{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Lecture Notes Week 7\n",
"\n",
"## Topics\n",
"\n",
"* [Similarirty measures](#sim)\n",
"* [Literature](#lit)\n",
"* [Project topics](#top)\n",
"* [Assignment](#as)\n",
"* Slides and Notebook: [Slides](../Slides/SimilarityMeasures.slides.html) and the slides as a notebook [Notebook](../NoteBooks/SimilarityMeasures.ipynb)\n",
" \n",
"## [Similarity measures](id:sim)\n",
"\n",
"### Jaccard\n",
"\n",
"### Cosine similarity\n",
"\n",
"### Pearson correlation\n",
"\n",
"### Mutual information\n",
" \n",
"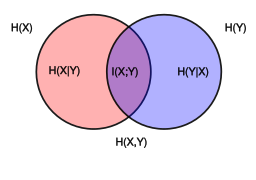 \n",
"\n",
"## [Literature](id:lit)\n",
"* Overzichtelijk artikel waarin een aantal maten worden beschereven en toegepast op een dataset, en daarna vergeleken.\n",
" \n",
"## [Project topics](id:top) \n",
"\n",
"### Data projectje als begin van je scriptie\n",
"* Als je een scriptie gaat schrijven die gebruik maakt van een flinke hoeveelheid data kan je prima deze opdracht als mooi eerste begin gebruiken. \n",
"* Je kunt dan met je groepje alvast een grondige eerste analyse uitvoeren.\n",
"\n",
"### Voorbeelden met bestaande datasets:\n",
"Er staan verschillende onderwerpen met datasets in de [Data folder](../Data/).\n",
"* Bouw verder aan de wordcloud/samenvatter van UvA proefschriften.\n",
" * Zie onderaan.\n",
" * Maak samenvattingenvan \"alle\" UvA proefschriften (allemaal direct te downloaden in PDF van uva.dare.nl)\n",
" * Verbeter de samenvattingen verder.\n",
" * Maak samenvattingen per hoogleraar (bijv Dick Swaab), en laat ontwikelingen door de tijd zien.\n",
"* [Cito toets scores per school in Nederland](../Data/CitoToets)\n",
"\t* [Notebook](http://nbviewer.ipython.org/url/maartenmarx.nl/teaching/ISatWork/Data/CitoToets/CitoToets.ipynb)\n",
"* Allerlei gegevens over het Voortgezet Onderwijs (middelbare school) in Nederland\n",
" * \n",
"* [WOB verzoeken subsidies aan bedrijven](../Data/SubsidiesWOB)\n",
"\t* * [Notebook](http://nbviewer.ipython.org/url/maartenmarx.nl/teaching/ISatWork/Data/SubsidiesWOB/SubsidiesWOB.ipynb)\n",
"* Allerlei gegevens over onderwijs in Nederland: \n",
"\t* Gebruik `wget` om al die csv bestanden met 1 script automatisch op te halen. Samen met de bijbehorende beschrijvingen in PDF.\n",
"\t* Een beginnetje is `wget -nd -r -np -l 8 http://www.ib-groep.nl/organisatie/open_onderwijsdata/databestanden/default.asp`\n",
"* Openspending.nl. Allerlei financiele data van nederlandse provincies en gemeentes. \n",
"\t* Voorbeeld onderzoeksvragen op deze data:\n",
"\t\t* Provinciale reserves: provincies zouden veel geld over hebben en op de plank hebben liggen vanwege de verkoop van energiebedrijven. Hoe zit het met de reserves van de provincies en in hoeverre zijn die nog over. Wat zijn verschillen tussen de provincies?\n",
"\t\t* Wat zijn grote fluctuaties binnen gemeenten tussen 2009 en 2014 in het kader van uitgaven? Is de crisis te zien in bijv. het aantal bijstandsuitkeringen en het geld wat daarin omgaat. En geven gemeentes minder uit aan andere zaken daardoor? Zoals bijv. groenvoorziening?\n",
"* Er zitten ook nog twee leuke datasets bij het Pandas book:\n",
"de movielens-data en fantastische data met voornamen in Amerika. Zie [het notebook behorende bij Hoofdstuk 2](http://nbviewer.ipython.org/github/pydata/pydata-book/blob/master/ch02.ipynb) en de data staat op \n",
"\t* Voor een grotere (10M) movielens dataset, zie (10 million ratings and 100,000 tag applications applied to 10,000 movies by 72,000 users.)\n",
"* Ten slotte staan er in de [Lecture notes van week 6](../LectureNotes/lecture_notes_week_6.html#data) nog een paar tekstuele datasets genoemd die beschikbaar zijn.\n",
"* [CrowdFlower](http://www.crowdflower.com/data-for-everyone) heeft ook flink wat beschikbare datasets.\n",
"\n",
" \n",
" \n",
" \n",
" \n",
"## [Assignment](id:as)\n",
"\n",
"Doe een mini-projectje met _\"big data\"_ en doe daar verslag van in de vorm van een IPython notebook. \n",
"\n",
"Je bent vrij in het kiezen van \n",
"\n",
"* de data\n",
"* de onderzoeksvraag\n",
"* de bijbehorende literatuur\n",
"\n",
"#### Tip\n",
"Gebruik dit mini-projectje als een eerste opzet voor je scriptie. Of om te kijken of je dat ene idee voor je scriptie echt wel ziet zitten. \n",
"\n",
"#### Vorm \n",
"De **vorm** van je verslag ziet er als volgt uit:\n",
"\n",
"1. Een draaiend IPython notebook met de volgende secties\n",
"2. Title, authors, abstract\n",
"\t3. hoogout 150 woorden\n",
"3. Introduction\n",
"\t* Bevat je onderzoeksvraag (of vragen)\n",
"\t* Plaatst je vraag in de bestaande literatuur.\n",
"\t* hooguit 500 woorden\n",
"4. Related work\n",
"\t* Korte opsomming van het wetenschappelijke werk waarin jouw mini projectje ligt. \n",
"\t* 5 sleutel referenties zijn voldoende.\n",
"\t* Doe het netjes met linked verwijzingen.\n",
"5. Methodology **key section**\n",
"\t* Data verzameling en beschrijving van de data\n",
"\t\t1. Hoe _is_ de data verzameld, en hoe heb _jij_ die data verkregen?\n",
"\t\t2. Wat staat er in de data? Niet alleen maar een technisch verhaal, maar ook inhoudelijk. DE lezer moet een goed idee krijgen over de technische inhoud en wat het betekent.\n",
"\t* Hoe je je vraag gaat beantwoorden.\n",
"\t* Dit is de langste sectie van je stuk. Als iets erg technisch wordt kan je het naar de Appendix verplaatsen. Probeer er een lopend verhaal van te maken.\n",
"6. Evaluatie **key section**\n",
"\t* In hoeverre is je vraag beantwoord?\t\n",
"\t* Een mooie graphic/visualisatie is hier heel gewenst.\n",
"\t* Hou het kort maar krachtig.\n",
"7. Conclusie\n",
"\t8. * 100-150 woorden max.\n",
"7. Appendix\n",
"\t* Alle, voor het lopende verhaal niet zo relevante, draaiende code.\n",
"8. Slideshow van dit notebook, ingebed in het notebook. \n",
"\t* Zie en verder hoe je een slideshow maakt van een notebook.\t\t\n",
"\n",
"##### Zorg dat je verslag leesbaar is als een 'scriptie'.\n",
" \n",
"##### Presentatie met slides\n",
"Naast het inleveren van het verslag geef je een presentatie met de slides die je hebt gemaakt van je notebook.\n",
"\n",
"Behandel in je slides ook de 7 stappen uit je notebook. Je slides hoeven natuurlijk niet het gehele notebook te bevatten.\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.11"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
\n",
"\n",
"## [Literature](id:lit)\n",
"* Overzichtelijk artikel waarin een aantal maten worden beschereven en toegepast op een dataset, en daarna vergeleken.\n",
" \n",
"## [Project topics](id:top) \n",
"\n",
"### Data projectje als begin van je scriptie\n",
"* Als je een scriptie gaat schrijven die gebruik maakt van een flinke hoeveelheid data kan je prima deze opdracht als mooi eerste begin gebruiken. \n",
"* Je kunt dan met je groepje alvast een grondige eerste analyse uitvoeren.\n",
"\n",
"### Voorbeelden met bestaande datasets:\n",
"Er staan verschillende onderwerpen met datasets in de [Data folder](../Data/).\n",
"* Bouw verder aan de wordcloud/samenvatter van UvA proefschriften.\n",
" * Zie onderaan.\n",
" * Maak samenvattingenvan \"alle\" UvA proefschriften (allemaal direct te downloaden in PDF van uva.dare.nl)\n",
" * Verbeter de samenvattingen verder.\n",
" * Maak samenvattingen per hoogleraar (bijv Dick Swaab), en laat ontwikelingen door de tijd zien.\n",
"* [Cito toets scores per school in Nederland](../Data/CitoToets)\n",
"\t* [Notebook](http://nbviewer.ipython.org/url/maartenmarx.nl/teaching/ISatWork/Data/CitoToets/CitoToets.ipynb)\n",
"* Allerlei gegevens over het Voortgezet Onderwijs (middelbare school) in Nederland\n",
" * \n",
"* [WOB verzoeken subsidies aan bedrijven](../Data/SubsidiesWOB)\n",
"\t* * [Notebook](http://nbviewer.ipython.org/url/maartenmarx.nl/teaching/ISatWork/Data/SubsidiesWOB/SubsidiesWOB.ipynb)\n",
"* Allerlei gegevens over onderwijs in Nederland: \n",
"\t* Gebruik `wget` om al die csv bestanden met 1 script automatisch op te halen. Samen met de bijbehorende beschrijvingen in PDF.\n",
"\t* Een beginnetje is `wget -nd -r -np -l 8 http://www.ib-groep.nl/organisatie/open_onderwijsdata/databestanden/default.asp`\n",
"* Openspending.nl. Allerlei financiele data van nederlandse provincies en gemeentes. \n",
"\t* Voorbeeld onderzoeksvragen op deze data:\n",
"\t\t* Provinciale reserves: provincies zouden veel geld over hebben en op de plank hebben liggen vanwege de verkoop van energiebedrijven. Hoe zit het met de reserves van de provincies en in hoeverre zijn die nog over. Wat zijn verschillen tussen de provincies?\n",
"\t\t* Wat zijn grote fluctuaties binnen gemeenten tussen 2009 en 2014 in het kader van uitgaven? Is de crisis te zien in bijv. het aantal bijstandsuitkeringen en het geld wat daarin omgaat. En geven gemeentes minder uit aan andere zaken daardoor? Zoals bijv. groenvoorziening?\n",
"* Er zitten ook nog twee leuke datasets bij het Pandas book:\n",
"de movielens-data en fantastische data met voornamen in Amerika. Zie [het notebook behorende bij Hoofdstuk 2](http://nbviewer.ipython.org/github/pydata/pydata-book/blob/master/ch02.ipynb) en de data staat op \n",
"\t* Voor een grotere (10M) movielens dataset, zie (10 million ratings and 100,000 tag applications applied to 10,000 movies by 72,000 users.)\n",
"* Ten slotte staan er in de [Lecture notes van week 6](../LectureNotes/lecture_notes_week_6.html#data) nog een paar tekstuele datasets genoemd die beschikbaar zijn.\n",
"* [CrowdFlower](http://www.crowdflower.com/data-for-everyone) heeft ook flink wat beschikbare datasets.\n",
"\n",
" \n",
" \n",
" \n",
" \n",
"## [Assignment](id:as)\n",
"\n",
"Doe een mini-projectje met _\"big data\"_ en doe daar verslag van in de vorm van een IPython notebook. \n",
"\n",
"Je bent vrij in het kiezen van \n",
"\n",
"* de data\n",
"* de onderzoeksvraag\n",
"* de bijbehorende literatuur\n",
"\n",
"#### Tip\n",
"Gebruik dit mini-projectje als een eerste opzet voor je scriptie. Of om te kijken of je dat ene idee voor je scriptie echt wel ziet zitten. \n",
"\n",
"#### Vorm \n",
"De **vorm** van je verslag ziet er als volgt uit:\n",
"\n",
"1. Een draaiend IPython notebook met de volgende secties\n",
"2. Title, authors, abstract\n",
"\t3. hoogout 150 woorden\n",
"3. Introduction\n",
"\t* Bevat je onderzoeksvraag (of vragen)\n",
"\t* Plaatst je vraag in de bestaande literatuur.\n",
"\t* hooguit 500 woorden\n",
"4. Related work\n",
"\t* Korte opsomming van het wetenschappelijke werk waarin jouw mini projectje ligt. \n",
"\t* 5 sleutel referenties zijn voldoende.\n",
"\t* Doe het netjes met linked verwijzingen.\n",
"5. Methodology **key section**\n",
"\t* Data verzameling en beschrijving van de data\n",
"\t\t1. Hoe _is_ de data verzameld, en hoe heb _jij_ die data verkregen?\n",
"\t\t2. Wat staat er in de data? Niet alleen maar een technisch verhaal, maar ook inhoudelijk. DE lezer moet een goed idee krijgen over de technische inhoud en wat het betekent.\n",
"\t* Hoe je je vraag gaat beantwoorden.\n",
"\t* Dit is de langste sectie van je stuk. Als iets erg technisch wordt kan je het naar de Appendix verplaatsen. Probeer er een lopend verhaal van te maken.\n",
"6. Evaluatie **key section**\n",
"\t* In hoeverre is je vraag beantwoord?\t\n",
"\t* Een mooie graphic/visualisatie is hier heel gewenst.\n",
"\t* Hou het kort maar krachtig.\n",
"7. Conclusie\n",
"\t8. * 100-150 woorden max.\n",
"7. Appendix\n",
"\t* Alle, voor het lopende verhaal niet zo relevante, draaiende code.\n",
"8. Slideshow van dit notebook, ingebed in het notebook. \n",
"\t* Zie en verder hoe je een slideshow maakt van een notebook.\t\t\n",
"\n",
"##### Zorg dat je verslag leesbaar is als een 'scriptie'.\n",
" \n",
"##### Presentatie met slides\n",
"Naast het inleveren van het verslag geef je een presentatie met de slides die je hebt gemaakt van je notebook.\n",
"\n",
"Behandel in je slides ook de 7 stappen uit je notebook. Je slides hoeven natuurlijk niet het gehele notebook te bevatten.\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.11"
}
},
"nbformat": 4,
"nbformat_minor": 0
}