2.6. Probability Distributions
There are a lot of probability mass functions and probability density functions for which an analytical expression is known. These functions are parameterized in the sense that only a few parameters define the value for every value \(x\).
In this section we discuss some of the most often used functions. In a later section we describe one method to estimate the parameters given a sample from a distribution.
2.6.1. Discrete Distributions
A discrete distribution is completely characterized with its probability mass function \(p_X\). Remember that for a probability mass function we should have that the sum over all possible outcomes \(x\) equals 1 and that all probabilities are greater than or equal to zero. Given that function we will calculate (or only give the result) both the expectation and the variance.
2.6.1.1. Bernoulli Distribution

Fig. 2.6.1 Heads or Tails. Grammarist explains. “Heads refers to the side of the coin with a person’s head on it. Tails refers to the opposite side, not because there is a tail on it, but because it is the opposite of heads.”
The simplest of all probabilistic experiments perhaps is tossing a coin. The outcome is either heads or tails, or 0 or 1. Such an experiment is called a Bernoully experiment and the corresponding distribution is called the Bernoulli distribution.
The Bernoulli distribution has parameter \(p\). In case the random variable \(X\) is Bernoulli distributed we write \(X\sim\Bernoulli(p)\).
The probability mass function is:
The expectation equals:
and its variance:
2.6.1.2. Binomial Distribution
Fig. 2.6.2 Galton Board. A simulation of a Galton board. The distribution of the ball over the bins follows binomial distribution. Open the animated gif image in a separate window to clearly see the pins that force a falling ball to go either left or right (the Bernouilli experiment). Google for Galton board video and you can see a physical Galton board in action.
Consider a Bernoulli distributed random variable \(Y\sim\Bernoulli(p)\), and let us repeat the experiment \(n\) times. What then is the probabilty of \(k\) successes. A success is defined as the outcome \(Y=1\) for the Bernoulli experiment.
So we define a new random variable \(X\) that is the sum of \(n\) outcomes of repeated independent and identicallu distributed (iid) Bernoulli experiments.
The outcomes of \(X\) run from \(0\) to \(n\) and the probability of finding \(k\) successes is given as:
This is called the Binomial Distribution. For a random variable \(X\) that has a binomial distribution we write \(X\sim\Bin(n,p)\).
The expectation is:
and the variance:
Show code for figure
1import numpy as np
2import matplotlib.pyplot as plt
3
4from scipy.stats import binom
5
6n = 20
7for p, c in zip([0.05, 0.4, 0.8], ['r', 'g', 'b']):
8 plt.stem(np.arange(0, n+1), binom.pmf(np.arange(0, n+1), n, p),
9 linefmt=c, markerfmt=c+'o',
10 label=f'p={p}')
11
12 plt.legend()
13plt.xticks(np.arange(0, n+1))
14plt.savefig('source/figures/binomialdistribution.png')
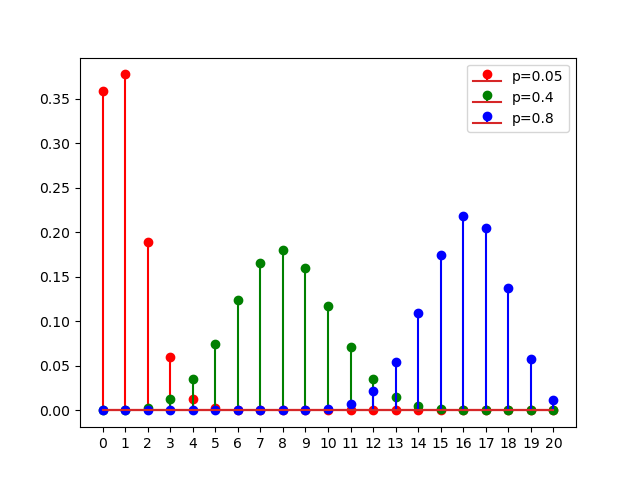
Fig. 2.6.3 Binomial Distribution. Shown are the binomial probability mass functions for \(n=20\) and \(p\in\{0.05, 0.4, 0.8\}\).
2.6.1.3. Uniform Distribution

Fig. 2.6.4 Twelve sided die. Throwing this die result in a number in the range from 1 to 12 to show on top with equal probability (in case of a fair die).
The discrete uniform distribution is used in case all possibe outcomes of a random experiment are equally probable. Let \(X\sim\Uniform(a,b)\), with \(a<b\) and \(a,b\in\setZ\), then
Its expectation is:
and its variance
2.6.2. Continuous Distributions
2.6.2.1. Uniform Distribution
The continuous uniform distribution characterizes a random experiment in which each real valued outcome in the interval \([a,b]\subset\setR\) is equally probable. The probability density function of \(X\sim\Uniform(a,b)\) is given by
The expectation of the continuous uniform distribution is
and its variance
2.6.2.2. Normal Distribution
The normal distribution is undoubtly the most often used distribution in probability and machine learning. For good reasons: a lot of natural phenomena of random character turn out to be normally distributed (at least in good approximation). Furthermore the normal distribution is a nice one to work with from a mathematical point of view.
Let \(X\sim\Normal(\mu,\sigma^2)\) then the probability density function is:
where the parameters \(\mu\) and \(\sigma^2\) are called the mean and variance for obvious reasons:
There is no analytical expression for the cumulative distribution function \(F_X\) for \(X\sim N(0,1)\) (nor for any normal distribution). We Instead we write:
where \(\text{erf}\) is the error function
The error function is available in Numpy as scipy.special.erf. Given
\(F_X(x)\) we can easily calculate the probability for any outcome in
the interval from \(a\) to $b%:
Famously we have:
which are illustrated in the figure below:
Show code for figure
1import numpy as np
2import matplotlib.pyplot as plt
3from scipy.special import erf
4
5def Phi(x):
6 return 0.5 * (1 + erf(x / np.sqrt(2)))
7
8def phi(x):
9 return 1/np.sqrt(2*np.pi) * np.exp(-x**2/2)
10
11fig, axs = plt.subplots(3)
12x = np.linspace(-4, 4, 1000)
13
14for i, s in enumerate([1,2,3]):
15 axs[i].plot(x, phi(x))
16 xi = x[np.logical_and(x>-s, x<s)]
17 axs[i].fill_between(xi, 0, phi(xi))
18 axs[i].text(2, 0.3, "P = {P:5.3f}".format(P=Phi(s)-Phi(-s)))
19 plt.axhline(0)
20
21plt.savefig('source/figures/normalintervals.png')
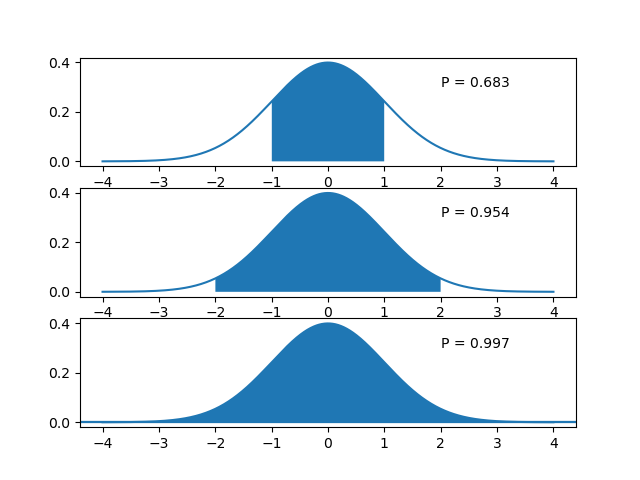
Fig. 2.6.5 Normal Distribution. Shown are the intervals from \(\mu-k\sigma\) to \(\mu + k\sigma\) and their probability \(\P(\mu-k\sigma\leq x \leq \mu+k\sigma)\) for \(k=1,2,3\).