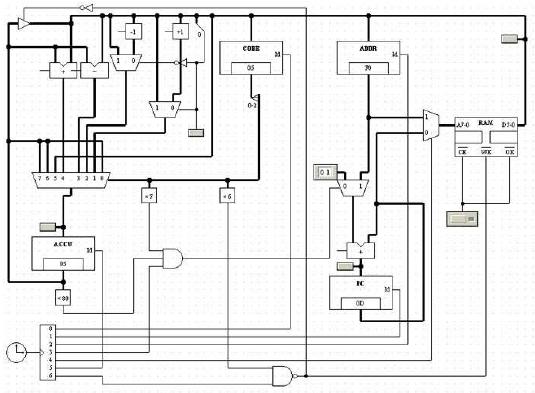
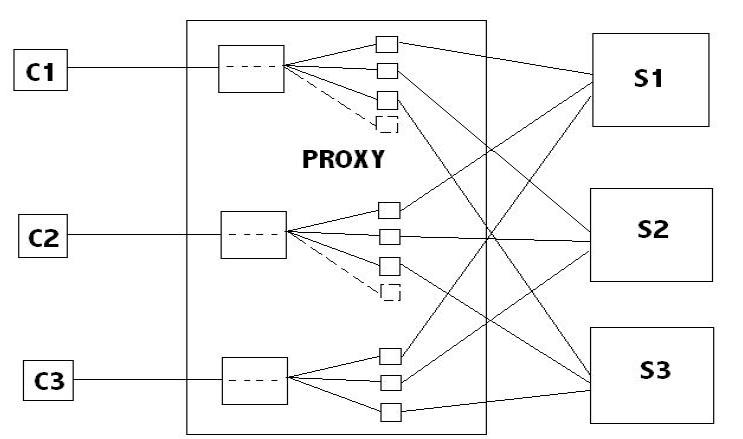
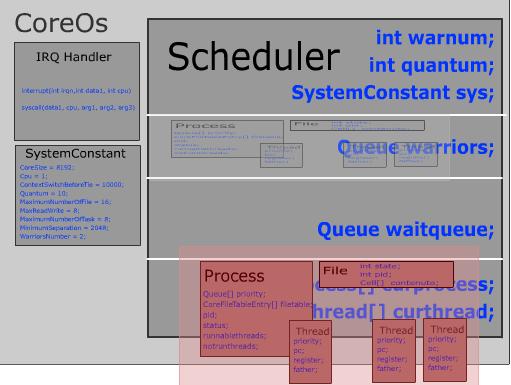
Note: For academic reasons some of the projects' source codes are protected by a password. To obtain the password please contact me by using your university/company mail address (mail from yahoo, hotmail, gmail etc... will not be considered) and clearly state the purpose of your request.
Projects for the University of Amsterdam:- Mean-shift Tracker
- Improving self-localisation and behaviour for Aibo's soccer-playing robots
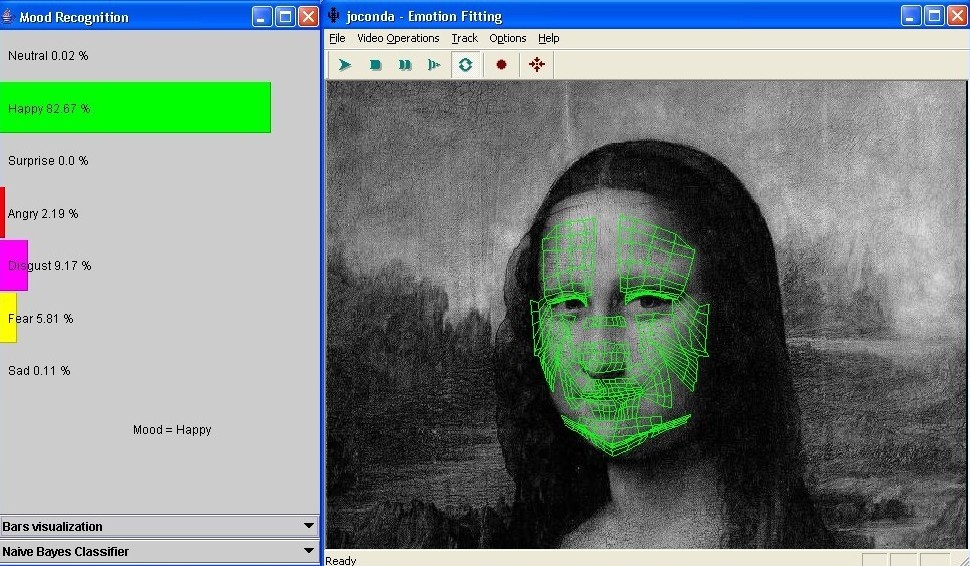
- Affective Human-Computer Interaction
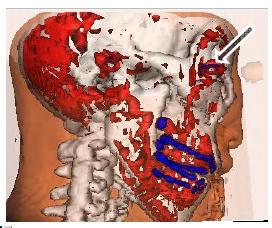
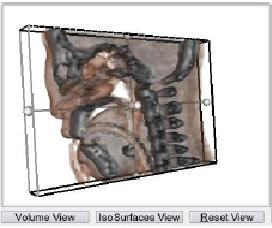
- 3D Visualization of Medical Datasets
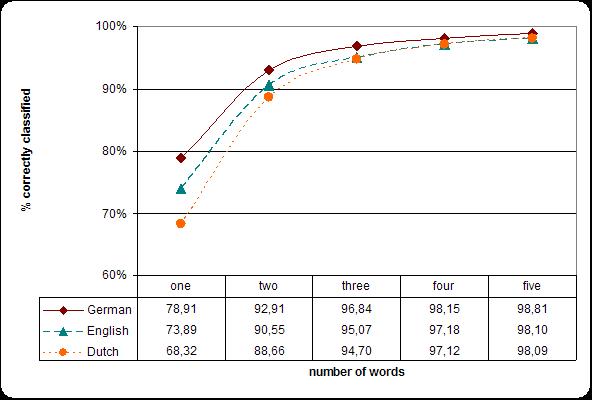
- Deployment of a Language Detector Grid Service
- The Melange Project
- Probabilistic Context Free Grammar Parser
- Part of Speech Tagger
- Q-learning and Value Iteration
- Multiagent coordination
- Multiagent Traffic Management
- One-dimensional Learning
- INCAPS - Intelligent Camera-Projector System
- The GGLE Project
- Bayes Classifier
- Kernel Estimators
- EM for a mixture of Gaussian densities
- Logistic Discriminant
- Adaboost
- Principal Components Analysis