4. Convolutional Neural Networks

This year (2021) these notes are freshly written and very sketchy at points. The official material for this subject therefore is the lecture video and the notes made during the lecture. Both can be found on the module page for week 7 in Canvas.
Please look again soon….
We have not discussed in what way computer vision systems can be used to link visual observations with semantic labels. Given an image tell me what i am looking at: a cat, a house, the number 7, etc, etc.
In this chapter we take that ‘simple’ task in mind. Decide whether a particular object or concept is visible in the image. Examples are:
- Recognizing digits (MNIST dataset)
Below are a number of images from the MNIST data set. Small images of handwritten digits.

Fig. 4.6 Handwritten Digits from the MNIST data set. The “Hello World” application for using a CNN.
- Recognizing objects (CIFAR10/CIFAR100 data sets)
Below some examples from the CIFAR-10 image data set. For each of the images a semantic label is given for what is visible in the image. Task is to get the same label using a computer vision system.

Fig. 4.7 CIFAR-10 data set. For 10 different labels (corresponding with 10 different object categories) a lot of small images are available. Nowadays considered an ‘easy’ task, an ideal way to start any new idea for image classification.
- Recognizing objects: ImageNet dataset
ImageNet is a collection of images depicting objected out of 1000 categories (with labels). This set was used in many image classification challenges in the past.

Fig. 4.8 ImageNet data set. Eight images from the ImageNet data set are shown. For each image the true label is given right below the image. The 5 most probable labels (unknown which classifier was used) are given below.
Many more datasets for all kind of challenges are available on the web nowadays. Tasks for CNN’s nowadays are among others:
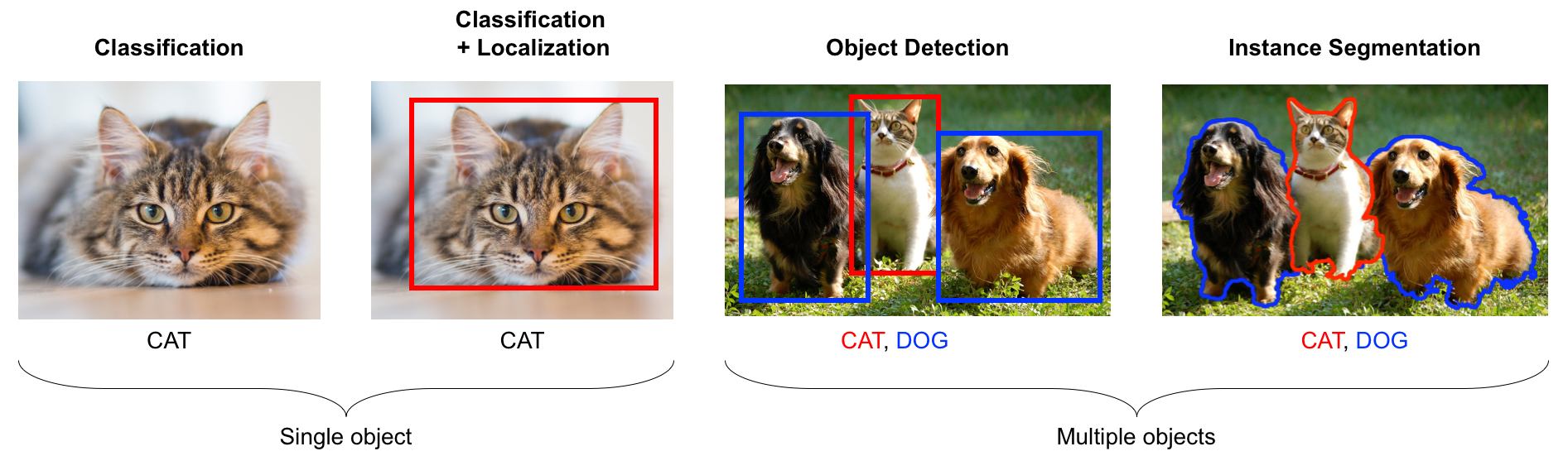
Fig. 4.9 Object Classification / Detection / Segmentation. In these notes we only discuss the classification task. All other tasks are usually tackled by running the classification network on subimages (that are selected in a clever and efficient way to prevent brute force searching at all locations and at all scales). The segmentation task requires a network that does not simply end in a label (and bounding boxes) but that results in a pixel mask indicating all pixels belonging to an object.
recognize AND detect (with a bounding box) an object
recognize and detect multiple objects in images
recognize and segment objects (not only a bounding box but a labeling on pixel level)
Furthermore CNN’s, often in combination with networks specialized for (time) sequences, are used to analyse video’s and detect and analyze motion.

Fig. 4.10 Image Colorization. Starting from a black and white image the CNN can fill in the colors. This is a rare example of a task where ‘labelled’ images (i.e. images with the groundtruth for the required outcome) are easy to obtain.
And there are a lot of applications that were never thought of before: a NN to transfer the Monet painting style onto a photograph. Or the other way round: how to make a photograph out of a painting. Automatic colorization of old black and white pictures and movies. Transfering the movements and expressions from one face to another face leading to the so called /deep fakes/.

Fig. 4.11 Can you tell the spirals apart? The front cover of the (in)famous book “Perceptrons” by Minsky and Papert that allegedly set back the development of neural networks for more than a decade. Whether or not that is true i think there is still a lot of knowledge in that books that needs some more careful analysis (e.g. to answer the above question).
The last 10 years have shown that CNN’s form the basis of applications in the image processing and computer vision field that were then thought of to be only attainable in the far future. But where the last 10 years has shown that CNN based systems are very good at pattern recognition (in human terms: /pre attentive vision/) even much better than we thought was possible, but that there is still a long way to go to get to real understanding (whatever that may be…) of images. As far as i know we still have to come up with a CNN-based vision system that can distinguish between the two spirals in the image on the front cover of the (in)famous book on perceptrons.
In this chapter we lay the foundation for understanding what makes a CNN work. How to do back propagation for layers in a neural network that are convolution operators and what about max-pooling layers? We will look at these networks from a computer vision point of view. Using CNN’s in practice requires more knowledge then we provide in this chapter. For that you will need an advanced machine learning (deep learning) course.
We start with a section on some history on the use of (convolutional) neural networks for image classification. A history that already dates back to the 1950’s.
Then we take a brief look at fully connected neural networks as a starting point for our discussion on convolutional nets. Not only that but most classification type of CNN’s start with (a lot of) convolutions layers but end in several fully connected layers to do the actual classification.
In a subsequent section we will consider a convolutional processing block in a CNN. We will describe the forward pass as a (set of) convolutions and will show that the backward pass also consists of convolutions (albeit with mirrored kernels).