Con-Text : Fine-Grained Object Classification Using Scene Text

Automatic visual classification of very similar instances, a.k.a. fine-grained classification, is the problem of assigning images to classes where all instances differ only by minute details. Examples include flower types or specific bird species. In this project, we propose to use recognized scene texts images to aid in fine-grained classification.
When text is present in natural scenes, the text is typically there to give semantic meaning beyond what is obvious from exclusively visual cues. For instance, in figure above, the left and middle images share a very similar scene layout. However, if one wants to group these images based on the semantics of the scenes, the middle and the right images belong together because they share the same business name ("Starbucks").
In this project, we focus on fine-grained classification of Buildings into their sub-classes such as Cafe, Tavern, Diner, etc. by detecting scene text in images. We introduce a text detection method that does not try to detect all possible foreground text regions but instead aims to reconstruct the scene background to eliminate non-text regions. Object cues such as color, contrast, and objectiveness are used in corporation with a random forest classifier to detect background pixels in the scene.
Video Spotlight
Code
- 1. Please request the source code via email.
- 2. Please send us an email if you are interested obtaining word annotation boxes which are reported in "Words Matter".
Dataset
Con-Text dataset is built from sub-categories of the ImageNet "building" and "place of business" sets to evaluate fine-grained classification. The dataset consists of 28 categories with 24,255 images in total. Note that this dataset is not specifically build for text recognition and thus not all the images have text in them. Moreover, high variability of text size, location, resolution and style and, uncontrolled environmental settings ( illumination ) make text recognition from this dataset harder.
- Images (910MB)
- Word Annotations (2.5MB) README
Related Publications
- This list will be updated. Please cite [1] if you use the dataset.
2. S. Karaoglu, R. Tao, T. Gevers and Arnold W. M. Smeulders Words Matter: Scene Text for Image Classification and Retrieval., IEEE Transactions on MultiMedia (TMM) 2017 [pdf][code]
3. S. Karaoglu, J. C. van Gemert and T. Gevers, Con-Text: Text Detection Using Background Connectivity for Fine-Grained Object Classification., ACM Multimedia (ACM MM) 2013 [pdf] [poster][presentation]
BibTeX
@InProceedings{Karaoglu17,
author = "Sezer Karaoglu and Ran Tao and Jan van Gemert and Theo Gevers",
title = "Con-Text: Text Detection for Fine-grained Object Classification",
booktitle = "IEEE Transactions on Image Processing (TIP)",
year = "2017"
}
Results
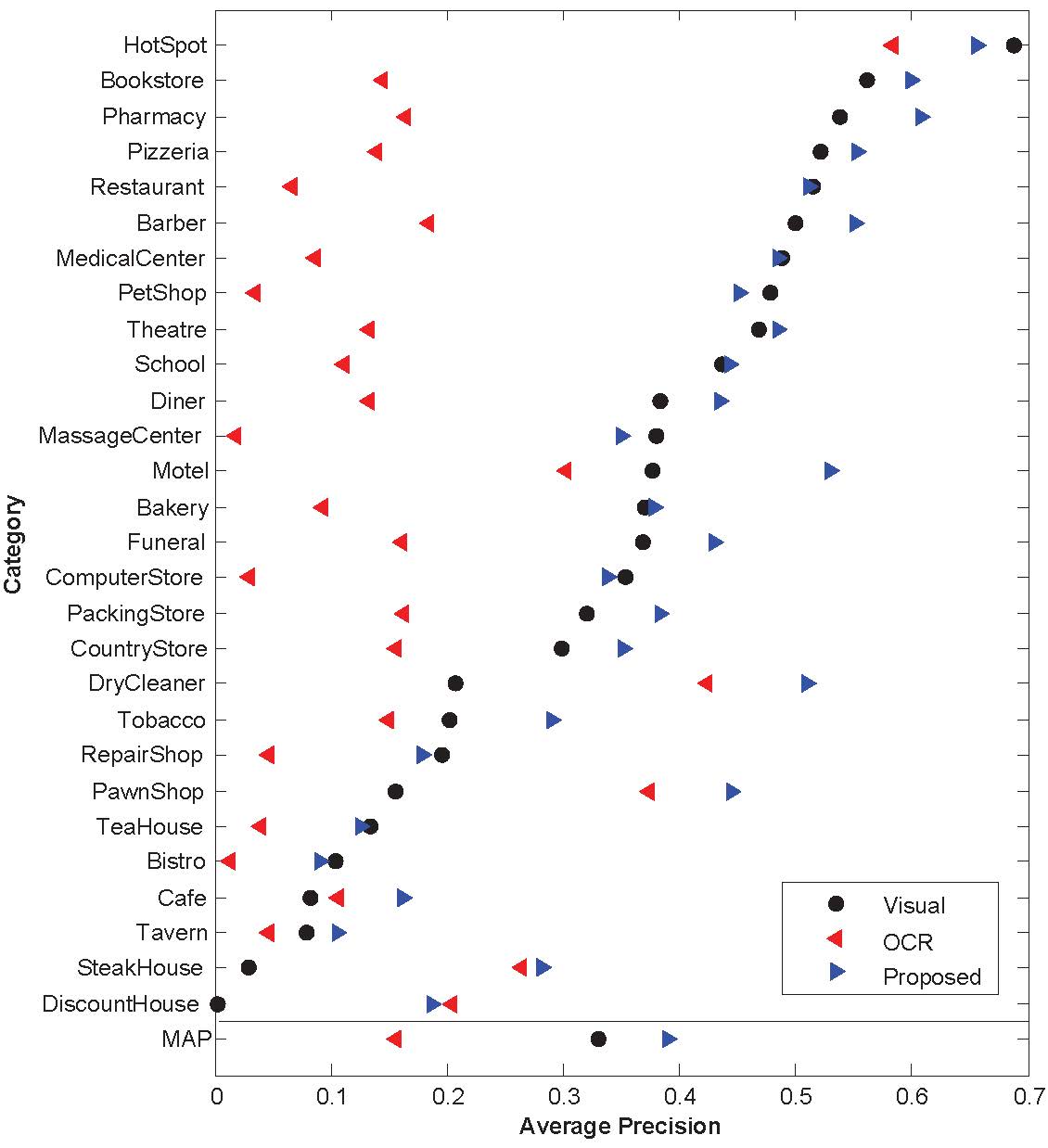
Acknowledgements
Sezer Karaoglu is supported by Dutch national program COMMIT.
Contact
For the questions about the dataset please contact Sezer Karaoglu and Jan C. van Gemert, (s.karaoglu[at]uva.nl and j.c.vangemert[at]uva.nl)