Lecture Notes Week 6
Topics
Literature
Video
- David Mimno with the slides At _ workshop on topic modeling and the humanities_ 2012.
Furter reading
Notebook
Assignment
Warm up
- Doe alle 4 de delen uit Local copy of topic_modeling_tutorial
- Herhaal de stappen met een eigen corpus.
- Bijvoorbeeld NLTK Reuters,
- iets anders van je zelf,
- of
- neem hiervoor 1 van deze 2 corpora (haal de data zelf op)
- NL debatten
- UK debatten
Neem als document alles binnen 1 topic. In de NL proceedings heb je 1 debat (topic genaamd, ja lekker vewarrend in deze context ;-) per file. In de UK proceedings zitten meerdere debatten per file.
Notes
Ons model van het schrijven van een stuk
- Stel je wit een artikel gaan schrijven.
- Dan (1) bepaal je waarover het zal gaan, en in welke verhouding (de topic distribution)
- En (2), als je gaat schrijven, laat je dat model bepalen welke woorden je gebruikt. Elk woord komt voort uit een topic.
- Dit noemen we een generatief model.
- We nemen aan dat onze documenten zo gemaakt zijn.
- De computer gaat nu dit “latente” generatieve model proberen te leren.
- Het is eigenlijk een proces van reverse engineering.
- We leren een instantie van het model dat het beste past bij de collectie waarover we leren.
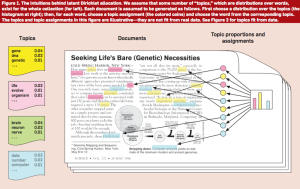
Goal of topic modeling
- The goal of topic modeling is to automatically discover the topics from a collection of documents.
- The documents themselves are observed, while the topic structure—the topics, per-document topic distributions, and the per-document per-word topic assignments—is hidden structure.
- The central computational problem for topic modeling is to use the observed documents to infer the hidden topic structure.
- This can be thought of as “reversing” the generative process— what is the hidden structure that likely generated the observed collection?
Topic modeling = unsupervised learning
- Het enige wat we vertellen aan het algorithme is
- het aantal topics
- de woord frequenties in een verzameling documenten.
- Bag of documents, and bag of words model.
Wat leren we dan?
Uitgelegd met behulp van het voorbeeld:
- De topics:
- De gekleurde lijsten van woorden links
- Elk topic is een taalmodel (Prob. dist. over woorden)
- De $\beta$ parameter
- De verdeling van topics over elk document.
- Het histogram rechts
- de $\theta$ parameter
- De verdeling van de topics over de woorden in elk document.
- "Welke kleurstift we gebruiken"
Het model anders gezegd:
- P(Z|W,D) is, de kans dat je een woord W in document D de kleur Z geeft.
- wordt bepaald door het product van
- P(Z|D) de kans dat Z een kleur is in document D
- en
- P(W|Z) het model van kleur (= topic) Z.
- de kans dat een Z-gekleurd woord woord W is.
De taak anders gezien:
- We willen P(W|Z) en P(Z|D) bepalen.
- We hebben alleen maar P(W|D)
- namelijk gewoon met woordjes tellen
Topic model = soort samenvatting
- Voor topic modelling:
- Elk document is een bag of words
- dus een |V| dimensionale vector
voor V het vocabulair van de collectie.
- V is meestal heel groot (25K - 100K of meer)
- we kunnen dat ook zien als een taalmodel = P(W|D)
- Daarna:
- Elke document is een bag of topics
- een topic model P(Z|D)
- Vele malen kleiner
- aantal topics is meestal tussen 10 en 100
- Dimensionality reduction
- In matrix algebra heet dit principal component analysis
Wat kunnen we met een topic model?
- Enorme text collecties beter behappen.
- Semantisch zoeken.
- Bijvoorbeeld, zoeken met een voorbeeld document
- "Give me more like this"
- Patronen in grote collecties ontdekken
Software
- Malet, veel gebruikt door sociale wetenschappers en historici. Makkelijk te gebruiken.
- Gensim, Python pakket. Wat lastiger.
Data die wij kunnen gebruiken
Deze data is beschikbaar op de UvA. Vraag Maarten Marx.
Bij een paar datasets hebben we wat voorbeeld onderzoeksvragen gezet.
- 60 jaar Telegraaf.
- Waar gaan de mini-advertenties over?
- Hoe verandert dat door de tijd?
- Bijv. Kunnen we sex advertenties zien opkomen?
- Politieke debatten en toespraken.
- Wie blijft er "on topic" en wie niet?
- Hebben partijen hun eigen topics?
- Nog veel meer
- AirBnB
- NY Times
- Wikipedia
- ....
Notes on the tutorial
Het maken van een model uit een verzameling text documenten gaat in een aantal stappen.
Het is belangrijk die stappen goed te snappen, want je moet ze steeds doorlopen.
Die stappen zijn zo om stromende applicaties te kunnen maken, applicaties die werken op heel veel documenten, zonder ze allemaal tegelijk in geheugen te hebben.
Hieronder leg ik niet de stromende stappen uit. Zie daarvoor de tutorial.
stappen
- Maak van je documenten lijsten van woorden.
- Sla die op in een lijst of een generator.
- Maak daarmee een id2word dictionary
- Dit is een dict die woorden naar integer ids mapped.
- En voor elk woord telt hoe vaak het voorkomt.
- Met de
id2word.doc2bow methode kan je nu je documenten in "bag of words" veranderen.
- Maak daarmee een corpus:
politics_corpus = [id2word_politics.doc2bow(d[0]) for d in dutch_docs]
- Sla dat desgewenst op
- gensim.corpora.MmCorpus.serialize(filename, politics_corpus)
- Haal desgewenst op
mm_corpus = gensim.corpora.MmCorpus(filename)
- Train een model op basis van dit corpus.
lda_model = gensim.models.LdaModel(mm_corpus, num_topics=13, id2word=id2word_politics, passes=4)- Dit zijn de topics dus de prob dists over woorden.
- Doe de dimensionality reduction. Map elk document naar een prob dist over de lda topics.
politics_lda_mm=lda_model[mm_corpus]
- Maak nu bijvoorbeeld een index over het "nieuwe corpus" en ga semantische zoeken.
- Vergeet natuurlijk niet ook steeds je query net zo te transformeren als je met de documenten hebt gedaan!