Natural Language Processing & Artificial Intelligence
One of my main research ambitions in AI and NLP is to develop a general-purpose framework for applying appropriate analysis and interpretation methods to neural network models of text and speech. With colleagues and students, we distinguish two types of interpretation techniques and work on both types: data-driven and hypothesis-driven methods.
Hypothesis-driven methods test whether specific a priori defined information can be decoded from the internal states of a neural model. For instance, hypothesis-driven methods can be used to answer questions like “Does my translation model encode morphology?”.
Data-driven methods instead do not require a specific hypothesis about what information is encoded, but can consider in a more open way how representations are formed. Data-driven methods are more suitable for open questions such as “What kind of words are the main drivers for a particular translation”.
We aim to advance and integrate both types of interpretation techniques, as we explain below.
Hypothesis-driven methods
A variety of analysis techniques have been proposed in the academic literature for better understanding the representations learned by deep learning models of language. The main families of such methods include diagnostic classifiers (or probing techniques), representational similarity analysis and canonical correlation analysis.
Diagnostic classifiers often use the activations from different layers of a deep learning architecture as input to a prediction model. Success in predicting the target information is taken as evidence that the original model encodes that information in order to perform the task it is optimized for.
Representational Similarity Analysis (RSA) methods are borrowed from neuroscience, and used for correlating data points from two different representation spaces. When applied to deep learning models, layer activations construct one such representation space and are compared to the (structured) linguistic representations of each data item.
Canonical correlation analysis (CCA) techniques allow activations of a deep NLP model to be correlated with those of a parallel predictive model through estimating the strength of association between two canonical variates.
Each of these categories of techniques offer strengths and weaknesses. Our focus is to understand the strengths and weaknesses of each category of techniques, and identify which type of network architecture and analysis task they are best suitable for. Furthermore, we will develop integrated methods that combine the exploratory power of each type of technique1. Finally, we will develop a unified framework for applying different interpretation techniques to each case, depending on the characteristics of the task, the modality of the input and the architecture of the model under investigation.
Data-driven methods
Next to evaluating the representations learned by neural networks, we are also concerned with how and why this information ended up in those representations. In particular, we aim to integrate two techniques that can pin-point which events are responsible for the representation of a model at any particular point in time: layer-wise relevance propagation and contextual decomposition.
Layer-wise Relevance Propagation (LRP) is a method that has worked very well in the domain of vision. It has recently been adapted for the types of models that are typically used for processing text and speech. LRP defines specific gradient-based rules that quantify how ‘relevance’ propagates back through the network. For any particular state of the model, this allows to compute a relevance score for any input that the model received before.
Contextual Decomposition (CD) is a forward method, that uses clever linearisations of the non-linear network dynamics to compute how the information stemming from a particular input or model component propagates forward to the model and contributes to the decisions the model makes later on. Importantly, the generalised version of this method (GCD) also allows to understand how decisions depend on the biases of the model itself, irrespective of the information it receives (see Figure 1).
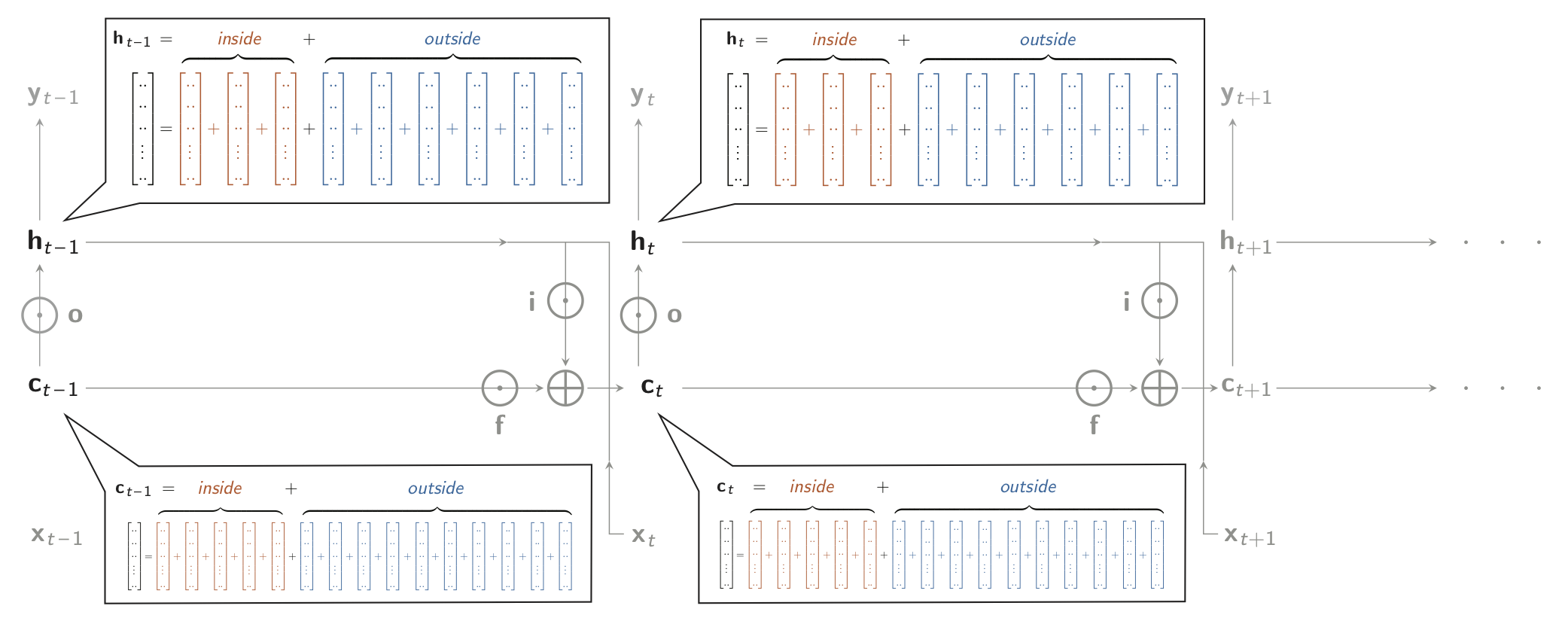
Figure 1. Diagram of an LSTM (unfolded in time), that takes inputs x and produces output y, both changing over time. Shown are the partitionings of the ‘memory cell’ c and the hidden layer h as sums of 15 and 9 terms each, as used in the Contextual Decomposition technique (Murdoch et al., 2018; Jumelet et al., 2019).
Both data-driven methods again have their own advantages and disadvantages. We aim to combine the advantages of both methods to create a best-of-both worlds technique that can show in a computationally efficient way which inputs and model components are responsible for the current model’s decision. We will define and test this technique for several different types of models with different non-linear dynamics and compare the results. Furthermore, we add a specific focus to the influence of the model’s biases, a better understanding of which may play an important role in the development of models that make more fair and predictable decisions.
Cognitive Science & Language
Language is extremely complex, extremely useful, universally found in all human populations and fundamentally different from any system of communication in other animals. Language is also acquired spontaneously within a few years by every healthy human child, and, although there is a recognizable language processing network in the adult brain, it does not seem to rely on anatomical or neural structures, or cell types, proteins or genes that differ fundamentally from those found in closely related species without language.
These sets of properties of language pose a major challenge for the language sciences: how do we reconcile observations about the uniqueness of language with those about the biological continuity of the underlying neural and genetic mechanisms? In my research I try to face this challenge head-on. Where much of the debate in linguistics has been between traditions that emphasized either uniqueness or continuity, I try to develop models that do justice to insights from both traditions.

Iterated Learning
I believe an important part of the solution to this puzzle is the mechanism of cultural evolution, as demonstrated in particular by models in the iterated learning framework (Kirby, 2000) that I helped develop during my PhD research (2000-2005) and afterwards (Zuidema, 2003; Ferdinand and Zuidema, 2009). The key idea here is that languages will, in the cultural transmission from generation to generation, adapt to the peculiarities of pre-existing learning and processing mechanisms of the brain. These pecularities might be there for reasons that have nothing to do with language or communication, but by adapting to them, languages can become much more complex than they could have otherwise (under constraints of expressivity, learnability and processability). This explains how small changes in the biology underlying language could in principle have major effects on the languages that we are able to learn – and thus provides a partial answer to the grand challenge – but much work remains in finding what exactly those small (but essential) biological changes are.
Hierarchical Compositionality
Many language researchers suspect that one of the key biological innovations making language possible is the ability to hierarchically combine words into phrases, small phrases into larger phrases and ultimately into sentences and discourse, while still being able to compute the meaning of these combinations. I have termed this property ’hierarchical compositionality’ (HC), and reviewed evidence from comparative biology that indicates that HC is a central concept in understanding the many qualitative differences between human language and various animal communication
systems (Zuidema, 2013). Interestingly, the difficulty of neural network models to account for HC provides additional evidence that a qualitative rewiring of the neural architecture is required to deal with the HC structure of natural language (e.g., Jackendoff, 2002). HC is therefore a prime candidate for the biological innovations that we are after. An important focus of my research has therefore been the possible neural representation of hierarchical structure in language.
Parsing
Once the ability to represent hierarchical structures is present a new problem arises: how to navigate the space of all possible hierarchical structures that could be assigned to a specific sentence. In computational linguistics this problem is usually conceived of as a problem of probabilistic inference: how do we learn a probabilistic grammar from examples (from a train set) such that the probability it assigns to the correct parse of a previously unseen sentence (from a test set) is higher than the probabilities assigned to incorrect parses. Train and test sets are usually very large (tens or hundreds of thousands of sentences) derived from naturally occurring (written)
text. This is a very different focus than that of psycholinguistics, where the focus has been on a small set of carefully constructed sentences and the temporal, error and neural activation profiles of human interpretations of those sentences.
I have spent much time and effort on developing a framework to solve the probabilistic inference task, which I have called Parsimonious Data-oriented Parsing, which is based on the (not so parsimonious) data-oriented parsing framework (Scha, 1990; Bod, 1998). We have had some great successes, in particular some of the best parsing results (with a pure, generative model) in English (on the Penn WSJ parsing benchmark test) with a model called Double-DOP (Sangati and Zuidema, 2011), which was also key in obtaining state-of-the-art results in parsing German and Dutch (van Cranenburgh and Bod, 2013). See here for an online demo. However, much work remains in connecting the insights we have obtained in this framework (about the actual probabilistic dependencies observable in large corpora) to research in the psycholinguistic tradition (c.f. Sangati and Keller, 2013).
Neural Networks
A first major step in bridging probabilistic grammars and more neurally plausible models of language processing is provided by Recursive Neural Networks (RxNNs). Unlike recurrent neural networks, recursive neural networks are hybrid symbolic-connectionist models, that rely on a symbolic control structure to represent hierarchical structure. That said, they do provide a connectionist alternative
to the treatment of syntactic and semantic categories and probabilities in probabilistic grammars and formal semantics. In that sense, they complement the work I do on neural representation of hierarchical structure by providing a candidate neural account of structural disambiguation and semantic composition.
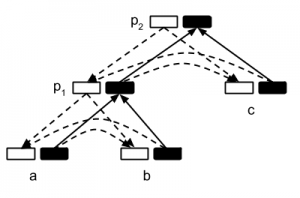
Recently, RxNNs have been successfully applied to a range of different tasks in computational linguistics and formal semantics, including constituency parsing, language modelling and recognizing logical entailment (e.g., Socher et al., 2013). I have worked out, with my PhD student Phong Le, an important extension of the standard RNN that we call Inside-Outside Semantics. This extension involves adding a second vector to every node in a parse tree for representing its context. These context vectors can, like the existing content vectors, be computed compositionally. With this major innovation, and a number of task-specific techniques, we have managed to obtain very promising results on tasks that heretofore did not allow the application of RxNNs: semantic role labeling, missing word prediction, supervised dependency parsing and unsupervised dependency parsing. On the last two task we have obtained state-of-the-art results: above 93% accuracy on supervised parsing (Penn WSJ benchmark) and 66.2% accuracy on unsupervised parsing (previously best was 64.4%).
Artificial Language Learning
In the research discussed so-far I try to account for complex patterns in natural language use. A final strand of my research interests concerns the tradition of Artificial Language Learning, where greatly simplified ’languages’ are designed and presented to participants in controlled experiments. One intriguing aspects of such experiments is that they can involve not only human adults, but also prelinguistic infants and non-human animals. Experiments in this tradition have provided some evidence for human-specific biases and/or skills in discovering patterns. Such findings are obviously extremely relevant for the grand question underlying my research about continuity and complexity. However, it turns out that the evidence is less conclusive than it has sometimes been presented. My work in this area has focused on using insights from modelling and formal language theory to (re)interpret experimental findings.
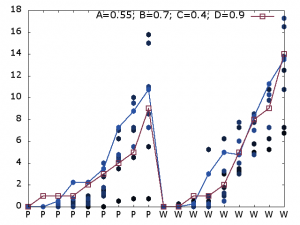
One eye-catching result, published in PNAS (van Heijningen et al., 2009) is that experiments claimed to show that humans and starlings can, while Tamarin monkeys cannot learn contextfree languages suffer from a (non-trivial) problem in the experimental design. With my PhD-student Raquel Alhama we are investigating another finding from this literature, about a dissociation between so-called ’statistical learning’ and ’rule learning’, and a lack of evidence for the latter in rats (and presumably other non-human mammals). We have worked out a unified model that provides an excellent fit with both human and rat data, using quantitatively different parameters for both species but no qualitative difference in the mechanisms involved.