\(\newcommand{\in}{\text{in}}\) \(\newcommand{\out}{\text{out}}\) \(\newcommand{\prt}{\partial}\)
6.4.3.1. Linear Block
The computational graph of a fully connected linear module is depicted in the figure below.
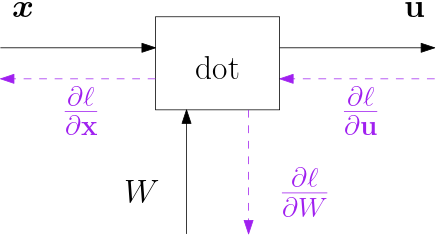
Fig. 6.4.15 Fully Connected Linear Block. The input vector \(\v x\) is mapped on output vector \(\v u = W\v x\).
The input is an \(s_\in\)-dimensional vector \(\v x\) and the output is a vector \(\v u\) that is \(s_\out\) dimensional. We have:
where \(W\) is an $s_\out\times s_\in$ matrix. Assuming \(\pfrac{\ell}{\v y}\) is known we can calculate \(\pfrac{\ell}{\v x}\):
The proof of this result is rather simple. We could either dive into matrix calculus (see Matrix Calculus) or we can give a straightforward proof by looking at the components of the vectors keeping in mind the chain rule for multivariate functions (see Multivariate Functions). We will follow the second route.
and thus
Next we need to know the derivative \(\prt\ell/\prt W\) in order to update the weights in a gradient descent procedure. Again we start with an elementwise analysis:
where
substituting this into the expression for \(\prt \ell/\prt W_{ij}\) we get:
or equivalently:
Let \(X\) be the data matrix in which each row is an input vector and \(U\) is the matrix in which each row it the corresponding output vector then
or
where each row in \(U\) is the linear response to the corresponding row in \(X\). In this case:
or
For the derivative with respect to the weight matrix we have: