6.4.2. The Classical View on Neural Networks
In the classical view on neural networks graphs are used as well as in the modern view. In the classical graphs each node represents both a function as well as the value that it the outcome of that function., the edges in the graph indicate both the flow of values as well as the ‘connection strengths’ (the weight values).
A two layer network with one output node is the same as a logistic regression unit. The input layer contains \(n\) values (in the input nodes the values are not processed). In the node in the second layer we first calculate a weighted sum of the input values \(a_i\) and add a bias term to it
where \(\v a\) is the vector \((a_1\cdots a_n)\T\) and \(\hv a\) is the augmented vector \((1 \; a_1\cdots a_n)\T\). The extra element equal to 1 is added to ‘pick up’ the bias term \(\theta_0\). The final value is
where \(g\) is the activation function.. For now think of the logistic function as it is also used in logistic regression.
To get an entire layer in a nearal network we feed our input vector \(\hv a\) not in one logistic regression node but in \(m\) nodes. Each of those nodes is characterized with its own parameter vector \(\v\theta_j\) for \(j=1,\ldots,m\). Combining these into a weight matrix \(\Theta\)
The \(m\) outputs then are combined into one vector \({\v a}_\text{out}\). Given an input \({\hv a}_\text{in}\) we have:
Carefully note that whereas the input is augmented (with the 1 element) the output is not augmented.
Now we can build a complete network with these layers of ‘logistic regression units’.
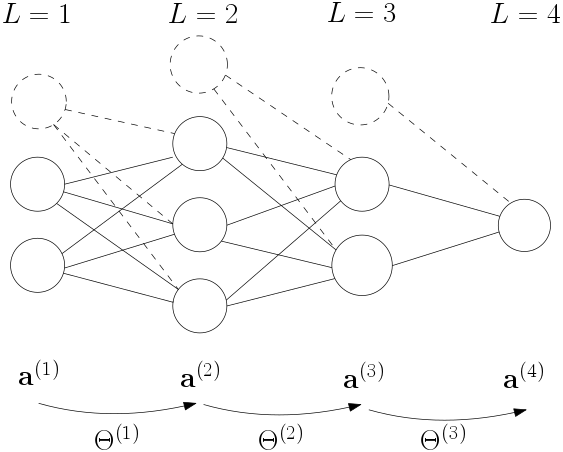
Fig. 6.4.9 A 4 layer neural network. The number of nodes in each of the layers is 2,3,2,1. The ‘bias nodes’ (dashed) are not counted. There are three weight matrices in this network \(\Theta\ls 1\), \(\Theta\ls 2\) and \(\Theta\ls 3\).
Note that in the classical view this is called a 4 layer network as the input nodes are called a layer as well (although nothing is calculated in that ‘layer’). A \(L\)-layer network is thus characterized with \(L-1\) weight matrices.
The values in the nodes in one layer are called the activation of that layer and we will write the activation in layer \(l\) as \(\v a\ls l\). We start numbering at 1 so \(\v a\ls 1\) is the input \(\v x\) to our network. Going from layer 1 to layer 2 we have:
In general going from layer \(l\) to layer \(l+1\) we have:
The final output of the network is \(\v a\ls L\). Formally we write
where the \(\v\Theta\) is used to indicate all weight matrices in the network, \(\v\Theta =\{\Theta\ls 1,\cdots\Theta\ls{L-1}\}\). Note that the above expression is sloppy math, the \(\v x\) in the left hand side is nowhere to be found on the right hand side. But evidently \(\v a\ls L\) depends ultimately on \(\v x = \v a\ls 1\).
Finding all the parameters in a neural network boils down to finding all weight matrices in the network. Assuming a mean squared error loss over a learning set of tuples \((\v x\ls i, \v y\ls i)\) for \(i=1,\ldots,m\), we have the following loss (cost) to be minimized:
We have left out a possible regularization term. Also note that the cross entropy error measure as used in logistic regression can be used here as well,
The minimization of the cost (or loss) function is the same as for all other minimization procedures that we have encountered before: gradient descent:
In these lecture notes you will not find the expressions for the cost gradients (in this form). Instead we will first rewrite the neural network into the computational graph formalism and do the backpropagation in that formalism. The reason that we go that route is twofold. First the derivations are easier (IMHO). Secondly and more importantly the ‘language’ used is the one from the modern view on neural networks paving the way for a somewhat easier understanding of deep learning methodologies.