How to automatically update a list of publications from Pure on a research group’s website?
Official route
Ask Pure people for the UUID of the research group and use UvA Dare which looks like:
http://dare.uva.nl/search?org-uuid=1f129de9-e2f4-41a0-a223-94f32e993ac1&smode=iframe
but only validated publications will appear which I find unsatisfactory. Fortunately there is an unofficial route.
Unofficial route
Make a report in Pure, schedule it to be emailed, receive it, and process it. This will include not-yet-validated publications, but it gets messy:
– Make a report
See the video and use report type ‘Listing’:
http://www.atira.dk/en/pure/screencasts/how-to-get-familiar-with-reporting-4.12.html
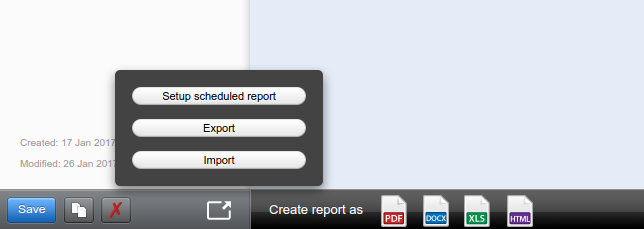
– Schedule it to be emailed
Schedule the report to be send in HTML format to a gmail account dedicated for this purpose:
– Receive it
Set your gmail-name and gmail-password in the script below and use it to install and configure ‘fetchmail’, ‘procmail’ and ‘mpack’. Only tested on Ubuntu Linux.
# based on: https://outhereinthefield.wordpress.com/2015/06/14/scripting-gmail-download-and-saving-the-attachments-with-fetchmail-pro
cmail-and-munpack/
####################################
email=my-gmail-name
password=my-gmail-password
####################################
### install software
sudo apt-get install fetchmail procmail mpack
### config fetchmail
echo "poll pop.gmail.com
protocol pop3
timeout 300
port 995
username \"${email}@gmail.com\" password \"${password}\"
keep
mimedecode
ssl
sslcertck
sslproto TLS1
mda \"/usr/bin/procmail -m '$HOME/.procmailrc'\"" > $HOME/.fetchmailrc
chmod 700 $HOME/.fetchmailrc
### config procmail
echo "LOGFILE=/home/${USER}/.procmail.log
MAILDIR=/home/${USER}/
VERBOSE=on
:0
Maildir/" > $HOME/.procmailrc
mkdir -p $HOME/Maildir/process
mkdir -p $HOME/Maildir/process/landing
mkdir -p $HOME/Maildir/process/extract
mkdir -p $HOME/Maildir/process/store
mkdir -p $HOME/Maildir/process/archive
Then use this script in a cron job to copy the ‘.html’ attachment to the target file (email with report is expected around 1:00 am):
#!/bin/bash
####################################
targetfile=/var/www/publications.html
####################################
DIR=$HOME/Maildir
LOG=$HOME/Maildir/getpublications.log
date +%r-%-d/%-m/%-y >> $LOG
fetchmail
mv $DIR/new/* $DIR/process/landing/
cd $DIR/process/landing/
shopt -s nullglob
for i in *
do
echo "processing $i" >> $LOG
mkdir $DIR/process/extract/$i
cp $i $DIR/process/extract/$i/
echo "saving backup $i to archive" >> $LOG
mv $i $DIR/process/archive
echo "unpacking $i" >> $LOG
munpack -C $DIR/process/extract/$i -q $DIR/process/extract/$i/$i
find $DIR/process/extract/$i -name '*.html' -exec cp {} ${targetfile} \;
done
shopt -u nullglob
echo "finishing.." >> $LOG
mv $DIR/process/extract/* $DIR/process/store/
echo "done!" >> $LOG
– Process it
Add this to the script above to clean up the report and add links:
# remove header and footer
perl -i -0pe 's/<h1 class="ReportTitle">.*?<br>//igs' ${targetfile}
perl -i -0pe '$datestring = localtime(); s/<span class="body">.*?<br>.*?<br>/<span class="body">updated $datestring<\/span>/igs' ${targetfile} # insert update time
perl -i -0pe 's/<h2 class="ReportElementTitle">.*?<\/h2>//igs' ${targetfile}
perl -i -0pe 's/<p class="reportdescription">.*?<\/p>//igs' ${targetfile}
# remove paragraph counts
perl -i -0pe 's/(<h3 class="ListGroupingTitle1">).*?\. /$1/igs' ${targetfile}
# add links
perl -i -0pe 's/(?<total><strong>(?<title>.*?)<\/strong>)/<a href="https:\/\/www.google.nl\/#q=%22$+{title}%22">$+{total}<\/a>/igs' ${targetfile}