also commented out generate_message part and the explicit catkin commands. The code now fails on including ros/ros.h.
Received the ros2_package_generator from TNO. Seems that the conversion is based on a package_configuration.json, as given in examples.
Looked in the templates/setup.sh, but rosdep install -i --from-path src --rosdistro dashing -y fails on a missing rosdep definition for message_runtime.
At dreamvu v1.2 for Ubuntu is now available. Trying it for Ubuntu 18.04 under WSL. Starting with the opencv.sh script.
Next run sudo dependencies.sh, ros_cmake.sh, ./setup_python.sh and the rest of the install.sh script.
Yet, the PAL-usb camera is not visible with lsusb.
Received PUM8D21007.zip, which contains the camera specific /usr/local/bin/data. Tried 001_cv_png.out, but receive error that the camera is not connected (for both libPAL_CAMERA.so libraries).
Changed the requirement from dataclasses from 0.8 to >= 0.6 and numpy >=1.17.0
Installed python3.6 from following the instructions from here
Changed the requirement for scitlearn to >=0.14.5
Now the installation of the python_requirements is hanging on oauthlib.
Changed /usr/bin/python3 from python3.8 to python3.6 and build a fresh dreamvu_ws envirnment. After skipping pkg-resources that works.
Could now start Explorer (from commandline) and run 001_cv_png.out, but with the segmented view.
For both applications I get an error from onnxruntime: CleanUnusedInitializers. For the explorer, I also get errors on the CUDA drivers, with the suggestion to compile TensorFlow with the CPU instructions AVX2 AVX512F FMA.
At least, the Explorer works and has a framerate of 4. Try tomorrow again on my workstation.
Recorded Theta m15 images in all rooms of the TNO villa.
Continue with the installation/ros.sh on the Jetson Jetpack 4.4.
This script failed on executing catkin_make, so installed pip3 install empy and pip3 install catkin_pkg manually.
Update has problem with not existing /etc/ld.so.conf.d/aarch64-linux-gnu_GL.conf. Yet, it is a warning, seems to have no consequences.
Copied the directory dreamvu_pal_camera to ~/catkin_ws/src and did a catkin_make. That fails on the project cv_bridge.
The file /opt/ros/melodic/share/cv_bridge/cmake/cv_bridgeConfig.cmake explicitly points to three *.so.3.2.0 libraries (while the *.so.4.1.1 are installed from source). The include files are expected in /usr/include/opencv, while the source installed them in /usr/include/opencv4. Tried sudo apt libopencv-dev, but received the message that the latest version (v4.4) was already installed. Modified the cv_bridgeConfig.cmake to include /usr/include/opencv4, now the target is build. Got warnings of version conflict, so replaced explicit reference to current *.so. That worked.
Run rosrun dreamvu_pal_camera capture. That publishes four topics. Installed ros-melodic-image-view and run rosrun image_view image_view image=/dreamvu/pal/get/depth, but nothing happens (note even the previous cap_v4l.cpp (1004) tryIoctl VIDEOIO(V4L2:/dev/pal5): select() timeout.
Also tried roslaunch dreamvu_pal_camera pal_rviz.launch. Starts nicely, although I receive warnings on both the Global Status, Left Panorama and Depth Panorama. Yet, no image occurs.
Looked at ROS2 versions. ROS Dashing has binaries for Ubuntu 18.04. The older version Crystal has binaries and Eloquent for both 16.04 and 18.04. The latest version Foxy has binaries for Ubuntu 20.04.
Spot is running Dashing, so followed the instructions and did sudo apt install ros-dashing-desktop (400+ packages).
The talker / listener example worked.
Next I continue with the creating a workspace tutorial. Yet, the catkin_make alternative colcon cannot be found. Solved that with Colcon tutorial: sudo apt install python3-colcon-common-extensions.
Now turtlesim is starting to be build, but fails on missing python-module lark. Installed v0.11.3 with pip3 install lark. Now turtlesim is succesfully build.
Warnings are on IN_LIST commands in /opt/ros/dashing/share. Adding cmake_policy(VERSION 3.3) at the top of the dreamvu_pal_camera/CMakeLists.txt solves this. Yet, roscpp and roscpy are not found.
Looked at python_data/dualenet.bin, which has multiple layers. Layer 1.3.0 is a convolutional layer, which continues to layer4.1.0. After that a decoder (also pretrained) is applied (also 4 layers). The file python_data/depth.bin has 18 layers of features for the encoder and 5 up layers for the decoder.
May 6, 2021
Promising approach to find object prototypes: paper and code.
April 30, 2021
I can now get images from the PAL-USB camera, although on the JetPack 4.4 it takes quite a long time (not only for the transfer, but also for the correction). Worse, the correction has not taken place. Exectuted the python_data/setup.sh, but maybe I should also recompile the tutorial code, because some of the libraries like jetson_inference.so are overwritten:
Updating the 377 packages on the JetPack.
The mirror sections were clearly visible in the image, but when I switched libPAL_CAMERA.so the result improved.
Executing the tutorial takes quite some time. The process also uses a huge amount of memory (1.3 Gb for 003_disparity). The result is a depth and disparity panorama:
Unfortunatelly the tutorial 004_point_cloud gets a segmentation fault after calling the SDE method.
Both libPAL_DE.so and libPAL_Depth.so contain this string.
Changed the resolution in PALsettings.txt to from 1320x454 to 660x227, but still the Memory usage when staring up the Explorer increases from 1.5 Gb to full 3.9 Gb, whereafter the system halts when the Swap reaches the full capacity of 1.9 Gb.
April 29, 2021
The make of opencv on the Jetpack 4.4 in principal worked, only the nano frose during compilation because it was out of memory.
Trying it with only thread.
With one thread opencv can be build. Opencv is installed, although I am maybe are missing some installed libs.
All libraries can be found for Explorer. Running explorer just works (again a memory warning).
Yet, I receive a core dump on registering the TRT plugin: FlattenConcat_TRT. The complaint is that compute 5.3 is expected, while compute 7.2 is received. Suggestion is to rebuld jetson.inference.
Packages not yet installed were libtiff-dev, libavcodec-dev, libv4l-dev, libx264-dev, libgtk-4-dev, gfortran, ffmpeg.
Compiled the code_samples. The programm 001_stereo_panorama.out fails on a non-implemented function (recommendation to install libgtk2.0-dev and pkg-config.
Rebuilding OpenCV library. Note that the script also does a upgrade (with more than 300 packages pending).
There exists a (two step) tool to convert ros1 bags to ros2 db3 format, but I haven't found the reverse.
April 28, 2021
Found another Micro SD card (Samsung 64Gb Evo), which contains the dlinano image.
The previous card (SanDisk 64Gb ultra) contained the libnppicc.so.10.0.326 of April 26.
Alsof found a card labeled arnoud, which contains the mmdetection project of March 31, 2020.
Registered for Workshop organized by DreamVu on Robot navigation.
Flashed the card labeled arnoud with Jetpack 4.4 and started the install.sh in installations.
Just running the default install script failed on creating a virtual environment, because pip was not available. Probably because I ran the script with sudo ./install.sh (which I shouldn't have done).
April 27, 2021
When the PAL camera is used by another program (i.e. detectnet-camera /dev/video2 jetcar_detected.mp4), the code_samples reports [PAL:ERROR] Camaera initializaion failed. Modified the example with giving the index of /dev/video2, but that gives VIDEOIO(V4L2:/dev/video2): can't open camera by index.
Dreamvu thought about clashes between python3.6 and python3.8 (although /usr/lib/aarch64-linnux-gnu/libpython3.6.m.so.1.0 is linked), so I ordered a new Micro SD card to install a fresh Jetpack 4.4.
April 26, 2021
Tried the Explorer again. In the dreamvu_ws there is no library missing. Still, I have the same assertion error, although I first get a first a opencv/modules/videoio/src/cap_v4l.cpp error on /dev/pal5: select() timeout. After some waiting I get several Opening in BLOCKING MODE messages, followed by the abort on the assert.
The libnppicc.so.10.0 can be found by Explorer, because it is in /usr/local/cuda/lib64
The libraries should be defined in the LD_LIBRARY_PATH. Added a copy to libnppicc.so.10 in PAL-Firmware-v1.2-NX-J4.4/lib, but still the correct version is not found.
This is strange, because libjetson-utils.so refers to a npp@libnippicc.so.10 string, which can be found in both libnppicc.so.10.0.166 and so.10.0.326.
Can reproduce the error of version not found when I do ldd /usr/local/lib/libjetson-utils.so
Looking if I can repair it by rebuilding the libjetson-inference from the source on github. There are tags for branches. I can image than L4T-R32.4.4 is for Jetpack 4.4, but I say no documentation on the branches, so I will try the master first.
Following the instructions, and choosing all defaults (as for instance downloading the default models GoogleNet, ResNet-18, SSD-Mobilenet-v2, PedNet, FaceNet, DetectNet-COCO-Dog, FCN-ResNet18-Cityscapes, DeepScene, MHP, Pascal-VOC, etc).
This solves the issue, ldd does no longer complains and PAL's python test_py_installations.py reports success.
Continue with installations/ros.sh, which should install ros-melodic-desktop, which fails because I upgraded to focal. Instead installed ros-noetic-desktop.
Had to do some pip3 install empy and pip3 install catkin_pkg (because of the virtual environment0, to be able to do an empty catkin_make.
The compilation of the dreamvu_pal_camera goes well, but linking fails on missing ros libraries.
Problem was that in dreamvu_pal_camera/CMakeList.txt explictly the link_directory /opt/ros/melodic/lib was specified. With noetic the linking succeeds.
Also the pal_camera_node dies on the assert in PAL_DUAL_ENET.cpp
April 24, 2021
The built and install of opencv4.4 works on the JetCar. Receive some warning that the LAPACK libraries could not be found, nor the JNI libraries. Also julia, tesseract and cuda4dnn are excluded from the source list.
Compilation of the PAL tutorial code now works, but get in all four cases: ::Init(): Assertion 'm_pModule != NULL' failed.. The assertion can be found in ../create_all_so/PAL_DUAL_ENET.cpp:44.
Switching the libPAL_CAMERA.so (other serial number) didn't help.
Same is truth for the code_samples. Trying a reboot.
At least cheese works, although cheese gives the warning that the gst_base_sink_is_too_late: There may be a timestamping problem, or this computer is too slow:
April 23, 2021
Received the links to libPAL_CAMERA.so for the aarch64 architecture. TNO bought two cameras, the two libraries differ binary.
Downloaded v1.2 for the Jetson on my JetCar.
Unpacked in ~/packages, copied the first libPAL_CAMERA.so in PAL_Firmware-v1.2-NX-J4.4/lib.
Following the commands in install.sh, beginning with dependencies.sh.
Skipped again the python3.6-dev, because python3.8 is already installed. Instead installed python3-venv
libglew2.1 is installed (instead of libglew2.0).
Downloading the torch-1.7.0.whl didn't work, because it is python3.6 based. Installing pip install pyton-1.7.0 also failed, but pip install torch works fine (installs torch-1.8.1 and numpy 1.20.2, instead of 1.19.3).
Installed pip install opencv-python instead of opencv-python-headless.
Installed torchvision with pip install (which installs v0.9.1 instead of 0.8.1).
Checked python installation. libglew2.0 was missing (part of 18.04, while I have 20.04). Downloaded the deb from ubuntu.pkgs.org.
The ldd now finds it, but the test_py_installation.py still gives an import error on libnppicc.so.10.
The library is part of the cuda-toolkit, but this seems to be installed with the sdkmanager.
With command the sdk downloads the deb in /tmp/cuda_pkg, but first need a docker image of the sdkmanager on my host computer. Unfortunatelly, the dockerdaemon dockerd fails to run under WSL.
Finalized the install with updating the udev rules, and see if I can at least compile the C++ examples.
Started with executing ./Explorer, but this requires libopencv_core.so.4.4, while libopencv_core.so.3.3 is installed.
Yet, Ubuntu 21.04 has libopencv 4.5, while Ubuntu 20.10 has libopencv 4.2. So, I have the feeling that opencv has to be installed from source.
In the readme is already indicated that the software depends on Jetpack 4.4 and OpenCV 4.4.
The script installation/opencv.sh is not called from install.sh, so did it manually.
The library libjasper-dev couldn't be found.
Build of opencv with cuda_compile fails because gcc version is too modern, which is strange because the version is v7.5.0. Cannot fine package gcc-6, so could not configure alternatives. /usr/bin/g++ was a symbolic link to g++-9, so replaced that with a link to g++-7. Now the compilation continues.
April 15, 2021
Downloaded the PAL mini SDK and VIS ROS package from DreamVU software. The SDK is for Ubuntu 18.04, the ROS package also for Ubuntu 20.04 (based on ROS Kinetic).
Unpacked the SKD in ~/packages/PAL-mini-v1.1.
Run the ./installations/opencv.sh script which downloads and builds opencv v3.4.4 from ~/opencv in my home-directory. After that it does installs the just build package.
The script setup_env.sh installs python3.6. Instead just installed python3-venv (which uses python3.8). python3-dev and python3-tk were already installed
While still compiling opencv3.4.4, I already continued with the setup_env.sh script, and created the virtual environment ~/PAL-mini-v1.1/installations/dreamvu_ws/bin/activate.
Added cython>=0.23.4 to the python_requirements, which solves the issue with scikit-image.
Part of the install.sh is copying the file depth.bin to /usr/local/bin/depth.bin, which is not an executable but the weights of a cnn.
The python3 test_py_installation.py reports [INFO] Python Installations Successfull and added udev rule for the PAL camera and rebooted.
Continue with the installation of the ROS package.
Could find no previous ros installation on nb-dual, so installed sudo apt install ros-noetic-desktop. ros-noetic-desktop-full would also install 2D/3D perception package, but the PAL ROS package only depends on the ros packages cv_bridge , image_transport , roscpp , sensor_msgs , std_msgs
Created a catkin_ws as indicated in tutorial (also fresh, because I had my factory reset earlier this year!)
The building of the catkin_ws/src/dream_vu_camera fails on the missing libPAL_CAMERA.so, which according to the readme libPAL_CAMERA.so is provided with the camera.
Looked at the provided example code and ros package pal_camera_node.
The code 004_point_cloud.cpp creates a point_cloud.ply.
In principial pcl point cloud_viewer should be able to visualize a point cloud. I could convert ply to pcd /usr/bin/pcl_ply2pcd, or use the ply parser.
Not only installed libpcl-dev, but also pcl-tools. Still, pcd2ply and octree_viewer are not known, although plc_viewer is known /usr/bin/pcl_viewer.
Received the PAL-usb. The installation scripts of the PAL-usb and PAL-mini are the same. The only difference seems to be libPAL.so (libPAL_depth.so are the same). Modified the LD_LIBRARY_PATH setting in ~/.bashrc.
Watched Raquel Urtasun's GTC keynote, where she introduced LiDARsim based on the Raydrop network. According to her talk, physical rendering has to be augmented with the characteristics of the material, etc. The difference between LiDAR simulations in CARLA and real-data was 30%, while the Raydrop trained network could close that gap with 29%.
The Raydrop network uses as input the real-valued channels: range, original recorded intensity, incidence angle, original range of surfel hit, and original incidence angle of
surfel hit
and the integer-valued channels: laser id, semantic class
(road, vehicle, background).
The note indicate that the source code will be published, although it is not clear. Thomas Antony only has some solutions for the Udacity Car nanodegree.
The paper Pano2Scene is even more applicable for Emily, because it generates not only depth but also the point clouds, for segmented objects (like doors).
In the paper iSAM is mentioned as one of the state-of-the-art techniques, which is not the iMAP method Patrick was mentioning. The iMAP techniques uses a historic keyframe set and repeated global bundle adjustment like PTAM.
Note that smoothing techniques (like iSAM) outperform filtering techniques, except for visual-inertial problems where the linearization point for EKF is accurate (such as VIN, which is again not the same as the VINS-fusion mentioned in the ORB-SLAM3 paper).
Nice is the quote "In hindsight, the fact that short-term data association is much easier and
more reliable than the long-term one is what makes (visual, inertial) odometry simpler than SLAM".


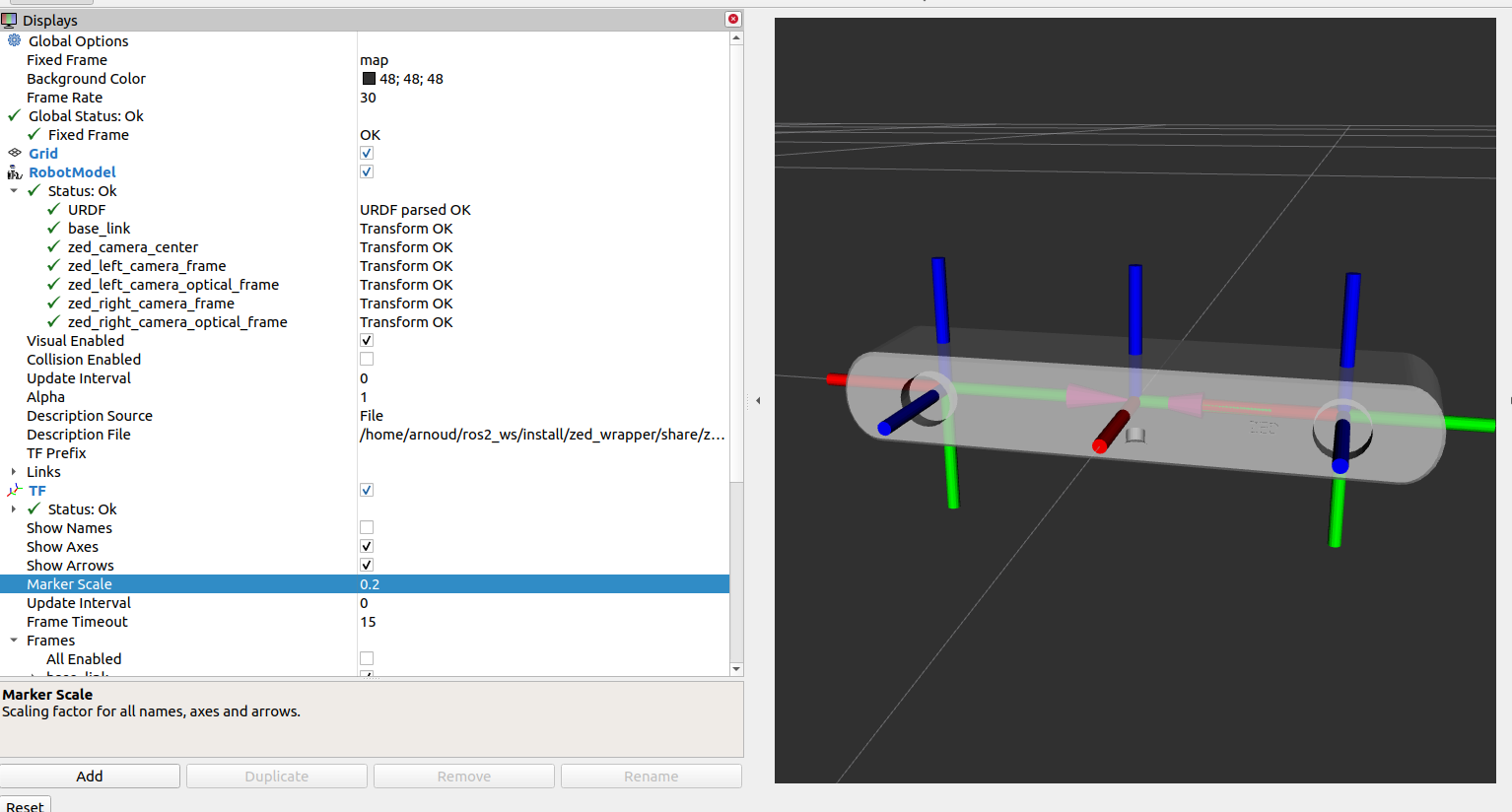
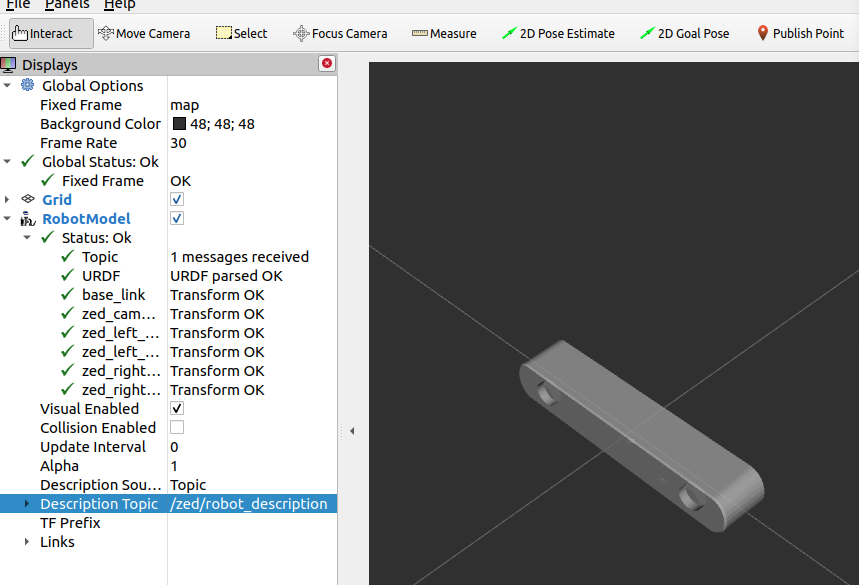
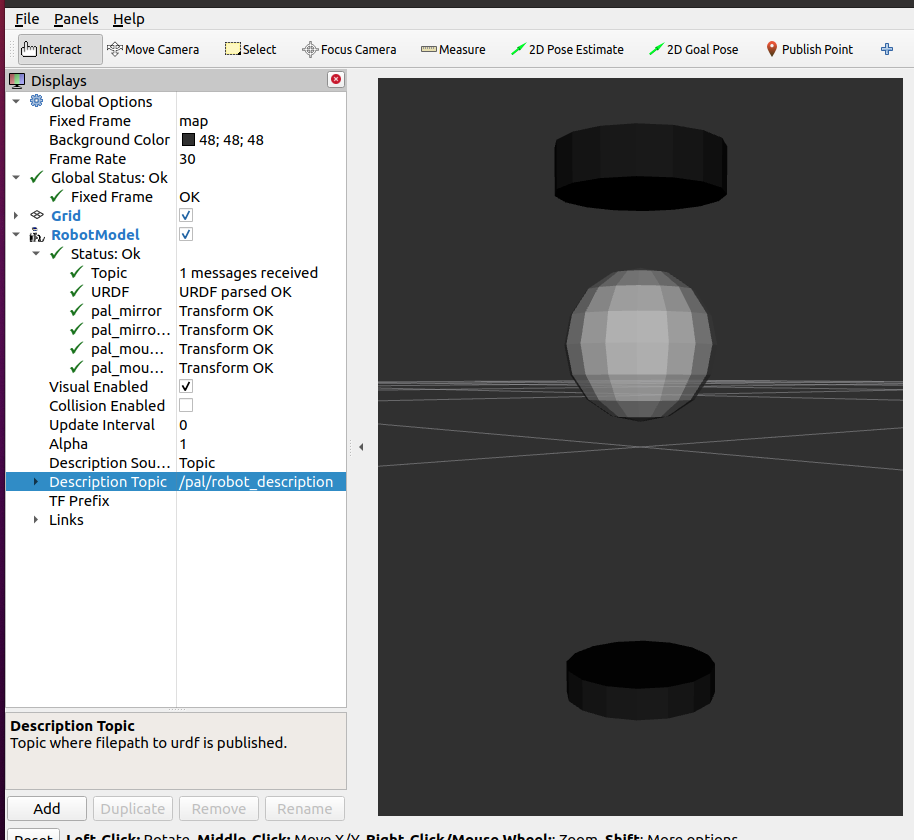
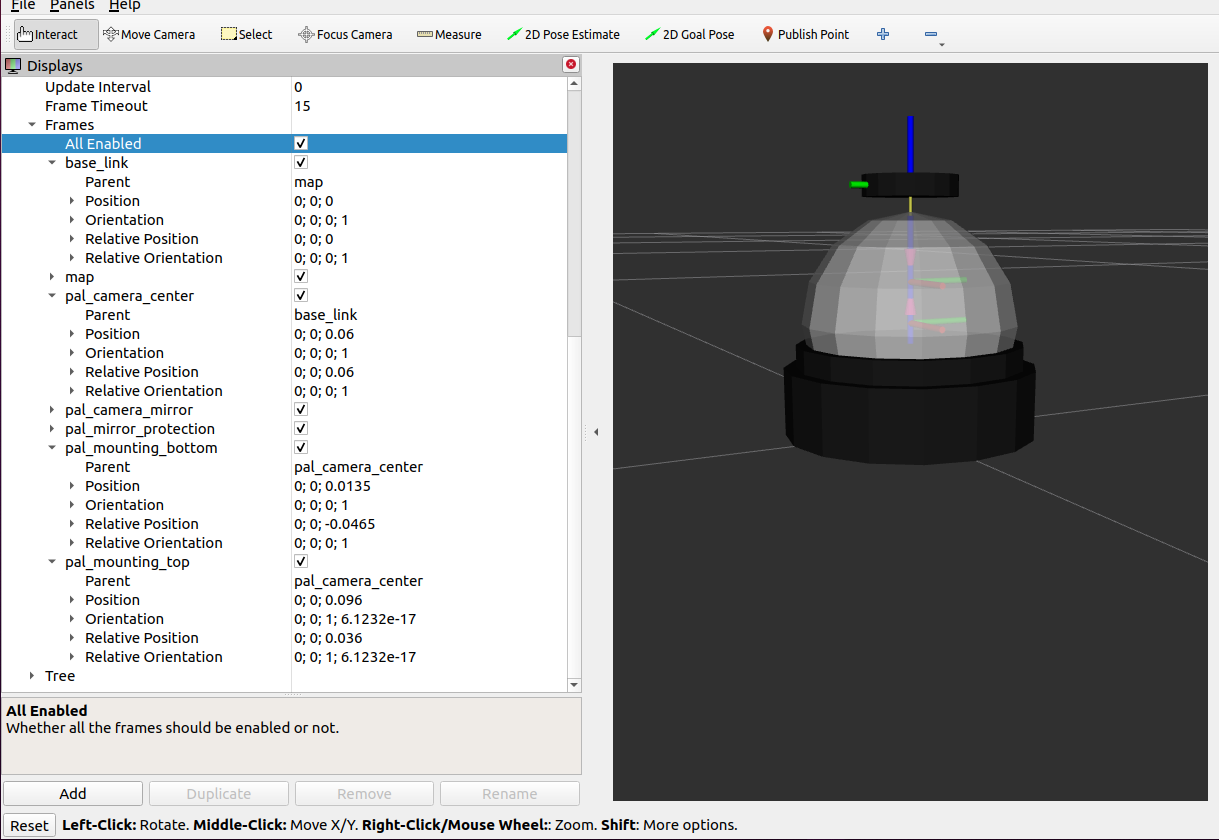
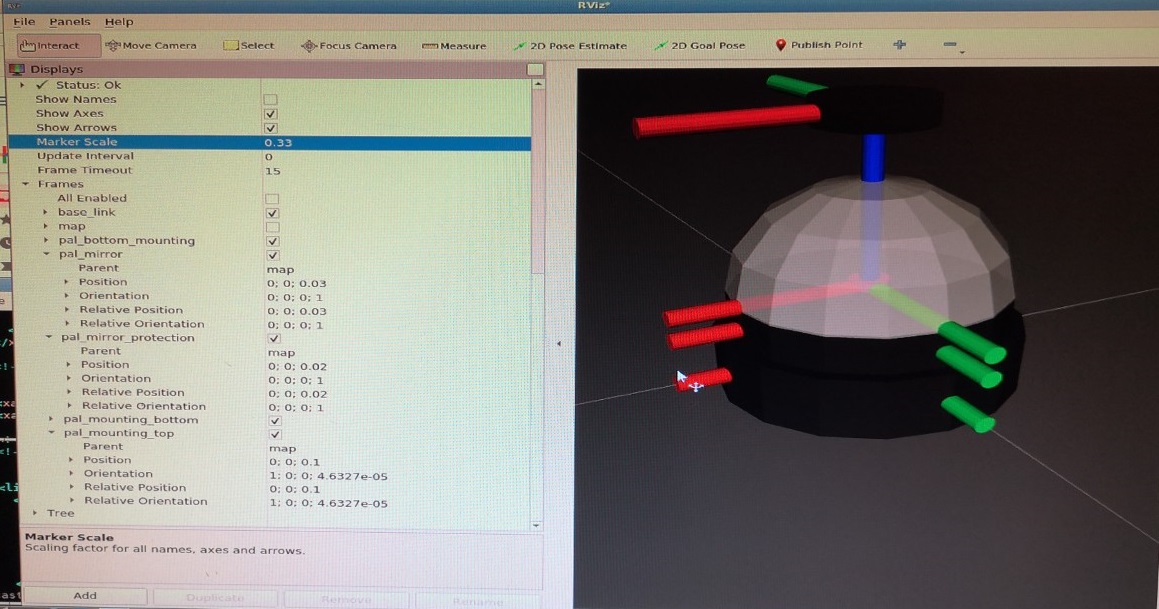
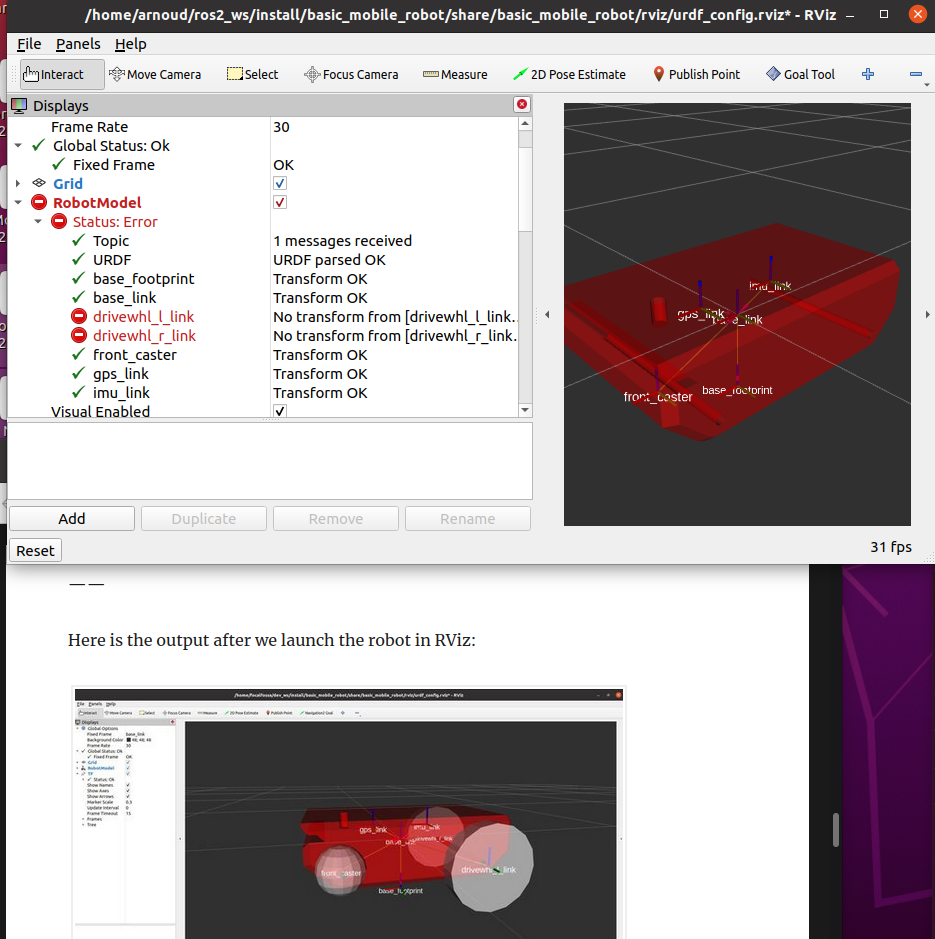

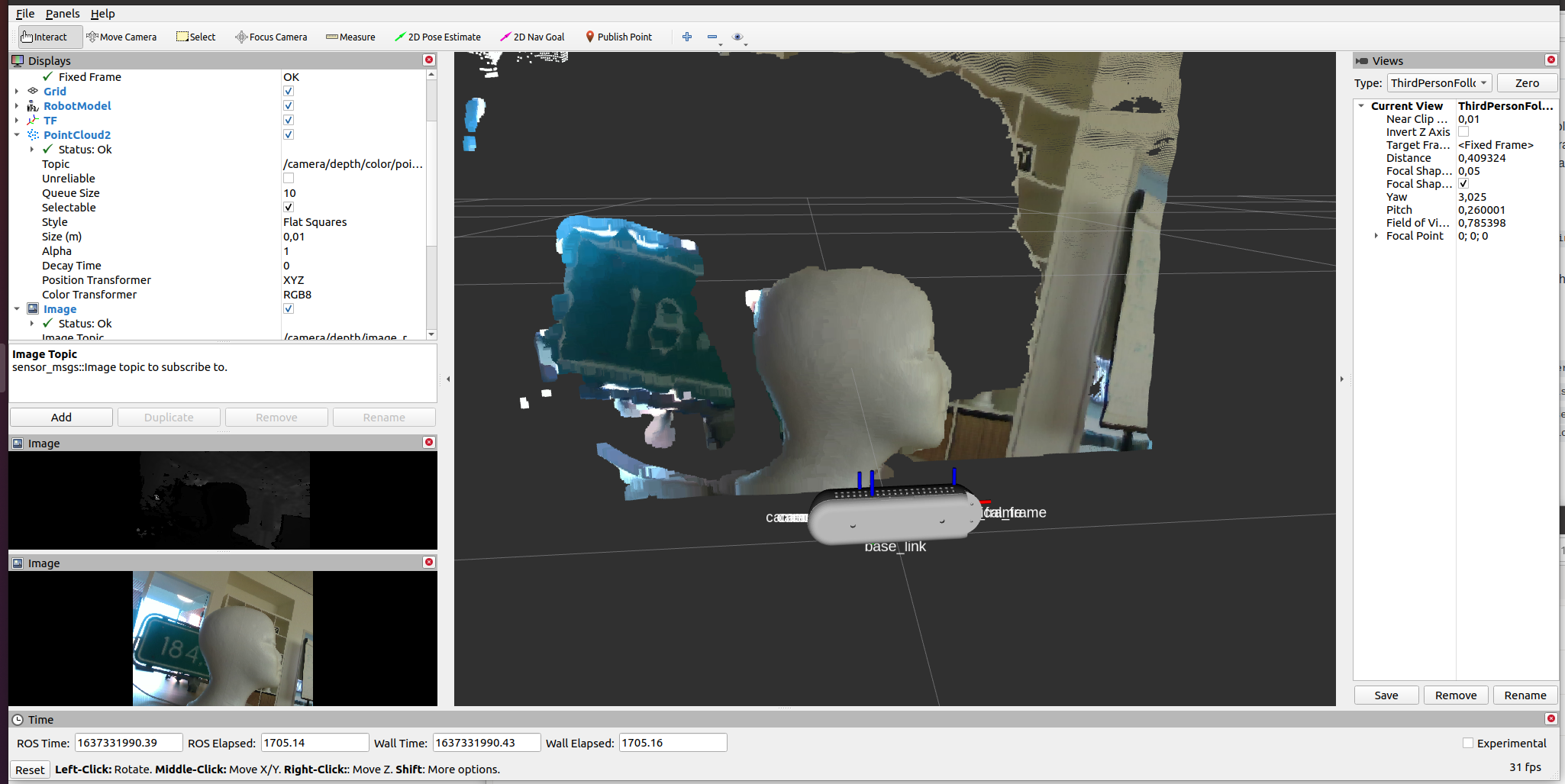






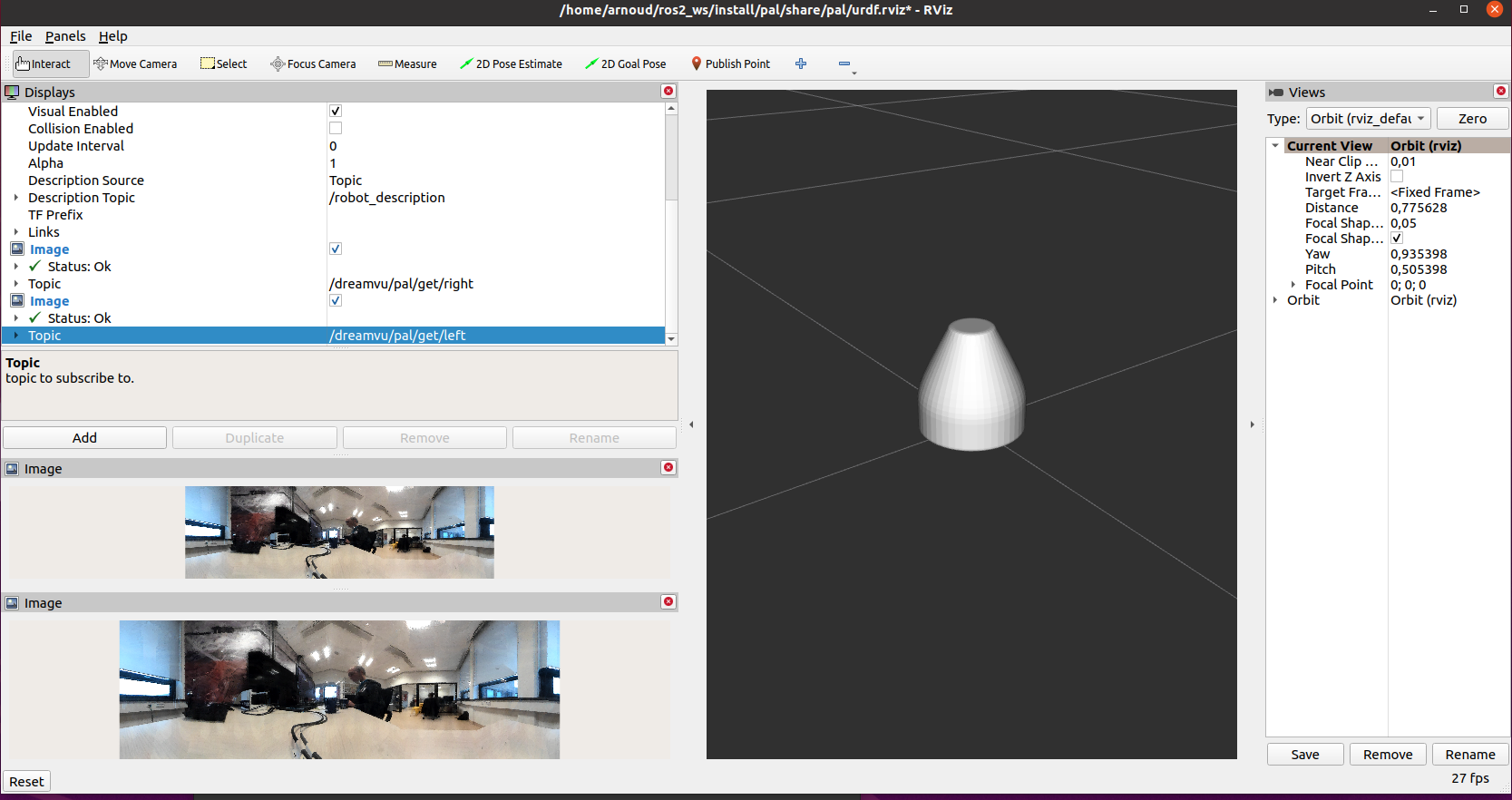
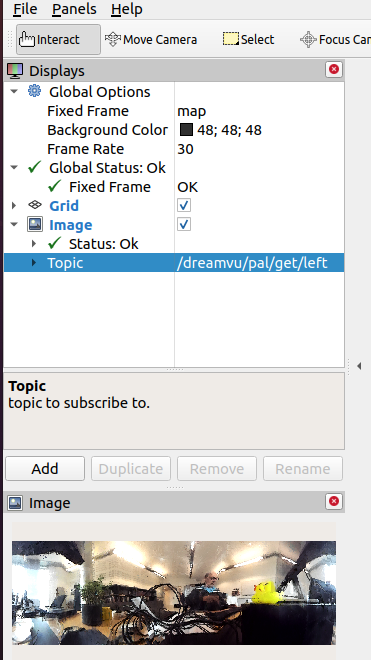
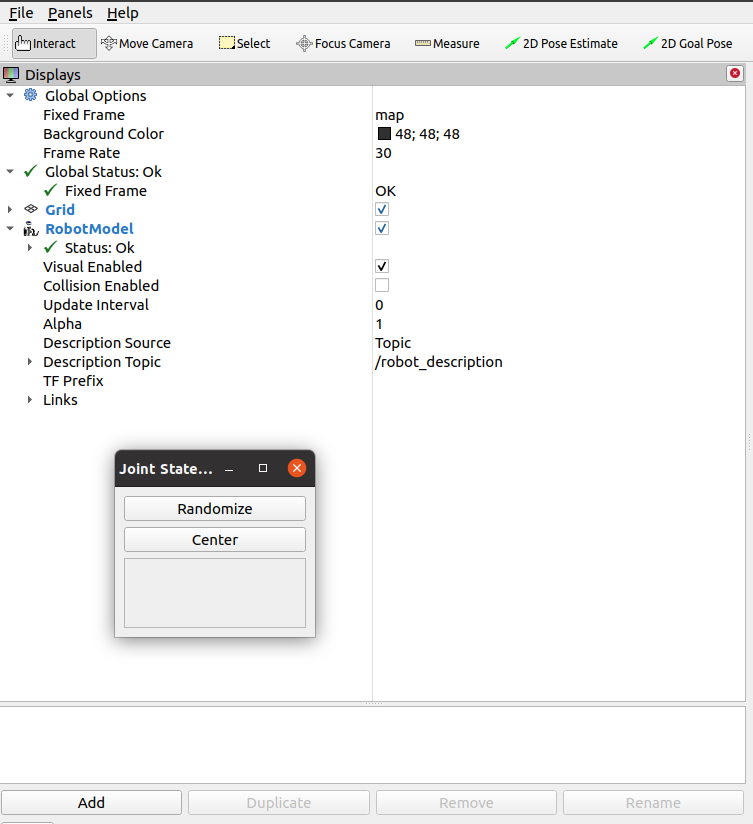
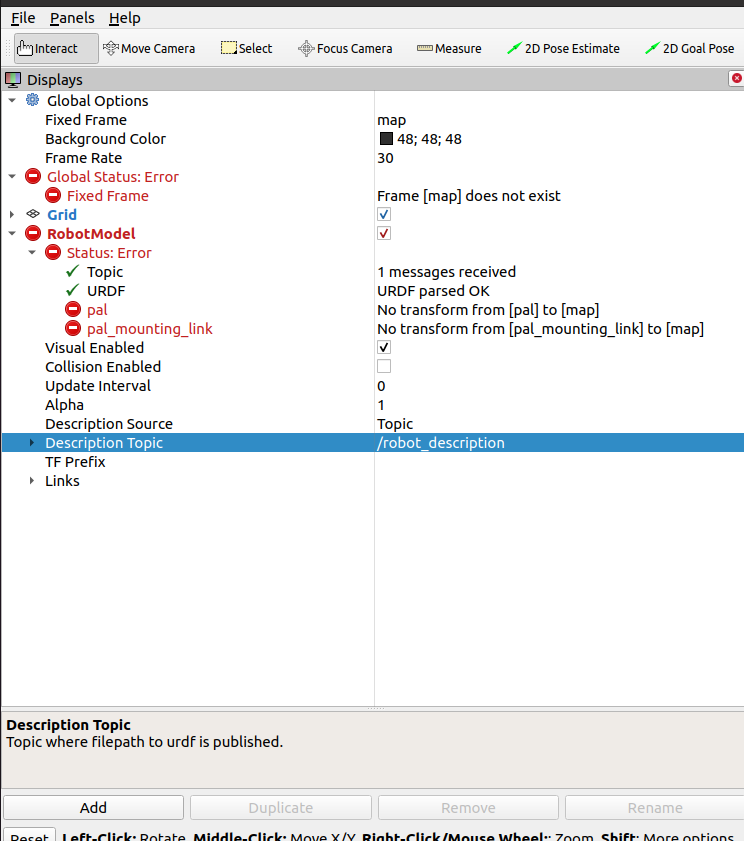
.