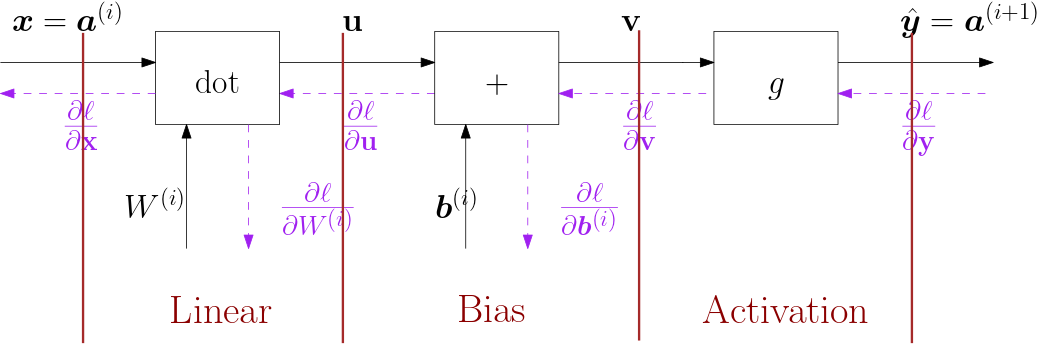
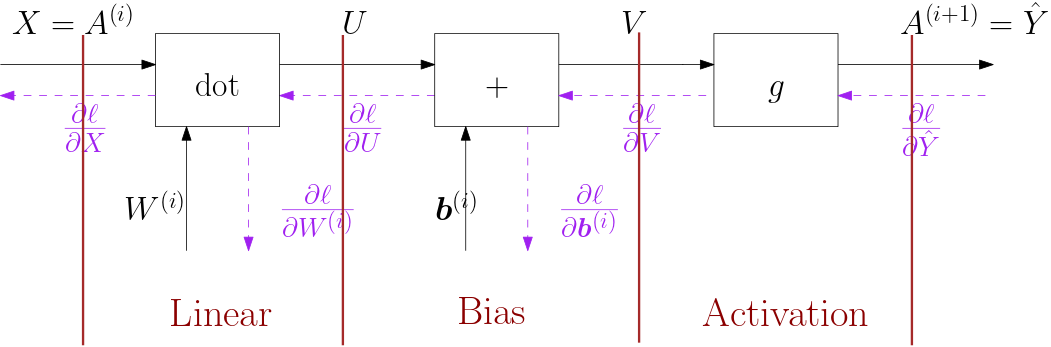
In the figure below one layer in a fully connected neural network is
sketched. Not only the arrows and formula’s for the forward pass are
given but also the arrows and formula’s for the backward pass.
The first sketch is for one training example, input \(\v x\) and output
\(\hat{\v y}\).
Fig. 6.4.19 One layer in a fully connected neural network.
The formulas for the forward pass by concatenating the actions of the
three blocks in one layer (see previous sections). In the formula’s
below we write \(W\) instead of \(W\ls i\) and \(\v b\) instead of \(\v b\ls
i\).
\[\begin{split}\v u &= W \v x\\
\v v &= \v u + \v b &= W\v x + \v b\\
\hat{\v y} &= g\aew(\v v) &= g\aew(W\v x + \v b)\end{split}\]